1. Introduction
Network intrusion detection assumes paramount significance in ensuring the security and integrity of computer networks within our contemporary interconnected and digital milieu [
1]. It plays an integral role in the identification and prevention of malicious activities that pose threats to the confidentiality, availability, and integrity of sensitive information and digital resources.
Primarily, network intrusion detection is indispensable for the identification and mitigation of diverse cyber threats, encompassing malware, ransomware, and unauthorized access attempts [
2]. Through the meticulous analysis of network traffic patterns and the vigilant monitoring of system logs, intrusion detection systems (IDSs) [
3] can discern unusual or suspicious activities indicative of a potential security breach. Such early detection empowers security teams to respond promptly, thereby minimizing the potential damage inflicted by cyber attacks.
Secondarily, network intrusion detection plays a pivotal role in aiding organizations to conform to stringent regulatory requirements and industry standards [
4]. Various sectors, including finance, healthcare, and government, are subject to rigorous regulations governing the protection of sensitive data. The implementation of effective intrusion detection systems serves to showcase organizational commitment to security and compliance, thereby mitigating the risks of legal and financial repercussions associated with data breaches [
5].
Moreover, network intrusion detection contributes substantively to the overarching risk management strategy of an organization. By identifying vulnerabilities and potential security weaknesses, intrusion detection systems facilitate proactive measures to fortify the network’s defenses [
6]. This includes addressing software vulnerabilities through timely patching, updating security policies, and implementing additional security controls to mitigate the risk of future cyber threats.
Additionally, the significance of network intrusion detection extends to the monitoring of insider threats and employee activities within an organization. The manifestation of malicious insider actions or unintentional security lapses by employees poses considerable risks to an organization’s security [
7]. Intrusion detection systems prove invaluable in detecting abnormal user behavior or unauthorized access attempts, affording organizations the ability to investigate and address potential insider threats.
In summary, network intrusion detection stands as a foundational component of a comprehensive cybersecurity strategy, providing continuous monitoring and analysis of network traffic for the real-time detection and response to cyber threats [
8]. This proactive approach is essential for safeguarding sensitive information, maintaining regulatory compliance, and protecting the overall well-being of an organization amidst the ever-evolving landscape of cyber threats.
The utilization of artificial intelligence (AI) in network intrusion detection becomes imperative due to its efficacy in enhancing the efficiency and accuracy of threat detection within complex and dynamic cyber environments. AI-powered intrusion detection systems harness machine learning algorithms to scrutinize extensive network data, identifying patterns and anomalies indicative of potential security breaches. Unlike traditional signature-based systems, AI-driven solutions exhibit adaptability and learning capabilities, thereby offering a proactive defense against sophisticated and previously unknown cyber attacks. This enables organizations to stay ahead of evolving threats, minimize false positives, and respond more effectively to emerging security challenges, ultimately fortifying the resilience of their network infrastructure in the face of constantly evolving cyber risks.
Furthermore, various studies have explored the application of Artificial Neural Networks (ANNs) in the detection of malicious network traffic [
9]. One such investigation employed the 10-fold cross-validation technique for ANN training, achieving an accuracy (ACC) of 0.98 and an area under the receiver operator characteristic curve (AUC) of 0.98 [
9]. In another study, the UNSW-NB15 dataset and the original dataset were employed to train a Convolutional Neural Network (CNN) for multiclass classification, achieving an accuracy of 0.956 [
10]. Support vector classifiers (SVCs) and extreme learning machines (ELMs) were utilized for network intrusion detection in conjunction with a modified K-Means method for feature extraction, yielding a highest estimation accuracy of 0.9575 [
11]. An ensemble method, comprising Naive Bayes, PART, and Adaptive Boost, was employed for network intrusion detection, achieving the highest accuracy (ACC) of 0.9997 [
12]. Similarly, a multi-layer ensemble method utilizing SVC was applied for network intrusion detection and classification, coupled with a Deep Belief Network for feature extraction, resulting in the highest classification accuracy (ACC) of 0.9727 [
13]. Principal component analysis (PCA) and Auto-Encoder were employed for feature extraction, and a CNN was utilized for the detection of network intrusion types in yet another study, achieving the highest accuracy (ACC) of 0.94 [
14].
The authors in [
15] used recurrent neural networks (RNNs) for network intrusion type detection and compared the classification performance to that achieved with J48, ANN, random forest (RFC) and SVC. In this case, the RNN achieved the highest classification accuracy of 0.9709. The ensemble method based on selection using the Bat algorithm was used in [
16] for the detection of the network intrusion type, and the highest accuracy achieved was 0.98944. A nonsymmetric deep auto encoder with random forest classifier was used [
17] for network intrusion detection on KDD Cup 99 and NSL-KDD benchmark datasets. The highest classification accuracy achieved in this case was 0.979 on the KDD Cup 99 dataset. Deep learning neural networks (DNNs) have been used in [
18,
19] for network intrusion detection, and the highest classification accuracy results achieved in both cases were 0.9995 and 0.9938, respectively.
The reinforcement learning methods have also been used for network intrusion detection [
20,
21]. In [
21], deep Q-learning was used for the detection of different types of network intrusions. The highest accuracy achieved with this model was 0.78.
The results of the previously discussed research are summarized in
Table 1.
From the findings presented in
Table 1, it becomes evident that a predominant number of scholarly works have employed neural networks, specifically Artificial Neural Networks (ANNs) and Convolutional Neural Networks (CNNs), for the purpose of network intrusion detection. In certain investigations, sophisticated ensemble methods have been incorporated alongside ANN/CNN methodologies. Remarkably, all these methodologies have exhibited exemplary levels of detection and classification performance. However, a critical limitation of these approaches lies in their inherent complexity, rendering them resistant to facile transformation into succinct symbolic expressions (SEs). Furthermore, the exigent computational demands for training, storage, and reutilization pose an additional challenge for these AI methods.
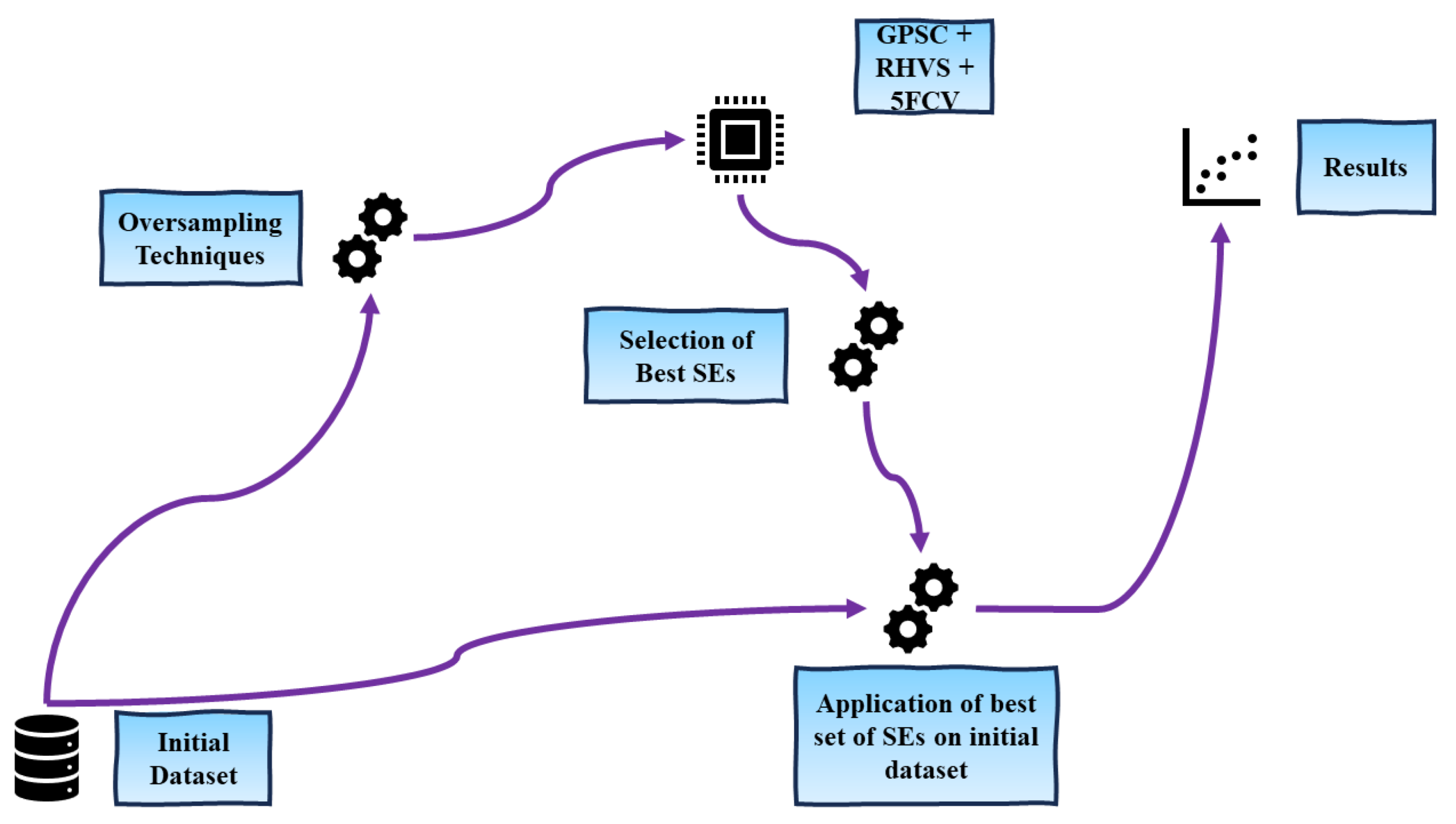
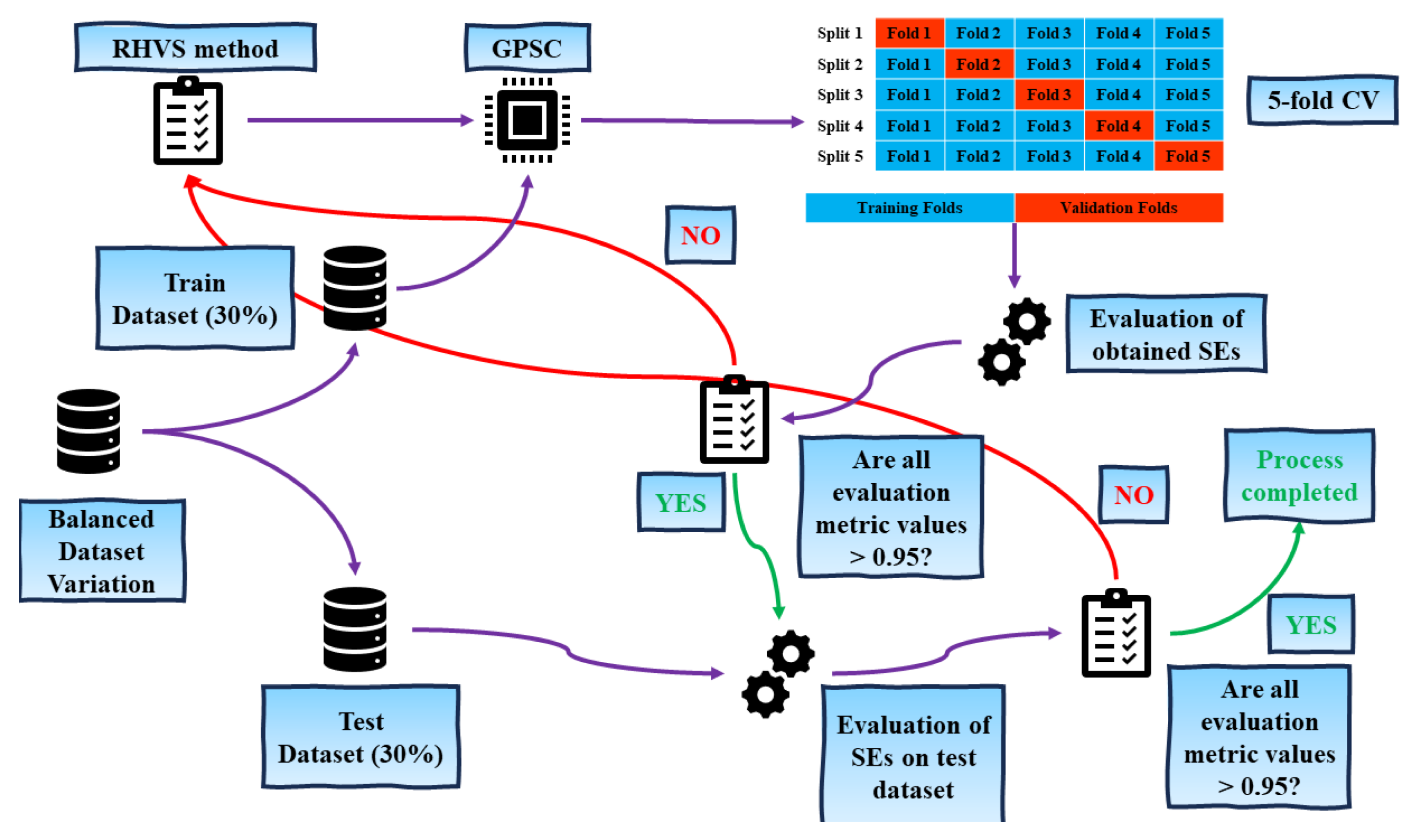
This paper endeavors to surmount these challenges by deploying the Genetic Programming Symbolic Classifier (GPSC) method on a publicly available dataset. The aim is to derive symbolic expressions (SEs) possessing the capacity for highly accurate network intrusion detection. To optimize the classification performance of the resultant SEs, a novel Random Hyperparameter Value Search (RHVS) methodology has been introduced. This method randomly selects hyperparameter values for GPSC, acknowledging the extensive range of parameters involved. The training of GPSC is conducted through a meticulous five-fold cross-validation (5FCV) process, yielding a robust ensemble of SEs. The synergistic integration of GPSC, RHVS, and 5FCV aims to procure a superlative and resilient set of SEs conducive to high-accuracy network intrusion detection.
Given the imbalanced nature of the initial dataset, this paper advocates for the application of diverse oversampling techniques. This strategic maneuver seeks to rectify the class imbalances and facilitate the utilization of balanced dataset variations within GPSC, thereby optimizing the generation of an optimal set of SEs with enhanced discriminatory capabilities. In essence, this paper propounds the integration of GPSC, RHVS, 5FCV, and oversampling techniques as a holistic approach for the acquisition of a robust SE system capable of efficacious network intrusion detection, particularly in the context of imbalanced datasets. Drawing upon the extensive review of existing literature and the distinctive contributions of this paper, the following inquiries emerge:
Can SEs be derived effectively for the purpose of network intrusion detection through the utilization of the GPSC?
Can the attainment of balanced dataset variations through the strategic implementation of oversampling techniques be realized, and to what extent can these oversampling techniques contribute to the enhancement of classification accuracy within the Genetic Programming Symbolic Classifier (GPSC)?
To what extent is it feasible to ascertain the optimal combination of hyperparameter values within GPSC, thereby facilitating the generation of SEs characterized by heightened classification accuracies? This entails the formulation and implementation of a method employing Random Hyperparameter Value Searches.
Can an augmentation in classification accuracy be realized through the amalgamation of the most adept SEs? This entails adjusting the minimum threshold for correct classifications made by SEs, presenting an avenue for improving overall accuracy.
These sophisticated queries encapsulate the core investigatory elements of this study, probing the efficacy and optimization potential of the proposed methodology in network intrusion detection.
The structure of this manuscript encompasses four main sections: Materials and Methods, Results, Discussion, and Conclusions. The Materials and Methods section provides a comprehensive overview of the dataset, incorporating elements such as statistical analysis, correlation analysis, outlier detection, dataset scaling and normalization techniques, oversampling methods, details of the Genetic Programming Symbolic Classifier (GPSC) algorithm, evaluation metrics, and the intricacies of the training procedure.
Moving to the Results section, the presentation unfolds with the display of outcomes derived from analyses conducted on scaled and normalized datasets, emphasizing balanced variations. The final results are then delineated concerning the original, imbalanced dataset. The ensuing Discussion section supplements the results by offering deeper insights into the dataset and its implications.
The Conclusions section encapsulates a succinct summary of the proposed research methodology. It provides a condensed overview, aligning the conclusions with the hypotheses posited in the introduction and substantiated in the discussion. Additionally, this section offers a nuanced exploration of the advantages and disadvantages of the proposed research methodology, concluding with a forward-looking perspective on potential future research avenues.
An adjunct to the primary sections, an
Appendix A is appended, furnishing supplementary details pertaining to modified mathematical functions utilized in GPSC. Furthermore, a procedural guide on accessing and utilizing the obtained SEs in this research is included. This meticulous arrangement ensures a comprehensive and organized presentation of the research endeavors and outcomes.
3. Results
Within this section, the outcomes showcase the optimal SEs derived from the balanced dataset variations. Subsequently, these premier SEs were amalgamated into an ensemble and subjected to testing on the initial imbalanced dataset. The ensuing examination delves into the classification performance of the ensemble, considering the tally of accurate predictions as a pivotal metric.
3.1. The Best Symbolic Expressions
The premier SEs acquired from each balanced dataset variation were derived through the selection of optimal GPSC hyperparameter values, determined randomly via the RHVS method. The particulars of the optimal GPSC hyperparameter values, instrumental in obtaining the most effective SEs for each balanced dataset variation, are enumerated in
Table 7.
Examining
Table 7 reveals distinctive trends in the selection of optimal GPSC hyperparameter values across various balanced dataset variations. Notably, the SVMSMOTE dataset application necessitated the utilization of the highest population size, followed closely by the ADASYN dataset. In contrast, the remaining datasets saw GPSC employ lower population size values, strategically aligned near the lower boundary of the Random Hyperparameter Value Search (RHVS) method as delineated in
Table 5. The adoption of a larger population size assumes significance in fostering heightened diversity within the population.
Crucially, an additional pivotal hyperparameter influencing population diversity is the initial tree depth. The SMOTE dataset witnessed the implementation of the most substantial initial tree depth, whereas the ADASYN dataset observed the application of the smallest depth. The predominant termination criterion for GPSC in this investigation was the number of generations. Given the dual termination criteria within GPSC—number of generations and stopping criteria—the latter remained unmet throughout, as its predetermined value (minimum fitness function value) proved exceptionally low, preventing attainment by any population member. The stopping criteria ranged from for the SMOTE dataset to for the SVMSMOTE dataset.
A prevailing genetic operation in this study was the subtree mutation, consistently featuring values of 0.95 or higher. The max samples parameter consistently exceeded 0.99 across all GPSC executions. Notably, the KMeansSMOTE dataset exhibited the broadest range of constant values (−735.19, 492.48), signifying a distinctive range of evolutionary operations. Examining the parsimony coefficient values from
Table 7, it is evident that the coefficients are uniformly diminutive, with the KMeansSMOTE dataset registering the lowest (
) and the BorderlineSMOTE dataset recording the highest (
) coefficient. Despite their modest values, these parsimony coefficients effectively mitigated the bloat phenomenon, ensuring the stability and efficiency of GPSC executions in this investigation.
In
Figure 6, the change of loss value (fitness function value) over number of generations for one split in 5FCV is shown in case of GPSC and MLP Classifier applied on the SMOTE dataset. The MLP Classifier configuration consisted of three hidden layers with relu activation function. The first hidden layer consisted of 50 neurons; the second, 20 neurons; and third, 10 neurons. The MLP Classifier was just used for comparison and is labeled ANN in
Figure 6.
As seen from
Figure 6, the log-loss value in the first 50 generations drops from 0.5 to 0.08 value and continuously decreases up to the 248th generation. However, the drop from the 50th to 248th generation is much lower when compared to the drop in the first 50 generations. On the other hand, ANN (MLP classifier) showed a high drop in value in the first 20 iterations, and up to the 248th iteration, the decrease in the loss function was low. When these loss values are compared, it can be noticed that the GPSC outperformed the ANN.
The evaluation metric values of the best SEs obtained on the train and test datasets are graphically shown in
Figure 7.
Examining
Figure 7 reveals notable disparities in the classification performance of the best SEs derived from diverse balanced dataset variations. Particularly, the highest classification performance is discerned in SEs obtained from the SVMSMOTE dataset. A descending order of classification performance follows for SEs derived from SMOTE, KMeansSMOTE, BorderlineSMOTE, and ADASYN datasets. It is noteworthy that even the SEs obtained from the ADASYN dataset exhibit commendable classification accuracy, albeit the lowest in this comparative analysis, standing at 0.968.
Across all balanced dataset variations, the standard deviation for the best SEs is remarkably small, underscoring the consistency of performance. The set of SEs derived from the BorderlineSMOTE dataset, specifically in terms of mean precision, yields the lowest standard deviation. Notably, when comparing the standard deviation among the best SEs obtained from diverse dataset variations for all evaluation metrics, a slightly elevated standard deviation is observed in the case of SEs derived from the ADASYN dataset.
As elucidated in the GPSC description, the size of obtained SEs can be assessed through two dimensions: depth and length. Depth is measured along the tree structure representation during GPSC execution, spanning from the root node (the first element in text representation) to the deepest leaf. Length, on the other hand, quantifies the entirety of elements within a symbolic expression, encompassing mathematical functions, input variables, and constants.
For a comprehensive understanding,
Table 8 enumerates the depth and length measurements for the best SEs acquired from diverse balanced dataset variations.
Analyzing
Table 8 reveals distinctive characteristics in the depth and length metrics of SEs obtained from various balanced dataset variations. Notably, SEs acquired from the BorderlineSMOTE dataset exhibit the lowest average depth and length, while those derived from the KMeansSMOTE dataset showcase the highest average values for both depth and length. The SEs obtained from the SVMSMOTE dataset, conversely, demonstrate the highest average length.
Further scrutiny of
Table 8 underscores that SEs sharing identical depth values may exhibit dissimilar lengths. For instance, SE1 and SE2 obtained from the BorderlineSMOTE dataset both possess a depth of 16, yet SE1 has a length of 92, while SE2 spans 114 elements. A similar trend is observed for SE4 obtained from the KMeansSMOTE dataset, where despite an equal depth of 17, the length registers as 129.
This decoupling of depth and length is further exemplified by SE5 from the ADASYN and KMeansSMOTE datasets, as well as SE2 from the SVMSMOTE dataset, all featuring a shared depth of 17, yet showcasing distinct length values: 160, 177, and 123, respectively. These instances illustrate that identical depth values do not imply uniform length values for SEs.
Subsequent analysis of the best SEs illuminates the requisite input variables for their utilization. With the exception of , , , , and , the majority of input variables are essential for incorporating all the best SEs. Distinct sets of non-essential variables emerge for SEs obtained from different dataset variations. For instance, the best SEs from the ADASYN dataset do not necessitate , , , , , , and . In comparison, the best SEs from the BorderlineSMOTE dataset, in addition to the aforementioned variables, also exclude , , and . Analogously, the best SEs from the KMeansSMOTE dataset exclude , , and , while those from the SMOTE dataset omit , , , , , and . Finally, the best SEs from the SVMSMOTE dataset, apart from , , , , and , do not require .
For a detailed guide on downloading and utilizing the obtained SEs, refer to
Appendix A.2.
4. Discussion
In this investigation, the utilization of a publicly available dataset was instrumental in the derivation of SEs employing the GPSC for the purpose of network intrusion detection, with a specific focus on achieving elevated classification performance. The initial dataset, characterized by its imbalanced nature, necessitated meticulous data preprocessing, particularly in transforming variables from a string to numeric format. The outcomes of these transformations are meticulously detailed in
Table 2.
Subsequent to the application of the LabelEncoder for dataset transformation, an initial statistical analysis was conducted to ascertain crucial parameters, such as minimum, maximum, mean, and standard deviation. This analysis revealed a dataset void of missing values, comprising 25,192 samples across all 44 variables, including the output (target) variable. However, two variables, namely num_outbound_cmds and is_host_login, exhibited constant values of 0. Despite this, these values were retained within the dataset. The statistical summary exposed a uniform minimum value of 0 across all dataset variables. The class variable demonstrated a mean value of 0.53 and a standard deviation of 0.49, indicative of a marginal class imbalance, necessitating potential oversampling.
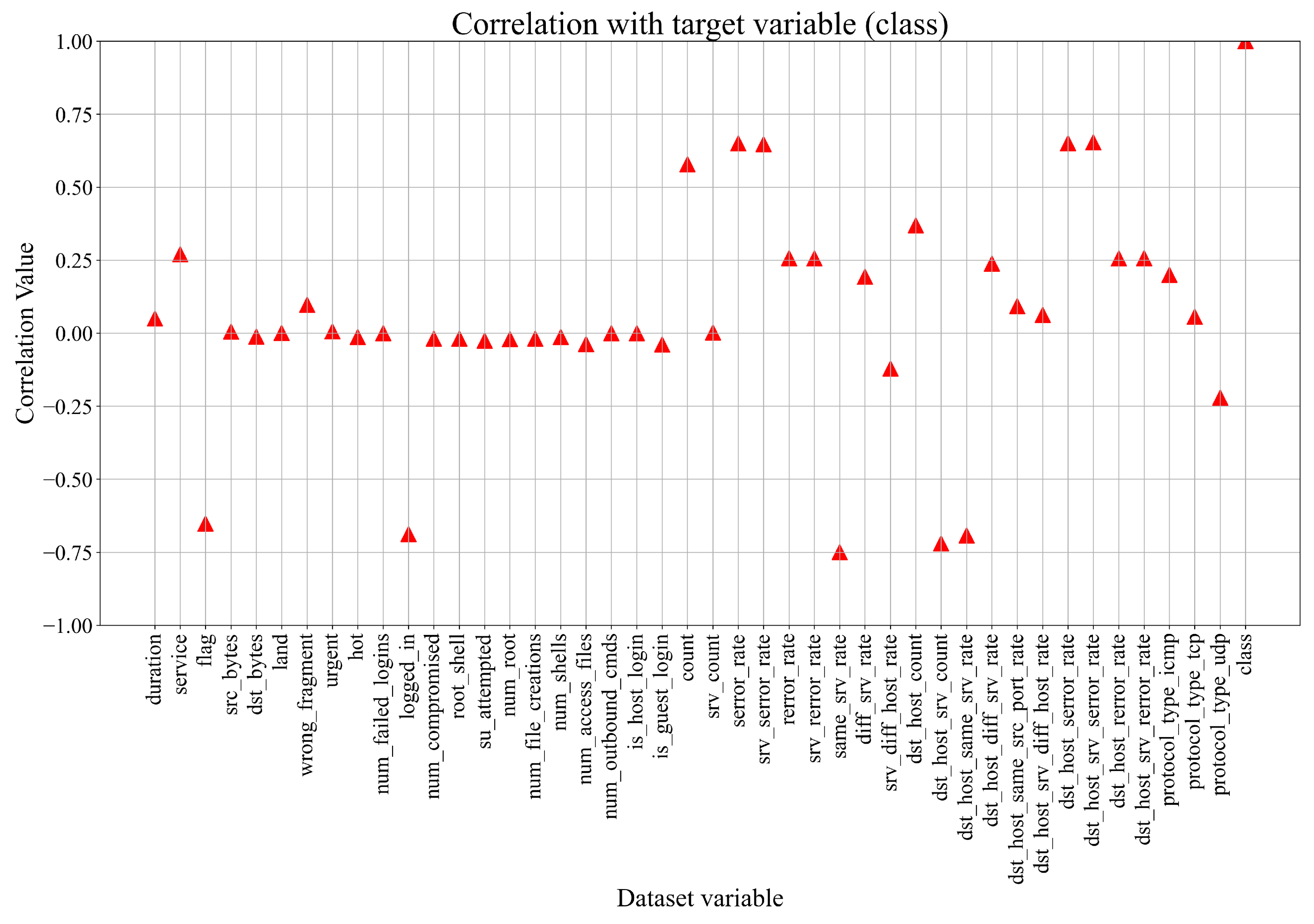
Given the substantial number of variables, the exploration of a correlation matrix proved inelegant for this study. Consequently, Pearson’s correlation analysis focused solely on the class variable, revealing noteworthy insights portrayed in
Figure 2. This analysis unveiled that merely five input variables exhibited a positive correlation with the class variable, while another five displayed a robust negative correlation. Notably, a majority of variables exhibited correlations below 0.5 or above −0.5, suggesting proximity to zero.
Efforts were directed towards balancing the initially imbalanced dataset through the application of the BorderlineSMOTE, SMOTE, and SVMSMOTE oversampling techniques. However, perfect balance was not universally achieved as evidenced by ADASYN and KMeansSMOTE. Despite a marginal discrepancy in the sample counts, the dataset variations obtained using ADASYN and KMeansSMOTE were considered well balanced and were consequently employed in this investigation.
The implementation of GPSC, coupled with a Random Hyperparameter Value Search method on each dataset variation, demanded time investments to ascertain the optimal hyperparameter values conducive to the derivation of SEs boasting optimal classification performance. The examination of optimal hyperparameter combinations revealed nuanced patterns, such as varying population sizes and termination criteria across different oversampled datasets.
The culmination of this research is embodied in the performance evaluation of the best SEs on balanced dataset variations (
Figure 7). The achieved classification performance exhibited a remarkable range of accuracy, consistently surpassing 0.96 and falling below 0.985. The subsequent application of the amalgamated best SEs to the initial imbalanced dataset yielded exceptional evaluation metric values, each exceeding 0.99 (
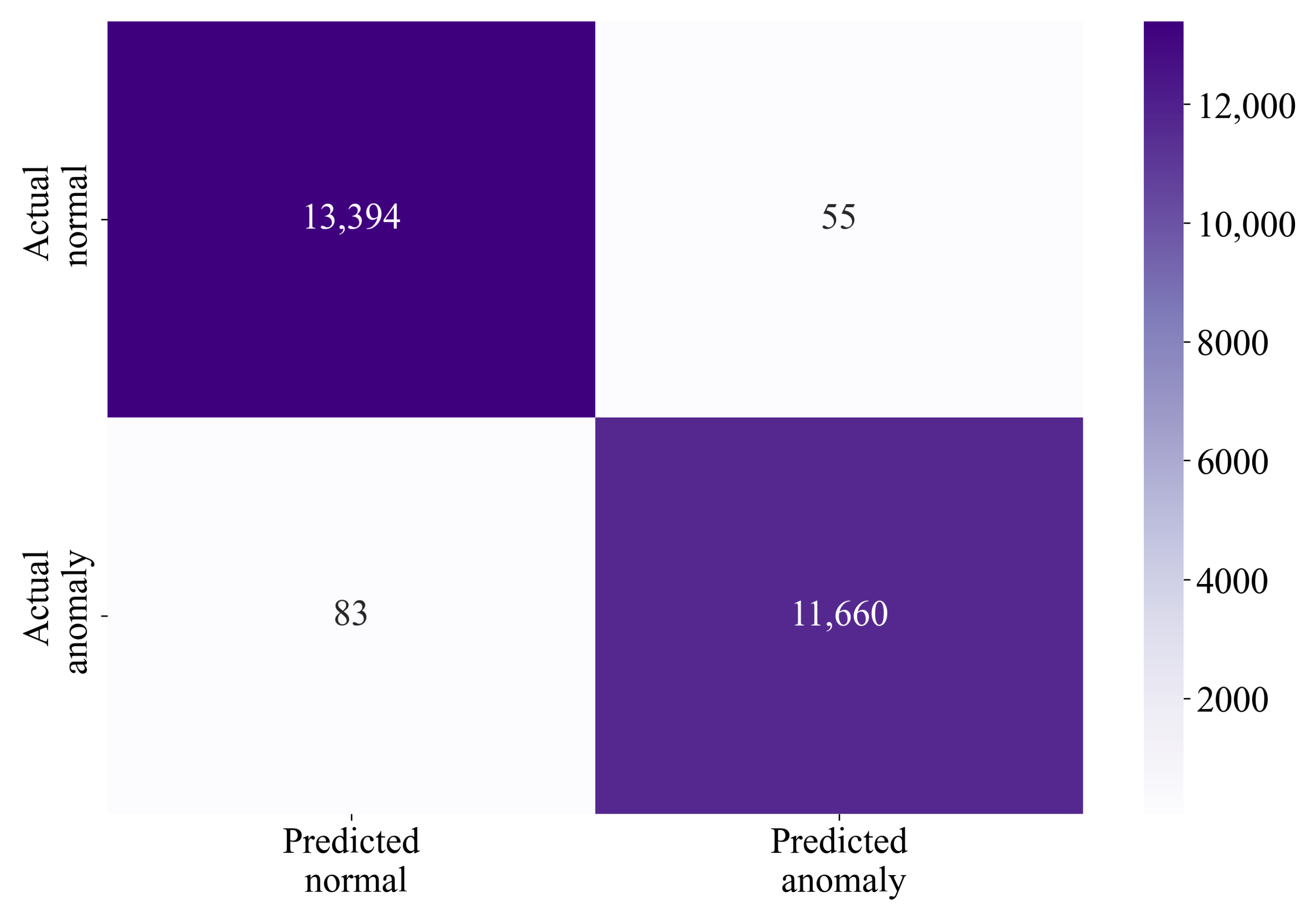
Table 8). The confusion matrix (
Figure 8) attested to the superb performance of the best SEs, with minimal misclassifications observed.
A comparative analysis of the proposed approach and results vis à vis prior research is elucidated in
Table 10, underscoring the noteworthy contributions of the presented methodology.
Upon scrutinizing the results comparison delineated in
Table 9, it becomes evident that the research proposed in this paper exhibits superior performance in contrast to a majority of outcomes reported in other research papers. While acknowledging that the results in [
12] marginally surpass those presented herein, it is noteworthy that the proposed methodology outperforms a significant array of alternative investigations.
The distinctive advantage conferred by the presented methodology in this paper lies in the acquisition of SEs capable of network intrusion detection with exceptional classification accuracy. The SEs, once obtained, offer the distinct benefit of efficient storage and obviate the need for substantial computational resources when calculating outputs for new samples. This attribute further underscores the practicality and efficiency of the proposed approach.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}