Task Staggering Peak Scheduling Policy for Cloud Mixed Workloads

Abstract
:1. Introduction
- The task sequences of mixed workloads are divided into multiple types of queues by the fuzzy clustering algorithm based on different task characteristics.
- We introduce the Performance Counters (PMC) mechanism to dynamically monitor the node resource load status and respectively sort the resources by CPU, memory, and I/O load size.
- We develop a policy SPSLAM from the perspective of task types and resource load for mixed workloads and by doing so, the system can realize load balancing and improve efficiency.
2. Related Work
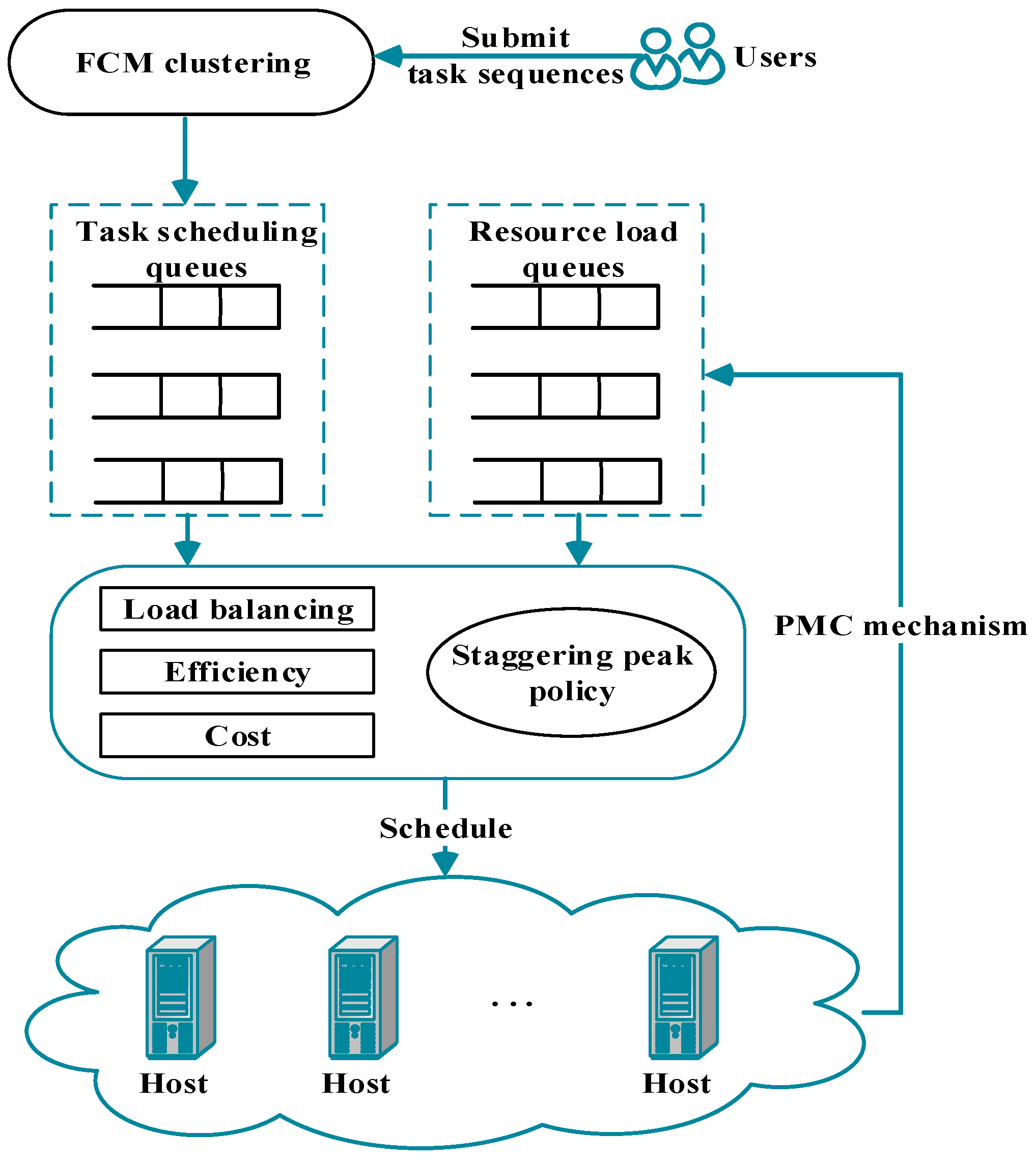
3. Model Description
System Framework Model
4. Staggering Peak Scheduling Policy
4.1. Task Sequences Classification
| Algorithm 1: The algorithm of task sequences classification |
| Input: Output: 1: Initialize the sample matrix through the task attribute values ; 2: for do 3: Standardize and normalize to get ; 4: End for 5: Initialize the membership matrix ; 6: Do calculate three cluster centers; 7: Calculate the value function ; 8: Recalculate the membership matrix ; 9: Until 10: Return ; |
4.2. Resources Load Sorting
4.3. Staggering Peak Policy
| Algorithm 2: SPSLAM |
| Input: Output: 1: for 2: if has been scheduled then 3: if then 4: Schedule into ; 5: End if 6: if then 7: Schedule into ; 8: End if 9: if then 10: Schedule into ; 11: End if 12: End if 13: End for |
5. Experiments and Evaluation
5.1. Workloads and Setup
5.2. Experiment Metrics
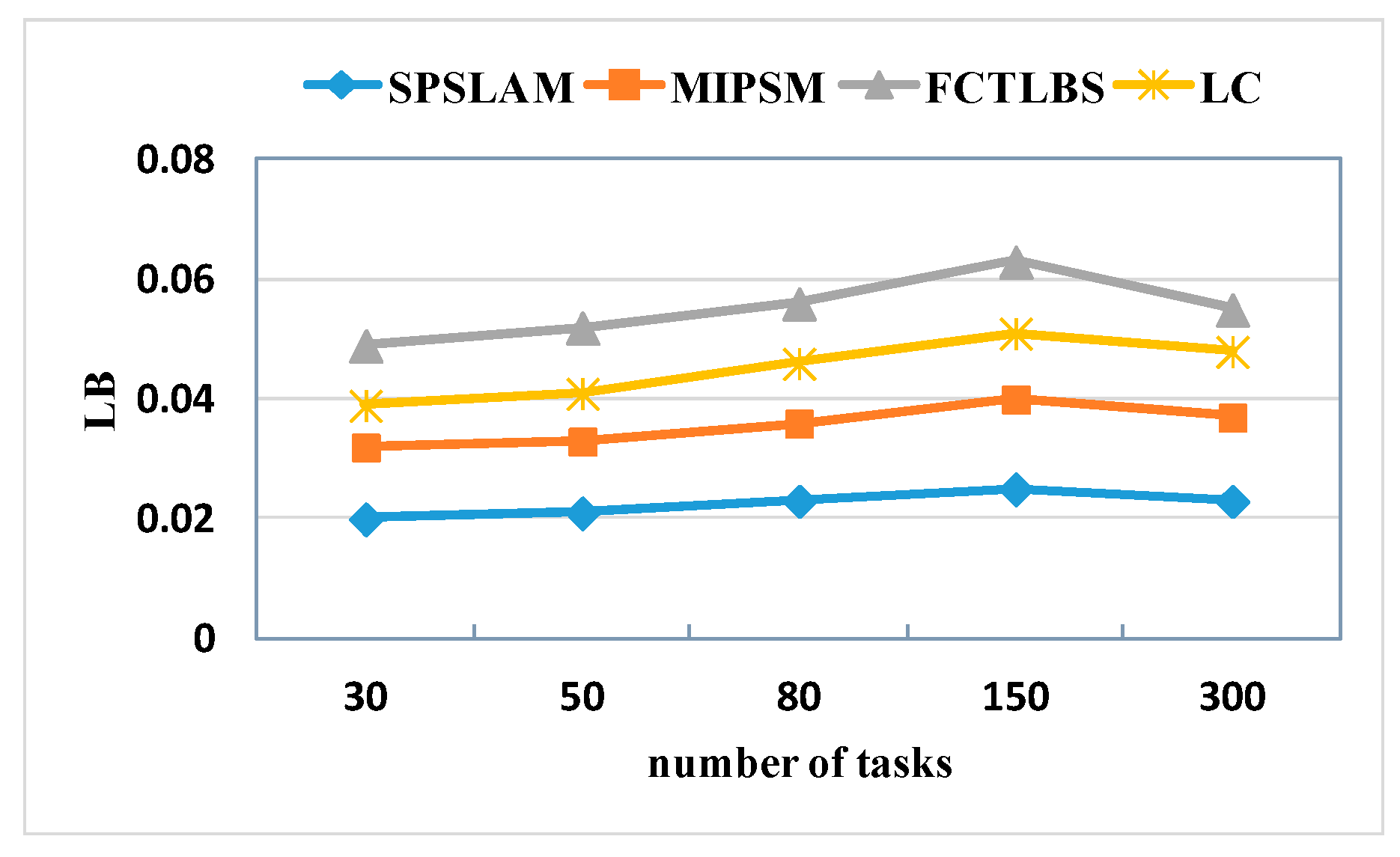
5.2.1. Load Balancing
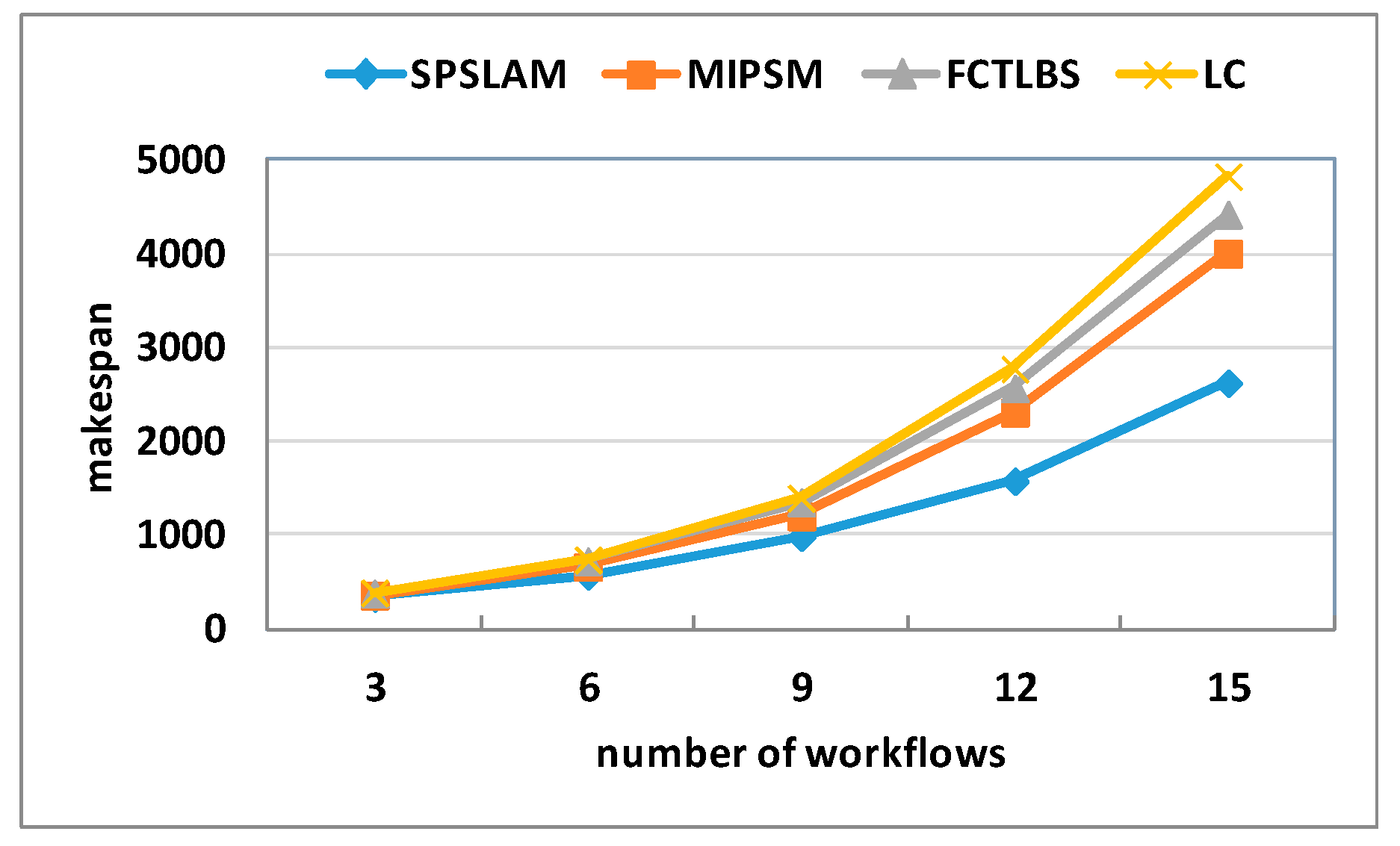
5.2.2. Scheduling Completion Time
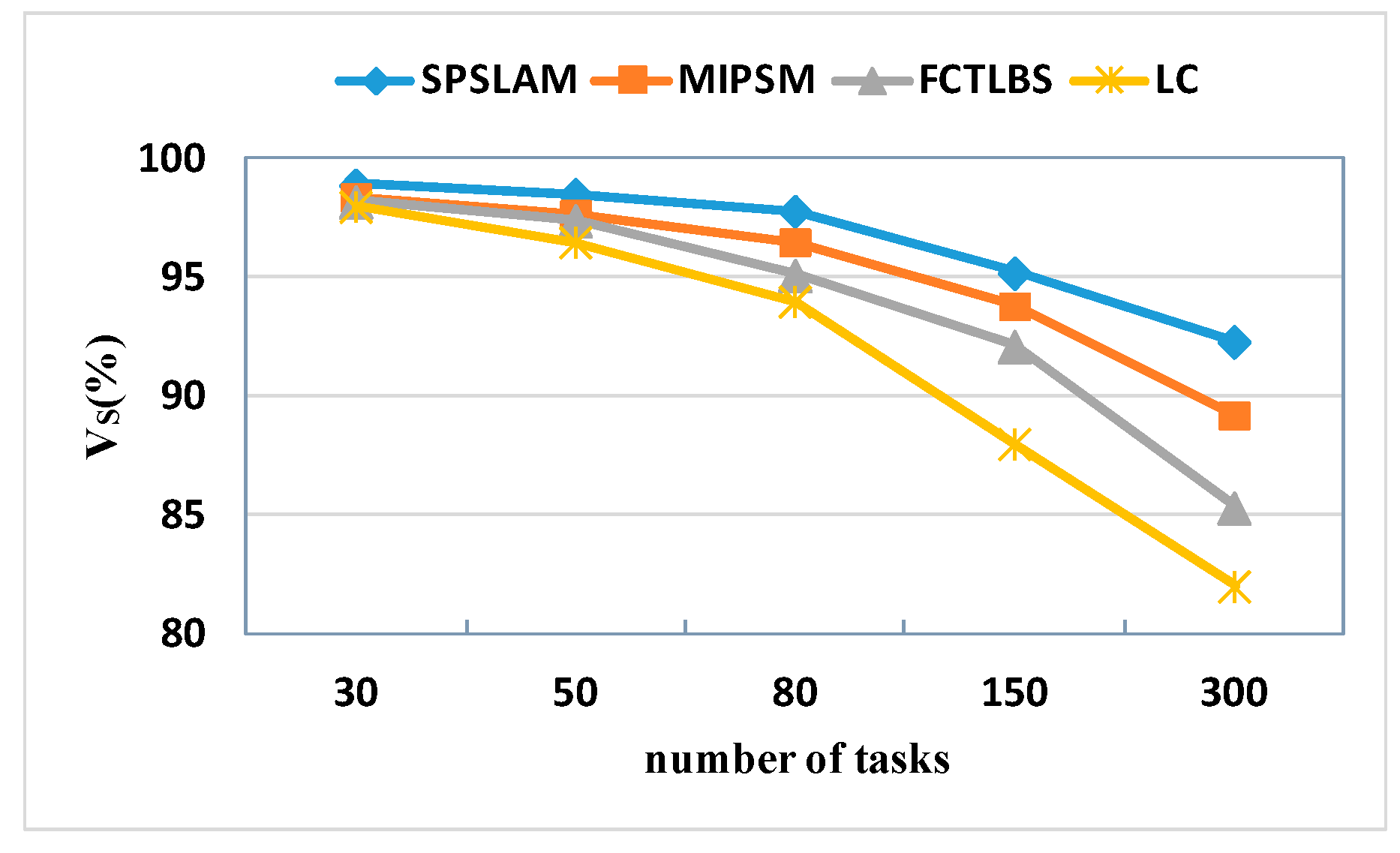
5.2.3. Task Success Rate
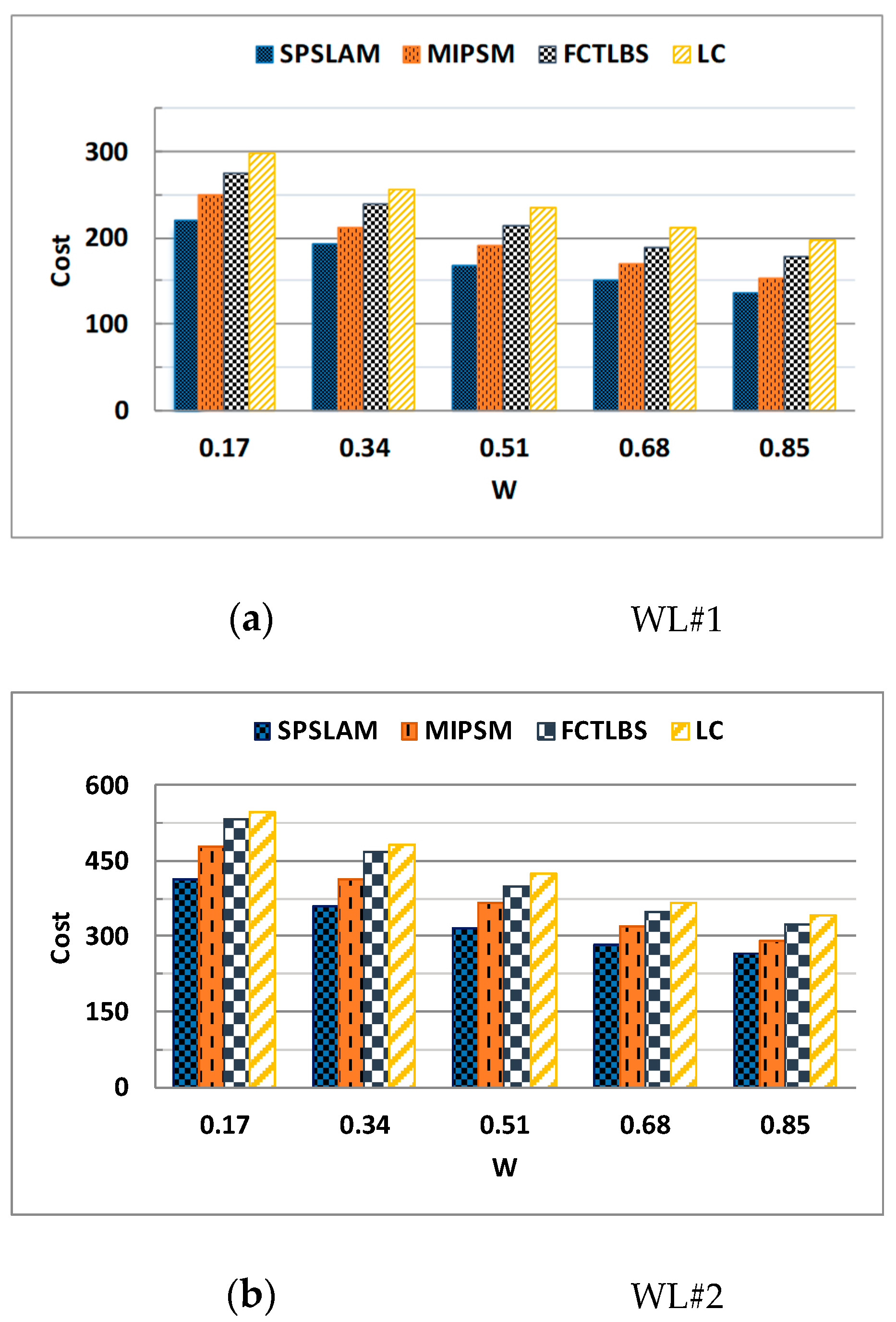
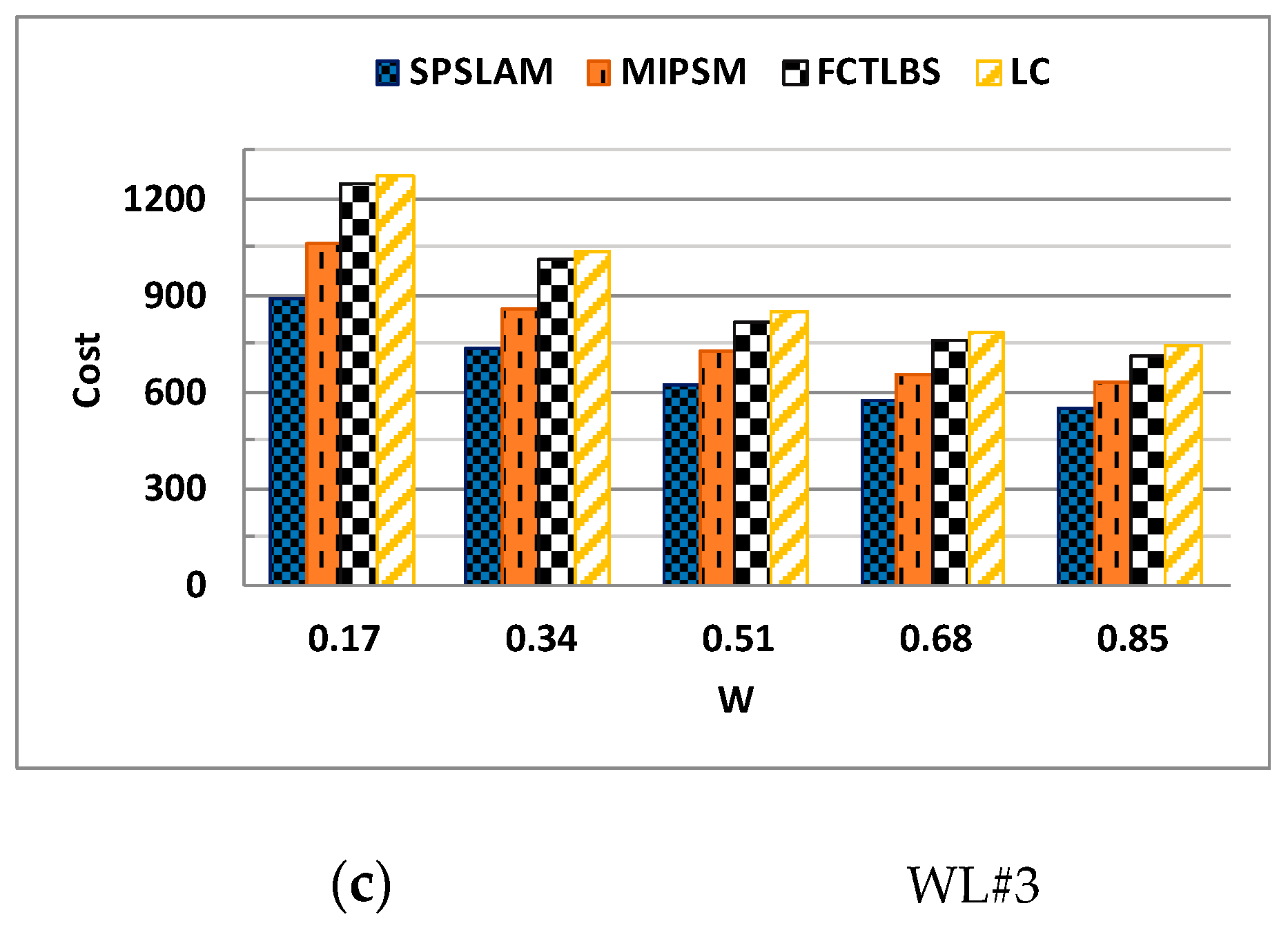
5.2.4. Resource Usage Cost
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hameed, A.; Khoshkbarforoushha, A.; Ranjan, R.; Jayaraman, P.P.; Kolodziej, J.; Balaji, P.; Zeadally, S.; Malluhi, Q.M.; Tziritas, N.; Vishnu, A.; et al. A survey and taxonomy on energy efficient resource allocation techniques for cloud computing systems. Computing 2016, 98, 751–774. [Google Scholar] [CrossRef]
- Yousafzai, A.; Gani, A.; Noor, R.M.; Sookhak, M.; Talebian, H.; Shiraz, M.; Khan, M.K. Cloud resource allocation schemes: Review, taxonomy, and opportunities. Knowl. Inf. Syst. 2017, 50, 347–381. [Google Scholar] [CrossRef]
- Madni, S.H.H.; Latiff, M.S.A.; Coulibaly, Y.; Abdulhamid, S.M. Resource scheduling for infrastructure as a service (IaaS) in cloud computing. J. Netw. Comput. Appl. 2016, 68, 173–200. [Google Scholar] [CrossRef]
- Kapil, D.; Tyagi, P.; Kumar, S.; Tamta, V.P. Cloud Computing: Overview and Research Issues. In Proceedings of the International Conference on Green Informatics, Fuzhou, China, 15–17 August 2017. [Google Scholar]
- Wang, R.; Shang, P.; Zhang, J.; Wang, Q.; Liu, T.; Wang, J. MAR: A Novel Power Management for CMP Systems in Data-Intensive Environment. IEEE Trans. Comput. 2016, 65, 1816–1830. [Google Scholar] [CrossRef]
- Mon, E.E.; Thein, M.M.; Aung, M.T. Clustering based on task dependency for data-intensive workflow scheduling optimization. In Proceedings of the Workshop on Many-Task Computing on Clouds, Grids, and Supercomputers (MTAGS), Salt Lake City, UT, USA, 14 November 2016. [Google Scholar]
- Yang, J.; Meng, Q.; Wang, S.; Li, D.; Huang, T.; Dou, W. Energy-Aware Tasks Scheduling with Deadline-constrained in Clouds. In Proceedings of the IEEE International Conference on Advanced Cloud and Big Data, Chengdu, China, 13–16 August 2016. [Google Scholar]
- Ye, X.; Liang, J.; Liu, S.; Li, J. A Survey on Scheduling Workflows in Cloud Environment. In Proceedings of the International Conference on Network and Information Systems for Computers, Wuhan, China, 23–25 January 2015. [Google Scholar]
- Tan, Y.; Wu, F.; Wu, Q.; Liao, X. Resource stealing: A resource multiplexing method for mix workloads in cloud system. J. Supercomput. 2016, 6, 1–17. [Google Scholar] [CrossRef]
- Hanani, A.; Rahmani, A.M.; Sahafi, A. A multi-parameter scheduling method of dynamic workloads for big data calculation in cloud computing. J. Supercomput. 2017, 73, 1–27. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y.; Hao, Z.; Du, J. The Research on Resource Scheduling Based on Fuzzy Clustering in Cloud Computing. In Proceedings of the International Conference on Intelligent Computation Technology & Automation, Nanchang, China, 14–15 June 2016. [Google Scholar]
- Liu, L.; Mei, H.; Xie, B. Towards a multi-QoS human-centric cloud computing load balance resource allocation method. J. Supercomput. 2016, 72, 1–14. [Google Scholar] [CrossRef]
- Zuo, L.; Dong, S.; Shu, L.; Zhu, C.; Han, G. A Multiqueue Interlacing Peak Scheduling Method Based on Tasks’ Classification in Cloud Computing. IEEE Syst. J. 2018, 12, 1518–1530. [Google Scholar] [CrossRef] [Green Version]
- Khorandi, S.M.; Sharifi, M. Scheduling of online compute-intensive synchronized jobs on high performance virtual clusters. J. Comput. Syst. Sci. 2016, 85, 1–17. [Google Scholar] [CrossRef]
- Wang, H.; Li, T.; Shea, R.; Ma, X.; Wang, F.; Liu, J.; Xu, K. Toward Cloud-Based Distributed Interactive Applications: Measurement, Modeling, and Analysis. IEEE/ACM Trans. Netw. 2018, 26, 3–16. [Google Scholar] [CrossRef]
- Mao, L.; Li, Y.; Peng, G.; Xu, X.; Lin, W. A Multi-Resource Task Scheduling Algorithm for Energy-Performance Trade-offs in Green Clouds. Sustain. Comput. Inf. Syst. 2018, 19, 233–241. [Google Scholar] [CrossRef]
- Dave, A.; Patel, B.; Bhatt, G. Load balancing in cloud computing using optimization techniques: A study. In Proceedings of the International Conference on Communication & Electronics Systems, Coimbatore, India, 21–22 October 2017. [Google Scholar]
- Chen, Y.; Zhang, Z.; Ren, J. Improved Minimum Link Load Balancing Scheduling Algorithm. Comput. Syst. Appl. 2015, 24, 88–92. [Google Scholar]
- Zhao, Z.; Martin, P.; Jones, A.; Taylor, I.; Stankovski, V.; Salado, G.F.; Suciu, G.; Ulisses, A.; de Laat, C. Developing, Provisioning and Controlling Time Critical Applications in Cloud. In Proceedings of the European Conference on Service-oriented & Cloud Computing, Oslo, Norway, 27–29 September 2017. [Google Scholar]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Mao, Y.; Leng, S.; Maharjan, S.; Zhang, Y. Optimal delay constrained offloading for vehicular edge computing networks. In Proceedings of the IEEE International Conference on Communications, Paris, France, 21–25 May 2017. [Google Scholar]
- Jošilo, S.; Dán, G. A game theoretic analysis of selfish mobile computation offloading. In Proceedings of the IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017. [Google Scholar]
- Dargie, W. A Stochastic Model for Estimating the Power Consumption of a Processor. IEEE Trans. Comput. 2015, 64, 1311–1322. [Google Scholar] [CrossRef] [Green Version]
- Jijun, W.; Hua, C. Computer Power Estimation Model Based on Performance Events. Appl. Res. Comput. 2017, 34, 734–738. [Google Scholar]
- Chen, W.; Deelman, E. WorkflowSim: A toolkit for simulating scientific workflows in distributed environments. In Proceedings of the IEEE, International Conference on E.-Science, Chicago, IL, USA, 8–12 October 2012. [Google Scholar]
- Bharathi, S.; Chervenak, A.; Deelman, E.; Mehta, G.; Su, Me.; Vahi, K. Characterization of scientific workflows. In Proceedings of the Third Workshop on Workflows in Support of Large-Scale Science, Austin, TX, USA, 17 November 2008. [Google Scholar]
- Montage: An Astronomical Image Engine. Available online: http://montage.ipac.caltech.edu (accessed on 30 March 2018).
- Southern California Earthquake Center. Available online: http://www.scec.org (accessed on 30 March 2018).
- Illumina. Available online: http://www.illumina.com/ (accessed on 30 March 2018).
- Panwar, R.; Mallick, B. Load balancing in cloud computing using dynamic load management algorithm. In Proceedings of the International Conference on Green Computing and Internet of Things, Noida, India, 8–10 October 2015. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Category | Type-intensive | Count | Runtime (s) | Inputs (MB) | Outputs (MB) |
|---|---|---|---|---|---|---|
| mConcaFit | Montage | CPU | 1 | 13.60 | 0.03 | 0.02 |
| mAdd | Montage | CPU | 1 | 30.34 | 357.28 | 330.86 |
| extract_agt | CyberShark | I/O | 19 | 355.31 | 38786.64 | 441.97 |
| fastqSplit | Epigenomics | Mem | 2 | 41.78 | 462.20 | 462.20 |
| map | Epigenomics | I/O | 146 | 9635.01 | 2964.24 | 0.58 |
| VM | CPU (MIPS) | RAM (GB) | BW (M/S) | Price ($/h) |
|---|---|---|---|---|
| 1 | 2500 | 0.85 | 750 | 4.65 |
| 2 | 2000 | 3.75 | 500 | 4.03 |
| 3 | 1000 | 1.70 | 980 | 3.71 |
| 4 | 750 | 1.25 | 1043 | 3.67 |
| 5 | 500 | 0.61 | 558 | 3.24 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Z.; Tao, Y.; Zheng, M.; Chang, C. Task Staggering Peak Scheduling Policy for Cloud Mixed Workloads. Information 2018, 9, 329. https://doi.org/10.3390/info9120329
Hu Z, Tao Y, Zheng M, Chang C. Task Staggering Peak Scheduling Policy for Cloud Mixed Workloads. Information. 2018; 9(12):329. https://doi.org/10.3390/info9120329
Chicago/Turabian StyleHu, Zhigang, Yong Tao, Meiguang Zheng, and Chenglong Chang. 2018. "Task Staggering Peak Scheduling Policy for Cloud Mixed Workloads" Information 9, no. 12: 329. https://doi.org/10.3390/info9120329
APA StyleHu, Z., Tao, Y., Zheng, M., & Chang, C. (2018). Task Staggering Peak Scheduling Policy for Cloud Mixed Workloads. Information, 9(12), 329. https://doi.org/10.3390/info9120329