
Using Natural Language Processing to Analyze Political Party Manifestos from New Zealand †


Abstract
:1. Introduction
1.1. Related Work
1.2. Case Background
2. Materials and Methods
2.1. Data
2.2. Document Similarities
2.3. Topic Modeling
2.4. Sentiment Analysis
3. Results
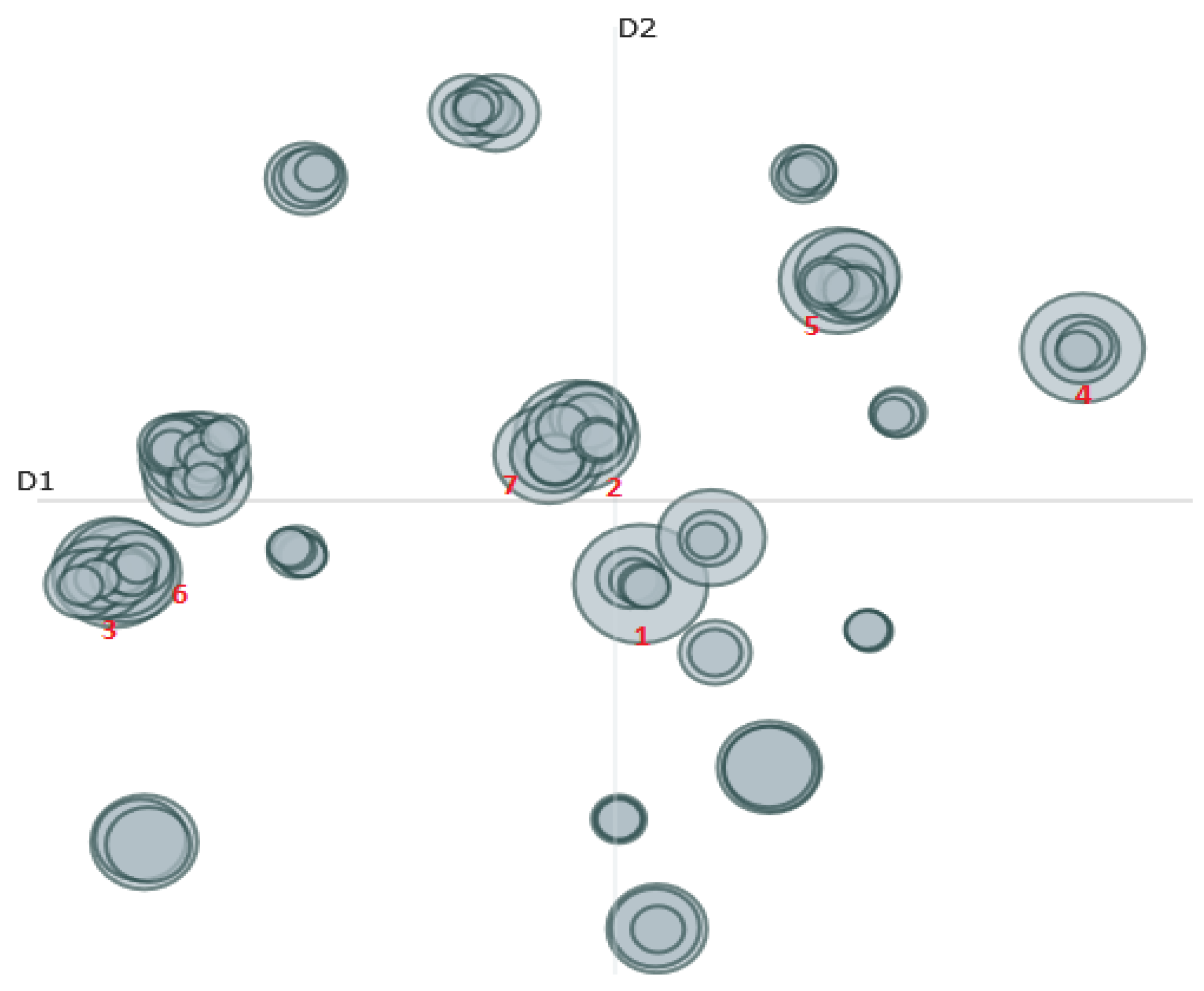
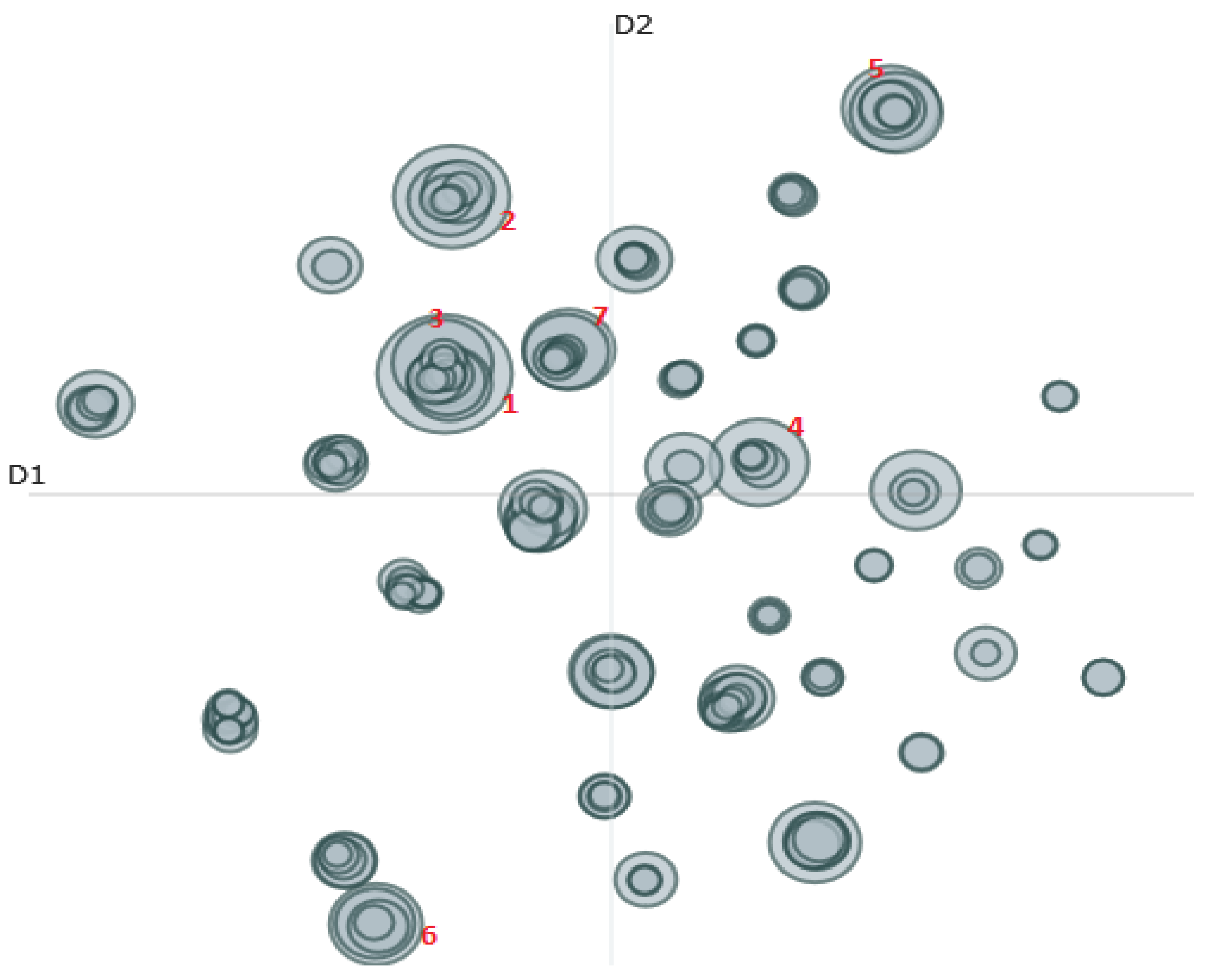
3.1. Manifesto Similarities
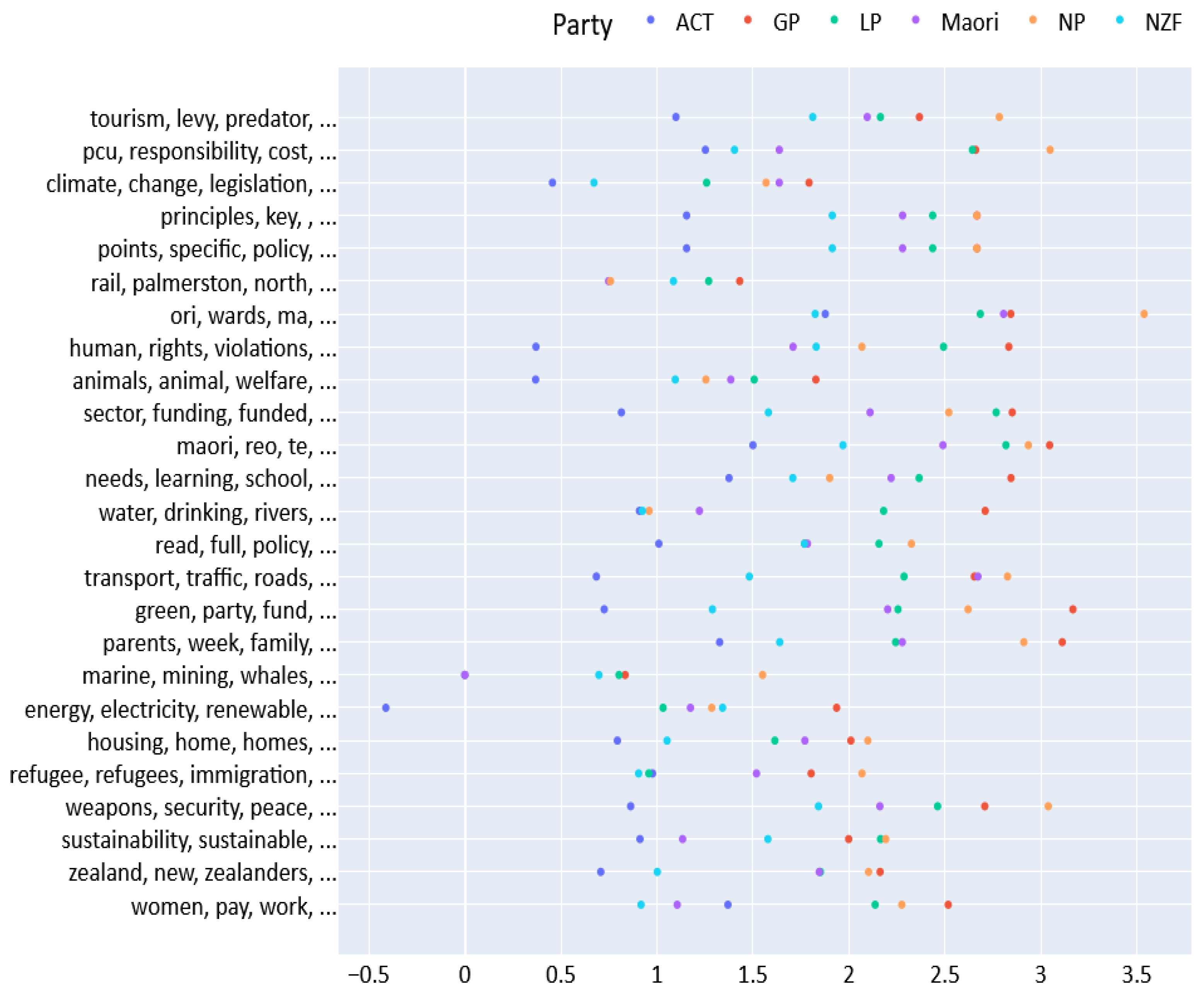
3.2. Topic Modeling of Manifestos
3.3. Sentiment Analysis of Manifesto Sentences
- Use topic modeling to find the topics;
- Use the key words making up the topic to find every sentence in a party’s manifesto that mentions that topic;
- Apply the VADER algorithm to each of those sentences to estimate the sentiment of that sentence;
- Create a party’s total sentiment score on that topic by calculating the average polarity score across all the sentences in a manifesto mentioning that topic and multiplying it by the log of the number of times (sentences) a party mentions the topic in their manifesto. Multiplying by the number of times a party mentions a topic helps account for the importance a party places on that topic. Taking the log reduces the effects of sizable variations in the number of mentions. Some parties, for example, will not mention a topic at all.
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Poole, K.T.; Rosenthal, H. D-nominate after 10 years: A comparative update to congress: A political-economic history of roll-call voting. Legis. Stud. Q. 2001, 5–29. [Google Scholar] [CrossRef]
- Hayward, J.; Rudd, C. Metropolitan newspapers and the election. In Left Turn: The New Zealand General Election of 1999; Te Herenga Waka University Press: Wellington, New Zealand, 1999; pp. 89–104. [Google Scholar]
- Volkens, A.; Bara, J.; Budge, I.; McDonald, M.D.; Klingemann, H.D. Mapping Policy Preferences from Texts: Statistical Solutions for Manifesto Analysts; OUP Oxford: Oxford, UK, 2013; Volume 3. [Google Scholar]
- Weber, R.P. Basic Content Analysis; Sage: Thousand Oaks, CA, USA, 1990; Volume 49. [Google Scholar]
- Neuendorf, K.A. The Content Analysis Guidebook; Sage: Thousand Oaks, CA, USA, 2017. [Google Scholar]
- Krippendorff, K. Content Analysis: An Introduction to Its Methodology; Sage: Thousand Oaks, CA, USA, 2018. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing: An Introduction to Speech Recognition, Computational Linguistics and Natural Language Processing; Prentice Hall: Upper Saddle River, NJ, USA, 2008. [Google Scholar]
- Manning, C.D.; Schütze, H. Foundations of Statistical Natural Language Processing (Ch. IV); MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Parthasarathy, R.; Rao, V.; Palaniswamy, N. Deliberative democracy in an unequal world: A text-as-data study of south India’s village assemblies. Am. Political Sci. Rev. 2019, 113, 623–640. [Google Scholar] [CrossRef]
- Chang, C.; Masterson, M. Using word order in political text classification with long short-term memory models. Political Anal. 2020, 28, 395–411. [Google Scholar] [CrossRef]
- Soroka, S.; Young, L.; Balmas, M. Bad news or mad news? Sentiment scoring of negativity, fear, and anger in news content. Ann. Am. Acad. Political Soc. Sci. 2015, 659, 108–121. [Google Scholar] [CrossRef]
- Iyyer, M.; Enns, P.; Boyd-Graber, J.; Resnik, P. Political ideology detection using recursive neural networks. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 23–24 June 2014; Volume 1, pp. 1113–1122. [Google Scholar]
- Baly, R.; Martino, G.D.S.; Glass, J.; Nakov, P. We can detect your bias: Predicting the political ideology of news articles. arXiv 2020, arXiv:2010.05338. [Google Scholar]
- Liu, Y.; Zhang, X.F.; Wegsman, D.; Beauchamp, N.; Wang, L. POLITICS: Pretraining with Same-story Article Comparison for Ideology Prediction and Stance Detection. arXiv 2022, arXiv:2205.00619. [Google Scholar]
- Yang Zen, T.H.; Hong, C.B.; Mohan, P.M.; Balachandran, V. ABC-Verify: AI-Blockchain Integrated Framework for Tweet Misinformation Detection. In Proceedings of the 2021 IEEE International Conference on Service Operations and Logistics, and Informatics (SOLI), Singapore, 11–12 December 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Pavlov, T.; Mirceva, G. COVID-19 Fake News Detection by Using BERT and RoBERTa models. In Proceedings of the 2022 45th Jubilee International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 23–27 May 2022; pp. 312–316. [Google Scholar] [CrossRef]
- Volkens, A. Manifesto Coding lnstructions, 1st ed.; Wissenschaftszentrum Berlin für Sozialforschung (WZB): Berlin, Germany, 2001. [Google Scholar]
- Laver, M.; Benoit, K.; Garry, J. Extracting policy positions from political texts using words as data. Am. Political Sci. Rev. 2003, 97, 311–331. [Google Scholar] [CrossRef] [Green Version]
- Johnston, R.J.; Pattie, C.J. Campaigning and split-ticket voting in new electoral systems: The first MMP elections in New Zealand, Scotland and Wales. Elect. Stud. 2002, 21, 583. [Google Scholar] [CrossRef]
- Vowles, J. The Politics of Electoral Reform in New Zealand. Int. Political Sci. Rev. 1995, 16, 95–115. [Google Scholar] [CrossRef]
- Lijphart, A. Patterns of Democracy: Government Forms and Performance in Thirty-Six Countries; Yale University Press: New Haven, CT, USA, 1999. [Google Scholar]
- Katz, R.S. Democracy and Elections; Oxford University Press: Oxford, UK, 1997; pp. 150–160. [Google Scholar]
- Volkens, A.; Burst, T.; Krause, W.; Lehmann, P.; Matthieß, T.; Merz, N.; Weßels, B.; Zehnter, L. The Manifesto Data Collection. Manifesto Project (MRG/CMP/MARPOR); Wissenschaftszentrum Berlin für Sozialforschung (WZB): Berlin, Germany, 2021. [Google Scholar]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Yih, W.T.; Zweig, G. Linguistic regularities in continuous space word representations. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 746–751. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Campbell, D.; Stanley, J. Experimental and Quasi-Experimental Designs for Research; Houghton Mifflin Company: Boston, MA, USA, 1963. [Google Scholar]
- Grootendorst, M. BERTopic: Leveraging BERT and c-TF-IDF to create easily interpretable topics. Zenodo 2020. [Google Scholar] [CrossRef]
- Hutto, C.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8, pp. 216–225. [Google Scholar]
- Cave, D. With Progressive Politics on March in New Zealand, Maori Minister Blazes New Trails. The New York Times, 16 November 2020. [Google Scholar]
- Rodgers, R.P. The Connection of Māori to Whales. Available online: https://ir.canterbury.ac.nz/bitstream/handle/10092/14087/The%20Connection%20of%20M%C3%84%20ori%20to%20Whales.pdf?sequence=1 (accessed on 19 January 2023).




{kind=link}
{kind=link}
{kind=link}
| LP 1987 | LP 1990 | LP 1993 | LP 1996 | LP 1999 | LP 2002 |
|---|---|---|---|---|---|
| NP 1987 | NP 1987 | NP 1987 | DP 1987 | NP 1993 | NP 1990 |
| DP 1987 | DP 1987 | LP 1987 | NP 1987 | ACT 1999 | NZF 1999 |
| NP 1990 | NP 1990 | NZF 1996 | NP 1987 | NZF 1996 | |
| LP 1987 | All 1993 | LP 1993 | NP 1999 | NP 2002 | |
| DP 1990 | NP 1993 | NP 1990 | NP 1996 | LP 1993 | |
| DP 1987 | LP 1987 | LP 1993 | All 1999 | ||
| LP 1990 | ACT 1996 | All 1993 | All 1996 | ||
| DP 1990 | NP 1996 | DP 1987 | NP 1996 | ||
| NP 1993 | NZF 1999 | Prog 2002 | |||
| All 1996 | LP 1990 | NZF 2002 | |||
| LP 1990 | All 1999 | LP 1987 | |||
| LP 2005 | LP 2008 | LP 2011 | LP 2014 | LP 2017 | |
| Prog 2002 | NP 2005 | Prog 2002 | LP 1993 | Prog 2002 | |
| NP 1996 | Prog 2005 | ACT 2002 | ACT 2008 | ACT 2002 | |
| All 1999 | NZF 2002 | LP 1987 | GP 2014 | NP 1987 | |
| LP 1999 | LP 1993 | ACT 1999 | NP 1990 | LP 1999 | |
| NP 1993 | NP 1990 | NP 2005 | UF 2014 | NP 1999 | |
| NP 1999 | NZF 1999 | NZF 1999 | ACT 2002 | NP 2008 | |
| ACT 1999 | LP 1987 | DP 1990 | Prog 2002 | ACT 1999 | |
| UF 2002 | ACT 2002 | All 1999 | LP 2005 | NZF 2014 | |
| LP 1993 | Prog 2002 | ACT 2008 | UF 2002 | Prog 2005 | |
| Maori 2005 | ACT 2008 | NZF 2011 | NP 2011 | NP 2011 | |
| Prog 2005 | ACT 1996 | UF 2002 | NP 2002 | GP 2011 | |
| NP 1987 | NP 1990 | NP 1993 | NP 1996 | NP 1999 | NP 2002 |
|---|---|---|---|---|---|
| DP 1987 | NP 1987 | NP 1987 | NP 1993 | NP 1996 | LP 1993 |
| LP 1987 | LP 1987 | LP 1993 | NP 1990 | NP 1993 | All 1993 |
| DP 1987 | LP 1987 | NP 1987 | All 1999 | NZF 2002 | |
| LP 1990 | All 1993 | NZF 1996 | LP 1999 | All 1999 | |
| DP 1990 | DP 1987 | All 1993 | ACT 1999 | LP 2002 | |
| LP 1990 | LP 1987 | NP 1987 | NP 1999 | ||
| NP 1990 | LP 1993 | All 1993 | NP 1990 | ||
| DP 1990 | ACT 1996 | LP 1987 | Prog 2002 | ||
| DP 1987 | LP 1993 | ACT 1996 | |||
| LP 1990 | DP 1987 | LP 1987 | |||
| LP 1996 | NP 1990 | NZF 1999 | |||
| NP 2005 | NP 2008 | NP 2011 | NP 2014 | NP 2017 | |
| Prog 2005 | NP 1999 | ACT 2008 | LP 1999 | ACT 2008 | |
| LP 1993 | NP 1993 | Prog 2005 | Maori 2008 | NP 2011 | |
| NP 1987 | Prog 2002 | NP 1987 | NP 2011 | NZF 1999 | |
| Prog 2002 | NP 1987 | ACT 2002 | NP 1993 | Prog 2005 | |
| NZF 1999 | Prog 2005 | LP 2002 | NP 1996 | LP 1993 | |
| LP 1987 | LP 1999 | Prog 2002 | ACT 2014 | NP 1987 | |
| NZF 2002 | ACT 2002 | ACT 1999 | Prog 2005 | LP 2008 | |
| ACT 2002 | LP 1993 | LP 1993 | NP 1987 | NP 2005 | |
| NP 1990 | NP 1996 | NP 2005 | ACT 1999 | NZF 2011 | |
| ACT 1996 | LP 1987 | LP 1999 | NP 1999 | Prog 2002 | |
| NP 1999 | ACT 1999 | UF 2008 | NP 2005 | NP 1996 | |
| Top 10 Words | Importance Value |
|---|---|
| transport | 0.047 |
| cycling | 0.039 |
| walking | 0.035 |
| rail | 0.027 |
| safe | 0.023 |
| buses | 0.021 |
| cycle | 0.021 |
| wellington | 0.020 |
| congestion | 0.020 |
| roads | 0.019 |
| Party | Text | Polarity Vader |
|---|---|---|
| GP | Support locating clusters near transport hubs (rail lines, ports, etc.) | 0.4019 |
| GP | Expand the nationwide network of cycle/pedestrian trails. | 0.3182 |
| GP | Promote rail as a great way to travel and seek to make it more available and reliable. | 0.7717 |
| GP | All goods and services produced or sold in New Zealand to meet quality and sustainability standards (e.g., energy and recycling standards). | 0.2732 |
| GP | Fast, electric rail lines eliminate pollution and create healthier, congestion-free cities. | 0.2732 |
| GP | Safe walking and cycling for kids. | 0.4404 |
| GP | Allocate NZD 50m a year for four years to build modern, convenient walking and cycling infrastructure around schools: separating kids and other users from road traffic, providing a safe choice for families. | 0.6486 |
| GP | Get half of kids walking or cycling to school by 2022: reducing congestion; improving health and learning; saving families time and money. | 0.4215 |
| GP | Better funding will enable more frequent buses on existing routes. | 0.4404 |
| Party | Number of Sentences | Avg Polarity Vader | Weighted Polarity |
|---|---|---|---|
| ACT | 14 | 0.151 | 0.574 |
| GP | 174 | 0.352 | 2.622 |
| LP | 54 | 0.338 | 1.943 |
| Maori | 14 | 0.556 | 2.118 |
| NP | 129 | 0.368 | 2.581 |
| NZF | 30 | 0.225 | 1.102 |
| NLP Technique | The Good | The Bad |
|---|---|---|
| Document Similarity |
|
|
| Topic Modeling |
|
|
| Sentiment Analysis |
|
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Orellana, S.; Bisgin, H. Using Natural Language Processing to Analyze Political Party Manifestos from New Zealand. Information 2023, 14, 152. https://doi.org/10.3390/info14030152
Orellana S, Bisgin H. Using Natural Language Processing to Analyze Political Party Manifestos from New Zealand. Information. 2023; 14(3):152. https://doi.org/10.3390/info14030152
Chicago/Turabian StyleOrellana, Salomon, and Halil Bisgin. 2023. "Using Natural Language Processing to Analyze Political Party Manifestos from New Zealand" Information 14, no. 3: 152. https://doi.org/10.3390/info14030152
APA StyleOrellana, S., & Bisgin, H. (2023). Using Natural Language Processing to Analyze Political Party Manifestos from New Zealand. Information, 14(3), 152. https://doi.org/10.3390/info14030152