


Towards Safe Cyber Practices: Developing a Proactive Cyber-Threat Intelligence System for Dark Web Forum Content by Identifying Cybercrimes



Abstract
:1. Introduction
- Are the activities on the DarkNet a potential indicator of possible cybercrimes? If so, what are the target domains and people at risk?
- What stolen/breached information is there, and what is the aftermath?
- Which preventive measures can be taken to minimize the losses?
- Providing information on vendors across markets, such as Pretty Good Service (PGP (https://en.wikipedia.org/wiki/Pretty_Good_Privacy, accessed on 27 March 2023)) key and feedback ratings [19,20].
- Identifying arrested/convicted vendors.
- Identifying vendor activities (products sold and ratings).
- Generating information to help operations, such as Operation Onymous (https://www.europol.europa.eu/operations-servi,ces-and-innovation/operations/operation-onymous, accessed on 27 March 2023).
- Topic modeling of forums.
- We performed the annotation to label the data for creating the ground-truth labels for the large Agora Dark Web dataset.
- We applied heuristic approaches to finally select the preprocessing strategies suitable and useful for our experimental dataset.
- Based on our annotation, we modeled a novel multiclass classification problem to identify activities (cybercrime) on Dark Web forums.
- We implemented several deep learning approaches (baseline and state-of-the-art) using pre-trained word-embedding representations.
- Finally, we provide an in-depth discussion of the experimental outcome and present our key findings of this research work.
2. Literature Review
3. Dataset, Preprocessing, and Problem Formulation
3.1. Dataset Description
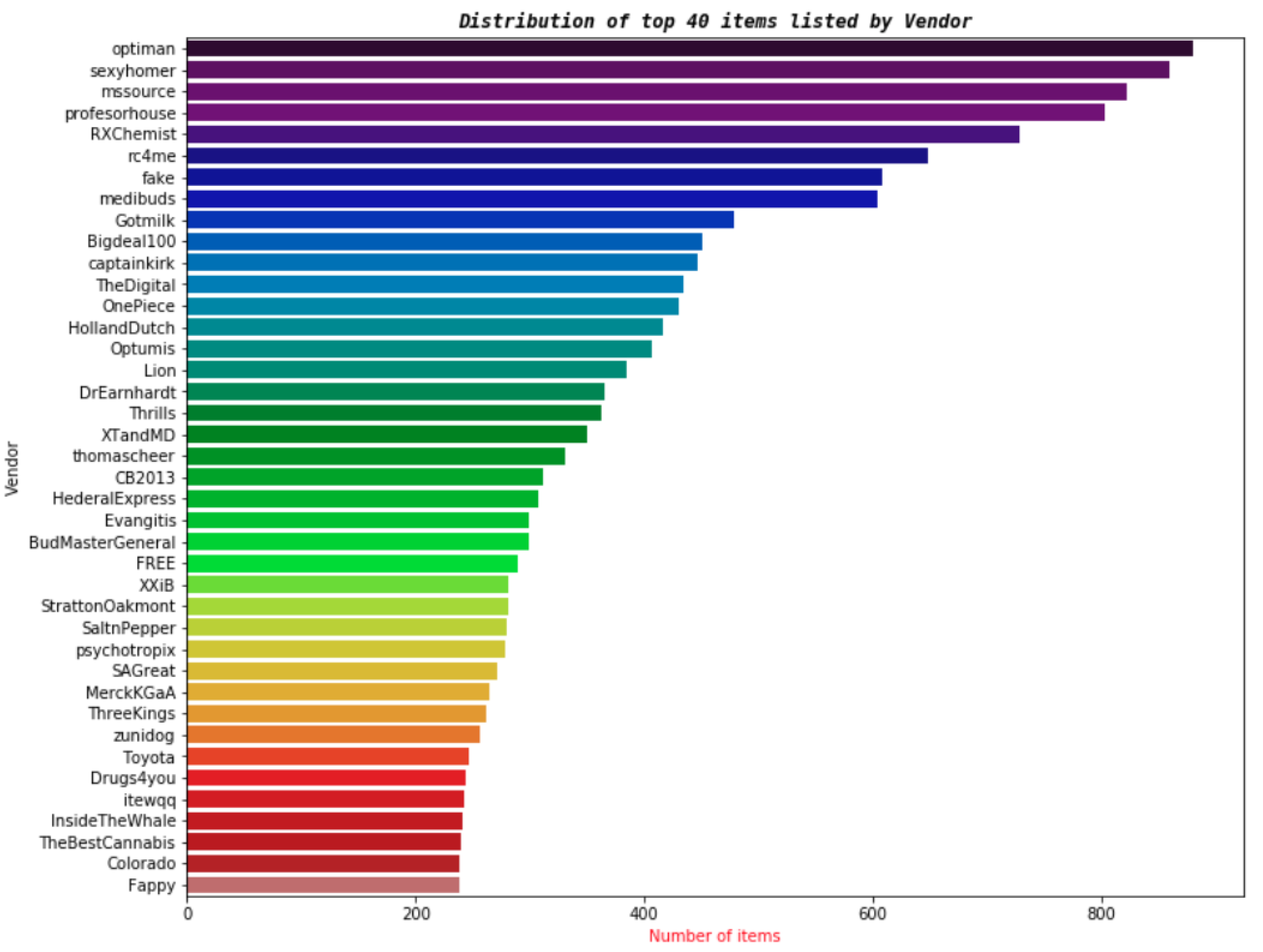
- Vendor: The items of this attribute are related to vendors, types of vendors, etc. There are 3192 distinct items listed in this attribute, and the distribution of the top 40 items is shown in Figure 3.
- Category: This attribute contains where the marketplace items are listed. There are a total of 109 specific items listed in the raw dataset.
- Item: This attribute contains the title of the listed items.
- Description: This attribute contains the description of the items.
- Price: This attribute contains the cost of the items. The cost is averaged for duplicate listings between 2014 and 2015)
- Origin: This attribute contains the place of origin from where the item is shipped. Several data points in this attribute are empty or missing.
- Destination: This attribute contains the place where the item is to be shipped (blank means no information was provided, but most likely worldwide.) Several data points in this attribute are also empty or missing.
- Rating: This attribute contains the seller’s rating, typically on a scale of 5. A rating of “[0 deals]” or anything else indicates that the number of deals is too small for a rating to be displayed.
- Remarks: This attribute contains remarks such as “[0 deals]” or “Average price may be skewed outlier >0.5 BTC found”. In this attribute also, several data points are empty or missing.

3.2. Dataset Preprocessing
- The entire text is converted to lowercase to make the dataset uniform in terms of representation (e.g., “Category” and “category” are represented by a common token: “category”).
- Punctuation is removed since it does not add valuable semantic information to the text.
- We removed stopwords for the above-mentioned reason.
- We removed newlines, whitespaces, and extra spaces from the text.
- We removed the special characters, symbols, and elements that are not part of standard English language.
- We performed stemming and lemmatization alternatively to observe the impact of classification models.
- Finally, we tokenized the text data to get words/tokens.
- We removed the blank and outlier values of the attribute “category”.
3.3. Problem Formulation
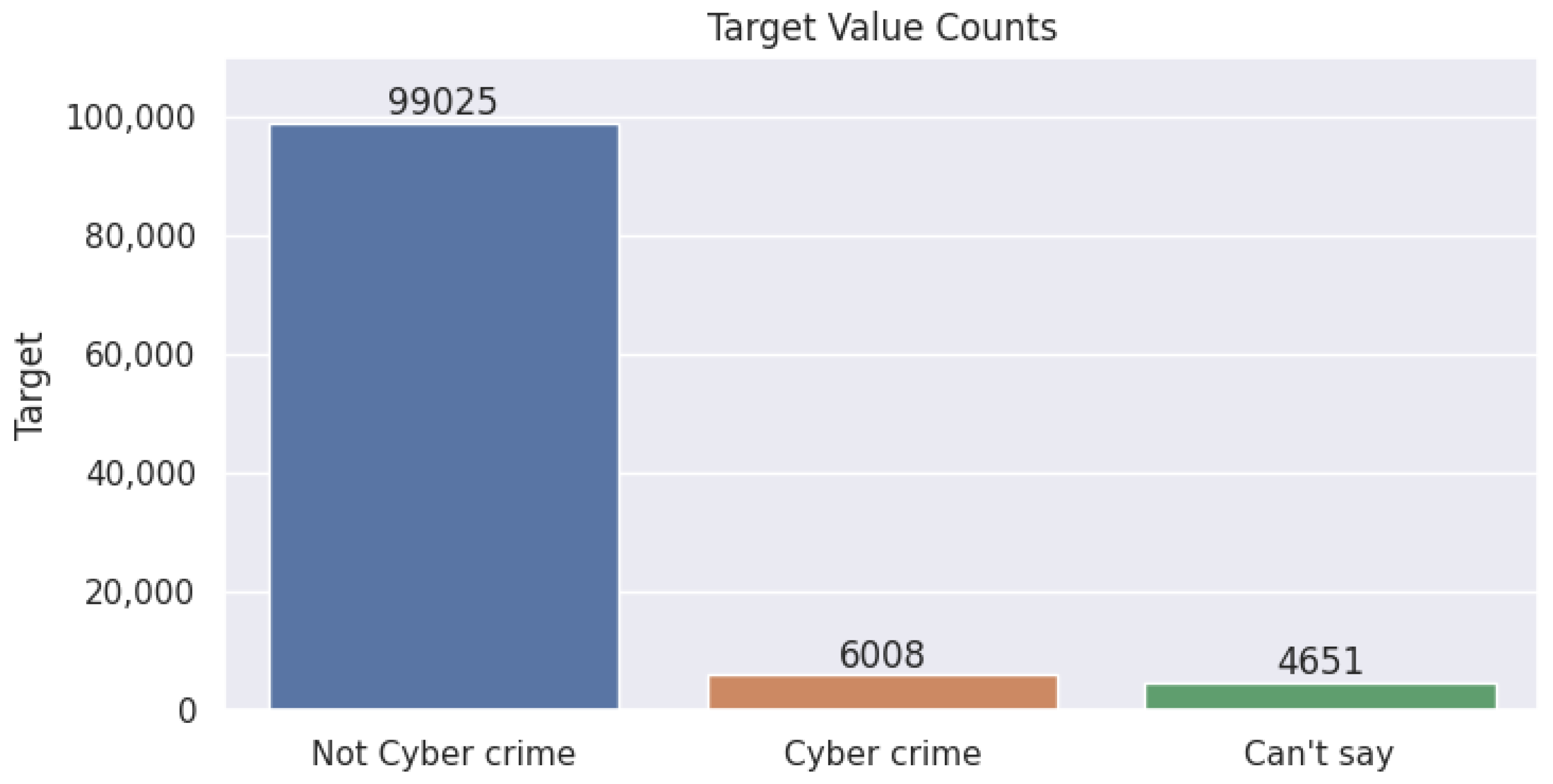
- The activities are clearly indicative of “Cybercrime”.
- The activities are clearly indicative of “Not Cybercrime”.
- It is difficult to say if the activity is explicitly Cybercrime “Can’t say if cybercrime”.
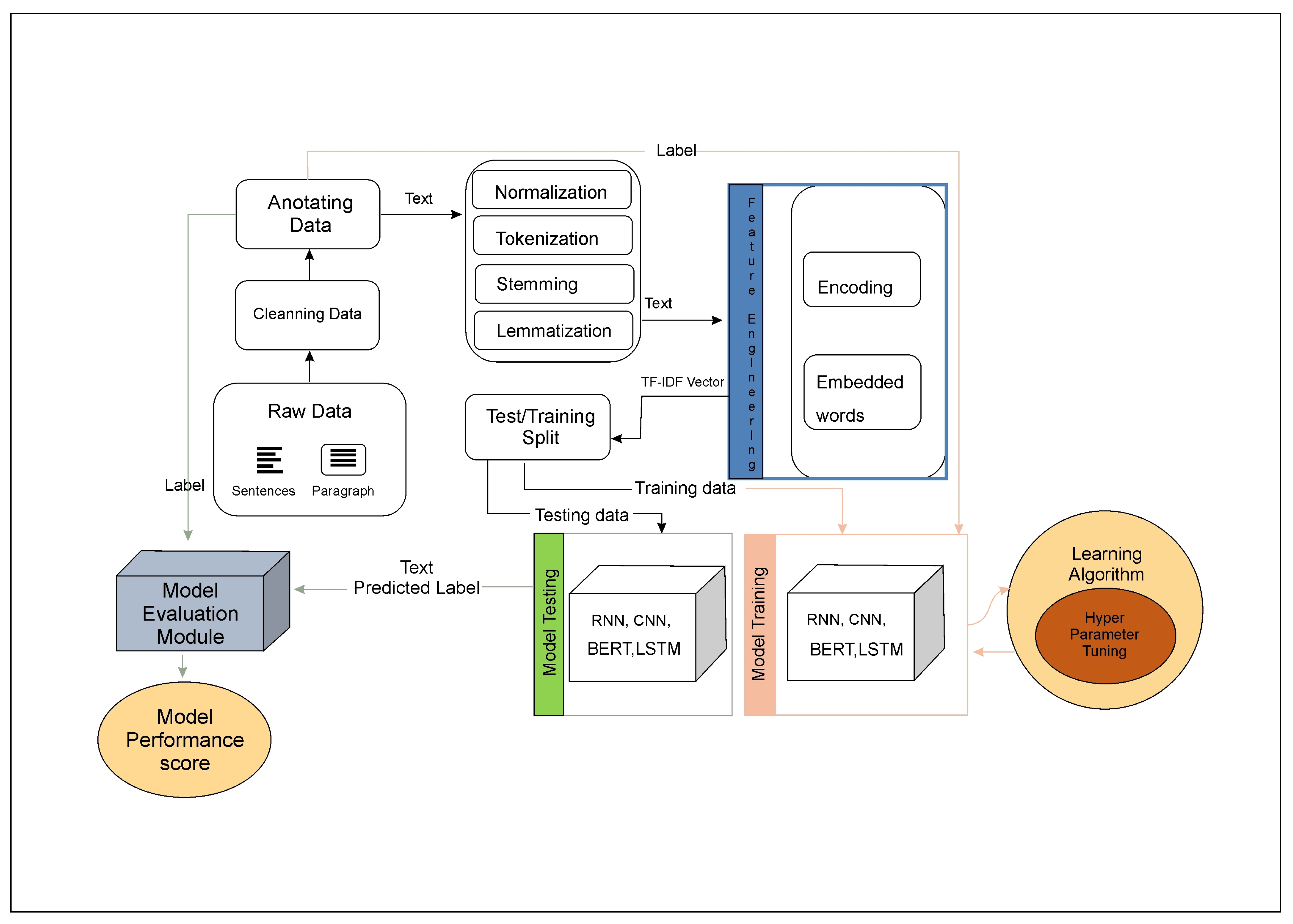
4. Materials and Methods
4.1. Resource Description
4.2. Architecture of Classification Models
- First, the raw dataset is cleaned.
- Then, annotation of the dataset is executed.
- Post-annotation, the dataset is normalized, which essentially executes the preprocessing steps.
- Then, the tokenized dataset is integer encoded.
- Post encoding, the embedding matrix is generated.
- The embedding matrix and encoded text are used to train the classification models.
- As a last step, the prediction is done on the test dataset.
5. Results and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| DL | Deep Learning |
| NLP | Natural Language Processing |
| CTI | Cyber-Threat Intelligence |
| TOR | The Onion Router |
| WWW | World Wide Web |
| CNN | Convolution Neural Network |
| LSTM | Long Short-Term Memory |
| BERT | Bidirectional Encoder Representations from Transformers |
| CT | Counter-Terrorism |
| GAN | Generative Adversarial Network |
References
- Pallen, M. Guide to the Internet: The world wide web. BMJ 1995, 311, 1552–1556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gehl, R.W. Archives for the dark web: A field guide for study. In Research Methods for the Digital Humanities; Springer: Berlin/Heidelberg, Germany, 2018; pp. 31–51. [Google Scholar]
- Mancini, S.; Tomei, L.A. The Dark Web: Defined, Discovered, Exploited. Int. J. Cyber Res. Educ. 2019, 1, 1–12. [Google Scholar] [CrossRef]
- Jardine, E. The Dark Web dilemma: Tor, anonymity and online policing. Glob. Comm. Internet Gov. Pap. Ser. 2015, 21, 1–13. [Google Scholar] [CrossRef]
- Chertoff, M.; Simon, T. The Impact of the Dark Web on Internet Governance and Cyber Security. 2015. Available online: https://policycommons.net/artifacts/1203086/the-impact-of-the-dark-web-on-internet-goverannce-and-cyber-security/1756195/ (accessed on 27 March 2023).
- Weimann, G. Going dark: Terrorism on the dark web. Stud. Confl. Terror. 2016, 39, 195–206. [Google Scholar] [CrossRef] [Green Version]
- Ablon, L.; Libicki, M.C.; Golay, A.A. Markets for Cybercrime Tools and Stolen Data: Hackers’ Bazaar; Rand Corporation: Santa Monica, CA, USA, 2014. [Google Scholar]
- Weimann, G. Terrorist migration to the dark web. Perspect. Terror. 2016, 10, 40–44. [Google Scholar]
- Gupta, A.; Maynard, S.B.; Ahmad, A. The Dark Web Phenomenon: A Review and Research Agenda. 2019. Available online: https://aisel.aisnet.org/acis2019/1/ (accessed on 27 March 2023).
- Lacson, W.; Jones, B. The 21st century darknet market: Lessons from the fall of Silk Road. Int. J. Cyber Criminol. 2016, 10, 40. [Google Scholar]
- Buxton, J.; Bingham, T. The rise and challenge of dark net drug markets. Policy Brief 2015, 7, 1–2. [Google Scholar]
- Rhumorbarbe, D.; Staehli, L.; Broséus, J.; Rossy, Q.; Esseiva, P. Buying drugs on a Darknet market: A better deal? Studying the online illicit drug market through the analysis of digital, physical and chemical data. Forensic Sci. Int. 2016, 267, 173–182. [Google Scholar] [CrossRef] [Green Version]
- Lacey, D.; Salmon, P.M. It’s dark in there: Using systems analysis to investigate trust and engagement in dark web forums. In Proceedings of the Engineering Psychology and Cognitive Ergonomics: 12th International Conference, EPCE 2015, Held as Part of HCI International 2015, Los Angeles, CA, USA, 2–7 August 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 117–128. [Google Scholar]
- Van Hout, M.C.; Bingham, T. Responsible vendors, intelligent consumers: Silk Road, the online revolution in drug trading. Int. J. Drug Policy 2014, 25, 183–189. [Google Scholar] [CrossRef]
- Cherqi, O.; Mezzour, G.; Ghogho, M.; El Koutbi, M. Analysis of hacking related trade in the darkweb. In Proceedings of the 2018 IEEE International Conference on Intelligence and Security Informatics (ISI), Miami, FL, USA, 9–11 November 2018; pp. 79–84. [Google Scholar]
- Ghosh, S.; Das, A.; Porras, P.; Yegneswaran, V.; Gehani, A. Automated categorization of onion sites for analyzing the darkweb ecosystem. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1793–1802. [Google Scholar]
- Montieri, A.; Ciuonzo, D.; Aceto, G.; Pescapé, A. Anonymity services tor, i2p, jondonym: Classifying in the dark (web). IEEE Trans. Dependable Secur. Comput. 2018, 17, 662–675. [Google Scholar] [CrossRef] [Green Version]
- ElBahrawy, A.; Alessandretti, L.; Rusnac, L.; Goldsmith, D.; Teytelboym, A.; Baronchelli, A. Collective dynamics of dark web marketplaces. Sci. Rep. 2020, 10, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Broséus, J.; Rhumorbarbe, D.; Mireault, C.; Ouellette, V.; Crispino, F.; Décary-Hétu, D. Studying illicit drug trafficking on Darknet markets: Structure and organisation from a Canadian perspective. Forensic Sci. Int. 2016, 264, 7–14. [Google Scholar] [CrossRef] [PubMed]
- Dwyer, A.C.; Hallett, J.; Peersman, C.; Edwards, M.; Davidson, B.I.; Rashid, A. How darknet market users learned to worry more and love PGP: Analysis of security advice on darknet marketplaces. arXiv 2022, arXiv:2203.08557. [Google Scholar]
- Zaunseder, A.; Bancroft, A. Pricing of illicit drugs on darknet markets: A conceptual exploration. Drugs Alcohol Today 2021, 21, 135–145. [Google Scholar] [CrossRef]
- Zambiasi, D. Drugs on the web, crime in the streets. the impact of shutdowns of dark net marketplaces on street crime. J. Econ. Behav. Organ. 2022, 202, 274–306. [Google Scholar] [CrossRef]
- Armona, L. Measuring the Demand Effects of Formal and Informal Communication: Evidence from Online Markets for Illicit Drugs. arXiv 2018, arXiv:1802.08778. [Google Scholar]
- Miller, J.N. The war on drugs 2.0: Darknet fentanyl’s rise and the effects of regulatory and law enforcement action. Contemp. Econ. Policy 2020, 38, 246–257. [Google Scholar] [CrossRef]
- Andrei, F.; Barrera, D.; Krakowski, K.; Sulis, E. Trust intermediary in a cryptomarket for illegal drugs. Eur. Sociol. Rev. 2023, jcad020. [Google Scholar] [CrossRef]
- Hiramoto, N.; Tsuchiya, Y. Are Illicit Drugs a Driving Force for Cryptomarket Leadership? J. Drug Issues 2022, 53, 451–474. [Google Scholar] [CrossRef]
- Bogensperger, J.; Schlarb, S.; Hanbury, A.; Recski, G. DreamDrug-A crowdsourced NER dataset for detecting drugs in darknet markets. In Proceedings of the Seventh Workshop on Noisy User-generated Text (W-NUT 2021), Gyeongju, Republic of Korea, 11 November 2021; pp. 137–157. [Google Scholar]
- Zhang, Y.; Qian, Y.; Fan, Y.; Ye, Y.; Li, X.; Xiong, Q.; Shao, F. dstyle-gan: Generative adversarial network based on writing and photography styles for drug identification in darknet markets. In Proceedings of the Annual Computer Security Applications Conference, Austin, TX, USA, 7–11 December 2022; pp. 669–680. [Google Scholar]
- Manolache, A.; Brad, F.; Barbalau, A.; Ionescu, R.T.; Popescu, M. VeriDark: A Large-Scale Benchmark for Authorship Verification on the Dark Web. In Advances in Neural Information Processing Systems; Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2022; Volume 35, pp. 15574–15588. [Google Scholar]
- Dearden, T.E.; Tucker, S.E. Follow the Money: Analyzing Darknet Activity Using Cryptocurrency and the Bitcoin Blockchain. J. Contemp. Crim. Justice 2023, 39, 257–275. [Google Scholar] [CrossRef]
- Akcora, C.G.; Purusotham, S.; Gel, Y.R.; Krawiec-Thayer, M.; Kantarcioglu, M. How to not get caught when you launder money on blockchain? arXiv 2020, arXiv:2010.15082. [Google Scholar]
- Gomez, G.; Moreno-Sanchez, P.; Caballero, J. Watch Your Back: Identifying Cybercrime Financial Relationships in Bitcoin through Back-and-Forth Exploration. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, Los Angeles, CA, USA, 7–11 November 2022; pp. 1291–1305. [Google Scholar]
- Demant, J.; Munksgaard, R.; Houborg, E. Personal use, social supply or redistribution? Cryptomarket demand on Silk Road 2 and Agora. Trends Organ. Crime 2018, 21, 42–61. [Google Scholar] [CrossRef]
- Chen, C.; Peersman, C.; Edwards, M.; Ursani, Z.; Rashid, A. Amoc: A multifaceted machine learning-based toolkit for analysing cybercriminal communities on the darknet. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 2516–2524. [Google Scholar]
- Saxena, V.; Rethmeier, N.; Van Dijck, G.; Spanakis, G. VendorLink: An NLP approach for Identifying & Linking Vendor Migrants & Potential Aliases on Darknet Markets. arXiv 2023, arXiv:2305.02763. [Google Scholar]
- Maras, M.H.; Arsovska, J.; Wandt, A.S.; Logie, K. Keeping Pace With the Evolution of Illicit Darknet Fentanyl Markets: Using a Mixed Methods Approach to Identify Trust Signals and Develop a Vendor Trustworthiness Index. J. Contemp. Crim. Justice 2023, 39, 276–297. [Google Scholar] [CrossRef]
- Booij, T.M.; Verburgh, T.; Falconieri, F.; van Wegberg, R.S. Get Rich or Keep Tryin’Trajectories in dark net market vendor careers. In Proceedings of the 2021 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), Vienna, Austria, 6–10 September 2021; pp. 202–212. [Google Scholar]
- Szigeti, Á.; Frank, R.; Kiss, T. Trust factors in the social figuration of online drug trafficking: A qualitative content analysis on a darknet market. J. Contemp. Crim. Justice 2023, 39, 167–184. [Google Scholar] [CrossRef]
- Lokala, U.; Phukan, O.C.; Dastidar, T.G.; Lamy, F.; Daniulaityte, R.; Sheth, A. “Can We Detect Substance Use Disorder?”: Knowledge and Time Aware Classification on Social Media from Darkweb. arXiv 2023, arXiv:2304.10512. [Google Scholar]
- Cork, A.; Everson, R.; Levine, M.; Koschate, M. Using computational techniques to study social influence online. Group Process. Intergroup Relations 2020, 23, 808–826. [Google Scholar] [CrossRef]
- Liu, H.; Zhao, J.; Huo, Y.; Wang, Y.; Liao, C.; Shen, L.; Cui, S.; Shi, J. URM4DMU: An User Representation Model for Darknet Markets Users. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Luong, H.T. Preliminary Findings of the Trends and Patterns of Darknet-Related Criminals in the Last Decade. 2022. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4174766 (accessed on 27 March 2023).
- Ogbanufe, O.; Baucum, F.; Benjamin, J. Network Analysis of a Darknet Marketplace: Identifying Themes and Key Users of Illicit Networks. 2022. Available online: https://aisel.aisnet.org/wisp2022/15/ (accessed on 27 March 2023).
- Stoddart, K. Non and Sub-State Actors: Cybercrime, Terrorism, and Hackers. In Cyberwarfare: Threats to Critical Infrastructure; Springer International Publishing: Cham, Switzerland, 2022; pp. 351–399. [Google Scholar] [CrossRef]
- Maneriker, P.; He, Y.; Parthasarathy, S. SYSML: StYlometry with Structure and Multitask Learning: Implications for Darknet Forum Migrant Analysis. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 7–11 November 2021; pp. 6844–6857. [Google Scholar] [CrossRef]
- Baravalle, A.; Lopez, M.S.; Lee, S.W. Mining the dark web: Drugs and fake ids. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 350–356. [Google Scholar]
- Fu, T.; Abbasi, A.; Chen, H. A focused crawler for Dark Web forums. J. Am. Soc. Inf. Sci. Technol. 2010, 61, 1213–1231. [Google Scholar] [CrossRef]
- Raghavan, S.; Garcia-Molina, H. Crawling the hidden web. In Proceedings of the Vldb, Roma, Italy, 11–14 September 2001; Volume 1, pp. 129–138. [Google Scholar]
- Zulkarnine, A.T.; Frank, R.; Monk, B.; Mitchell, J.; Davies, G. Surfacing collaborated networks in dark web to find illicit and criminal content. In Proceedings of the 2016 IEEE Conference on Intelligence and Security Informatics (ISI), Tucson, AZ, USA, 28–30 September 2016; pp. 109–114. [Google Scholar]
- Nazah, S.; Huda, S.; Abawajy, J.H.; Hassan, M.M. An Unsupervised Model for Identifying and Characterizing Dark Web Forums. IEEE Access 2021, 9, 112871–112892. [Google Scholar] [CrossRef]
- Yang, L.; Liu, F.; Kizza, J.M.; Ege, R.K. Discovering topics from dark websites. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence in Cyber Security, Nashville, TN, USA, 31 March–2 April 2009; pp. 175–179. [Google Scholar]
- L’huillier, G.; Alvarez, H.; Ríos, S.A.; Aguilera, F. Topic-based social network analysis for virtual communities of interests in the dark web. ACM Sigkdd Explor. Newsl. 2011, 12, 66–73. [Google Scholar] [CrossRef]
- Porter, K. Analyzing the DarkNetMarkets subreddit for evolutions of tools and trends using LDA topic modeling. Digit. Investig. 2018, 26, S87–S97. [Google Scholar] [CrossRef]
- Ríos, S.A.; Muñoz, R. Dark web portal overlapping community detection based on topic models. In Proceedings of the ACM SIGKDD Workshop on Intelligence and Security Informatics, New York, NY, USA, 12 August 2012; pp. 1–7. [Google Scholar]
- Sachan, A. Countering terrorism through dark web analysis. In Proceedings of the 2012 Third International Conference on Computing, Communication and Networking Technologies (ICCCNT’12), Coimbatore, India, 26–28 July 2012; pp. 1–5. [Google Scholar] [CrossRef]
- Kramer, S. Anomaly detection in extremist web forums using a dynamical systems approach. In Proceedings of the ACM SIGKDD Workshop on Intelligence and Security Informatics, Washington, DC, USA, 25 July 2010; pp. 1–10. [Google Scholar]
- Arnold, N.; Ebrahimi, M.; Zhang, N.; Lazarine, B.; Patton, M.; Chen, H.; Samtani, S. Dark-net ecosystem cyber-threat intelligence (CTI) tool. In Proceedings of the 2019 IEEE International Conference on Intelligence and Security Informatics (ISI), Shenzhen, China, 1–3 July 2019; pp. 92–97. [Google Scholar]
- Dalvi, A.; Patil, G.; Bhirud, S. Dark Web Marketplace Monitoring-The Emerging Business Trend of Cybersecurity. In Proceedings of the 2022 International Conference on Trends in Quantum Computing and Emerging Business Technologies (TQCEBT), Maharashtra, India, 13–15 October 2022; pp. 1–6. [Google Scholar]
- Nazah, S.; Huda, S.; Abawajy, J.; Hassan, M.M. Evolution of dark web threat analysis and detection: A systematic approach. IEEE Access 2020, 8, 171796–171819. [Google Scholar] [CrossRef]
- Nunes, E.; Diab, A.; Gunn, A.; Marin, E.; Mishra, V.; Paliath, V.; Robertson, J.; Shakarian, J.; Thart, A.; Shakarian, P. Darknet and deepnet mining for proactive cybersecurity threat intelligence. In Proceedings of the 2016 IEEE Conference on Intelligence and Security Informatics (ISI), Tucson, AZ, USA, 28–30 September 2016; pp. 7–12. [Google Scholar]
- Benjamin, V.; Li, W.; Holt, T.; Chen, H. Exploring threats and vulnerabilities in hacker web: Forums, IRC and carding shops. In Proceedings of the 2015 IEEE International Conference on Intelligence and Security Informatics (ISI), Baltimore, MD, USA, 27–29 May 2015; pp. 85–90. [Google Scholar]
- Robertson, J.; Paliath, V.; Shakarian, J.; Thart, A.; Shakarian, P. Data driven game theoretic cyber threat mitigation. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30, pp. 4041–4046. [Google Scholar]
- Pineau, T.; Schopfer, A.; Grossrieder, L.; Broséus, J.; Esseiva, P.; Rossy, Q. The study of doping market: How to produce intelligence from Internet forums. Forensic Sci. Int. 2016, 268, 103–115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Al Nabki, M.W.; Fidalgo, E.; Alegre, E.; De Paz, I. Classifying illegal activities on tor network based on web textual contents. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, Valencia, Spain, 3–7 April 2017; pp. 35–43. [Google Scholar]
- Abbasi, A.; Chen, H. Affect intensity analysis of dark web forums. In Proceedings of the 2007 IEEE Intelligence and Security Informatics, New Brunswick, NJ, USA, 23–24 May 2007; pp. 282–288. [Google Scholar]
- Glancy, F.H.; Yadav, S.B. A computational model for financial reporting fraud detection. Decis. Support Syst. 2011, 50, 595–601. [Google Scholar] [CrossRef]
- Holt, T.J.; Strumsky, D.; Smirnova, O.; Kilger, M. Examining the social networks of malware writers and hackers. Int. J. Cyber Criminol. 2012, 6, 891–903. [Google Scholar]
- Jordan, T.; Taylor, P. A sociology of hackers. Sociol. Rev. 1998, 46, 757–780. [Google Scholar] [CrossRef]
- Habibi Lashkari, A.; Kaur, G.; Rahali, A. Didarknet: A contemporary approach to detect and characterize the darknet traffic using deep image learning. In Proceedings of the 2020 the 10th International Conference on Communication and Network Security, Tokyo, Japan, 27–29 November 2020; pp. 1–13. [Google Scholar]
- Ebrahimi, M.; Nunamaker, J.F., Jr.; Chen, H. Semi-supervised cyber threat identification in dark net markets: A transductive and deep learning approach. J. Manag. Inf. Syst. 2020, 37, 694–722. [Google Scholar] [CrossRef]
- Iliadis, L.A.; Kaifas, T. Darknet traffic classification using machine learning techniques. In Proceedings of the 2021 10th International Conference on Modern Circuits and Systems Technologies (MOCAST), Thessaloniki, Greece, 5–7 July 2021; pp. 1–4. [Google Scholar]
- Zhang, Y.; Zeng, S.; Fan, L.; Dang, Y.; Larson, C.A.; Chen, H. Dark web forums portal: Searching and analyzing jihadist forums. In Proceedings of the 2009 IEEE International Conference on Intelligence and Security Informatics, Dallas, TX, USA, 8–11 June 2009; pp. 71–76. [Google Scholar]
- Scanlon, J.R.; Gerber, M.S. Automatic detection of cyber-recruitment by violent extremists. Secur. Inform. 2014, 3, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Chen, H. Sentiment and affect analysis of dark web forums: Measuring radicalization on the internet. In Proceedings of the 2008 IEEE International Conference on Intelligence and Security Informatics, San Antonio, TX, USA, 2–3 November 2008; pp. 104–109. [Google Scholar]
- Zhou, Y.; Reid, E.; Qin, J.; Chen, H.; Lai, G. US domestic extremist groups on the Web: Link and content analysis. IEEE Intell. Syst. 2005, 20, 44–51. [Google Scholar] [CrossRef]
- Branwen, G.; Christin, N.; Décary-Hétu, D.; Andersen, R.M.; Presidente, E.; Lau, D.; Sohhlz, D.K.; Cakic, V. Dark Net Market Archives, 2011–2015. Available online: https://gwern.net/dnm-archive (accessed on 27 March 2023).
- Dessì, D.; Helaoui, R.; Kumar, V.; Recupero, D.R.; Riboni, D. TF-IDF vs. Word Embeddings for Morbidity Identification in Clinical Notes: An Initial Study. In Proceedings of the First Workshop on Smart Personal Health Interfaces Co-Located with 25th International Conference on Intelligent User Interfaces, SmartPhil@IUI 2020, Cagliari, Italy, 17 March 2020; pp. 1–12. [Google Scholar]
- Kumar, V.; Verma, A.; Mittal, N.; Gromov, S.V. Anatomy of Preprocessing of Big Data for Monolingual Corpora Paraphrase Extraction: Source Language Sentence. Emerg. Technol. Data Min. Inf. Secur. 2019, 3, 495. [Google Scholar]
- Kumar, V.; Recupero, D.R.; Riboni, D.; Helaoui, R. Ensembling Classical Machine Learning and Deep Learning Approaches for Morbidity Identification From Clinical Notes. IEEE Access 2021, 9, 7107–7126. [Google Scholar] [CrossRef]
- Uysal, A.K.; Gunal, S. The impact of preprocessing on text classification. Inf. Process. Manag. 2014, 50, 104–112. [Google Scholar] [CrossRef]
- Bhandari, A.; Kumar, V.; Thien Huong, P.T.; Thanh, D.N. Sentiment analysis of COVID-19 tweets: Leveraging stacked word embedding representation for identifying distinct classes within a sentiment. In Artificial Intelligence in Data and Big Data Processing: Proceedings of ICABDE 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 341–352. [Google Scholar]
- Kumar, V.; Mishra, B.K.; Mazzara, M.; Thanh, D.N.; Verma, A. Prediction of malignant and benign breast cancer: A data mining approach in healthcare applications. In Advances in Data Science and Management; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Wu, Z.; Balloccu, S.; Kumar, V.; Helaoui, R.; Reforgiato Recupero, D.; Riboni, D. Creation, Analysis and Evaluation of AnnoMI, a Dataset of Expert-Annotated Counselling Dialogues. Future Internet 2023, 15, 110. [Google Scholar] [CrossRef]
- Wu, Z.; Balloccu, S.; Kumar, V.; Helaoui, R.; Reiter, E.; Recupero, D.R.; Riboni, D. Anno-mi: A dataset of expert-annotated counselling dialogues. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 6177–6181. [Google Scholar]
- Kumar, V.; Balloccu, S.; Wu, Z.; Reiter, E.; Helaoui, R.; Recupero, D.; Riboni, D. Data Augmentation for Reliability and Fairness in Counselling Quality Classification. In 1st Workshop on Scarce Data in Artificial Intelligence for Healthcare-SDAIH, INSTICC; SciTePress: Setúbal, Portugal, 2023; pp. 23–28. [Google Scholar] [CrossRef]
- Kumar, V.; Reforgiato Recupero, D.; Helaoui, R.; Riboni, D. K-LM: Knowledge Augmenting in Language Models Within the Scholarly Domain. IEEE Access 2022, 10, 91802–91815. [Google Scholar] [CrossRef]
- Liu, P.; Qiu, X.; Huang, X. Recurrent neural network for text classification with multi-task learning. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2873–2879. [Google Scholar]
- Medsker, L.; Jain, L.C. Recurrent Neural Networks: Design and Applications; CRC Press: Boca Raton, FL, USA, 1999. [Google Scholar]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; pp. 253–256. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Beauxis-Aussalet, E.; Hardman, L. Simplifying the visualization of confusion matrix. In Proceedings of the 26th Benelux Conference on Artificial Intelligence (BNAIC), Nijmegen, The Netherlands, 6–7 November 2014. [Google Scholar]
- Mandrekar, J.N. Receiver operating characteristic curve in diagnostic test assessment. J. Thorac. Oncol. 2010, 5, 1315–1316. [Google Scholar] [CrossRef] [Green Version]
- Hajian-Tilaki, K. Receiver operating characteristic (ROC) curve analysis for medical diagnostic test evaluation. Casp. J. Intern. Med. 2013, 4, 627. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sr. No. | Category (Items) | Count | Sr. No. | Category (Items) | Counts |
|---|---|---|---|---|---|
| 1 | Drugs/Cannabis/Weed | 21,272 | 53 | Drugs/Opioids/Buprenorphine | 284 |
| 2 | Drugs/Ecstasy/Pills | 7534 | 54 | Drugs/Psychedelics/Other | 272 |
| 3 | Drugs/Ecstasy/MDMA | 6116 | 55 | Drugs/Weight loss | 252 |
| 4 | Drugs/Stimulants/Cocaine | 6007 | 56 | Counterfeits/Accessories | 250 |
| 5 | Drugs/Prescription | 5561 | 57 | Drugs/Opioids/Morphine | 248 |
| 6 | Drugs/Benzos | 5393 | 58 | Drugs/Dissociatives/GHB | 226 |
| 7 | Drugs/Cannabis/Concentrates | 4257 | 59 | Drugs/Psychedelics/5-MeO | 216 |
| 8 | Drugs/Psychedelics/LSD | 3775 | 60 | Info/eBooks/Anonymity | 204 |
| 9 | Drugs/Cannabis/Hash | 3241 | 61 | Drug paraphernalia/Pipes | 195 |
| 10 | Drugs/Steroids | 2779 | 62 | Drugs/Opioids/Hydrocodone | 191 |
| 11 | Drugs/Stimulants/Meth | 2467 | 63 | Drug paraphernalia/Containers | 186 |
| 12 | Drugs/Stimulants/Speed | 2401 | 64 | Info/eBooks/Science | 163 |
| 13 | Drugs/RCs | 2182 | 65 | Drug paraphernalia/Stashes | 149 |
| 14 | Drugs/Stimulants/Prescription | 1956 | 66 | Info/eBooks/Relationships/Sex | 145 |
| 15 | Drugs/Opioids/Heroin | 1799 | 67 | Info/eBooks/IT | 144 |
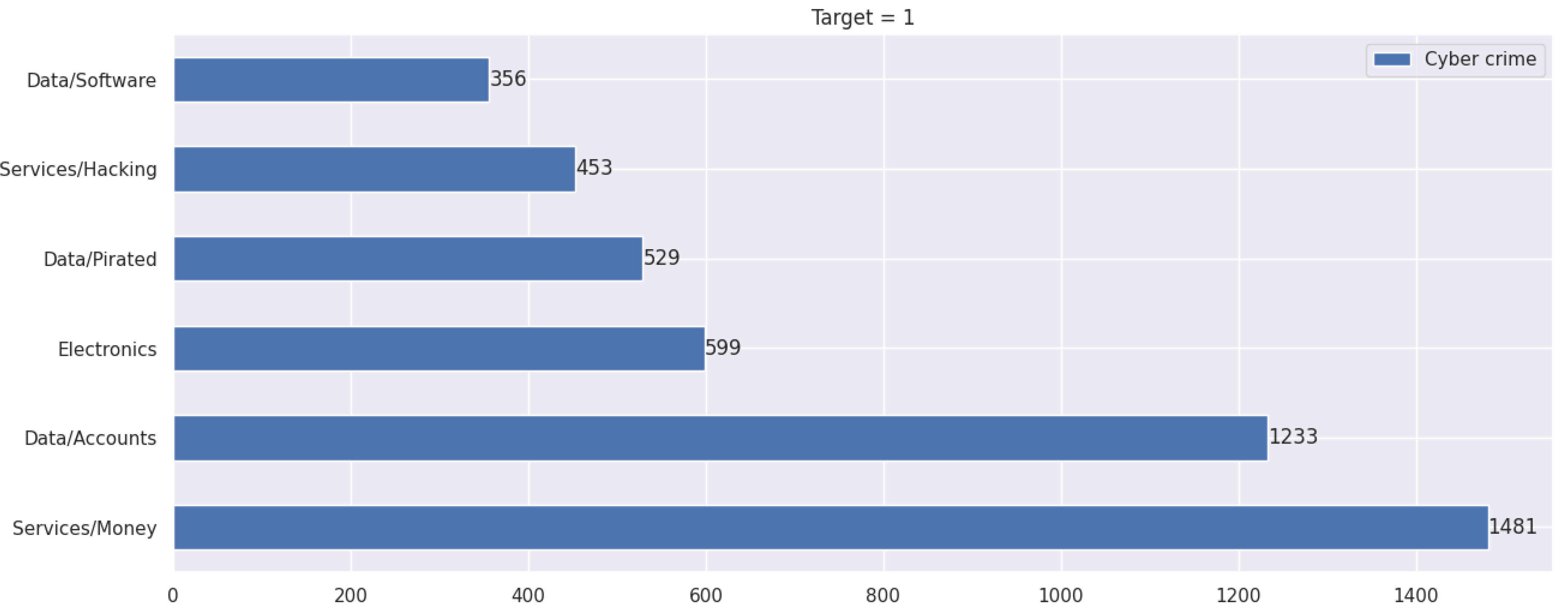
| 16 | Services/Money | 1481 | 68 | Weapons/Ammunition | 138 |
| 17 | Other | 1425 | 69 | Services/Advertising | 132 |
| 18 | Drugs/Opioids/Oxycodone | 1360 | 70 | Drugs/Cannabis/Shake/trim | 121 |
| 19 | Counterfeits/Watches | 1309 | 71 | Drugs/Psychedelics/Others | 106 |
| 20 | Drugs/Opioids | 1236 | 72 | Drug paraphernalia/Grinders | 106 |
| 21 | Data/Accounts | 1233 | 73 | Weapons/Melee | 103 |
| 22 | Drugs/Psychedelics/Mushrooms | 1140 | 74 | Forgeries/Other | 100 |
| 23 | Drugs/Cannabis/Edibles | 1109 | 75 | Drugs/Opioids/Codeine | 92 |
| 24 | Drugs/Ecstasy/Other | 1004 | 76 | Services/Travel | 90 |
| 25 | Drugs/Dissociatives/Ketamine | 992 | 77 | Chemicals | 90 |
| 26 | Drugs/Psychedelics/NB | 974 | 78 | Drugs/Opioids/Opium | 87 |
| 27 | Drugs/Psychedelics/2C | 932 | 79 | Drugs/Psychedelics/Mescaline | 86 |
| 28 | Information/Guides | 927 | 80 | Drugs/Psychedelics/Spores | 80 |
| 29 | Information/eBooks | 918 | 81 | Drugs/Dissociatives/GBL | 76 |
| 30 | Drugs/Other | 872 | 82 | Info/eBooks/Economy | 76 |
| 31 | Drugs/Opioids/Fentanyl | 848 | 83 | Drugs/Dissociatives/Other | 63 |
| 32 | Drugs/Psychedelics/DMT | 723 | 84 | Drug paraphernalia/Paper | 61 |
| 33 | Info/eBooks/Other | 691 | 85 | Counterfeits/Electronics | 59 |
| 34 | Drugs/Opioids/Other | 643 | 86 | Weapons/Non-lethal firearms | 57 |
| 35 | Drugs/Cannabis/Synthetics | 637 | 87 | Drugs/Opioids/Dihydrocodeine | 54 |
| 36 | Forgeries/Physical documents | 616 | 88 | Drug paraphernalia/Scales | 47 |
| 37 | Electronics | 599 | 89 | Drug paraphernalia/Injecting equipment/Syringes | 45 |
| 38 | Data/Pirated | 529 | 90 | Info/eBooks/Doomsday | 43 |
| 39 | Drugs/Cannabis/Seeds | 529 | 91 | Drugs/Stimulants/Mephedrone | 40 |
| 40 | Services/Other | 487 | 92 | Info/eBooks/Psychology | 40 |
| 41 | Services/Hacking | 453 | 93 | Drugs/Psychedelics/Salvia | 37 |
| 42 | Jewelry | 418 | 94 | Drugs/Barbiturates | 30 |
| 43 | Drugs/Dissociatives/MXE | 408 | 95 | Drug paraphernalia/Injecting equipment/Other | 30 |
| 44 | Tobacco/Smoked | 393 | 96 | Tobacco/Paraphernalia | 27 |
| 45 | Counterfeits/Money | 387 | 97 | Info/eBooks/Politics | 26 |
| 46 | Counterfeits/Clothing | 364 | 98 | Info/eBooks/Philosophy | 25 |
| 47 | Data/Software | 356 | 99 | Drug paraphernalia/Injecting equipment/Needles | 15 |
| 48 | Weapons/Lethal firearms | 344 | 100 | Weapons/Fireworks | 14 |
| 49 | Drugs/Ecstasy/MDA | 329 | 101 | Info/eBooks/Aliens/UFOs | 10 |
| 50 | Forgeries/Scans/Photos | 327 | 102 | Forgeries | 8 |
| 51 | Info/eBooks/Making money | 313 | 103 | Drug paraphernalia/Injecting equipment/Filters | 6 |
| 52 | Info/eBooks/Drugs | 289 | 104 | Drugs/Dissociatives/PCP | 4 |
| Target | Meaning | Category |
|---|---|---|
| 1 | Cybercrime | Services/Hacking |
| Services/Money | ||
| Electronics | ||
| Data/Accounts | ||
| Data/Software | ||
| Data/Pirated | ||
| 2 | Can’t say if cybercrime | Services/Other |
| Forgeries/Physical documents | ||
| Forgeries/Other | ||
| Forgeries/Scans/Photos | ||
| Information/Guides | ||
| Information/eBooks | ||
| Info/eBooks/Making money | ||
| Info/eBooks/Other | ||
| Info/eBooks/Anonymity | ||
| Other | ||
| 0 | Not cybercrime | Rest of the categories |
| Item | Specification |
|---|---|
| CPU | AMD Radeon (TM) Graphics |
| GPU | NVIDIA GeForce RTX 3060 |
| RAM | 16 GB |
| CUDA | CUDA 11.7 + CuDNN8.4.1.50 |
| OS | Windows 11 |
| Python | Version 3.10 |
| TensorFlow | Version 2.10.1 |
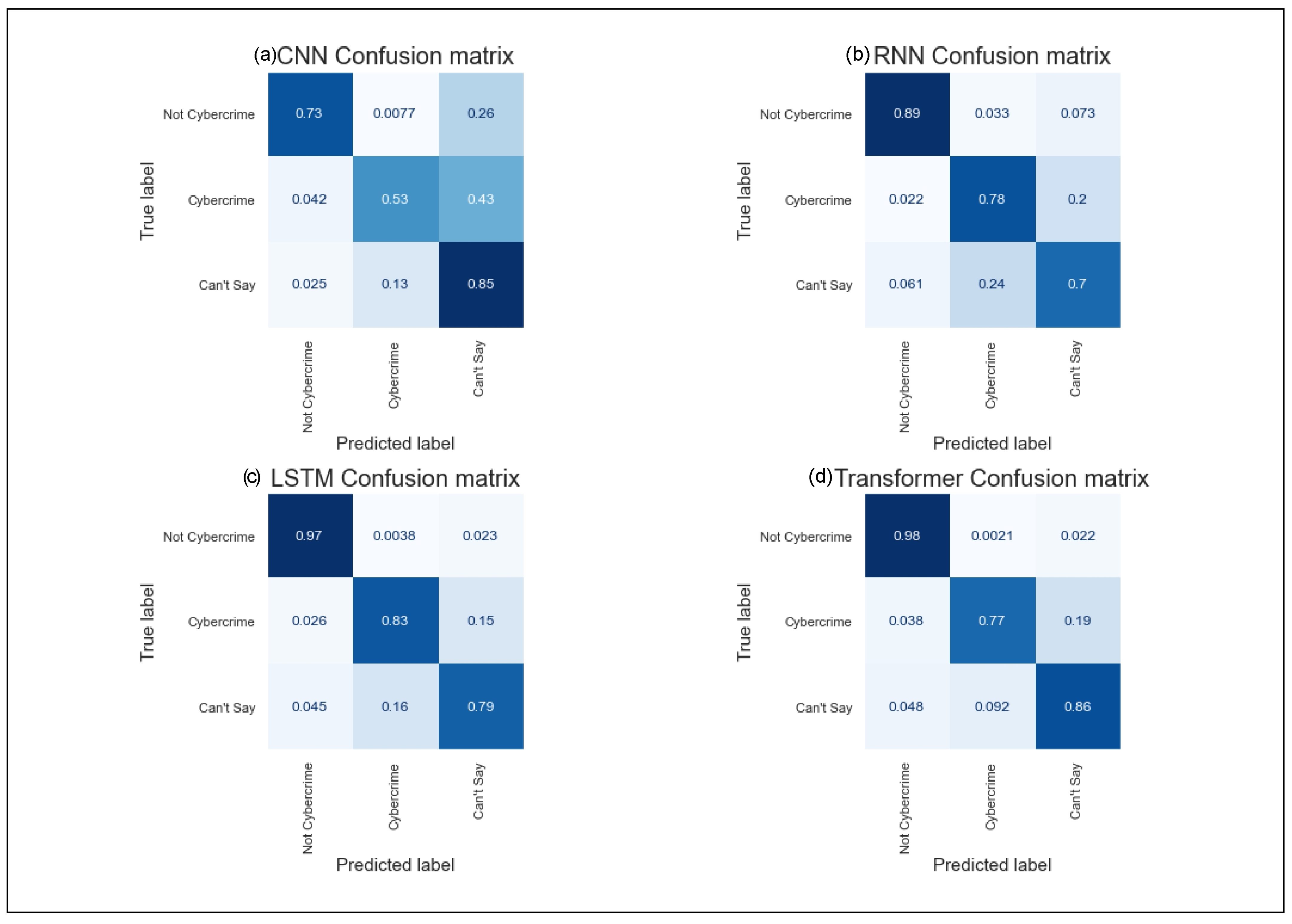
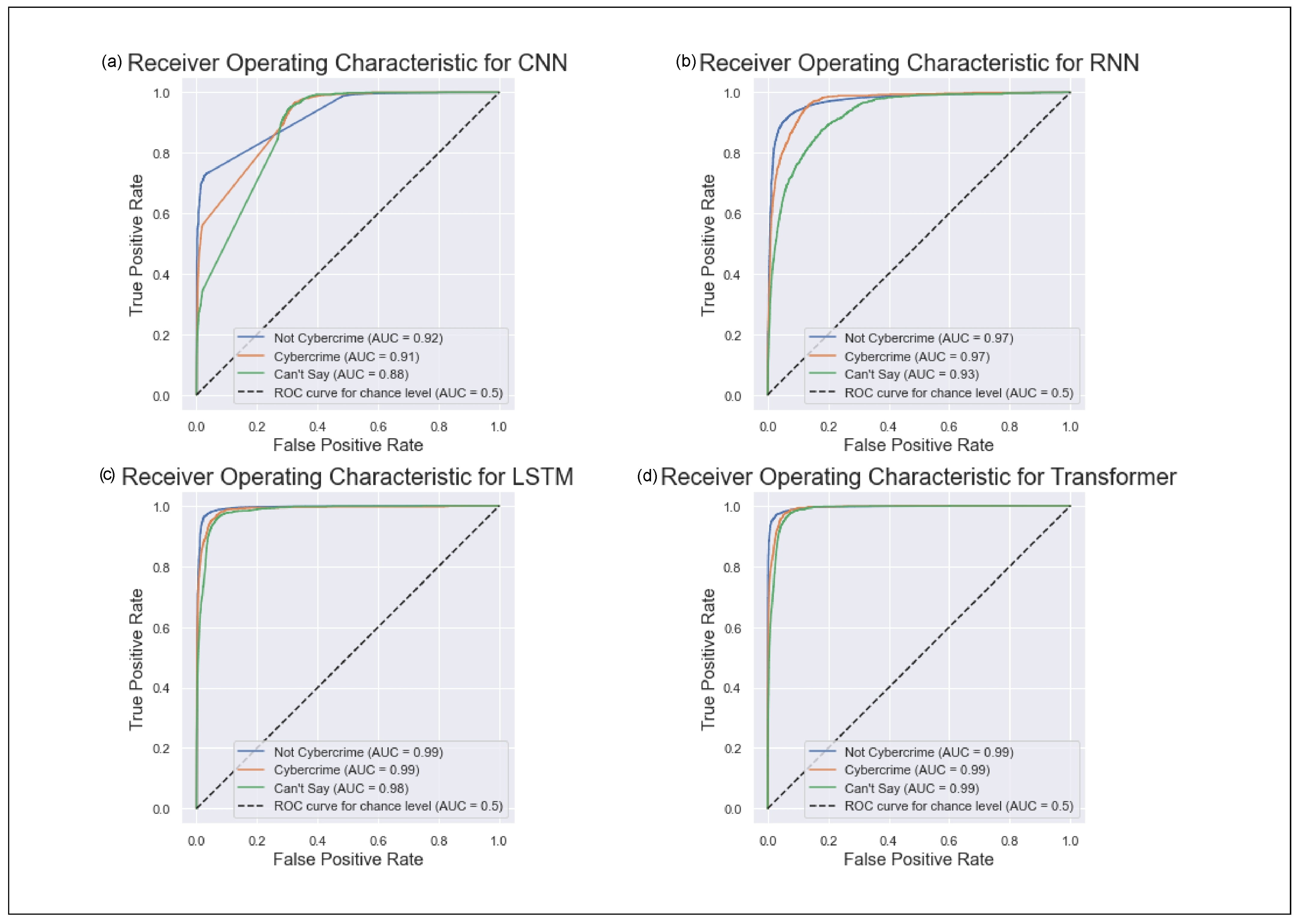
| Model | Target Class | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|---|
| CNN | Can’t Say | 0.17 | 0.85 | 0.28 | 0.73 |
| Cybercrime | 0.6 | 0.53 | 0.56 | ||
| Not Cybercrime | 0.99 | 0.73 | 0.84 | ||
| RNN | Can’t Say | 0.37 | 0.7 | 0.48 | 0.88 |
| Cybercrime | 0.43 | 0.78 | 0.55 | ||
| Not Cybercrime | 0.99 | 0.89 | 0.94 | ||
| LSTM | Can’t Say | 0.64 | 0.79 | 0.71 | 0.96 |
| Cybercrime | 0.72 | 0.83 | 0.77 | ||
| Not Cybercrime | 1 | 0.97 | 0.98 | ||
| BERT | Can’t Say | 0.65 | 0.86 | 0.74 | 0.96 |
| Cybercrime | 0.81 | 0.77 | 0.79 | ||
| Not Cybercrime | 0.99 | 0.98 | 0.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sangher, K.S.; Singh, A.; Pandey, H.M.; Kumar, V. Towards Safe Cyber Practices: Developing a Proactive Cyber-Threat Intelligence System for Dark Web Forum Content by Identifying Cybercrimes. Information 2023, 14, 349. https://doi.org/10.3390/info14060349
Sangher KS, Singh A, Pandey HM, Kumar V. Towards Safe Cyber Practices: Developing a Proactive Cyber-Threat Intelligence System for Dark Web Forum Content by Identifying Cybercrimes. Information. 2023; 14(6):349. https://doi.org/10.3390/info14060349
Chicago/Turabian StyleSangher, Kanti Singh, Archana Singh, Hari Mohan Pandey, and Vivek Kumar. 2023. "Towards Safe Cyber Practices: Developing a Proactive Cyber-Threat Intelligence System for Dark Web Forum Content by Identifying Cybercrimes" Information 14, no. 6: 349. https://doi.org/10.3390/info14060349
APA StyleSangher, K. S., Singh, A., Pandey, H. M., & Kumar, V. (2023). Towards Safe Cyber Practices: Developing a Proactive Cyber-Threat Intelligence System for Dark Web Forum Content by Identifying Cybercrimes. Information, 14(6), 349. https://doi.org/10.3390/info14060349