

Multi-Dimensional Information Alignment in Different Modalities for Generalized Zero-Shot and Few-Shot Learning


Abstract
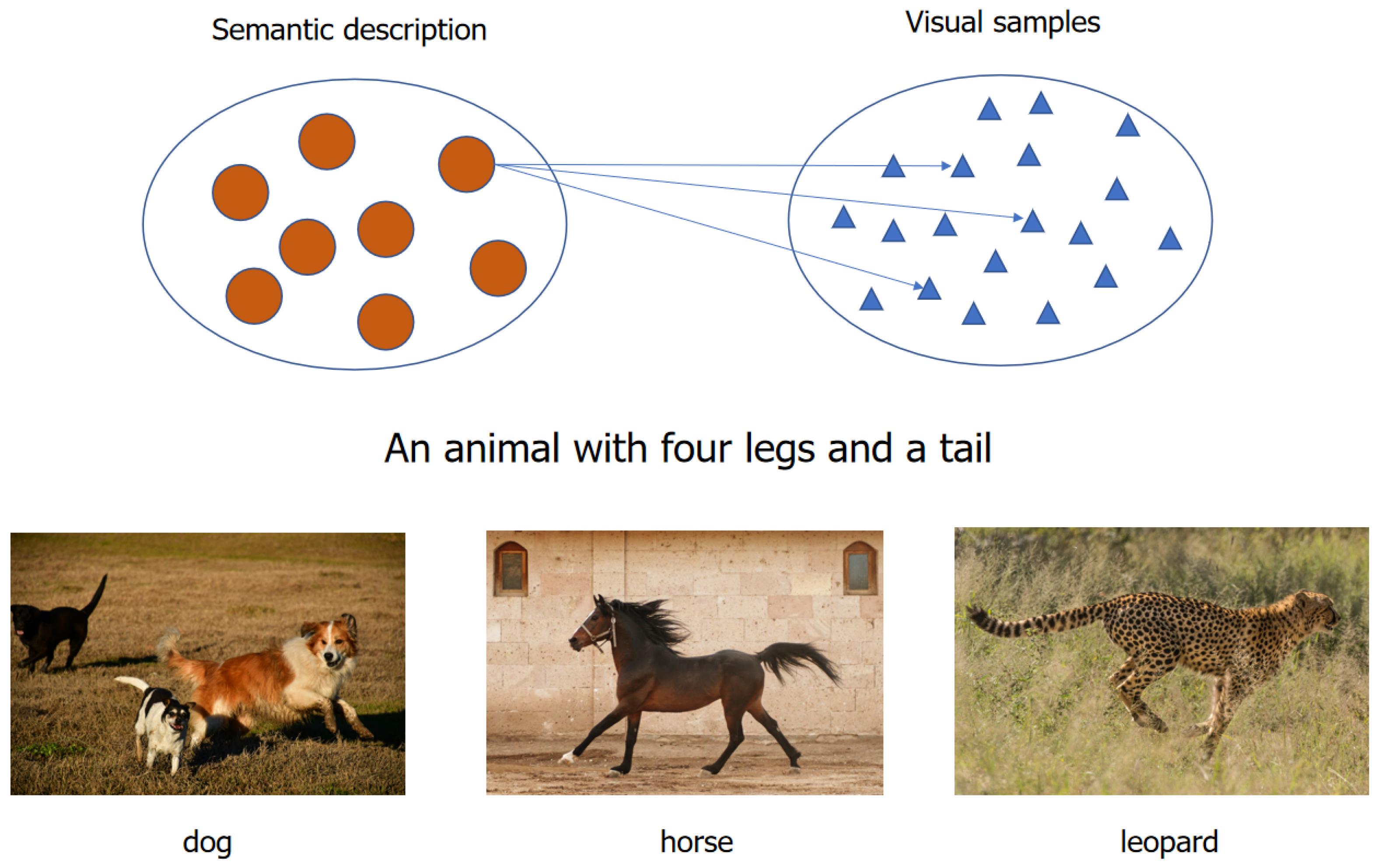
:1. Introduction
- (1)
- The method we put forward can make full use of the intrinsic discriminative information of visible class images. We project visual features and semantic attributes to the distribution of different dimensions in the same latent space, thus mapping information of different modalities to corresponding space positions more accurately.
- (2)
- To the best of our knowledge, we are the first to propose to map the feature information of different modalities into a different dimension of distribution representation in the same latent space. We take our experiment at the setting mapping visual feature and semantic attribute to there-dimensional distribution and two-dimensional distribution respectively in the latent embedding space and have good performance compared to CADA-VAE [11]. It can try more dimensional distributions corresponding to different modalities in the future.
- (3)
- We extensively evaluate our model on four benchmark datasets, i.e., CUB, SUN, AWA1, and AWA2. The result shows our model’s superior performance on ZSL and GZSL settings.
2. Related Work
3. The Proposed Method
3.1. Definitions and Notations
3.2. Variational Autoencoder (VAE)
3.3. New Reparametrization Trick
3.4. Model Loss
4. Experiments
4.1. Benchmark Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Model Analysis on AWA1
4.5. Comparing Approaches
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Lampert, C.H.; Nickisch, H.; Harmeling, S. Learning to detect unseen object classes by between-class attribute transfer. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 951–958. [Google Scholar]
- Xu, T.; Zhao, Y.; Liu, X. Dual generative network with discriminative information for generalized zero-shot learning. Complexity 2021, 2021, 6656797. [Google Scholar] [CrossRef]
- Chao, W.L.; Changpinyo, S.; Gong, B.; Sha, F. An empirical study and analysis of generalized zero-shot learning for object recognition in the wild. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 52–68. [Google Scholar]
- Xian, Y.; Lampert, C.H.; Schiele, B.; Akata, Z. Zero-shot learning—A comprehensive evaluation of the good, the bad and the ugly. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2251–2265. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, S.; Long, M.; Wang, J.; Jordan, M.I. Generalized zero-shot learning with deep calibration network. Adv. Neural Inf. Process. Syst. 2018, 31, 2009–2019. [Google Scholar]
- Dinu, G.; Lazaridou, A.; Baroni, M. Improving zero-shot learning by mitigating the hubness problem. arXiv 2014, arXiv:1412.6568. [Google Scholar]
- Shigeto, Y.; Suzuki, I.; Hara, K.; Shimbo, M.; Matsumoto, Y. Ridge regression, hubness, and zero-shot learning. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Porto, Portugal, 7–11 September 2015; Springer: Cham, Switzerland, 2015; pp. 135–151. [Google Scholar]
- Zhang, L.; Xiang, T.; Gong, S. Learning a deep embedding model for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2021–2030. [Google Scholar]
- Huang, Y.; Deng, Z.; Wu, T. Learning discriminative latent features for generalized zero-and few-shot learning. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Schonfeld, E.; Ebrahimi, S.; Sinha, S.; Darrell, T.; Akata, Z. Generalized zero-and few-shot learning via aligned variational autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8247–8255. [Google Scholar]
- Ni, J.; Zhang, S.; Xie, H. Dual adversarial semantics-consistent network for generalized zero-shot learning. Adv. Neural Inf. Process. Syst. 2019, 32, 6143–6154. [Google Scholar]
- Xian, Y.; Lorenz, T.; Schiele, B.; Akata, Z. Feature generating networks for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5542–5551. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. Adv. Neural Inf. Process. Syst. 2017, 30, 5767–5777. [Google Scholar]
- Vyas, M.R.; Venkateswara, H.; Panchanathan, S. Leveraging seen and unseen semantic relationships for generative zero-shot learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 70–86. [Google Scholar]
- Li, J.; Jing, M.; Lu, K.; Ding, Z.; Zhu, L.; Huang, Z. Leveraging the invariant side of generative zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7402–7411. [Google Scholar]
- Luo, Y.; Wang, X.; Pourpanah, F. Dual VAEGAN: A generative model for generalized zero-shot learning. Appl. Soft Comput. 2021, 107, 107352. [Google Scholar] [CrossRef]
- Chen, S.; Xie, G.; Liu, Y.; Peng, Q.; Sun, B.; Li, H.; You, X.; Shao, L. HSVA: Hierarchical semantic-visual adaptation for zero-shot learning. Adv. Neural Inf. Process. Syst. 2021, 34, 16622–16634. [Google Scholar]
- Bendre, N.; Desai, K.; Najafirad, P. Generalized zero-shot learning using multimodal variational auto-encoder with semantic concepts. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 1284–1288. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Mishra, A.; Krishna Reddy, S.; Mittal, A.; Murthy, H.A. A generative model for zero shot learning using conditional variational autoencoders. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2188–2196. [Google Scholar]
- Patterson, G.; Hays, J. Sun attribute database: Discovering, annotating, and recognizing scene attributes. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2751–2758. [Google Scholar]
- Welinder, P.; Branson, S.; Mita, T.; Wah, C.; Schroff, F.; Belongie, S.; Perona, P. Caltech-UCSD Birds 200; Technical Report CNS-TR-2010-001; California Institute of Technology: Pasadena, CA, USA, 2010. [Google Scholar]
- Socher, R.; Ganjoo, M.; Manning, C.D.; Ng, A. Zero-shot learning through cross-modal transfer. Adv. Neural Inf. Process. Syst. 2013, 26, 935–943. [Google Scholar]
- Verma, V.K.; Arora, G.; Mishra, A.; Rai, P. Generalized zero-shot learning via synthesized examples. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4281–4289. [Google Scholar]
- Xian, Y.; Akata, Z.; Sharma, G.; Nguyen, Q.; Hein, M.; Schiele, B. Latent embeddings for zero-shot classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 69–77. [Google Scholar]
- Akata, Z.; Reed, S.; Walter, D.; Lee, H.; Schiele, B. Evaluation of output embeddings for fine-grained image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2927–2936. [Google Scholar]
- Romera-Paredes, B.; Torr, P. An embarrassingly simple approach to zero-shot learning. In Proceedings of the International Conference on Machine Learning, PMLR, Miami, FL, USA, 9–11 December 2015; pp. 2152–2161. [Google Scholar]
- Akata, Z.; Perronnin, F.; Harchaoui, Z.; Schmid, C. Label-embedding for image classification. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1425–1438. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frome, A.; Corrado, G.S.; Shlens, J.; Bengio, S.; Dean, J.; Ranzato, M.; Mikolov, T. Devise: A deep visual-semantic embedding model. Adv. Neural Inf. Process. Syst. 2013, 26, 2121–2129. [Google Scholar]
- Changpinyo, S.; Chao, W.L.; Gong, B.; Sha, F. Synthesized classifiers for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5327–5336. [Google Scholar]
- Hubert Tsai, Y.H.; Huang, L.K.; Salakhutdinov, R. Learning robust visual-semantic embeddings. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2017; pp. 3571–3580. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Model | S | U | H |
|---|---|---|---|
| DA-VAE | 65.1 | 60.1 | 62.5 |
| CA-VAE | 61.3 | 56.5 | 58.8 |
| CADA-VAE | 72.8 | 57.3 | 64.1 |
| n-CADA-VAE | 74.6 | 61.3 | 67.3 |
| Methods | CUB | SUN | AWA1 | AWA2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S | U | H | S | U | H | S | U | H | S | U | H | |
| CMT [24] | 49.8 | 7.2 | 12.6 | 21.8 | 8.1 | 11.8 | 87.6 | 0.9 | 1.8 | 90.0 | 0.5 | 1.0 |
| SJE [27] | 59.2 | 23.5 | 33.6 | 30.5 | 14.7 | 19.8 | 74.6 | 11.3 | 19.6 | 73.9 | 8.0 | 14.4 |
| ALE [29] | 62.8 | 23.7 | 34.4 | 33.1 | 21.8 | 26.3 | 76.1 | 16.8 | 27.5 | 81.8 | 14.0 | 23.9 |
| LATEM [26] | 57.3 | 15.2 | 24.0 | 28.8 | 14.7 | 19.5 | 71.7 | 7.3 | 13.3 | 77.3 | 11.5 | 20.0 |
| EZSL [28] | 63.8 | 12.6 | 21.0 | 27.9 | 11.0 | 15.8 | 75.6 | 6.6 | 12.1 | 77.8 | 5.9 | 11.0 |
| SYNC [31] | 70.9 | 11.5 | 19.8 | 43.3 | 7.9 | 13.4 | 87.3 | 8.9 | 16.2 | 90.5 | 10.0 | 18.0 |
| DeViSE [30] | 53.0 | 23.8 | 32.8 | 27.4 | 16.9 | 20.9 | 68.7 | 13.4 | 22.4 | 74.7 | 17.1 | 27.8 |
| f-CLSWGAN [13] | 57.7 | 43.7 | 49.7 | 36.6 | 42.6 | 39.4 | 61.4 | 57.9 | 59.6 | 68.9 | 52.1 | 59.4 |
| SE [25] | 53.3 | 41.5 | 46.7 | 30.5 | 40.9 | 34.9 | 67.8 | 56.3 | 61.5 | 68.1 | 58.3 | 62.8 |
| ReViSE [32] | 28.3 | 37.6 | 32.3 | 20.1 | 24.3 | 22.0 | 37.1 | 46.1 | 41.1 | 39.7 | 46.4 | 42.8 |
| CADA-VAE [11] | 53.5 | 51.6 | 52.4 | 35.7 | 47.2 | 40.6 | 72.8 | 57.3 | 64.1 | 75.0 | 55.8 | 63.9 |
| n-CADA-VAE | 54.7 | 51.0 | 52.8 | 35.7 | 50.1 | 41.7 | 74.6 | 61.3 | 67.3 | 78.6 | 57.0 | 66.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, J.; Wu, L.; Wu, D.; Li, J.; Wu, X. Multi-Dimensional Information Alignment in Different Modalities for Generalized Zero-Shot and Few-Shot Learning. Information 2023, 14, 148. https://doi.org/10.3390/info14030148
Cai J, Wu L, Wu D, Li J, Wu X. Multi-Dimensional Information Alignment in Different Modalities for Generalized Zero-Shot and Few-Shot Learning. Information. 2023; 14(3):148. https://doi.org/10.3390/info14030148
Chicago/Turabian StyleCai, Jiyan, Libing Wu, Dan Wu, Jianxin Li, and Xianfeng Wu. 2023. "Multi-Dimensional Information Alignment in Different Modalities for Generalized Zero-Shot and Few-Shot Learning" Information 14, no. 3: 148. https://doi.org/10.3390/info14030148
APA StyleCai, J., Wu, L., Wu, D., Li, J., & Wu, X. (2023). Multi-Dimensional Information Alignment in Different Modalities for Generalized Zero-Shot and Few-Shot Learning. Information, 14(3), 148. https://doi.org/10.3390/info14030148