1. Introduction
Tourism has undergone long-term development and expansion, becoming one of the most globally competitive and dynamic markets [
1]. Significantly, the United Nations World Tourism Organization (UNWTO) (2019) in [
2] observed a significant reality that international tourism continues to expand with greater diversity than global economies, making the tourism industry a global engine of economic growth and sustainability. Therefore, tourism forecasting has gained traction in recent decades, especially considering the fragile nature of tourism services, such as the imbalanced supply and demand, vacant hotel rooms, and airplane seats that cannot be boarded [
3,
4,
5,
6,
7]. Thus, the time series of tourist arrivals includes multiple non-stability, non-linearity, and complex patterns that reflect the nature of volatility or variation in tourist arrivals [
8].
The concept of volatility originated in finance due to the observation that high market returns tend to be followed by large returns, whereas low market returns also appear to be followed by small returns [
9]. Tourism forecasting is related to tourism volatility to forecast the tendency of tourism variation. It is defined as the influence of shocks that occur in periods of very high and low activity. These shifts are commonly associated with what is known as “news shocks” [
4], such as unpredictable financial recession [
10], seasonality changes [
11,
12], natural catastrophes [
13], terrorist attacks [
14], and other effects. Utilizing and constructing effective methods for tourism demand volatility forecasting becomes a matter of urgent consideration for the entire tourism industry [
15,
16].
The desire to reduce risk and ambiguity is the driving force behind the demand for more accurate tourism forecasting [
17,
18]. Therefore, it is critical to create tourism forecasting models with high accuracy and reliability. Abundant data processing systems have emerged to facilitate the development of a wide range of new approaches to tourism forecasting. The novel methods include time series models, econometric models, artificial intelligence, judgmental forecasting, and combined or hybrid models [
19]. Researchers are inclined to use generalized autoregressive conditional heteroscedasticity (GARCH) models to simulate stylized facts when discussing volatility forecasting. Since GARCH models can recreate stylized phenomena, such as volatility clustering, they are widely used to analyze time series data pertaining to financial markets and have achieved satisfactory results [
20]. Meanwhile, the autoregressive integrated moving average (ARIMA) model and its offshoots have aroused great interest recently, primarily because of their excellent adaptability and convenience in representing a diverse range of time series. The other reason is that the ARIMA model is built using the Box–Jenkins method, which has high effectiveness in establishing models [
21]. An extension model known as SARIMA eliminates non-stationarity in the series through seasonal differencing of the proper order. The SARIMA model is developed for time series data showing seasonal variations. It has been validated that the SARIMA model can fit to the time series data well. Therefore, (S)ARIMA and GARCH approaches are extensively applied to modeling and forecasting. Academics have also focused on several traditional statistical approaches, such as the exponential smoothing (ETS-ES), which has been demonstrated superior to several complicated algorithms [
22]. The ETS-ES technique overcomes the shortcomings of conventional ES models. Specifically, ETS-ES predictions are simply weighted averages of past observations. Higher weights indicate more recent observations, and total weights drop exponentially with time. In this study, the smooth transition exponential smoothing (STES) method was employed for forecasting tourism demand volatility for the first time. The STES method allows the change of the smoothing parameter, which is basically a logistic function of a variable specified by the user [
23,
24,
25,
26].
It makes sense to use numerous forecast combining methods, providing a new orientation for tourism forecasting research that incorporates the forecasts associated with the single models [
27], given that forecast combining is a method that developed by a set of single models lying on a weighting distribution [
28]. Another viewpoint is that combining gives the potential for a diversified portfolio of different forecasts [
29]. According to empirical research, forecast combining is an effective method for improving the accuracy of tourism forecasting [
27,
30,
31]. In addition to the above-mentioned models, tourist forecasting studies have also investigated simple combination, variance-covariance, and discounted mean square forecast error (MSFE) [
32,
33,
34,
35]; weighted combination [
9,
36,
37,
38,
39,
40]; ARIMA-back propagation neural network (ARIMA-BPNN), Naïve-support vector regression (Naïve-SVR), ES-SVR, and ARIMA-SVR methods [
41]. Based on the findings of empirical research, to improve the forecasting accuracy of the model, it is necessary to use effective approaches to breakdown the original information and mix linear and nonlinear models throughout the hybridization process. In fact, linear models, such as ARIMA and GARCH, are more capable of forecasting linear and smooth trends [
20]. Therefore, GARCH and ES specifications were added to the SARIMA model, and SARIMA-GARCH and SARIMA-ES models were thereby constructed for forecasts of the tourism demand volatility in this paper. Moreover, smooth transition (ST), a new combined approach, was introduced in this research. By modeling the combining weight as a logistic function of one or more transition variables, the ST method enabled the combination to adapt over time to the relative supremacy of various methods [
42].
There is a growing body of literature on forecast combining, but it is surprising that research on volatility forecast combining in the tourism section is significantly less developed. The purpose of this study is to close the aforementioned gap by determining if forecast combining methods may improve the tourism demand volatility forecasting accuracy in a practical setting pertaining to the primary source markets of Malaysia’s inbound tourism. Furthermore, this study offers a reliable and realistic volatility forecasting for policy agencies, policymaking, and academic literature. The fact that volatility patterns have a major impact on the forecasting accuracy is a crucial explanation. Forecast limitations (upper and lower bounds) are required to evaluate the impact of extreme shocks and hazards on international tourism demand [
43].
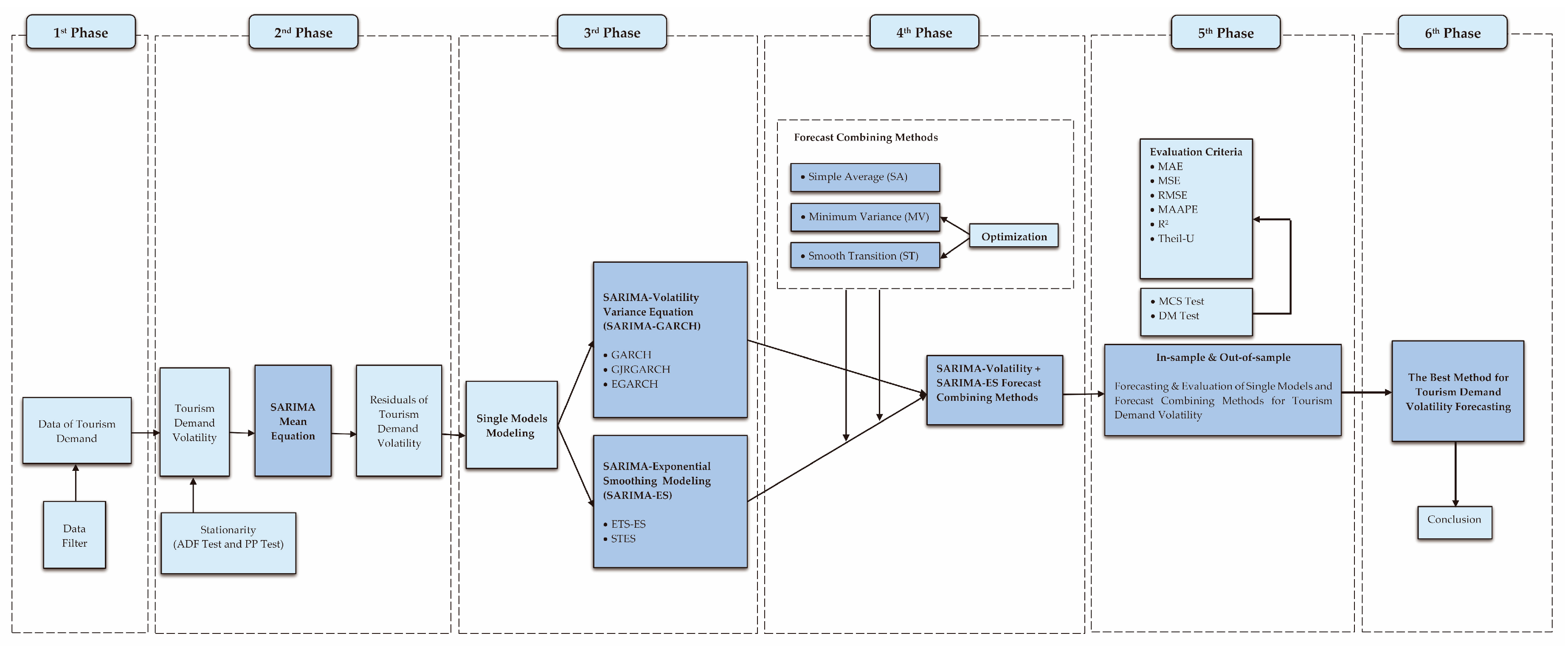
Thus, this research also incorporates innovative methods for combining volatility forecasts. Among them, four modeling methods, namely seasonal autoregressive integrated moving average (SARIMA), generalized autoregressive conditional heteroskedasticity (GARCH), error-trend-seasonal exponential smoothing (ETS-ES), and smooth transition exponential smoothing (STES), are utilized to construct models that forecast tourist arrivals into Malaysia. The prime focus is on the three forecast combining methods, including simple average (SA), minimum variance (MV), and an innovative proposed smooth transition (ST), which has never been considered before in forecasting tourism demand volatility. They are utilized to examine how effective forecast combining is at forecasting the tourism demand volatility. This study analyzes the performance of the GARCH and ES family methods, and their combinations, primarily with respect to three forecast combining methods. The most important contribution of this work is deciphering the forecasting accuracy of forecast combining and single forecasts in tourism demand volatility and discovering the optimal method for forecasting tourism demand volatility in Malaysia.
The remaining sections of this study are organized as follows.
Section 2 discusses current research in tourism forecasting and modeling, and the yield of forecast combining methods. Three forecast combining methods, four volatility models, two exponential smoothing methods, and evaluation measures of forecasting accuracy are introduced in
Section 3. In
Section 4, the data sources and research methodology are explained.
Section 5 and
Section 6 examine, respectively, the in-sample outcomes associated with the methods and the out-of-sample outcomes.
Section 7 summarizes this study.
5. In-Sample Estimation Results
To fit SARIMA models to stationary time series, it is important to perform both regular and seasonal differentiation. From the test time series data, the first-order regular difference and first seasonal difference were calculated. The Akaike information criterion (AIC) and the Bayesian information criterion (BIC) were used to assess the parameters of the best-fitting SARIMA model. The relevance of the model parameters was then tested using t-test statistics. The residuals of the estimated model were created and compared to a white noise series using ACF, PACF plots, and the Ljung–Box test, respectively. To determine residual heteroscedasticity, the autoregressive conditional heteroscedasticity Lagrange multiplier test was utilized. If the estimated values were too small and the residuals did not reflect white noise, model identification, parameter estimation, and diagnostic testing were repeated until the correct model was discovered.
Based on AIC and BIC values, the first column of
Table 4 displays the mean equations for various series. These models created “residuals” for variance equation modeling and forecast combining methods evaluation for forecasting the Malaysian tourism demand volatility. The unit root(s) and the requirement for differences, as determined by the ADF and PP tests, indicate that each series meets the associative significance criteria of at least 5%. Obviously, the models of China, Brunei, India, South Korea, and Australia have AR parameters. Importantly, these models provide seasonal parameters for all series. In this study, the relative order of seasonal and nonseasonal factors was established by combining
Figure 1 and
Figure 2. These certificates allow us to account for seasonality in the modeling process and analysis of news shocks.
Since several volatility models were used to examine seasonal volatility estimates for Malaysia tourist arrivals data, the conditional variance equation must always be discovered during the second phase. The completed SARIMA-conditional variance equations (GARCH, EGARCH, and GJRGARCH) suggest that tourism movements into Malaysia are volatile, and
Table 5,
Table 6 and
Table 7 present additive seasonal patterns with variable amplitudes for inbound tourism statistics. The results are consistent with the prior findings [
12,
37,
57,
78,
86,
141]. This study utilized lag month values to assess monthly changes in Malaysian tourism demand. This is because the lagged dependent variables can reduce the occurrence of autocorrelation resulting from model misspecification. Consequently, we can defend the presence of autocorrelation in the model by taking lagged dependent variables into consideration. Importantly, months in different years are accompanied by sudden news shocks, such as natural disasters, disease, climate fluctuation, events, and financial crises, which will have gradual short-term or long-term delayed effects on incoming tourism. In other words, many visitors’ decisions or behaviors may be more sensitive to long-term changes in tourism circumstances or surroundings than they are to transient fluctuations in conditions. In this instance, the lagged values of conditions determine the duration of the change, and the presence of lagged effects illustrates this unequal reaction to short-term and long-term tourism variation. In addition, these data are monthly time series, and with the unique monthly dummy, the coefficients of each month t represent that month’s influence on the tourist arrivals of the following month (t + 1).
GARCH (1,1) models in
Table 5 have an asterisk value to indicate that the model’s parameters are statistically significant at
p values less than 10%, 5%, and 1%, respectively. In all series, the volatility of Malaysian tourism demand is more likely to be affected by news shocks since
α +
β equals 1. However, with only a few series having a large monthly impact (a significance at 10%, 5%, and 1% correspondingly), GARCH (1, 1) shows that the effect of tourism on each series is less pronounced. For example, according to the coefficients of months in different series, January (−1), February (−1), March (−1), July (−1), August (−1), and October (−1) in S1 (Singapore) have implications for tourists entering Malaysia; S3 (China) represents February (−1), May (−1) and October (−1); S5 (Brunei) shows January (−1), April (−1), May (−1), July (−1) to October (−1) and S13 (UK) displays May (−1), August (−1), and Nov (−1). Overall, in the GARCH (1,1) model, May, August, and October have a larger monthly impact on tourists.
However, the GARCH model is incapable of examining asymmetric effects and the influence of both positive and negative news shocks on leverage. GJRGARCH and EGARCH models were developed in response to this issue. In the EGARCH (1,1) models presented in
Table 6, the coefficients
ϕ that are highlighted with an asterisk indicate that they reach statistical significance at 1%, 5%, and 10%, respectively, including S1 (Singapore), S3 (China), S6 (India), S7 (South Korea), and S13 (UK). All of these values, with the exception of S6 (India), demonstrate that
ϕ is less than zero, which suggests that leverage effects are presented in the models. In addition, the presence of a negative sign for shows that bad news has a higher impact on Malaysia’s monthly tourism demand volatility than good news. The EGARCH (1,1) model produced a greater monthly effect for visitors in all other series than the GARCH (1,1) model, with the exception of S15 (France). February (−1), May (−1), August (−1), October (−1), and November (−1) are the months that have the largest impact on Malaysian tourist arrivals.
While the leverage effect is being analysed, asymmetric GJRGARCH model allows the conditional variance to respond differentially to bad and good news. Referring to
Table 7, there are the asymmetric effects on the monthly tourism demand volatility in the GJRGARCH (1,1) model, which are presented in S2 (Indonesia), S4 (Thailand), S5 (Brunei), S7 (South Korea), S8 (Japan), and S16 (Germany). At the same time, through the coefficients of months in different series, GJRGARCH (1, 1) modeling produces fewer monthly effects on inbound tourists to Malaysia compared to GARCH (1, 1) and EGARCH (1, 1). Only S3 (China), S4 (Thailand), S5 (Brunei), S9 (Philippines), S11 (Taiwan (China)), S13 (UK), S16 (Germany), and S17 (Saudi Arabia) have monthly effects.
The values for adjusted R2, log-likelihood, AIC, and BIC are used to analyze and investigate the conditional variance, which is determined based on the forecasting ability of each volatility model. In other words, the conditional variance is determined based on how well each model can forecast future volatility. The EGARCH (1,1) model has the highest adjusted R2 values and outperforms the GJRGARCH (1,1) and GARCH (1,1) models in log-likelihood performance. The AIC and BIC of EGARCH (1,1) is the lowest. Furthermore, the EGARCH (1,1) represents more monthly effects for the most series. Hence, it can be inferred that the EGARCH model utilized in this study had the most significant power to forecast conditional variance. Malaysian tourism developers can adjust tourism marketing strategies and plans accordingly based on EGARCH modeling and the dynamics of tourists in the lag few months.
In addition to the above-mentioned analysis, as an example, it relies upon the following selected criteria: (i). top tourist arrivals into Malaysia from different states/areas; (ii). top expenditures from different states/areas; (iii). the temperate countries/regions with distinct seasons; we chose the UK, the USA, China, Germany, and Australia, shown in
Table 8, to compare the conditional variance equations.
Table 8 depicts the estimated parameters for the conditional variance equations based on the three unique volatility models with the seasonal dummy, GARCH (1,1), GJRGARCH (1,1), and EGARCH (1,1), corresponding to the
Table 4 mean equations for the five tourist arrival markets. It basically displays the model with the maximum log-likelihood (LL), adjusted R
2, AIC, and BIC statistics when more than conditional variance equations have significant parameters while adhering to specified limits. In addition, dummy variables for the reference month, December, are calculated from JAN (January) to NOV (November).
Seasonal dummies are significant at p < 0.01 or p < 0.1, indicating that monthly seasonality occurs. The GARCH (1,1) model suggests that May (−1), August (−1) and November (−1) have monthly impacts on tourist arrivals from the UK. Similarly, the EGARCH (1,1) model shows May (−1), August (−1), October (−1), and November (−1) effects on visitor arrivals from the UK. All the remaining lag months have monthly influences on tourist arrivals from the UK, except February (−1), April (−1), June (−1), and July (−1). Therefore, under the influence of the lag months, there will be more British tourists traveling to Malaysia in June, September, and December. This is because the UK is mainly located in the northern part of Europe, and it enjoys a typical maritime climate with relatively minimal temperature changes between seasons and a lot of rain. Generally speaking, the months between June and September include public holidays in the UK. The weather in spring and autumn is changeable and humid, and the winter (November–February) is cold with little sunshine. Therefore, the British prefer to travel in summer.
As for the USA, GARCH (1,1), EGARCH (1,1), and GJRGARCH (1,1) models indicate no marked monthly impacts on tourist arrivals to Malaysia. Due to the vast territory and complex terrain of the USA, the weather varies greatly from place to place. However, most regions of the USA have a continental climate, but the south has a subtropical climate. There is a large temperature difference between the central part and northern plains. Meanwhile, like Malaysia, America is a multiracial country, and that is one reason why Malaysia attracts them. Thus, visitors from the USA travel abroad regardless of the season of the year, unaffected by any monthly effects.
In China, the GARCH (1,1) model reveals February (−1), May (−1), and October (−1) effects on tourist arrivals to Malaysia. All the remaining lag months, except January (−1), March (−1), June (−1), and August (−1), have monthly effects on tourist arrivals from China in the EGARCH (1,1) and GJRGARCH (1,1) models. The Chinese Spring Festival holiday is celebrated from January to February, the summer holiday lasts from June to August, and the National Day holiday falls in October. These holidays motivate seasonal traveling [
142,
143].
The monthly effect results of Germany are comparable to those of China. In the GJRGARCH (1,1), GARCH (1,1), and EGARCH (1,1) models, the effects of January (−1), February (−1), March (−1), April (−1), June (−1), September (−1), and November (−1) on tourist arrivals from Germany are notable. Germany is in a cool, westerly wind belt of the eastern Atlantic, having a continental climate. Extreme temperatures and sharp temperature fluctuations are rare here. It rains all year round. Spring in Germany (April–May) is relatively short and cold, with varied temperatures. Summer (June–August) is rainy and hot. Autumn (September–November) is warm and dry, and much rain falls. In winter (December–March), there is sufficient precipitation, and it is extremely wet and cold. Like China, Germany is a country with four distinct seasons. However, it is like summer all the year round in Malaysia. According to the above analysis, it is reasonable that Germans like to travel to Malaysia. In the meantime, there are cultural links in education and language between Germany and Malaysia. Besides, several German political foundations support sociocultural, education and media projects in Malaysia. These factors further facilitate tourism exchanges between the two countries.
Similar to the USA, there are almost no monthly effects on tourist arrivals from Australia to Malaysia. In the EGARCH (1,1) model, July (−1) and August (−1) effects on the number of tourists visiting Australia are remarkable. Located in the southern hemisphere, Australia has a tropical climate varying between desert and semi-desert. Most of the area of this country is arid. The seasons here are opposite to those in the northern hemisphere. Australia and Malaysia conduct cultural, economic, and trade exchanges. Thus, passengers from the USA may travel overseas at any time of year without being influenced by seasonal fluctuations.
Taken above, tourist arrivals to Malaysia from the USA and Australia are not affected by months. Visitor arrivals to Malaysia from the UK, China, and Germany are notably affected by months, according to the results of the three methods. An increasing number of tourists are inclined to travel to Malaysia for the reason that Malaysia is close to the equator and has a tropical rainforest climate and a tropical monsoon climate. There is no notable variation of the weather with the season, and the annual temperature remains almost unchanged. Malaysia is a multicultural country with various religions and cultural beliefs, so it is known as the best place to “experience the charm of Asia”. Coming to Malaysia, tourists can learn about three major Asian civilizations, namely Malay, Chinese, and Indian cultures. Moreover, the pace of life in this country is slow and people here live a life of leisure and ease. The unique landscape and the summer-like weather all the year around make Malaysia a tourist attraction, luring an average greater than tens of millions of global tourists every year.
While forecast evaluation is the primary objective of this work, it is fascinating to observe how well the GARCH (1,1), GJRGARCH (1,1), and EGARCH (1,1) models read statistical measures of tourism demand volatility and how news shocks influence key source tourist arrivals separately. The GARCH (1,1) model is symmetric, so it cannot accurately capture leverage or asymmetric effects. The essential ϕ of the EGARCH (1,1) model and γ of the GJRGARCH (1,1) model are significant at p < 0.01 or p < 0.1, demonstrating that asymmetric or leverage effects respond to shocks of tourist arrival news. In the EGARCH (1,1) model, the ϕ values of the UK and China are less than zero, indicating that the tourism demand volatility is affected by a negative shock of “bad news”. Meanwhile, only the γ value of Germany is significant and greater than zero, suggesting that the GJRGARCH (1, 1) model has leverage effects on tourists to Malaysia from Germany.
Therefore, as for these many models, the magnitude and duration of unstable oscillations in tourism vary depending on the type of shocks the destination experienced. As demonstrated by the preceding examples, the GJRGARCH (1,1) model forecasted strong positive shocks for Germany. According to the EGARCH (1,1) model, powerful negative shocks increase the volatility of tourist arrivals in Malaysia more than positive shocks of the same magnitude, but only within the selected series.
Moreover, asymmetries and symmetries in the impacts on visitors are the topic of models, such as GARCH (1,1), EGARCH (1,1), and GJRGARCH (1,1), based on the study of the preceding models. Consequently, as a specific illustration,
Figure 4 depicts the estimated conditional variance under the impacts of news shocks up to December 2014 for four analyzed series: China, Japan, the USA, and Australia. This is because news shocks have direct and indirect effects on tourism demand. Current events may influence the desire for tourism. The graph illustrates that the four series experienced the similar period of SARS spread volatility in 2003. Due to the tremors of a 7.0 magnitude earthquake that struck the main island in May and an 8.3 magnitude earthquake that struck in September 2003, Japan became very volatile in 2003. In 2001, the USA’s response to the shocks of September 11th was comparatively volatile. Other volatile periods following them for Australia are the 2000 summer Olympics ending with a big party in October 2000, the flooding crisis in February 2011, and lightning strikes that ignited fires in January 2014. However, other periods reacted in a less volatile manner to shocks [
144,
145,
146,
147,
148,
149,
150,
151,
152]. Therefore, whether an internal or external news shock occurs in a country/region may influence on the inbound or outgoing tourism of tourists.
The next step is to construct the exponential smoothing models. When computing the exponential smoothing values for every interval, the weighted average of the current period’s observations and the historical exponential smoothing values serve as the basis for computation. Depending on
Table 1 and
Table 2, using the AIC and BIC, the best, most distinct ETS-ES models derived for each series with incoming tourist arrivals to Malaysia were determined via EViews 11 in
Table 9. As demonstrated in
Table 9, the smoothing procedure can be applied outside the context, including its in-sample data, to generate out-of-sample smoothing forecasts of the array. The higher value of parameter
α indicates that the model focuses on even the most recent historical observations. In comparison, the lower value implies that the model considers much of the past while conducting a forecast.
β regulates the dampening degree at which the effect of a pattern shift declines. The method is compatible with patterns that vary in two different ways (additive and multiplicative) and focuses on whether the pattern is linear or exponential. Similar methods were utilized to reduce the propensity to represent it explicitly, additively or multiplicatively for a linear or exponential decay impact. China, the Philippines, Vietnam, and Saudi Arabia are examples of series where the slope of a series has stayed strikingly consistent across time. The models from China, Thailand, and Brunei have used a damping coefficient,
ϕ, to manage the decay rate.
γ restricts the effect on the seasonal factor. The values of
γ are very large, demonstrating that the series is greatly influenced by seasonality. Eleven series’ ETS-ES models (China, India, South Korea, Japan, the Philippines, Taiwan (China), Australia, the UK, the USA, Germany and Saudi Arabia) for international tourist arrivals are subject to seasonality, with the UK having the most significant seasonality. Singapore, Indonesia, Thailand, Brunei, Vietnam, and France have not developed any seasonality models.
6. Empirical Results of Out-of-Sample Volatility Forecasting Accuracy
Before integrating all models of volatility, this research must determine the best single model based on several evaluation criteria. Taylor (2004) stated in [
23,
24] that the GJRGARCH (1,1) estimation outperforms the GARCH estimation in data processing. Here, our benchmark model of choice would be GJRGARCH for the further data processing. Importantly, Theil-U statistics is specified as the ratios of the MAE, MSE, RMSE, and MAAPE inside GJRGARCH forecasting to the MAE, MSE, RMSE, and MAAPE within our forecasting models. To determine which model is the most accurate, we calculated the values of mean Theil-U statistics for the whole series in the final column of
Table 10,
Table 11,
Table 12,
Table 13,
Table 14 and
Table 15. The value of U-statistics just below one indicates vastly superior performance with a comparison to the GJRGARCH. In other words, the lower the value, the better the model [
23,
24,
153].
A total of nine different SARIMA-GARCH and SARIMA-ES family models were examined for this study, and the results are listed in
Table 10. First, to determine whether the results of this study can adequately address the questions posed by the objectives, we need to select the best model to combine from each relevant family. Therefore, these nine models were estimated using four evaluation criteria (MAE, MSE, RMSE, and MAAPE) for each of the 17 series. After that, we determined the best single model to combine by computing the mean rank of all mean Theil-U values under evaluation criteria between two-family methods. STES-AE (0.854), ETS-ES (0.887), and EGARCH (0.903) are the models that have the lowest values in MAE; the best models in terms of both MSE and RMSE are STES-E (0.742, 0.853), ETS-ES (0.912, 0.860), and GJRGARCH (1.000, 1.000), separately; MAAPE with the fewest values are EGARCH (0.926), STES-ESE (0.958), and ETS-ES (0.969). It is regarded as fair to use the mean rank to determine which model is the best because the best model may not always be the same for each evaluation criterion. Consequently, based on the final mean rank in
Table 10, the best STES model is STES-E, followed by the ETS-ES model from the ES family. Similarly, GJRGARCH is a superior model within the GARCH family, but it ranks behind the other two. The results confirm unequivocally the consistency discovered by Coshall (2009) in [
9], where exponential smoothing combining models outperform volatility models. Therefore, STES-E, ETS-ES, and GJRGARCH were utilized to test if the forecast combining methods outperform the single forecasts methods during the process of combining.
To determine whether our suggested novel methods can increase the accuracy of tourism demand volatility forecasting in Malaysia, we presented multiple evaluation criteria (MAE, MSE, RMSE, MAAPE, R
2, MCS test, and DM test). The highlighted values indicate the optimal model. In the meantime, the prior methods are used independently to produce monthly estimates for the out-of-sample absolute forecasting error and squared forecasting error in the combining phase for 17 tourist arrivals time series. Consequently, the data from January 2015 to December 2019 were used to illustrate the forecasting performance of several methods in this subsection. The forecast was generated by combining the results of SA, MV, and ST (ST1 (sign of residuals), ST2 (size of residuals), ST3 (absolute (residuals)), ST4 (sign of residuals + size of residuals), ST5 (sign of residuals + absolute (residuals)), and ST6 (size of residuals + absolute (residuals))), spanning
Table 11,
Table 12,
Table 13,
Table 14,
Table 15,
Table 16,
Table 17,
Table 18 and
Table 19. Overall, the top five forecast combining models are denoted in bold in the last column for each respective series.
The comparison of single models and forecast combining methods in
Table 11,
Table 12,
Table 13,
Table 14,
Table 15,
Table 16,
Table 17,
Table 18 and
Table 19 reveals that the average forecasting performance of ES family models (M1, M2) is superior to that of GARCH family models (M3, M4, M5) for forecasting the Malaysian tourism demand volatility. The forecasting performance of STES-E is marginally superior to that of ETS-ES. At the same time, the average forecasting performance of single models overall is lower than the performance of forecast combining methods based on MAE, MSE, RMSE, MAAPE, R
2, MCS test, and DM test. ETS-ES and EGARCH offer superior forecasting performance compared to MAAPE. In addition, ES family methods have improved forecasting performance in the R
2 and DM tests, particularly STES-E. These results indicate that the forecasting performance of the best single model can surpass that of forecast combining methods. However, the performance of the poorest single model cannot. In other words, forecast combining methods are not necessarily the best models for forecasting tourism demand volatility.
The rank of mean Theil-U results in the SA combining method in MAE, MSE, RMSE, MAAPE, R
2, MCS test, and DM tests indicate that all combining models outperform the worst single model. While SA is acknowledged in the financial sector, the results indicate that the SA forecast combining method has the smallest sums among the top five forecast combining models in each series from
Table 11,
Table 12,
Table 13,
Table 14,
Table 15,
Table 16,
Table 17,
Table 18 and
Table 19, except for MAE. The superiority of the forecast combining methods under the SA combining method is barely discernible in comparison to the other models examined in this study. This demonstrates that the SA combining method is not optimal for creating the combining models in the tourism demand volatility forecasting of this study. In the meantime, the combining weights for the minimum variance (MV) forecast combining method are computed, and the preceding performance of the forecast combining methods is considered throughout Equation (9). Excel’s “Solver” function can provide ideal weights for the minimum variance equation in various combining models to produce the best values across all evaluative criteria. All forecasting evaluation criteria indicate that MV’s average forecasting performance is substantially inferior to other forecast combining methods. However, it is superior to single models. In general, the SA combining method is not more prominent than other combining methods in the 17 series. Similarly, MV is still not the optimal method for forecasting the Malaysia’s tourism demand volatility. The outcomes transcend the conclusion reached by Shen et al. (2011) in [
30], that the minimum variance forecast combining method was the most effective in combining research. The results of the mean Theil-U indicate that, except for the STES-E and ETS-ES models, forecast combining does not consistently outperform the best single forecast. The combining outcomes of SA and MV are coincidental with the results of Andrawis et al. (2011) in [
154], Jun et al. (2018) in [
155], Winkler and Clemen (1992) in [
156], and Wong et al. (2007) in [
27]. This is because the weight values assigned to one of the other models affect the forecast combining results. This appears to be another reason why forecast combining does not routinely improve forecasting performance over single forecasts.
The empirical results are currently being reconsidered from a new angle. From
Table 11,
Table 12,
Table 13,
Table 14,
Table 15,
Table 16,
Table 17,
Table 18 and
Table 19, it is evident that combining estimates from multiple distinct models tends to prevent the worst forecasts. Clearly, the smooth transition (ST) combining method produces favorable results for forecasting the inbound tourism demand volatility in 17 source markets in Malaysia. Similarly, the ST combining method must utilize the “Solver” to automatically determine the appropriate weight for the transition variable in Equation (11) to obtain the best combining method based on all evaluation criteria. Therefore, whether under ST1, ST2, ST3, ST4, ST5, or ST6, there is a top five combining methods cluster in different series to be obtained via the MAE, MSE, RMSE, MAAPE, R
2, MCS test, and DM test. Therefore, the average performance of the ST method exceeds that of the other methods. Significantly, based on the rank value of mean Theil-U across single models, the top five combining methods are all included in distinct series of the ST combining method. The top five forecast combining methods are denoted with a bold underline. This demonstrates that the relative forecasting output by the combining methods versus the single models vary by countries/regions of origin. In addition, the results reveal that, among 16 forecast combining methods in each of main three forecast combining methods, the average performance of STES-E_GJRGARCH exceeds that of ETS-ES_GJRGARCH across all evaluation criteria. The MCS and DM tests significantly confirm the results of the evaluation criteria. Among them, the best models are the M11 and M15, followed by M13, M17, and M21. They are all STES-E_GJRGARCH methods in ST. Importantly, their average performance of forecast combining surpasses that of the best single forecast model. According to the literature, GJRGARCH is the best model, while STES is the most novel method. Thus, the performance of ST2 and ST4 with STES-E_GJR is superior to that of other ST combining methods based on various evaluation criteria. This is because ST accounts for all optimization transition factors, including sign and size. This method permits the combining to adapt over time to the relative supremacy of the single models. In other words, by matching the optimal parameters, ST can reduce the error in forecasting of the combining models.
For the series included in this study, it is evident that combining ST forecasts with SA and MV improves forecasting accuracy. Therefore, in many instances, the ST combining method is a worthwhile procedure for the forecast combining of tourism demand volatility. In addition, the study indicated that forecast combining does not always outperform the best single model but provides more accurate forecasting than the worst single model, depending on the source markets evaluated and the combining methods utilized.
As represented in the forecasting methods subsection, we employed the MCS test of Hansen et al. (2011) in [
130]. This was conducted to determine if the prior statistical results are statistically accurate. The objective here is to increase the predictability of forecast combining while optimizing the post-processing of forecast combining methods. The R software provides the “MCS test package” to evaluate the significance of combining methods and produce forecasts with a high degree of precision. The absolute squared error was utilized to assess the effectiveness of single and forecast combining methods. If the method is superior to other methods, 1 is used to indicate this; otherwise, 0. They were used to calculate the total counts of the 17 series. We used the counts to determine if the MCS test findings support the prior MAE, MSE, RMSE, MAAPE, R
2, and Theil-U results.
The different entries in each column of
Table 16 and
Table 17 show the number of methods that adhered to the SSM during the MCS test procedure, categorized by model. Using squared forecast error and absolute forecast error, we find that the SSM becomes very uniform in terms of its models’ shapes. As measured by MCS, it can be seen that the performance of the combining models is superior to that of the single models. Overall, the MCS test suggests that ETS-ES and STES-E are the most accurate single forecasts, even surpassing other forecast combining methods. This again demonstrates that the best single forecasts methods outperform the weakest forecast combining methods. However, the GARCH family models have the weakest forecasting performance, followed by the SA and MV forecast combining methods. Significantly, ST performed in a fiercely competitive manner, with STES-E yielding the best results for all methods. Consequently, based on the results of squared forecast error and absolute forecast error, the methods with STES-E are the least excluded models among those utilized in this research. Simultaneously, the combining methods with the greatest number of counts continue to employ the ST combining methods, namely STES-E_GJRGARCH (M11, M13, M15, M17, and M21) with 14 counts and squared forecast error. These outcomes support the primary MSE and RMSE evaluation criteria outcomes. ETS-ES_GJRGARCH (M10, M18, and M20) and STES-E_GJRGARCH (M13, M15, and M21) with the most, namely ten, counts utilize the ST combining method employing absolute forecast error. The SA and MV combining methods yield the poorest outcomes overall. Consequently, the ST forecast combining method is preferable, which is consistent with the findings of the aforementioned criteria.
Diebold and Mariano (2002) in [
133] used the loss-differential test to test the null hypothesis that two forecasts possess identical forecasting accuracy. The DM test was performed by building the t statistics with a simple regression of the loss function based on a constant using a Newey–West estimator for MAE and RMSE. A negative sign for the t-statistic associated with the DM test shows that the forecast error connected with the competitive series forecast is reduced, whereas a positive sign implies the opposite. Therefore, when comparing the two models based on t statistics, we employed “1” to indicate that the benchmark model makes more accurate forecasts than the other volatility model in each comparison for every series, and “0” to indicate that the two models have the same forecasting accuracy in this study. After calculating the results of the comparison between the two models in 17 series, it is determined that the model with the highest number of “1” is the best model for forecasting Malaysian tourism demand volatility. This further verifies whether the joint forecast models can outperform the single models.
In addition,
Table 18 and
Table 19 display the evaluated values of the DM test for the out-of-sample performance of a total of 21 methods. These tables compared methods’ differentials from MAE and RMSE in 17 series using the “row versus column” format. The null hypothesis was tested without changes in forecasting accuracy. Most DM test results reject the null hypothesis that the forecasting error of the benchmark modes are equivalent to either of the comparison models. The comparison’s results are separated into two portions for analysis. First, compare the forecast combining methods to the single models. The MAE results indicate that the forecast combining methods, particularly the ST forecast combining method, produces statistically superior results compared to methods 3 and 4. Similarly, in terms of RMSE, ST achieves superior statistics when comparing forecast combining methods using SARIMA-GARCH family models as benchmarks. In contrast to ES family models (ETS-ES and STES), however, forecast combining methods produce fewer statistics for MAE and RMSE. Second, when compared to the SA and MV forecast combining methods, ST produces comparatively more statistics overall, when ST is compared as the standard to method 9. Nonetheless, when comparing ST to its own family methods, several results do not reject the null hypothesis. DM test results are consistent with earlier criteria (MAE, MSE, RMSE, and MAAPE).
All aforementioned findings indicate that the forecasting performance of ES family models exceeds that of GARCH family models. In the meanwhile, the forecast combining does not always outperform the best single forecasts, but nearly outperforms the worst single forecast. Among the forecast combining models that outperform single models, ST is the best forecast combining method for forecasting Malaysian tourism demand volatility. This indicates that forecast combining can greatly reduce the probability of an incorrect forecast. In many real-world settings, it follows that forecast combining is superior to single forecasts.
7. Conclusions
This is one of the few studies to incorporate modeling volatility forecast combining within the context of tourism volatility and to primarily evaluate the forecasting potential of this class of model. In this work, the empirical results of single and combining methods for forecasting tourism demand volatility are explored further. The primary purpose is to determine whether forecast combining outperforms single forecasts and whether forecast combining can improve forecasting accuracy when utilizing the ST forecast combining method. Single forecasts, such as ETS-ES, STES-E, GARCH, EGARCH, and GJRGARCH, were utilized to investigate this phenomenon. Moreover, if two forecasts offer overlapping information, forecast merging is unlikely to outperform the forecasts offered by each model individually. Forecast combining will only be effective when forecast error correlations between single forecasts are minimal. Therefore, we utilized SA, MV, and a recently proposed ST for combining volatility forecasts.
This study reveals that, among the GARCH-type family models, the GJRGARCH model is superior. In out-of-sample tourism demand volatility forecasting, STES fared best among the single models, followed by ETS-ES. Intriguingly, forecast combining methods do not always outperform the best single model, but they do outperform the worst single model. The ST combining method surpasses the SA and MV methods. It is an effective method for making accurate forecasts despite the tourism demand volatility. This is because ST accounts for the necessary optimization transition factors, such as sign and size. This method permits the combination to adjust over time to the relative superiority of the different methods by modeling the combining weight as a logistic function of one or more transition factors. In other words, once ST matches the most relevant parameters to discover the shortest forecasting error, this can lower the forecasting error of the combined models, resulting in the best model. ST has been discovered to be the best method for combining volatility forecasts across all forecast combining models. Consequently, by evaluating the performance of various volatility forecast combining methods, we provide support to the assertion that forecasts are more accurate and dependable when employing the ST forecast combining method.
Significantly, the MCS test and DM test increase the confidence of the aforementioned forecasting results, making it necessary to execute these tests by combining single models. This is a novel solution to the problem of determining the “best” forecasting method among volatility forecast combining methods, based on the MCS, employing a out-of-sample evaluation beneath a loss function proposed in this study. It is straightforward to evaluate whether the forecast combining outperforms the single forecasts by using the MCS test to the ensemble of models, with the forecast combining as an additional model. In the meantime, DM loss-differential forecasting accuracy testing examines the particulars and distinctions between two competing series. Therefore, it can bolster the competitive comparison between the two forecasting models evaluated in this article.
In terms of tourist arrivals assessments, substantial volatility models of 17 tourist arrivals into Malaysia have been built, which are likely to be of greater actual value. The conditional variance and tourist arrivals over time revealed the volatility associated with negative shocks, such as the SARS outbreak in 2003 and the September 11th, 2001 tragedy. Both of these periods influenced the influx of tourists from many countries/regions into Malaysia. Additionally, periods of volatility were typically brief. The models demonstrated that the magnitude and duration of tourism demand volatility vary depending on the nature and location of shocks. Negative shocks had a greater influence on tourism demand volatility at the sites investigated than positive shocks of equal magnitude. The tourism product might not be as fragile as is generally believed. Integrated with an exponential smoothing time series model, the advantage of modeling volatility is revealed when forecasting the tourism demand volatility.
The findings of this study have significant implications for the tourism industry and government agencies. First, for tourism-related businesses to minimize losses caused by an imbalance between the supply and demand for tourism goods and services, accurate forecasts of tourism demand volatility are essential. This is related to effective management and sound decisions considering investments in different tourism facilities and project expansion. When faced with several sets of forecasts generated by diverse models, certain business executives may become overwhelmed. Their most reliable option is based on combining the best single forecasts, but they instead choose those generated from the weakest single model. If forecasting swings in tourism demand can be improved by integrating the best single and forecast combining, then tourism policy decision-makers in both the public and private sectors will certainly value this. Based on the general extent and independent resource marketplaces, applicable administrative tourist rules and competitive business strategies of destination marketing agencies will aid in forecasting the expansion and trends of tourism volatility.
This study makes a substantial contribution to either specific or tourism volatility forecast combining studies by offering findings on the productivity of forecast combining. In the future, it would be worthwhile to examine other transition variables, like macroeconomic variables. It would also be interesting to see the outcomes of combining ST with other data and forecasting methods. As ST permits the combining weights to adjust gradually and smoothly over time as relevant transition variables adapt, we plan to examine its performance over a somewhat longer time series in future research. Another extension of our investigation would be to explore an ST that combines more than two single models. In addition, significant research into advanced and specialized volatility forecast combining methods, as well as newer linear or non-linear combining methods, is forecasted. This should also be assessed to determine if these methods provide a more accurate combination of tourism demand volatility forecasts than those offered in the tourism demand volatility forecasting sector.









{kind=link}
{kind=link}
{kind=link}
{kind=link}