

An Efficient Healthcare Data Mining Approach Using Apriori Algorithm: A Case Study of Eye Disorders in Young Adults

 , ,
, ,  ,
,
Abstract
:1. Introduction
1.1. Motivation
1.2. Contribution
2. Literature Review
2.1. Research Gap
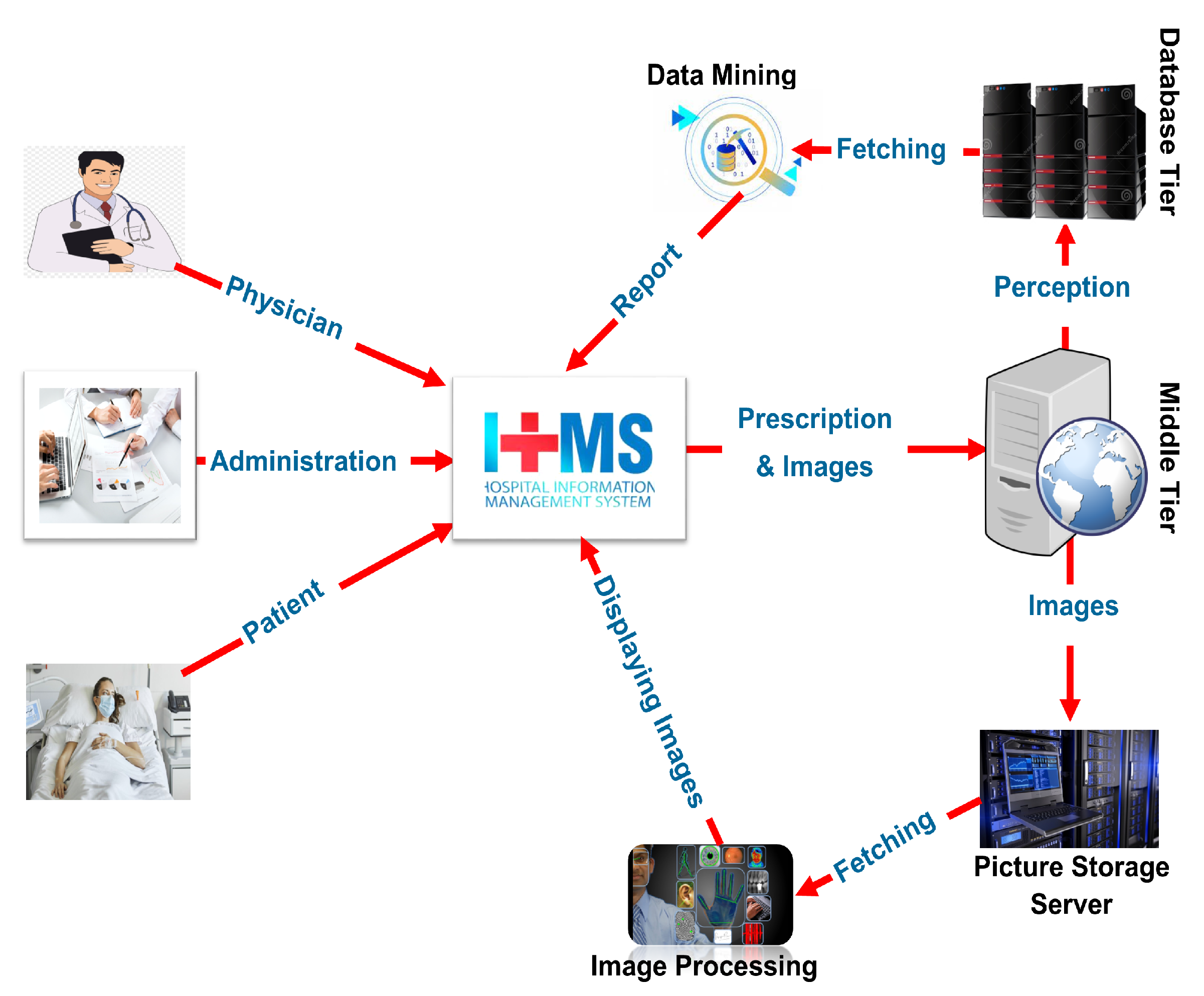
3. Proposed Model of Hospital Information Management System (HIMS)
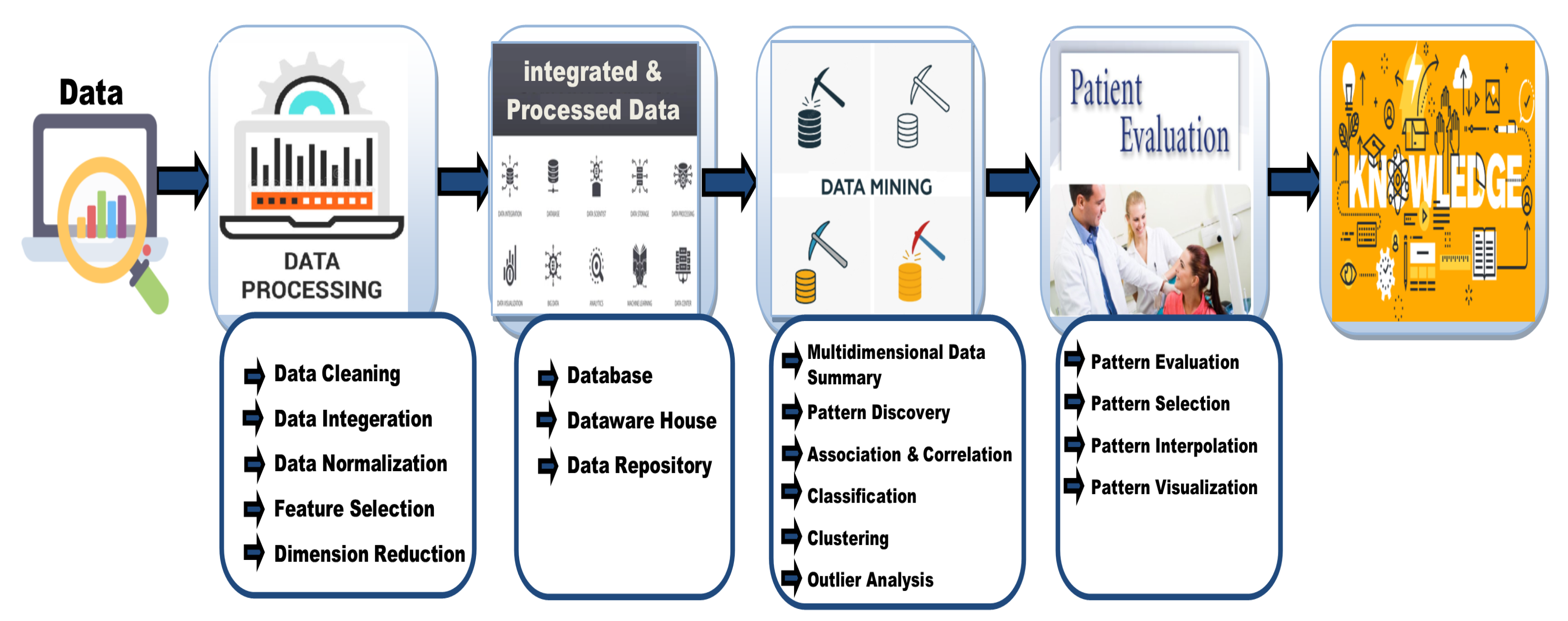
4. Mining Patient’s Health Records to Identify Frequent Patterns Using Association Rule-Based Apriori Algorithm
4.1. Data Analysis
- I.
- Data Requirement: Data requirement is the first and most important phase that defines what kind of data are required for analysis purposes. It varies from company to company and from requirement to requirement for analyzing a business process. Our data collection relates to eye disorder patients. The data obtained can be numerical or categorical (numerical or text). For our case study, we asked Chinese students about their age, sex, location, profession, hobbies, disease (if they have any) and age at the time of diagnosis, and use of glasses or treatments to overcome a disease.
- II.
- Data Collection: For data collection purposes, a questionnaire containing 10 questions relevant to the data requirement was created. The questionnaire contains “input data, single selection and multiple selection” type questions. An online survey form is created on Facebook, What’s App, and We Chat to achieve this goal.
- III.
- Data Processing: It is the process of organizing or handling the collected data for analysis purposes. There is a verity of data mining tools used for data processing purposes. In this research work, Rapid Miner5 community edition is used for most of the data mining tasks.
- IV.
- Data Cleaning: Data cleaning is the process of preventing and correcting data-related errors. We found that, in the eye disorder patient’s records, some of the individuals did not fill out required information, which resulted in missing values. These errors were removed using data mining tools such as Rapid Miner5.
- V.
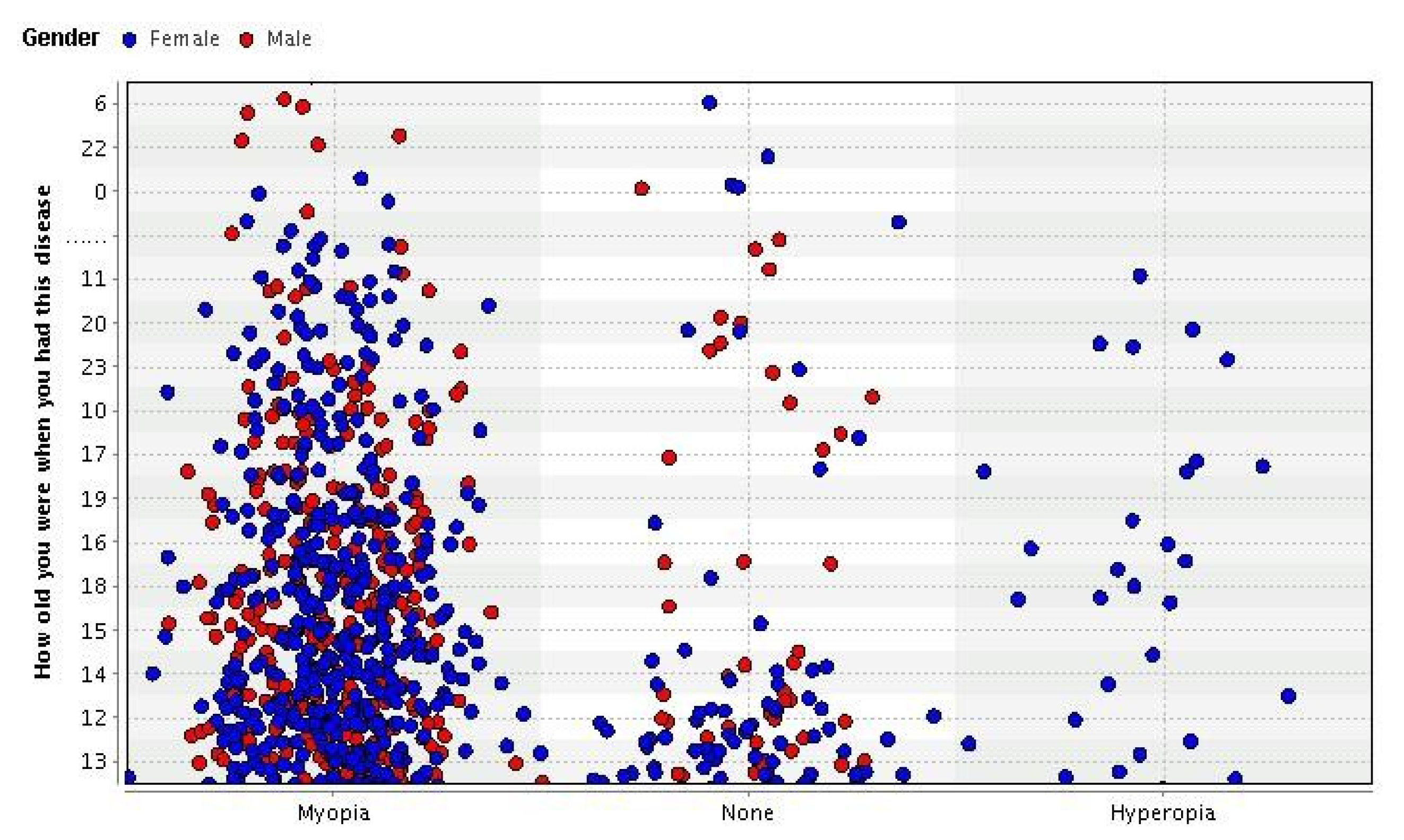
- Analyzing Data: A variety of data mining tools (either commercial or open source) are present to analyze data. Many tools provide different kinds of charts for data analysis purposes. The data of eye patients are analyzed by using Bar, Scatter, and histogram charts.
- VI.
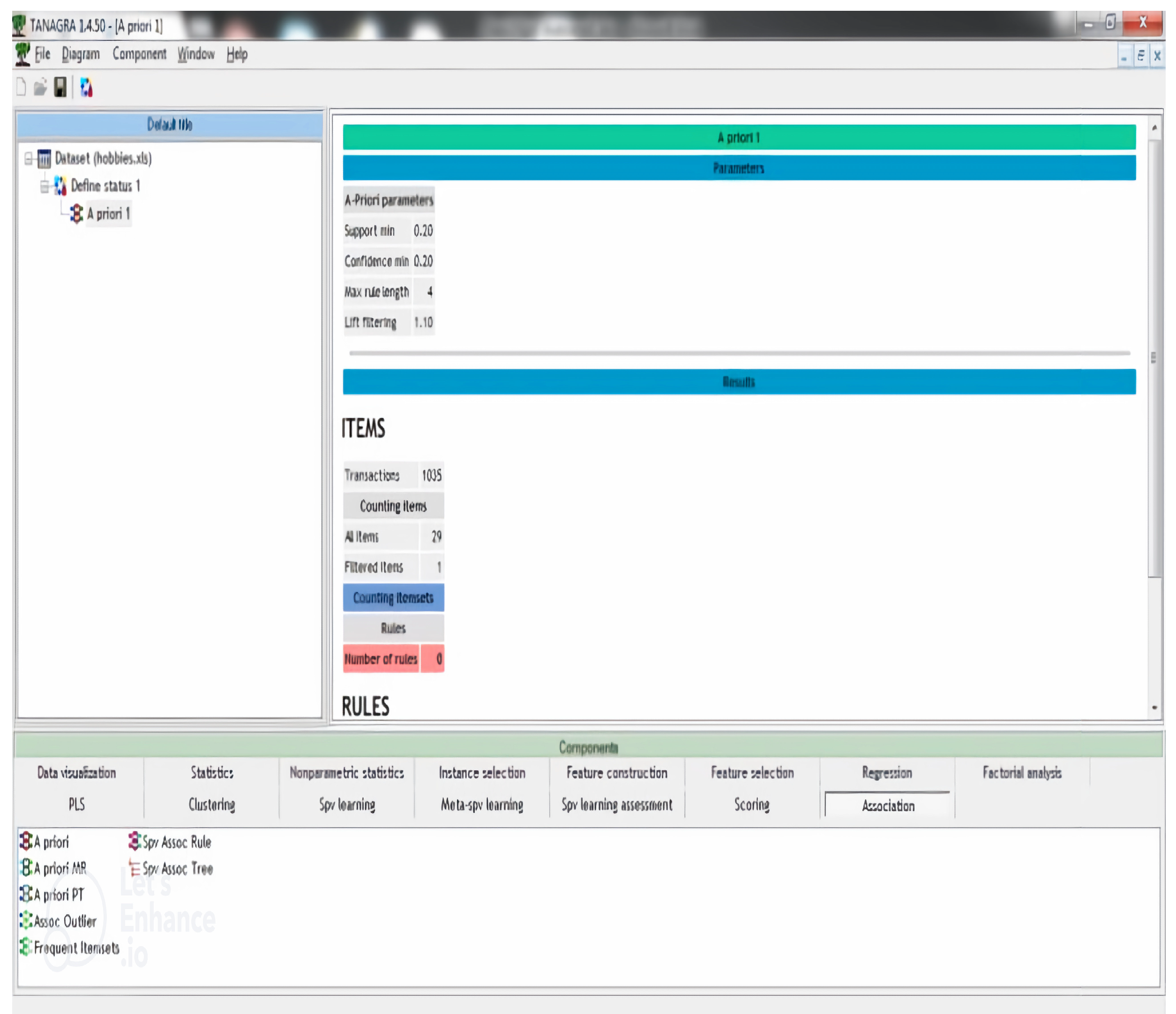
- Discovering Frequent Patterns: After analyzing the data of eye patients, we found interesting patterns by using the association rule approach. The Apriori algorithm, using an association rule, was employed to accomplish this goal.
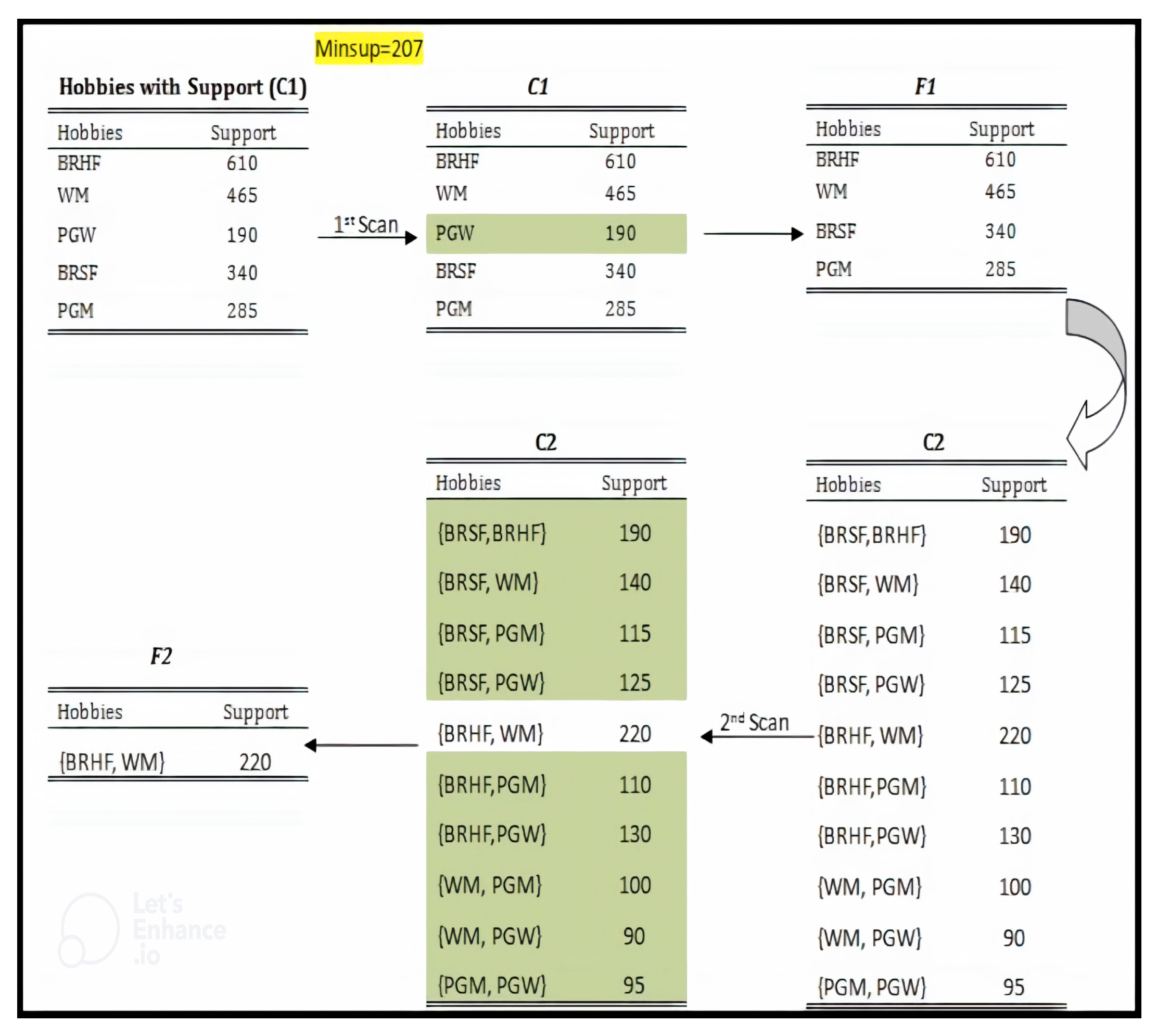
4.2. Apriori Algorithm
| Algorithm 1 Pseudo code of the Apriori algorithm. |
m: Patients’ Hobbies data item set of size m Fm: Frequent item set of size m m: = 1 Fm: = frequent items; While (Fm!= ) do { Cm+1:= Patients’ Hobbies data generated from Fm; Derive Fm by counting Patients’ Hobbies data in Cm+1 with respect to DB at minsup; m: = m+1 } Return Fm |
4.3. Apriori Algorithm on Patients Hobbies Record
5. Experimental Setup and Results
6. Discussion
- 1.
- Encourage young females (as they are more prone to eye problems) to perform some physical exercise.
- 2.
- Convince them to visit some fun places instead of staying in the hostel for long to avoid more frequent use of mobiles.
- 3.
- Ensure the physical participation in campus activities such as games.
- 4.
- Introduce them to healthy meal plans full of vitamins essential for eye health.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chae, Y.M.; Ho, S.H.; Cho, K.W.; Lee, D.H.; Ji, S.H. Data mining approach to policy analysis in a health insurance domain. Int. J. Med. Inform. 2001, 62, 103–111. [Google Scholar] [CrossRef] [PubMed]
- Bhagya Lakshmi, K.; Rajaram, M. Impact of information technology reliance and innovativeness on rural healthcare services: Study of dindigul district in Tamilnadu, India. Telemed. e-Health 2012, 18, 360–370. [Google Scholar] [CrossRef] [PubMed]
- Takeuchi, H.; Kodama, N.; Hashiguchi, T.; Hayashi, D. Automated healthcare data mining based on a personal dynamic healthcare system. In Proceedings of the 2006 International Conference of the IEEE Engineering in Medicine and Biology Society, New York, NY, USA, 30 August–3 September 2006; IEEE: New York, NY, USA, 2006; pp. 3604–3607. [Google Scholar]
- National Research Council. Protecting Individual Privacy in the Struggle Against Terrorists: A Framework for Program Assessment; National Academies Press: Washington, DC, USA, 2008. [Google Scholar]
- Stephen, H.; Cummings, M.; Phillips, A. Management Information Systems for the Information Age; McGraw-Hill/Irwin: New York, NY, USA, 2007. [Google Scholar]
- Rajkumar, N.; Karthick, R.V.; Nathiya, M.; Silambarasan, K. Mining association rules in big data for e-healthcare information system. Res. J. Appl. Sci. Eng. Technol. 2014, 8, 1002–1008. [Google Scholar] [CrossRef]
- Acharya, S.; Madhu, N. Discovery of students’ academic patterns using data mining techniques. Int. J. Comput. Sci. Eng. 2012, 4, 1054. [Google Scholar]
- NHHRC National Health and Hospitals Reform Commission. A Healthier Future for All Australians; Publications Number: P3–5499; Commonwealth of Australia: Canberra, ACT, Australia, 2009; ISBN 174186-940-4. [Google Scholar]
- Tomar, D.; Agarwal, S. A survey on Data Mining approaches for Healthcare. Int. J. Bio-Sci. Bio-Technol. 2013, 5, 241–266. [Google Scholar] [CrossRef]
- Durairaj, M.; Ranjani, V. Data mining applications in healthcare sector: A study. Int. J. Sci. Technol. Res. 2013, 2, 29–35. [Google Scholar]
- Elbattah, M.; Molloy, O. Data-Driven patient segmentation using K-Means clustering: The case of hip fracture care in Ireland. In Proceedings of the Australasian Computer Science Week Multiconference, Geelong, VIC, Australia, 30 January–3 February 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Pellicer-Valero, O.J.; Fernández-de-las-Peñas, C.; Martín-Guerrero, J.D.; Navarro-Pardo, E.; Cigarán-Méndez, M.I.; Florencio, L.L. Patient profiling based on spectral clustering for an enhanced classification of patients with tension-type headache. Appl. Sci. 2020, 10, 9109. [Google Scholar] [CrossRef]
- Fernández-Llatas, C.; Meneu, T.; Benedi, J.M.; Traver, V. Activity-based process mining for clinical pathways computer aided design. In Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology, Buenos Aires, Argentina, 31 August–4 September 2010; IEEE: New York, NY, USA, 2010; pp. 6178–6181. [Google Scholar]
- Jhang, K.M.; Chang, M.C.; Lo, T.Y.; Lin, C.W.; Wang, W.F.; Wu, H.H. Using the Apriori algorithm to classify the care needs of patients with different types of dementia. Patient Prefer. Adherence 2019, 13, 1899–1912. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, W.B. Apply the Data Mining Technology of Apriori Association Rule Algorithm to Mine E-Commerce Potential Customers. Ph.D. Thesis, Zhejiang University of Technology, Zhejiang, China, 2012. [Google Scholar]
- Xie, H. Research and case analysis of apriori algorithm based on mining frequent item-sets. Open J. Soc. Sci. 2021, 9, 458. [Google Scholar] [CrossRef]
- Wang, D. Research and Implementation of Apriori Algorithm for Association Rules Based on Cloud Computing. Ph.D. Thesis, Nanchang University, Nanchang, China, 2010. [Google Scholar]
- Schindelin, J.; Rueden, C.T.; Hiner, M.C.; Eliceiri, K.W. The ImageJ ecosystem: An open platform for biomedical image analysis. Mol. Reprod. Dev. 2015, 82, 518–529. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Singhal, S.; Jena, M. A study on WEKA tool for data preprocessing, classification and clustering. Int. J. Innov. Technol. Explor. Eng. IJItee 2013, 2, 250–253. [Google Scholar]
- Lan, K.; Wang, D.; Fong, S.; Liu, L.; Wong, K.K.L.; Dey, N. A Survey of Data Mining and Deep Learning in Bioinformatics. J. Med. Syst. 2018, 42, 139. [Google Scholar] [CrossRef] [PubMed]
- Varlamis, I.; Apostolakis, I.; Sifaki-Pistolla, D.; Dey, N.; Georgoulias, V.; Lionis, C. Application of data mining techniques and data analysis methods to measure cancer morbidity and mortality data in a regional cancer registry: The case of the island of Crete, Greece. Comput. Methods Programs Biomed. 2017, 145, 73–83. [Google Scholar] [CrossRef] [PubMed]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases (VLDB), Santiago, Chile, 12–15 September 1994; Volume 1215, pp. 487–499. [Google Scholar]
- Li, Q.; Zhang, Y.; Kang, H.; Xin, Y.; Shi, C. Mining association rules between stroke risk factors based on the Apriori algorithm. Technol. Health Care 2017, 25, 197–205. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hasim, N.; Haris, N.A. A study of open-source data mining tools for forecasting. In Proceedings of the 9th International Conference on Ubiquitous Information Management and Communication, Bali, Indonesia, 8–10 January 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Sarwar Kamal, M.; Dey, N.; Ashour, A.S. Large scale medical data mining for accurate diagnosis: A blueprint. In Handbook of Large-Scale Distributed Computing in Smart Healthcare; Springer: Cham, Switzerland, 2017; pp. 157–176. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sr. # | Abbreviation | Description |
|---|---|---|
| 1 | BRHF | Books Reading in Hard Form |
| 2 | WM | Watching Movies |
| 3 | PGW | Playing Games on Work Station |
| 4 | BRSF | Books Reading in Soft Form |
| 5 | PGM | Playing Games on Mobile |
| Sr. # | Hobby | Count |
|---|---|---|
| 1 | PGW | 70 |
| 2 | PGM | 10 |
| 3 | PGM, PGW | 5 |
| 4 | BRHF, PGW | 35 |
| 5 | BRHF | 240 |
| 6 | BRHF, PGM | 5 |
| 7 | BRHF, PGM, PGW | 5 |
| 8 | BRHF, WM | 105 |
| 9 | BRHF, WM, PGW | 10 |
| 10 | BRHF, WM, PGM | 15 |
| 11 | BRHF, WM, PGM, PGW | 5 |
| 12 | BRSF | 60 |
| 13 | BRSF, PGW | 20 |
| 14 | BRSF, PGM | 5 |
| 15 | BRSF, PGM, PGW | 10 |
| 16 | BRSF, BRHF | 40 |
| 17 | BRSF, BRHF, PGW | 15 |
| 18 | BRSF, BRHF, PGM | 15 |
| 19 | BRSF, BRHF, PGM, PGW | 35 |
| 20 | BRSF, BRHF, WM | 55 |
| 21 | BRSF, BRHF, WM, PGM | 5 |
| 22 | BRSF, BRHF, WM, PGM, PGW | 25 |
| 23 | BRSF, WM | 25 |
| 24 | BRSF, WM, PGW | 10 |
| 25 | BRSF, WM, PGM | 20 |
| 26 | WM | 130 |
| 27 | WM, PGW | 30 |
| 28 | WM, PGM | 20 |
| 29 | WM, PGM, PGW | 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gulzar, K.; Ayoob Memon, M.; Mohsin, S.M.; Aslam, S.; Akber, S.M.A.; Nadeem, M.A. An Efficient Healthcare Data Mining Approach Using Apriori Algorithm: A Case Study of Eye Disorders in Young Adults. Information 2023, 14, 203. https://doi.org/10.3390/info14040203
Gulzar K, Ayoob Memon M, Mohsin SM, Aslam S, Akber SMA, Nadeem MA. An Efficient Healthcare Data Mining Approach Using Apriori Algorithm: A Case Study of Eye Disorders in Young Adults. Information. 2023; 14(4):203. https://doi.org/10.3390/info14040203
Chicago/Turabian StyleGulzar, Kanza, Muhammad Ayoob Memon, Syed Muhammad Mohsin, Sheraz Aslam, Syed Muhammad Abrar Akber, and Muhammad Asghar Nadeem. 2023. "An Efficient Healthcare Data Mining Approach Using Apriori Algorithm: A Case Study of Eye Disorders in Young Adults" Information 14, no. 4: 203. https://doi.org/10.3390/info14040203
APA StyleGulzar, K., Ayoob Memon, M., Mohsin, S. M., Aslam, S., Akber, S. M. A., & Nadeem, M. A. (2023). An Efficient Healthcare Data Mining Approach Using Apriori Algorithm: A Case Study of Eye Disorders in Young Adults. Information, 14(4), 203. https://doi.org/10.3390/info14040203