Target Tracking Algorithm Based on an Adaptive Feature and Particle Filter


Abstract
:1. Introduction
2. Materials and Methods
3. Introduction to the Related Theory
3.1. Particle Filter Framework
3.2. Sparse Representation
4. The Proposed Tracker
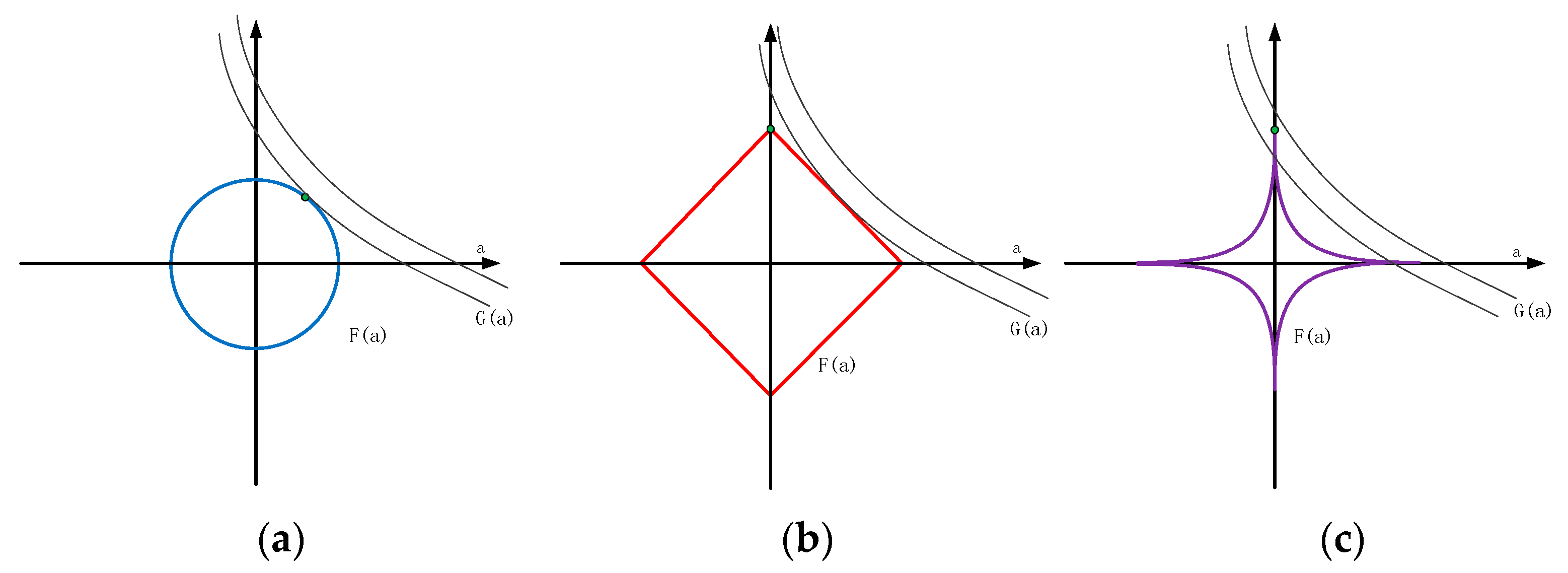
4.1. Intelligent Particle Filter
4.2. The Minimization Model for Lp Tracker
| Algorithm 1. Lp-accelerated proximal gradient (APG) |
| Input: template , regularization factor , , Lipchitz constant [8,29] 1. 2. For k = 0, 1, …, iterate until convergence 3. ; 4. ; 5. ; 6. ; 7. ; 8. ; 9. End. Output: convergent |
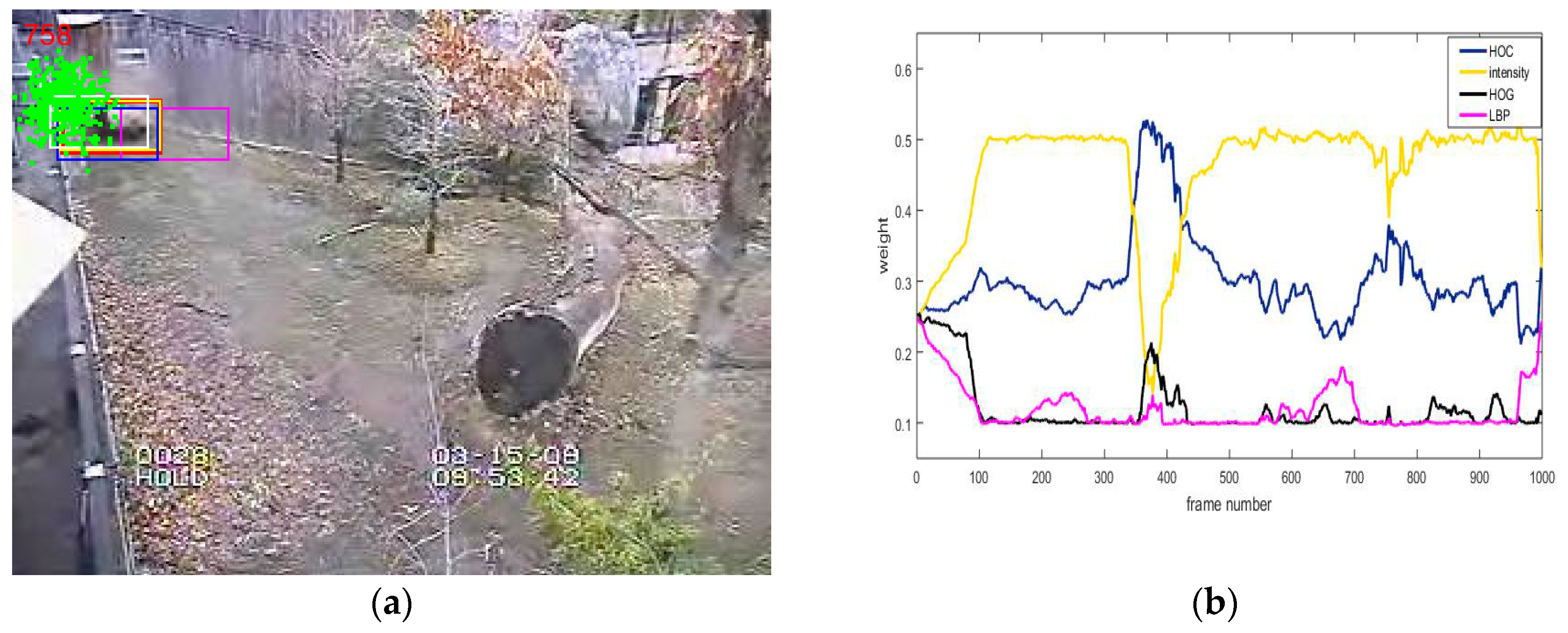
4.3. Adaptive Multi-Feature Fusion Strategy
5. Experiment and Analysis
5.1. Setting Parameters
5.2. Quantitative Analysis
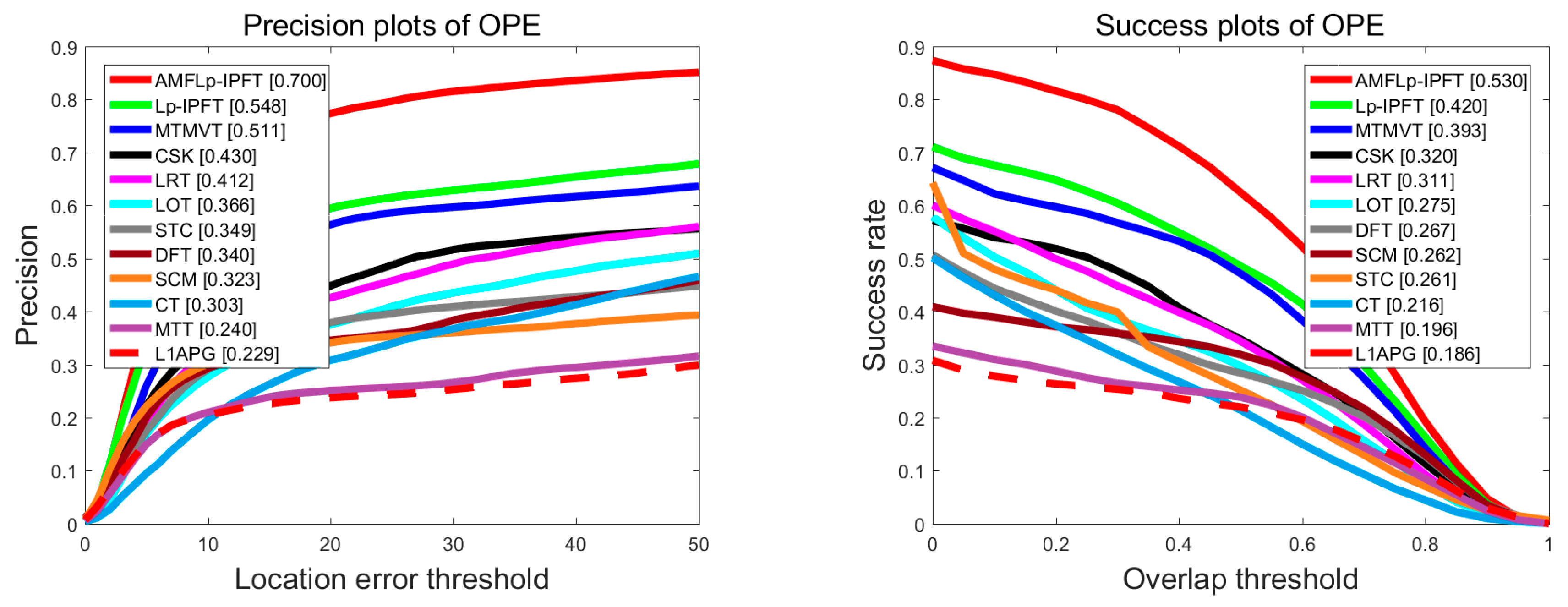
5.2.1. Overall Performance Analysis
5.2.2. Attribute-Based Performance Analysis
5.3. Qualitative Analysis
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yilmaz, A. Object tracking: A survey. ACM Comput. Surv. 2006, 38, 81–93. [Google Scholar] [CrossRef]
- Smeulders, A.W.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual Tracking: An Experimental Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1442–1468. [Google Scholar] [PubMed] [Green Version]
- Che, Z.; Hong, Z.; Tao, D. An Experimental Survey on Correlation Filter-based Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 1–13. [Google Scholar]
- Li, H.; Shen, C.; Shi, Q. Real-time visual tracking using compressive sensing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 20–25 June 2011; pp. 1305–1312. [Google Scholar]
- Mei, X.; Ling, H.B. Robust visual tracking and vehicle classification via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2259–2272. [Google Scholar] [PubMed]
- Mei, X.; Ling, H.B. Robust Visual Tracking Using L1 Minimization. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1436–1443. [Google Scholar]
- Mei, X.; Ling, H.B.; Wu, Y.; Blasch, E.; Bai, L. Minimum error bounded efficient L1 tracker with occlusion detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 20–25 June 2011; pp. 1257–1264. [Google Scholar]
- Bao, C.L.; Wu, Y.; Ling, H.B.; Ji, H. Real time robust L1 tracker using accelerated proximal gradient approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1830–1837. [Google Scholar]
- Zhang, T.; Liu, S.; Ahuja, N.; Yang, M.H.; Ghanem, B. Robust visual tracking via consistent low-rank sparse learning. Int. J. Comput. Vis. 2014, 111, 171–190. [Google Scholar] [CrossRef]
- Zhang, T.; Ghanem, B.; Liu, S.; Ahuja, N. Low-rank sparse learning for robust visual tracking. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 470–484. [Google Scholar]
- Yang, Y.; Hu, W.; Xie, Y.; Zhang, W.; Zhang, T. Temporal Restricted Visual Tracking via Reverse-Low-Rank Sparse Learning. IEEE Trans. Cybern. 2017, 47, 485–498. [Google Scholar] [CrossRef] [PubMed]
- Chartrand, R. Fast algorithms for nonconvex compressive sensing: MRI reconstruction from very few data. In Proceedings of the IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Boston, MA, USA, 28 June–1 July 2009; pp. 262–265. [Google Scholar]
- Zuo, W.; Meng, D.; Zhang, L.; Feng, X.; Zhang, D. A generalized iterated shrinkage algorithm for non-convex sparse coding. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 217–224. [Google Scholar]
- Chartrand, R. Shrinkage mappings and their induced penalty functions. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal, Florence, Italy, 4–9 May 2014; pp. 1026–1029. [Google Scholar]
- Hong, Z.; Mei, X.; Prokhorov, D.; Tao, D. Tracking via Robust Multi-task Multi-view Joint Sparse Representation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 649–656. [Google Scholar]
- Kwon, J.; Lee, K.M. Visual tracking decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1269–1276. [Google Scholar]
- Zhang, S.P.; Zhou, H.Y.; Jiang, F.; Li, X. Robust Visual Tracking Using Structurally Random Projection and Weighted Least Squares. IEEE Trans Circuits Syst. Video Technol. 2015, 25, 1749–1760. [Google Scholar] [CrossRef]
- Meshgi, K.; Maeda, S.I.; Oba, S.; Skibbe, H.; Li, Y.Z.; Ishii, S. An occlusion-aware particle filter tracker to handle complex and persistent occlusions. Comput. Vis. Image Underst. 2016, 150, 81–94. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, L.; Yan, B.; Lei, L.; Cai, A.; Hu, G. Constrained Total Generalized p-Variation Minimization for Few-View X-Ray Computed Tomography Image Reconstruction. PLoS ONE 2016, 11, e0149899. [Google Scholar] [CrossRef] [PubMed]
- Xie, Y.; Gu, S.; Liu, Y.; Zuo, W.; Zhang, W.; Zhang, L. Weighted Schatten, p-Norm Minimization for Image Denoising and Background Subtraction. IEEE Trans. Image Process. 2016, 25, 4842–4857. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, H.; Zhu, P.; Zhang, D.; Zuo, W. Non-convex Regularized Self-representation for Unsupervised Feature Selection. In Proceedings of the International Conference on Intelligent Science and Big Data Engineering, Suzhou, China, 14–16 June 2015; Volume 9243, pp. 55–65. [Google Scholar]
- Chartrand, R. Nonconvex Splitting for Regularized Low-Rank + Sparse Decomposition. IEEE Trans. Signal Process. 2012, 60, 5810–5819. [Google Scholar] [CrossRef]
- Dash, P.P.; Patra, D.; Mishra, S.K. Local Binary Pattern as a Texture Feature Descriptor in Object Tracking Algorithm. In Intelligent Computing, Networking, and Informatics; Springer: India, Pune, 2014; pp. 541–548. [Google Scholar]
- Yoon, J.H.; Kim, D.Y.; Yoon, K.J. Visual tracking via adaptive tracker selection with multiple features. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 28–41. [Google Scholar]
- Morenonoguer, F.; Sanfeliu, A.; Samaras, D. Dependent Multiple Cue Integration for Robust Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 670–685. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yin, M.; Zhang, J.; Sun, H.; Gu, W. Multi-cue-based CamShift guided particle filter tracking. Exp. Syst. Appl. 2011, 38, 6313–6318. [Google Scholar] [CrossRef]
- Zhao, S.; Wang, W.; Ma, S.; Zhang, Y.; Yu, M. A fast particle filter object tracking algorithm by dual features fusion. Proc. SPIE 2014, 9301, 1–8. [Google Scholar]
- Tian, P. A particle filter object tracking based on feature and location fusion. In Proceedings of the IEEE International Conference on Software Engineering and Service Science, Beijing, China, 23–25 September 2015; pp. 762–765. [Google Scholar]
- Tseng, P. On accelerated proximal gradient methods for convex-concave optimization. SIAM J. Opt. 2008. [Google Scholar]
- Zhong, W.; Lu, H.; Yang, M.H. Robust object tracking via sparsity-based collaborative model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1838–1845. [Google Scholar]
- Zhang, K.; Zhang, L.; Liu, Q.; Zhang, D.; Yang, M.H. Fast Visual Tracking via Dense Spatio-temporal Context Learning. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; Volume 8693, pp. 127–141. [Google Scholar]
- Caseiro, R.; Martins, P.; Batista, J. Exploiting the Circulant Structure of Tracking-by-Detection with Kernels. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 702–715. [Google Scholar]
- Zhang, T.; Ghanem, B.; Liu, S.; Ahuja, N. Robust visual tracking via structured multi-task sparse learning. Int. J. Comput. Vis. 2013, 101, 367–383. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, L.; Yang, M.H. Real-time compressive tracking. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 866–879. [Google Scholar]
- Laura, S.L.; Erik, L.M. Distribution fields for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1910–1917. [Google Scholar]
- Avidan, S.; Levi, D.; BarHillel, A.; Oron, S. Locally Orderless Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1940–1947. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Online Object Tracking: A Benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tracker | Car4 | David2 | Dog | Dudek | Deer | Girl | Surfer | Trellis |
|---|---|---|---|---|---|---|---|---|
| L1-APG | 4.870 | 2.857 | 11.50 | 22.55 | 25.69 | 4.14 | 44.42 | 62.20 |
| L0.5-APG | 2.019 | 3.913 | 8.951 | 25.42 | 11.22 | 3.913 | 8.024 | 28.841 |
| SCM | L1-APG | STC | CSK | MTT | CT | DFT | LOT | MTMVT | LRT | Lp-IPFT | AMFLp-IPFT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DP | 0.341 | 0.237 | 0.379 | 0.449 | 0.251 | 0.308 | 0.346 | 0.376 | 0.564 | 0.426 | 0.595 | 0.774 |
| OS | 0.319 | 0.220 | 0.251 | 0.348 | 0.238 | 0.214 | 0.284 | 0.297 | 0.471 | 0.344 | 0.485 | 0.624 |
| Challenge | SCM | L1-APG | STC | CSK | MTT | CT | DFT | LOT | MTMVT | LRT | Lp-IPFT | AMFLp-IPFT |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BC | 0.310 | 0.223 | 0.331 | 0.419 | 0.226 | 0.245 | 0.357 | 0.325 | 0.512 | 0.416 | 0.420 | 0.695 |
| FM | 0.167 | 0.158 | 0.175 | 0.339 | 0.173 | 0.240 | 0.231 | 0.352 | 0.442 | 0.310 | 0.542 | 0.629 |
| MB | 0.166 | 0.134 | 0.210 | 0.382 | 0.131 | 0.230 | 0.224 | 0.328 | 0.438 | 0.321 | 0.572 | 0.651 |
| DEF | 0.246 | 0.170 | 0.313 | 0.373 | 0.172 | 0.247 | 0.338 | 0.353 | 0.474 | 0.315 | 0.427 | 0.680 |
| IV | 0.441 | 0.217 | 0.424 | 0.459 | 0.241 | 0.259 | 0.367 | 0.297 | 0.489 | 0.399 | 0.442 | 0.714 |
| IPR | 0.320 | 0.235 | 0.337 | 0.411 | 0.249 | 0.340 | 0.322 | 0.337 | 0.527 | 0.490 | 0.565 | 0.707 |
| LR | 0.128 | 0.177 | 0.362 | 0.369 | 0.183 | 0.364 | 0.278 | 0.233 | 0.421 | 0.488 | 0.663 | 0.659 |
| OCC | 0.390 | 0.270 | 0.353 | 0.424 | 0.272 | 0.379 | 0.372 | 0.403 | 0.441 | 0.446 | 0.505 | 0.686 |
| OPR | 0.384 | 0.237 | 0.356 | 0.388 | 0.248 | 0.357 | 0.363 | 0.392 | 0.490 | 0.447 | 0.482 | 0.706 |
| OV | 0.231 | 0.233 | 0.285 | 0.368 | 0.265 | 0.391 | 0.295 | 0.347 | 0.439 | 0.426 | 0.542 | 0.638 |
| SV | 0.321 | 0.204 | 0.336 | 0.388 | 0.205 | 0.317 | 0.313 | 0.333 | 0.461 | 0.403 | 0.561 | 0.665 |
| Challenge | SCM | L1-APG | STC | CSK | MTT | CT | DFT | LOT | MTMVT | LRT | Lp-IPFT | AMFLp-IPFT |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BC | 0.259 | 0.193 | 0.250 | 0.332 | 0.201 | 0.220 | 0.306 | 0.247 | 0.417 | 0.327 | 0.329 | 0.539 |
| FM | 0.143 | 0.133 | 0.150 | 0.272 | 0.148 | 0.186 | 0.196 | 0.283 | 0.360 | 0.248 | 0.441 | 0.497 |
| MB | 0.136 | 0.110 | 0.182 | 0.306 | 0.111 | 0.178 | 0.193 | 0.265 | 0.360 | 0.274 | 0.463 | 0.515 |
| DEF | 0.194 | 0.141 | 0.232 | 0.279 | 0.142 | 0.202 | 0.277 | 0.257 | 0.358 | 0.245 | 0.314 | 0.498 |
| IV | 0.364 | 0.179 | 0.305 | 0.339 | 0.202 | 0.200 | 0.300 | 0.235 | 0.385 | 0.306 | 0.347 | 0.528 |
| IPR | 0.260 | 0.189 | 0.247 | 0.318 | 0.203 | 0.253 | 0.258 | 0.257 | 0.409 | 0.347 | 0.413 | 0.546 |
| LR | 0.113 | 0.154 | 0.199 | 0.251 | 0.157 | 0.214 | 0.196 | 0.169 | 0.297 | 0.304 | 0.475 | 0.467 |
| OCC | 0.313 | 0.216 | 0.245 | 0.296 | 0.220 | 0.263 | 0.275 | 0.297 | 0.325 | 0.316 | 0.380 | 0.498 |
| OPR | 0.310 | 0.189 | 0.247 | 0.281 | 0.202 | 0.257 | 0.278 | 0.292 | 0.370 | 0.319 | 0.363 | 0.523 |
| OV | 0.205 | 0.207 | 0.197 | 0.294 | 0.232 | 0.296 | 0.233 | 0.281 | 0.339 | 0.312 | 0.419 | 0.474 |
| SV | 0.261 | 0.166 | 0.276 | 0.276 | 0.169 | 0.220 | 0.236 | 0.251 | 0.346 | 0.293 | 0.427 | 0.498 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y.; Huang, D.; Huang, W. Target Tracking Algorithm Based on an Adaptive Feature and Particle Filter. Information 2018, 9, 140. https://doi.org/10.3390/info9060140
Lin Y, Huang D, Huang W. Target Tracking Algorithm Based on an Adaptive Feature and Particle Filter. Information. 2018; 9(6):140. https://doi.org/10.3390/info9060140
Chicago/Turabian StyleLin, Yanming, Detian Huang, and Weiqin Huang. 2018. "Target Tracking Algorithm Based on an Adaptive Feature and Particle Filter" Information 9, no. 6: 140. https://doi.org/10.3390/info9060140
APA StyleLin, Y., Huang, D., & Huang, W. (2018). Target Tracking Algorithm Based on an Adaptive Feature and Particle Filter. Information, 9(6), 140. https://doi.org/10.3390/info9060140