
Inverse Modeling of Hydrologic Parameters in CLM4 via Generalized Polynomial Chaos in the Bayesian Framework




Abstract
:1. Introduction
2. Dataset and Parameterization
3. Bayesian Methodology
3.1. Bayesian Inverse Problem Setup
| Algorithm 1 Updates of a single MCMC swap. |
|
3.2. Surrogate Model Specification
3.2.1. Generalized Polynomial Chaos Expansion
3.2.2. Bayesian Training Procedure
| Algorithm 2 Updates of the Gibbs swap. |
|
Bayesian Model Averaging
Median Probability Model Based Evaluation
4. Analysis of the US-ARM Data-Set
Surrogate Model Building Step
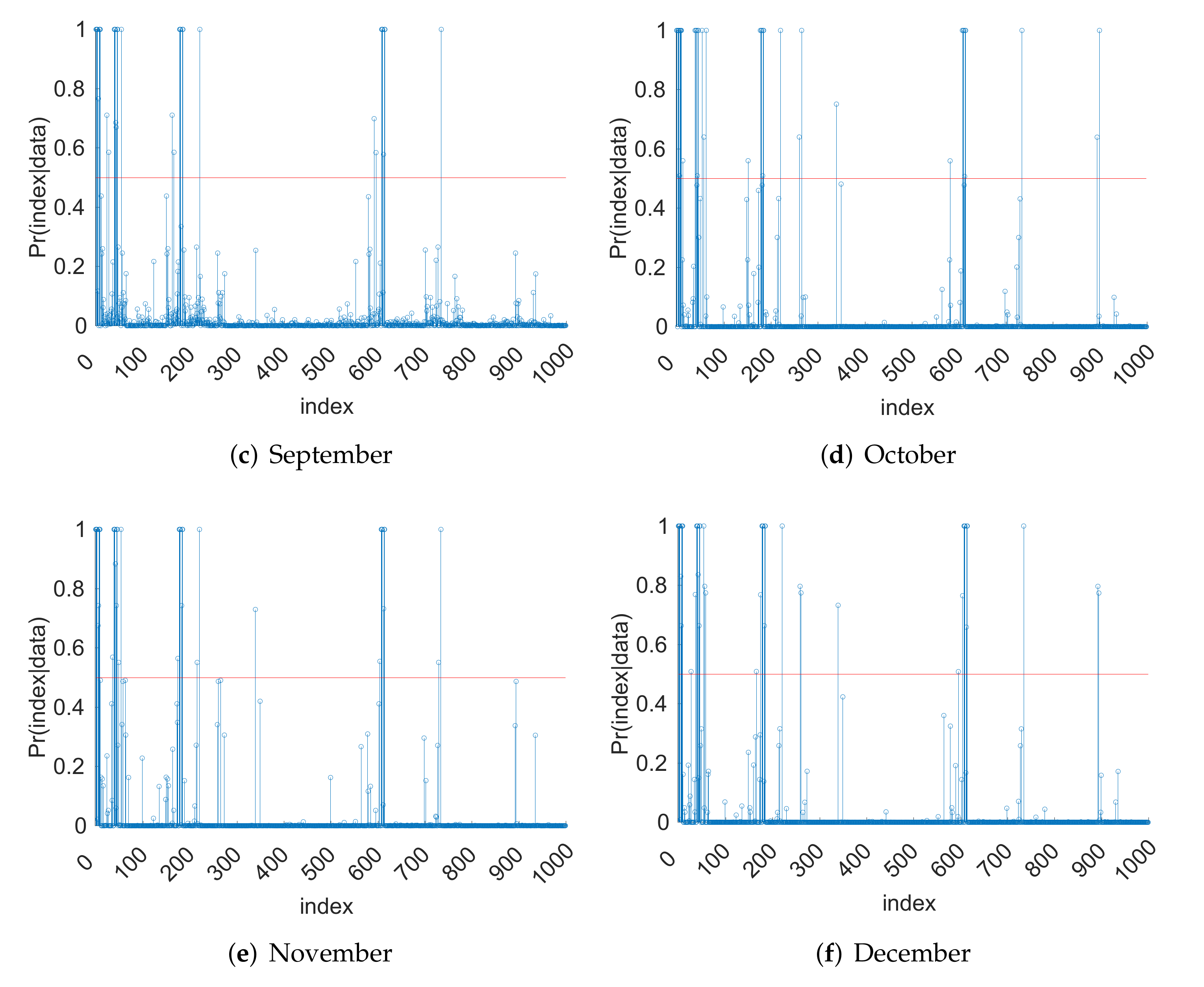
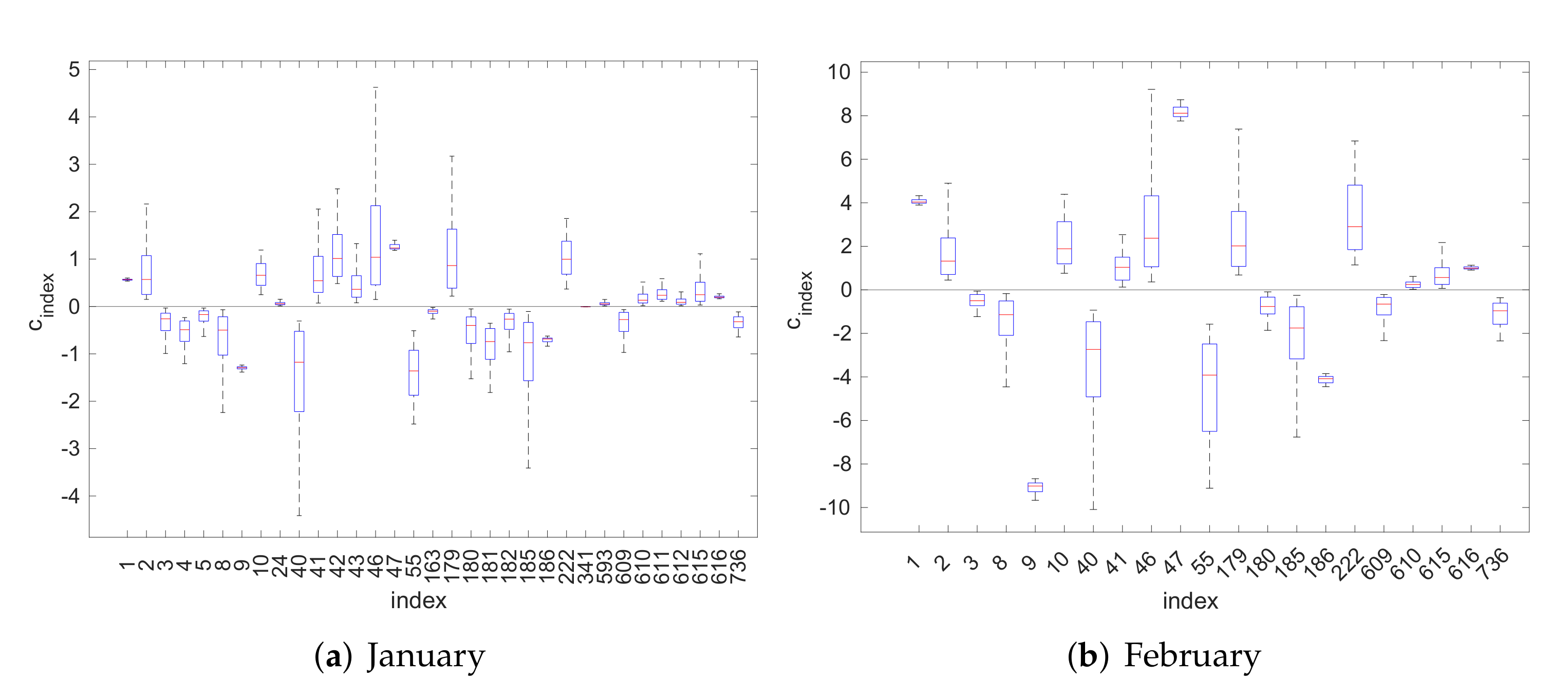
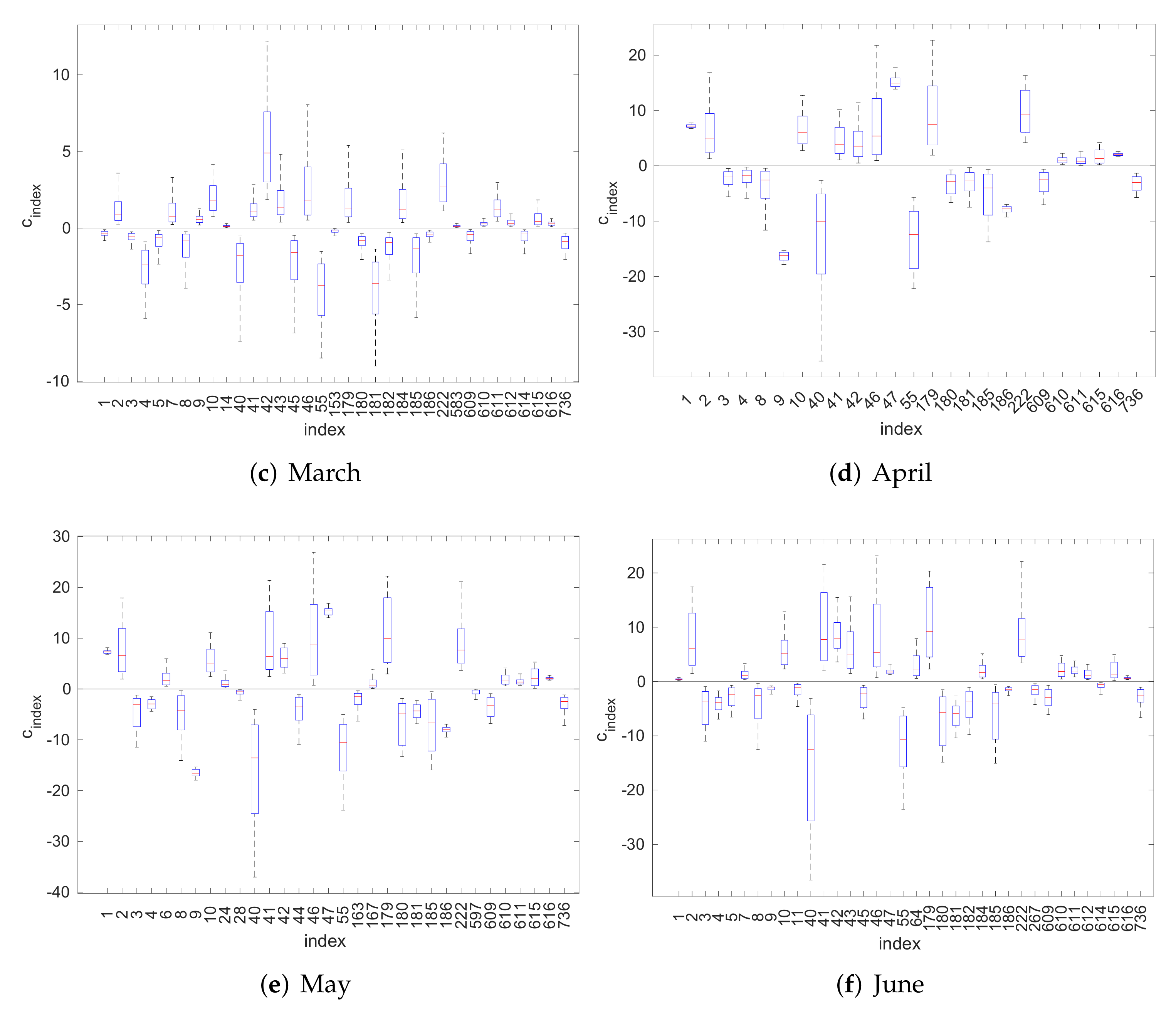
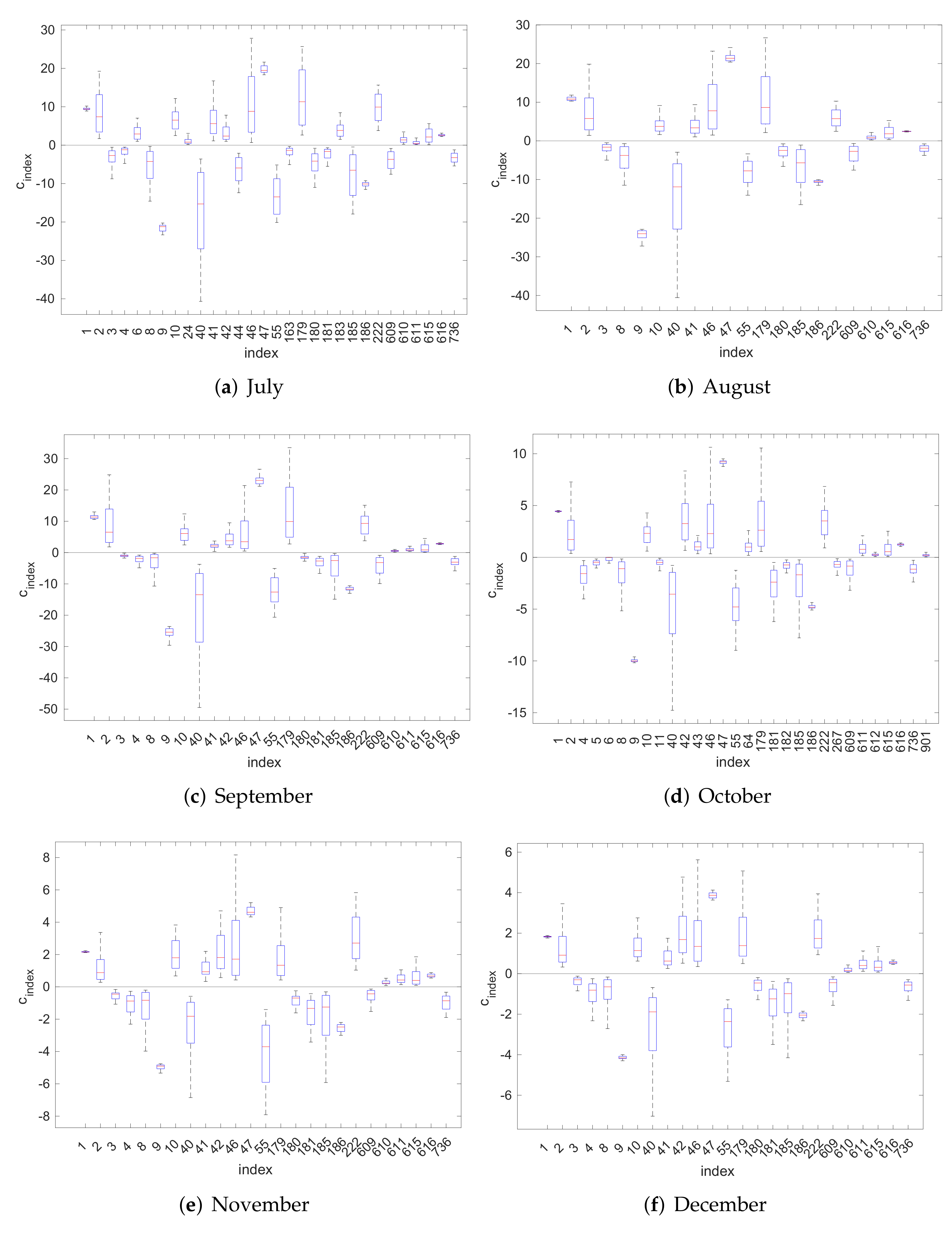
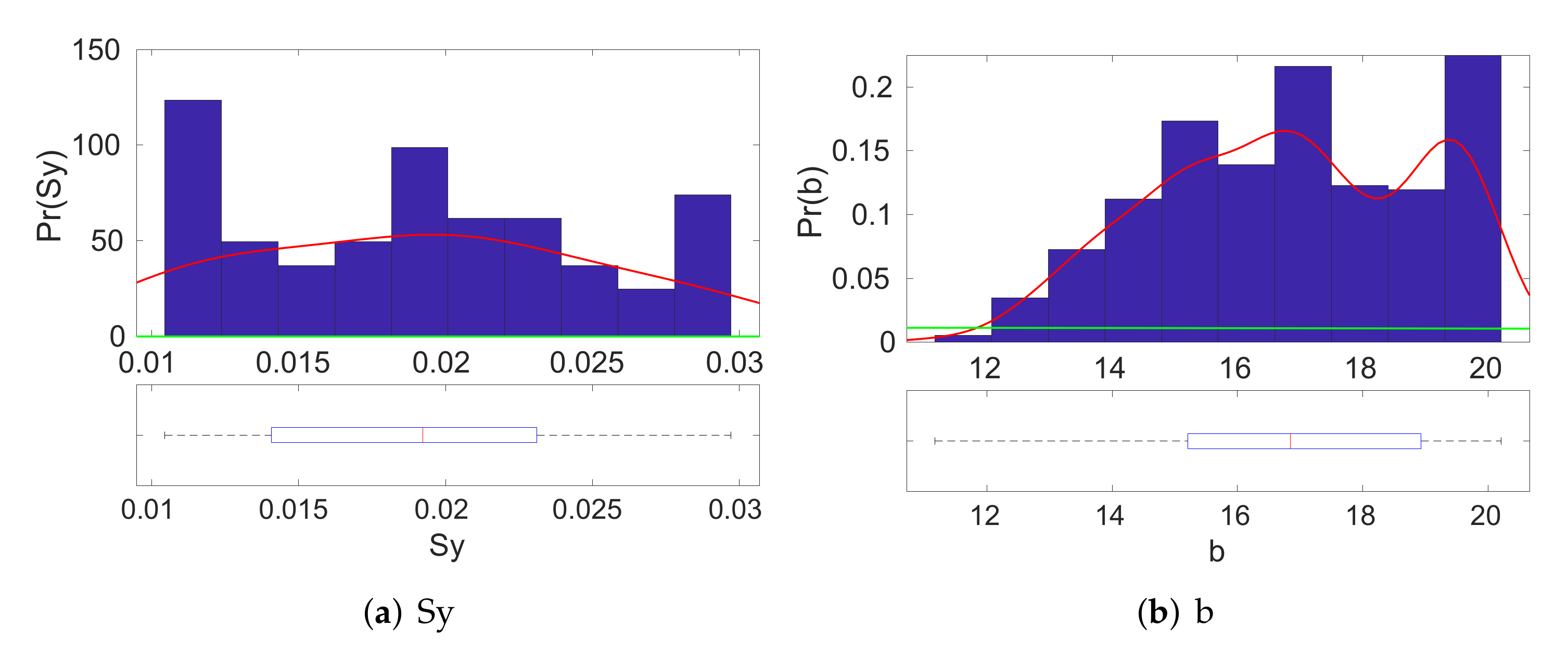
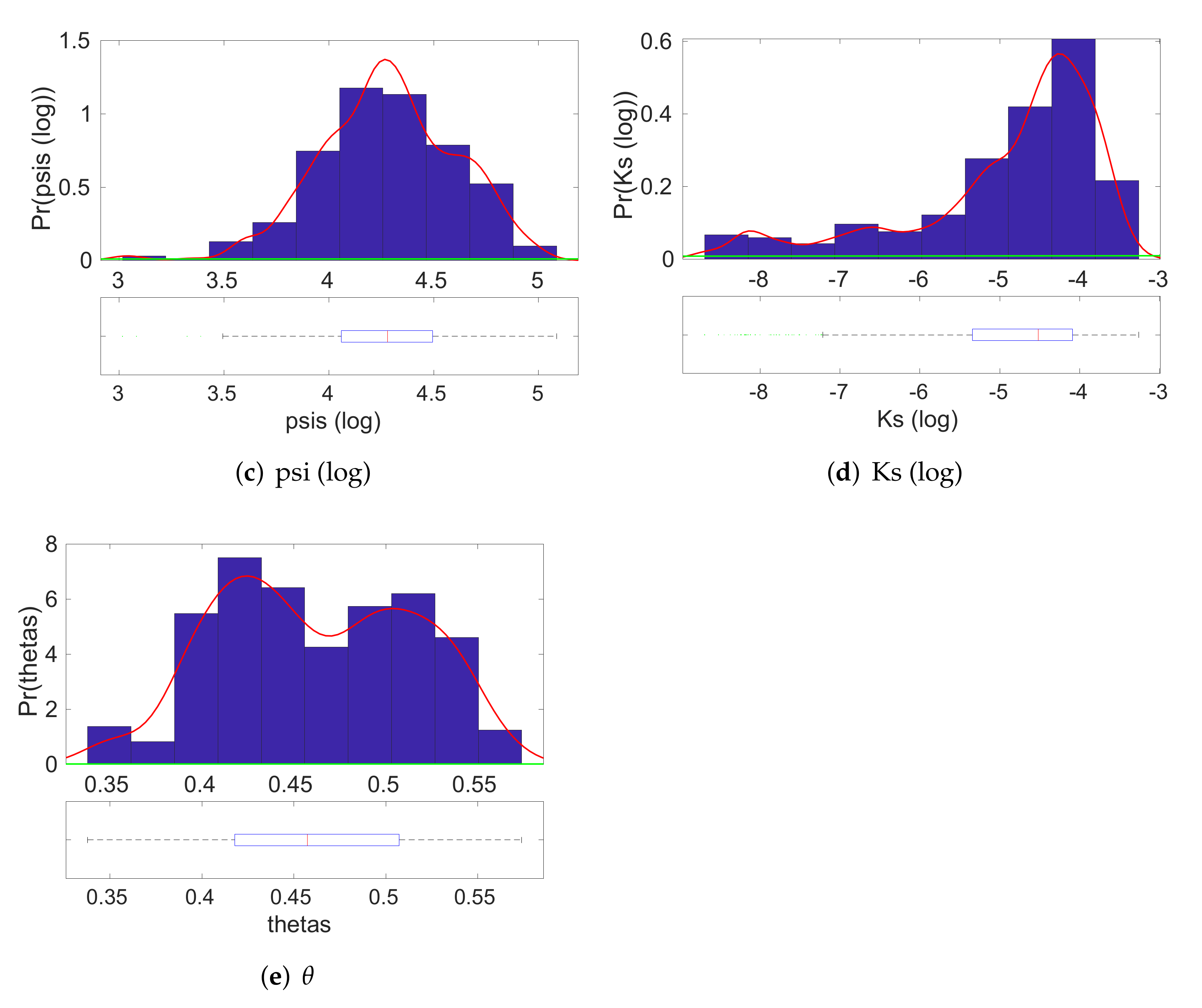
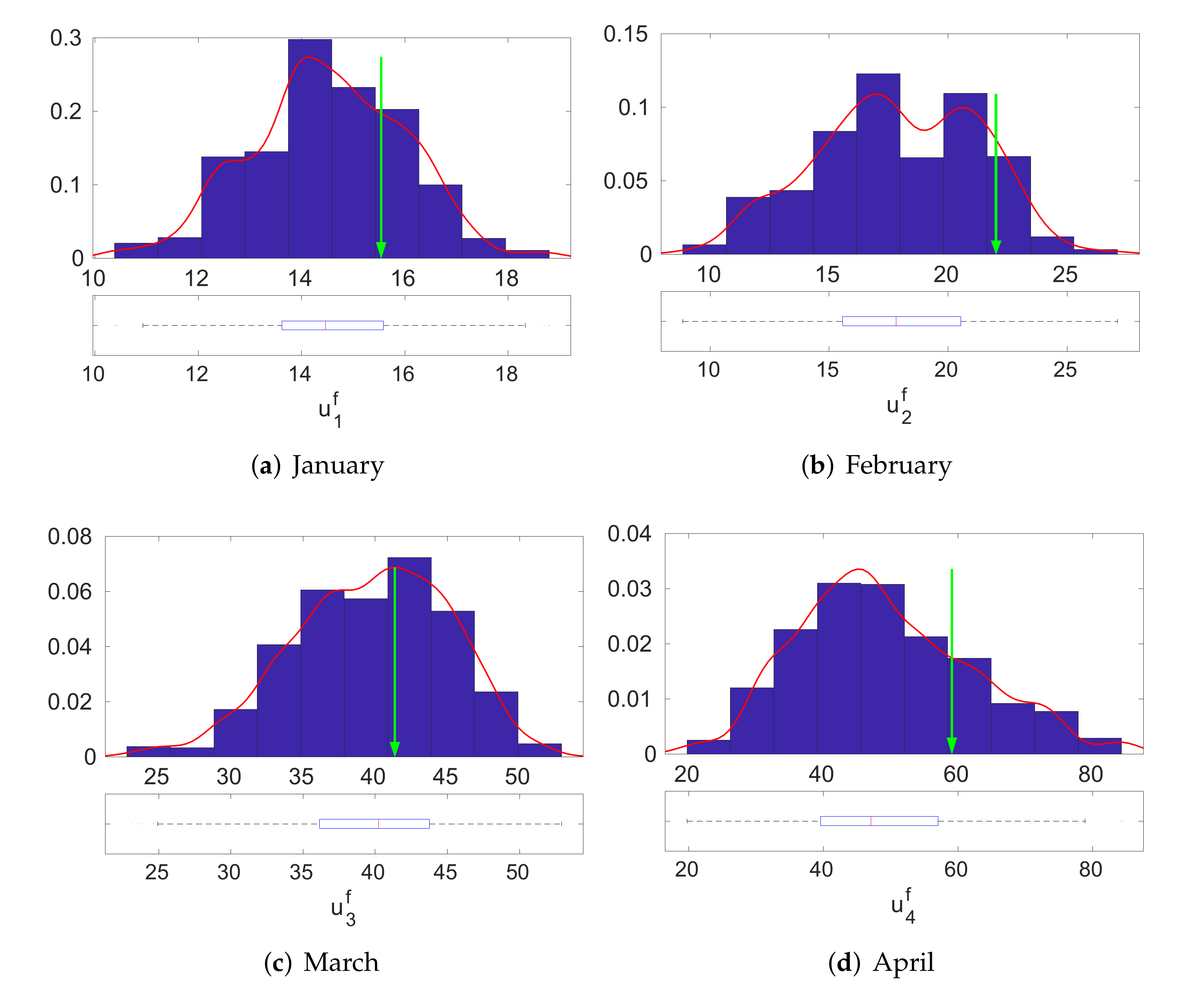
4.1. Inversion Step
4.2. Model Validation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pitman, A. The evolution of, and revolution in, land surface schemes designed for climate models. Int. J. Climatol. J. R. Meteorol. Soc. 2003, 23, 479–510. [Google Scholar] [CrossRef]
- Bastidas, L.; Gupta, H.V.; Sorooshian, S.; Shuttleworth, W.J.; Yang, Z.L. Sensitivity analysis of a land surface scheme using multicriteria methods. J. Geophys. Res. Atmos. 1999, 104, 19481–19490. [Google Scholar] [CrossRef] [Green Version]
- Henderson-Sellers, A.; Pitman, A.; Love, P.; Irannejad, P.; Chen, T. The project for intercomparison of land surface parameterization schemes (PILPS): Phases 2 and 3. Bull. Am. Meteorol. Soc. 1995, 76, 489–504. [Google Scholar] [CrossRef] [Green Version]
- Henderson-Sellers, A.; Chen, T.; Nakken, M. Predicting Global Change at the Land-Surface: The Project for Intercomparison of Land-Surface pArameterization Schemes (PILPS) (Phase 4); Technical Report; American Meteorological Society: Boston, MA, USA, 1996. [Google Scholar]
- Rosero, E.; Yang, Z.L.; Wagener, T.; Gulden, L.E.; Yatheendradas, S.; Niu, G.Y. Quantifying parameter sensitivity, interaction, and transferability in hydrologically enhanced versions of the Noah land surface model over transition zones during the warm season. J. Geophys. Res. Atmos. 2010, 115, D03106. [Google Scholar] [CrossRef] [Green Version]
- Hou, Z.; Huang, M.; Leung, L.R.; Lin, G.; Ricciuto, D.M. Sensitivity of surface flux simulations to hydrologic parameters based on an uncertainty quantification framework applied to the Community Land Model. J. Geophys. Res. Atmos. 2012, 117, D15. [Google Scholar] [CrossRef]
- Huang, M.; Hou, Z.; Leung, L.R.; Ke, Y.; Liu, Y.; Fang, Z.; Sun, Y. Uncertainty analysis of runoff simulations and parameter identifiability in the Community Land Model: Evidence from MOPEX basins. J. Hydrometeorol. 2013, 14, 1754–1772. [Google Scholar] [CrossRef]
- Collins, W.D.; Rasch, P.J.; Boville, B.A.; Hack, J.J.; McCaa, J.R.; Williamson, D.L.; Briegleb, B.P.; Bitz, C.M.; Lin, S.J.; Zhang, M. The formulation and atmospheric simulation of the Community Atmosphere Model version 3 (CAM3). J. Clim. 2006, 19, 2144–2161. [Google Scholar] [CrossRef] [Green Version]
- Gent, P.R.; Yeager, S.G.; Neale, R.B.; Levis, S.; Bailey, D.A. Improvements in a half degree atmosphere/land version of the CCSM. Clim. Dyn. 2010, 34, 819–833. [Google Scholar] [CrossRef]
- Lawrence, D.M.; Oleson, K.W.; Flanner, M.G.; Thornton, P.E.; Swenson, S.C.; Lawrence, P.J.; Zeng, X.; Yang, Z.L.; Levis, S.; Sakaguchi, K.; et al. Parameterization improvements and functional and structural advances in version 4 of the Community Land Model. J. Adv. Model. Earth Syst. 2011, 3. [Google Scholar] [CrossRef]
- Ray, J.; Hou, Z.; Huang, M.; Sargsyan, K.; Swiler, L. Bayesian calibration of the Community Land Model using surrogates. SIAM/ASA J. Uncertain. Quantif. 2015, 3, 199–233. [Google Scholar] [CrossRef] [Green Version]
- Huang, M.; Ray, J.; Hou, Z.; Ren, H.; Liu, Y.; Swiler, L. On the applicability of surrogate-based Markov chain Monte Carlo-Bayesian inversion to the Community Land Model: Case studies at flux tower sites. J. Geophys. Res. Atmos. 2016, 121, 7548–7563. [Google Scholar] [CrossRef]
- Gong, W.; Duan, Q.; Li, J.; Wang, C.; Di, Z.; Dai, Y.; Ye, A.; Miao, C. Multi-objective parameter optimization of common land model using adaptive surrogate modeling. Hydrol. Earth Syst. Sci. 2015, 19, 2409–2425. [Google Scholar] [CrossRef] [Green Version]
- Sargsyan, K.; Safta, C.; Najm, H.N.; Debusschere, B.J.; Ricciuto, D.; Thornton, P. Dimensionality reduction for complex models via Bayesian compressive sensing. Int. J. Uncertain. Quantif. 2014, 4, 63–93. [Google Scholar] [CrossRef]
- Karagiannis, G.; Lin, G. Selection of polynomial chaos bases via Bayesian model uncertainty methods with applications to sparse approximation of PDEs with stochastic inputs. J. Comput. Phys. 2014, 259, 114–134. [Google Scholar] [CrossRef] [Green Version]
- Fischer, M.L.; Billesbach, D.P.; Berry, J.A.; Riley, W.J.; Torn, M.S. Spatiotemporal variations in growing season exchanges of CO2, H2O, and sensible heat in agricultural fields of the Southern Great Plains. Earth Interact. 2007, 11, 1–21. [Google Scholar] [CrossRef]
- Torn, M. AmeriFlux US-ARM ARM Southern Great Plains Site-Lamont; Technical Report, AmeriFlux; Lawrence Berkeley National Laboratory: Berkeley, CA, USA, 2016. [Google Scholar]
- Niu, G.Y.; Yang, Z.L.; Dickinson, R.E.; Gulden, L.E. A simple TOPMODEL-based runoff parameterization (SIMTOP) for use in global climate models. J. Geophys. Res. Atmos. 2005, 110, D21. [Google Scholar] [CrossRef] [Green Version]
- Niu, G.Y.; Yang, Z.L.; Dickinson, R.E.; Gulden, L.E.; Su, H. Development of a simple groundwater model for use in climate models and evaluation with Gravity Recovery and Climate Experiment data. J. Geophys. Res. Atmos. 2007, 112, D7. [Google Scholar] [CrossRef]
- Oleson, K.; Niu, G.Y.; Yang, Z.L.; Lawrence, D.; Thornton, P.; Lawrence, P.; Stöckli, R.; Dickinson, R.; Bonan, G.; Levis, S.; et al. Improvements to the Community Land Model and their impact on the hydrological cycle. J. Geophys. Res. Biogeosci. 2008, 113, G1. [Google Scholar] [CrossRef]
- Oleson, K.W.; Lawrence, D.M.; Gordon, B.; Flanner, M.G.; Kluzek, E.; Peter, J.; Levis, S.; Swenson, S.C.; Thornton, E.; Feddema, J.; et al. Technical Description of Version 4.0 of the Community Land Model (CLM). 2010. Available online: https://www.researchgate.net/publication/277114326_Technical_Description_of_version_40_of_the_Community_Land_Model_CLM (accessed on 20 March 2022).
- Caflisch, R.E. Monte carlo and quasi-monte carlo methods. Acta Numer. 1998, 7, 1–49. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Sloan, I.H. Low discrepancy sequences in high dimensions: How well are their projections distributed? J. Comput. Appl. Math. 2008, 213, 366–386. [Google Scholar] [CrossRef] [Green Version]
- Marzouk, Y.; Xiu, D. A Stochastic Collocation Approach to Bayesian Inference in Inverse Problems. Commun. Comput. Phys. 2009, 6, 826–847. [Google Scholar] [CrossRef] [Green Version]
- Berger, J.O. Statistical Decision Theory and Bayesian Analysis; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Robert, C.P.; Casella, G. Monte Carlo Statistical Methods, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Xiu, D. Numerical Methods for Stochastic Computations: A Spectral Method Approach; Princeton University Press: Princeton, NJ, USA, 2010. [Google Scholar]
- Xiu, D.; Karniadakis, G.E. The Wiener–Askey Polynomial Chaos for Stochastic Differential Equations. SIAM J. Sci. Comput. 2002, 24, 619–644. [Google Scholar] [CrossRef]
- Blatman, G.; Sudret, B. Adaptive sparse polynomial chaos expansion based on least angle regression. J. Comput. Phys. 2011, 230, 2345–2367. [Google Scholar] [CrossRef]
- Doostan, A.; Owhadi, H. A non-adapted sparse approximation of PDEs with stochastic inputs. J. Comput. Phys. 2011, 230, 3015–3034. [Google Scholar] [CrossRef] [Green Version]
- Hans, C. Model uncertainty and variable selection in Bayesian LASSO regression. Stat. Comput. 2010, 20, 221–229. [Google Scholar] [CrossRef]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 721–741. [Google Scholar] [CrossRef]
- Hoeting, J.A.; Madigan, D.; Raftery, A.E.; Volinsky, C.T. Bayesian model averaging: A tutorial. Stat. Sci. 1999, 14, 382–401. [Google Scholar]
- Barbieri, M.M.; Berger, J.O. Optimal Predictive Model Selection. Ann. Stat. 2004, 32, 870–897. [Google Scholar] [CrossRef]
- Sun, Y.; Hou, Z.; Huang, M.; Tian, F.; Ruby Leung, L. Inverse modeling of hydrologic parameters using surface flux and runoff observations in the Community Land Model. Hydrol. Earth Syst. Sci. 2013, 17, 4995–5011. [Google Scholar] [CrossRef] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Months | Measurement | |||
|---|---|---|---|---|
| January-April | ||||
| May-July | ||||
| August-December | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karagiannis, G.; Hou, Z.; Huang, M.; Lin, G. Inverse Modeling of Hydrologic Parameters in CLM4 via Generalized Polynomial Chaos in the Bayesian Framework. Computation 2022, 10, 72. https://doi.org/10.3390/computation10050072
Karagiannis G, Hou Z, Huang M, Lin G. Inverse Modeling of Hydrologic Parameters in CLM4 via Generalized Polynomial Chaos in the Bayesian Framework. Computation. 2022; 10(5):72. https://doi.org/10.3390/computation10050072
Chicago/Turabian StyleKaragiannis, Georgios, Zhangshuan Hou, Maoyi Huang, and Guang Lin. 2022. "Inverse Modeling of Hydrologic Parameters in CLM4 via Generalized Polynomial Chaos in the Bayesian Framework" Computation 10, no. 5: 72. https://doi.org/10.3390/computation10050072
APA StyleKaragiannis, G., Hou, Z., Huang, M., & Lin, G. (2022). Inverse Modeling of Hydrologic Parameters in CLM4 via Generalized Polynomial Chaos in the Bayesian Framework. Computation, 10(5), 72. https://doi.org/10.3390/computation10050072