
Text to Causal Knowledge Graph: A Framework to Synthesize Knowledge from Unstructured Business Texts into Causal Graphs

 , , and
, , and 
Abstract
:1. Introduction
Contributions in This Article
- We created a new annotated dataset of cause-and-effect relationships and performance term classifications, based on the S&P Financial Company 10-K reports.
- We created a pipeline to automatically read a text document and process it to create a knowledge graph.
- We compared the extracted causalities against a domain taxonomy and classified the extracted causalities.
- We developed a novel approach to bridge machine reading with domain expertise (e.g., a pre-built taxonomy from domain experts).
- The presented architecture can be used as a framework for extracting causal information in other domains, for example, in medical texts.
2. Related Work
3. Data
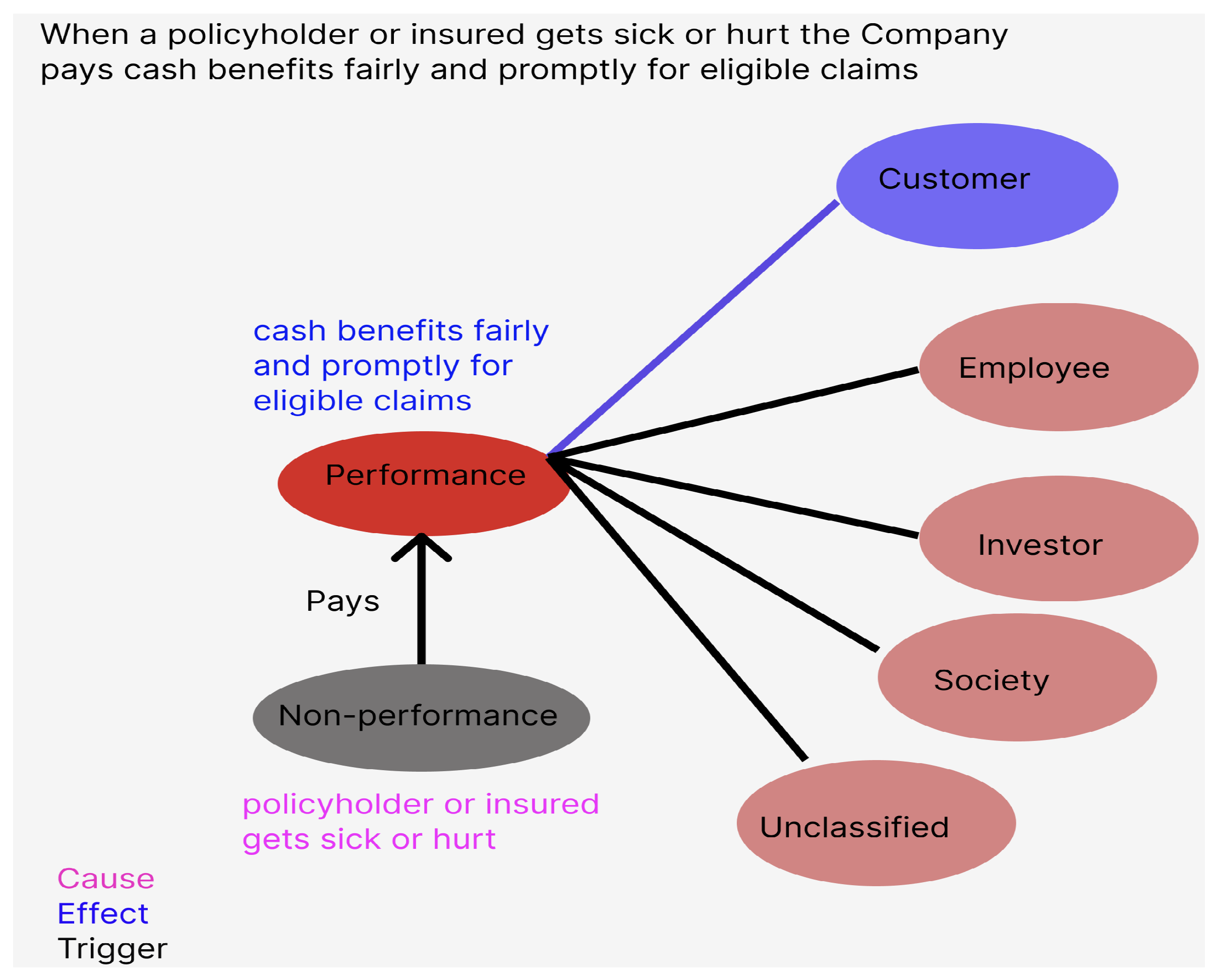
<causal-relation> When a <cause> policyholder or insured person becomes sick or hurt </cause>, the Company <trigger> pays </trigger> <outcome> cash benefits fairly and promptly for eligible claims </outcome> </causal-relation>.
Due to the size of Aflac Japan, where functional currency is the Japanese yen, fluctuations in the exchange rate between the yen and the U.S. dollar can have a significant effect on the Company’s reported financial position and results of operations. (⋯) claims and most expenses are paid in yen. (⋯) yen-denominated assets and U.S. dollar-denominated assets, which may be hedged to yen, (⋯)
4. Methodology
| Algorithm 1 Text to Knowledge Graph. The sample output of Algorithm 1 is shown in Figure 2. |
|
4.1. Data Preparation and Preprocessing
4.2. Machine Learning for Automatic Causal Sentence Detection and Extraction
4.3. Machine Learning for Automatic Causality Extraction
4.4. Automatic Classification of Causes and Effects into a Stakeholder Taxonomy
4.5. Visualizing the Output
5. Error Analysis
Input text: Over time, certain sectors of the financial services industry have become more concentrated as institutions involved in a broad range of financial services have been acquired by or merged into other firms. These developments could result in the Company’s competitors gaining greater capital and other resources, such as a broader range of products and services and geographic diversity. The Company may experience pricing pressures as a result of these factors and as some of its competitors seek to increase market share by reducing prices or paying higher rates of interest on deposits.
Step 1 (extracting causal sentences using BERT) produces:
The Company may experience pricing pressures as a result of these factors and as some of its competitors seek to increase market share by reducing prices or paying higher rates of interest on deposits.
Step 2: Extract causalities (which part of the sentence is cause/effect in the classified causal sentence in Step 1, above)
Gold data:
O E E E E E CT CT CT O O C O O O O O C C C C C C C C C C C C C C C C C
Prediction:
E E E E E E CT CT CT O O C O O E E C E E E E E E E E E E E E E E E E
Input text: In times of market stress, unanticipated market movements, or unanticipated claims experience resulting from greater than expected morbidity, mortality, longevity, or persistency, the effectiveness of the Company’s risk management strategies may be limited, resulting in losses to the Company. Under difficult or less liquid market conditions, the Company’s risk management strategies may be ineffective or more difficult or expensive to execute because other market participants may be using the same or similar strategies to manage risk.
Step 1: Classify whether a sentence is causal or not using the transformer-based model (BERT):
Under difficult or less liquid market conditions, the Company’s risk management strategies may be ineffective or more difficult or expensive to execute because other market participants may be using the same or similar strategies to manage risk.
Step 2: Extract causalities, i.e., which part of the sentence is cause/effect in the classified causal sentence in Step 1.
Gold data:
O O O O O O O C C C C C C C C C C C C C C C C CT E E E E E E E E E E E E E E
Prediction:
O C C C C E E E E E E E E E E E E E E E E E E CT C C C C C C C C C C C C C C
Input text: If the contractual counterparty made a claim against the receivership (or conservatorship) for breach of contract, the amount paid to the counterparty would depend upon, among other factors, the receivership (or conservatorship) assets available to pay the claim and the priority of the claim relative to others. In addition, the FDIC may enforce most contracts entered into by the insolvent institution, notwithstanding any provision that would terminate, cause a default, accelerate, or give other rights under the contract solely because of the insolvency, the appointment of the receiver (or conservator), or the exercise of rights or powers by the receiver (or conservator).
Step 1: The causal label is produced using the transformer-based model (BERT): In addition, the FDIC may enforce most contracts entered into by the insolvent institution, notwithstanding any provision that would terminate, cause a default, accelerate, or give other rights.
Step 2: Extract causalities (which part of the sentence is cause/effect in the classified causal sentence in Step 1)
Gold data:
O O C C C C C C C C C C C C C C C C C C CT O E E E E E E
Prediction—DistilBERT:
O O O E O C C C C C C C C C C C C C C C C C E E E E E E
Prediction—SpanBERT:
O O C C C C C C C C C C C C C C C C C C CT E E E E E E E
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| NLP | Natural Language Processing |
| IFAC | International Federation of Accountants |
| CSR | Corporate Social Responsibility |
| ESG | Environmental, Social, and Governance |
| SEM | Structural Equation Modeling |
| SCITE | Self-attentive BiLSTM-CRF wIth Transferred Embeddings |
| BiLSTM-CRF | Bidirectional Long Short-Term Memory-Conditional Random Field |
| CNN | Convolutional neural network |
| NLTK | Natural Language Toolkit |
| SEC | Securities and Exchange Commission |
| BERT | Bidirectional Encoder Representations from Transformers |
Appendix A

{kind=link}
{kind=link}
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Class 0: Negative class with all cases of a causal trigger where the sentence does not contain a causal relation and random sample of sentences without causal relations and without causal triggers | 0.91 | 0.86 | 0.88 |
| Class 1: Positive class, consisting of sentences that contain causal relations | 0.86 | 0.91 | 0.89 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Class 0: Negative class with all cases of a causal trigger where the sentence does not contain a causal relation | 0.91 | 0.83 | 0.87 |
| Class 1: Positive class, which consists of sentences that contain causal relations | 0.85 | 0.92 | 0.88 |
Appendix B
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Beginning of effect | 0.67 | 0.06 | 0.10 |
| Beginning of cause | 0.68 | 0.27 | 0.39 |
| Inside of cause | 0.76 | 0.83 | 0.79 |
| Inside of causal trigger | 0.76 | 0.95 | 0.84 |
| Inside of effect | 0.72 | 0.94 | 0.82 |
| Beginning of causal trigger | 0.89 | 0.85 | 0.87 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Beginning of effect | 0.62 | 0.63 | 0.62 |
| Beginning of cause | 0.56 | 0.59 | 0.57 |
| Inside of cause | 0.78 | 0.87 | 0.83 |
| Inside of causal trigger | 0.94 | 0.96 | 0.95 |
| Inside of effect | 0.84 | 0.90 | 0.87 |
| Beginning of causal trigger | 0.94 | 0.96 | 0.95 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Beginning of effect | 1.00 | 0.00 | 0.00 |
| Beginning of cause | 0.83 | 0.02 | 0.04 |
| Inside of cause | 0.70 | 0.87 | 0.77 |
| Inside of causal trigger | 0.63 | 0.70 | 0.66 |
| Inside of effect | 0.71 | 0.91 | 0.80 |
| Beginning of causal trigger | 0.74 | 0.67 | 0.70 |
Appendix C
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Cause | 0.49 | 0.28 | 0.36 |
| Causal trigger | 0.05 | 0.05 | 0.05 |
| Effect | 0.47 | 0.38 | 0.42 |
| Precision | Recall | F1-Score | |
|---|---|---|---|
| Non-Performance | 0.72 | 0.80 | 0.76 |
| Performance | 0.12 | 0.08 | 0.10 |
References
- IFAC; International Federation of Accountants. Regulatory Divergence: Costs, Risks and Impacts. 2018. Available online: https://www.ifac.org/knowledge-gateway/contributing-global-economy/publications/regulatory-divergence-costs-risks-and-impacts (accessed on 26 April 2023).
- Khan, M.; Serafeim, G.; Yoon, A. Corporate sustainability: First evidence on materiality. Account. Rev. 2016, 91, 1697–1724. [Google Scholar] [CrossRef] [Green Version]
- Naughton, J.P.; Wang, C.; Yeung, I. Investor sentiment for corporate social performance. Account. Rev. 2019, 94, 401–420. [Google Scholar] [CrossRef]
- Green, W.J.; Cheng, M.M. Materiality judgments in an integrated reporting setting: The effect of strategic relevance and strategy map. Account. Organ. Soc. 2019, 73, 1–14. [Google Scholar] [CrossRef]
- Yang, J.; Han, S.C.; Poon, J. A survey on extraction of causal relations from natural language text. Knowl. Inf. Syst. 2022, 64, 1161–1186. [Google Scholar] [CrossRef]
- Radinsky, K.; Davidovich, S.; Markovitch, S. Learning causality for news events prediction. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 909–918. [Google Scholar]
- Ittoo, A.; Bouma, G. Minimally-supervised learning of domain-specific causal relations using an open-domain corpus as knowledge base. Data Knowl. Eng. 2013, 88, 142–163. [Google Scholar] [CrossRef]
- Kang, N.; Singh, B.; Bui, C.; Afzal, Z.; van Mulligen, E.M.; Kors, J.A. Knowledge-based extraction of adverse drug events from biomedical text. BMC Bioinform. 2014, 15, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pechsiri, C.; Kawtrakul, A.; Piriyakul, R. Mining Causality Knowledge from Textual Data. In Proceedings of the Artificial Intelligence and Applications, Innsbruck, Austria, 13–16 February 2006; pp. 85–90. [Google Scholar]
- Keskes, I.; Zitoune, F.B.; Belguith, L.H. Learning explicit and implicit arabic discourse relations. J. King Saud-Univ.-Comput. Inf. Sci. 2014, 26, 398–416. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Mou, L.; Li, G.; Chen, Y.; Peng, H.; Jin, Z. Classifying relations via long short term memory networks along shortest dependency paths. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1785–1794. [Google Scholar]
- Li, Z.; Li, Q.; Zou, X.; Ren, J. Causality extraction based on self-attentive BiLSTM-CRF with transferred embeddings. Neurocomputing 2021, 423, 207–219. [Google Scholar] [CrossRef]
- Wang, L.; Cao, Z.; De Melo, G.; Liu, Z. Relation classification via multi-level attention cnns. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1298–1307. [Google Scholar]
- Garcia, D.; EDF-DER; IMA-TIEM. COATIS, an NLP system to locate expressions of actions connected by causality links. In Proceedings of the Knowledge Acquisition, Modeling and Management: 10th European Workshop, EKAW’97, Sant Feliu de Guixols, Catalonia, Spain, 15–18 October 1997; Proceedings 10. pp. 347–352. [Google Scholar]
- Khoo, C.S.; Chan, S.; Niu, Y. Extracting causal knowledge from a medical database using graphical patterns. In Proceedings of the 38th Annual Meeting of The Association for Computational Linguistics, Hing Kong, China, 3–6 October 2000; pp. 336–343. [Google Scholar]
- Pakray, P.; Gelbukh, A. An open-domain cause-effect relation detection from paired nominals. In Proceedings of the Nature-Inspired Computation and Machine Learning: 13th Mexican International Conference on Artificial Intelligence, MICAI 2014, Tuxtla Gutiérrez, Mexico, 16–22 November 2014; Proceedings, Part II 13. pp. 263–271. [Google Scholar]
- Smirnova, A.; Cudré-Mauroux, P. Relation extraction using distant supervision: A survey. ACM Comput. Surv. (CSUR) 2018, 51, 1–35. [Google Scholar] [CrossRef]
- Marcu, D.; Echihabi, A. An unsupervised approach to recognizing discourse relations. In Proceedings of the 40th Annual Meeting of The Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 368–375. [Google Scholar]
- Jin, X.; Wang, X.; Luo, X.; Huang, S.; Gu, S. Inter-sentence and implicit causality extraction from chinese corpus. In Proceedings of the Advances in Knowledge Discovery and Data Mining: 24th Pacific-Asia Conference, PAKDD 2020, Singapore, 11–14 May 2020; Proceedings, Part I 24. pp. 739–751. [Google Scholar]
- Oh, J.H.; Torisawa, K.; Hashimoto, C.; Sano, M.; De Saeger, S.; Ohtake, K. Why-question answering using intra-and inter-sentential causal relations. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Sofia, Bulgaria, 4–9 August 2013; pp. 1733–1743. [Google Scholar]
- Girju, R. Automatic detection of causal relations for question answering. In Proceedings of the ACL 2003 Workshop on Multilingual Summarization and Question Answering, Sapporo, Japan, 11 July 2003; pp. 76–83. [Google Scholar]
- Martínez-Cámara, E.; Shwartz, V.; Gurevych, I.; Dagan, I. Neural disambiguation of causal lexical markers based on context. In Proceedings of the IWCS 2017—12th International Conference on Computational Semantics—Short Papers, Montpellier, France, 19–22 September 2017. [Google Scholar]
- Ittoo, A.; Bouma, G. Extracting explicit and implicit causal relations from sparse, domain-specific texts. In Proceedings of the Natural Language Processing and Information Systems: 16th International Conference on Applications of Natural Language to Information Systems, NLDB 2011, Alicante, Spain, 28–30 June 2011; Proceedings 16. pp. 52–63. [Google Scholar]
- Akbik, A.; Bergmann, T.; Blythe, D.; Rasul, K.; Schweter, S.; Vollgraf, R. FLAIR: An easy-to-use framework for state-of-the-art NLP. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), Minneapolis, MN, USA, 2–7 June 2019; pp. 54–59. [Google Scholar]
- Li, P.; Mao, K. Knowledge-oriented convolutional neural network for causal relation extraction from natural language texts. Expert Syst. Appl. 2019, 115, 512–523. [Google Scholar] [CrossRef]
- Hendrickx, I.; Kim, S.N.; Kozareva, Z.; Nakov, P.; Séaghdha, D.O.; Padó, S.; Pennacchiotti, M.; Romano, L.; Szpakowicz, S. Semeval-2010 task 8: Multi-way classification of semantic relations between pairs of nominals. arXiv 2019, arXiv:1911.10422. [Google Scholar]
- Mirza, P. Extracting temporal and causal relations between events. In Proceedings of the ACL 2014 Student Research Workshop, Baltimore, MD, USA, 22–27 June 2014; pp. 10–17. [Google Scholar]
- Caselli, T.; Vossen, P. The event storyline corpus: A new benchmark for causal and temporal relation extraction. In Proceedings of the Events and Stories in the News Workshop, Vancouver, BC, Canada, 4 August 2017; pp. 77–86. [Google Scholar]
- Fischbach, J.; Springer, T.; Frattini, J.; Femmer, H.; Vogelsang, A.; Mendez, D. Fine-grained causality extraction from natural language requirements using recursive neural tensor networks. In Proceedings of the 2021 IEEE 29th International Requirements Engineering Conference Workshops (REW), Notre Dame, IN, USA, 20–24 September 2021; pp. 60–69. [Google Scholar]
- Socher, R.; Lin, C.C.; Manning, C.; Ng, A.Y. Parsing natural scenes and natural language with recursive neural networks. In Proceedings of the 28th international conference on machine learning (ICML-11), Bellevue, DC, USA, 28 June–2 July 2011; pp. 129–136. [Google Scholar]
- Lyu, C.; Ji, T.; Sun, Q.; Zhou, L. DCU-Lorcan at FinCausal 2022: Span-based Causality Extraction from Financial Documents using Pre-trained Language Models. In Proceedings of the 4th Financial Narrative Processing Workshop@ LREC2022, Marseille, France, 20–25 June 2022; pp. 116–120. [Google Scholar]
- Ancin-Murguzur, F.J.; Hausner, V.H. causalizeR: A text mining algorithm to identify causal relationships in scientific literature. PeerJ 2021, 9, e11850. [Google Scholar] [CrossRef]
- Kıcıman, E.; Ness, R.; Sharma, A.; Tan, C. Causal Reasoning and Large Language Models: Opening a New Frontier for Causality. arXiv 2023, arXiv:2305.00050. [Google Scholar]
- Fischbach, J.; Frattini, J.; Spaans, A.; Kummeth, M.; Vogelsang, A.; Mendez, D.; Unterkalmsteiner, M. Automatic detection of causality in requirement artifacts: The cira approach. In Proceedings of the Requirements Engineering: Foundation for Software Quality: 27th International Working Conference, REFSQ 2021, Essen, Germany, 12–15 April 2021; Proceedings 27. pp. 19–36. [Google Scholar]
- Barbaresi, A. Trafilatura: A web scraping library and command-line tool for text discovery and extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations, Bangkok, Thailand, 1–6 August 2021; pp. 122–131. [Google Scholar]
- Bird, S. NLTK: The natural language toolkit. In Proceedings of the COLING/ACL 2006 Interactive Presentation Sessions, Sydney, Australia, 17–18 July 2006; pp. 69–72. [Google Scholar]
- Barrett, E.; Paradis, J.; Perelman, L.C. The Mayfield Handbook of Technical & Scientific Writing; Mayfield Company: Mountain View, CA, USA, 1998. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Shi, P.; Lin, J. Simple bert models for relation extraction and semantic role labeling. arXiv 2019, arXiv:1904.05255. [Google Scholar]
- Lin, C.; Miller, T.; Dligach, D.; Bethard, S.; Savova, G. A BERT-based universal model for both within-and cross-sentence clinical temporal relation extraction. In Proceedings of the 2nd Clinical Natural Language Processing Workshop, Minneapolis, MN, USA, 7 June 2019; pp. 65–71. [Google Scholar]
- Souza, F.; Nogueira, R.; Lotufo, R. Portuguese named entity recognition using BERT-CRF. arXiv 2019, arXiv:1909.10649. [Google Scholar]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; et al. Large Language Models Encode Clinical Knowledge. arXiv 2020, arXiv:2212.13138. [Google Scholar]
- Si, C.; Gan, Z.; Yang, Z.; Wang, S.; Wang, J.; Boyd-Graber, J.; Wang, L. Prompting gpt-3 to be reliable. arXiv 2022, arXiv:2210.09150. [Google Scholar]
- Gao, J.; Ding, X.; Qin, B.; Liu, T. Is ChatGPT a Good Causal Reasoner? A Comprehensive Evaluation. arXiv 2023, arXiv:2305.07375. [Google Scholar]


| Level 1 | Level 2 | Level 2 Description |
|---|---|---|
| Performance (P) | Investors (INV) | The economic or financial outcomes for the firm, which benefit investors, shareholders, debtholders, or financiers. |
| Customers (CUS) | The value and utility of products/services the firm creates for, and delivers to, customers, clients, or users. | |
| Employees (EMP) | The benefits and welfare employees (workers and managers) receive from an organization. | |
| Society (SOC) | An organization’s efforts and impacts on addressing community, environmental, and general public concerns. | |
| Unclassified | ||
| Non-performance (NP) | Sentences which do not fall under a performance category. |
| P(Span) | R(Span) | F1(Span) | P(Distil) | R(Distil) | F1(Distil) | |
|---|---|---|---|---|---|---|
| Cause | 0.82 | 0.86 | 0.84 | 0.78 | 0.93 | 0.85 |
| Causal trigger | 0.93 | 0.97 | 0.95 | 0.77 | 0.86 | 0.81 |
| Effect | 0.86 | 0.90 | 0.88 | 0.88 | 0.94 | 0.91 |
| P(Span) | R(Span) | F1(Span) | P(Distil) | R(Distil) | F1(Distil) | |
|---|---|---|---|---|---|---|
| Cause | 0.83 | 0.88 | 0.85 | 0.79 | 0.87 | 0.83 |
| Causal trigger | 0.93 | 0.97 | 0.95 | 0.91 | 0.93 | 0.92 |
| Effect | 0.87 | 0.91 | 0.89 | 0.80 | 0.94 | 0.86 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Business Performance | 0.58 | 0.65 | 0.62 | 12532 |
| Business Non-performance | 0.94 | 0.93 | 0.94 | 1976 |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Customer | 0.11 | 0.06 | 0.08 | 31 |
| Employee | 0.61 | 0.52 | 0.56 | 204 |
| Investor | 0.56 | 0.70 | 0.62 | 1013 |
| Society | 0.22 | 0.11 | 0.15 | 35 |
| Unclassified | 0.36 | 0.32 | 0.34 | 693 |
| Business Non-performance | 0.94 | 0.93 | 0.94 | 12532 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gopalakrishnan, S.; Chen, V.Z.; Dou, W.; Hahn-Powell, G.; Nedunuri, S.; Zadrozny, W. Text to Causal Knowledge Graph: A Framework to Synthesize Knowledge from Unstructured Business Texts into Causal Graphs. Information 2023, 14, 367. https://doi.org/10.3390/info14070367
Gopalakrishnan S, Chen VZ, Dou W, Hahn-Powell G, Nedunuri S, Zadrozny W. Text to Causal Knowledge Graph: A Framework to Synthesize Knowledge from Unstructured Business Texts into Causal Graphs. Information. 2023; 14(7):367. https://doi.org/10.3390/info14070367
Chicago/Turabian StyleGopalakrishnan, Seethalakshmi, Victor Zitian Chen, Wenwen Dou, Gus Hahn-Powell, Sreekar Nedunuri, and Wlodek Zadrozny. 2023. "Text to Causal Knowledge Graph: A Framework to Synthesize Knowledge from Unstructured Business Texts into Causal Graphs" Information 14, no. 7: 367. https://doi.org/10.3390/info14070367
APA StyleGopalakrishnan, S., Chen, V. Z., Dou, W., Hahn-Powell, G., Nedunuri, S., & Zadrozny, W. (2023). Text to Causal Knowledge Graph: A Framework to Synthesize Knowledge from Unstructured Business Texts into Causal Graphs. Information, 14(7), 367. https://doi.org/10.3390/info14070367