

Prediction Machine Learning Models on Propensity Convicts to Criminal Recidivism

 , ,
, ,  and
and
Abstract
:1. Introduction
2. Related Work
3. Background
4. Materials and Methods
- Recidivism (binominal): 1—yes; 2—no;
- Sex (binominal): 1—male, 2—female;
- Age (nominal): 1—to 18 years old, 2—18 to 30 years old, 3—30 to 45 years old; 4—over 45 years old;
- Age1: (age at the time of the first conviction (to the actual degree of punishment), integer): 1—to 18 years old, 2—18 to 30 years old, 3—30 to 45 years old; 4—over 45 years old;
- Age2: (age at the time of the first conviction (suspended or actual sentence), integer): 1—to 18 years old, 2—18 to 30 years old, 3—30 to 45 years old; 4—over 45 years old;
- Marital status (binominal): 1—single, 2—married;
- Education (nominal): 0—incomplete secondary, 1—secondary, 2—special secondary, 3—incomplete higher, 4—higher;
- Place of residence (place of residence to the actual degree of punishment, nominal): 1—rural area, 2—urban area;
- Type of employment (type of employment at the time of conviction (up to actual punishment), nominal): 0—unemployed, 1—part-time, 2—full-time;
- Early dismissals (availability of early dismissals, binominal): 0—no, 1—yes;
- Motivation for dismissal (binominal): 0—no,1—yes;
- Real convictions (number);
- Suspended convictions (number).
- Generalized Linear Model: generalization of linear regression models;
- Deep Learning: multi-level neural network for learning non-linear relationships;
- Decision Tree: finds simple tree-like models which are easy to clarify;
- Random Forest: an ensemble of multiple randomized trees;
- Gradient Boosted Trees: powerful but complex model using ensembles of Decision Trees;
- Support Vector Machine: powerful but relatively fast model, especially for non-linear relationships.
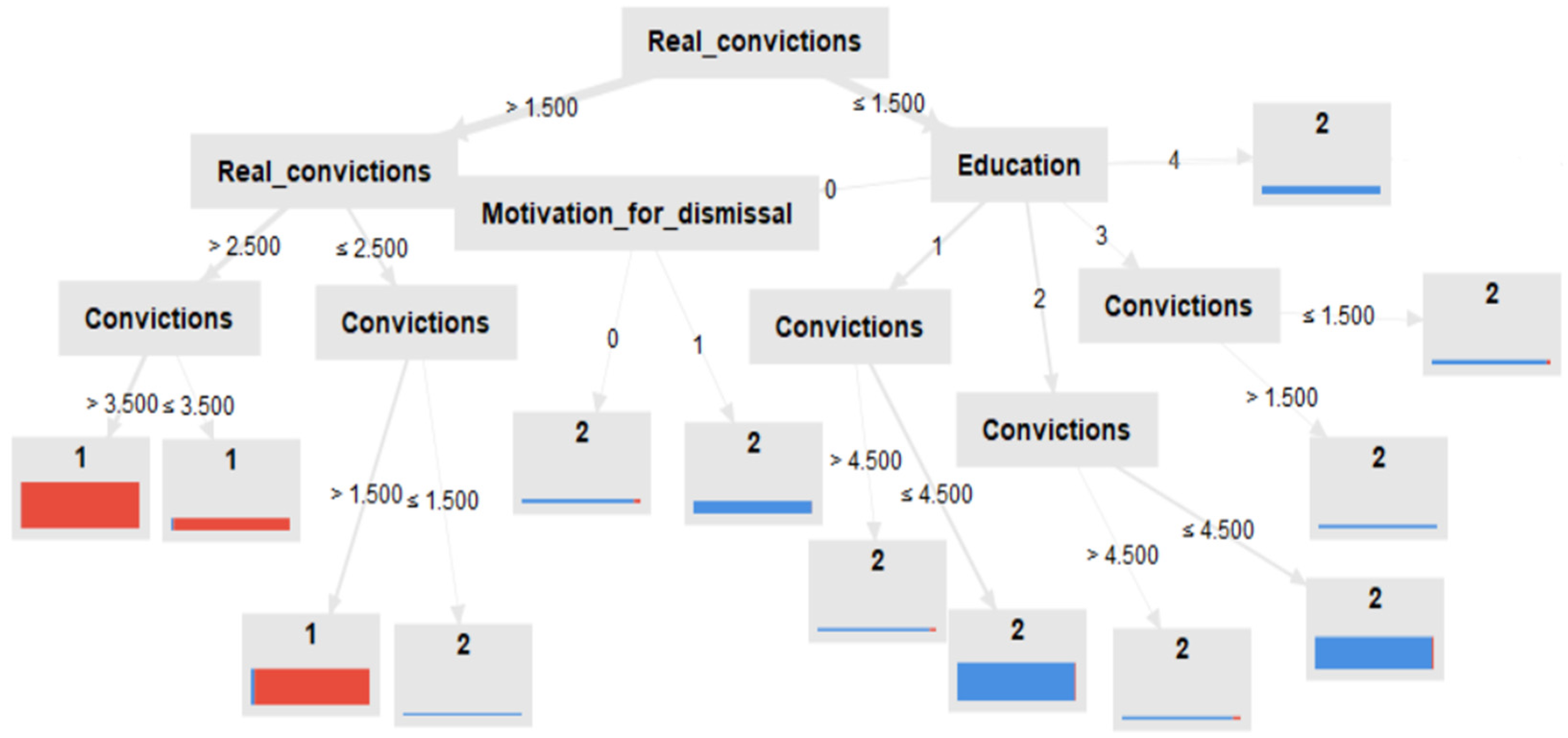
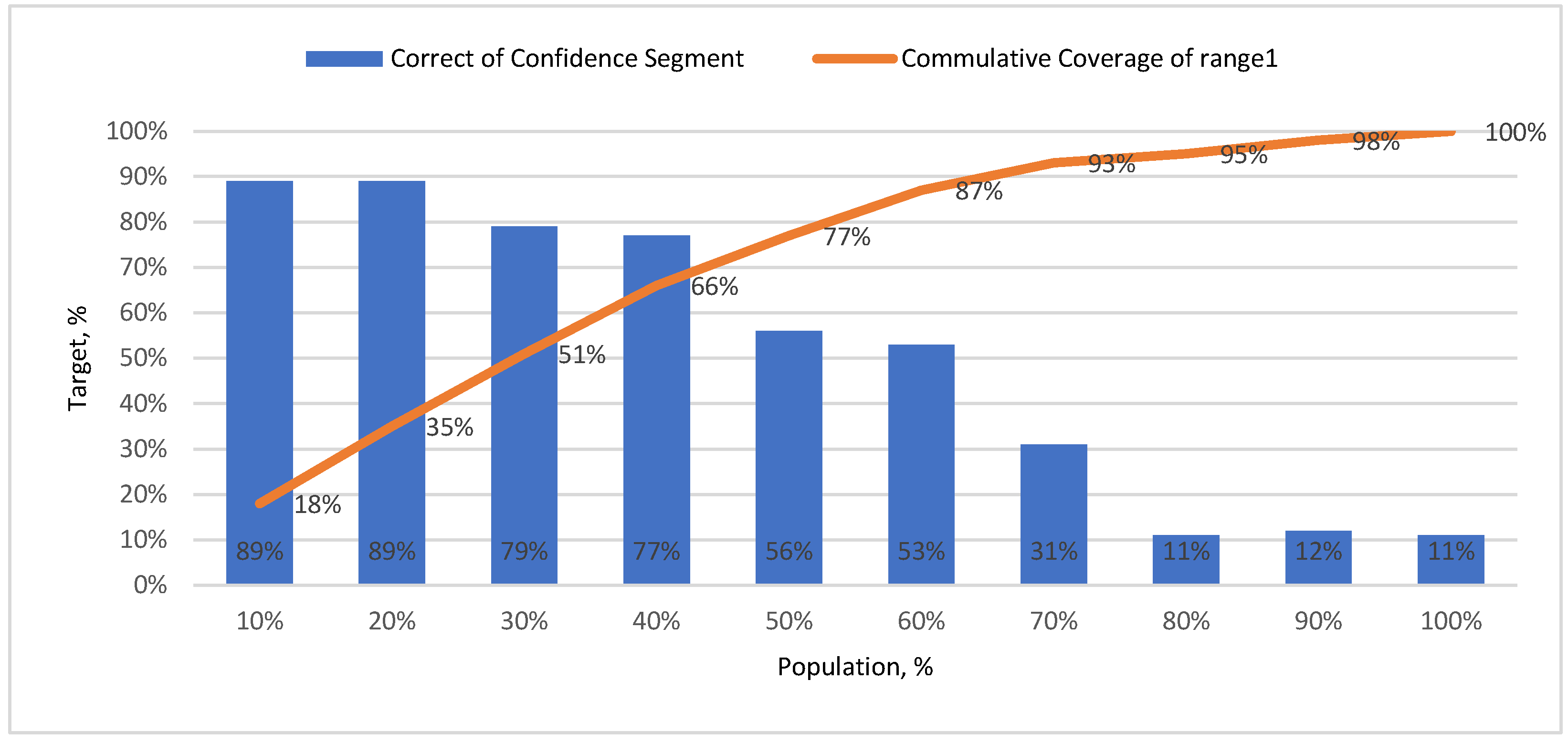
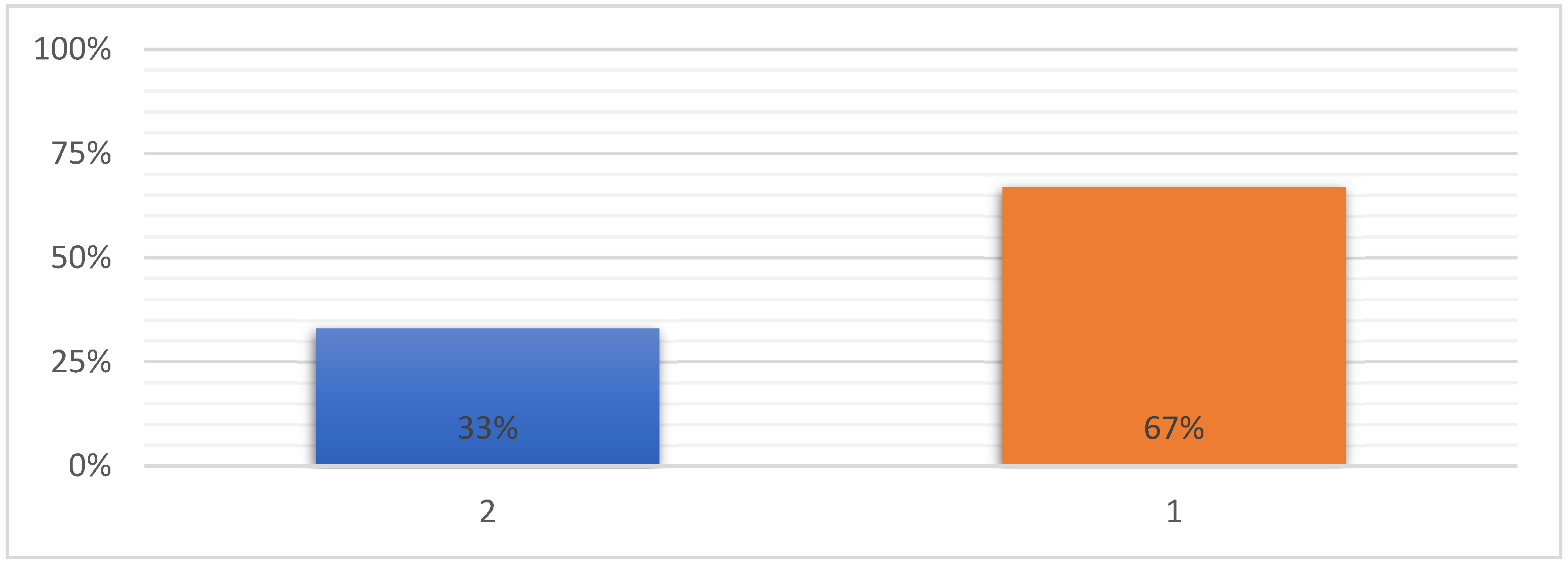
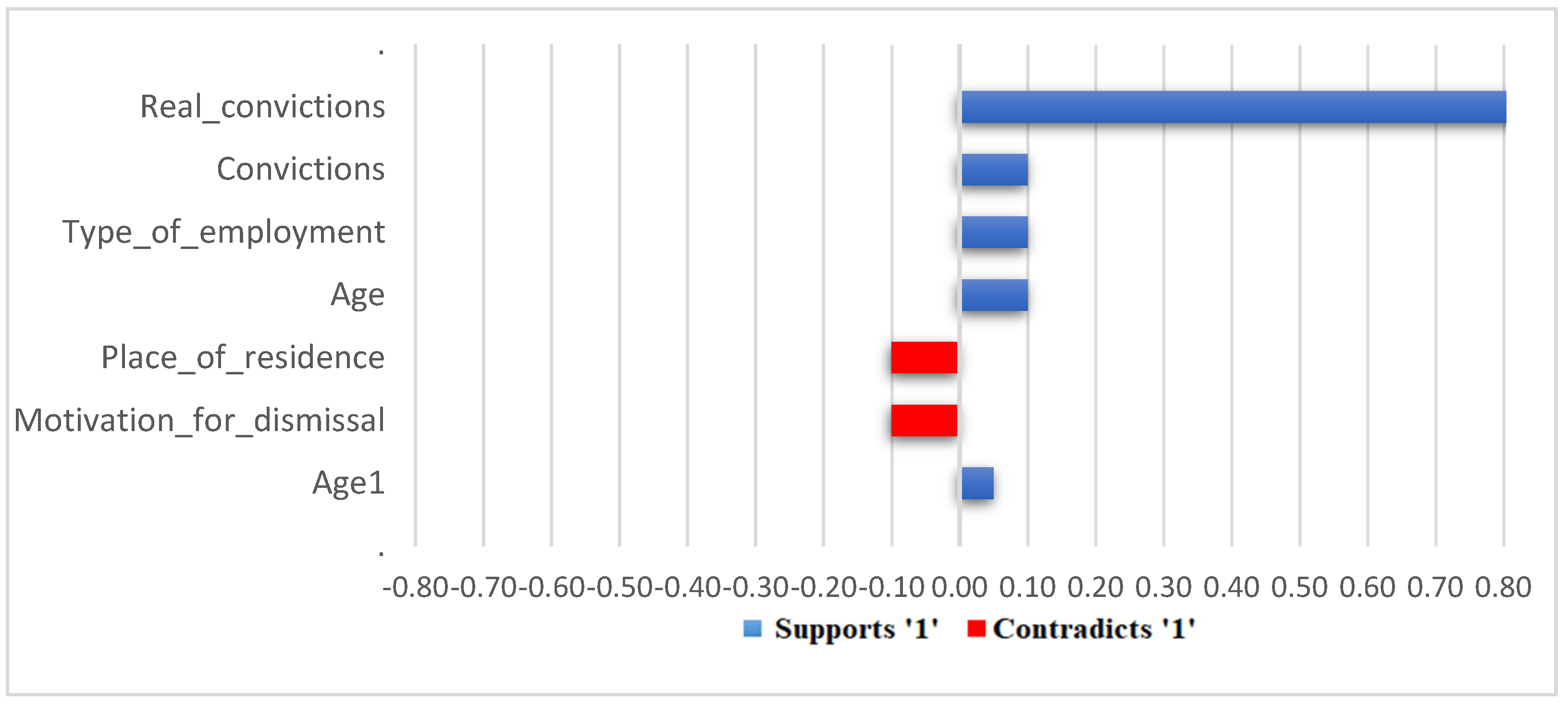
5. Results
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hutt, O.; Bowers, K.; Johnson, S.; Davies, T. Data and evidence challenges facing placebased policing. Polic. Int. J. 2018, 41, 339–351. [Google Scholar] [CrossRef] [Green Version]
- Jabeen, N.; Agarwal, P. Data Mining in Crime Analysis. In Proceedings of the Second International Conference on Smart Energy and Communication, Jaipur, India, March 20–21 2020. [Google Scholar] [CrossRef]
- Ogochukwu, O.; Forster, O. An Overview of Crime Analysis, Prevention and Prediction Using Data Mining Based on Real Time and Location Data. Int. J. Eng. Appl. Sci. Technol. 2021, 5, 99–103. [Google Scholar] [CrossRef]
- Saravanan, P.; Selvaprabu, J.; Raj, L.A.; Khan, A.; Sathick, K. Survey on crime analysis and prediction using data mining and machine learning techniques. Lect. Notes Electr. Eng. 2021, 688, 435–448. [Google Scholar] [CrossRef]
- Greenstein, S. Preserving the rule of law in the era of artificial intelligence (AI). Artif. Intell. Law 2022, 30, 291–323. [Google Scholar] [CrossRef]
- Coldren, J.R.; Huntoon, A.; Medaris, M. Introducing Smart Policing: Foundations, Principles, and Practice. Police Q. 2013, 16, 275–286. Available online: https://journals.sagepub.com (accessed on 8 December 2022).
- Walter, L.P.; McInnis, B.; Price, C.C.; Smith, S.; Hollywood, J.S. Predictive Policing: The Role of Crime Forecasting in Law Enforcement Operations. RAND Corporation 2013. Available online: https://www.rand.org/pubs/research_reports/RR233.html (accessed on 8 December 2022).
- Sandhu, A.; Fussey, P. The ‘uberization of policing’? How police negotiate and operationalize predictive policing technology. Polic. Soc. 2020, 31, 66–81. [Google Scholar] [CrossRef]
- Dervis, H. Bibliometric analysis using bibliometrix an R package. J. Scientometr. Res. 2019, 8, 156–160. [Google Scholar] [CrossRef]
- Wyner, A.; Mochales-Palau, R.; Moens, M.-F.; Milward, D. Approaches to Text Mining Arguments from Legal Cases. In Proceedings of the Conference “Semantic Processing of Legal Texts”, Valletta, Malta, 23 May 2010. [Google Scholar] [CrossRef]
- Kovalchuk, O.; Banakh, S.; Masonkova, M.; Berezka, K.; Mokhun, S.; Fedchyshyn. Text Mining for the Analysis of Legal Texts. In Proceedings of the 12th International Conference “Advanced Computer Information Technologies”, Spišská Kapitula, Slovakia, 26–28 September 2022. [Google Scholar] [CrossRef]
- Zhdanov, D.; Bhattacharjee, S.; Bragin, M.A. Incorporating FAT and privacy aware AI modeling approaches into business decision making frameworks. Decis. Support Syst. 2022, 155. (accessed on 2 November 2022). [Google Scholar] [CrossRef]
- Blockchain Facts: What Is It, How It Works, and How It Can Be Used. Investopedia. Available online: https://www.investopedia.com/terms/b/blockchain.asp (accessed on 2 December 2022).
- Kovalchuk, O.; Masonkova, M.; Banakh, S. The Dark Web Worldwide 2020: Anonymous vs Safety. In Proceedings of the 11th International Conference “Advanced Computer Information Technologies”, Deggendorf, Germany, 15–17 September 2021. [Google Scholar] [CrossRef]
- Fazel, S.; Wolf, A. A Systematic Review of Criminal Recidivism Rates Worldwide: Current Difficulties and Recommendations for Best Practice. PLoS ONE 2015, 10, e0130390. [Google Scholar] [CrossRef] [Green Version]
- Basilio, M.P.; Brum, G.S.; Pereira, V. A model of policing strategy choice: The integration of the Latent Dirichlet Allocation (LDA) method with ELECTRE I. J. Model. Manag. 2020, 15, 849–891. [Google Scholar] [CrossRef]
- Basilio, M.P.; Pereira, V. Operational research applied in the field of public security: The ordering of policing strategies such as the ELECTRE IV. J. Model. Manag. 2020, 15, 1227–1276. [Google Scholar] [CrossRef]
- Basilio, M.P.; Pereira, V.; Oliveira, M.W.C.D.; Costa Neto, A.F. Ranking policing strategies as a function of criminal complaints: Application of the PROMETHEE II method in the brazilian context. J. Model. Manag. 2020, 5, 549–562. [Google Scholar] [CrossRef]
- Hendrix, J.A.; Taniguchi, T.; Strom, K.J.; Aagaard, B.J.N. Strategic policing philosophy and the acquisition of technology: Findings from a nationally representative survey of law enforcement. Polic. Soc. 2019, 29, 727–743. [Google Scholar] [CrossRef]
- Mucchielli, L. The evolution of municipal police forces in France: An imitation of state police doomed to failure? Deviance Et Soc. 2017, 41, 239–271. [Google Scholar] [CrossRef]
- Basilio, M.P.; Pereira, V.; Oliveira, M.W.C.M.D. Knowledge discovery in research on policing strategies: An overview of the past fifty years. J. Model. Manag. 2021, 17, 1372–1409. [Google Scholar] [CrossRef]
- Dakalbab, F.; Talib, M.; Waraga, O.; Nassif, A.; Abbas, S.; Nasir, Q. Artificial intelligence & crime prediction: A systematic literature review. Soc. Sci. Humanit. Open 2022, 6, 100342. [Google Scholar] [CrossRef]
- Sangani, A.; Sampat, C.; Pinjarkar, V. Crime Prediction and Analysis. In Proceedings of the 2nd International Conference on Advances in Science & Technology (ICAST) 2019, Mumbai, India, 8–9 April 2019. [Google Scholar] [CrossRef]
- Meijer, A.; Wessels, M. Predictive policing: Review of benefits and drawbacks. Int. J. Public Adm. 2019, 42, 1031–1039. [Google Scholar] [CrossRef] [Green Version]
- Leigh, J.; Dunnett, S.; Jackson, L. Predictive police patrolling to target hotspots and cover response demand. Ann. Oper. Res. 2019, 283, 395–410. [Google Scholar] [CrossRef] [Green Version]
- Egbert, S. Predictive policing and the platformization of police work. Surveill. Soc. 2019, 17, 83–88. [Google Scholar] [CrossRef]
- Andresen, M.A.; Hodgkinson, T.K. Evaluating the impact of police foot patrol at the microgeographic level. Polic. Int. J. 2018, 41, 314–324. [Google Scholar] [CrossRef]
- Andresen, M.A.; Shen, J.L. The spatial effect of police foot patrol on crime patterns: A local analysis. Int. J. Offender Ther. Comp. Criminol. 2019, 63, 1446–1464. [Google Scholar] [CrossRef]
- Yu, R.; Långström, N.; Forsman, M.; Sjölander, A.; Fazel, S.; Molero, Y. Associations between prisons and recidivism: A nationwide longitudinal study. National Center for Biotechnology Information. PLoS ONE 2022, 17, e0267941. [Google Scholar] [CrossRef]
- Berezka, K.; Kovalchuk, O.; Banakh, S.; Zlyvko, S.; Hrechaniuk, R. A Binary Logistic Regression Model for Support Decision Making in Criminal Justice. Folia Oeconomica Stetin. 2022, 22, 1–17. [Google Scholar] [CrossRef]
- Kovalchuk, O.; Banakh, S.; Masonkova, M.; Burdin, V.; Zaverukha, O.; Ivanytskyy, R. A Scoring Model for Support Decision Making in Criminal Justice. In Proceedings of the 12th International Conference “Advanced Computer Information Technologies”, Spišská Kapitula, Slovakia, 26–28 September 2022. [Google Scholar] [CrossRef]
- Edberg, H.; Chen, Q.; Andiné, P.; Larsson, H.; Hirvikoski, T. Criminal recidivism in offenders with and without intellectual disability sentenced to forensic psychiatric care in Sweden—A 17-year follow-up study. Forensic Psychiatry 2022, 13. [Google Scholar] [CrossRef]
- Zgoba, K.; Reeves, R.; Tamburello, A.C.; Debilio, L. Criminal Recidivism in Inmates with Mental Illness and Substance Use Disorders. J. Am. Acad. Psychiatry Law 2020, 48, 209–215. [Google Scholar] [CrossRef]
- Karlsson, A.; Håkansson, A. Crime-Specific Recidivism in Criminal Justice Clients with Substance Use—A Cohort Study. Int. J. Environ. Res. Public Health 2022, 19, 7623. [Google Scholar] [CrossRef]
- Jacobs, L.A.; Fixler, A.; Labrum, T.; Givens, A.; Newhill, C. Ashley Givens, and Christina Newhill. Risk Factors for Criminal Recidivism Among Persons With Serious Psychiatric Diagnoses: Disentangling What Matters for Whom. Front. Psychiatry 2021, 12, 778399. [Google Scholar] [CrossRef] [PubMed]
- Yukhnenko, D.; Sridhar, S.; Fazel, S. A systematic review of criminal recidivism rates worldwide: 3-year update. PubMed Cent. 2019, 4, 28. [Google Scholar] [CrossRef]
- Shapiro, A. Predictive policing for reform? Indeterminacy and intervention in big data policing. Surveill. Soc. 2019, 17, 456–472. [Google Scholar] [CrossRef]
- Inamdar, Z.; Raut, R.; Narwane, V.S.; Gardas, B.; Narkhede, B.; Sagnak, M. A systematic literature review with bibliometric analysis of big data analytics adoption from period 2014 to 2018. J. Enterp. Inf. Manag. 2020, 34, 101–139. [Google Scholar] [CrossRef]
- Chen, P.; Kurland, J.; Shi, S.C. Predicting repeat offenders with machine learning: A case study of Beijing theives and burglars. In Proceedings of the 4th IEEE International Conference on Big Data Analytics (ICBDA), Suzhou, China, 15–18 March 2019. [Google Scholar] [CrossRef]
- Anderes, D.; Baumel, E.; Grier, C.; Veun, R.; Wright, S. The Use of Blockchain within Evidence Management Systems; Neithercutt, K., Ed.; Alister Inc.: New York, NY, USA, 2020; p. 21. Available online: https://f.hubspotusercontent10.net/hubfs/5260862/Ebooks%20and%20Whitepapers/Blockchain%20of%20Evidence%20FINAL%20DRAFT-3.pdf (accessed on 13 November 2022).
- Project to Prevent Criminal Use of Blockchain Technology Launched by International Consortium. Interpol. 2017. Available online: https://www.interpol.int/fr/Actualites-et-evenements/Actualites/2017/Project-to-prevent-criminal-use-of-blockchain-technology-launched-by-international-consortium (accessed on 9 January 2022).
- Kovalchuk, O. Modeling the risks of the confession process of the accused of criminal offenses based on survival concept. Sci. J. TNTU 2022, 108, 27–37. [Google Scholar]
- World Prison Brief Data. World Prison Brief. Available online: https://www.prisonstudies.org/ (accessed on 3 January 2023).
- Aebi, M.F.; Cocco, E.; Hashimoto, Y.Z. Probation and Prisons in Europe 2022: Key Findings of the SPACE Reports. Series UNILCRIM 2022/4. Council of Europe and University of Lausanne. Available online: https://wp.unil.ch/space/files/2022/06/Key-Findings_Prisons-and-Prisoners-in-Europe-2021_220615.pdf (accessed on 13 December 2022).
- Caldwell, M.; Andrews, J.T.; Tanay, T. AI-enabled future crime. Crime Sci. 2020, 9, 14. [Google Scholar] [CrossRef]
- Yıldırım, S. 15 Must-Know Machine Learning Algorithms. A Comprehensive Guide for Machine Learning. Towards Data Science. Available online: https://towardsdatascience.com/15-must-know-machine-learning-algorithms-44faf6bc758e (accessed on 21 November 2022).
- Gupta, P. Decision Trees in Machine Learning. Towards Data Science. Available online: https://towardsdatascience.com/decision-trees-in-machine-learning-641b9c4e8052 (accessed on 21 November 2022).
- RapidMiner Documentation. Available online: https://docs.rapidminer.com (accessed on 13 June 2022).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
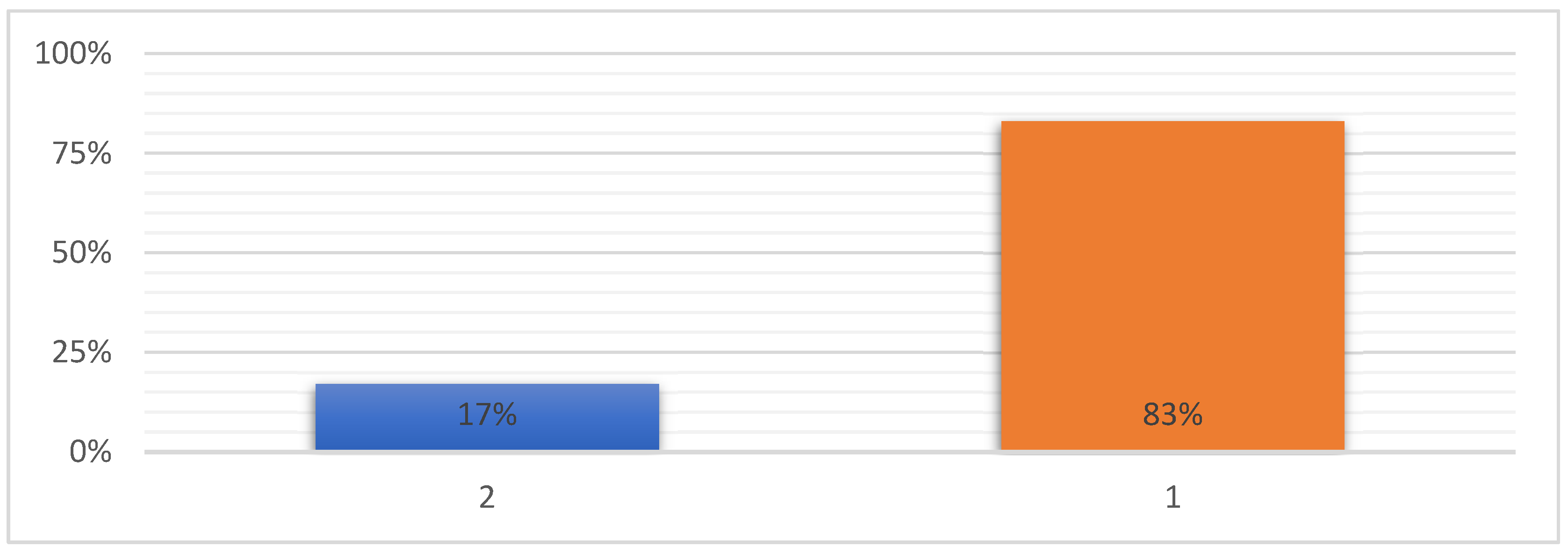{kind=link}
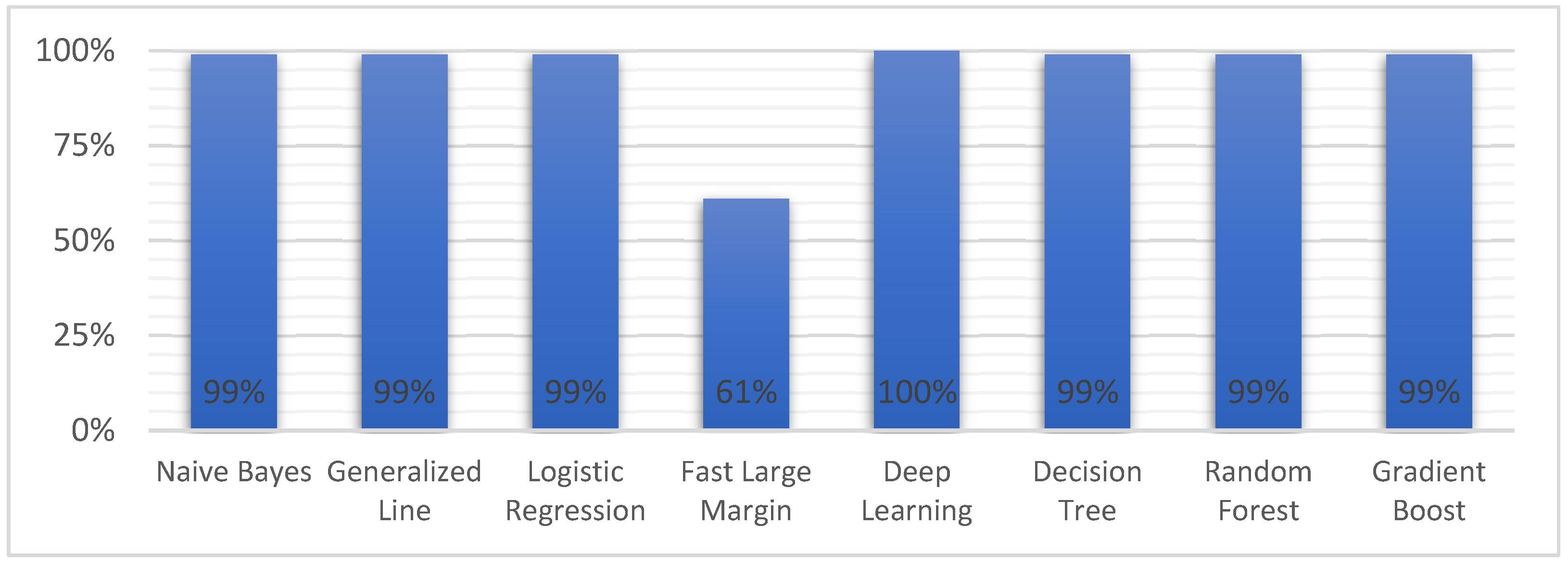
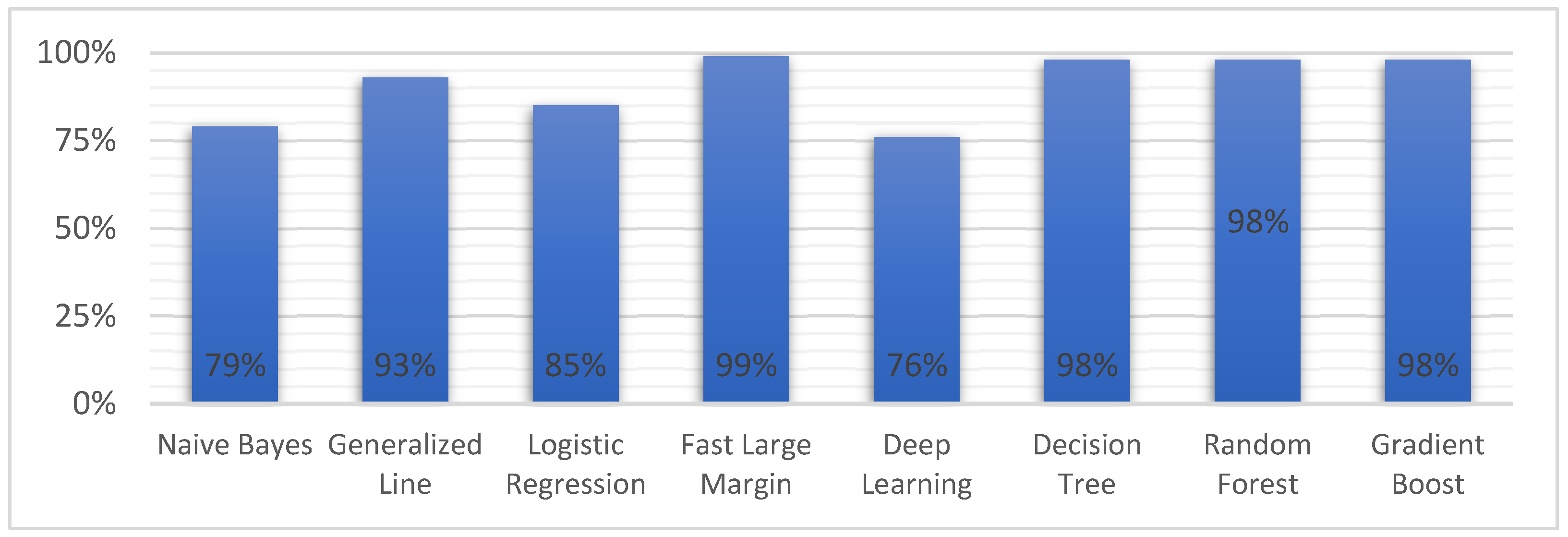
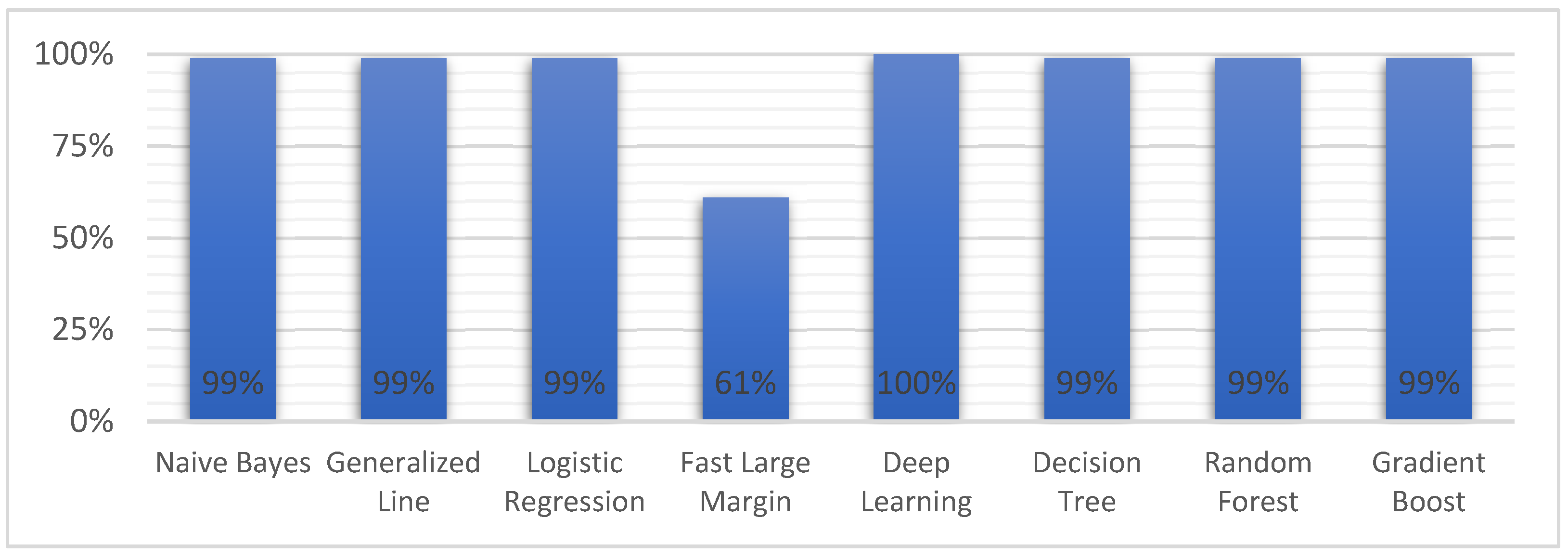
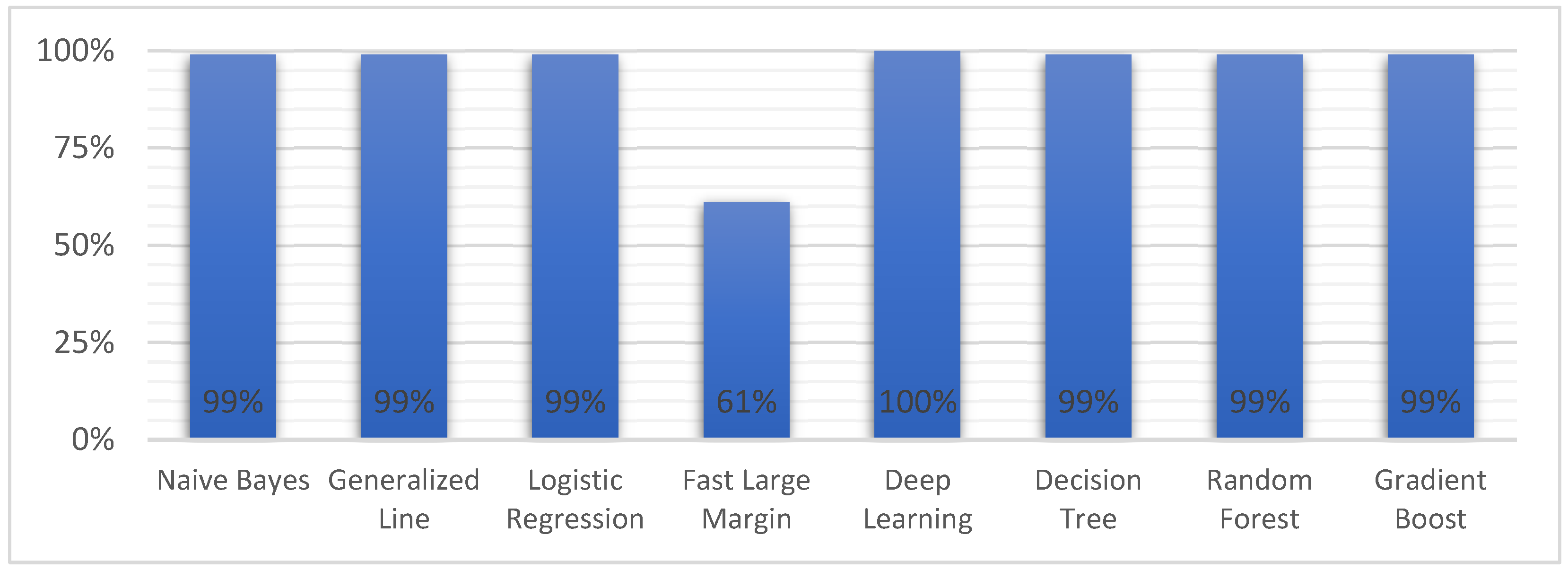
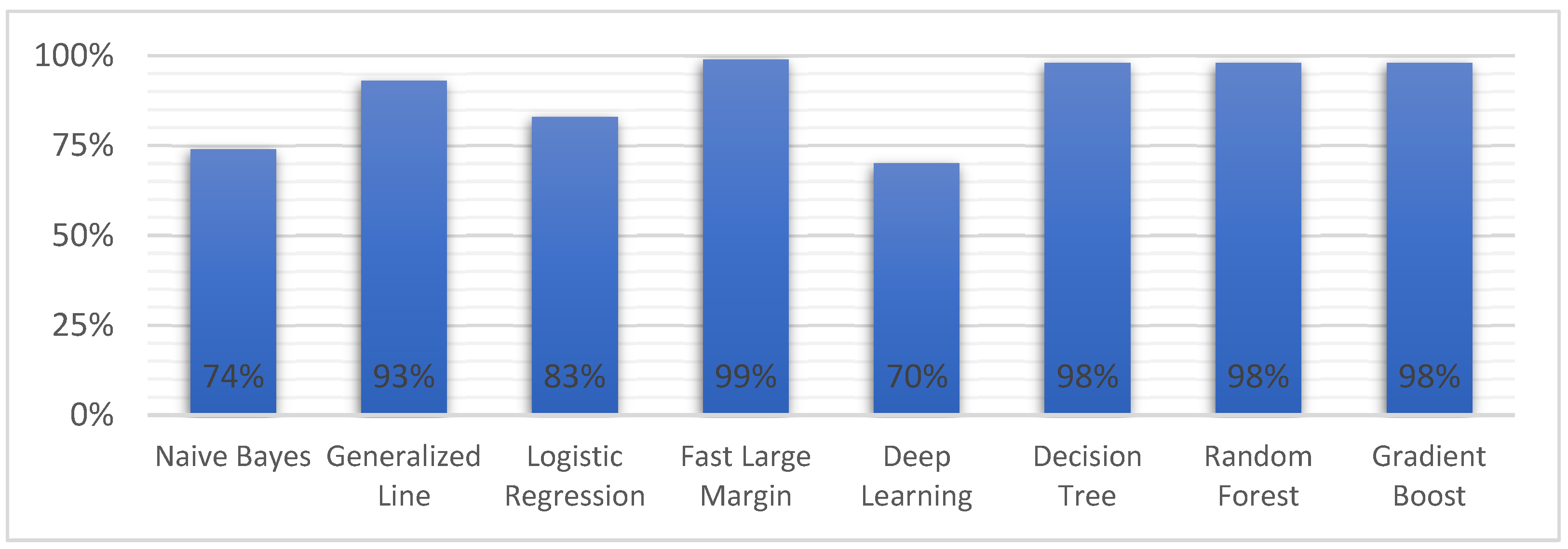
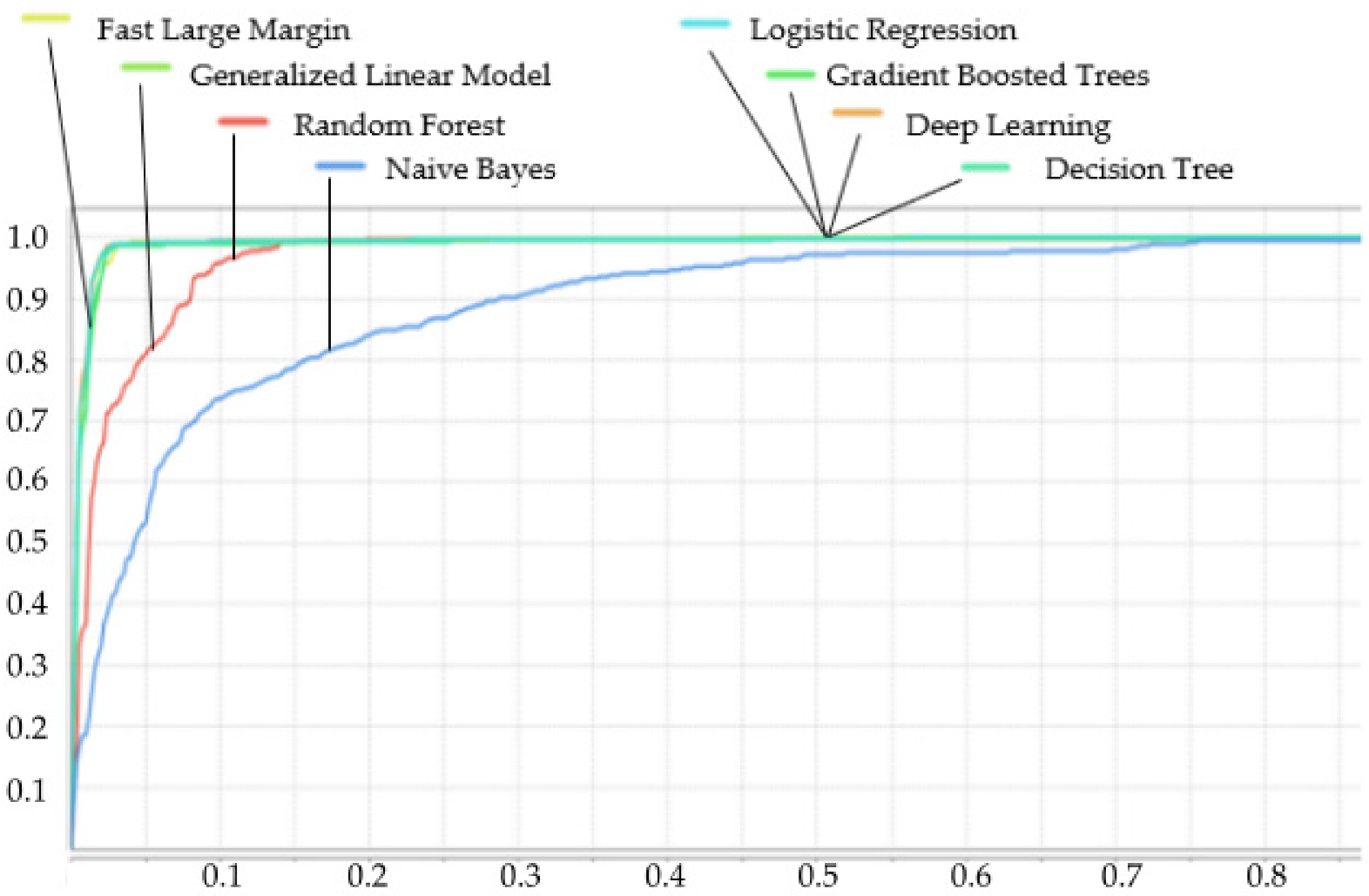
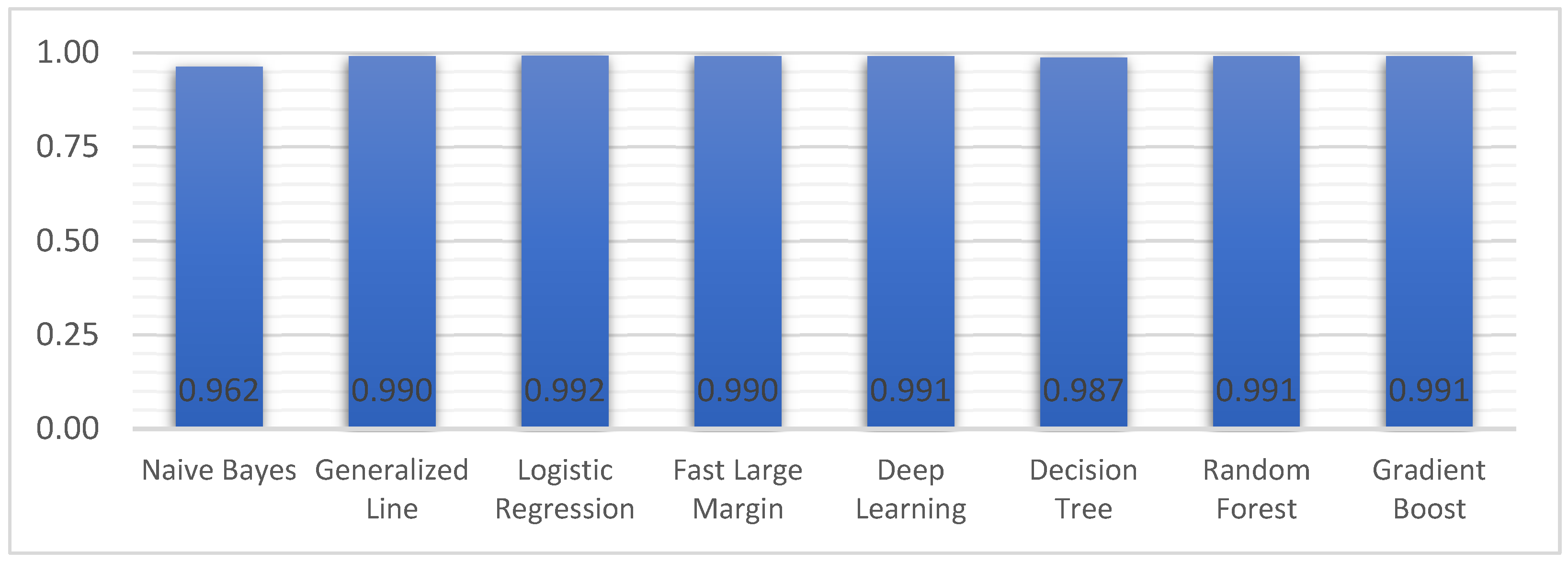
| Model | Accuracy | Precision | Recall | F Measure | Sensitivity | Specificity | AUC |
|---|---|---|---|---|---|---|---|
| Naive Bayes | 86.7% | 78.9% | 99.5% | 88.0% | 99.5% | 74.4% | 0.96 |
| Generalized Linear Model | 95.8% | 92.8% | 99.1% | 95.8% | 99.1% | 92.6% | 0.99 |
| Logistic Regression | 91.1% | 85.0% | 99.5% | 91.7% | 99.5% | 83.1% | 0.99 |
| Fast Large Margin | 80.5% | 98.7% | 61.3% | 75.6% | 61.3% | 99.2% | 0.99 |
| Deep Learning | 84.4% | 76.1% | 99.5% | 86.3% | 99.5% | 69.6% | 0.99 |
| Decision Tree | 98.3% | 97.7% | 98.8% | 98.3% | 98.8% | 97.8% | 0.99 |
| Random Forest | 98.3% | 97.7% | 98.8% | 98.3% | 98.8% | 97.8% | 0.99 |
| Gradient Boosted Trees | 98.3% | 97.7% | 98.8% | 98.3% | 98.8% | 97.8% | 0.99 |
| Title 1 | True 2 | True 1 | Class Precision |
|---|---|---|---|
| pred 2 | 1844 | 21 | 98.88% |
| pred 1 | 42 | 1808 | 97.73% |
| class recall | 97.77% | 98.85% |
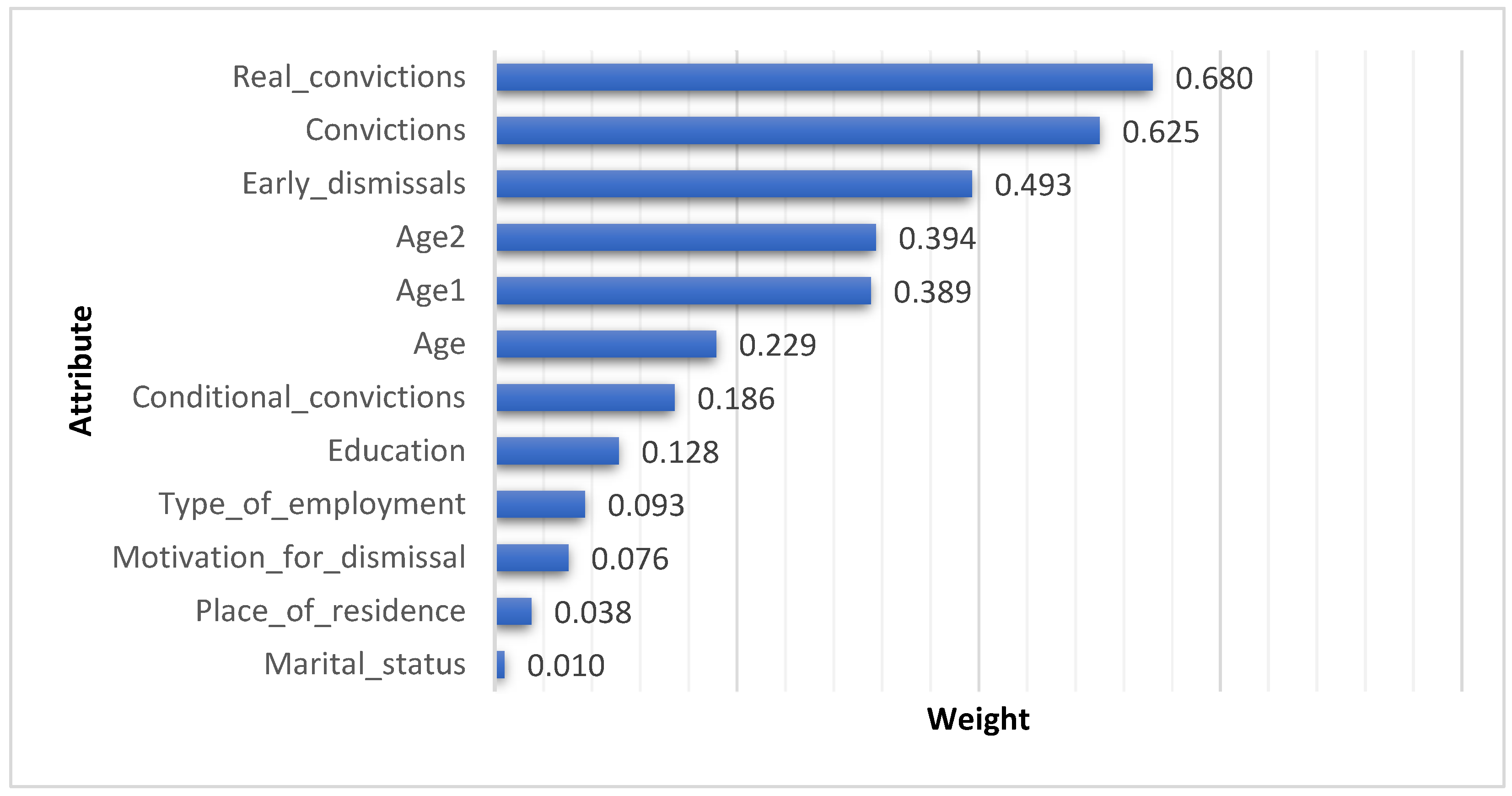
| Attributes | Age1 = 1 | Age1 = 2 | Age1 = 3 | Early_dismissals = 1 | Convictions | Real_convictions |
|---|---|---|---|---|---|---|
| Early_dissmissals = 1 | 0.133 | 0.093 | −0.154 | 1 | 0.421 | 0.42 |
| Convictions | 0.254 | 0.099 | −0.225 | 0.421 | 1 | 0.834 |
| Real_convictions | 0.291 | 0.075 | −0.236 | 0.412 | 0.834 | 1 |
| Conditional_convictions | 0.055 | 0.074 | −0.079 | 0.188 | 0.648 | 0.121 |
| Row No. | Recidivism | Prediction (Recidivism) | Age 1 | Age 2 | Number of Convictions | Early Dismission |
|---|---|---|---|---|---|---|
| 2970 | 1 | 0.904 | 1 | 1 | 2 | 1 |
| 2971 | 1 | 0.904 | 2 | 1 | 9 | 1 |
| 2972 | 1 | 0.904 | 1 | 1 | 2 | 1 |
| 2973 | 1 | 0.904 | 1 | 1 | 0 | 1 |
| 2974 | 1 | 0.389 | 2 | 2 | 0 | 0 |
| 2975 | 1 | 0.904 | 2 | 1 | 3 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kovalchuk, O.; Karpinski, M.; Banakh, S.; Kasianchuk, M.; Shevchuk, R.; Zagorodna, N. Prediction Machine Learning Models on Propensity Convicts to Criminal Recidivism. Information 2023, 14, 161. https://doi.org/10.3390/info14030161
Kovalchuk O, Karpinski M, Banakh S, Kasianchuk M, Shevchuk R, Zagorodna N. Prediction Machine Learning Models on Propensity Convicts to Criminal Recidivism. Information. 2023; 14(3):161. https://doi.org/10.3390/info14030161
Chicago/Turabian StyleKovalchuk, Olha, Mikolaj Karpinski, Serhiy Banakh, Mykhailo Kasianchuk, Ruslan Shevchuk, and Nataliya Zagorodna. 2023. "Prediction Machine Learning Models on Propensity Convicts to Criminal Recidivism" Information 14, no. 3: 161. https://doi.org/10.3390/info14030161
APA StyleKovalchuk, O., Karpinski, M., Banakh, S., Kasianchuk, M., Shevchuk, R., & Zagorodna, N. (2023). Prediction Machine Learning Models on Propensity Convicts to Criminal Recidivism. Information, 14(3), 161. https://doi.org/10.3390/info14030161