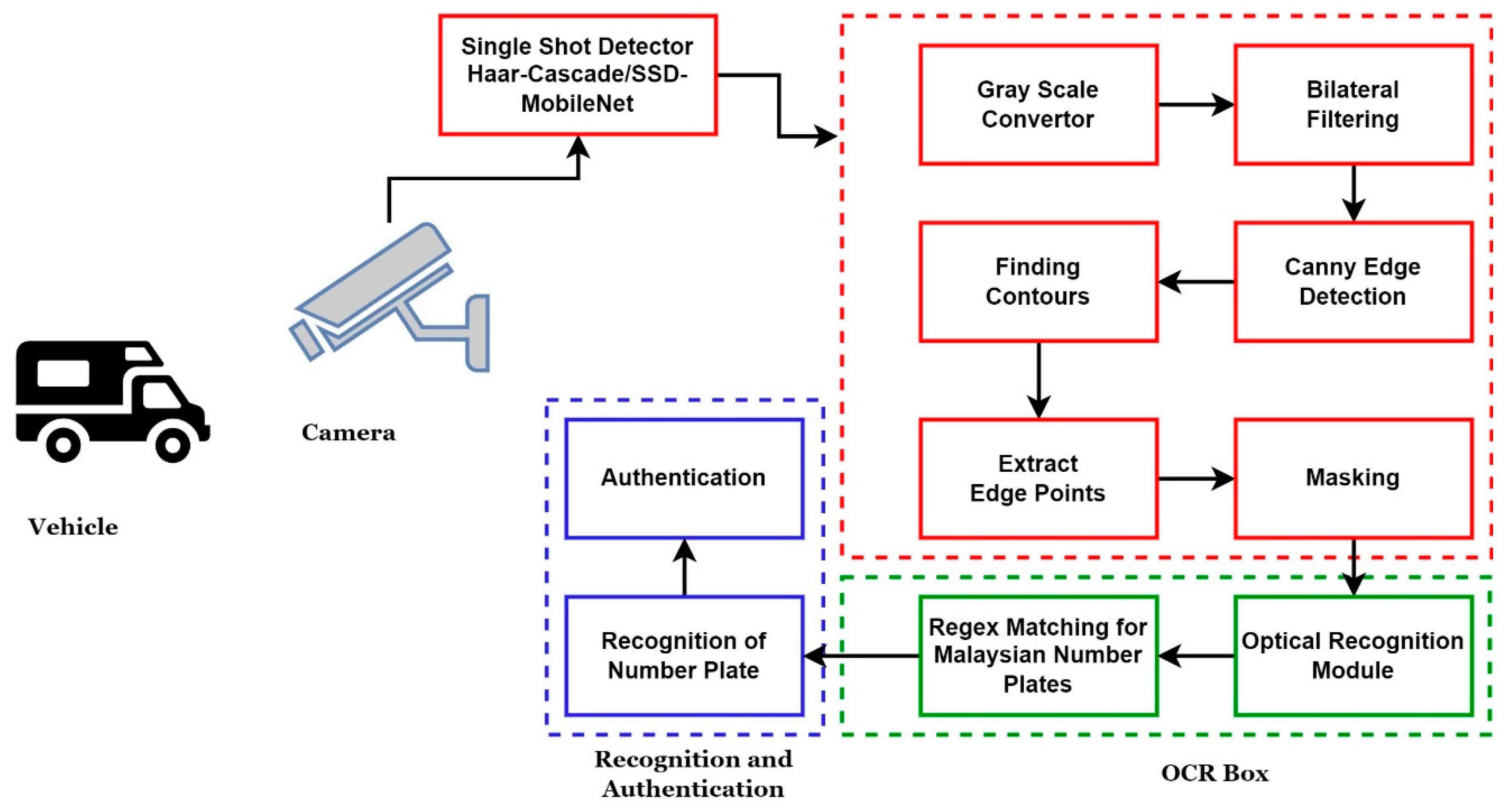
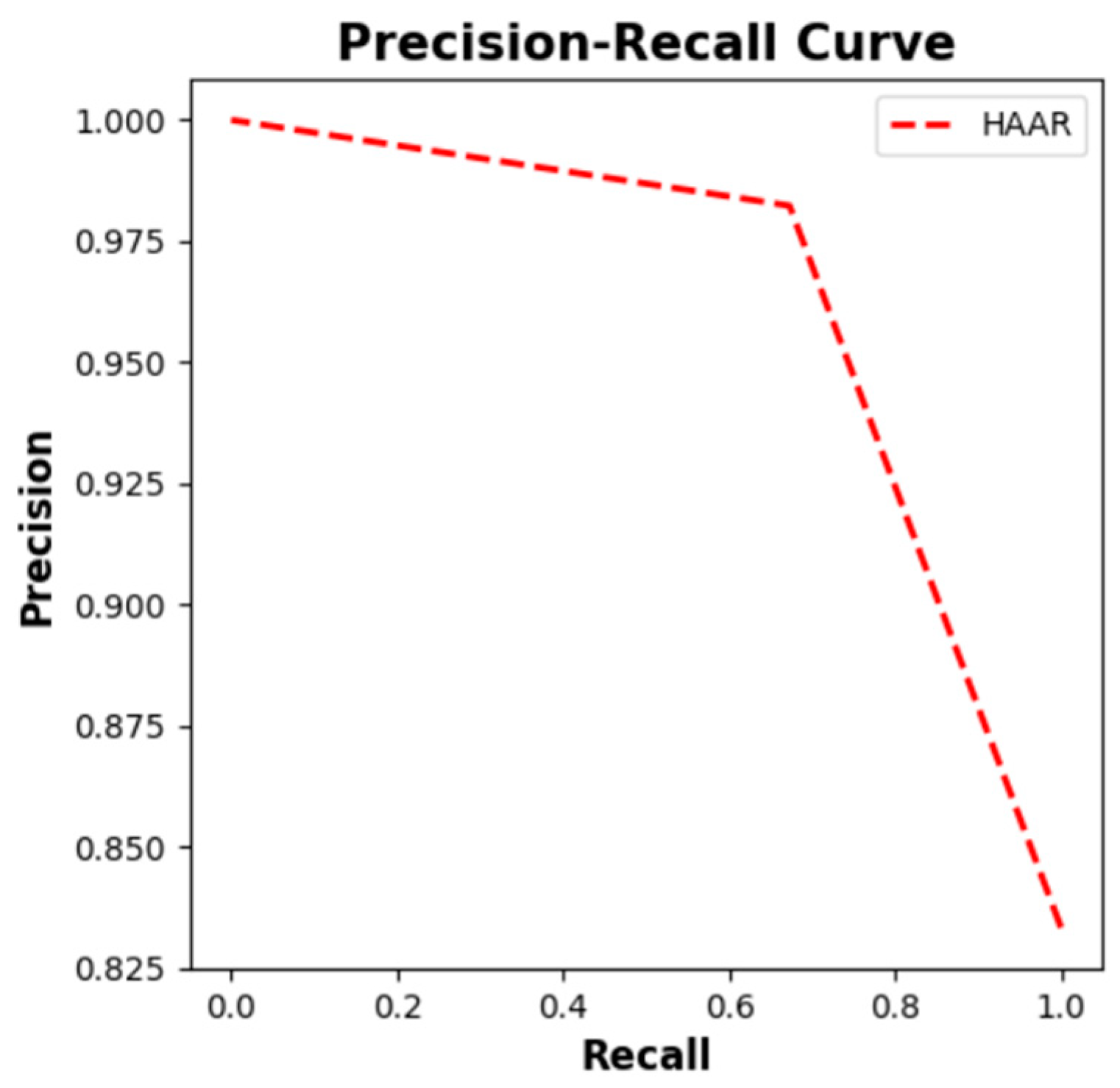
We are proposing a novel hybrid approach for automated number plate recognition (ANPR) that combines Haar cascade object detectors, MobileNet-SSD, and a new optical character reader mechanism for character identification on number plates. There are three broad segments when it comes to segmenting ANPR.
The details of each component are given below.
3.2. Mobile Architecture
MobileNet object detection component provides us with a class index of the objects along with their respective prediction probabilities and bounding box edges. We filter out our desired class objects with a more than 0.65 prediction probability. For object detection, we are implementing SSD-MobileNet. SSD single-shot multi-box detection is a neural network architecture designed to detect object classes, which means the extraction of bounding boxes and object classification occurs in one go. The author of this novel study has mentioned the use of the VGG neural network as the base network, which is the feature extractor for detection [
43], on top of SSD architecture. Therefore, two types of deep neural network, namely a combination of a base network and detection network, are being used here. The high-level features for classification objects come from the base network. To reduce the model size and complexities, depthwise separable convolution is used. It is used for classification purposes, to extract features for detection. As shown in
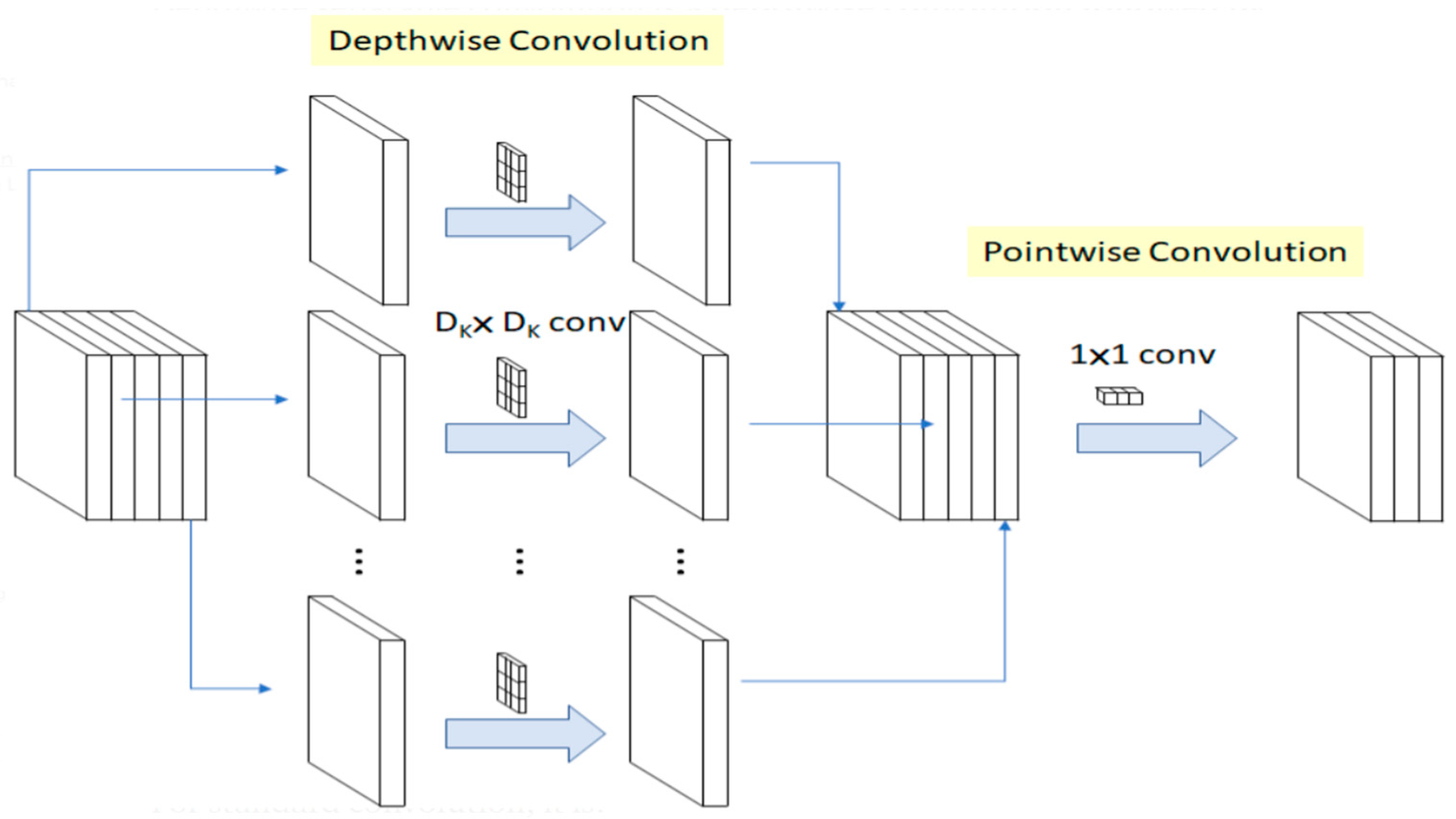
Figure 2, we can see that depthwise convolution is followed by pointwise convolution.
Depthwise convolution is the channel-wise spatial convolution. For 5 channels, we have 5 × spatial convolution. Pointwise convolution is always 1 × 1 Conv. This is to change the dimension of the channel. Convolution is always a product of two functions that produces a third function which can be seen as an altered version of the first function. Let us suppose that we have two functions, j, and k. The second function, k, is considered the filter. A spatial convolution operation is when the f function is defined on a variable (spatial), like x, rather than a time (t). Convolution for functions j(x) and k(x) on a variable x is shown in Equation (4).
In the case of images, the functions are always of two variables. In image processing, the image made by the lens is always a continuous function. Thus, the function happens to be j(x, y). In those cases, a smoothing filter is applied, k(x, y) and we obtain Equation (5) as follows:
where * represents the convolution operation.
By referring to
Figure 2, we can find the equation of depthwise convolution and pointwise convolution. As shown in Expression (6), the first part is referring to depthwise operation and the second part is referring to pointwise operation. Here, M indicates the number of in channels, N represents the number of out channels,
is the kernel size and
is the feature map size [
12].
Expression (7) denotes standard convolution operation. When we divide Expression (6) by Expression (7), we obtain the total computational/operational reduction. When we apply architecture for a 3 × 3 kernel size, we can achieve 8–9 times less computation by this method.
Single-shot detection has two components, including a base network, which in our case is MobileNet, for extracted feature mapping. Another component is to apply a convolution filter to detect objects [
43].
MobileNet provides us with all the required feature maps. The six-layer convolution network performs the classification detection of the object class. The architecture can make 8732 predictions per object class. The architecture checks the confidence score of each box of 8732 predictions per object class and will pick only the top 200 predictions from the image. This is handled with the help of non-max suppression which selects a few entities out of overlapping entities based on probability. The calculation for reference is provided. At Conv4_3, it is of size 38 × 38 × 512.
A 3 × 3 kernel convolution is applied. There are 4 bounding boxes, and each bounding box will have (classes + 4) outputs. Classes cannot be zero. In at least one class, the background is always included. Thus, at Conv4_3, the output is 38 × 38 × 4 × (class + 4). Let us suppose that there are ten object classes. By default, one background class is always inclusive. Then, the output will be 38 × 38 × 4 × (10 + 1 + 4) = 86,640. Thus, for the bounding box calculation,
Table 2 presents the total number of bounding boxes (that add up to 8732) which is our prediction probability per object class. It means that we require 4 to 6 bounded boxes for the detection of the object in the image.
In object detection, the architecture not only predicts object classes but also locates their bounding boxes. The subtle difference between object classification and object detection is that in the case of object classification, the prediction is about if the class of object is present or not. But for object detection, not only does it provide prediction probability of the object class but also the boundary location of the object. Instead of using normal sliding window operation for convolution networks, a single-shot detector divides the image into multiple regions, like a grid. Every individual grid is tasked with detecting objects in that particular region of an image. If there is no object detected in a particular grid, then we consider it null, and that particular location is ignored.
There are possibilities of certain scenarios where there are many objects in a single grid or there are multiple objects of different sizes and shapes that need to be detected. To handle this, we have an anchor. These are also known as ground truth boxes. While training, the matching phase anchors boxes are connected to the bounding boxes of every ground truth object within a frame. Anchor boxes are predefined, precalculated, fixed regions of probable space, and approximate box predictions. The highest region of overlap with the anchor box determines the object’s class, its probability, and its location. This is the base principle of training the network and predicting the detected class of objects and their locations. In practice, each anchor box is specified by an aspect ratio. Aspect ratios of anchor boxes are pre-defined in single-shot detection architecture. This allows for accommodating different sizes and shapes of objects.
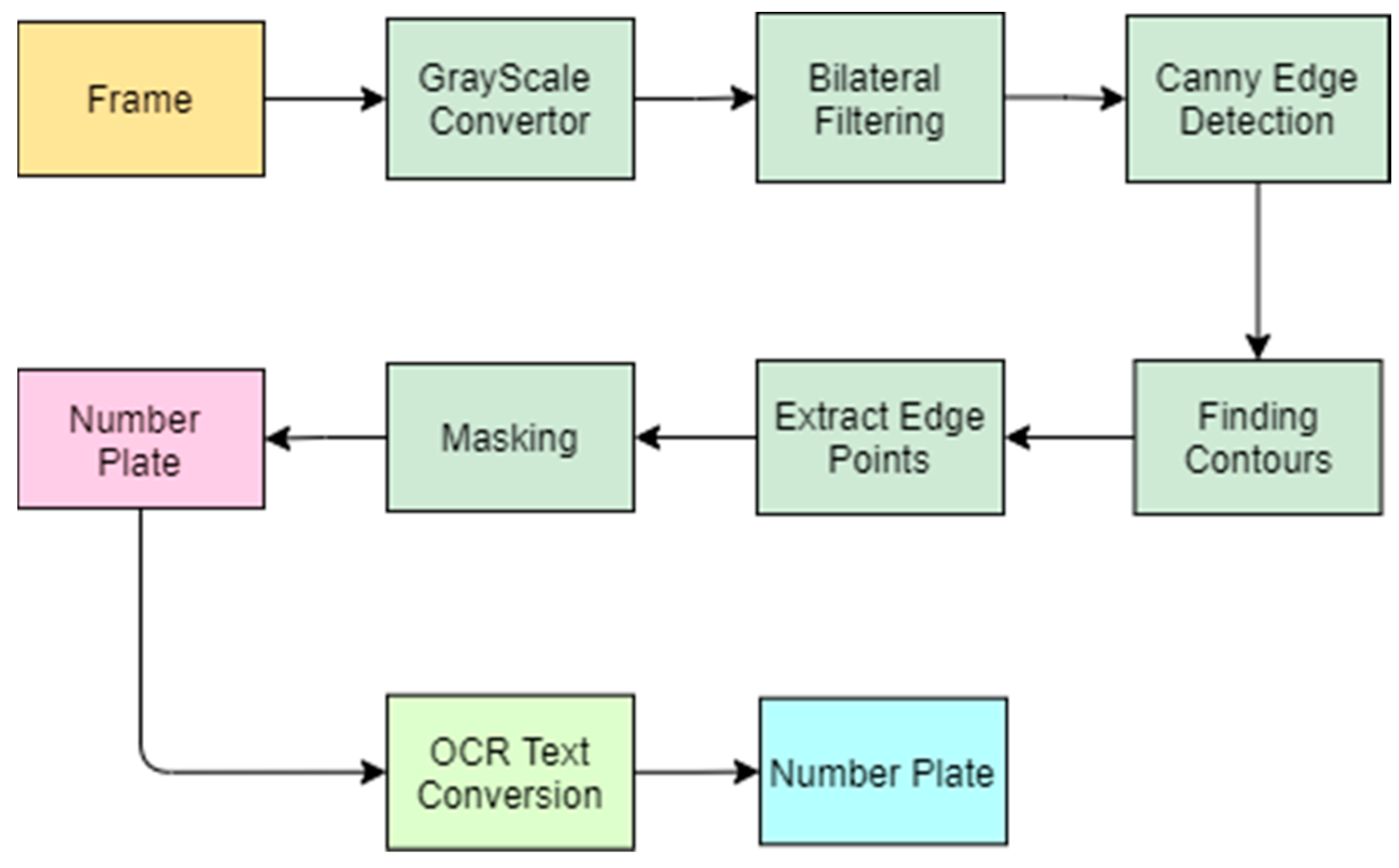
Once we have the desired frame with our intended class object, we have to find out our candidate region and number plate section. The series of steps that are required to extract the number plate region is shown in
Figure 3.
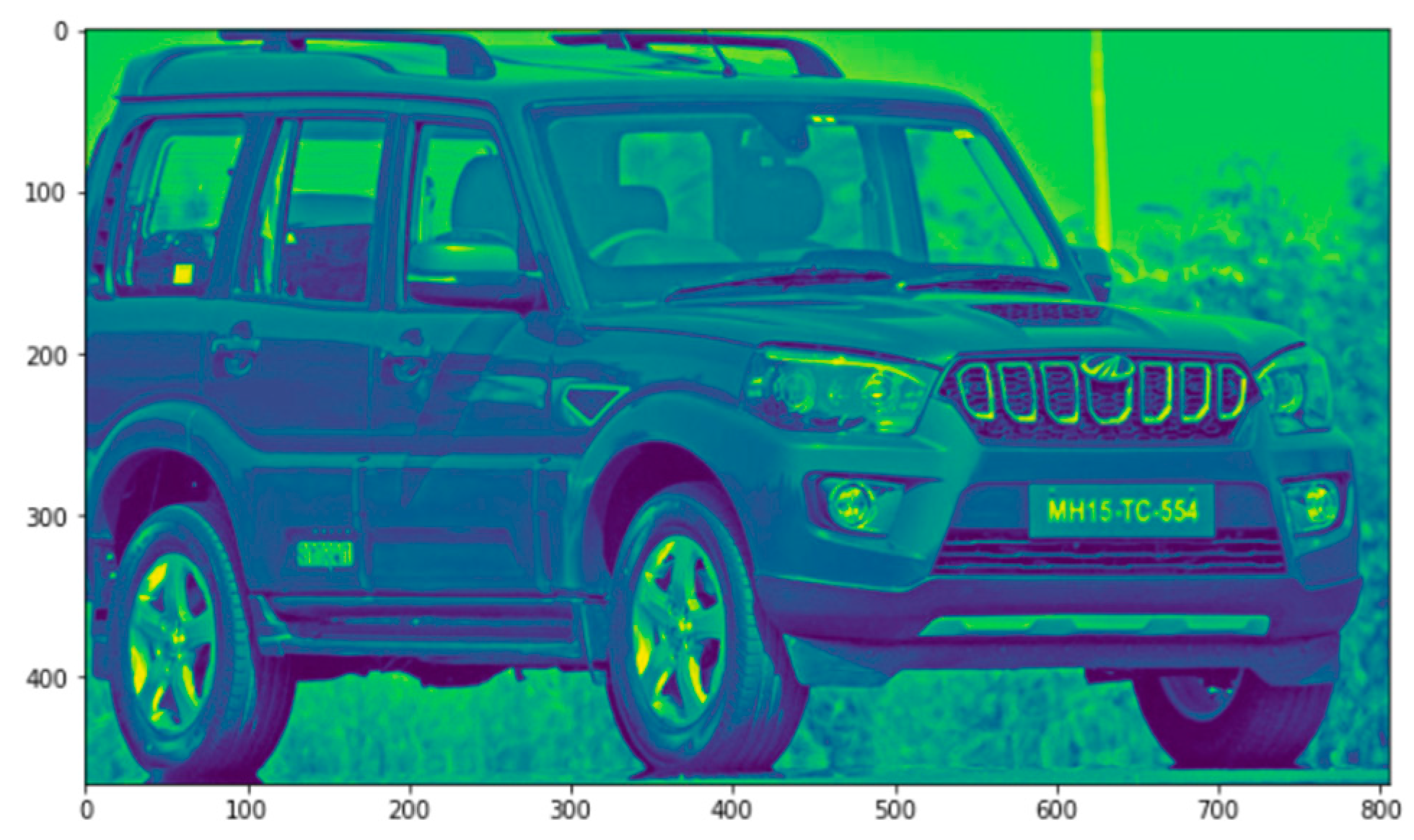
In
Figure 4, we can see our reference image. We need to convert the frame to grayscale, as shown in
Figure 5. This is very important as the consequent steps cannot be performed without this.
Next, we proceed with the bilateral filtering process as shown in
Figure 6. A bilateral filter is used for reducing noise and smoothing images. Other denoising filters are present, like the average filter, median filter, and Gaussian filter. The bilateral filter retains the edges while the Gaussian filter uniformly blurs the content and edges together.
A canny edge detector is used for detecting edges as shown in
Figure 7. A prerequisite for a canny edge is to have a noise-reduced image, which we already have from bilateral filtering. The canny edge detector points out all the edges with the help of non-maximum suppression as an edge is a sharp difference and change in a frame’s pixel values.
We find contours which are curves that are joining all the points, continuous in nature, along the edges of the same color intensity. When we apply a find-contour operation the original frame will become impacted. A copy of the image should be processed during this phase. This function is to detect objects in an image. Sometimes objects are separated and located at different places without any overlapping. But in some cases, many of the objects overlap with one another. The outer edge is the parent, and the inner edge is referred to as the child.
The relationship between contours in an image is established like this. Due to the relationship between parent and child, we can call this a hierarchy. Retr_tree is passed as contour retrieval mode which provides the total hierarchy of all the edges in a tree hierarchy-like structure. The contour approximation method needs to also be specified in this step, otherwise it will not be able to judge the (x, y) coordinates of the boundary points of any shape. We use chain_approx_simple to return only the two endpoints of a line; otherwise, it will return all the point coordinates in a line.
Now, we approximate polygons. The target here is to fetch the number plate region, which is always rectangular. This step helps us to fetch the polygonal-shaped edges or contour points. The rectangle is a four-sided polygon. Thus, any approximation which returns four sides can be our possible edge point for the number plate. Edge points returned are the (x, y) coordinates of four corners of a rectangle.
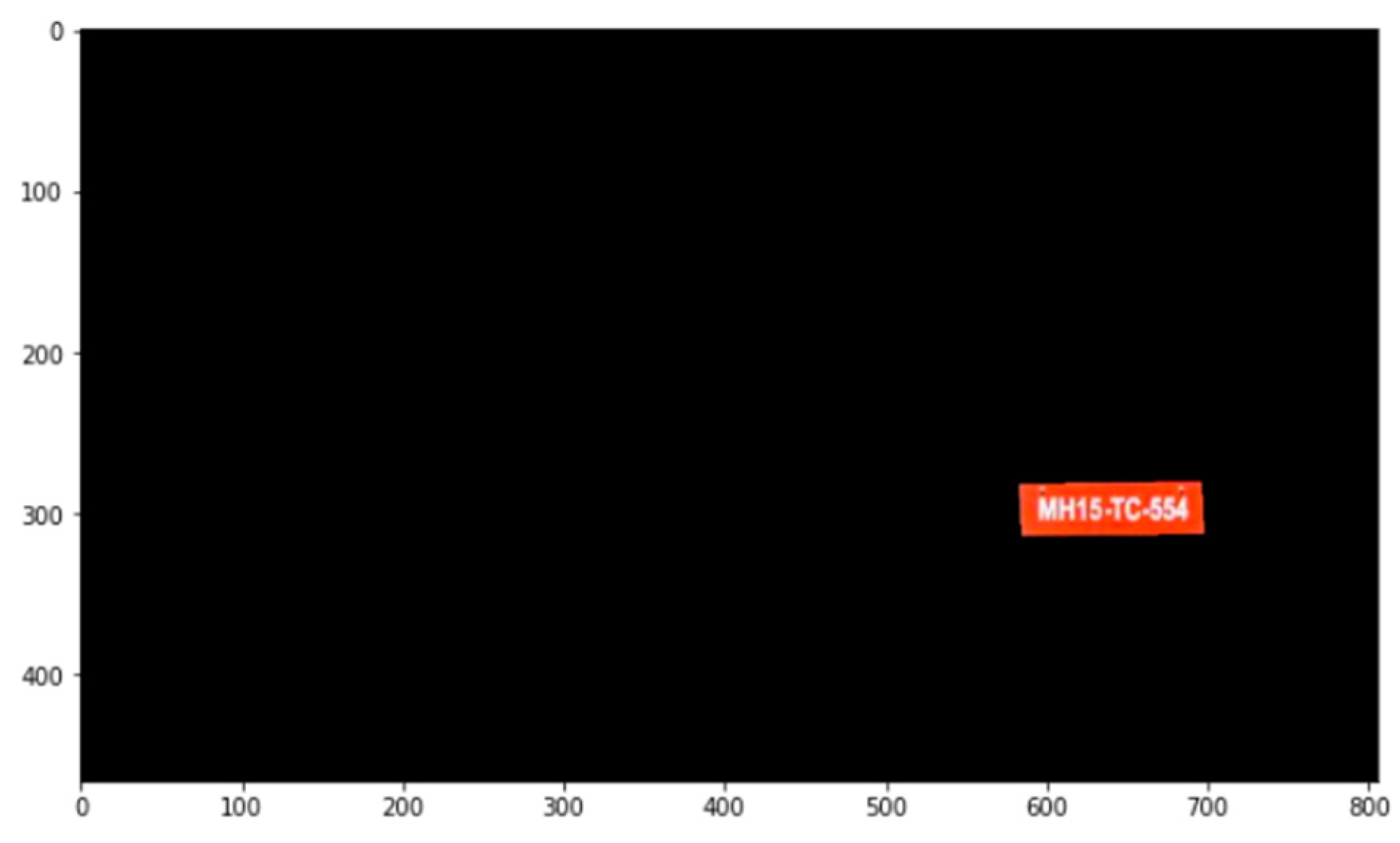
Masking is the process applied before we draw the contours of the new edge points that were approximated. Once the original image is masked and only the candidate region is passed, we obtain our desired number plate output, as shown in
Figure 8.
Now we have our desired area. We segregate the number plate region from the image for further processing, as shown in
Figure 9.
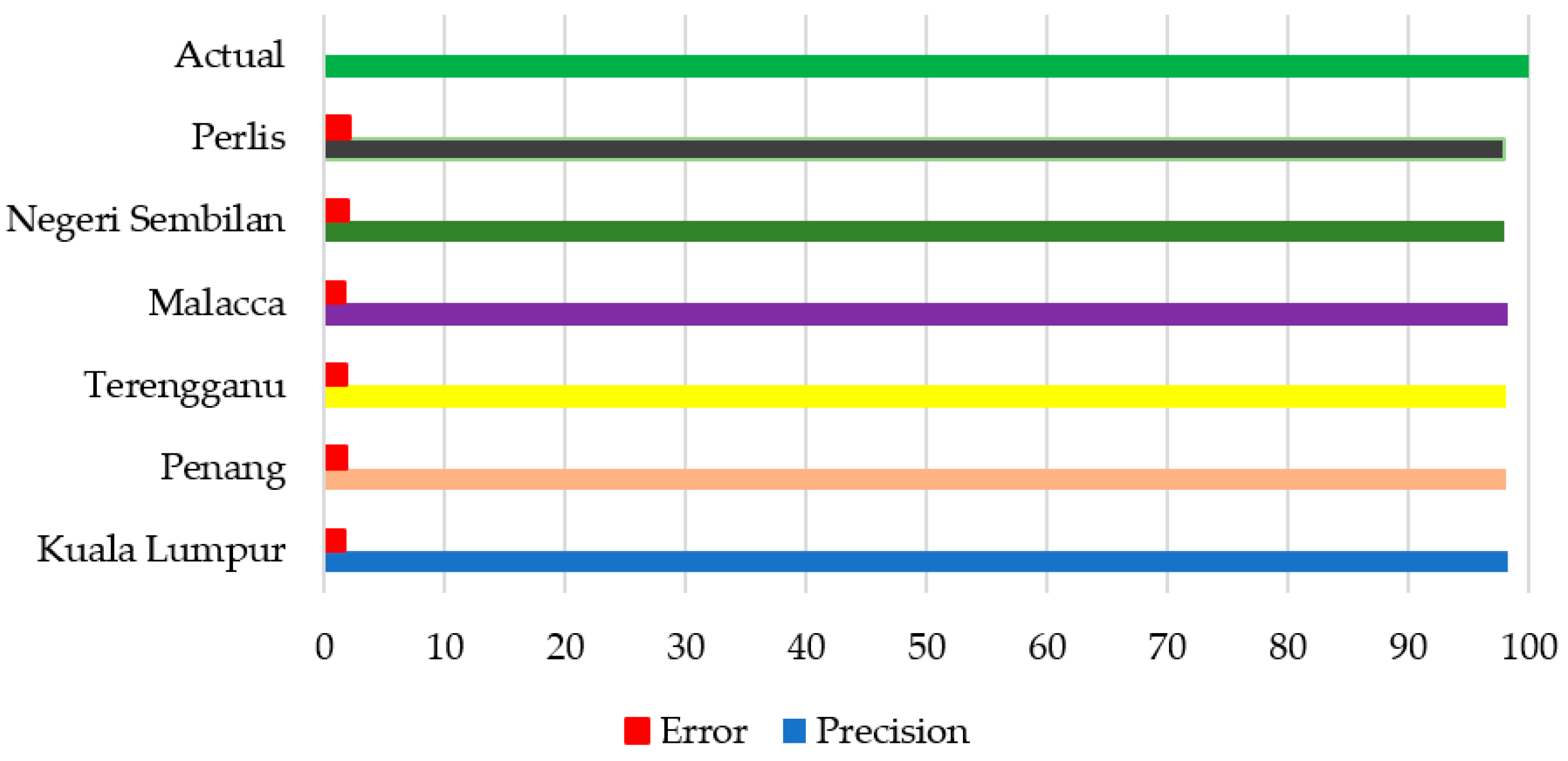
For character recognition from the segregated license plate, we use EasyOCR. This is a library for optical recognition. EasyOCR is based on deep learning models which involve text recognition and detection models. This optical character recognition process returns text along with its prediction probability. We have deployed a regex conditioning which helps us to format all the text as per Malaysian car number plate formats. Different car number plate formats were designed into regex formats to validate the text conversion. Most Malaysian number plates follow a format of Sxx @@@@, where:
S—The state or territory prefix. (e.g.,: W = Kuala Lumpur, A = Perak etc.);
X—The alphabetical sequences. (e.g.,: A, B, C, …, X, Y);
@—The number sequence (0, 1, 2, 3 to 9999).
Please find below
Table 3 for state references.
The number plate format being used for Sarawak is QDx @@@@ x, where:
Q—The constant prefix for all Sarawak number plates;
D—The division prefix. (e.g.,: A = Kuching, M = Miri);
x—The alphabetical sequences. (e.g.,: A, B, C, …, X, Y, except Q and S are restricted);
@—The number sequence (0, 1, 2, 3 to 9999).
Refer to
Table 4 for the division prefix of different regions of Sarawak.
The number plate format being used for Sabah is SDx @@@@ x, where:
S—The constant prefix for all Sabah number plates;
D—The division prefix. (e.g.,: A = West Coast, T = Tawau;
x—The alphabetical sequences. (e.g.,: A, B, C, …, X, Y, except Q and S are restricted);
@—The number sequence (0, 1, 2, 3 to 9999).
Refer to
Table 5 for the division prefix of different regions of Sabah.
The number plate format being used for Taxi is HSx @@@@, where:
H—The constant prefix for all taxi number plates;
S—The state or territory prefix. (e.g.,: W = Kuala Lumpur, P = Penang);
X—The alphabetical sequence. (e.g.,: A, B, C, …, X, Y);
@—The number sequence (0, 1, 2, 3 to 9999).
Refer to
Table 6 for the division prefix for different regions.
Certain taxis around Shah Alam use a somewhat different format of HB #### SA. Certain limo service from the airport also use a different format of LIMO #### S. Military services use the format ZB ####, where:
Z—Malaysian Armed Forces vehicles;
B—Segment prefix. (e.g.,: A = prior use before the division of different services, D = Malaysian Army, L = Royal Malaysian Navy, U = Royal Malaysian Air Force, Z = Ministry of Defense);
#—The number sequence. (e.g.,: 1, 2, 3 to 9999).
All the mentioned regex formats help to make sure that the optical recognized character is in format, because there are times when the converted texts are incorrect with a high confidence probability, while at times texts are correct with a low confidence probability.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}