Impact of Reciprocity in Information Spreading Using Epidemic Model Variants


Abstract
:1. Introduction
2. Information Spreading Mechanisms and Measures
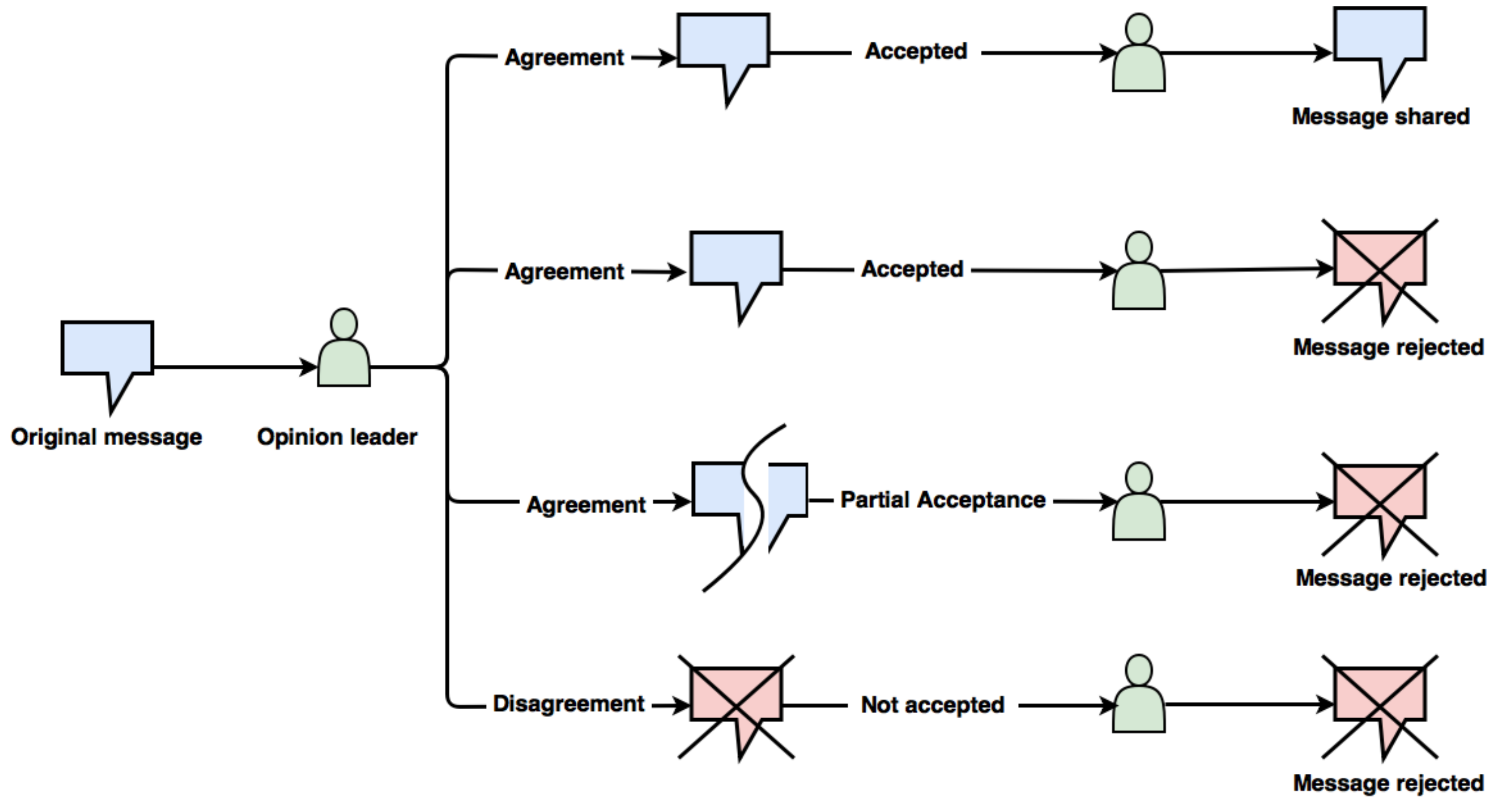
2.1. Opinion Leaders
2.1.1. Degree Centrality
2.1.2. Radius Centrality
2.1.3. Closeness Centrality
2.1.4. Betweenness Centrality
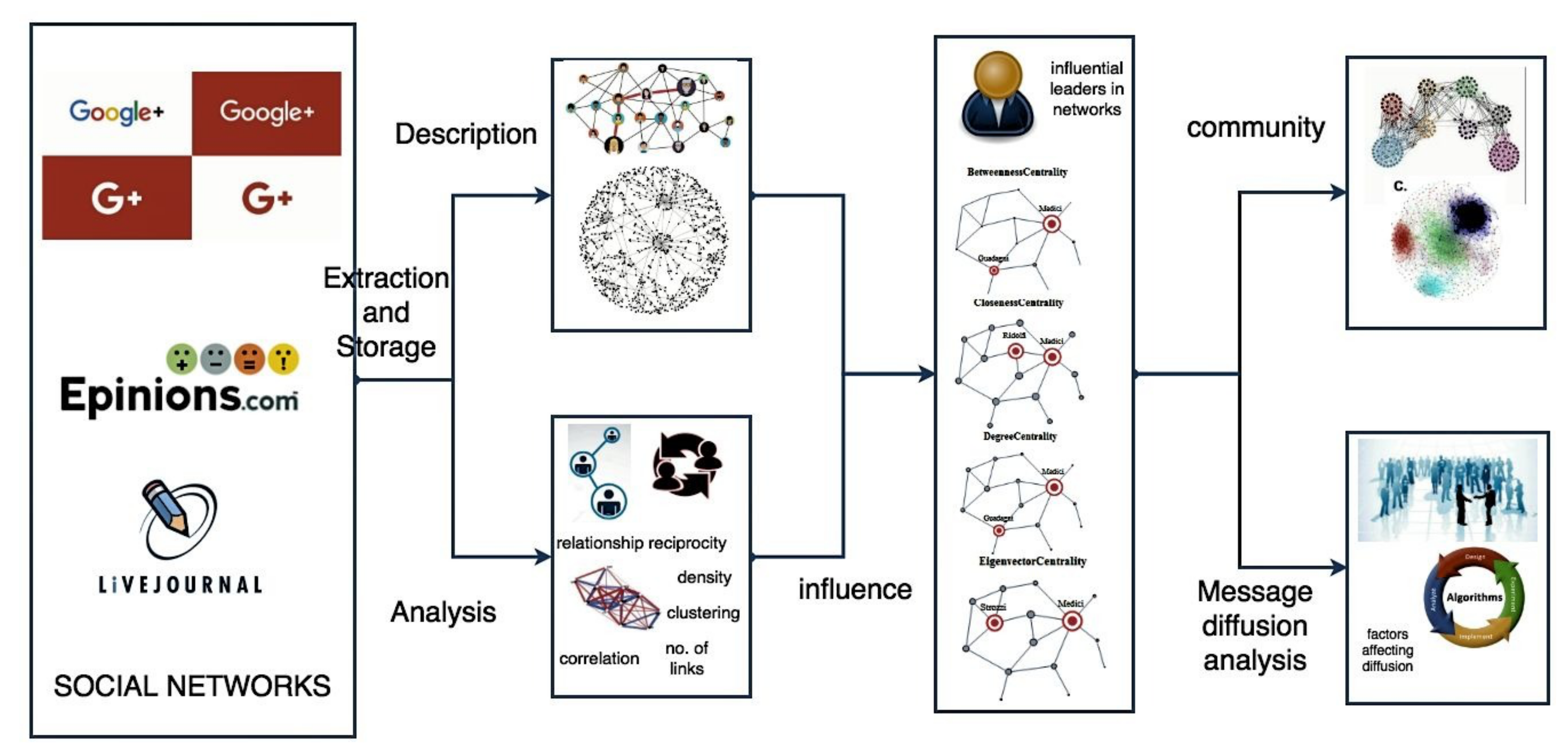
3. Methods and Material
3.1. Data and Analysis
- Epinions: This is a who-trust-whom online social network of a general consumer review site Epinions.com. Users of the site form “trust” relationships by deciding whether to “trust” each other.
- Google+: It is a social networking service offered by Google, where the user can add any other user of the network to his circles, thereby creating a directed social network.
- LiveJournal: It is an online social network that allows members of the web site to maintain their journals, individual and group blogs, and it allows people to declare which other members are their friends.
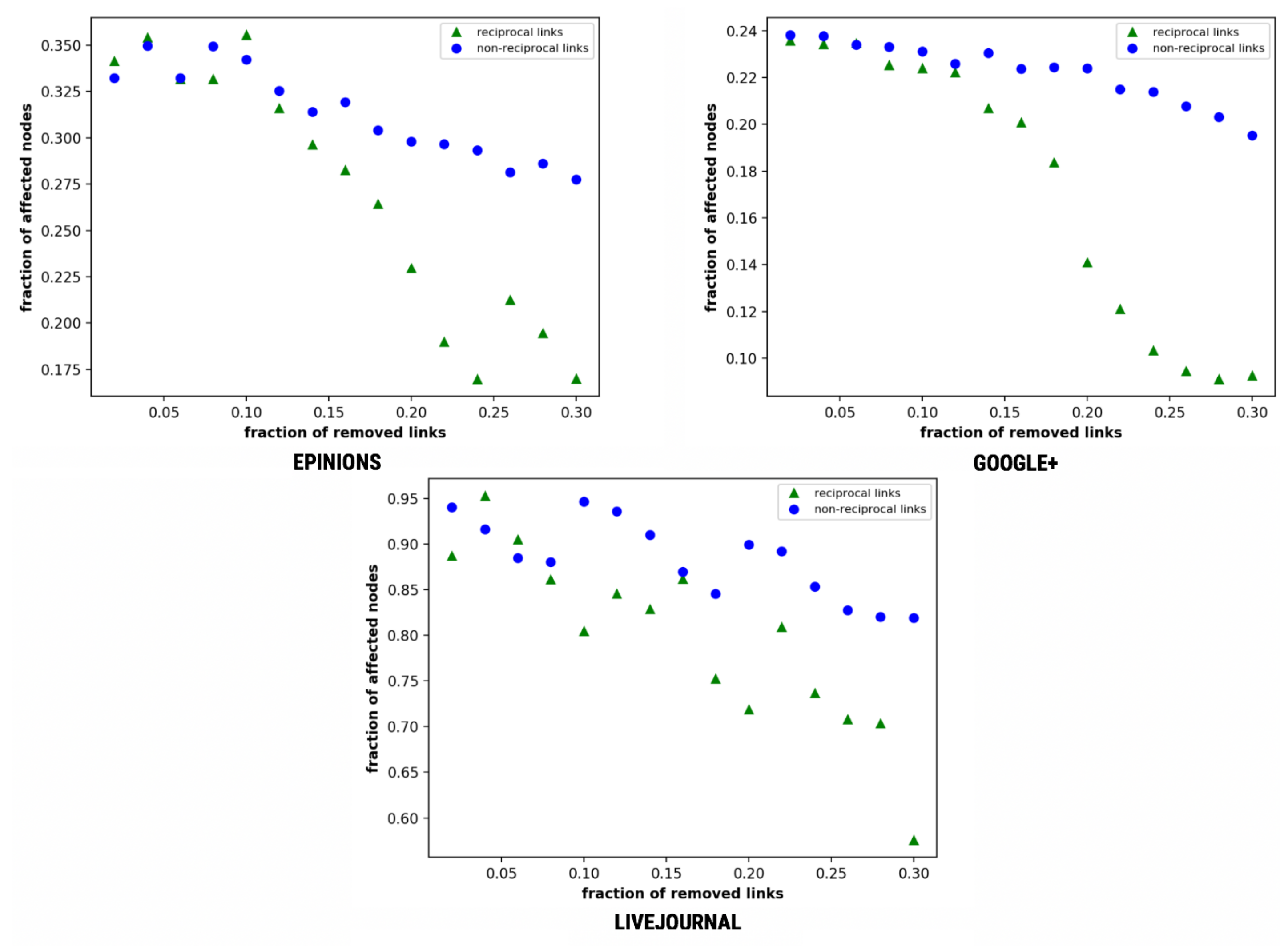
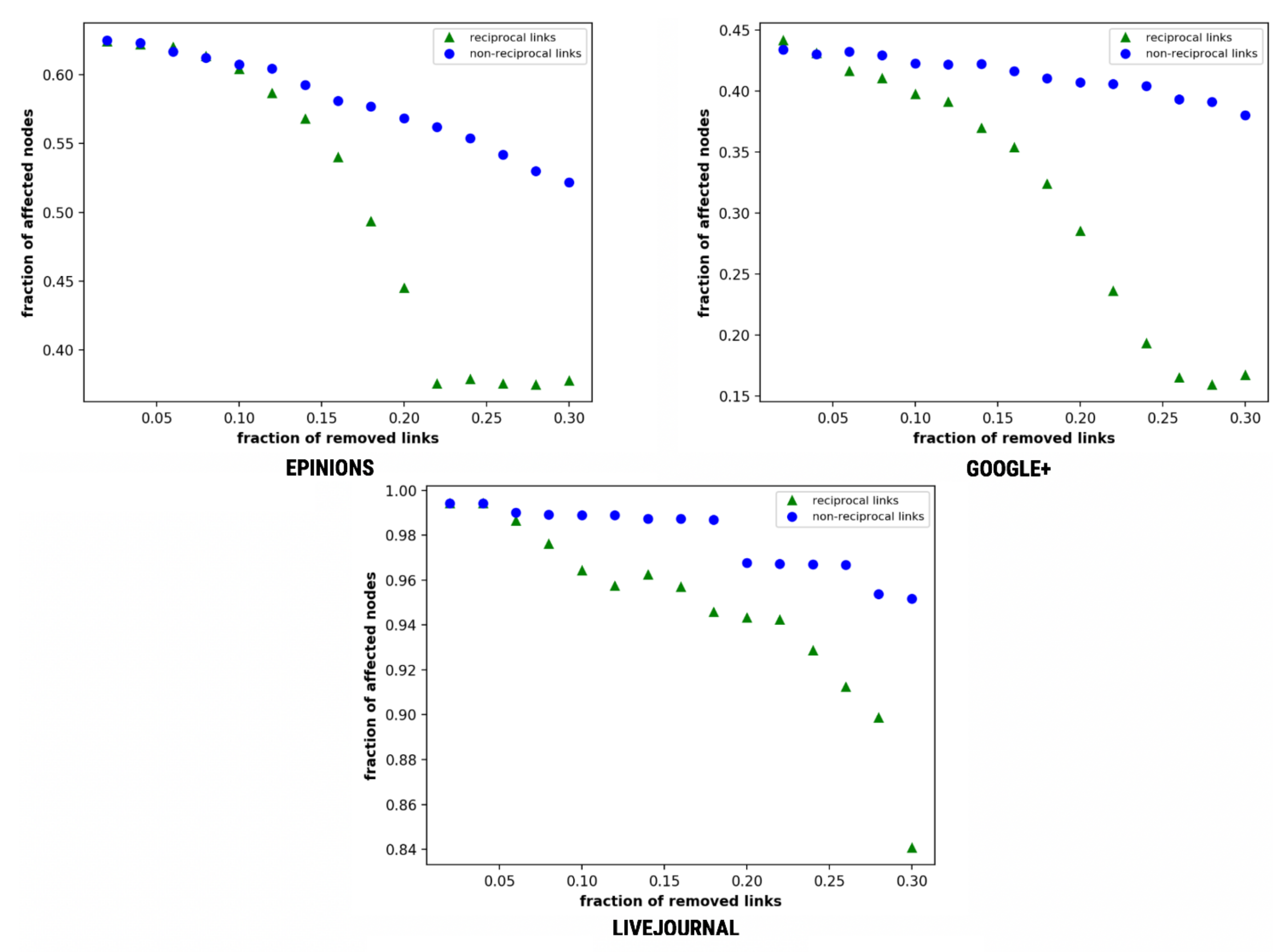
4. Results and Discussion
4.1. Simple Diffusion
| Algorithm 1: Simple diffusion process (Adapted from [18]) |
 |
4.2. Multiple Diffusion
- Broadcast a message m from a starting node (opinion leader) to all its neighbours (adjacent nodes).
- Each node that receives the message, and has not already broadcasted can choose to re-broadcast it to all adjacent nodes with a transmission probability p.
| Algorithm 2: Multiple diffusion |
 |
4.3. Dynamic Diffusion
| Algorithm 3: Dynamic diffusion |
 |
4.4. Edge Diffusion
| Algorithm 4: Edge diffusion |
 |
4.5. Weighted Diffusion
- A user i, who is considered as a start node, broadcasts a message m to all its neighbours.
- The maximum weighted node of all nodes that receive this message m can only broadcast the message to its adjacent nodes with a probability p. Here, probability p is the same transmission probability describing the willingness of the user to diffuse the given message m.
- The above process is repeated until the message m diffuses to all the achievable nodes.
| Algorithm 5: Weighted diffusion |
 |
4.6. Decay Diffusion
- A user i, who is considered as a start node, broadcasts a message m to all its neighbours.
- As the message spreads in the network, the transmission probability of each node decays by a multiple of . The farther the message is from its origination source, the lesser is the willingness of the user to share.
- The above process gets repeated until message m diffuses to all achievable nodes.
| Algorithm 6: Decay diffusion |
 |
4.7. Network Structure
4.7.1. Network Density
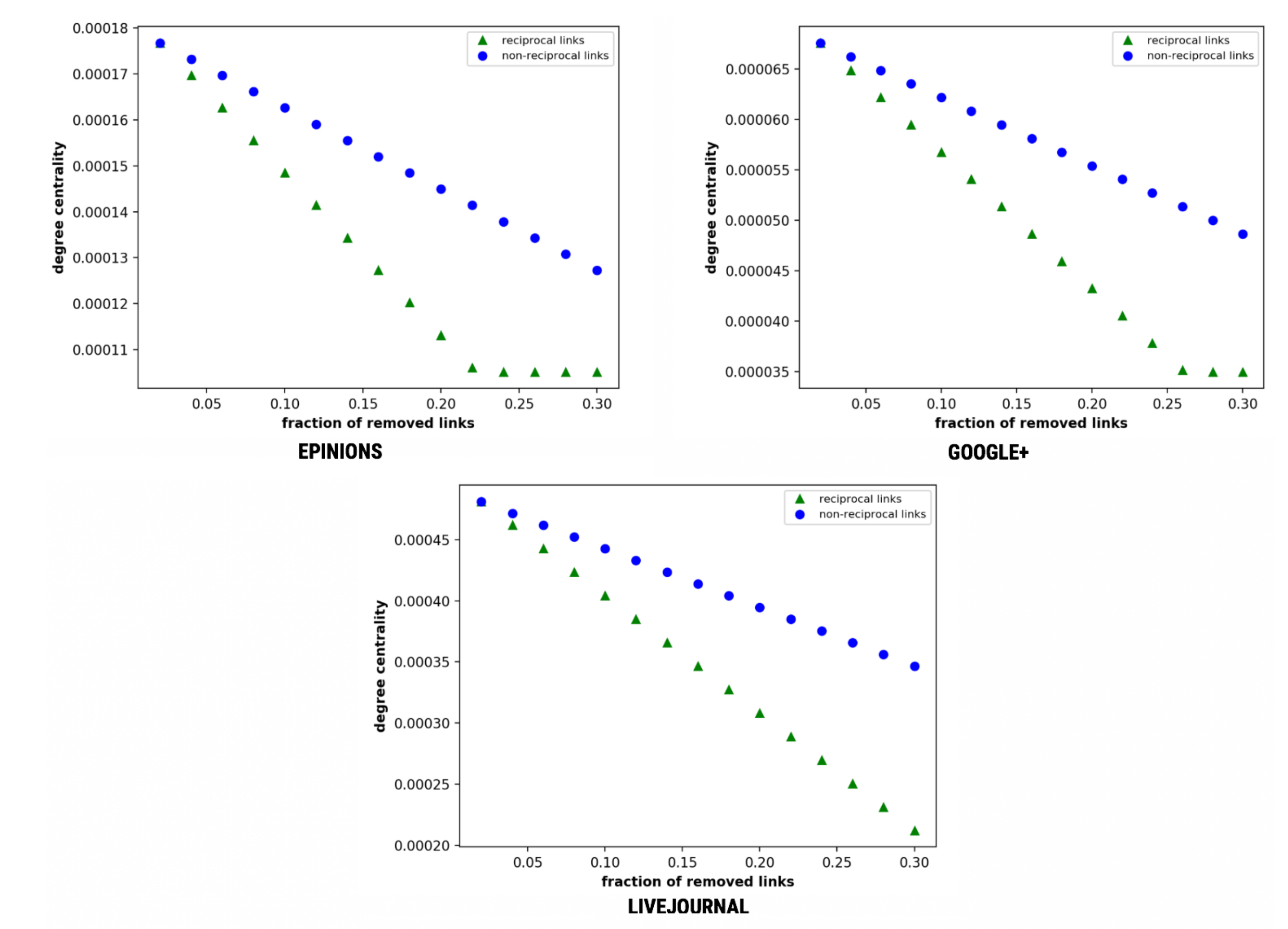
4.7.2. Degree Centrality
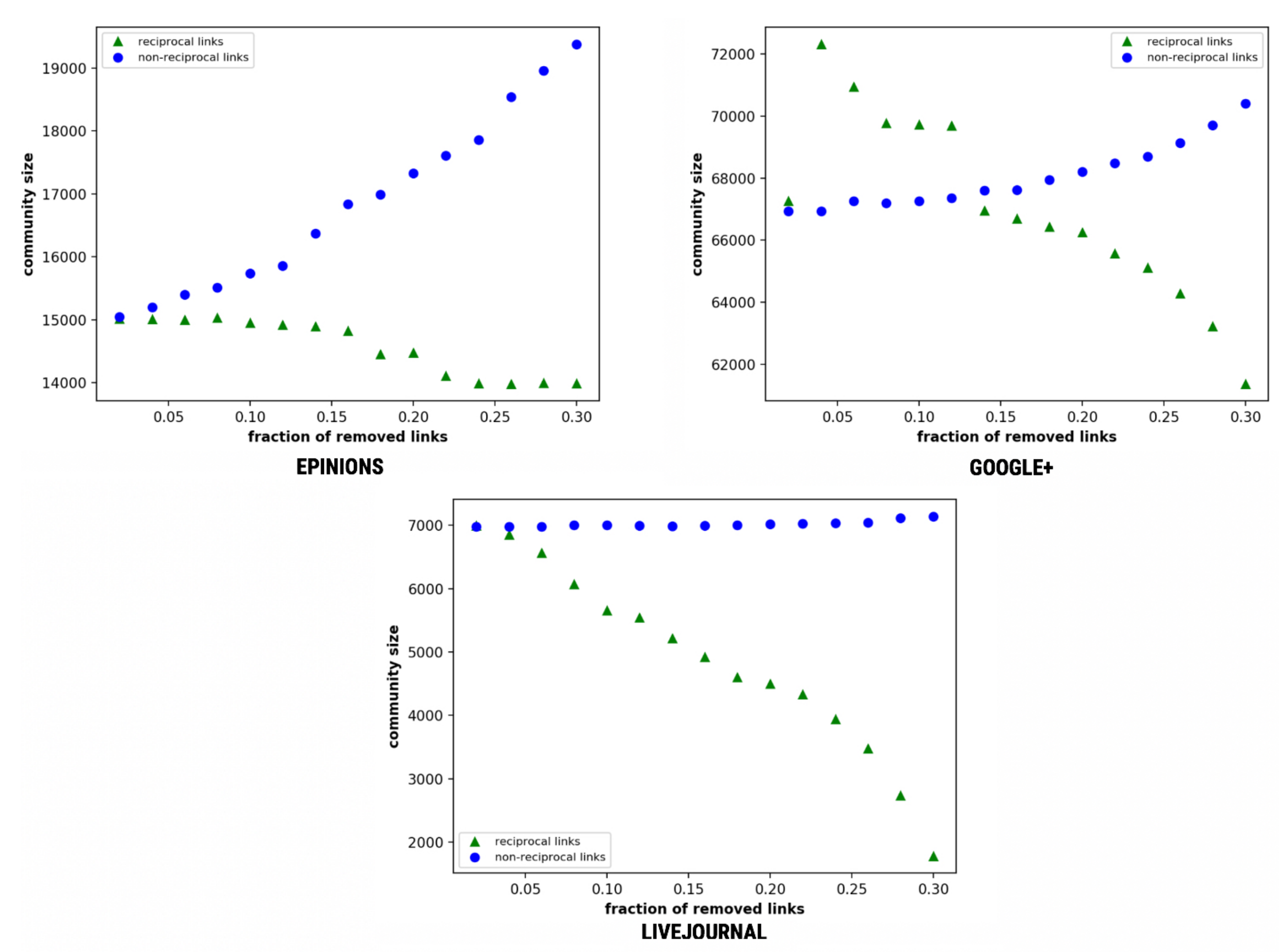
4.7.3. Community Size in a Network
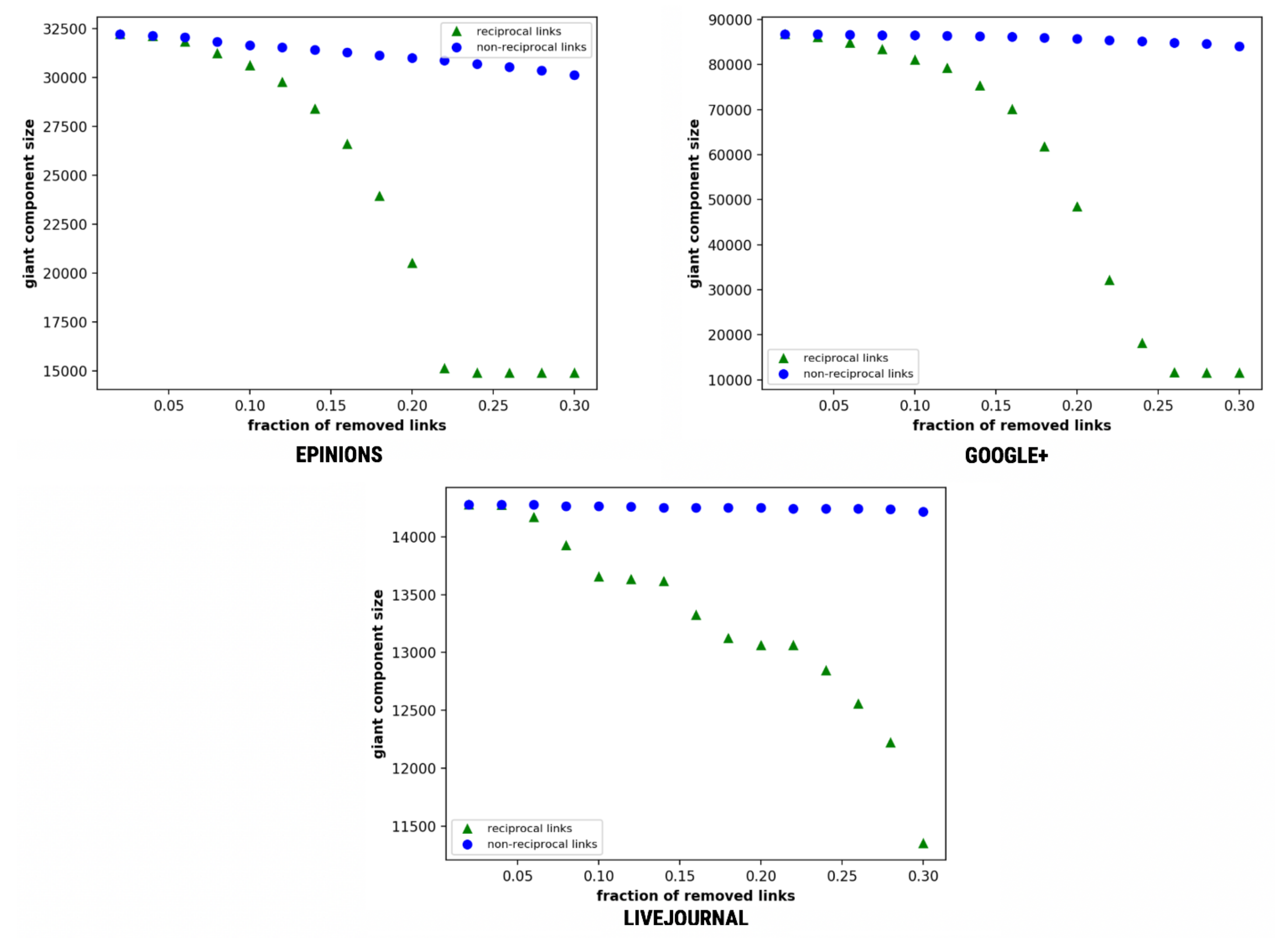
4.7.4. Giant Component Size
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Bakshy, E.; Rosenn, I.; Marlow, C.; Adamic, L. The role of social networks in information diffusion. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; ACM: New York, NY, USA, 2012; pp. 519–528. [Google Scholar]
- Claros, I.; Cobos, R.; Collazos, C.A. An Approach Based on Social Network Analysis Applied to a Collaborative Learning Experience. IEEE Trans. Learn. Technol. 2016, 9, 190–195. [Google Scholar] [CrossRef]
- Knoke, D.; Yang, S. Social Network Analysis; Sage: Newcastle upon Tyne, UK, 2008; Volume 154. [Google Scholar]
- Mitchell, J.C. Networks, algorithms, and analysis. In Perspectives on Social Network Research; Elsevier: New York, NY, USA, 1979; pp. 425–451. [Google Scholar]
- Newman, M.E.; Forrest, S.; Balthrop, J. Email networks and the spread of computer viruses. Phys. Rev. E 2002, 66, 035101. [Google Scholar] [CrossRef] [PubMed]
- Arenas, A.; Danon, L.; Díaz-Guilera, A.; Gleiser, P.M.; Guimerá, R. Community analysis in social networks. Eur. Phys. J. B 2004, 38, 373–380. [Google Scholar] [CrossRef] [Green Version]
- Backstrom, L.; Huttenlocher, D.; Kleinberg, J.; Lan, X. Group formation in large social networks: membership, growth, and evolution. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; ACM: New York, NY, USA, 2006; pp. 44–54. [Google Scholar]
- Squartini, T.; Picciolo, F.; Ruzzenenti, F.; Garlaschelli, D. Reciprocity of weighted networks. Sci. Rep. 2013, 3, 2729. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Newman, M.E. A measure of betweenness centrality based on random walks. Soc. Netw. 2005, 27, 39–54. [Google Scholar] [CrossRef] [Green Version]
- Ratkiewicz, J.; Fortunato, S.; Flammini, A.; Menczer, F.; Vespignani, A. Characterizing and modeling the dynamics of online popularity. Phys. Rev. Lett. 2010, 105, 158701. [Google Scholar] [CrossRef] [PubMed]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef] [Green Version]
- Iribarren, J.L.; Moro, E. Impact of human activity patterns on the dynamics of information diffusion. Phys. Rev. Lett. 2009, 103, 038702. [Google Scholar] [CrossRef] [PubMed]
- Miritello, G.; Moro, E.; Lara, R. Dynamical strength of social ties in information spreading. Phys. Rev. E 2011, 83, 045102. [Google Scholar] [CrossRef] [PubMed]
- Haythornthwaite, C. Social network analysis: An approach and technique for the study of information exchange. Libr. Inf. Sci. Res. 1996, 18, 323–342. [Google Scholar] [CrossRef]
- Li, M.; Wang, X.; Gao, K.; Zhang, S. A Survey on Information Diffusion in Online Social Networks: Models and Methods. Information 2017, 8, 118. [Google Scholar]
- Khan, N.S.; Ata, M.; Rajput, Q. Identification of opinion leaders in social network. In Proceedings of the International Conference on Information and Communication Technologies (ICICT), Karachi, Pakistan, 12–13 December 2015; pp. 1–6. [Google Scholar]
- Scott, J. Social Network Analysis; Sage: Newcastle upon Tyne, UK, 2017. [Google Scholar]
- Zhu, Y.X.; Zhang, X.G.; Sun, G.Q.; Tang, M.; Zhou, T.; Zhang, Z.K. Influence of reciprocal links in social networks. PLoS ONE 2014, 9, e103007. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Yang, X.Y.; Xu, K.; Ma, J.F. SEIR-Based model for the information spreading over SNS. Acta Electron. Sin. 2014, 11, 31. [Google Scholar]
- Xu, R.; Li, H.; Xing, C. Research on information dissemination model for social networking services. Int. J. Comput. Sci. Appl. 2013, 2, 1–6. [Google Scholar]
- Ding, X. Research on propagation model of public opinion topics based on SCIR in microblogging. Comput. Eng. Appl. 2015, 51, 20–26. [Google Scholar]
- Cannarella, J.; Spechler, J.A. Epidemiological modeling of online social network dynamics. arXiv, 2014; arXiv:1401.4208. [Google Scholar]
- Feng, L.; Hu, Y.; Li, B.; Stanley, H.E.; Havlin, S.; Braunstein, L.A. Competing for attention in social media under information overload conditions. PLoS ONE 2015, 10, e0126090. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Lin, Z.; Jin, Y.; Cheng, S.; Yang, T. ESIS: Emotion-based spreader–ignorant–stifler model for information diffusion. Knowl.-Based Syst. 2015, 81, 46–55. [Google Scholar] [CrossRef]
- Woo, J.; Chen, H. Epidemic model for information diffusion in web forums: Experiments in marketing exchange and political dialog. SpringerPlus 2016, 5, 66. [Google Scholar] [CrossRef] [PubMed]
- Torche, F.; Valenzuela, E. Trust and reciprocity: A theoretical distinction of the sources of social capital. Eur. J. Soc. Theory 2011, 14, 181–198. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, Z.K. Information spreading on dynamic social networks. Commun. Nonlinear Sci. Numer. Simul. 2014, 19, 896–904. [Google Scholar] [CrossRef]
- Wu, F.; Huberman, B.A. Novelty and collective attention. Proc. Natl. Acad. Sci. USA 2007, 104, 17599–17601. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Crane, R.; Sornette, D. Robust dynamic classes revealed by measuring the response function of a social system. Proc. Natl. Acad. Sci. USA 2008, 105, 15649–15653. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lü, L.; Chen, D.B.; Zhou, T. The small world yields the most effective information spreading. New J. Phys. 2011, 13, 123005. [Google Scholar] [CrossRef] [Green Version]
- Dodds, P.S.; Watts, D.J. Universal behavior in a generalized model of contagion. Phys. Rev. Lett. 2004, 92, 218701. [Google Scholar] [CrossRef] [PubMed]
- Medo, M.; Zhang, Y.C.; Zhou, T. Adaptive model for recommendation of news. EPL (Europhys. Lett.) 2009, 88, 38005. [Google Scholar] [CrossRef] [Green Version]
- Cimini, G.; Medo, M.; Zhou, T.; Wei, D.; Zhang, Y.C. Heterogeneity, quality, and reputation in an adaptive recommendation model. Eur. Phys. J. B 2011, 80, 201–208. [Google Scholar] [CrossRef] [Green Version]
- Jalili, M.; Perc, M. Information cascades in complex networks. J. Complex Netw. 2017, 5, 665–693. [Google Scholar] [CrossRef]
- Piraveenan, M.; Prokopenko, M.; Hossain, L. Percolation centrality: Quantifying graph-theoretic impact of nodes during percolation in networks. PLoS ONE 2013, 8, e53095. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aghdam, S.M.; Navimipour, N.J. Opinion leaders selection in the social networks based on trust relationships propagation. Karbala Int. J. Mod. Sci. 2016, 2, 88–97. [Google Scholar] [CrossRef]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [PubMed]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440. [Google Scholar] [CrossRef] [PubMed]
- Watts, D.J. A simple model of global cascades on random networks. Proc. Natl. Acad. Sci. USA 2002, 99, 5766–5771. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pacheco, J.M.; Traulsen, A.; Nowak, M.A. Active linking in evolutionary games. J. Theor. Biol. 2006, 243, 437–443. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Santos, F.; Rodrigues, J.; Pacheco, J. Graph topology plays a determinant role in the evolution of cooperation. Proc. R. Soc. Lond. B Biolog. Sci. 2006, 273, 51–55. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pastor-Satorras, R.; Vespignani, A. Epidemic spreading in scale-free networks. Phys. Rev. Lett. 2001, 86, 3200. [Google Scholar] [CrossRef] [PubMed]
- Bettencourt, L.M.; Cintrón-Arias, A.; Kaiser, D.I.; Castillo-Chávez, C. The power of a good idea: Quantitative modeling of the spread of ideas from epidemiological models. Phys. A Stat. Mech. Appl. 2006, 364, 513–536. [Google Scholar] [CrossRef] [Green Version]
- Wu, A.; DiMicco, J.M.; Millen, D.R. Detecting professional versus personal closeness using an enterprise social network site. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 10–15 April 2010; ACM: New York, NY, USA, 2010; pp. 1955–1964. [Google Scholar]
- Yoganarasimhan, H. Impact of social network structure on content propagation: A study using YouTube data. Quant. Mark. Econ. 2012, 10, 111–150. [Google Scholar] [CrossRef]
- Hinz, O.; Skiera, B.; Barrot, C.; Becker, J.U. Seeding strategies for viral marketing: An empirical comparison. J. Mark. 2011, 75, 55–71. [Google Scholar] [CrossRef]
- Hill, S.; Provost, F.; Volinsky, C. Network-based marketing: Identifying likely adopters via consumer networks. Stat. Sci. 2006, 21, 256–276. [Google Scholar] [CrossRef]
- Katona, Z.; Zubcsek, P.P.; Sarvary, M. Network effects and personal influences: The diffusion of an online social network. J. Mark. Res. 2011, 48, 425–443. [Google Scholar] [CrossRef]
- Kermack, W.O.; McKendrick, A.G. Contributions to the mathematical theory of epidemics. II.—The problem of endemicity. Proc. R. Soc. Lond. A. R. Soc. 1932, 138, 55–83. [Google Scholar] [CrossRef]
- Wan, H.; Cui, J.A. An SEIS epidemic model with transport-related infection. J. Theor. Biol. 2007, 247, 507–524. [Google Scholar] [CrossRef] [PubMed]
- Yang, R.; Zhou, T.; Xie, Y.B.; Lai, Y.C.; Wang, B.H. Optimal contact process on complex networks. Phys. Rev. E 2008, 78, 066109. [Google Scholar] [CrossRef] [PubMed]
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef] [Green Version]
- Kimura, M.; Saito, K. Tractable models for information diffusion in social networks. In Proceedings of the European Conference on Principles of Data Mining and Knowledge Discovery, Berlin, Germany, 18–22 September 2006; Springer: Berlin, Germany, 2006; pp. 259–271. [Google Scholar]
- Kitsak, M.; Gallos, L.K.; Havlin, S.; Liljeros, F.; Muchnik, L.; Stanley, H.E.; Makse, H.A. Identification of influential spreaders in complex networks. Nat. Phys. 2010, 6, 888. [Google Scholar] [CrossRef]
- Pei, S.; Makse, H.A. Spreading dynamics in complex networks. J. Stat. Mech. Theory Exp. 2013, 2013, P12002. [Google Scholar] [CrossRef]
- Pei, S.; Muchnik, L.; Andrade, J.S., Jr.; Zheng, Z.; Makse, H.A. Searching for superspreaders of information in real-world social media. Sci. Rep. 2014, 4, 5547. [Google Scholar] [CrossRef] [PubMed]
- Giatsidis, C.; Thilikos, D.M.; Vazirgiannis, M. D-cores: Measuring collaboration of directed graphs based on degeneracy. Knowl. Inf. Syst. 2013, 35, 311–343. [Google Scholar] [CrossRef] [Green Version]
- Sabidussi, G. The centrality index of a graph. Psychometrika 1966, 31, 581–603. [Google Scholar] [CrossRef] [PubMed]
- Newman, M.E. The structure of scientific collaboration networks. Proc. Natl. Acad. Sci. USA 2001, 98, 404–409. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beauchamp, M.A. An improved index of centrality. Syst. Res. Behav. Sci. 1965, 10, 161–163. [Google Scholar] [CrossRef]
- Leskovec, J.; Mcauley, J.J. Learning to discover social circles in ego networks. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2012; pp. 539–547. [Google Scholar]
- Fire, M.; Tenenboim-Chekina, L.; Puzis, R.; Lesser, O.; Rokach, L.; Elovici, Y. Computationally efficient link prediction in a variety of social networks. ACM Trans. Intell. Syst. Technol. (TIST) 2013, 5, 10. [Google Scholar] [CrossRef]
- Rossi, R.A.; Ahmed, N.K. The Network Data Repository with Interactive Graph Analytics and Visualization. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Leskovec, J.; Lang, K.J.; Dasgupta, A.; Mahoney, M.W. Community structure in large networks: Natural cluster sizes and the absence of large well-defined clusters. Internet Math. 2009, 6, 29–123. [Google Scholar] [CrossRef]
- Leskovec, J.; Krevl, A. SNAP Datasets: Stanford Large Network Dataset Collection. 2014. Available online: http://snap.stanford.edu/data (accessed on 21 March 2018).
- Wasserman, S.; Faust, K. Social Network Analysis: Methods and Applications; Cambridge University Press: Cambridge, UK, 1994; Volume 8. [Google Scholar]
- Frank, D.; Huang, Z.; Chyan, A. Sampling A Large Network: How Small Can My Sample Be? 2012. Available online: http://snap.stanford.edu/class/cs224w-2012/projects/cs224w-036-final.pdf (accessed on 20 May 2018).
- Leskovec, J.; Faloutsos, C. Sampling from large graphs. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; ACM: New York, NY, USA, 2006; pp. 631–636. [Google Scholar]
- Kamp, C.; Moslonka-Lefebvre, M.; Alizon, S. Epidemic spread on weighted networks. PLoS Comput. Biol. 2013, 9, e1003352. [Google Scholar] [CrossRef] [PubMed]
- Wu, F.; Huberman, B.A.; Adamic, L.A.; Tyler, J.R. Information flow in social groups. Phys. A Stat. Mech. Appl. 2004, 337, 327–335. [Google Scholar] [CrossRef] [Green Version]
- Centola, D. The spread of behavior in an online social network experiment. Science 2010, 329, 1194–1197. [Google Scholar] [CrossRef] [PubMed]
- Girvan, M.; Newman, M.E. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, Z.; Wang, X.; Zhang, W.; Zhu, Z. A community-based approach to identifying influential spreaders. Entropy 2015, 17, 2228–2252. [Google Scholar] [CrossRef]
- Rosvall, M.; Bergstrom, C.T. Maps of random walks on complex networks reveal community structure. Proc. Natl. Acad. Sci. USA 2008, 105, 1118–1123. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Enns, E.A.; Brandeau, M.L. Link removal for the control of stochastically evolving epidemics over networks: A comparison of approaches. J. Theor. Biol. 2015, 371, 154–165. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, J.; Wu, J.; Xu, K. Weak ties: Subtle role of information diffusion in online social networks. Phys. Rev. E 2010, 82, 016105. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Researcher | Definition |
|---|---|---|
| SIR | Kermack and McKendrick [49] | The SIR model deals with the modeling of diseases with long-lasting immunity to immunising infections. Thus, it is partitioned into three disjoint groups: S, I and R. Susceptible (S) represents node susceptible to a disease, “Infected” (I) states node infected by a disease, “Recovered” (R) represents the people who are infected and immune to the infection. |
| SIS | Pastor-Satorras [42] | The SIS compartmental model segregates compartments through non-immune infections, such infections do not give immunisation upon recovery from infection, and individuals become susceptible again. Thus it segregates into two compartments: Susceptible (S) and Infected (I). In the spreading process, infected individuals infect their susceptible neighbours with a certain probability () and return to S state with a certain probability (). |
| SEIR | Wang et al. [19] | SEIR model has an additional compartment which consists of exposed individuals in the latent period. The individual is in an exposed compartment “E” (exposed) when he is infected but not yet infectious . These models make the following assumptions: (1) susceptible individuals can get infected from infected individuals via contacts; and (2) an infected individual becomes immune after recovering from the disease. |
| SEIS | Wan and Cui [50] | SEIS compartmental model considers the exposed or latent period of the disease, thus introducing an additional compartment E. The infection does not leave any immunity, therefore individuals that have recovered return to being susceptible. |
| SIRL | Yang et al. [51] | SIRL model is a modified SIR model, in which each node is assigned with an identical capability of active contacts, L. It stands for the spreading with limited contacting ability. At each step, the infected individuals will generate L contacts. Multiple contacts with one neighbour are allowed, and contacts that are not between susceptible and infected ones are also counted just like the standard SIR model. |
| Dataset | Total | Total | Reciprocal | Non Reciprocal | Recipro | Clustering | Opinion Leader |
|---|---|---|---|---|---|---|---|
| Nodes | Edges | Links | Links | -City | Coefficient | Node ID | |
| Epinions | 12,209 | 508,837 | 206,194 | 302,643 | 0.399 | 0.137 | 645 |
| Google+ | 211,187 | 1,506,896 | 726,970 | 779,926 | 0.479 | 0.145 | 197,967 |
| Live Journal | 10,608 | 1,656,116 | 1,166,146 | 489,970 | 0.697 | 0.327 | 4 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Narang, R.; Sarin, S.; Singh, P.; Goyal, R. Impact of Reciprocity in Information Spreading Using Epidemic Model Variants. Information 2018, 9, 136. https://doi.org/10.3390/info9060136
Narang R, Sarin S, Singh P, Goyal R. Impact of Reciprocity in Information Spreading Using Epidemic Model Variants. Information. 2018; 9(6):136. https://doi.org/10.3390/info9060136
Chicago/Turabian StyleNarang, Rishabh, Simran Sarin, Prajjwal Singh, and Rinkaj Goyal. 2018. "Impact of Reciprocity in Information Spreading Using Epidemic Model Variants" Information 9, no. 6: 136. https://doi.org/10.3390/info9060136
APA StyleNarang, R., Sarin, S., Singh, P., & Goyal, R. (2018). Impact of Reciprocity in Information Spreading Using Epidemic Model Variants. Information, 9(6), 136. https://doi.org/10.3390/info9060136