
FUSeg: The Foot Ulcer Segmentation Challenge


 ,
,  ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset
2.1.1. Data Collection
2.1.2. Annotation
2.2. Challenge Design
2.2.1. Infrastructure and Timeline
2.2.2. Submission and Evaluation
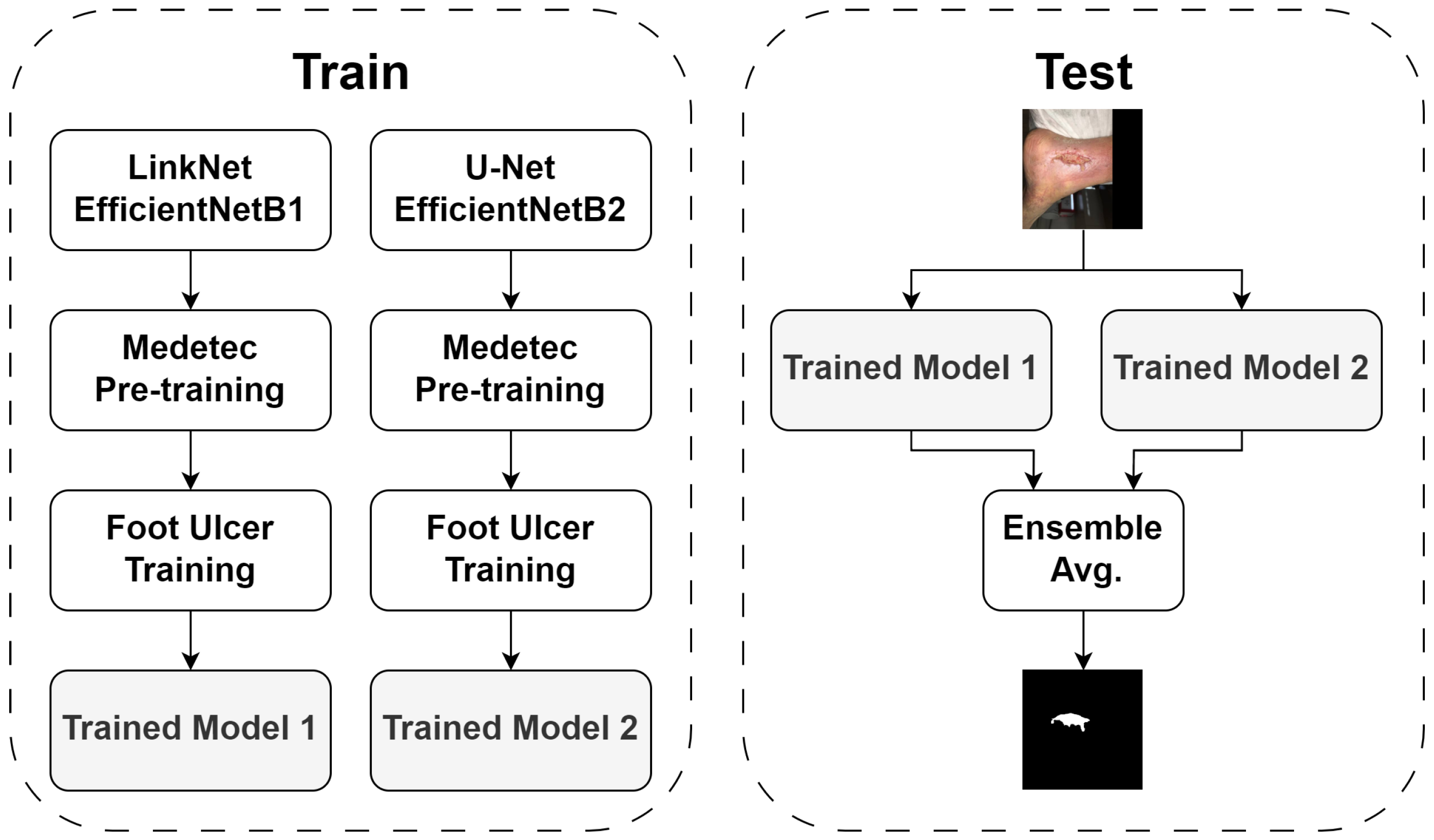
2.3. Top Three Submissions
2.3.1. First Place
2.3.2. Second Place
2.3.3. Third Place
3. Results
4. Discussion
4.1. Overall Segmentation Performance
4.2. U-Net Architecture
4.3. Ensembling
5. Conclusions and Future Works
- Current state-of-the-art algorithms can accurately segment the wound area, with Dice scores reaching 88.8% and precision reaching 91.55%.
- There is still room for improvement for newer deep learning models to be applied on wound segmentation. For example, transformer-based methods and semi-supervised methods.
- From the predictions generated by the submitted algorithms, we observed the challenges in distinguishing between epithelial tissue and granulation tissue and segmenting small isolated wound regions.
- We also observed the superiority of ensemble networks over individual networks applied to our dataset.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| AZH | Advancing the Zenith of Healthcare |
| BN | Batch Normalization |
| DFU | Diabetic Foot Ulcer |
| FUSeg | Foot Ulcer Segmentation |
| HarDNet | Harmonic Densely Connected Network |
| LR | Learning Rate |
| MICCAI | International Conference on Medical Image Computing and Computer Assisted Intervention |
| TTA | Test Time Augmentation |
References
- Frykberg, R.G.; Banks, J. Challenges in the Treatment of Chronic Wounds. Adv. Wound Care 2015, 4, 560–582. [Google Scholar] [CrossRef]
- Sen, C.K. Human Wounds and Its Burden: An Updated Compendium of Estimates. Adv. Wound Care 2019, 8, 39–48. [Google Scholar] [CrossRef] [PubMed]
- Branski, L.K.; Gauglitz, G.G.; Herndon, D.N.; Jeschke, M.G. A review of gene and stem cell therapy in cutaneous wound healing. Burns 2009, 35, 171–180. [Google Scholar] [CrossRef] [PubMed]
- Nussbaum, S.R.; Carter, M.J.; Fife, C.E.; DaVanzo, J.; Haught, R.; Nusgart, M.; Cartwright, D. An Economic Evaluation of the Impact, Cost, and Medicare Policy Implications of Chronic non-healing Wounds. Value Health 2018, 21, 27–32. [Google Scholar] [CrossRef] [PubMed]
- Yap, M.H.; Cassidy, B.; Pappachan, J.M.; O’Shea, C.; Gillespie, D.; Reeves, N.D. Analysis Towards Classification of Infection and Ischaemia of Diabetic Foot Ulcers. In Proceedings of the EMBS International Conference on Biomedical and Health Informatics, Athens, Greece, 27–30 July 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Thomas, S. Medetec Wound Database. 2014. Available online: http://www.medetec.co.uk/files/medetec-image-databases.html (accessed on 22 January 2024).
- Kręcichwost, M.; Czajkowska, J.; Wijata, A.; Juszczyk, J.; Pyciński, B.; Biesok, M.; Rudzki, M.; Majewski, J.; Kostecki, J.; Pietka, E. Chronic wounds multimodal image database. Comput. Med. Imaging Graph. 2021, 88, 101844. [Google Scholar] [CrossRef] [PubMed]
- Dice, L.R. Measures of the Amount of Ecologic Association Between Species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Mahbod, A.; Schaefer, G.; Ecker, R.; Ellinger, I. Automatic Foot Ulcer Segmentation Using an Ensemble of Convolutional Neural Networks. In Proceedings of the 26th International Conference on Pattern Recognition, Montreal, QC, Canada, 21–25 August 2022; pp. 4358–4364. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the IEEE Visual Communications and Image Processing, St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; Proceedings of Machine Learning Research PMLR, PMLR. Volume 97, pp. 6105–6114. [Google Scholar]
- Mahbod, A.; Schaefer, G.; Ecker, R.; Ellinger, I. Pollen grain microscopic image classification using an ensemble of fine-tuned deep convolutional neural networks. In Proceedings of the International Conference on Pattern Recognition, Virtual, 10–15 January 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 344–356. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zhang, Y.; Liu, S.; Li, C.; Wang, J. Rethinking the Dice Loss for Deep Learning Lesion Segmentation in Medical Images. J. Shanghai Jiaotong Univ. Sci. 2021, 26, 93–102. [Google Scholar] [CrossRef]
- Moshkov, N.; Mathe, B.; Kertesz-Farkas, A.; Hollandi, R.; Horvath, P. Test-time augmentation for deep learning-based cell segmentation on microscopy images. Sci. Rep. 2020, 10, 5068. [Google Scholar] [CrossRef] [PubMed]
- Tsiknakis, N.; Savvidaki, E.; Manikis, G.C.; Gotsiou, P.; Remoundou, I.; Marias, K.; Alissandrakis, E.; Vidakis, N. Pollen Grain Classification Based on Ensemble Transfer Learning on the Cretan Pollen Dataset. Plants 2022, 11, 919. [Google Scholar] [CrossRef] [PubMed]
- Gaillochet, M.; Desrosiers, C.; Lombaert, H. TAAL: Test-Time Augmentation for Active Learning in Medical Image Segmentation. In Proceedings of the Data Augmentation, Labelling, and Imperfections, Singapore, 22 September 2022; Nguyen, H.V., Huang, S.X., Xue, Y., Eds.; Springer: Cham, Switzerland, 2022; pp. 43–53. [Google Scholar] [CrossRef]
- Wang, C.; Anisuzzaman, D.M.; Williamson, V.; Dhar, M.K.; Rostami, B.; Niezgoda, J.; Gopalakrishnan, S.; Yu, Z. Fully automatic wound segmentation with deep convolutional neural networks. Sci. Rep. 2020, 10, 21897. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.H.; Wu, H.Y.; Lin, Y.L. HarDNet-MSEG: A simple encoder–decoder polyp segmentation neural network that achieves over 0.9 mean dice and 86 fps. arXiv 2021, arXiv:2101.07172. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef]
- Wu, Z.; Su, L.; Huang, Q. Cascaded Partial Decoder for Fast and Accurate Salient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, S.; Huang, D.; Wang, A. Receptive Field Block Net for Accurate and Fast Object Detection. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Galdran, A.; Carneiro, G.; Ballester, M.A.G. Double encoder–decoder Networks for Gastrointestinal Polyp Segmentation. In Proceedings of the International Conference on Pattern Recognition, Virtual, 10–15 January 2021; pp. 293–307. [Google Scholar] [CrossRef]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Bartko, J.J. Measurement and Reliability: Statistical Thinking Considerations. Schizophr. Bull. 1991, 17, 483–489. [Google Scholar] [CrossRef] [PubMed]
- Boehringer, A.S.; Sanaat, A.; Arabi, H.; Zaidi, H. An active learning approach to train a deep learning algorithm for tumor segmentation from brain MR images. Insights Imaging 2023, 14, 141. [Google Scholar] [CrossRef] [PubMed]
- Zijdenbos, A.; Dawant, B.; Margolin, R.; Palmer, A. Morphometric analysis of white matter lesions in MR images: Method and validation. IEEE Trans. Med. Imaging 1994, 13, 716–724. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Azad, R.; Kazerouni, A.; Heidari, M.; Aghdam, E.K.; Molaei, A.; Jia, Y.; Jose, A.; Roy, R.; Merhof, D. Advances in medical image analysis with vision Transformers: A comprehensive review. Med. Image Anal. 2024, 91, 103000. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gan, C.; Li, Z.; Rekik, I.; Yin, Z.; Ji, W.; Gao, Y.; Wang, Q.; Zhang, J.; Shen, D. Transformers in medical image analysis. Intell. Med. 2023, 3, 59–78. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Meila, M., Zhang, T., Eds.; Proceedings of Machine Learning Research PMLR, PMLR. Volume 139, pp. 10347–10357. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking Semantic Segmentation From a Sequence-to-Sequence Perspective With Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Mahbod, A.; Dorffner, G.; Ellinger, I.; Woitek, R.; Hatamikia, S. Improving generalization capability of deep learning-based nuclei instance segmentation by non-deterministic train time and deterministic test time stain normalization. Comput. Struct. Biotechnol. J. 2024, 23, 669–678. [Google Scholar] [CrossRef] [PubMed]
- Wen, Y.; Tran, D.; Ba, J. BatchEnsemble: An alternative approach to efficient ensemble and lifelong learning. arXiv 2020, arXiv:2002.06715. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank | Precision (%) | Recall (%) | Dice (%) |
|---|---|---|---|
| First Rank | 91.55 | 86.22 | 88.80 |
| Second Rank | 88.87 | 86.31 | 87.57 |
| Third Rank | 90.03 | 84.00 | 86.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Mahbod, A.; Ellinger, I.; Galdran, A.; Gopalakrishnan, S.; Niezgoda, J.; Yu, Z. FUSeg: The Foot Ulcer Segmentation Challenge. Information 2024, 15, 140. https://doi.org/10.3390/info15030140
Wang C, Mahbod A, Ellinger I, Galdran A, Gopalakrishnan S, Niezgoda J, Yu Z. FUSeg: The Foot Ulcer Segmentation Challenge. Information. 2024; 15(3):140. https://doi.org/10.3390/info15030140
Chicago/Turabian StyleWang, Chuanbo, Amirreza Mahbod, Isabella Ellinger, Adrian Galdran, Sandeep Gopalakrishnan, Jeffrey Niezgoda, and Zeyun Yu. 2024. "FUSeg: The Foot Ulcer Segmentation Challenge" Information 15, no. 3: 140. https://doi.org/10.3390/info15030140
APA StyleWang, C., Mahbod, A., Ellinger, I., Galdran, A., Gopalakrishnan, S., Niezgoda, J., & Yu, Z. (2024). FUSeg: The Foot Ulcer Segmentation Challenge. Information, 15(3), 140. https://doi.org/10.3390/info15030140