

A Novel Non-Intrusive Load Monitoring Algorithm for Unsupervised Disaggregation of Household Appliances

Abstract
:1. Introduction
- It is the first unsupervised algorithm that can be deployed in any residential household without any additional supervised information;
- We propose a novel event detection algorithm capable of recognizing some instances in which rising/falling edges overlap;
- The NILM algorithm provides its disaggregation through knowledge of the common use of appliances and how they work, making it easy to understand but limiting the number of appliances it can detect.
2. Materials and Methods
2.1. NILM Problem Formulation
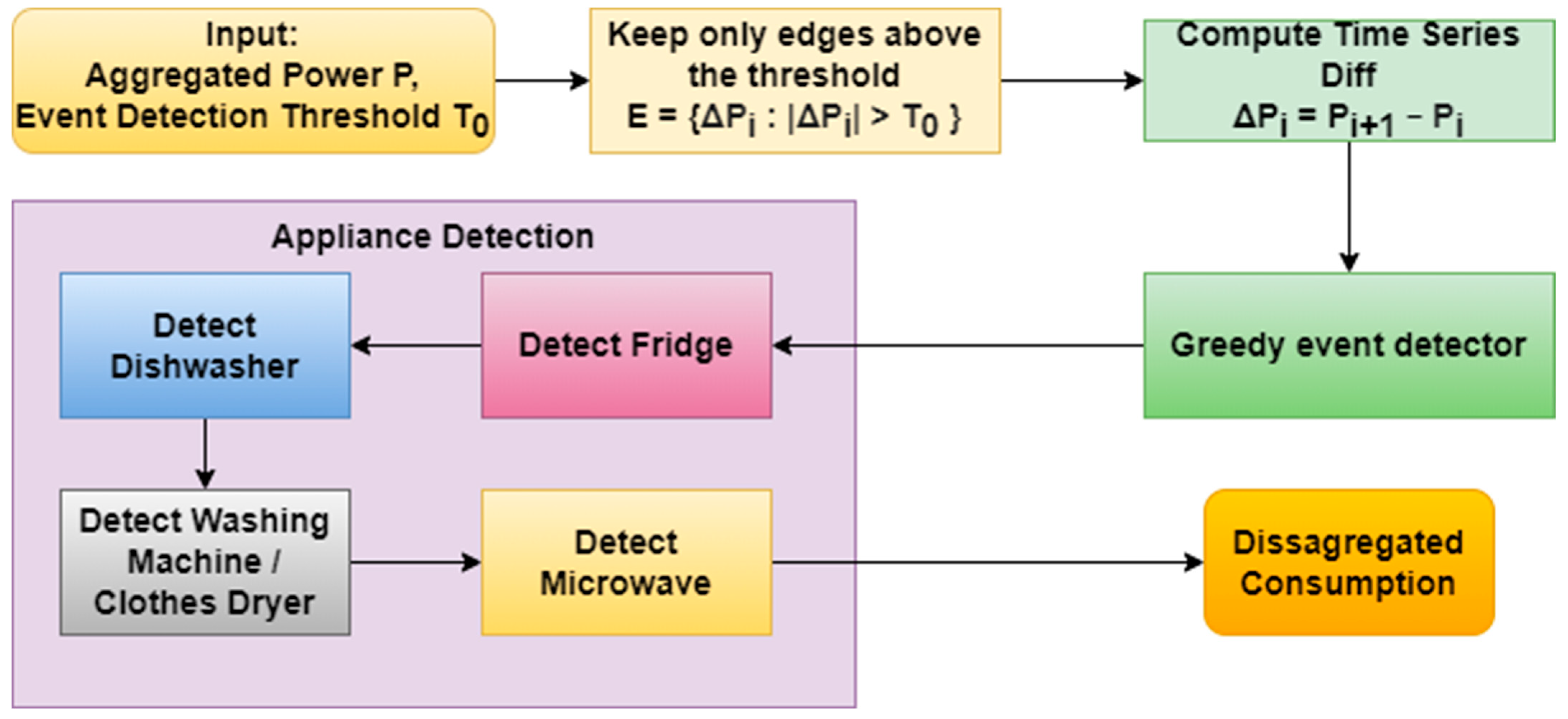
2.2. General Overview of Our Algorithm
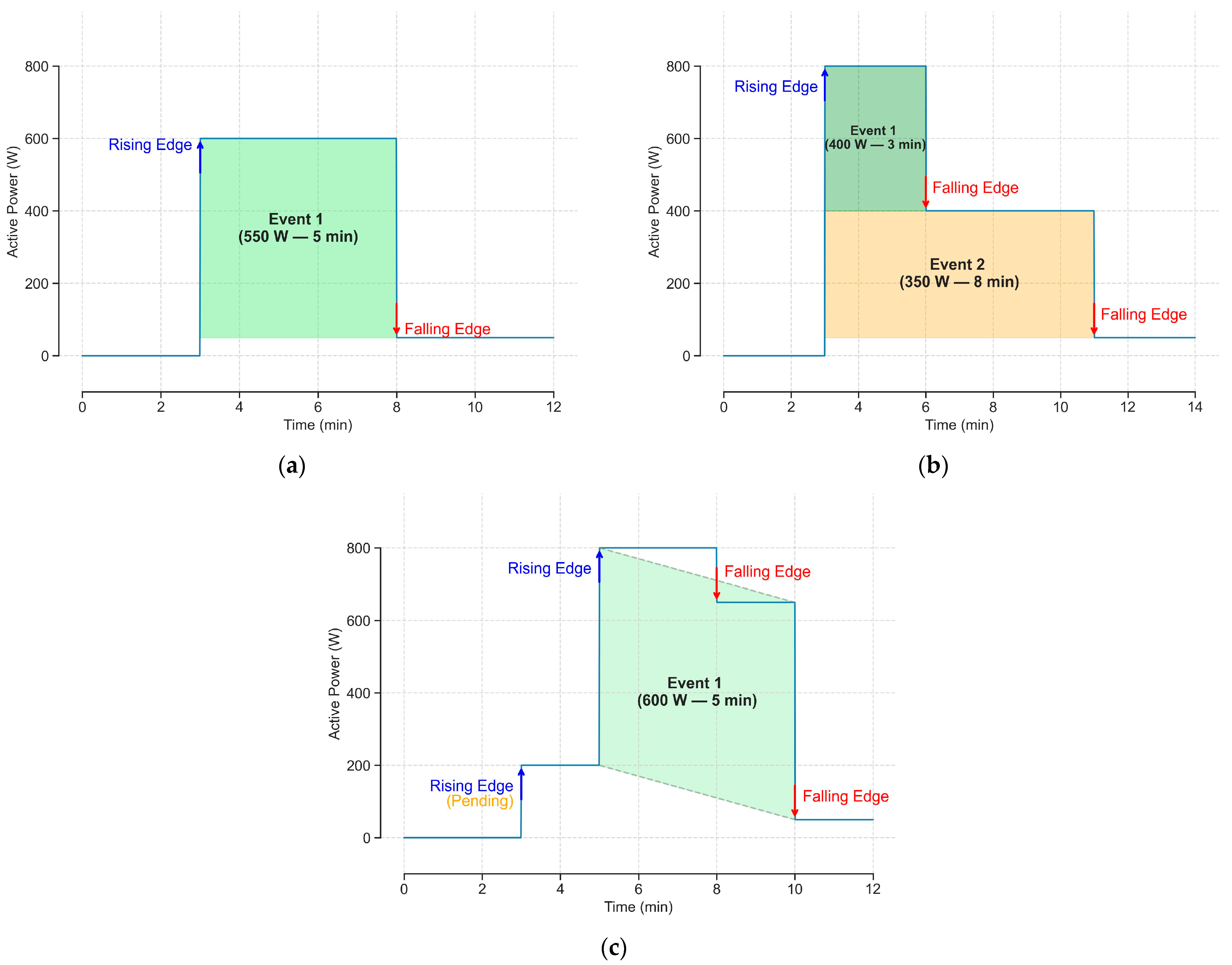
2.3. Event Detection
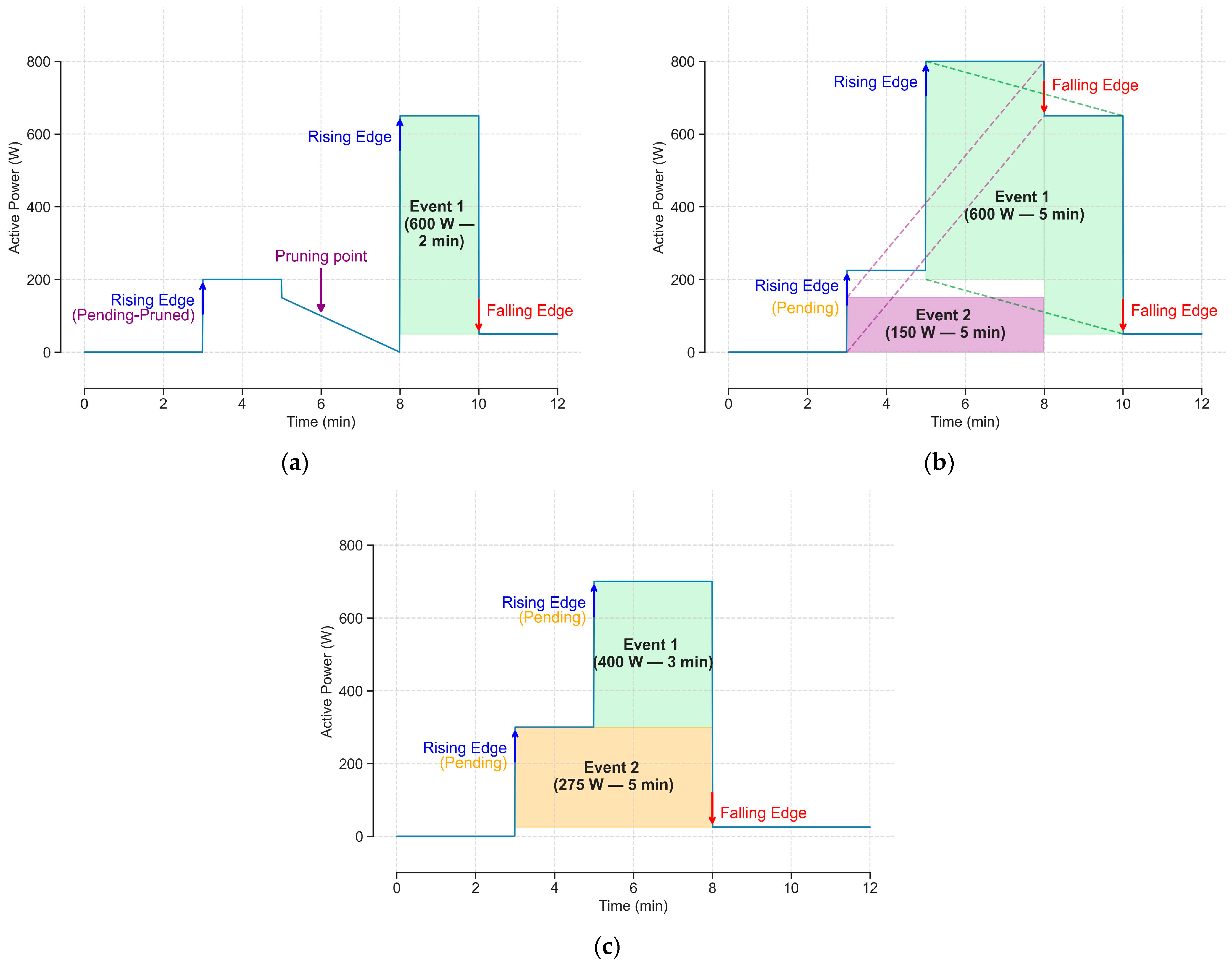
2.3.1. Matching Phase
2.3.2. Pruning Phase
2.4. Appliance Detection
2.4.1. Fridge Detection
- If there are any situations in which two events start or finish simultaneously, the other edge is one minute apart, and the sum of power respects the rules for length and duration described previously, we also mark them as a fridge event (Line 10). This is undertaken to manage possible transients at the end of the cycle;
- The second optimization (Line 11) allows the selection of an event with a slightly higher difference in power consumption if only one suitable event is found in any instance in which too much time has passed between consecutive fridge events;
- Lastly, the third optimization (Lines 12–16) manages situations in which multiple fridge events have been found overlapping with each other, preserving those that are more likely to be the real ones.
| Algorithm 1. Fridge detection and labeling optimizations | |||
| Input: | |||
| Output:} found. | |||
| 1: | nonOverlappingEvents = Extract from eventList all events that do not overlap with any other event. | ||
| 2: | For event in nonOverlappingEvents: | ||
| 3: | If and | ||
| 4: | Append event to validEvents | ||
| 5: | If size (validEvents) | ||
| 6: | = median (validEvents.P); median (validEvents.t); | ||
| 7: | Else: | ||
| 8: | return None (fridge was not found) | ||
| 9: | fridgeEvents = all events from nonOverlappingEvents that last and consume | ||
| 10: | Add to fridgeEvents all events that either start or finish simultaneously; their sum and duration are between the boundaries described in the previous line and do not overlap with a previous fridgeEvent. | ||
| 11: | If the time between two fridgeEvents is longer than the median and there is only one event that can be a fridge event if in Line 9 was increased by we add it | ||
| 12: | For each group of fridgeEvents g that overlap: | ||
| 13: | If size(g) == 2: | ||
| 14: | Keep the element with the closest duration to | ||
| 15: | Else: | ||
| 16: | Keep the combination of events with the closest energy (duration multiplied by the event power) to the median cycle energy () | ||
| 17: | Return fridgeEvents | ||
2.4.2. Dishwasher Detection
| Algorithm 2. Dishwasher program detection | |||||
| Input: | |||||
| Output: Most frequent dishwashing program { | |||||
| 1: | validList = [] (empty list) | ||||
| 2: | For event in eventList: | ||||
| 3: | If and : | ||||
| 4: | Append to validEvents | ||||
| 5: | Add to each event a new variable “count” that counts the number of validEvents in a range that happen in less than an hour | ||||
| 6: | Remove all events with count equal or superior to | ||||
| 7: | validTuples = [] | ||||
| 8: | For in eventList: | ||||
| 9: | For in eventList: (only events that start after the end of ) | ||||
| 10: | = start of end of | ||||
| 11: | If ( and : | ||||
| 12: | to validTuples | ||||
| 13: | groupsFound = [] | ||||
| 14: | For in validTuples: | ||||
| 15: | If size(groupsFound) == 0: | ||||
| 16: | to groupsFound | ||||
| 17: | Else: | ||||
| 18: | For in groupsFound: | ||||
| 19: | If are in range of and times have at most a difference of minutes with | ||||
| 20: | as the mean of all previous validTuples in the group and increase by 1. | ||||
| 21: | break | ||||
| 22: | Return or nothing if | ||||
2.4.3. Other Thermostat-Based Appliances
| Algorithm 3. Spike-based appliance detection | |||||
| Input: | |||||
| Output: Most frequent spike-based appliance median power consumption | |||||
| 1: | validSpikes = [] (empty list) | ||||
| 2: | For event in eventList: (only events that are yet to be assigned to an appliance) | ||||
| 3: | If | ||||
| 4: | mySpikes = [] (empty list) | ||||
| 5: | lastEnd = .end | ||||
| 6: | For event in eventList: (only events that start after the end of ): | ||||
| 7: | If start–lastEnd > | ||||
| 8: | break | ||||
| 9: | Else If | ||||
| 10: | lastEnd = .end | ||||
| 11: | Append to mySpikes | ||||
| 12: | If size (mySpikes) : | ||||
| 13: | Append mySpikes to validSpikes | ||||
| 14: | If size (validSpikes) : | ||||
| 15: | Return median (validSpikes) | ||||
2.4.4. Microwave Detection
2.5. Validation Methodology
3. Results
3.1. Evaluation Metrics
3.2. Disaggregation Accuracy in Each Household Evaluated
3.3. Real-Life Applications
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abdeen, A.; Kharvari, F.; O’Brien, W.; Gunay, B. The Impact of the COVID-19 on Households’ Hourly Electricity Consumption in Canada. Energy Build. 2021, 250, 111280. [Google Scholar] [CrossRef]
- Khan, I. A Survey-Based Electricity Demand Profiling Method for Developing Countries: The Case of Urban Households in Bangladesh. J. Build. Eng. 2021, 42, 102507. [Google Scholar] [CrossRef]
- Liu, Y.; Ma, J.; Xing, X.; Liu, X.; Wang, W. A Home Energy Management System Incorporating Data-Driven Uncertainty-Aware User Preference. Appl. Energy 2022, 326, 119911. [Google Scholar] [CrossRef]
- Rashid, H.; Singh, P.; Stankovic, V.; Stankovic, L. Can Non-Intrusive Load Monitoring Be Used for Identifying an Appliance’s Anomalous Behaviour? Appl. Energy 2019, 238, 796–805. [Google Scholar] [CrossRef]
- Green, D.; Kane, T.; Kidwell, S.; Lindahl, P.; Donnal, J.; Leeb, S. NILM Dashboard: Actionable Feedback for Condition-Based Maintenance. IEEE Instrum. Meas. Mag. 2020, 23, 3–10. [Google Scholar] [CrossRef]
- Hart, G.W. Prototype Nonintrusive Appliance Load Monitor, MIT Energy Laboratory Technical Report, and Electric Power Research Institute Technical Report. 1985.
- Hart, G.W. Nonintrusive Appliance Load Monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, C.; Peng, W.; Liu, W.; Zhang, H. Non-Intrusive Load Monitoring Using Factorial Hidden Markov Model Based on Adaptive Density Peak Clustering. Energy Build. 2021, 244, 111025. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, C.; Zhang, H.; Peng, W.; Liu, W. A Time-Efficient Factorial Hidden Semi-Markov Model for Non-Intrusive Load Monitoring. Electr. Power Syst. Res. 2021, 199, 107372. [Google Scholar] [CrossRef]
- Kumar, P.; Abhyankar, A.R. A Time Efficient Factorial Hidden Markov Model Based Approach for Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2023, 14, 3627–3639. [Google Scholar] [CrossRef]
- Kolter, J.; Batra, S.; Ng, A. Energy Disaggregation via Discriminative Sparse Coding. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, Canada, 6–9 December 2010; Curran Associates, Inc.: Red Hook, NY, USA, 2010; Volume 23. [Google Scholar]
- Elhamifar, E.; Sastry, S. Energy Disaggregation via Learning “Powerlets” and Sparse Coding. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; AAAI Press: Austin, TX, USA, 2015; pp. 629–635. [Google Scholar]
- Singh, S.; Majumdar, A. Deep Sparse Coding for Non–Intrusive Load Monitoring. IEEE Trans. Smart Grid 2018, 9, 4669–4678. [Google Scholar] [CrossRef]
- Singhal, V.; Maggu, J.; Majumdar, A. Simultaneous Detection of Multiple Appliances From Smart-Meter Measurements via Multi-Label Consistent Deep Dictionary Learning and Deep Transform Learning. IEEE Trans. Smart Grid 2019, 10, 2969–2978. [Google Scholar] [CrossRef]
- Faustine, A.; Pereira, L.; Bousbiat, H.; Kulkarni, S. UNet-NILM: A Deep Neural Network for Multi-Tasks Appliances State Detection and Power Estimation in NILM. In Proceedings of the 5th International Workshop on Non-Intrusive Load Monitoring, New York, NY, USA, 18 November 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 84–88. [Google Scholar]
- Zhou, X.; Li, S.; Liu, C.; Zhu, H.; Dong, N.; Xiao, T. Non-Intrusive Load Monitoring Using a CNN-LSTM-RF Model Considering Label Correlation and Class-Imbalance. IEEE Access 2021, 9, 84306–84315. [Google Scholar] [CrossRef]
- Kaselimi, M.; Doulamis, N.; Voulodimos, A.; Doulamis, A.; Protopapadakis, E. EnerGAN++: A Generative Adversarial Gated Recurrent Network for Robust Energy Disaggregation. IEEE Open J. Signal Process. 2021, 2, 1–16. [Google Scholar] [CrossRef]
- Liao, J.; Elafoudi, G.; Stankovic, L.; Stankovic, V. Non-Intrusive Appliance Load Monitoring Using Low-Resolution Smart Meter Data. In Proceedings of the 2014 IEEE International Conference on Smart Grid Communications (SmartGridComm), Venice, Italy, 3–6 November 2014; pp. 535–540. [Google Scholar]
- Giri, S.; Bergés, M. An Energy Estimation Framework for Event-Based Methods in Non-Intrusive Load Monitoring. Energy Convers. Manag. 2015, 90, 488–498. [Google Scholar] [CrossRef]
- Alcalá, J.; Ureña, J.; Hernández, Á.; Gualda, D. Event-Based Energy Disaggregation Algorithm for Activity Monitoring From a Single-Point Sensor. IEEE Trans. Instrum. Meas. 2017, 66, 2615–2626. [Google Scholar] [CrossRef]
- Zhao, B.; Stankovic, L.; Stankovic, V. On a Training-Less Solution for Non-Intrusive Appliance Load Monitoring Using Graph Signal Processing. IEEE Access 2016, 4, 1784–1799. [Google Scholar] [CrossRef]
- Zhao, B.; He, K.; Stankovic, L.; Stankovic, V. Improving Event-Based Non-Intrusive Load Monitoring Using Graph Signal Processing. IEEE Access 2018, 6, 53944–53959. [Google Scholar] [CrossRef]
- Li, X.; Zhao, B.; Luan, W.; Liu, B. A Training-Free Non-Intrusive Load Monitoring Approach for High-Frequency Measurements Based on Graph Signal Processing. In Proceedings of the 2022 7th Asia Conference on Power and Electrical Engineering (ACPEE), Hangzhou, China, 15–17 April 2022; pp. 859–863. [Google Scholar]
- Holweger, J.; Dorokhova, M.; Bloch, L.; Ballif, C.; Wyrsch, N. Unsupervised Algorithm for Disaggregating Low-Sampling-Rate Electricity Consumption of Households. Sustain. Energy Grids Netw. 2019, 19, 100244. [Google Scholar] [CrossRef]
- Mascheroni, R.; Salvadori, V. Household Refrigerators and Freezers. In Handbook of Frozen Food Processing and Packaging; CRC PRESS: Boca Raton, FL, USA, 2011; pp. 253–272. [Google Scholar]
- Reinhardt, A.; Baumann, P.; Burgstahler, D.; Hollick, M.; Chonov, H.; Werner, M.; Steinmetz, R. On the Accuracy of Appliance Identification Based on Distributed Load Metering Data. In Proceedings of the 2012 Sustainable Internet and ICT for Sustainability (SustainIT), Pisa, Italy, 4–5 October 2012; IEEE: Toulouse, France, 2012; pp. 1–9. [Google Scholar]
- Liu, D.-Y.; Chang, W.-R.; Lin, J.-Y. Performance Comparison with Effect of Door Opening on Variable and Fixed Frequency Refrigerators/Freezers. Appl. Therm. Eng. 2004, 24, 2281–2292. [Google Scholar] [CrossRef]
- Kolter, J.; Johnson, M. REDD: A Public Data Set for Energy Disaggregation Research. Artif Intell 2011, 25, 59–62. [Google Scholar]
- Bengtsson, P.; Berghel, J.; Renström, R. A Household Dishwasher Heated by a Heat Pump System Using an Energy Storage Unit with Water as the Heat Source. Int. J. Refrig. 2015, 49, 19–27. [Google Scholar] [CrossRef]
- Issi, F.; Kaplan, O. The Determination of Load Profiles and Power Consumptions of Home Appliances. Energies 2018, 11, 607. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value | Explanation |
|---|---|---|
| 450 W | Maximum power of events used for fridge detection | |
| 7 min | Minimum length of each fridge cycle | |
| 90 min | Maximum length of each fridge cycle | |
| 100 | Minimum number of non-overlapping fridge events to consider it detected | |
| 0.25 | Maximum percentual threshold for fridge events | |
| 0.05 | Additional threshold for fridge events if too much time has passed | |
| 750 W | Minimum power consumption for dishwasher events | |
| 10 min | Minimum length of each cycle of dishwashing programs | |
| 90 min | Maximum length of each cycle of dishwashing programs | |
| 5 | Minimum number of times the dishwashing program must be detected | |
| 5 | Maximum number of similar dishwashing cycles allowed in one program | |
| 0.25 | Maximum percentual threshold for dishwashing cycles power | |
| 3 min | Maximum time difference between new events and the detected dishwashing program | |
| 750 W | Minimum power of events for a spike-based appliance | |
| 7 min | Maximum time between two consecutive spike events | |
| 5 | Minimum number of full spike-based events to detect a spike-based appliance | |
| 6 | Minimum number of consecutive spikes to consider it a full spike-based event | |
| 0.25 | Percentual difference allowed between a spike-based appliance’s event | |
| 7 min | Maximum length of microwave events | |
| 10 | Minimum number of times the microwave must be detected | |
| 0.1 | Percentual difference allowed between microwave events | |
| 600 W | Minimum power of events for microwave detection | |
| 2000 W | Maximum power of events for microwave detection |
| TP | FP | TN | FN | RE | PR | F1 | |
|---|---|---|---|---|---|---|---|
| Fridge | 5539 | 422 | 19,337 | 1002 | 0.9292 | 0.8468 | 0.8861 |
| Dishwasher | 125 | 0 | 25,319 | 856 | 0.1274 | 1.0 | 0.2260 |
| Microwave | 190 | 112 | 25,846 | 152 | 0.5555 | 0.6291 | 0.5901 |
| Washer/Dryer | 232 | 25 | 25,822 | 221 | 0.5121 | 0.9027 | 0.6535 |
| TP | FP | TN | FN | RE | PR | F1 | |
|---|---|---|---|---|---|---|---|
| Fridge | 7457 | 440 | 10,793 | 1444 | 0.8377 | 0.9443 | 0.8878 |
| Dishwasher | 103 | 0 | 19,893 | 138 | 0.4274 | 1.0 | 0.5988 |
| Microwave | 36 | 2 | 19,986 | 110 | 0.2466 | 0.9474 | 0.3913 |
| Washer/Dryer | Not used in this house | ||||||
| TP | FP | TN | FN | RE | PR | F1 | |
|---|---|---|---|---|---|---|---|
| Fridge | 7549 | 1228 | 14,219 | 1669 | 0.8189 | 0.8601 | 0.8390 |
| Microwave | 52 | 35 | 24,505 | 73 | 0.416 | 0.5977 | 0.5988 |
| Washer/Dryer | 350 | 0 | 23,633 | 682 | 0.3391 | 1.0 | 0.5065 |
| Dishwasher | Not detected | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Criado-Ramón, D.; Ruiz, L.G.B.; Iruela, J.R.S.; Pegalajar, M.C. A Novel Non-Intrusive Load Monitoring Algorithm for Unsupervised Disaggregation of Household Appliances. Information 2024, 15, 87. https://doi.org/10.3390/info15020087
Criado-Ramón D, Ruiz LGB, Iruela JRS, Pegalajar MC. A Novel Non-Intrusive Load Monitoring Algorithm for Unsupervised Disaggregation of Household Appliances. Information. 2024; 15(2):87. https://doi.org/10.3390/info15020087
Chicago/Turabian StyleCriado-Ramón, D., L. G. B. Ruiz, J. R. S. Iruela, and M. C. Pegalajar. 2024. "A Novel Non-Intrusive Load Monitoring Algorithm for Unsupervised Disaggregation of Household Appliances" Information 15, no. 2: 87. https://doi.org/10.3390/info15020087
APA StyleCriado-Ramón, D., Ruiz, L. G. B., Iruela, J. R. S., & Pegalajar, M. C. (2024). A Novel Non-Intrusive Load Monitoring Algorithm for Unsupervised Disaggregation of Household Appliances. Information, 15(2), 87. https://doi.org/10.3390/info15020087