
A Survey on Compression Domain Image and Video Data Processing and Analysis Techniques


Abstract
:1. Introduction
2. Image
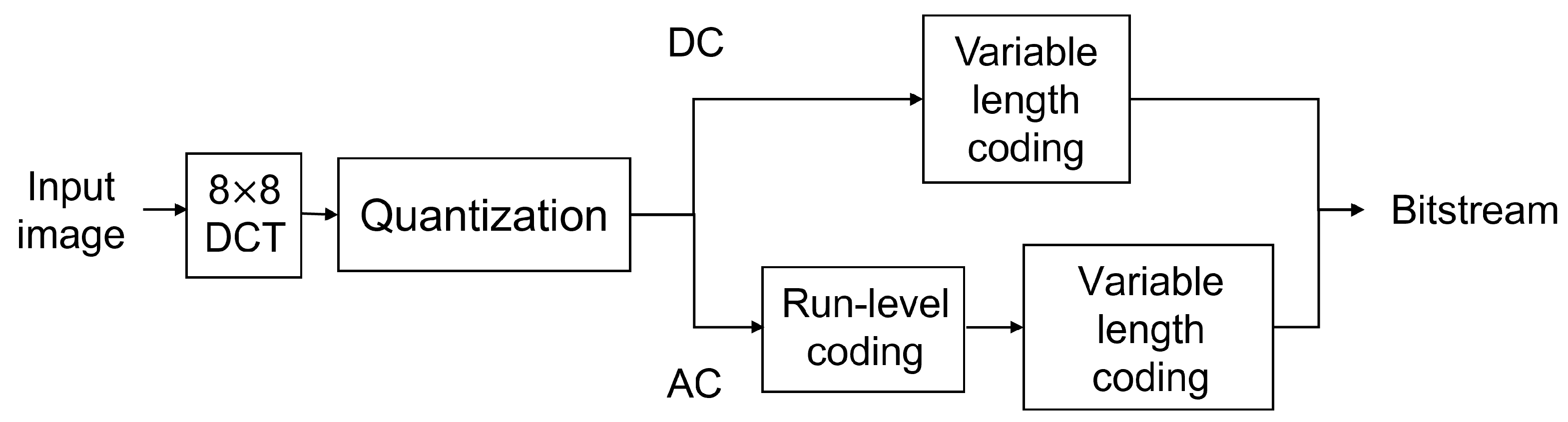
2.1. JPEG and DCT
2.2. Image Resizing
2.3. Image Enhancement and Edge Detection
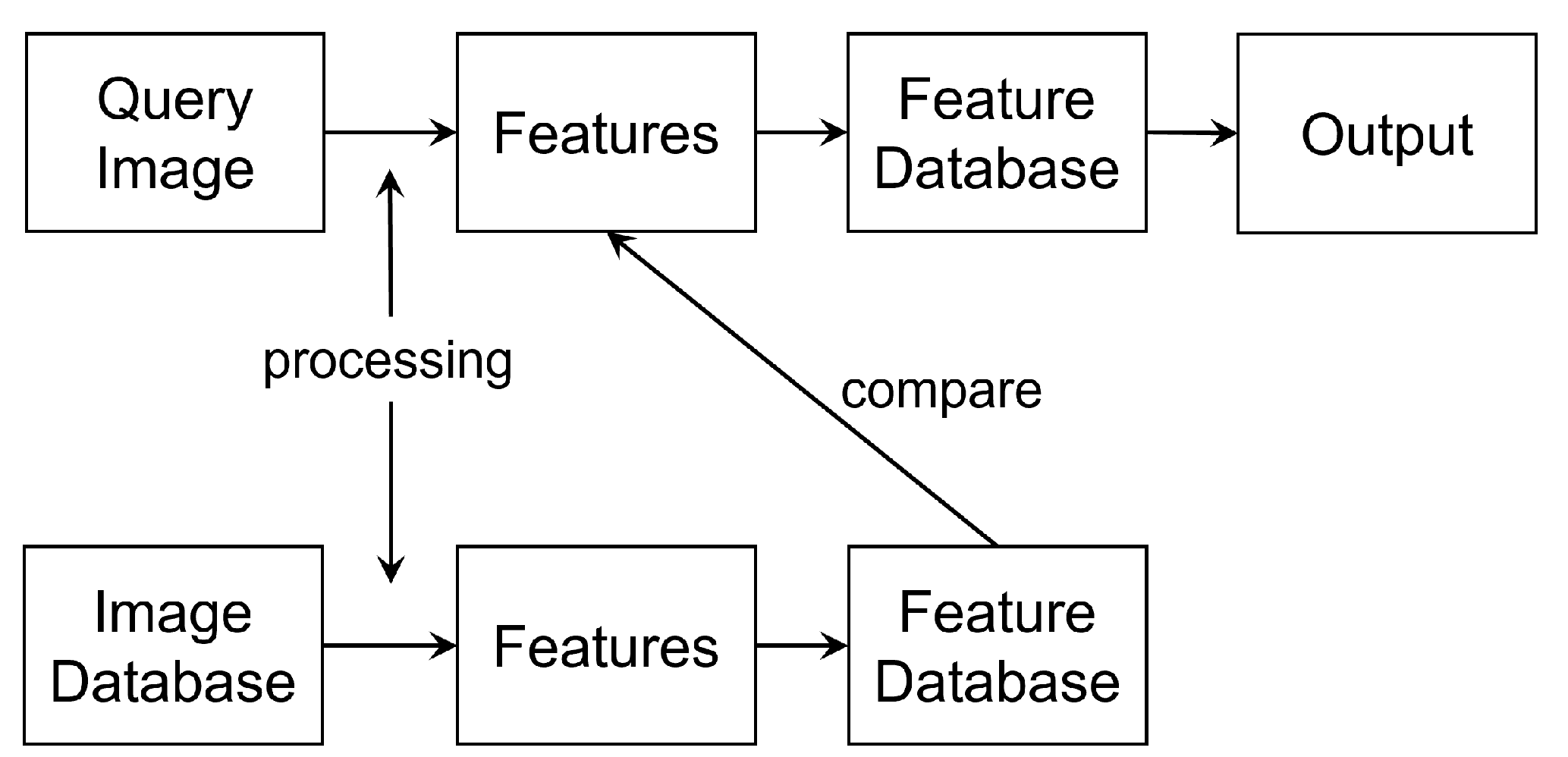
2.4. Image Retrieval
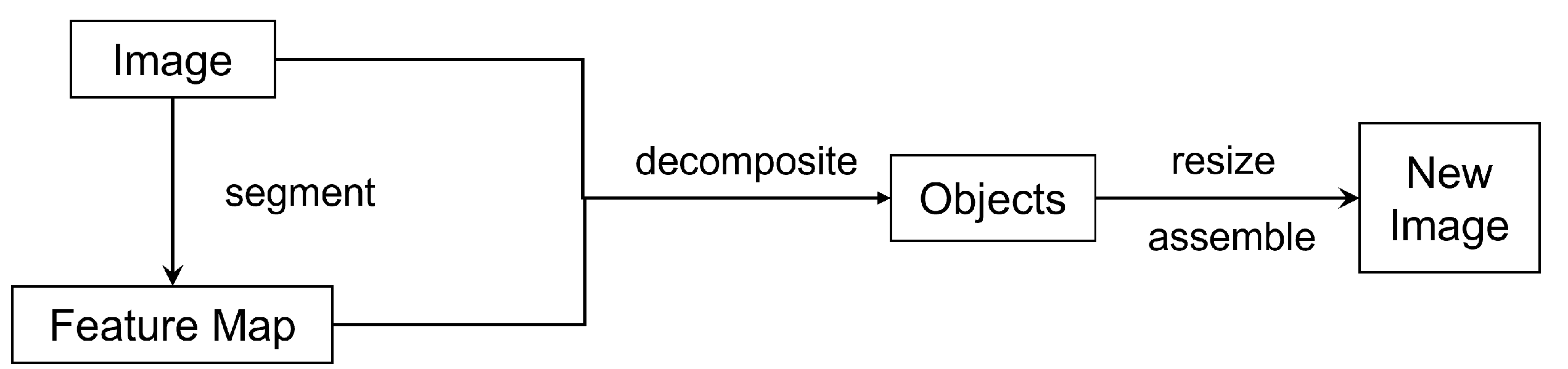
2.5. Image Retargeting
2.6. Image Hiding
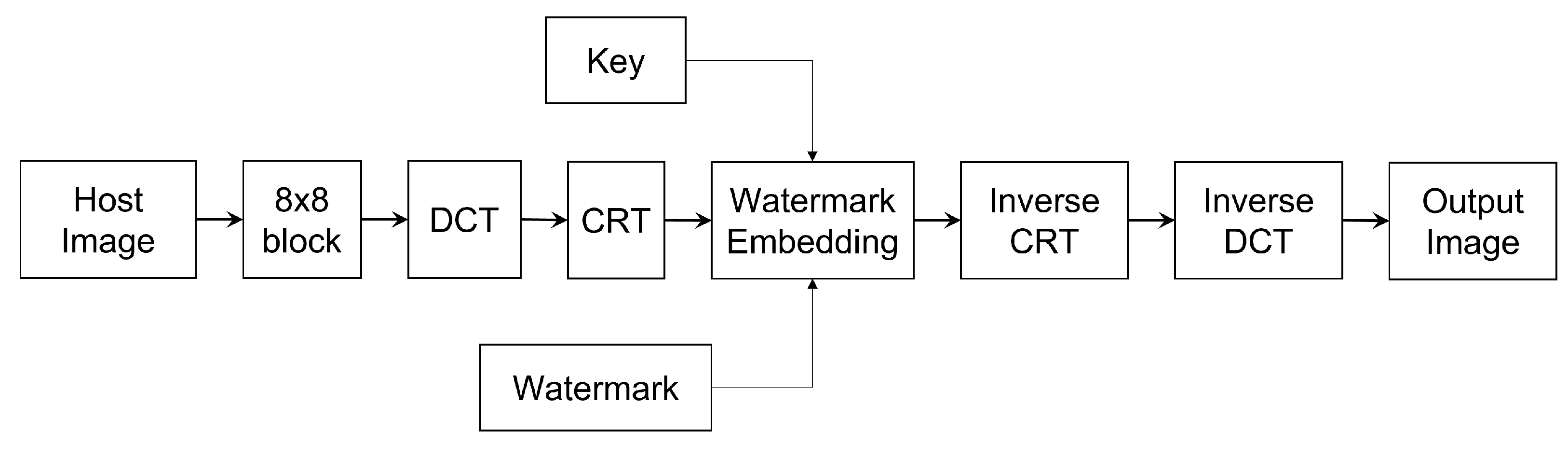
2.7. Watermark Embedding
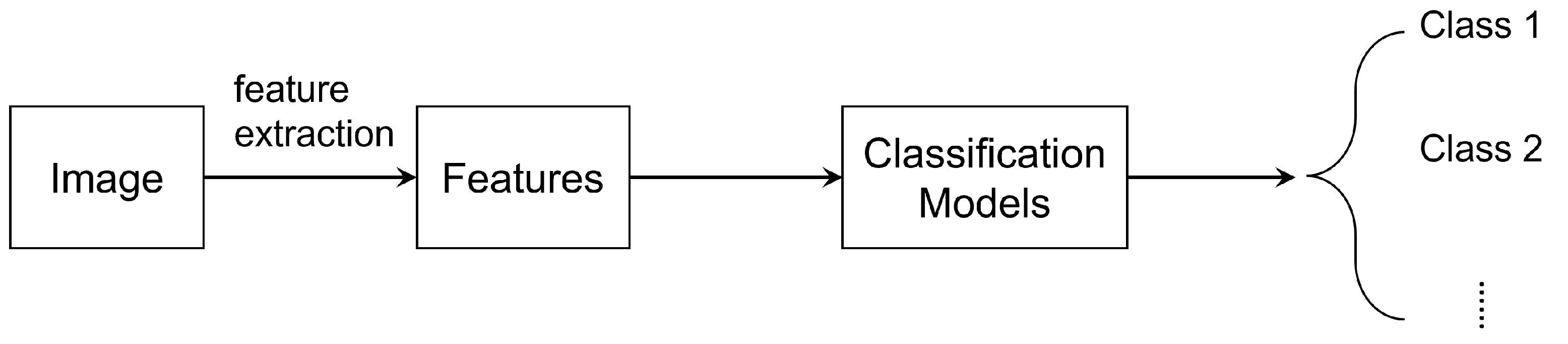
2.8. Image Classification
2.9. Other Applications
2.10. Summary
3. Video
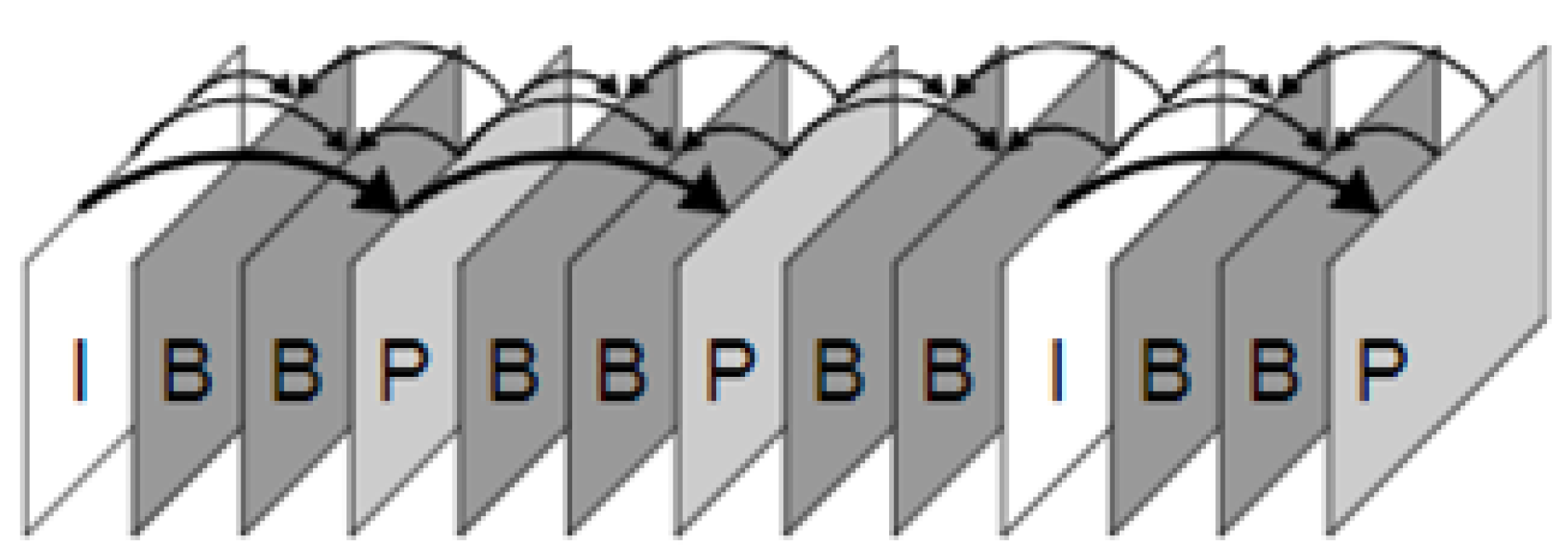
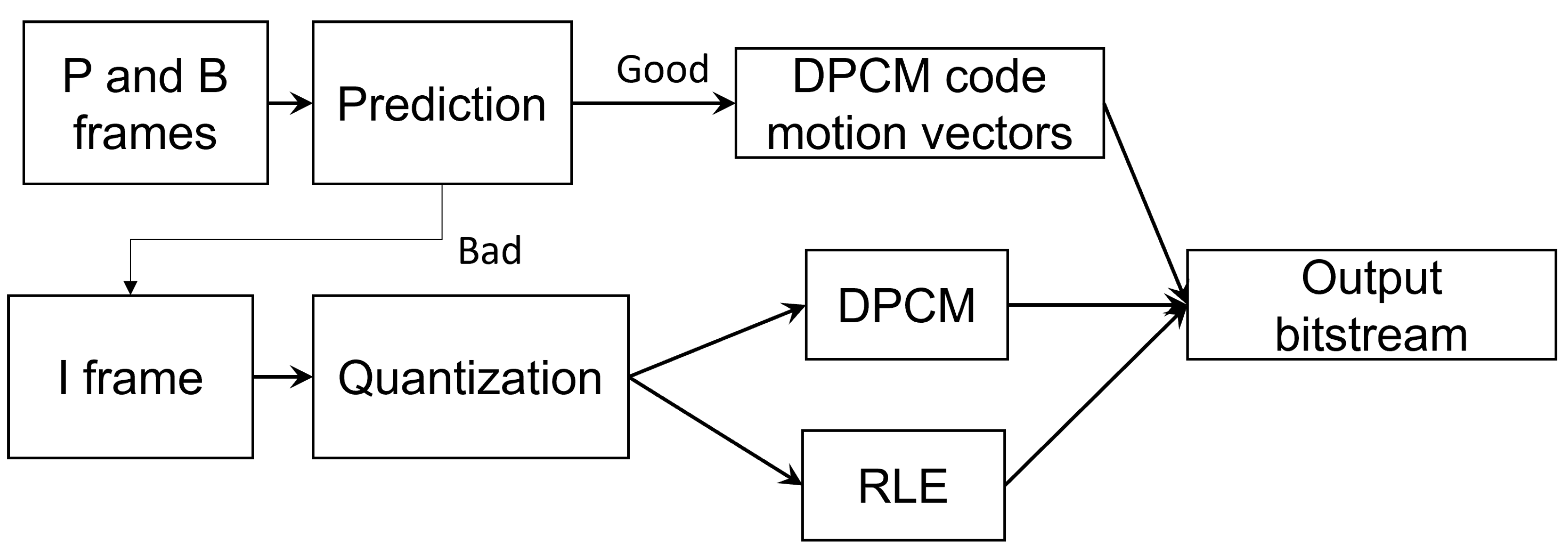
3.1. Video Compression and IPB Frames
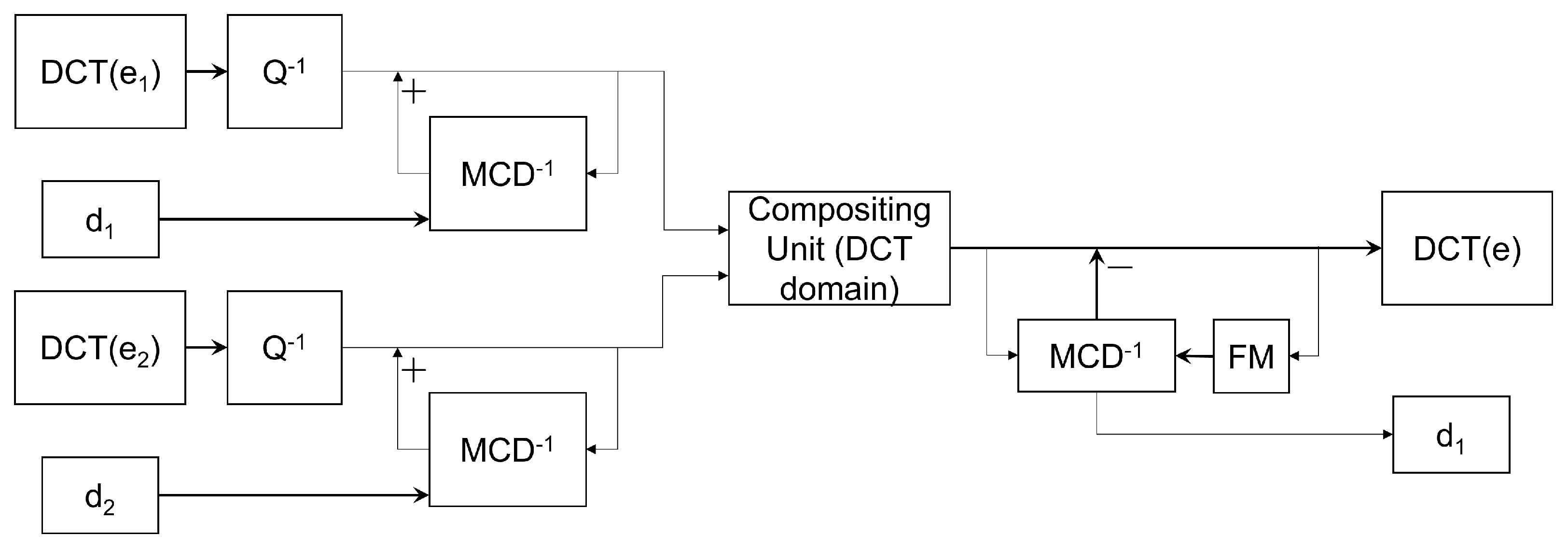
3.2. Video Compositing
3.3. Video Archiving, Indexing and Retrieval
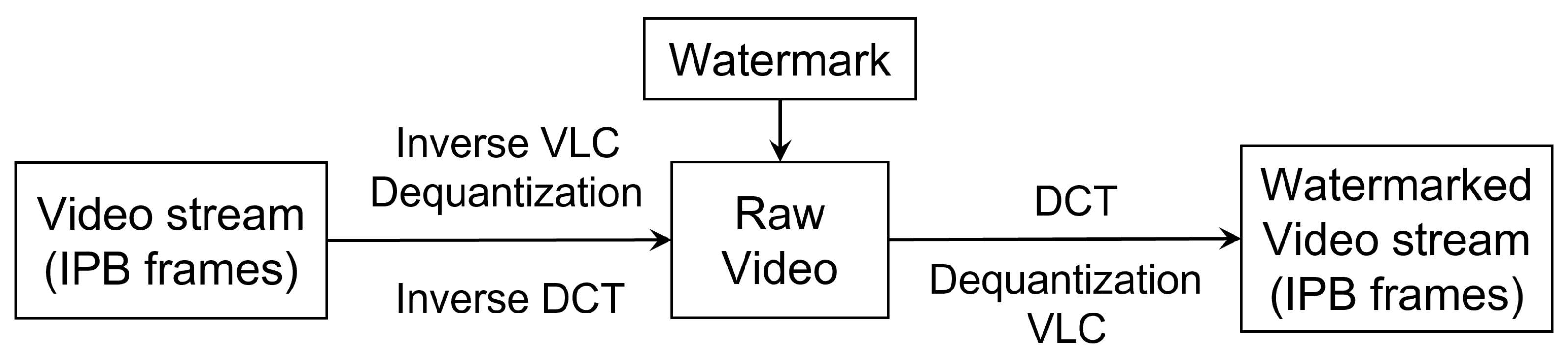
3.4. Caption and Watermark Embedding
3.5. Video Transcoding
3.6. Object Detection
3.7. Segmentation
3.8. Video Steganalysis
3.9. Salient Motion Detection
3.10. Video Resizing
3.11. Video Summarization and Abstraction
3.12. Other Applications
3.13. Summary
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| JPEG | Joint Photographic Experts Group |
| DCT | Discrete cosine transform |
| MCU | minimum coded unit |
| PSNR | peak signal-to-noise ratio |
| DWT | discrete wavelet transform |
| SVM | support vector machine |
| CNN | Convolutional neural network |
| LSTM | Long short-term memory |
| MPEG | Moving Picture Experts Group |
| HEVC | High Efficiency Video Coding |
| MV | motion vector |
| MC | motion compensation |
| NNZ | number of nonzero |
| PNG | Portable Network Graphic |
| CTU | coding tree unit |
References
- Paula Dootson. 3.2 Billion Images and 720,000 Hours of Video Are Shared Online Daily. Can You Sort Real from Fake? Available online: https://www.qut.edu.au/study/business/insights/3.2-billion-images-and-720000-hours-of-video-are-shared-online-daily.-can-you-sort-real-from-fake (accessed on 14 March 2023).
- Antonio, R.; Faria, S.; Tavora, L.M.; Navarro, A.; Assuncao, P. Learning-based compression of visual objects for smart surveillance. In Proceedings of the 2022 Eleventh International Conference on Image Processing Theory, Tools and Applications (IPTA), Salzburg, Austria, 19–22 April 2022; IEEE: New York, NY, USA, 2022; pp. 1–6. [Google Scholar]
- Bhardwaj, V.; Rasamsetti, Y.; Valsan, V. Traffic Control System for Smart City Using Image Processing. In AI and IoT for Smart City Applications; IEEE: New York, NY, USA, 2022; pp. 83–99. [Google Scholar]
- Mavrogiorgou, A.; Kiourtis, A.; Kyriazis, D. Iot devices recognition through object detection and classification techniques. In Proceedings of the 2019 Third World Conference on Smart Trends in Systems Security and Sustainablity (WorldS4), London, UK, 30–31 July 2019; IEEE: New York, NY, USA, 2019; pp. 12–20. [Google Scholar]
- Anand, A.; Singh, A.K.; Lv, Z.; Bhatnagar, G. Compression-then-encryption-based secure watermarking technique for smart healthcare system. IEEE Multimed. 2020, 27, 133–143. [Google Scholar] [CrossRef]
- Ammah, P.N.T.; Owusu, E. Robust medical image compression based on wavelet transform and vector quantization. Inform. Med. Unlocked 2019, 15, 100183. [Google Scholar] [CrossRef]
- Abdellatif, A.A.; Emam, A.; Chiasserini, C.F.; Mohamed, A.; Jaoua, A.; Ward, R. Edge-based compression and classification for smart healthcare systems: Concept, implementation and evaluation. Expert Syst. Appl. 2019, 117, 1–14. [Google Scholar] [CrossRef]
- Pareek, P.K.; Sridhar, C.; Kalidoss, R.; Aslam, M.; Maheshwari, M.; Shukla, P.K.; Nuagah, S.J. IntOPMICM: Intelligent medical image size reduction model. J. Healthc. Eng. 2022, 2022, 5171016. [Google Scholar] [CrossRef]
- Dimililer, K. DCT-based medical image compression using machine learning. Signal Image Video Process. 2022, 16, 55–62. [Google Scholar] [CrossRef]
- Golini, M. Real-Time and High-Quality Video Compression for Telesurgery; Politecnico di Milano: Milan, Italy, 2022. [Google Scholar]
- Sikka, R. Agricultural Image Analysis on Wavelet Transform. In Proceedings of the International Conference on Intelligent Emerging Methods of Artificial Intelligence & Cloud Computing: Proceedings of IEMAICLOUD 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 122–127. [Google Scholar]
- Wallace, G.K. The JPEG still picture compression standard. Commun. ACM 1991, 34, 30–44. [Google Scholar] [CrossRef]
- Martucci, S.A. Image resizing in the discrete cosine transform domain. In International Conference on Image Processing; IEEE: New York, NY, USA, 1995; Volume 2, pp. 244–247. [Google Scholar]
- Dugad, R.; Ahuja, N. A fast scheme for image size change in the compressed domain. IEEE Trans. Circuits Syst. Video Technol. 2001, 11, 461–474. [Google Scholar] [CrossRef] [Green Version]
- Mukherjee, J.; Mitra, S.K. Image resizing in the compressed domain using subband DCT. IEEE Trans. Circuits Syst. Video Technol. 2002, 12, 620–627. [Google Scholar] [CrossRef]
- Shen, B.; Sethi, I.K. Direct feature extraction from compressed images. In Proceedings of the Storage and retrieval for still image and video databases IV, San Jose, CA, USA, 28 January–2 February 1996; SPIE: Washington, DC, USA, 1996; pp. 404–414. [Google Scholar]
- Shen, B.; Sethi, I.K. Convolution-based edge detection for image/video in block DCT domain. J. Vis. Commun. Image Represent. 1996, 7, 411–423. [Google Scholar] [CrossRef]
- Shen, B. Compressed Domain Processing: Algorithms and Applications; Wayne State University ProQuest Dissertations Publishing: Detroit, MI, USA, 1997. [Google Scholar]
- Shen, B.; Sethi, I.K. Block-based manipulations on transform-compressed images and videos. Multimed. Syst. 1998, 6, 113–124. [Google Scholar] [CrossRef]
- Wee, S.; Shen, B.; Apostolopoulos, J. Compressed-Domain Video Processing. In Hewlett-Packard, Tech. Rep. HPL-2002-282; 2002; Available online: https://www.hpl.hp.com/techreports/2002/HPL-2002-282.pdf (accessed on 14 March 2023).
- Chen, B.; Latifi, S.; Kanai, J. Edge enhancement of remote sensing image data in the DCT domain. Image Vis. Comput. 1999, 17, 913–921. [Google Scholar] [CrossRef]
- Javed, M.; Nagabhushan, P.; Chaudhuri, B.B.; Singh, S.K. Edge based enhancement of retinal images using an efficient JPEG-compressed domain technique. J. Intell. Fuzzy Syst. 2019, 36, 541–556. [Google Scholar] [CrossRef]
- Jiang, J. Image segmentation in compressed domain. J. Electron. Imaging 2003, 12, 390. [Google Scholar] [CrossRef]
- Tang, J.; Peli, E.; Acton, S. Image enhancement using a contrast measure in the compressed domain. IEEE Signal Process. Lett. 2003, 10, 289–292. [Google Scholar] [CrossRef]
- Jain, A.K.; Zhong, Y.; Jain, A.K. Object localization using color, texture and shape. Pattern Recognit. 2000, 33, 671–684. [Google Scholar]
- Jamil, A.; Majid, M.; Anwar, S.M. An Optimal Codebook for Content-Based Image Retrieval in JPEG Compressed Domain. Arab. J. Sci. Eng. 2019, 44, 9755–9767. [Google Scholar] [CrossRef]
- Pimentel Filho, C.A.F.; Bustos, B.; Araújo, A.d.A.; Guimarães, S.J.F. Combining pixel domain and compressed domain index for sketch based image retrieval. Multimed. Tools Appl. 2017, 76, 22019–22042. [Google Scholar] [CrossRef]
- Temburwar, S.; Rajesh, B.; Javed, M. Deep Learning-Based Image Retrieval in the JPEG Compressed Domain. In Advanced Machine Intelligence and Signal Processing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 351–363. [Google Scholar]
- Liu, P.; Guo, J.M.; Wu, C.Y.; Cai, D. Fusion of deep learning and compressed domain features for content-based image retrieval. IEEE Trans. Image Process. 2017, 26, 5706–5717. [Google Scholar] [CrossRef]
- Fang, Y.; Chen, Z.; Lin, W.; Lin, C.W. Saliency detection in the compressed domain for adaptive image retargeting. IEEE Trans. Image Process. 2012, 21, 3888–3901. [Google Scholar] [CrossRef] [Green Version]
- Tang, Z.; Yao, J.; Zhang, Q. Multi-operator image retargeting in compressed domain by preserving aspect ratio of important contents. Multimed. Tools Appl. 2022, 81, 1501–1522. [Google Scholar] [CrossRef]
- Jung, S.W. Adaptive post-filtering of JPEG compressed images considering compressed domain lossless data hiding. Inf. Sci. 2014, 281, 355–364. [Google Scholar] [CrossRef]
- Lu, Z.M.; Guo, S.Z. Lossless Information Hiding in Images; Zhejiang University Press: Hangzhou, China, 2016. [Google Scholar]
- Fei, C.; Kundur, D.; Kwong, R. The choice of watermark domain in the presence of compression. In Proceedings of the International Conference on Information Technology: Coding and Computing, Las Vegas, NV, USA, 2–4 April 2001; IEEE: New York, NY, USA, 2001; pp. 79–84. [Google Scholar]
- Patra, J.C.; Phua, J.E.; Bornand, C. A novel DCT domain CRT-based watermarking scheme for image authentication surviving JPEG compression. Digit. Signal Process. A Rev. J. 2010, 20, 1597–1611. [Google Scholar] [CrossRef]
- Ye, Q.; Gao, W.; Zeng, W.; Zhang, T.; Wang, W.; Liu, Y. Objectionable image recognition system in compression domain. Lect. Notes Comput. Sci. 2004, 2690, 1131–1135. [Google Scholar] [CrossRef]
- Fu, D.; Guimaraes, G. Using Compression to Speed Up Image Classification in Artificial Neural Networks. Available online: https://www.danfu.org/files/CompressionImageClassification.pdf (accessed on 14 March 2023).
- Arslan, H.S.; Archambault, S.; Bhatt, P.; Watanabe, K.; Cuevaz, J.; Le, P.; Miller, D.; Zhumatiy, V. Usage of compressed domain in fast frameworks. Signal Image Video Process. 2022, 16, 1763–1771. [Google Scholar] [CrossRef]
- Hill, P.R.; Bull, D.R. Transform and Bitstream Domain Image Classification. arXiv 2021, arXiv:2110.06740. [Google Scholar]
- Tang, J.; Deng, C.; Huang, G.B.; Zhao, B. Compressed-domain ship detection on spaceborne optical image using deep neural network and extreme learning machine. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1174–1185. [Google Scholar] [CrossRef]
- Hafed, Z.M.; Levine, M.D. Face Recognition Using the Discrete Cosine Transform. Int. J. Comput. Vis. 2001, 43, 167–188. [Google Scholar] [CrossRef]
- Verma, V.; Agarwal, N.; Khanna, N. DCT-domain deep convolutional neural networks for multiple JPEG compression classification. Signal Process. Image Commun. 2018, 67, 22–33. [Google Scholar] [CrossRef] [Green Version]
- Dong, Y.; Pan, W.D. Image Classification in JPEG Compression Domain for Malaria Infection Detection. J. Imaging 2022, 8, 129. [Google Scholar] [CrossRef]
- Rajesh, B.; Dusa, N.; Javed, M.; Dubey, S.R.; Nagabhushan, P. T2CI-GAN: Text to Compressed Image generation using Generative Adversarial Network. arXiv 2022, arXiv:2210.03734. [Google Scholar]
- Li, X.; Zhang, Y.; Yuan, J.; Lu, H.; Zhu, Y. Discrete Cosin TransFormer: Image Modeling From Frequency Domain. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 5468–5478. [Google Scholar]
- Chang, S.F.; Messerschmitt, D.G. A new approach to decoding and compositing motion-compensated DCT-based images. In Proceedings of the 1993 IEEE International Conference on Acoustics, Speech, and Signal Processing, Minneapolis, MN, USA, 27–30 April 1993; IEEE: New York, NY, USA, 1993; Volume 5, pp. 421–424. [Google Scholar]
- Merhav, N.; Bhaskaran, V. A Fast Algorithm for Dct-Domain Inverse Motion Compensation. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings, Atlanta, GA, USA, 7–10 May 1996; IEEE: New York, NY, USA; pp. 2307–2310. [Google Scholar]
- Meng, J.; Chang, S.F. CVEPS-a compressed video editing And parsing system. In Proceedings of the Forth International Conference on Multimedia, Boston, MA, USA, 18–22 November 1996; ACM: Rochester, NY, USA; pp. 43–53. [Google Scholar]
- Meng, J.; Chang, S.F. Tools for compressed-domain video indexing and editing. In Proceedings of the Storage and Retrieval for Still Image and Video Databases IV, San Jose, CA, USA, 28 January–2 February 1996; SPIE: Washington, DC, USA, 1996; Volume 2670, pp. 180–191. [Google Scholar]
- Noguchi, Y.; Messerschmitt, D.G.; Chang, S.F. MPEG video compositing in the compressed domain. In Proceedings of the 1996 IEEE International Symposium on Circuits and Systems (ISCAS), Atlanta, GA, USA, 12–15 May 1996; IEEE: New York, NY, USA, 1996; Volume 2, pp. 596–599. [Google Scholar]
- Smith, B.C.; Rowe, L.A. Compressed Domain Processing of JPEG-encoded images. Real-Time Imaging 1996, 2, 3–17. [Google Scholar] [CrossRef]
- Kobla, V.; Doermann, D.S.; Lin, K.I. Archiving, indexing, and retrieval of video in the compressed domain. In Multimedia Storage and Archiving Systems; SPIE: Washington, DC, USA, 1996; Volume 2916, pp. 78–89. [Google Scholar] [CrossRef]
- Kobla, V.; Doermann, D.S.; Lin, K.I.; Faloutsos, C. Compressed-domain video indexing techniques using DCT and motion vector information in MPEG video. In Storage and Retrieval for Image and Video Databases V; SPIE: Washington, DC, USA, 1997; Volume 3022, pp. 200–211. [Google Scholar]
- Mandal, M.K.; Idris, F.; Panchanathan, S. A critical evaluation of image and video indexing techniques in the compressed domain. Image Vis. Comput. 1999, 17, 513–529. [Google Scholar] [CrossRef]
- Wang, H.; Divakaran, A.; Vetro, A.; Chang, S.F.; Sun, H. Survey of compressed-domain features used in audio-visual indexing and analysis. J. Vis. Commun. Image Represent. 2003, 14, 150–183. [Google Scholar] [CrossRef]
- Meng, J.; Chang, S.F. Embedding visible video watermarks in the compressed domain. In Proceedings of the 1998 International Conference on Image Processing, ICIP98 (Cat. No. 98CB36269), Chicago, IL, USA, 4–7 October 1998; IEEE: New York, NY, USA, 1998; Volume 1, pp. 474–477. [Google Scholar]
- Nang, J.; Kwon, O.; Hong, S. Caption processing for MPEG video in MC-DCT compressed domain. In Proceedings of the Eighth ACM International Conference on Multimedia, Los Angeles, CA, USA, 30 October–3 November 2000; pp. 211–218. [Google Scholar]
- Mansouri, A.; Aznaveh, A.M.; Torkamani-Azar, F.; Kurugollu, F. A low complexity video watermarking in H.264 compressed domain. IEEE Trans. Inf. Forensics Secur. 2010, 5, 649–657. [Google Scholar] [CrossRef]
- Dutta, T.; Gupta, H.P. An efficient framework for compressed domain watermarking in p frames of high-efficiency video coding (HEVC)-encoded video. ACM Trans. Multimed. Comput. Commun. Appl. 2017, 13, 1–24. [Google Scholar] [CrossRef]
- Acharya, S.; Smith, B. Compressed domain transcoding of MPEG. In Proceedings of the IEEE International Conference on Multimedia Computing and Systems (Cat. No. 98TB100241), Austin, TX, USA, 1 July 1998; IEEE: New York, NY, USA, 1998; pp. 295–304. [Google Scholar] [CrossRef]
- Shanableh, T.; Ghanbari, M. Hybrid DCT/pixel domain architecture for heterogeneous video transcoding. Signal Process. Image Commun. 2003, 18, 601–620. [Google Scholar] [CrossRef]
- Lin, H.Y.; Tsai, T.H.; Lin, Y.F. Video transcoder in DCT-domain spatial resolution reduction using low-complexity motion vector refinement algorithm. Eurasip J. Adv. Signal Process. 2008, 2008, 467290. [Google Scholar] [CrossRef] [Green Version]
- Wee, S.J.; Vasudev, B. Compressed-domain reverse play of MPEG video streams. In Multimedia Systems and Applications; SPIE: Washington, DC, USA, 1999; Volume 3528, pp. 237–248. [Google Scholar]
- Hesseler, W.; Eickeler, S. MPEG-2 compressed-domain algorithms for video analysis. Eurasip J. Appl. Signal Process. 2006, 2006, 056940. [Google Scholar] [CrossRef] [Green Version]
- Alvar, S.R.; Bajić, I.V. MV-YOLO: Motion vector-aided tracking by semantic object detection. In Proceedings of the 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), Vancouver, BC, Canada, 29–31 August 2018; IEEE: New York, NY, USA, 2018; pp. 1–5. [Google Scholar]
- Ujiie, T.; Hiromoto, M.; Sato, T. Interpolation-based object detection using motion vectors for embedded real-time tracking systems. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 616–624. [Google Scholar]
- Liu, Q.; Liu, B.; Wu, Y.; Li, W.; Yu, N. Real-time Online Multi-Object Tracking in Compressed Domain. arXiv 2022, arXiv:2204.02081. [Google Scholar] [CrossRef]
- Chen, L.; Sun, H.; Katto, J.; Zeng, X.; Fan, Y. Fast Object Detection in HEVC Intra Compressed Domain. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; IEEE: New York, NY, USA, 2021; pp. 756–760. [Google Scholar]
- Alizadeh, M.; Sharifkhani, M. Compressed Domain Moving Object Detection Based on CRF. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 674–684. [Google Scholar] [CrossRef]
- LAFFERTY, J. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Proc. 18th International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Porikli, F.; Bashir, F.; Sun, H. Compressed domain video object segmentation. IEEE Trans. Circuits Syst. Video Technol. 2010, 20, 2–14. [Google Scholar] [CrossRef]
- Tan, Z.; Liu, B.; Chu, Q.; Zhong, H.; Wu, Y.; Li, W.; Yu, N. Real Time Video Object Segmentation in Compressed Domain. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 175–188. [Google Scholar] [CrossRef]
- Alvar, S.R.; Choi, H.; Bajic, I.V. Can you tell a face from a HEVC bitstream? In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; IEEE: New York, NY, USA, 2018; pp. 257–261. [Google Scholar]
- Feng, J.; Li, S.; Li, X.; Wu, F.; Tian, Q.; Yang, M.H.; Ling, H. TapLab: A Fast Framework for Semantic Video Segmentation Tapping into Compressed-Domain Knowledge. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1591–1603. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Sung, A.H.; Qiao, M. Video steganalysis based on the expanded Markov and joint distribution on the transform domains - Detecting MSU stegovideo. In Proceedings of the 2008 Seventh International Conference on Machine Learning and Applications, San Diego, CA, USA, 11–13 December 2008; pp. 671–674. [Google Scholar] [CrossRef]
- Mstafa, R.J.; Elleithy, K.M. Compressed and raw video steganography techniques: A comprehensive survey and analysis. Multimed. Tools Appl. 2017, 76, 21749–21786. [Google Scholar] [CrossRef]
- Muthuswamy, K.; Rajan, D. Salient motion detection in compressed domain. IEEE Signal Process. Lett. 2013, 20, 996–999. [Google Scholar] [CrossRef]
- Fang, Y.; Lin, W.; Chen, Z.; Tsai, C.M.; Lin, C.W. A video saliency detection model in compressed domain. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 27–38. [Google Scholar] [CrossRef]
- Zhu, S.; Liu, C.; Xu, Z. High-Definition Video Compression System Based on Perception Guidance of Salient Information of a Convolutional Neural Network and HEVC Compression Domain. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 1946–1959. [Google Scholar] [CrossRef]
- Chadha, A.; Abbas, A.; Andreopoulos, Y. Compressed-domain video classification with deep neural networks: “There’s way too much information to decode the matrix”. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: New York, NY, USA, 2017; pp. 1832–1836. [Google Scholar]
- Zhu, W.; Yang, K.H.; Beacken, M.J. CIF-to-QCIF Video Bitstream Down-Conversion in the DCT Domain. Bell Labs Tech. J. 1998, 3, 21–29. [Google Scholar] [CrossRef]
- Roma, N.; Sousa, L. Efficient hybrid DCT-domain algorithm for video spatial downscaling. Eurasip J. Adv. Signal Process. 2007, 2007, 057291. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Li, S.; Kuo, C.C. Compressed-domain video retargeting. IEEE Trans. Image Process. 2014, 23, 797–809. [Google Scholar] [CrossRef]
- Almeida, J.; Leite, N.J.; Torres, R.D.S. Online video summarization on compressed domain. J. Vis. Commun. Image Represent. 2013, 24, 729–738. [Google Scholar] [CrossRef]
- Yamghani, A.R.; Zargari, F. Compressed Domain Video Abstraction Based on I-Frame of HEVC Coded Videos. Circuits, Syst. Signal Process. 2019, 38, 1695–1716. [Google Scholar] [CrossRef]
- Basavarajaiah, M.; Sharma, P. Survey of compressed domain video summarization techniques. ACM Comput. Surv. 2019, 52, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Dorai, C.; Ratha, N.K.; Bolle, R.M. Detecting dynamic behavior in compressed fingerprint videos: Distortion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2000 (Cat. No. PR00662), Hilton Head, SC, USA, 13–15 June 2000; IEEE: New York, NY, USA, 2000; Volume 2, pp. 320–326. [Google Scholar] [CrossRef]
- Arman, F.; Hsu, A.; Chiu, M.Y. Image processing on compressed data for large video databases. In Proceedings of the First ACM International Conference on Multimedia, Anaheim, CA, USA, 1–6 August 1993; pp. 267–272. [Google Scholar]
- Darwish, A.M. A Video coprocessor: Video processing in the DCT domain. In Proceedings of the Media Processors, San Jose, CA, USA, 28–29 January 1999; SPIE: Washington, DC, USA, 1998; Volume 3655, pp. 158–168. [Google Scholar] [CrossRef]
- Kaminsky, E.; Ginzburg, A.; Hadar, O. DCT-domain coder for digital video applications. J. Real-Time Image Process. 2010, 5, 259–274. [Google Scholar] [CrossRef]
- Ilgin, H.A.; Chaparro, L.F. Low bit rate video coding using DCT-based fast decimation/interpolation and embedded zerotree coding. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 833–844. [Google Scholar] [CrossRef]
- Shapiro, J.M. Embedded image coding using zerotrees of wavelet coefficients. IEEE Trans. Signal Process. 1993, 41, 3445–3462. [Google Scholar] [CrossRef]
- Thies, W.; Hall, S.; Amarasinghe, S. Manipulating Lossless Video in the Compressed Domain; ACM: Rochester, NY, USA, 2009; p. 1166. [Google Scholar]
- Mao, N.; Zhuo, L.; Zhang, J.; Li, X. Fast Compression Domain Video Encryption Scheme for H.264/AVC Stream; IEEE: New York, NY, USA, 2012. [Google Scholar]
- Wang, Z.; Liu, X.; Feng, J.; Yang, J.; Xi, H. Compressed-Domain Highway Vehicle Counting by Spatial and Temporal Regression. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 263–274. [Google Scholar] [CrossRef]
- He, P.; Li, H.; Wang, H.; Wang, S.; Jiang, X.; Zhang, R. Frame-Wise Detection of Double HEVC Compression by Learning Deep Spatio-Temporal Representations in Compression Domain. IEEE Trans. Multimed. 2021, 23, 3179–3192. [Google Scholar] [CrossRef]
- Chen, P.; Yang, W.; Wang, M.; Sun, L.; Hu, K.; Wang, S. Compressed Domain Deep Video Super-Resolution. IEEE Trans. Image Process. 2021, 30, 7156–7169. [Google Scholar] [CrossRef]
- Chen, J.; Ho, C.M. MM-ViT: Multi-modal video transformer for compressed video action recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; IEEE: New York, NY, USA; pp. 1910–1921. [Google Scholar]
- Patel, R.; Lad, K.; Patel, M. Study and investigation of video steganography over uncompressed and compressed domain: A comprehensive review. Multimed. Syst. 2021, 27, 985–1024. [Google Scholar] [CrossRef]
- Mukhopadhyay, J. Image and Video Processing in the Compressed Domain; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Babu, R.V.; Tom, M.; Wadekar, P. A survey on compressed domain video analysis techniques. Multimed. Tools Appl. 2016, 75, 1043–1078. [Google Scholar] [CrossRef]
- Javed, M.; Nagabhushan, P.; Chaudhuri, B.B. A review on document image analysis techniques directly in the compressed domain. Artif. Intell. Rev. 2018, 50, 539–568. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target | References | Detail |
|---|---|---|
| Image Resizing | [13,14,15] | Change image dimensions |
| Image Enhancement | ||
| and Edge Detection | [16,17,18,19,20,21,22,23,24] | Change image properties to highlight certain region |
| Image Retrieval | [25,26,27,28,29] | Locate certain type of images from a large image database |
| Image Retargeting | [30,31] | Rearrange objects in differently sized images |
| Image Hiding | [32,33] | Conceal image in another image |
| Watermark Embedding | [34,35] | Add watermark on images |
| Image Classification | [36,37,38,39] | Separate images according to various attributes |
| Other Applications | [40,41] | Extract feature wavelet coefficients to detect objects, etc. |
| Target | References | Details |
|---|---|---|
| Video Compositing | [46,47,48,49,50,51] | Combine multiple video stream into one |
| Video Retrieval | [52,53,54,55] | Locate certain type of videos from a large video database |
| Watermark Embedding | [56,57,58,59] | Add watermark into video |
| Video Transcoding | [60,61,62,63] | Convert video from one format to another |
| Object Detection | [64,65,66,67,68,69,70] | Locate certain object |
| Segmentation | [71,72,73,74] | Separate certain object from frames |
| Video Steganalysis | [75,76] | Hide information in video stream |
| Salient Motion Detection | [77,78,79,80] | Detect saliency in video |
| Video Resizing | [81,82,83] | Change dimension of video |
| Video Summarization | [84,85,86] | Add tags that can be representative of the video |
| Other Applications | [87,88,89,90,91,92,93,94,95,96,97] | Detect double compression, etc. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, Y.; Pan, W.D. A Survey on Compression Domain Image and Video Data Processing and Analysis Techniques. Information 2023, 14, 184. https://doi.org/10.3390/info14030184
Dong Y, Pan WD. A Survey on Compression Domain Image and Video Data Processing and Analysis Techniques. Information. 2023; 14(3):184. https://doi.org/10.3390/info14030184
Chicago/Turabian StyleDong, Yuhang, and W. David Pan. 2023. "A Survey on Compression Domain Image and Video Data Processing and Analysis Techniques" Information 14, no. 3: 184. https://doi.org/10.3390/info14030184
APA StyleDong, Y., & Pan, W. D. (2023). A Survey on Compression Domain Image and Video Data Processing and Analysis Techniques. Information, 14(3), 184. https://doi.org/10.3390/info14030184