1. Introduction
Agriculture is an area of major importance for Bulgaria. Opportunities are being searched for the efficient use of fresh water, optimum use of chemicals and pesticides, and the maintenance and increase in yields in changing climatic conditions. The national strategy for the development of AI by 2030 gives a significant place to smart agriculture. In addition, a national research program called “Smart crop production” has been adopted as part of this strategy. One of the tasks of the program is to develop a pilot vertical IoT infrastructure for smart agriculture in the Plovdiv region, collecting data from this infrastructure in a regional data center, from where it can be used for analysis and prevention. The choice of Plovdiv is not a coincidence—Plovdiv is located in the Thracian Valley and is one of the most fertile regions in Bulgaria.
In conjunction with the above-mentioned national program, an environment for smart crop production called ZEMELA [
1] is being developed. It has been created as a cyber-physical social space and is a reference architecture of the virtual physical space (ViPS) [
2,
3] developed by a team of the DeLC Laboratory at the Faculty of Mathematics and Informatics of the University of Plovdiv.
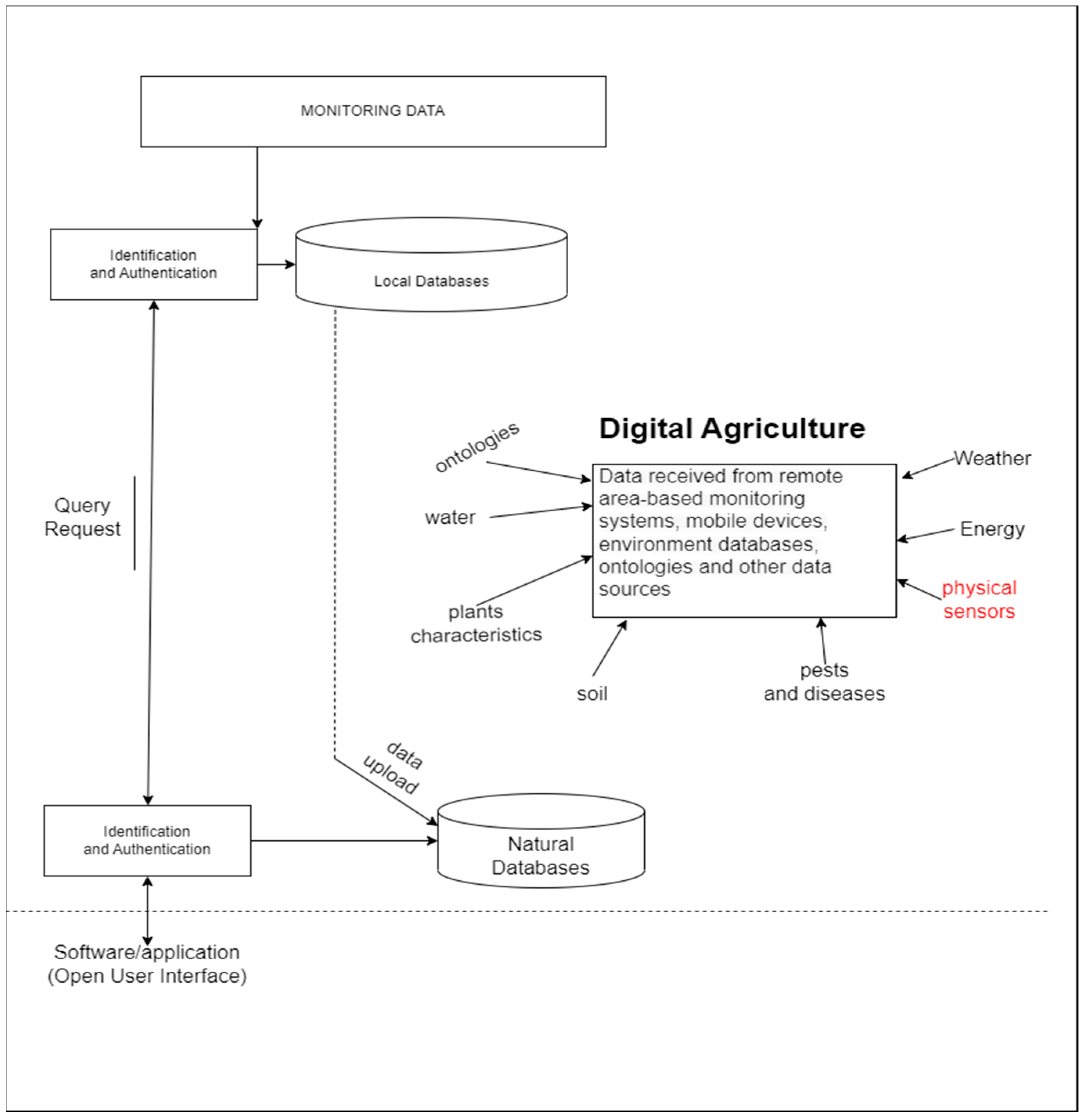
The aim of the platform is to serve farmers when growing different agricultural crops. One of its main components is personal assistants [
4]. The architecture of the personal assistants is built as a multi-agent system consisting of one interface agent and multiple operational agents. Typically, the actions of the interface agent are reminders, warnings, advice, etc. To fulfill their objectives, the personal assistants use information that is collected from crop fields and background knowledge about the development and characteristics of the monitored crops.
Another key part of the ZEMELA platform is the event engine (EE). It has the main task of monitoring the occurrence of different crop events and informing the personal assistants of their appearance. For this purpose, the EE uses knowledge about the physiological development of plants and knowledge about the environment of agricultural crops [
5]. This information is stored in the ADC (Agriculture Data Center), which is another core component of the ZEMELA platform [
6].
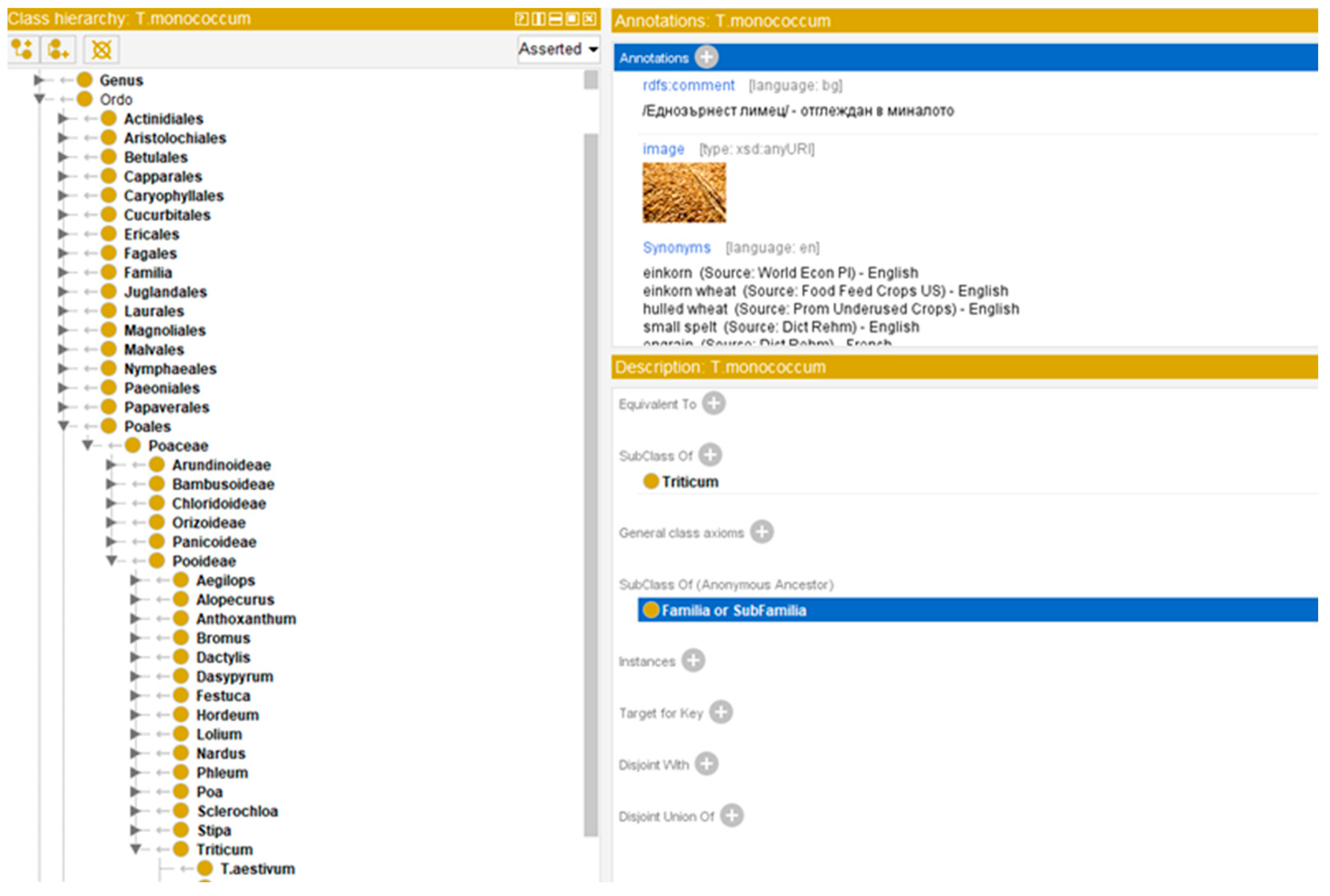
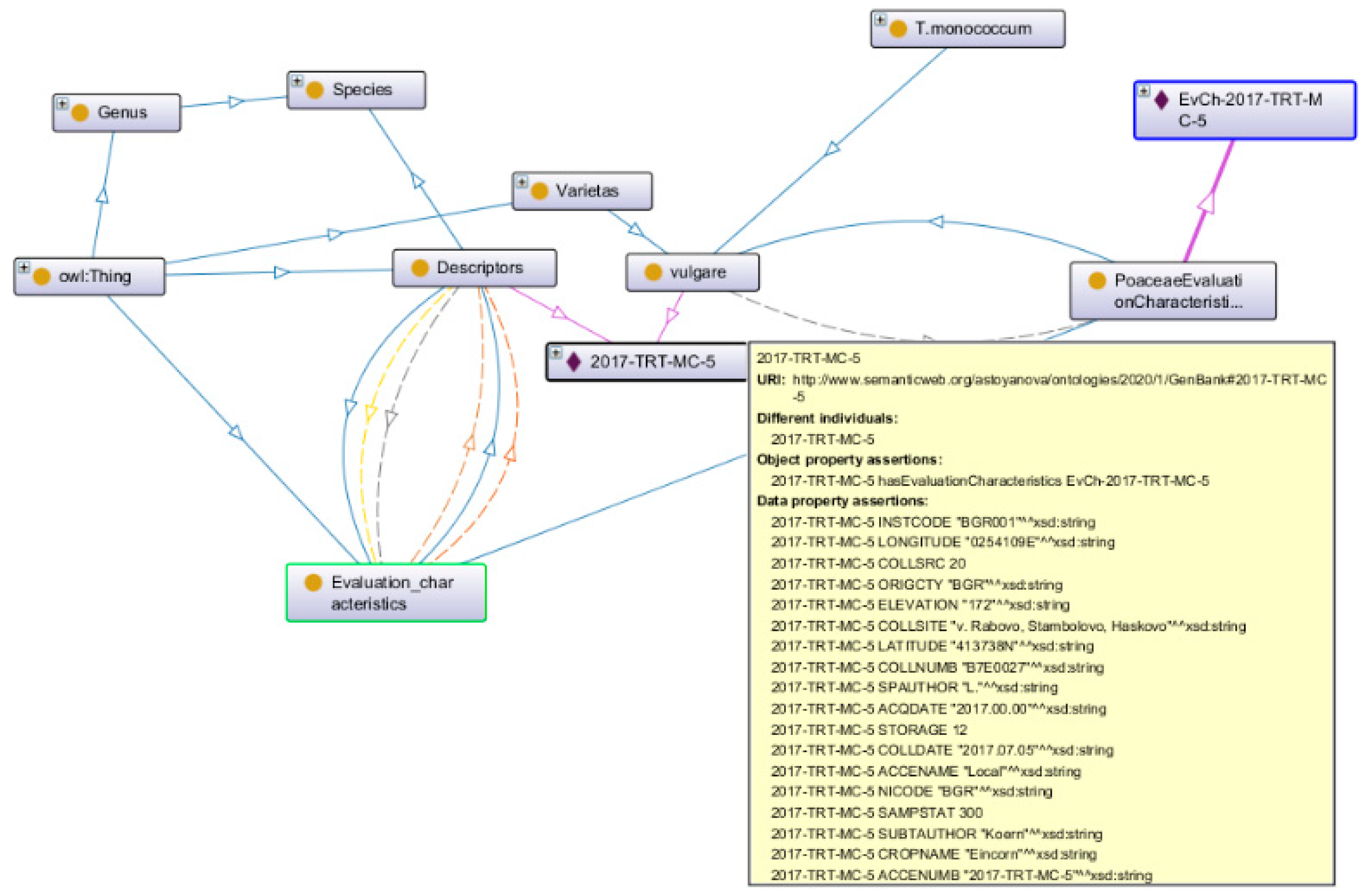
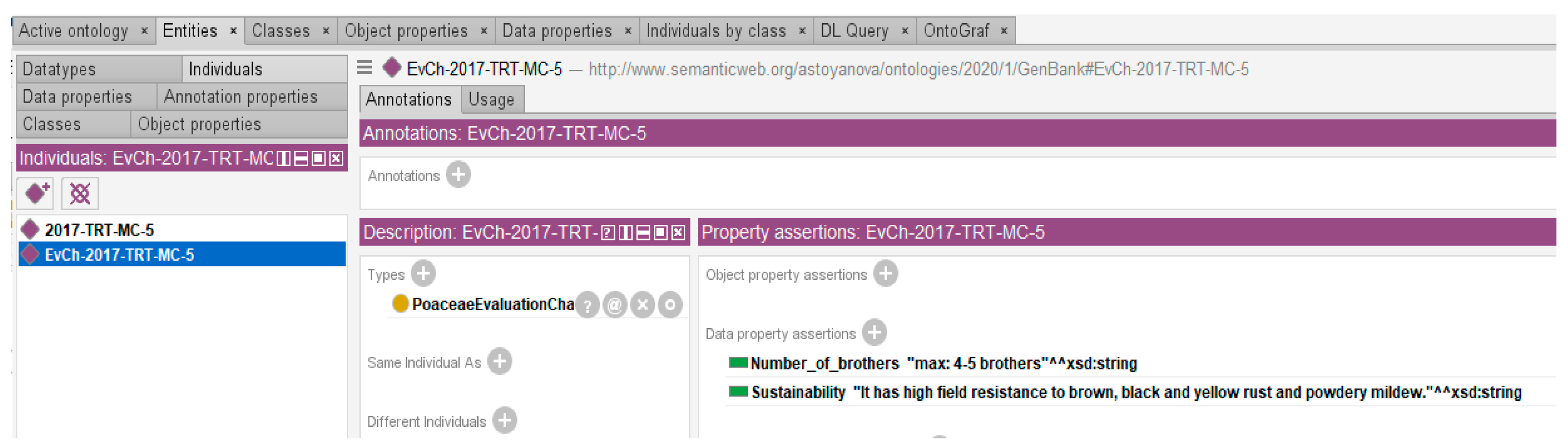
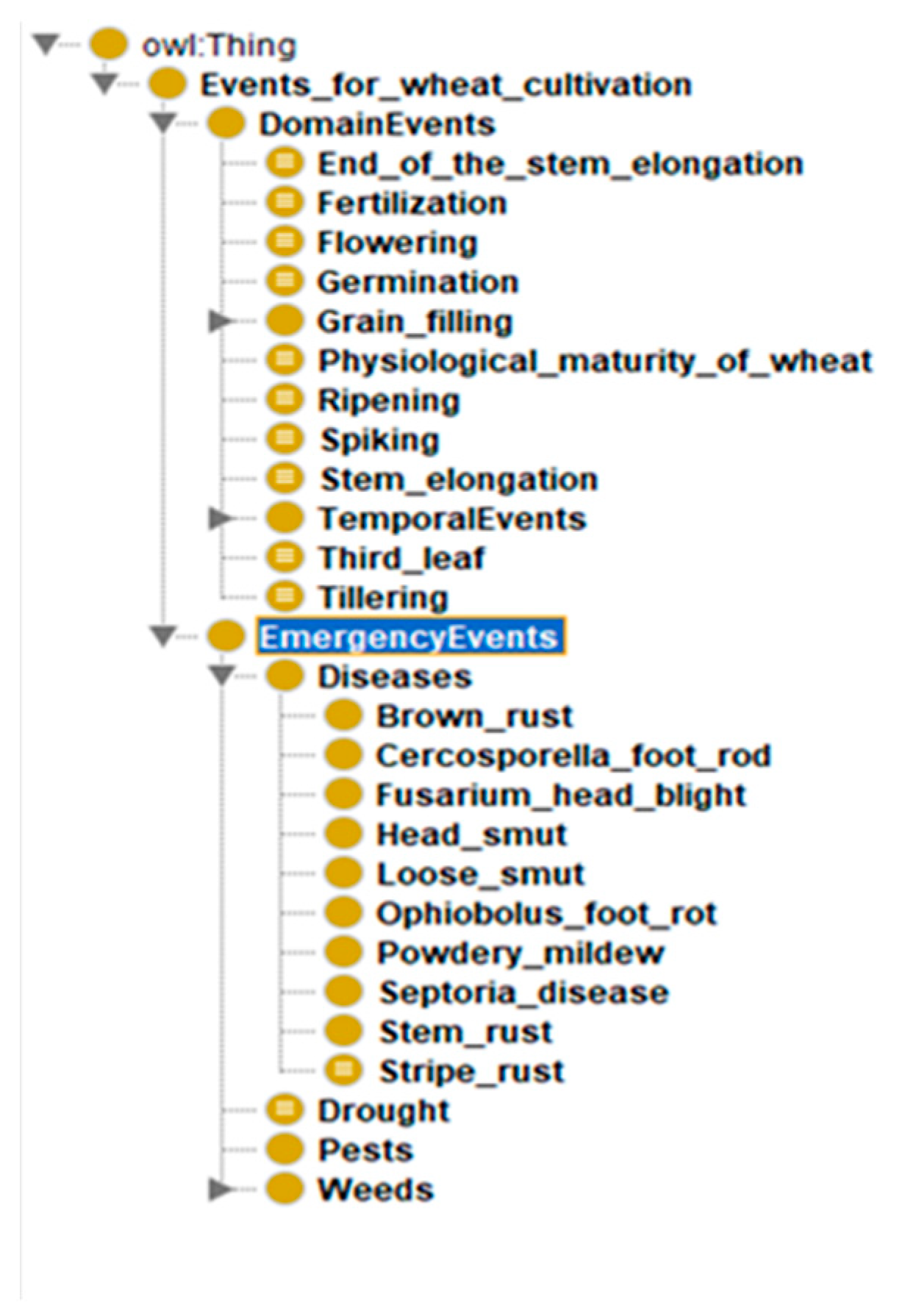
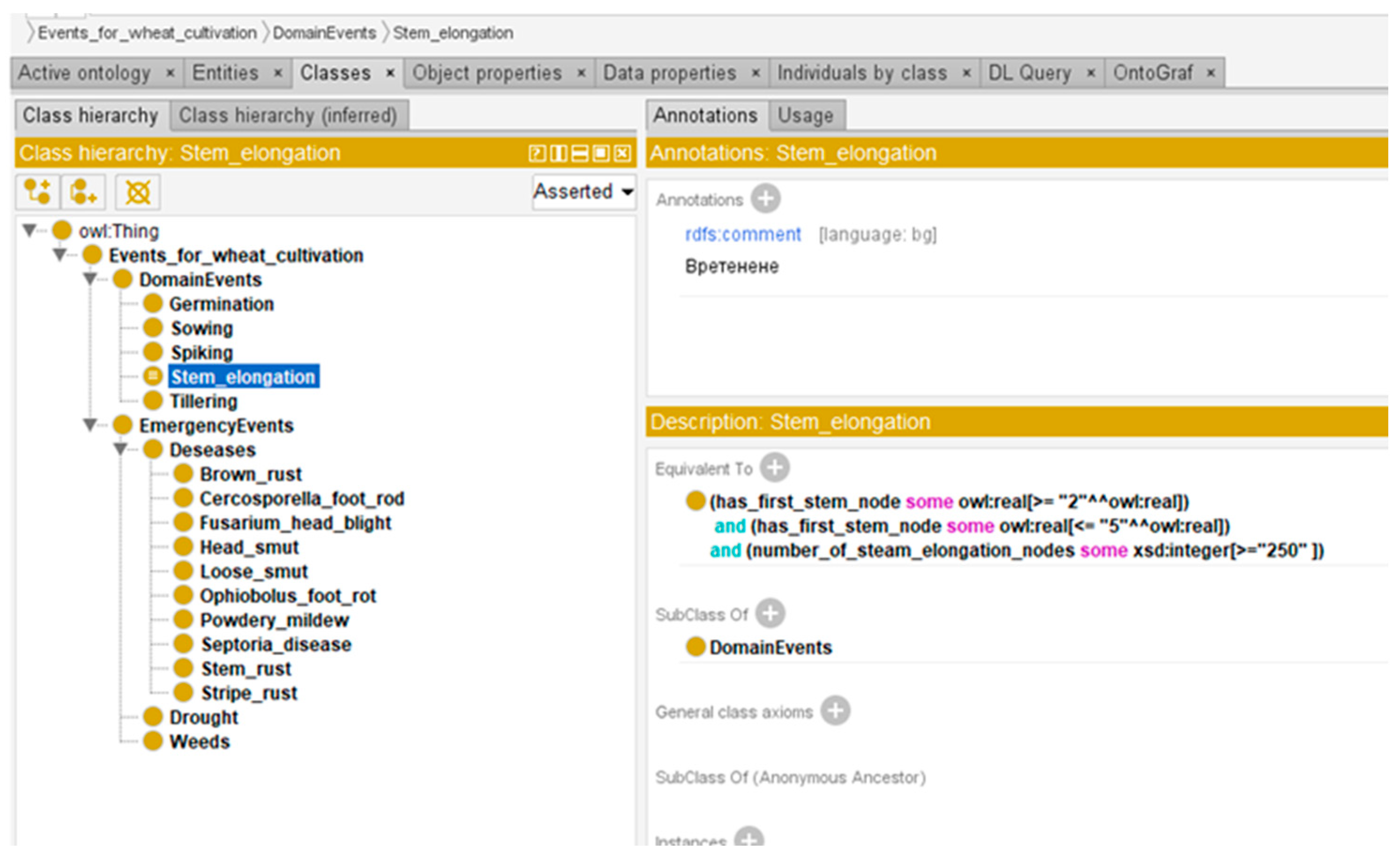
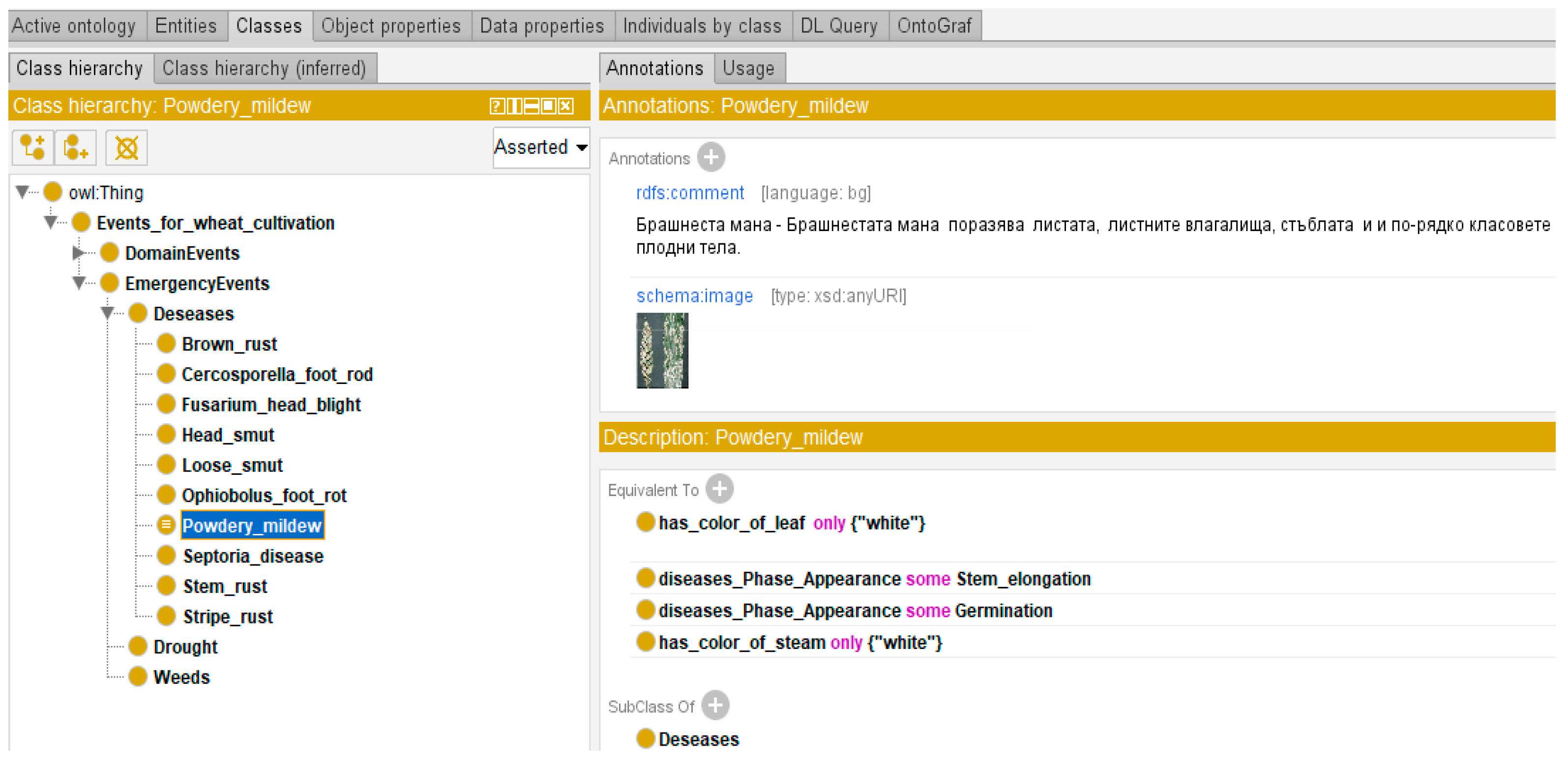
The implementation of the ZEMELA platform includes the development of a number of regional data centers in different areas of the country to collect data on crop cultivation, development, and environment. Based on this data, analyses and prevention are conducted for each crop in each of the districts. One of the regional data centers is in the Plovdiv region, the implementation of which is presented in this paper. The building of this center includes the development of the architecture, the infrastructure of the center, and data architecture. The detailed realization of one of the local pieces of infrastructure, implemented in the Institute of Plant Genetic Resources in the town of Sadovo in the Plovdiv region is presented, including the different types of sensors and types of data collected in the center when growing winter wheat. The architecture of the regional data center is also discussed as well as the data repositories where dynamic and background knowledge is stored. Dynamic knowledge includes the data that are collected based on the different IoT nodes deployed in the crop fields. Their storage is in relational and non-relational databases. Background knowledge is persistent knowledge about crop cultivation stored in ontologies. In this paper, special attention is paid to background knowledge and ontologies developed for winter wheat cultivation.
The proposed architecture of the regional data center and the architecture of the data stored in it are compatible with the development of the ZEMELA smart agriculture platform. The data center is an important part of the architecture of this platform and contributes to its transformation into a cyber-physical social space by storing and processing data obtained from different sensors and devices in a real environment. The regional data center also provides personal assistants in ZEMELA with background domain knowledge, developed in the form of ontologies.
The main advantage of the proposed architecture of the regional data center is that it offers storage not only of raw data from real environments, but also data that are used as background knowledge in the field, in the form of ontologies, used by the personal assistants of the ZEMELA platform. Another benefit is the project to develop cheaper sensors whose data can be matched against reference statistics. This would reduce costs for farmers who wish to use the platform. The processing of the sensor raw data is performed at a low level by developed software adapters. They provide the processed data in a format that is usable by the intelligent components.
3. Related Works
This section of the paper provides a literature review of studies in two main parts. The first part focuses on research by teams that have built IoT infrastructure for smart agriculture. The second part looks at studies that have combined IoT infrastructure with artificial intelligence. These studies were selected because the regional data center in the Plovdiv region focuses on developing IoT infrastructure for smart agriculture, and it is also part of the ZEMELA smart agriculture platform which uses intelligent components.
In recent years, numerous pieces of research and practical developments have been made to create IoT vertical infrastructures for smart agriculture. Various publications address more global issues of building IoT vertical infrastructure for smart agriculture and they offer more private solutions. The Internet of Things integrates several existing technologies, such as wireless sensor networks, radio-frequency identification, cloud computing, middleware systems, and end-user applications. In [
7], several advantages and challenges of IoT are identified. The authors present an IoT ecosystem and how the combination of IoT and DA enables smart agriculture. In addition, future trends and opportunities are presented which are categorized into technological innovations, application scenarios, business, and marketability. In [
8], a comprehensive review of emerging technologies for Internet of Things (IoT)-based smart agriculture is introduced. Unmanned aerial vehicles, wireless technologies, open-source IoT platforms, software-defined networking (SDN), network function virtualization (NFV) technologies, cloud/fog computing, and middleware platforms are referred to as emergent technologies for the agricultural IoT. A classification of IoT applications for smart agriculture is also provided, including smart monitoring, smart water management, agrochemical applications, disease management, smart harvesting, supply chain management, and smart agricultural practices.
An essential feature of modern agriculture is the integration of artificial intelligence with Internet of Things systems. In [
9], an intelligent IoT system for smart agriculture is presented based on the concept of front–rear-end separation and the framework of the Model-View-ViewModel. With the help of this system, it is possible to handle complex business logic and integrate intelligent components relatively easily. The system consists of a remote data service platform, data collection terminals, and wireless data transmission using narrow-band Internet of Things (NB-IoT) modules. An algorithm for deep-learning-based plant disease and pest detection is also implemented in the system. Furthermore, the system has a convenient expansion interface and can be used as a basic development platform for various agricultural IoT applications, such as a soil environmental monitoring system or an intelligent disease and pest monitoring system. In [
10], a novel, scalable and private geo-distance evaluation system is presented. The system provides geographic-based services by computing the distances between sensors and farms privately. The key idea is to perform efficient distance measurement and distance comparison on encrypted locations over a sphere, by leveraging a homomorphic cryptosystem. Through extensive experiments with real datasets, the authors show that the system achieves private distance evaluation on a large network of farms. Furthermore, the application of mobile devices in agriculture IoT applications is demonstrated. In [
11], the problem of the efficient path planning of robotic swarms is addressed, formulating it as a specific type of vehicle routing problem. Various state-of-the-art algorithms are employed to solve this problem in order to decide on the best approach for different agricultural topologies, tasks, and the number of robots available. An end-to-end system is proposed and evaluated, using the Internet/Web as an infrastructure and communication medium, taking GPS input data from map providers, identifying and applying the most suitable algorithm for the specific landscape and task, and finally producing GPS coordinates as routes for the robots to follow. Recommendations for further improvements are discussed such as exploring the factors that influence the willingness of users of smart agricultural Internet of Things to conduct information security measures; help the government, agricultural organizations, or related organizations to take effective measures; provide targeted information security education and training; and help to train users. The awareness of information security precautions promotes a willingness to adopt information security behaviors among users of the smart agricultural Internet of Things.
Many software developments offer a combination of IoT, ontologies, and services. For example, in [
12], the authors describe an ontology-based architecture that can be used for precision agriculture applications. There are different structures that work together; these structures have their own sensors and triggers and can function according to their role in the field. In [
13], the authors consider a scalable service-oriented architecture (ONTAgri) based on several groups of concepts. The two main groups are domain ontology and system ontology. Domain is further divided into services and basic parts of agriculture, e.g., irrigation, fertilization, etc. In [
14], the authors propose the AgriOnt framework that can be used for smart agriculture. It has four domains: a geographic ontology, a business subdomain, an IoT-based subdomain, and an agriculture-based subdomain.
The considered developments for smart agriculture that combine IoT and artificial intelligence are mainly based on data collected from IoT nodes deployed in monitored sites and services, or from IoT nodes, ontologies, and services that provide different functionalities in the field of agriculture. Inferences are made using various intelligent machine-learning algorithms. Although it is difficult to form a clear picture of the implementation of these systems from the exposition in the reference works, it can be inferred that our proposed architecture of a regional data center stores crop development data obtained not only from IoT sensors but also data that are specific and basic to the area in which the crops are grown. This knowledge is implemented as ontologies that can be reused for other regions in Bulgaria. The data are processed at a low level in the data center architecture, to be made available in a form convenient for processing by intelligent agents in the ZEMELA platform. These intelligent agents make their inferences and conclusions about crop development based on a combination of data from the IoT nodes and background knowledge about the field in the ontologies.
The realization of sensor networks requires large investments from farmers. In our research, we have made a proposal to use cheaper sensors along with high-quality ones to serve as reference points as the synchronization of the data accuracy is completed automatically before being written to the data stores. Processing and adjustment of the raw data are conducted at a low level in the architecture, using software adapters developed for different sensor types or data packet types. The architecture of the regional data center developed in this way enables its integration into independent workflows, analyzing data in real time like the intelligent components or services.
5. The Local Level of the Infrastructure
Here, we will briefly present the current state of the sensor level. The first sensor network is being built for open wheat blocks on the territory of the Institute of Plant Genetic Resources in the town of Sadovo. The experimental setup consists of multiple sensors used to monitor soil, leaf wetness, and air properties. The sensors that we are using are given in
Table 1.
The ADCON EnviroPro 40 sensor estimates soil moisture with a resolution of 0.01% and an accuracy of ±2%; salinity (or electrical conductivity) with a resolution of 0.001 dS/m and an accuracy of ±5%; and temperature with a resolution of 0.01 °C and an accuracy of ±1 °C. The sensors are located at four levels—at a depth of 0 cm (soil surface), 10 cm, 20 cm, and 30 cm. The device performs precise and repeatable measurements; therefore, in our pilot setup, we use it as a reference device to validate other low-cost sensors such as the Seeed Studio 101990667. The Seeed Studio 101990667 sensor estimates soil temperature with an accuracy of ±0.5 °C and a resolution of 0.1 °C, a moisture accuracy of ±2%, and a resolution of 0.03% (below 50%) and 1% (above 50%). The measured electrical conductivity is within the range of 0~10,000 μs/cm, with an accuracy of ±3% and a resolution of 10 μs/cm. The sensor provides built-in functionality for temperature compensation in the range of 0–50 °C. The experimental setup contains two more sensors for the estimation of the leaf wetness: the reference one is ADCON WET Leaf Wetness and the low-cost sensor is Seeed Studio 314990738.
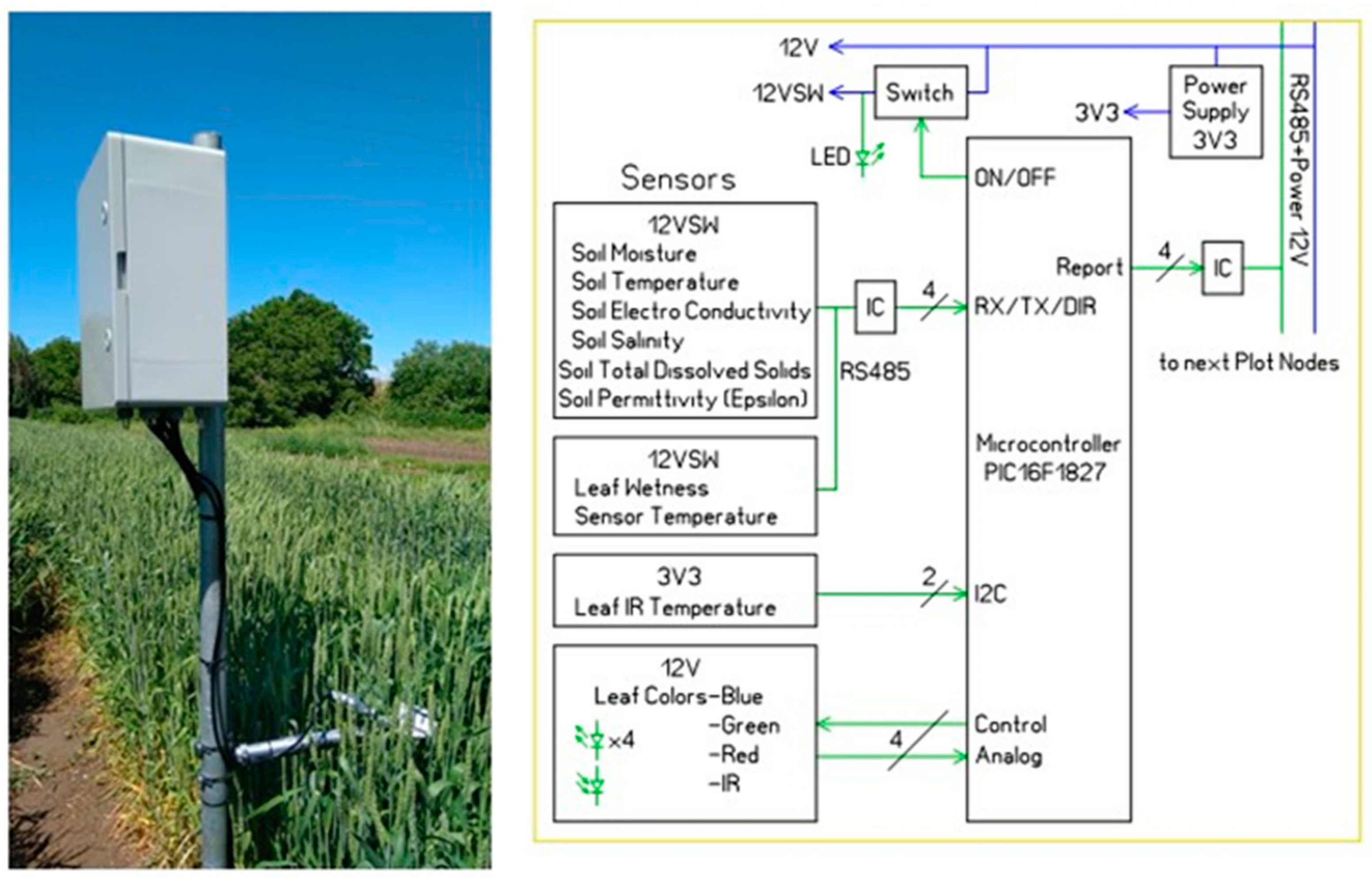
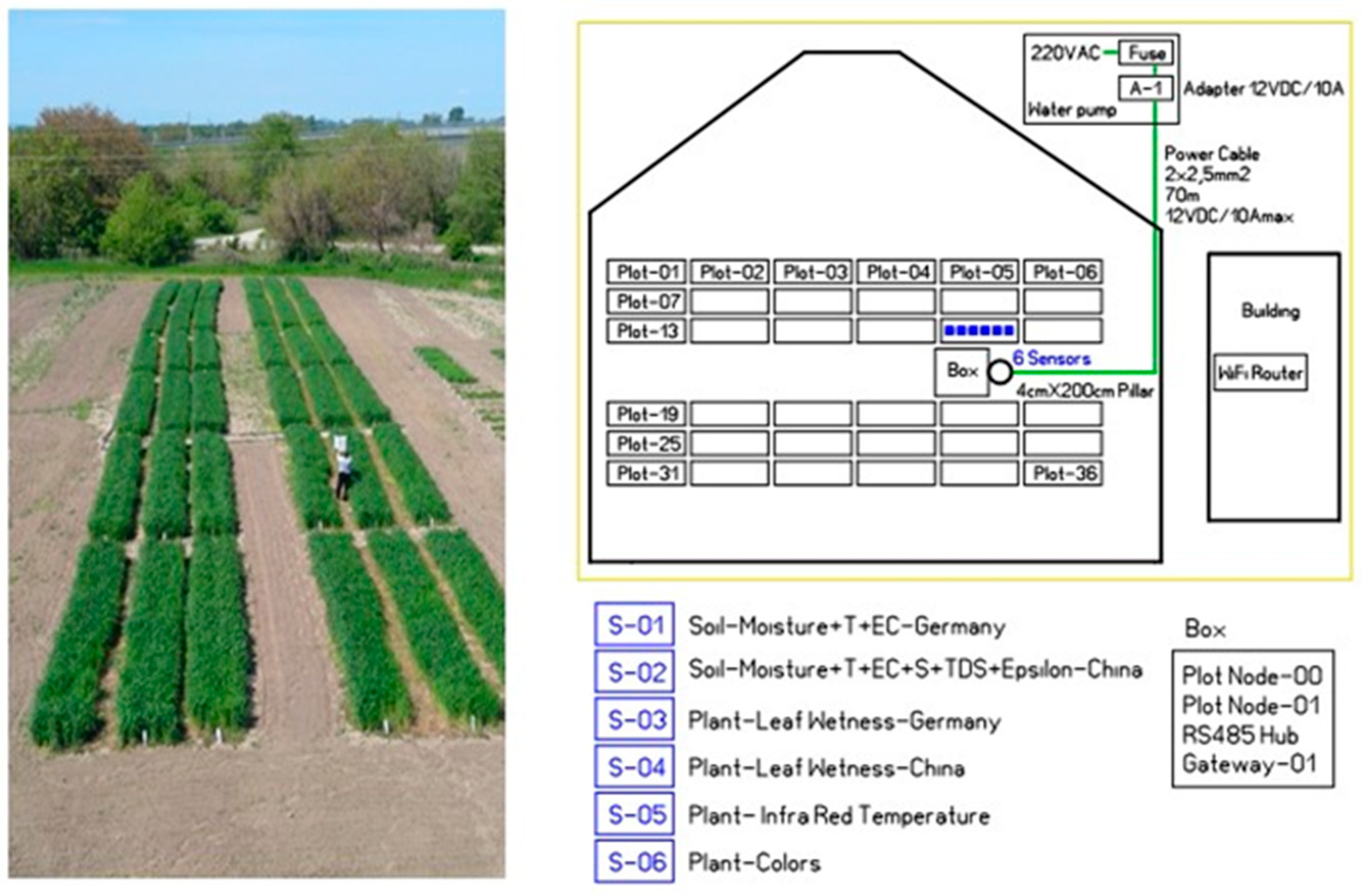
The sensors are installed in accordance with their requirements on a pillar into a field of crops in Sadovo, a small town near Plovdiv. The pillar consists of a portable metal tube where electronics, power supply, and communications are placed in a box and the sensor groups are attached on the side, as shown in the photograph in
Figure 4.
The flow chart of the electronics is schematically presented on the right side of the figure. There are several items controlled by a PIC processor, such as a 12 volts for a soil group that includes two devices, 12 volts for a leaf wetness group of two devices, two more sensor groups reserved for infrared temperature measurements, and an RGB/IR sensor to measure the leaf color to estimate nitrogen content.
The measurements are performed in a special study field of 36 lots of wheat. For the pilot measurements, we chose lot number 17, as shown in
Figure 5. Electricity is supplied via a cable to the pump room and the communication to the nearby building is wireless.
The current setup is operating until the harvest time and estimating the above-mentioned values every 30 min. The results in both raw data and graphics can be found on our data hub site, and they are publicly accessible [
19,
20].
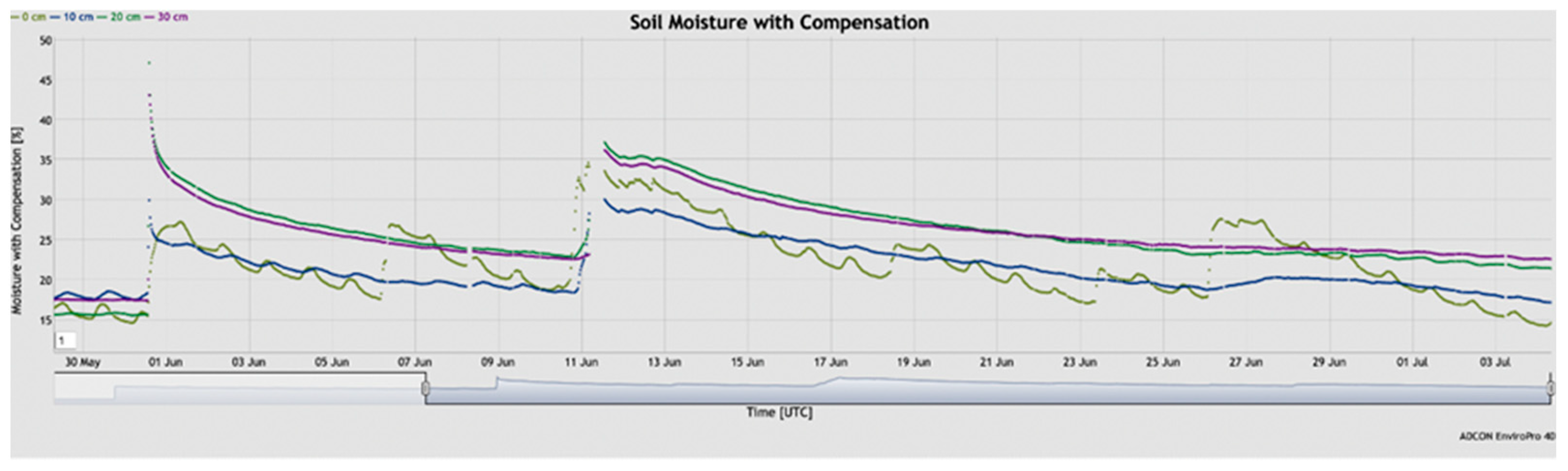
The soil moisture measurements within the interval from the end of May to the beginning of June 2022 are shown in
Figure 6. The color plots stand for the four soil depth levels: 0 cm or ground zero, 10 cm depth, 20 cm, and 30 cm. As expected, the highest moisture is observed in the top layer shortly after rainfall (20 and 31 May as well as 6 June). Later, due to the sun’s heat and strong evaporation, the zero-level moisture went down in a few days. However, water penetration in the soil in time and depth is a complex function, described by the second Fick’s law of diffusion [
21]. Furthermore, this data can be used for better the understanding, modeling, and prediction of when and with what amount the crops must be watered, depending on the depth of their root system.
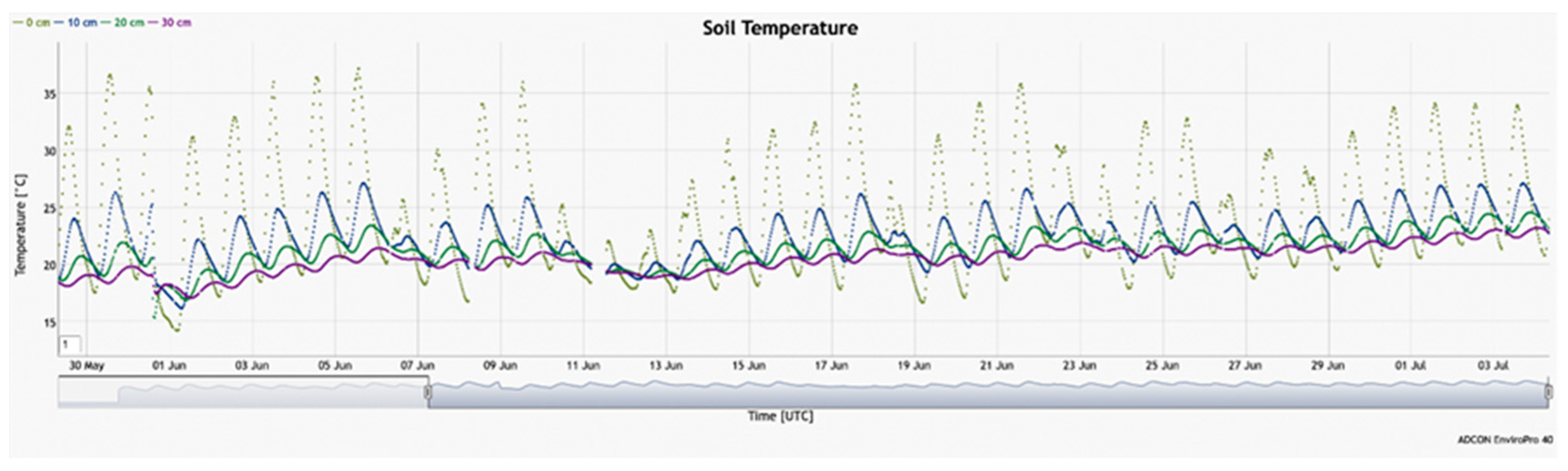
The next plot represents in-depth soil temperature measurements (
Figure 7). The data were taken simultaneously, as in the previous graph, and both are physically connected. The rainfall events mentioned above can also be seen here as a temperature drop observed at the ground-zero level.
With these preliminary results, we would like to validate our experimental setup and modeling assumptions and use them in production for the next season.
6. The Regional Data Center
The architecture of the regional data center includes two parts. The first one accomplishes communication to the local level to receive and store stream data arriving from the sensor networks. The second is a platform specializing in the delivery of various services to farmers, using different approaches to model agricultural scenarios. One such service is, for example, the tracking, identification, and localization of anomalies in the vegetation of agricultural crops. In this section, the first part is presented in more detail.
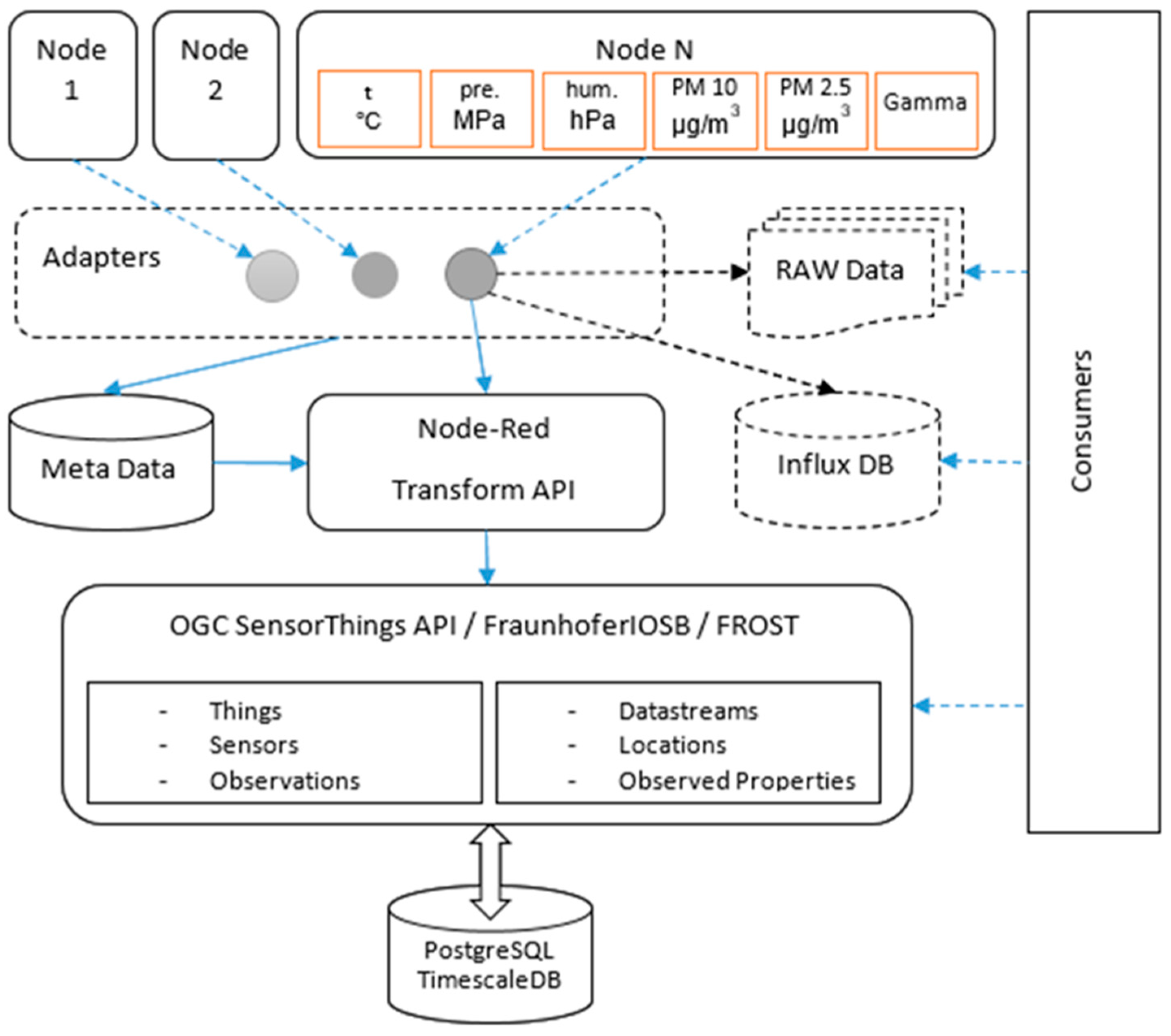
The regional data center has a layered architecture (
Figure 8). The first layer is made up of the physical sensor level presented in the article above (part 4—local level). In architecture, this layer is considered in the abstract as a combination of nodes and sensors. There are no restrictions on the number of nodes or the number and type of sensors that are included in them. The data generated by the sensors is accumulated by the nodes and transmitted at fixed intervals of time to the next layer—the adapters.
In order to minimize the data package, its structure is simplified as much as possible—a sequence of values separated by an interval. In addition to the data from the sensors, the package also includes information identifying the node itself, the exact time of transmission, and the type of sensors with which the respective measurements were made. An example data package looks like this:
Over time, the development of new components improves or changes due to alterations in the components and sensors used. Some components and sensors are discontinued, or their availability at suppliers is temporarily depleted, which requires their replacement with others that are not always close analogs. This inevitably leads to a change in the structure of the data packet. For this reason, the regional data center must be able to receive data from various types of nodes built with heterogeneous components and sensors. This problem is solved through the adapter layer. This layer contains a software component—an adapter, which receives the raw data packets from the nodes. A separate adapter is created for each type of node, or more precisely, for each type of data packet. Its purpose is to unify the raw data packet by eliminating the differences caused by the variation in the readings of the sensors used in the different nodes of the same entity.
Another role of the adapters is to correct the data from these nodes and sensors, which are known to give fixed deviations from the actual performance. They also identify and signal values that are outside the expected range. This helps in the early detection of defective nodes and components. The information about the expected limit values of the different types of sensors is maintained in the metadata database. It also stores the data needed to correct certain values from specific nodes.
As a security feature, the adapters register the raw data that they receive. Currently, this register is a different file rollover for each adapter. This register has several useful features:
It ensures that no data are lost in the event of a crash in the lower layers of the data center.
If necessary, it allows for analysis of the obtained data without superimposing the additional meaning of their transformation and adaptation.
It is possible to provide raw data directly to interested consumers.
In the future, the register will move to the use of a NoSQL database, which will ensure the storage of raw data and allow easier access to them.
The data unified by the adapters are then transmitted to the next layer, which is made up of two different systems with different purposes. One of them is the Influx Database, which directly stores unified data. This database is used by consumers that are interested in the current and average values over a period of time, e.g., visualization of changes in values of certain entities on a map or graphs (for example with Grafana).
The second system in this layer is designed to transform the unified data packet into a REST request, which is passed to the last layer that provides SensorThings API. The transformation is performed through Node-Red, a system that allows the visual construction of transforming logic by using nodes with predefined business logic. This makes it possible to reduce the effort associated with the implementation of this layer as well as facilitate maintenance when it is necessary to add new rules for new sensors and nodes.
The transforming logic also handles metadata that contain descriptions of specific nodes and sensors. From a unified data packet submitted by an adapter, the transform logic generates a set of REST requests to the SensorThings API, one for each entity. An example body of a REST request looks like this:
{
“result”: 132,
“resultTime”: “2021-12-08T14:52:32.000Z”, “phenomenonTime”: “2021-12-08T14:52:32.000Z”,
“Datastream”: {
“@iot.id”: “932”
}
}
The last layer is the implementation of the SensorThings API [
22]. This is a standard of the Open Geospatial Consortium, which “provides an open, geospatial-enabled and unified way to interconnect the Internet of Things (IoT) devices, data, and applications over the Web.” The FROST of the Fraunhofer Institut IOSB was selected for the implementation of this layer [
23].
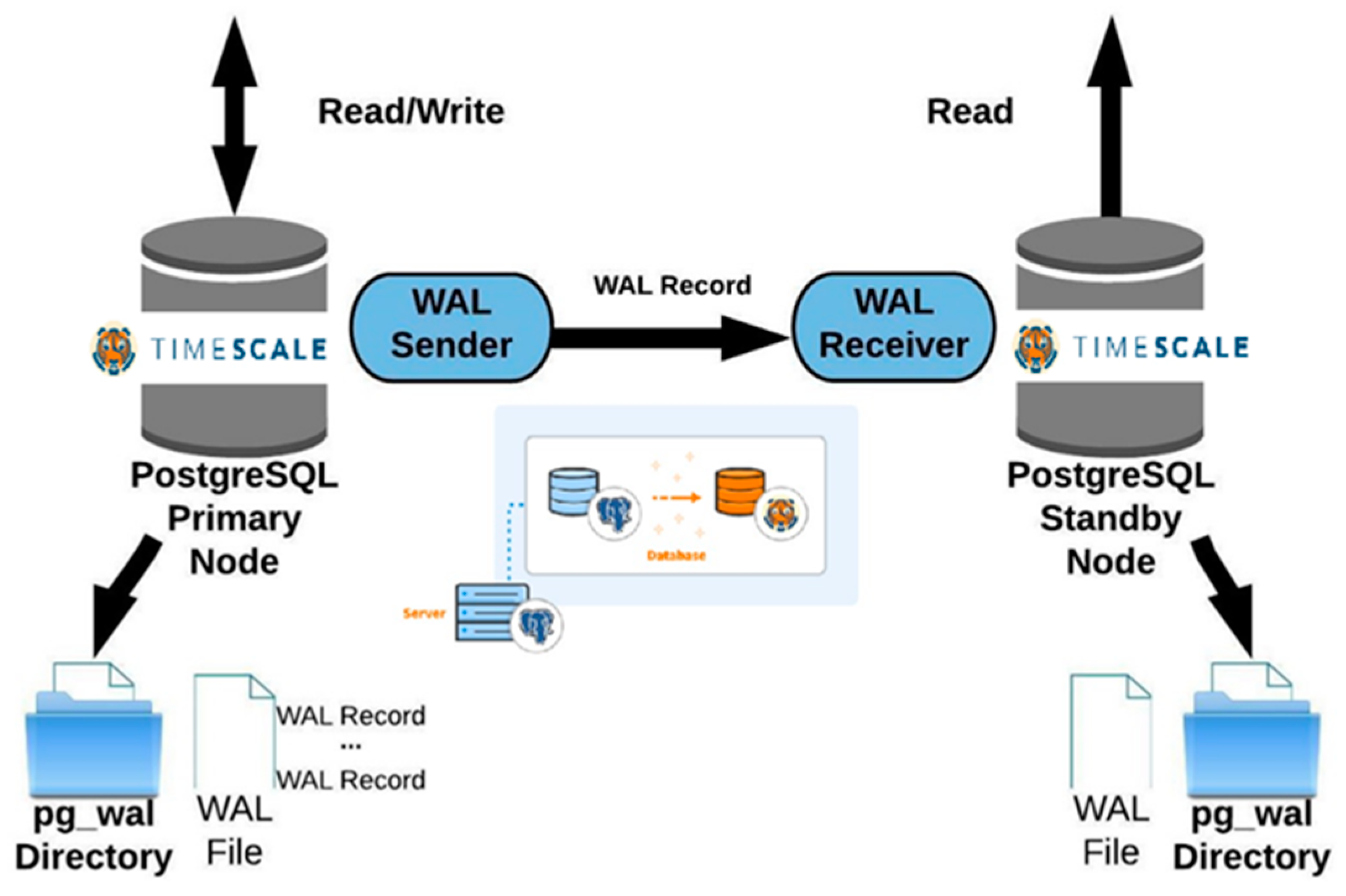
It provides a standard way to manage and retrieve observations and metadata from heterogeneous IoT sensor systems. The data are stored in a PostgreSQL database with a TimescaleDB extension. This significantly speeds up the recording and retrieval of data based on time intervals.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}