In the framework of RL, the individual undergoing the learning process is referred to as an agent, who also serves as the active participant in the learning system. The agent engages with the environment, its immediate surroundings, by executing actions. Upon performing an action inside a given environmental condition, the agent is rewarded and the system undergoes a transition to a different state. The primary objective of RL is to discover an optimal approach, comprising a series of actions, which can maximize the total reward, thereby delivering the most efficient solution to a specified problem. Within the framework of HDLBP, a RL algorithm acquires the most advantageous allocation strategy by utilizing live interactive data, ultimately achieving the ideal answer. Therefore, it is quite important to utilize the reinforcement learning approach for the HDLBP.
4.3. Reinforcement Learning Environment of HDLBP
During the interaction process between an agent and its environment, the actions executed by the agent lead to state transitions and subsequent reward outcomes. Well-designed actions play a critical role in enabling the agent to efficiently attain optimal rewards. Although the SAC algorithm is initially developed for environments with continuous action spaces, certain adaptations of SAC can be extended to accommodate discrete action environments as well.
This study employs OpenAI Gym to construct the HDLBP environment. Discrete and MultiDiscrete classes define discrete problems within the Gym framework, whereas the continuous problem action space is specified using the Box class.
The Discrete action space in OpenAI comprises discrete non-negative integers. The Discrete(4) distribution can be employed to represent a maze issue that involves four unique actions.The values 0, 1, 2, and 3 correspond to leftward, rightward, upward, and downward movement, respectively. MultiDiscrete enables simultaneous control over several discrete activities.
The Box action space is a formal representation utilized in reinforcement learning to encapsulate continuous action domains. It delineates a multi-dimensional space comprising real numbers, where each dimension corresponds to an action parameter capable of assuming any real value. Defined by two vectors, namely “low” and “high”, this space establishes the lower and upper bounds for each dimension, respectively, thereby offering a flexible range of action possibilities. The Box action space finds application in tasks necessitating fine-grained control and continuous action modulation, such as robotic manipulation, unmanned aerial vehicle navigation, and financial trading. Leveraging the Box action space, agents can iteratively select actions within specified bounds, facilitating ongoing interaction and optimization within the environment.
In this paper, the MO-A2C solves HDLBP as shown in
Figure 3. The agent generates actions based on the current strategy, and we encode and decode the actions (
Figure 4). Through the interaction with the environment, the corresponding state information, reward information, and two target values are obtained. According to the memory pool access rules, the eligible target values are written into the memory pool, the solution is evaluated, and the corresponding reward is output (
Figure 5). Save the status information, reward information, and action information to the experience pool. The agent modifies the strategy according to the information in the experience pool and repeats the above training.
(1) State Space
The state space is mostly used to store the disassembly state, which has two states: undisassembled () and fully disassembled (). The initial undisassembled state is denoted as , while the fully disassembled state after completing all tasks is represented by . Only alterations in the general condition are taken into consideration during disassembly, excluding any intermediate phases in the disassembly procedure.
(2) Action Space
We elucidate the procedure for selecting a disassembly line within a continuous action space. Consider a scenario where two products necessitate allocation to one of two distinct disassembly lines. Each dimension in the action space pertains to the selection of a disassembly line for a specific product, with the action space spanning from [0.0, 0.0] to [2.0, 2.0]. To ascertain the allocation, a vector of real numbers with a dimensionality of 2 is generated, where each value falls within the interval of 0.0 to 2.0. This vector denotes the assignment of each product to a particular disassembly line. Subsequently, the allocation values undergo mapping: if a sampled value falls within the interval [0.0, 1.0), the product is allocated to the LDL (represented by 0). Conversely, values falling within the range [1.0, 2.0] dictate allocation to the UDL (represented by 1). Upon completion of the mapping process, the subsequent encoding and decoding procedures follow a methodology analogous to that utilized in the MultiDiscrete class.
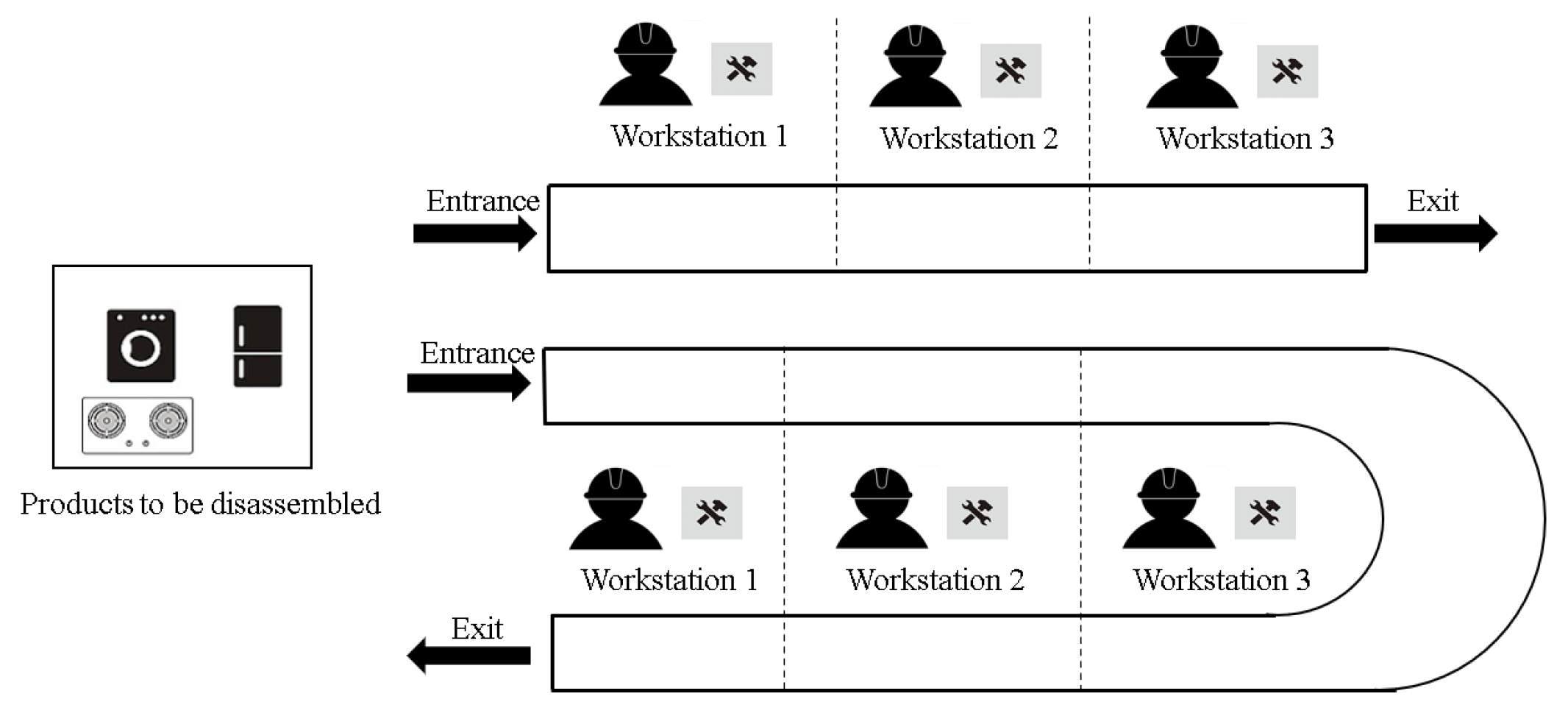
Referring to the HDLBP illustration in
Figure 4, where the product needs to be disassembled, there are two workstations on each line, and the specific meaning of the action selection code is shown in
Table 4. There are two steps for each disassembly product. The first step is to select the disassembly line of the product, and the second step is to assign the disassembly task to the workstation. In order to distinguish the inlet and outlet sides of the UDL workstation, two workstations have four options. When a product is allocated to a LDL, the task assignment to workstations is contingent upon the output values of the task selection, where values 0 or 1 assign to workstation 1, whereas values 2 or 3 assign to workstation 2. In the UDL, an output value of 0 directs task assignment to the entry side of workstation 1; a value of 1 corresponds to assignment at the entry side of workstation 2; a value of 2 leads to assignment at the exit side of workstation 2; and a value of 3 triggers assignment at the outlet side of workstation 1. Specific values represent unique disassembly selection operations, with the target value set according to the chosen operation.
As shown in
Figure 4, the agent may randomly choose the action code [0, 1, 2, 2] for product 1; this indicates that product 1 is slated for disassembly on the LDL, with task 1 being assigned to workstation 1, and tasks 2 and 3 being allocated to workstation 2.
Algorithm 1 shows the pseudocode of action for disassembly tasks. It takes as inputs the disassembly parameters, the action space, and the observation space. The outputs of the algorithm are obj1 and obj2. The algorithm operates in an iterative manner, looping over each product. For each product, it selects a disassembly line from the action space based on the assigned action for that particular product, stored in the variable . If is equal to 0, it means that the disassembly will take place on a linear workstation. In this case, the algorithm enters a nested loop, iterating over each task associated with the disassembly. Within this loop, it retrieves the assigned action for the current product and task, stored in the variable , and applies Algorithm 2.
Lastly, the algorithm calculates obj1 and obj2. On the other hand, if is not equal to 0, it implies that the disassembly will occur on a U-shaped workstation. The algorithm follows a similar pattern as above, but this time the assigned action for the current product and task is retrieved and stored in the variable before applying Algorithm 2. Finally, obj1 and obj2 are calculated. After processing all products, the algorithm returns obj1 and obj2 as the final output. In summary, the algorithm determines the disassembly line for each product based on the assigned actions, performs the corresponding disassembly tasks using the specified workstations (either linear or U-shaped), and calculates obj1 and obj2 as the results of these operations.
Algorithm 2 described in the pseudocode is called “action correction and decoding”. The inputs to the algorithm are two arrays, a linear workstation denoted by and a U-shaped workstation denoted by , as well as a line parameter indicating which type of workstation is being used. The outputs of the algorithm are the updated version of the two workstations and . The algorithm first sorts the values of the workstations in ascending order and then checks the value of the line parameter. If the line parameter equals 0, each element in the workstation arrays is updated based on its original value. Specifically, if the value is either 0 or 3, it is changed to 1; if the value is either 1 or 4, it is changed to 2; otherwise, it is changed to 3.
On the other hand, if the line parameter equals 1, each element in the workstation arrays is also updated based on its original value, but following a different set of rules. Specifically, if the value is either 0 or 5, it is changed to 1; if the value is either 1 or 4, it is changed to 2; otherwise, it is changed to 3. In summary, the algorithm provides a method for correcting and decoding the actions taken at two different types of workstations, based on their original values and the type of the production line being used. Handling incorrect actions can be achieved by providing negative feedback rewards to reduce the probability of the agent selecting incorrect actions. However, at the same time, training efficiency would significantly decrease, necessitating an increase in the number of training iterations to obtain satisfactory results. In contrast, correcting incorrect actions can accelerate training speed and enhance the agent’s exploration capabilities. It can also lead to better quality solutions within the same number of training iterations compared to negative feedback reward methods.
(3) Reward Function
In the definition of reward, we evaluate the reward that the agent can obtain in this state according to the quality of the multi-objective solution. Firstly, a memory pool is established to store the multi-objective solution of the training process, and the experience pool is empty in the initial state. The solution obtained by training during the first round can be successfully stored in the memory pool and a positive feedback reward can be obtained. Whether the solution of each subsequent training can enter the memory pool is determined according to the dominance relationship. Assuming that the new solution is , the minimum value and maximum value of target 1 in the memory pool is , and the minimum value maximum value of target 2 is . We set the reward coefficient and . The specific circumstances of the reward are divided into the following three.
For the repeated solution, we use the reward coefficient and to guide the exploration direction of the agent. In the initial state, both and values are 1. When the repeated solution belongs to the first kind, reducing the value of increases the value of , and guides the agent to explore on the same Pareto front. When the repeated solution belongs to the second kind, increasing the value of and decreasing the value of will lead the agent to explore the better solution.
The pseudocode in Algorithm 3 outlines a framework for the Non-Dominated Sort in A2C. The algorithm takes two input objectives, namely obj1 and obj2, and produces a single output reward. The algorithm begins by initializing the parameters, including the memory pool D and the weighting factors and , both set to 1. For each iteration, the algorithm proceeds to perform environment steps. If the memory pool D is not empty, the algorithm identifies the minimum and maximum values of “target1” as and , respectively, and the minimum and maximum values of “target2” as and , respectively. Next, the algorithm checks if obj1 is greater than and obj2 is less than . If this condition is satisfied, it further checks whether the solution is repeated. If the solution is repeated, the weighting factors are updated (), and the reward is calculated as . Otherwise, the reward is calculated as , and the memory pool D is updated. If the previous condition is not satisfied, the algorithm checks if obj1 is less than or “obj2” is greater than . Again, if the solution is repeated, the weighting factors are updated (), and the reward is calculated as . Otherwise, the reward is calculated as , and the memory pool D is updated.
The pseudocode in Algorithm 4 uses the environment
and the number of episodes
N as input parameters. The algorithm first initializes the policy network
and the value network
V, as well as the optimizers for the policy network and the value network. Then, for each episode
, the algorithm resets the environment and initializes the current state
s, clearing the episode buffer. In each episode, the algorithm selects an action
a from the current state
s using the policy network
, executes the action
a, uses Algorithms 1 and 3 to calculate reward
r, observes the reward
r and the next state
, and stores the state transition
in the episode buffer. Then, the state
s is updated to
. When the episode is finished, the algorithm calculates the discounted rewards
for each time step
t in the episode buffer, as well as the advantages
for each time step
t. Next, the algorithm uses gradient ascent to update the parameters
of the policy network
based on the expected cumulative rewards. Then, the algorithm uses the mean squared error loss function to update the parameters
of the value network
V based on the difference between the predicted and actual rewards. Finally, the algorithm repeats this process until all episodes are completed and returns the learned policy network
as output.
| Algorithm 4: MO-A2C. |
![Information 15 00168 i004]() |














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}