

Exploring Neural Dynamics in Source Code Processing Domain


Abstract
:1. Introduction
- A procedure for ranking neurons according to their ability in solving arbitrary binary classification tasks. With the experiments in this direction, we show how some neurons are able to autonomously build internal representations for different program properties.
- An information-theoretic approach for identifying neurons which exhibit interesting behaviours, with the aim to identify the most informative neurons in the network and to discriminate among neurons showing different activation patterns.
- A statistical measure for comparing the arbitrary binary tasks defined by single neurons (namely by simply establishing a threshold and by splitting the dataset according to the activation induced by each program instance) so as to identify neurons which recognize unique (or uncommon) concepts.
Related Work
2. Approach Description
- Binary classification experiments, for ranking neurons considering their ability in solving specific tasks.
- Analysis of the relevance of the neurons for the network itself, regardless of a given task.
- Pairwise comparison of the neurons’ dynamics, through the adoption of statistical techniques.
3. Experimental Settings
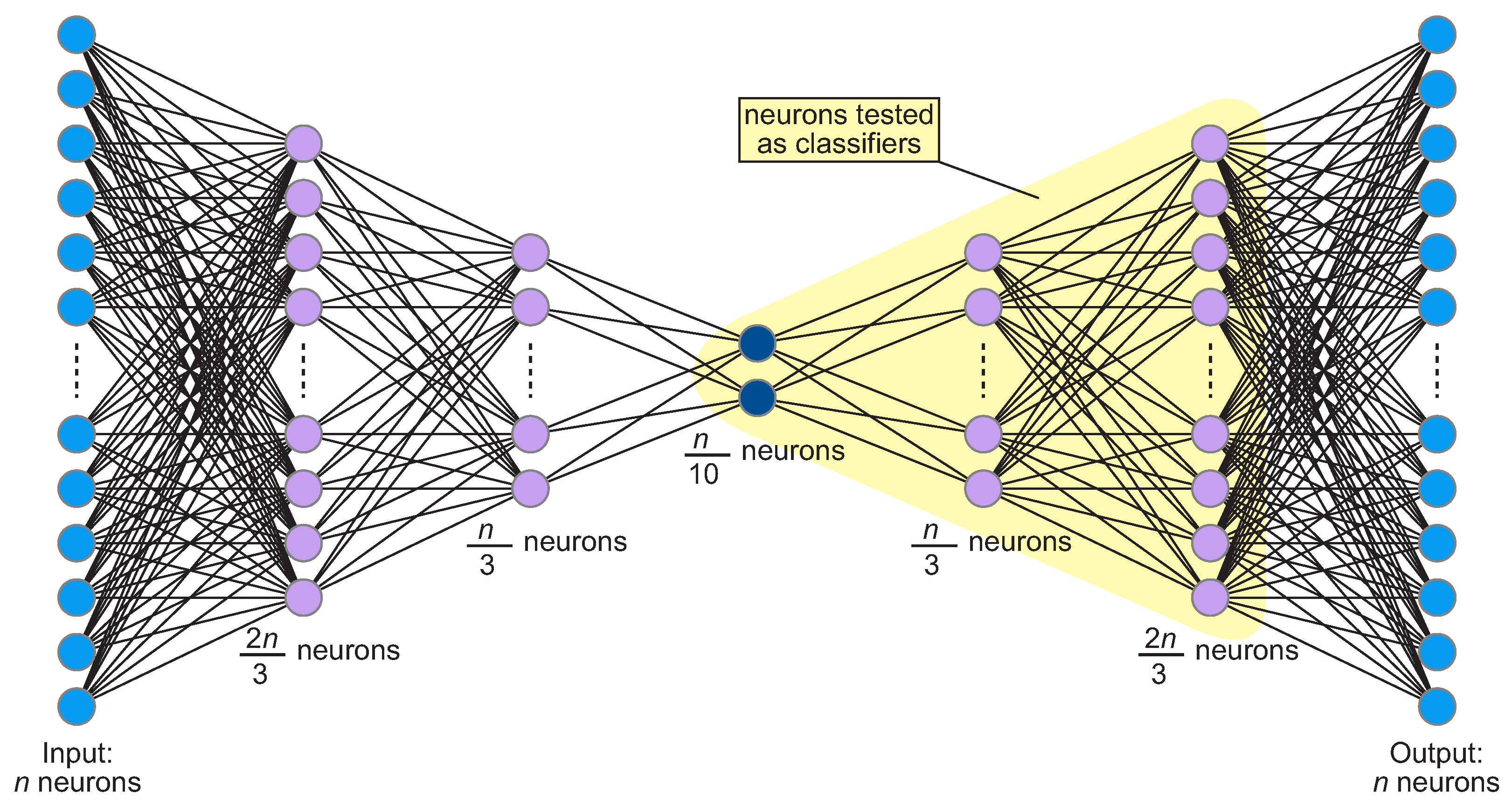
3.1. Network Architecture
3.2. Training
- A 300-dimensional embedding obtained by simply applying the doc2vec model [29] to the methods in the dataset using the gensim framework [30]. To avoid inconsistencies related to formatting choices, such as the presence or absence of spaces between operands and operators, keywords and parentheses, we applied the doc2vec model to a pretty printed version of the methods obtained by using the Javaparser library [31].
4. Experiments on Classification Tasks
4.1. Problems Definition
- The first one, designed using the control flow graph (CFG) [34], addresses the syntactical structure of a method in terms of its structural complexity.
- The second one relies on the method’s identifiers chosen by the programmers in order to target a task related to the functionality of a method.
- The third one is related to its I/O relationship, that is the relation between the input parameters and the returned object of a method.
- The last one is a random labeling strategy used as a baseline.
- Structural Labeling Policy
- Identifiers-Based Labeling Policy
- I/O-Based Labeling Policy
- 00:
- many to many
- 01:
- many to one
- 10:
- one to many
- 11:
- one to one
- Random Labeling Policy
4.2. Classification
| Algorithm 1 Algorithm for finding the best neuron in classifying programs on binary problems. The accuracy is computed by considering two balanced classes, each having at least 300 examples. | |
| 1: | ▹ accuracy of the best neuron |
| 2: for all neuron N do | |
| 3: activation values of N | |
| 4: activation thresholds | ▹ 10 evenly spaced thresholds between 0 and |
| 5: | ▹ best accuracy for N |
| 6: for all do | |
| 7: empty list | ▹ list of predictions |
| 8: for all do | |
| 9: if then | |
| 10: append 0 to | |
| 11: else | |
| 12: append 1 to | |
| 13: end if | |
| 14: end for | |
| 15: if accuracy() then | |
| 16: accuracy() | ▹ update best accuracy of N |
| 17: end if | |
| 18: end for | |
| 19: if then | |
| 20: | ▹ update best neuron |
| 21: | |
| 22: end if | |
| 23: end for | |
5. Scoring Neurons Independently of any Task
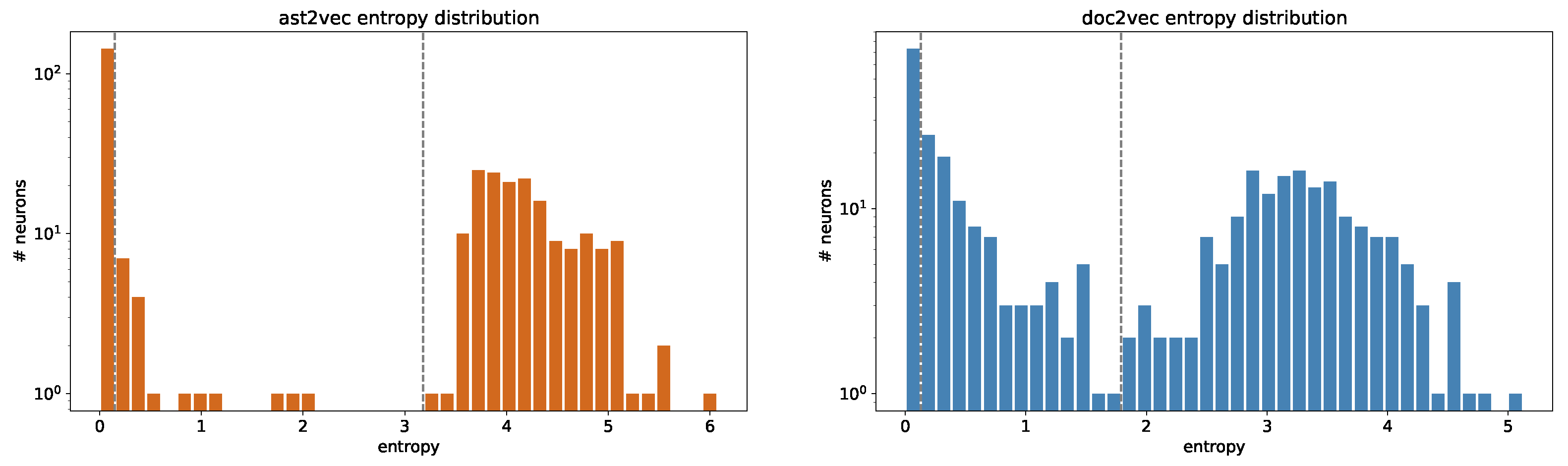
5.1. Entropy and Single Neurons
| Algorithm 2 Algorithm for computing the entropy of each neuron. |
|
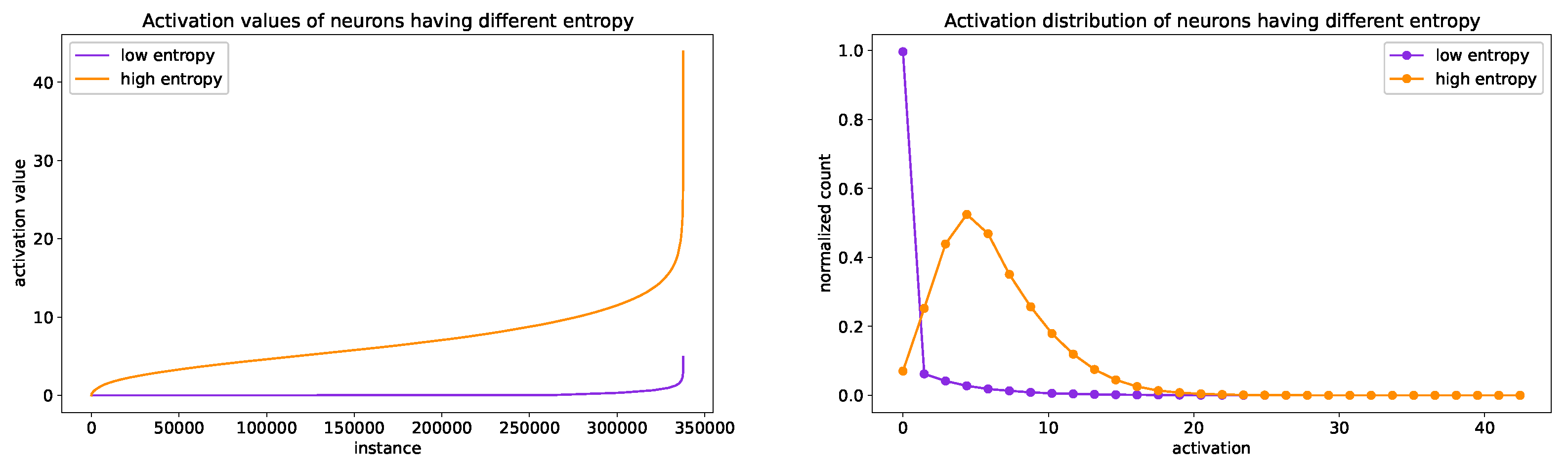
5.2. Pairwise Neuron Comparison
- Choose two neurons and , representing the neuron that defines the concept and the neuron to compare it to, respectively.
- Considering the neuron , for each program instance , compute the set of activation values and create the list , sorted according to .
- After splitting the sorted list L in three equally sized parts, generate the sets and by grouping the instances from the first and last of those parts, respectively.
- Select two equally sized random samples of instances from and and compute the corresponding two sets and of activation values for .
- Perform the Mann-Whitney U test on the sets of values and , with alternative hypothesis that the distribution underlying the first set is stochastically less than the distribution underlying the second one.
6. Results Discussion
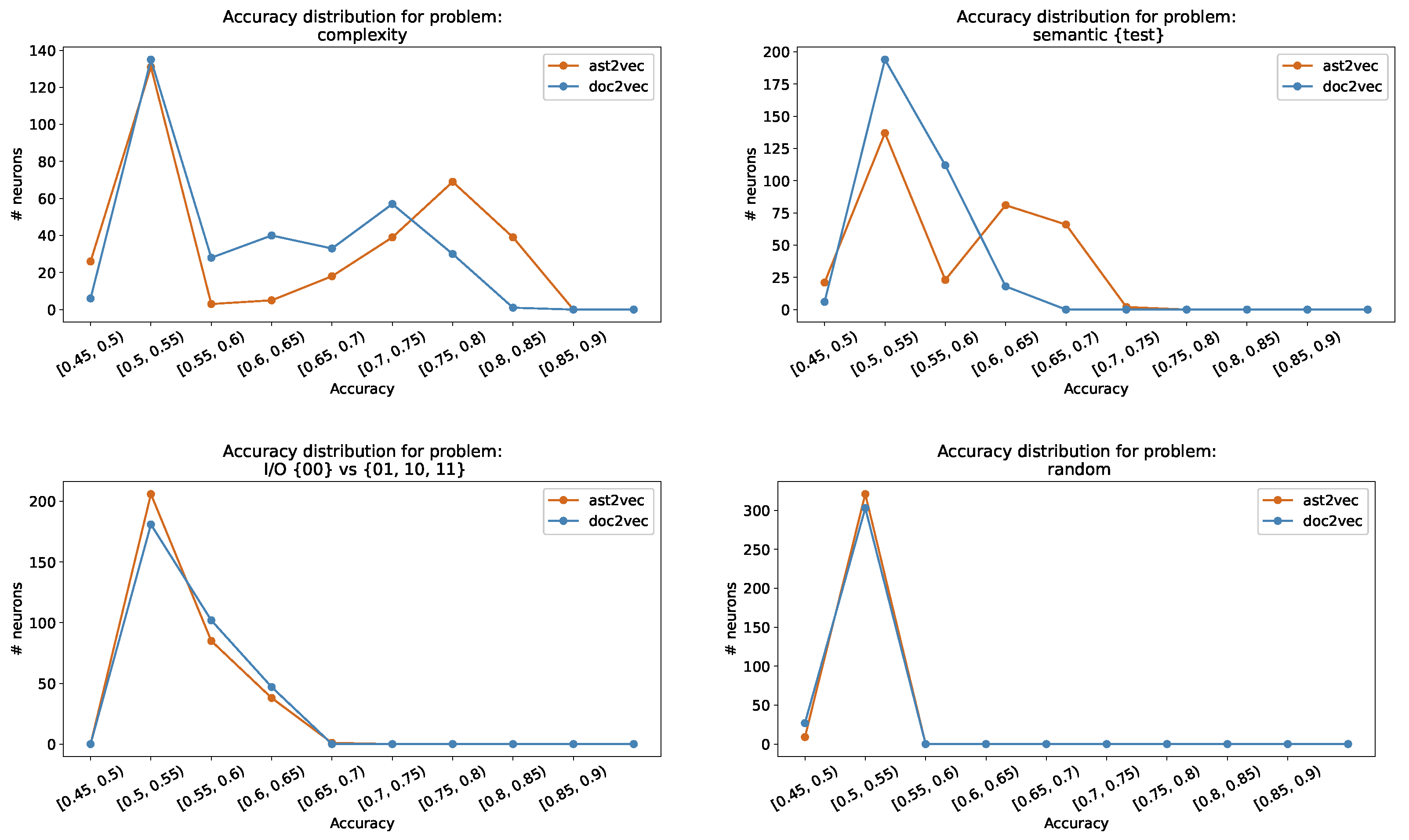
6.1. Task-Based Experiments
6.2. Task-Independent Experiments
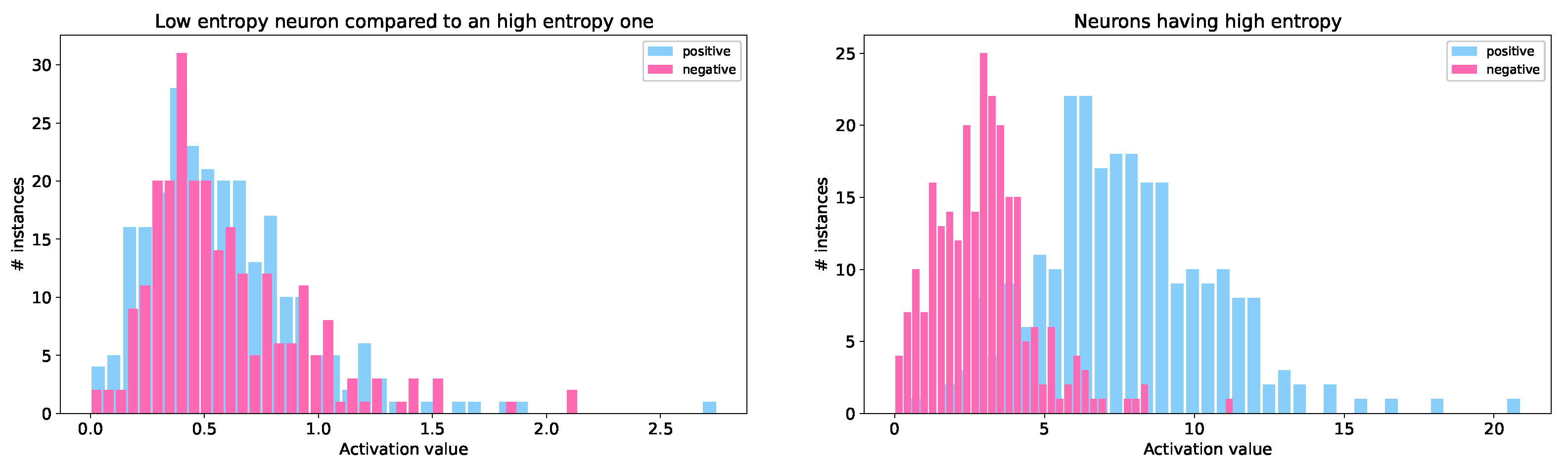
- A big number of neurons (notice that the figure is in a logarithmic scale) having an entropy equals or very close to 0. These neurons are of no interest in this context since they are neurons that (almost) never activate. They could only be used for pruning the network in order to optimize the architecture, but it is out of the focus of this work.
- Another big class of neurons having normally distributed high entropy values. Those neurons reach an high score since their activation values are distributed over a wide range. In addition, the probabilities of the occurring activation values to be in distinct intervals are relatively similar: this leads to an high score in terms of information theory.
- A smaller set of neurons whose values are higher than 0 but that are out of the normal distribution of the majority of the values. The corresponding activation values are those between the dashed bars plotted in Figure 3. As it will be clear by the discussion in Section 6, those neurons are peculiar since they produce an activation higher than 0 only for a significant amount of vectors (i.e., >10%), while in all the other cases their activation is equal to 0.
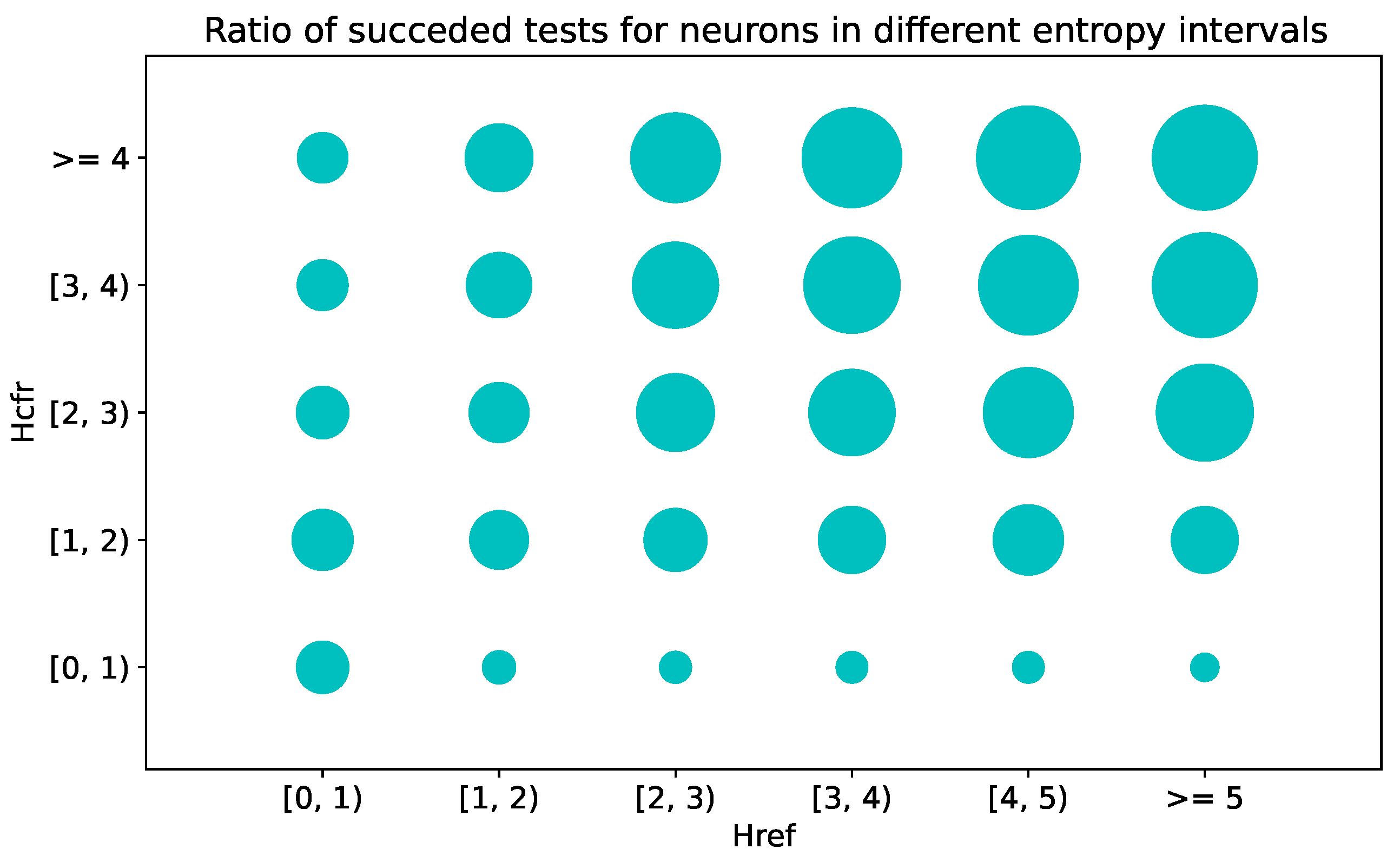
6.3. Pairwise Neuron Comparison Experiments
Putting Things Together
- Over the total 330 neurons, there are 39 under ast2vec embedding and only 1 for doc2vec,
- They all have entropy greater than 3.
- Some of the other neurons having high entropy perform badly on the task.
7. Conclusions and Further Directions
- Several internal neurons perform well on tasks related to syntactic properties of code, such as its cyclomatic complexity, a common software engineering metric.
- The two embeddings we used performed differently when considering different tasks.
- Neurons can be algorithmically selected based on the richness of their activation dynamics.
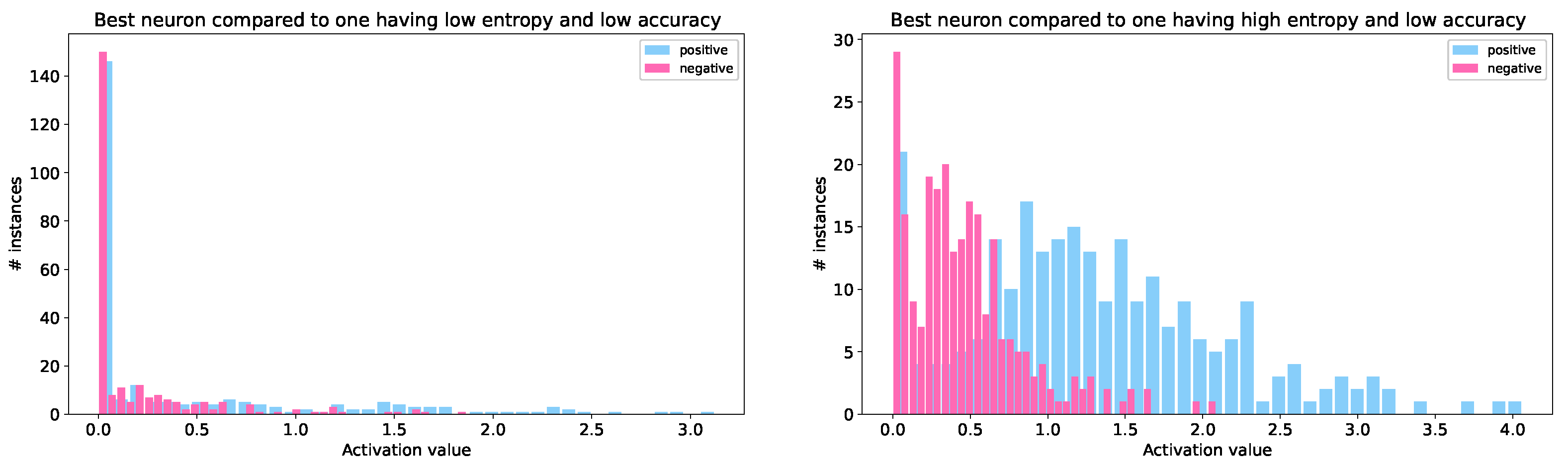
- All the neurons that perform well on known tasks also reach high scores with our entropy measure.
- By choosing appropriate thresholds on activation values, in order to classify instances, neurons with high entropy are able to approximate each other’s behavior.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Erhan, D.; Courville, A.; Bengio, Y.; Vincent, P. Why does unsupervised pre-training help deep learning? In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 201–208. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining explanations: An overview of interpretability of machine learning. In Proceedings of the IEEE 5th International Conference on data science and advanced analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 80–89. [Google Scholar]
- Le, Q.V.; Ranzato, M.; Monga, R.; Devin, M.; Corrado, G.; Chen, K.; Dean, J.; Ng, A.Y. Building high-level features using large scale unsupervised learning. In Proceedings of the 29th International Conference on Machine Learning, ICML, PMLR, Edinburgh, Scotland, 26 June–1 July 2012; pp. 507–514. [Google Scholar]
- Dalvi, F.; Durrani, N.; Sajjad, H.; Belinkov, Y.; Bau, A.; Glass, J.R. What Is One Grain of Sand in the Desert? Analyzing Individual Neurons in Deep NLP Models. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 6309–6317. [Google Scholar]
- Le, T.H.M.; Chen, H.; Babar, M.A. Deep Learning for Source Code Modeling and Generation: Models, Applications, and Challenges. ACM Comput. Surv. 2020, 53, 62:1–62:38. [Google Scholar] [CrossRef]
- Allamanis, M.; Barr, E.T.; Devanbu, P.T.; Sutton, C. A Survey of Machine Learning for Big Code and Naturalness. ACM Comput. Surv. 2018, 51, 81:1–81:37. [Google Scholar] [CrossRef]
- Del Carpio, A.F.; Angarita, L.B. Trends in Software Engineering Processes using Deep Learning: A Systematic Literature Review. In Proceedings of the 46th Euromicro Conference on Software Engineering and Advanced Applications (SEAA), Portoroz, Slovenia, 26–28 August 2020; pp. 445–454. [Google Scholar] [CrossRef]
- Liu, F.; Li, G.; Wei, B.; Xia, X.; Fu, Z.; Jin, Z. A Self-Attentional Neural Architecture for Code Completion with Multi-Task Learning. In Proceedings of the 28th International Conference on Program Comprehension, ICPC, ACM, Seoul, Republic of Korea, 13–15 July 2020; pp. 37–47. [Google Scholar]
- Allamanis, M.; Peng, H.; Sutton, C.A. A Convolutional Attention Network for Extreme Summarization of Source Code. In Proceedings of the 33nd International Conference on Machine Learning, ICML, New York, NY, USA, 19–24 June 2016; pp. 2091–2100. [Google Scholar]
- Mou, L.; Li, G.; Zhang, L.; Wang, T.; Jin, Z. Convolutional Neural Networks over Tree Structures for Programming Language Processing. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 1287–1293. [Google Scholar]
- Allamanis, M.; Brockschmidt, M.; Khademi, M. Learning to Represent Programs with Graphs. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Alon, U.; Zilberstein, M.; Levy, O.; Yahav, E. code2vec: Learning distributed representations of code. Proc. ACM Program. Lang. 2019, 3, 40:1–40:29. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Kanade, A.; Maniatis, P.; Balakrishnan, G.; Shi, K. Learning and evaluating contextual embedding of source code. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, Virtual, 12–18 July 2020. [Google Scholar]
- Ahmad, W.; Chakraborty, S.; Ray, B.; Chang, K.W. Unified Pre-training for Program Understanding and Generation. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 2655–2668. [Google Scholar]
- Yu, S.; Príncipe, J.C. Understanding autoencoders with information theoretic concepts. Neural Netw. 2019, 117, 104–123. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Jozefowicz, R.; Sutskever, I. Learning to Generate Reviews and Discovering Sentiment. arXiv 2017, arXiv:1704.01444. [Google Scholar]
- Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.J.; Wexler, J.; Viégas, F.B.; Sayres, R. Interpretability beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 2673–2682. [Google Scholar]
- McGrath, T.; Kapishnikov, A.; Tomašev, N.; Pearce, A.; Wattenberg, M.; Hassabis, D.; Kim, B.; Paquet, U.; Kramnik, V. Acquisition of chess knowledge in alphazero. Proc. Natl. Acad. Sci. USA 2022, 119, e2206625119. [Google Scholar] [CrossRef] [PubMed]
- Saletta, M.; Ferretti, C. Towards the evolutionary assessment of neural transformers trained on source code. In Proceedings of the GECCO’22: Genetic and Evolutionary Computation Conference, Companion Volume, Boston, MA, USA, 9–13 July 2022; Fieldsend, J.E., Wagner, M., Eds.; ACM: New York, NY, USA, 2022; pp. 1770–1778. [Google Scholar] [CrossRef]
- Ferretti, C.; Saletta, M. Do Neural Transformers Learn Human-Defined Concepts? An Extensive Study in Source Code Processing Domain. Algorithms 2022, 15, 449. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Bengio, Y.; Courville, A.C. Deep Learning; Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Bau, A.; Belinkov, Y.; Sajjad, H.; Durrani, N.; Dalvi, F.; Glass, J.R. Identifying and Controlling Important Neurons in Neural Machine Translation. In Proceedings of the 7th International Conference on Learning Representations, ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 623–656. [Google Scholar] [CrossRef]
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Chollet, F. Keras. Available online: https://keras.io (accessed on 4 April 2023).
- Alon, U.; Brody, S.; Levy, O.; Yahav, E. code2seq: Generating Sequences from Structured Representations of Code. In Proceedings of the 7th International Conference on Learning Representations, ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Le, Q.V.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the 31th International Conference on Machine Learning, ICML 2014, Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Řehůřek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 22 May 2010; pp. 45–50. [Google Scholar]
- Smith, N.; van Bruggen, D.; Tomassetti, F. JavaParser: Visited, Version Dated 5 February 2021; GitHub, Inc.: San Francisco, CA, USA, 2021. [Google Scholar]
- Saletta, M.; Ferretti, C. A Neural Embedding for Source Code: Security Analysis and CWE Lists. In Proceedings of the 18th IEEE International Conference on Dependable, Autonomic and Secure Computing, DASC/PiCom/CBDCom/CyberSciTech, Calgary, AB, Canada, 17–22 August 2020; pp. 523–530. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the Advances in Neural Information Processing Systems 26, Proceedings of NIPS, Lake Tahoe, Nevada, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Allen, F.E. Control Flow Analysis. ACM Sigplan Not. 1970, 5, 1–19. [Google Scholar] [CrossRef]
- McCabe, T.J. A Complexity Measure. IEEE Trans. Softw. Eng. 1976, 2, 308–320. [Google Scholar] [CrossRef]
- Alon, U.; Zilberstein, M.; Levy, O.; Yahav, E. A general path-based representation for predicting program properties. In Proceedings of the 39th ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI, Philadelphia, PA, USA, 18–22 June 2018; pp. 404–419. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Instance | doc2vec | ast2vec |
|---|---|---|---|
| Random | none | ||
| Structural | |||
| Semantic | |||
| Semantic | |||
| I/O | vs. | ||
| I/O | vs. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saletta, M.; Ferretti, C. Exploring Neural Dynamics in Source Code Processing Domain. Information 2023, 14, 251. https://doi.org/10.3390/info14040251
Saletta M, Ferretti C. Exploring Neural Dynamics in Source Code Processing Domain. Information. 2023; 14(4):251. https://doi.org/10.3390/info14040251
Chicago/Turabian StyleSaletta, Martina, and Claudio Ferretti. 2023. "Exploring Neural Dynamics in Source Code Processing Domain" Information 14, no. 4: 251. https://doi.org/10.3390/info14040251
APA StyleSaletta, M., & Ferretti, C. (2023). Exploring Neural Dynamics in Source Code Processing Domain. Information, 14(4), 251. https://doi.org/10.3390/info14040251