

PVI-Net: Point–Voxel–Image Fusion for Semantic Segmentation of Point Clouds in Large-Scale Autonomous Driving Scenarios


Abstract
:1. Introduction
- Proposing PVI-Net, a semantic segmentation framework for large-scale point cloud scenes, which integrates three different data perspectives—point cloud, voxel, and distance map—achieving an adaptive multi-dimensional information fusion strategy.
- Designing point–voxel cross-attention and Multi-perspective Fusion Attention (MF-Attention) mechanisms in the network structure, effectively addressing the structural differences and information fusion issues between different perspectives.
- Designing a multi-perspective feature post-fusion module. This module can effectively combine features from point clouds, voxels, and distance maps. In the post-fusion stage, the model integrates information from different perspectives, enhancing semantic understanding of complex outdoor scenes.
2. Related Works
2.1. Point Processing in Point Cloud Segmentation
2.2. Voxel Processing in Point Cloud Segmentation
2.3. Range Image Processing in Point Cloud Segmentation
2.4. Multi-Perspective Fusion
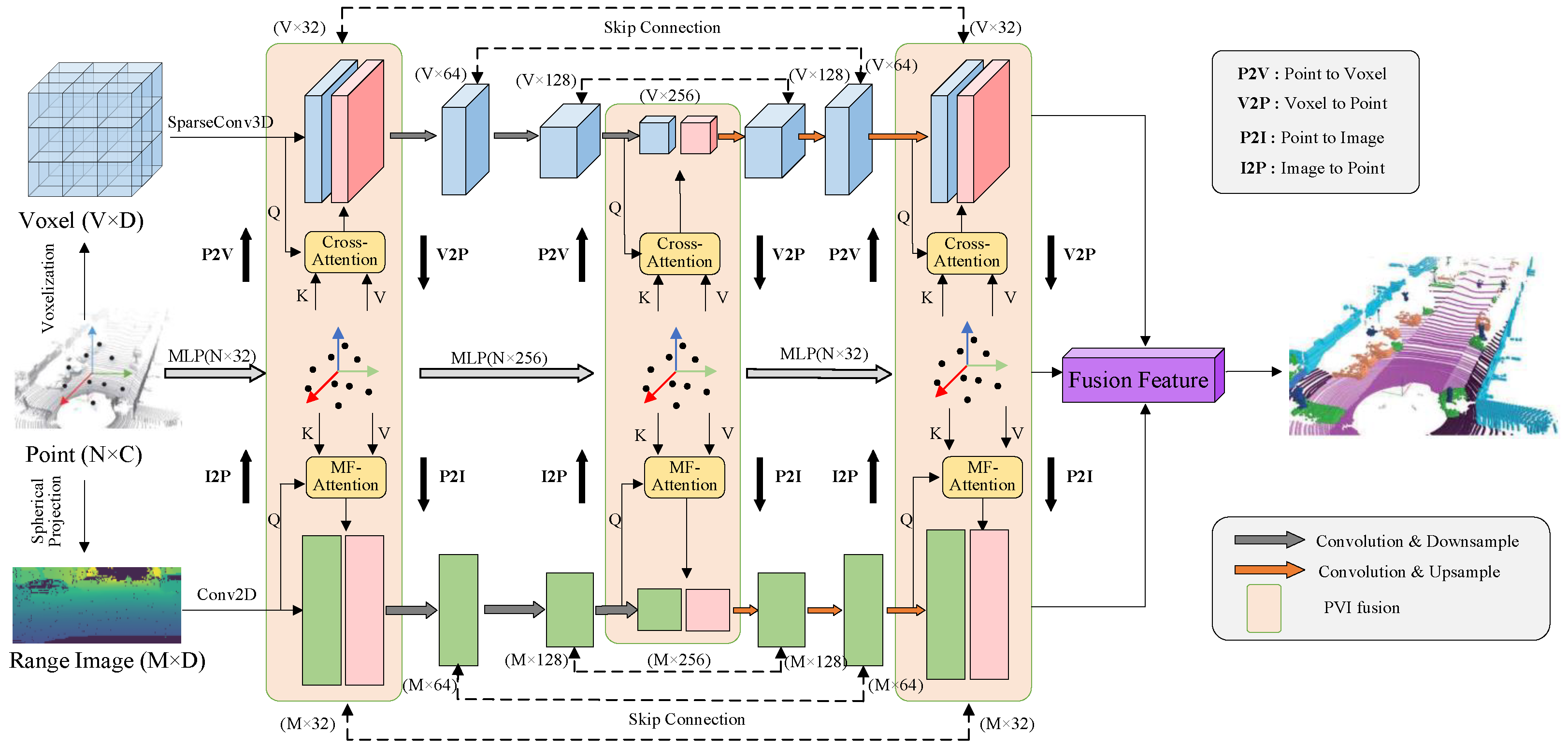
3. Methodology
3.1. Overview
3.2. Tri-Branch Feature Learning
3.2.1. Point Cloud Feature Extraction Branch
3.2.2. Voxel Feature Extraction Branch
3.2.3. Image Feature Extraction Branch
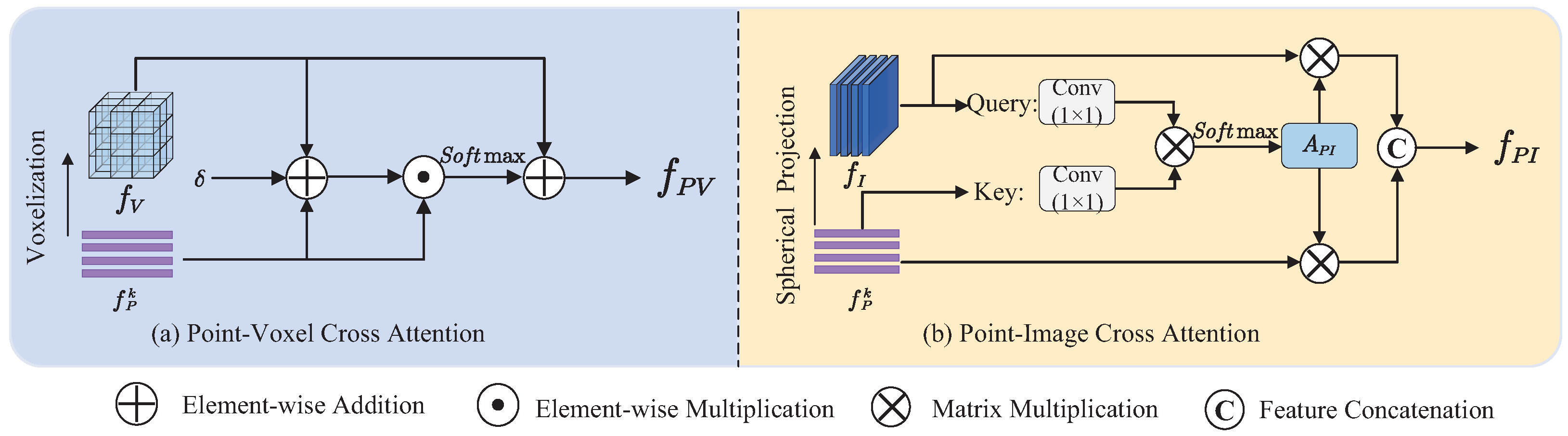
3.3. Multi-Perspective Feature Fusion
3.3.1. MF-Attention Feature Fusion Module
3.3.2. Multi-Perspective Feature Post-Fusion Module
4. Experiments
4.1. Datasets
4.2. Implementation Details and Settings
4.3. Results
4.3.1. Evaluation on SemanticKITTI Dataset
4.3.2. Evaluation on nuScenes Dataset
4.4. Ablation Study
4.4.1. Impact of Different Perspectives on Network Performance
4.4.2. Impact of Multi-Perspective Feature Deep Fusion Modules
4.4.3. Impact of Multi-Perspective Feature Post-Fusion Module
4.4.4. Multi-Perspective Fusion Addresses Challenges Encountered by Single-Perspective Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yan, X.; Zhan, H.; Zheng, C.; Gao, J.; Zhang, R.; Cui, S.; Li, Z. Let images give you more: Point cloud cross-modal training for shape analysis. Adv. Neural Inf. Process. Syst. 2022, 35, 32398–32411. [Google Scholar]
- Yan, X.; Gao, J.; Zheng, C.; Zheng, C.; Zhang, R.; Cui, S.; Li, Z. 2dpass: 2d priors assisted semantic segmentation on lidar point clouds. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 677–695. [Google Scholar]
- Wei, Y.; Zhao, L.; Zheng, W.; Zhu, Z.; Zhou, J.; Lu, J. Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2023, Paris, France, 4–6 October 2023; pp. 21729–21740. [Google Scholar]
- Ottonelli, S.; Spagnolo, P.; Mazzeo, P.L.; Leo, M. Improved video segmentation with color and depth using a stereo camera. In Proceedings of the IEEE International Conference on Industrial Technology 2013, Cape Town, South Africa, 25–28 February 2013; pp. 1134–1139. [Google Scholar]
- Zhang, Z.; Yang, B.; Wang, B.; Li, B. GrowSP: Unsupervised Semantic Segmentation of 3D Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 17619–17629. [Google Scholar]
- Xia, Y.; Gladkova, M.; Wang, R.; Li, Q.; Stilla, U.; Henriques, J.F.; Cremers, D. CASSPR: Cross Attention Single Scan Place Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2023, Paris, France, 4–6 October 2023; pp. 8461–8472. [Google Scholar]
- Fan, S.; Dong, Q.; Zhu, F.; Lv, Y.; Ye, P.; Wang, F.Y. SCF-Net: Learning spatial contextual features for large-scale point cloud segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 14504–14513. [Google Scholar]
- Li, L.; He, L.; Gao, J.; Han, X. Psnet: Fast data structuring for hierarchical deep learning on point cloud. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6835–6849. [Google Scholar] [CrossRef]
- Nie, D.; Lan, R.; Wang, L.; Ren, X. Pyramid architecture for multi-scale processing in point cloud segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 17284–17294. [Google Scholar]
- Phan, A.V.; Le Nguyen, M.; Nguyen, Y.L.H.; Bui, L.T. Dgcnn: A convolutional neural network over large-scale labeled graphs. Neural Netw. 2018, 108, 533–543. [Google Scholar] [CrossRef] [PubMed]
- Yuan, W.; Gu, X.; Li, H.; Dong, Z.; Zhu, S. Monocular Scene Reconstruction with 3D SDF Transformers. arXiv 2023, arXiv:2301.13510. [Google Scholar]
- Cui, M.; Long, J.; Feng, M.; Li, B.; Kai, H. OctFormer: Efficient octree-based transformer for point cloud compression with local enhancement. In Proceedings of the AAAI Conference on Artificial Intelligence 2023, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 470–478. [Google Scholar]
- Fei, J.; Chen, W.; Heidenreich, P.; Wirges, S.; Stiller, C. SemanticVoxels: Sequential fusion for 3D pedestrian detection using LiDAR point cloud and semantic segmentation. In Proceedings of the 2020 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Virtual, 14–16 September 2020; pp. 185–190. [Google Scholar]
- Park, C.; Jeong, Y.; Cho, M.; Park, J. Efficient Point Transformer for Large-Scale 3D Scene Understanding. Available online: https://openreview.net/forum?id=3SUToIxuIT3 (accessed on 1 January 2024).
- Wang, H.; Shi, C.; Shi, S.; Lei, M.; Wang, S.; He, D.; Schiele, B.; Wang, L. Dsvt: Dynamic sparse voxel transformer with rotated sets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 13520–13529. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. Rangenet++: Fast and accurate lidar semantic segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4213–4220. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3d lidar point cloud. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.L.; Han, S. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 2774–2781. [Google Scholar]
- Zhang, Z.; Shen, Y.; Li, H.; Zhao, X.; Yang, M.; Tan, W.; Pu, S.; Mao, H. Maff-net: Filter false positive for 3d vehicle detection with multi-modal adaptive feature fusion. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; pp. 369–376. [Google Scholar]
- Afham, M.; Dissanayake, I.; Dissanayake, D.; Dharmasiri, A.; Thilakarathna, K.; Rodrigo, R. Crosspoint: Self-supervised cross-modal contrastive learning for 3d point cloud understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 9902–9912. [Google Scholar]
- Chen, A.; Zhang, K.; Zhang, R.; Wang, Z.; Lu, Y.; Guo, Y.; Zhang, S. Pimae: Point cloud and image interactive masked autoencoders for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 5291–5301. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2019, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Xu, C.; Wu, B.; Wang, Z.; Zhan, W.; Vajda, P.; Keutzer, K.; Tomizuka, M. Squeezesegv3: Spatially-adaptive convolution for efficient point-cloud segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 1–19. [Google Scholar]
- Cortinhal, T.; Tzelepis, G.; Erdal Aksoy, E. Salsanext: Fast, uncertainty-aware semantic segmentation of lidar point clouds. In Proceedings of the Advances in Visual Computing: 15th International Symposium, ISVC 2020, San Diego, CA, USA, 5–7 October 2020; pp. 207–222. [Google Scholar]
- Zhang, Y.; Zhou, Z.; David, P.; Yue, X.; Xi, Z.; Gong, B.; Foroosh, H. Polarnet: An improved grid representation for online lidar point clouds semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 13–19 June 2020; pp. 9601–9610. [Google Scholar]
- Choy, C.; Gwak, J.; Savarese, S. 4d spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 3075–3084. [Google Scholar]
- Zhou, H.; Zhu, X.; Song, X.; Ma, Y.; Wang, Z.; Li, H.; Lin, D. Cylinder3d: An effective 3d framework for driving-scene lidar semantic segmentation. arXiv 2020, arXiv:2008.01550. [Google Scholar]
- Cheng, R.; Razani, R.; Taghavi, E.; Li, E.; Liu, B. 2-s3net: Attentive feature fusion with adaptive feature selection for sparse semantic segmentation network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021, Nashville, TN, USA, 20–25 June 2021; pp. 12547–12556. [Google Scholar]
- Zhang, F.; Fang, J.; Wah, B.; Torr, P. Deep fusionnet for point cloud semantic segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 644–663. [Google Scholar]
- Gerdzhev, M.; Razani, R.; Taghavi, E.; Bingbing, L. Tornado-net: Multiview total variation semantic segmentation with diamond inception module. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 9543–9549. [Google Scholar]
- Liong, V.E.; Nguyen, T.N.T.; Widjaja, S.; Sharma, D.; Chong, Z.J. Amvnet: Assertion-based multi-view fusion network for lidar semantic segmentation. arXiv 2020, arXiv:2012.04934. [Google Scholar]
- Axelsson, M.; Holmberg, M.; Serra, S.; Ovren, H.; Tulldahl, M. Semantic labeling of lidar point clouds for UAV applications. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021, Nashville, TN, USA, 20–25 June 2021; pp. 4314–4321. [Google Scholar]
- Liu, Z.; Tang, H.; Zhao, S.; Shao, K.; Han, S. Pvnas: 3d neural architecture search with point-voxel convolution. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 8552–8568. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Zhang, R.; Dou, J.; Zhu, Y.; Sun, J.; Pu, S. Rpvnet: A deep and efficient range-point-voxel fusion network for lidar point cloud segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 16024–16033. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Data | mIoU (%) ↑ | Car | Bicycle | Motorcycle | Truck | Other-Vehicle | Person | Bicyclist | Motorcyclist | Road | Parking | Sidewalk | Other-Ground | Building | Fence | Vegetation | Trunk | Terrain | Pole | Traffic-Sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet [22] | Point | 14.6 | 46.3 | 1.3 | 0.3 | 0.1 | 0.8 | 0.2 | 0.2 | 0.0 | 61.6 | 15.8 | 35.7 | 1.4 | 41.4 | 12.9 | 31.0 | 4.6 | 17.6 | 2.4 | 3.7 |
| RandLANet [23] | Point | 53.9 | 94.2 | 26.0 | 25.8 | 40.1 | 38.9 | 49.2 | 48.2 | 7.2 | 90.2 | 60.3 | 73.7 | 20.4 | 86.9 | 56.3 | 81.4 | 61.3 | 66.8 | 49.2 | 47.7 |
| KPConv [24] | Point | 58.8 | 96.0 | 30.2 | 42.5 | 33.4 | 44.3 | 61.5 | 61.6 | 11.8 | 88.8 | 61.3 | 72.7 | 31.6 | 90.5 | 64.2 | 84.8 | 69.2 | 69.1 | 56.4 | 47.4 |
| SqueezeSegv3 [25] | Range | 55.9 | 92.5 | 38.7 | 36.5 | 29.6 | 33.0 | 45.6 | 46.2 | 20.1 | 91.7 | 63.4 | 74.8 | 26.4 | 89.0 | 59.4 | 82.0 | 58.7 | 65.4 | 49.6 | 58.9 |
| RangeNet++ [16] | Range | 52.2 | 91.4 | 25.7 | 34.4 | 25.7 | 23.0 | 38.3 | 38.8 | 4.8 | 91.8 | 65.0 | 75.2 | 27.8 | 87.4 | 58.6 | 80.5 | 55.1 | 64.6 | 47.9 | 55.9 |
| SalsaNext [26] | Range | 59.5 | 91.9 | 48.3 | 38.6 | 38.9 | 31.9 | 60.2 | 59.2 | 19.4 | 91.7 | 63.7 | 75.8 | 29.1 | 90.2 | 64.2 | 81.8 | 63.6 | 66.5 | 54.3 | 62.1 |
| PolarNet [27] | Voxel | 54.3 | 93.8 | 40.3 | 30.1 | 22.9 | 28.5 | 43.2 | 40.2 | 5.6 | 90.8 | 61.7 | 74.4 | 21.7 | 90.0 | 61.3 | 84.0 | 65.5 | 67.8 | 51.8 | 57.5 |
| MinkowskiNet [28] | Voxel | 63.1 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| Cylinder3D [29] | Voxel | 67.8 | 97.1 | 67.6 | 64.0 | 59.0 | 58.6 | 73.9 | 67.9 | 36.0 | 91.4 | 65.1 | 75.5 | 32.3 | 91.0 | 66.5 | 85.4 | 71.8 | 68.5 | 62.6 | 65.6 |
| AF2S3 [30] | Voxel | 69.7 | 94.5 | 65.4 | 86.8 | 39.2 | 41.1 | 80.7 | 80.4 | 74.3 | 91.3 | 68.8 | 72.5 | 53.5 | 87.9 | 63.2 | 70.2 | 68.5 | 53.7 | 61.5 | 71.0 |
| FusionNet [31] | Fusion | 61.3 | 95.3 | 47.5 | 37.7 | 41.8 | 34.5 | 59.5 | 56.8 | 11.9 | 91.8 | 68.8 | 77.1 | 30.8 | 92.5 | 69.4 | 84.5 | 69.8 | 68.5 | 60.4 | 66.5 |
| TornadoNet [32] | Fusion | 63.1 | 94.2 | 55.7 | 48.1 | 40.0 | 38.2 | 63.6 | 60.1 | 34.9 | 89.7 | 66.3 | 74.5 | 28.7 | 91.3 | 65.6 | 85.6 | 67.0 | 71.5 | 58.0 | 65.9 |
| AMVNet [33] | Fusion | 65.3 | 96.2 | 59.9 | 54.2 | 48.8 | 45.7 | 71.0 | 65.7 | 11.0 | 90.1 | 71.0 | 75.8 | 32.4 | 91.4 | 69.1 | 85.6 | 67.0 | 71.5 | 58.0 | 65.9 |
| SPVCNN [34] | Fusion | 63.8 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| PVNAS [35] | Fusion | 67.0 | 97.2 | 50.6 | 50.4 | 56.6 | 58.0 | 67.4 | 67.1 | 50.3 | 90.2 | 67.6 | 75.4 | 21.8 | 91.6 | 66.9 | 86.1 | 73.4 | 71.0 | 64.3 | 67.3 |
| RPVNet [36] | Fusion | 70.3 | 97.6 | 68.4 | 68.7 | 44.2 | 61.1 | 75.9 | 74.4 | 73.4 | 93.4 | 70.3 | 80.7 | 33.3 | 93.5 | 70.2 | 86.5 | 75.1 | 71.7 | 64.8 | 61.4 |
| PIV-Net | Fusion | 70.9 | 97.4 | 67.2 | 68.9 | 43.7 | 61.5 | 76.6 | 75.0 | 73.6 | 92.3 | 71.2 | 80.1 | 32.8 | 92.6 | 70.8 | 86.9 | 74.5 | 72.5 | 64.8 | 62.5 |
| Methods | Data | mIoU (%) ↑ | Barrier | Bicycle | Bus | Car | Construction | Motorcycle | Pedestrian | Traffic-Cone | Trailer | Truck | Driveable | Other_Flat | Sidewalk | Terrain | Manmade | Vegetation |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RangeNet++ [16] | Range | 65.5 | 66.0 | 21.3 | 77.2 | 80.9 | 30.2 | 66.8 | 69.6 | 52.1 | 54.2 | 72.3 | 94.1 | 66.6 | 63.5 | 70.1 | 83.1 | 79.8 |
| PolarNet [27] | Voxel | 71.0 | 74.7 | 28.2 | 85.3 | 90.9 | 35.1 | 77.5 | 71.3 | 58.8 | 57.4 | 76.1 | 96.5 | 71.1 | 74.7 | 74.0 | 87.3 | 85.7 |
| Salsanext [26] | Range | 72.2 | 74.8 | 34.1 | 85.9 | 88.4 | 42.2 | 72.4 | 72.2 | 63.1 | 61.3 | 76.5 | 96.0 | 70.8 | 71.2 | 71.5 | 86.7 | 84.4 |
| AMVNet [33] | Fusion | 76.1 | 79.8 | 32.4 | 82.2 | 86.4 | 62.5 | 81.9 | 75.3 | 72.3 | 83.5 | 65.1 | 97.4 | 67.0 | 78.8 | 74.6 | 90.8 | 87.4 |
| Cylinder3D [29] | Voxel | 76.1 | 76.4 | 40.3 | 91.2 | 92.8 | 51.3 | 78.0 | 78.9 | 64.9 | 62.1 | 84.4 | 96.8 | 71.6 | 76.4 | 75.4 | 90.5 | 87.4 |
| RPVNet [36] | Fusion | 77.6 | 78.2 | 43.4 | 92.7 | 93.2 | 49.0 | 85.7 | 80.5 | 66.0 | 66.9 | 84.0 | 96.9 | 73.5 | 75.9 | 76.0 | 90.6 | 88.9 |
| PVI-Net | Fusion | 78.1 | 78.8 | 43.8 | 93.5 | 93.1 | 48.6 | 87.0 | 80.4 | 65.9 | 67.5 | 85.1 | 97.0 | 74.5 | 75.8 | 76.4 | 90.6 | 89.0 |
| View | mIoU (%) ↑ | Params (M) ↓ | Latency (ms) ↓ |
|---|---|---|---|
| Point | 15.3 | 0.065 | 13.8 |
| Voxel | 65.5 | 23.3 | 97.6 |
| Image | 50.8 | 3.36 | 23.2 |
| Point+Voxel | 68.1 | 24.8 | 125.4 |
| Point+Image | 56.8 | 3.32 | 41.3 |
| Point+Voxel+Image | 70.9 | 28.2 | 158.7 |
| PVC Attention | MF-Attention | Skip Connection | mIoU (%) ↑ |
|---|---|---|---|
| ✓ | 68.8 | ||
| ✓ | ✓ | 69.6 | |
| ✓ | ✓ | ✓ | 70.9 |
| Method | mIoU (%) ↑ |
|---|---|
| Addition | 69.2 |
| Concatenation | 69.5 |
| Our fusion | 70.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Li, C.; Ma, J.; Feng, Z.; Xiao, L. PVI-Net: Point–Voxel–Image Fusion for Semantic Segmentation of Point Clouds in Large-Scale Autonomous Driving Scenarios. Information 2024, 15, 148. https://doi.org/10.3390/info15030148
Wang Z, Li C, Ma J, Feng Z, Xiao L. PVI-Net: Point–Voxel–Image Fusion for Semantic Segmentation of Point Clouds in Large-Scale Autonomous Driving Scenarios. Information. 2024; 15(3):148. https://doi.org/10.3390/info15030148
Chicago/Turabian StyleWang, Zongshun, Ce Li, Jialin Ma, Zhiqiang Feng, and Limei Xiao. 2024. "PVI-Net: Point–Voxel–Image Fusion for Semantic Segmentation of Point Clouds in Large-Scale Autonomous Driving Scenarios" Information 15, no. 3: 148. https://doi.org/10.3390/info15030148
APA StyleWang, Z., Li, C., Ma, J., Feng, Z., & Xiao, L. (2024). PVI-Net: Point–Voxel–Image Fusion for Semantic Segmentation of Point Clouds in Large-Scale Autonomous Driving Scenarios. Information, 15(3), 148. https://doi.org/10.3390/info15030148