

Capturing the Complexity of COVID-19 Research: Trend Analysis in the First Two Years of the Pandemic Using a Bayesian Probabilistic Model and Machine Learning Tools

 , ,
, ,  and
and
Abstract
:1. Introduction
- Question 1 (Q1): What were the key publishing sources and major contributions to COVID-19 research?
- Question 2 (Q2): What are the major research topics in this field?
- Question 3 (Q3): How do these research topics evolve with time?
- Question 4 (Q4): What are the distributions of these topics across countries and journals?
2. Materials and Methods
2.1. Data Collection
2.2. Data Preprocessing
2.3. Identifying Research Topics
2.3.1. Creation of LDA Model
2.3.2. Labeling Topics
2.4. Quantitative Indices Used to Analyze the Trend of Topics
3. Results
3.1. Search Results
3.2. LDA Modeling and Topics
3.2.1. Trend of Topics
3.2.2. Topic Distributions of Various Journals
3.2.3. Topic Distribution over Country
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- WHO Announces COVID-19 Outbreak a Pandemic; Word Health Organization-Regional Office for Europe: Copenhagen, Denmark, 2020; Available online: http://www.euro.who.int/en/health-topics/health-emergencies/coronavirus-COVIDcovid-19/news/news/2020/3/who-announces-COVID-19-outbreak-a-pandemic (accessed on 1 June 2020).
- Älgå, A.; Eriksson, O.; Nordberg, M. Analysis of Scientific Publications during the Early Phase of the COVID-19 Pandemic: Topic Modeling Study. J. Med. Internet Res. 2020, 22, e21559. [Google Scholar] [CrossRef] [PubMed]
- Larsen, P.O.; von Ins, M. The rate of growth in scientific publication and the decline in coverage provided by science citation index. Scientometrics 2010, 84, 575–603. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Guan, B.; Su, T.; Liu, W.; Chen, M.; Waleed, K.B.; Zhu, Z. Impact of cardiovascular disease and cardiac injury on in-hospital mortality in patients with COVID-19: A systematic review and meta-analysis. Heart 2020, 106, 1142–1147. [Google Scholar] [CrossRef] [PubMed]
- Parasa, S.; Desai, M.; Chandrasekar, V.T.; Patel, H.K.; Kennedy, K.F.; Roesch, T.; Sharma, P. Prevalence of gastrointestinal symptoms and fecal viral shedding in patients with coronavirus disease 2019: A systematic review and meta-analysis. JAMA Netw. Open. 2020, 3, e2011335. [Google Scholar] [CrossRef]
- Cortegiani, A.; Ingoglia, G.; Ippolito, M.; Giarratano, A.; Einav, S. A systematic review on the efficacy and safety of chloroquine for the treatment of COVID-19. J. Crit. Care 2020, 57, 279–283. [Google Scholar] [CrossRef]
- Aristovnik, A.; Ravšelj, D.; Umek, L. A bibliometric analysis of COVID-19 across science and social science research landscape. Sustainability 2020, 12, 9132. [Google Scholar] [CrossRef]
- Haghani, M.; Bliemer, M.C.; Goerlandt, F.; Li, J. The scientific literature on Coronaviruses, COVID-19 and its associated safety-related research dimensions: A scientometric analysis and scoping review. Saf Sci. 2020, 129, 104806. [Google Scholar] [CrossRef]
- Doanvo, A.; Qian, X.; Ramjee, D.; Piontkivska, H.; Desai, A.; Majumder, M. Machine learning maps research needs in COVID-19 literature. Patterns 2020, 1, 100123. [Google Scholar] [CrossRef]
- Mao, X.; Guo, L.; Fu, P.; Xiang, C. The status and trends of coronavirus research: A global bibliometric and visualized analysis. Medicine 2020, 99, e20137. [Google Scholar] [CrossRef]
- Aria, M.; Cuccurullo, C. Bibliometrix: An R-toolfor comprehensive science mapping analysis. J. Informetr. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Cobo, M.J.; López-Herrera, A.G.; Herrera-Viedma, E.; Herrera, F. Science mapping software tools: Review, analysis, and cooperative study among tools. J. Assoc. Inf. Sci. Technol. 2011, 62, 1382–1402. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing. 2019. Available online: https://www.r-project.org (accessed on 1 May 2021).
- Vijayarani, S.; Ilamathi, M.J.; Nithya, M. Preprocessing techniques for text mining-an overview. Int. J. Comput. Sci. Commun. Netw. 2015, 5, 7–16. [Google Scholar]
- De La Hoz-M, J.; Fernández-Gómez, M.J.; Mendes, S. LDAShiny: An R package for exploratory review of scientific literature based on a Bayesian probabilistic model and machine learning tools. Mathematics 2021, 9, 1671. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn Res. 2003, 3, 93–1022. [Google Scholar]
- Hornik, K.; Grün, B. Topicmodels: An R package for fitting topic models. J. Stat. Softw. 2011, 40, 1–30. [Google Scholar] [CrossRef]
- Syed, S.; Borit, M.; Spruit, M. Using Machine Learning to Uncover Latent Research Topics in Fishery Models. Rev. Fish. Sci. Aquac. 2018, 26, 319–336. [Google Scholar] [CrossRef]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 6, 721–741. [Google Scholar] [CrossRef]
- Blei, D.M.; Lafferty, J.D. A correlated topic model of science. Ann. Appl. Stat. 2007, 1, 17–35. [Google Scholar] [CrossRef]
- Roder, M.; Both, A.; Hinneburg, A. Exploring the space of topic coherence measures. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, New York, NY, USA, 31 January–6 February 2015; pp. 399–408. [Google Scholar]
- Porteous, I.; Newman, D.; Ihler, A.; Asuncion, A.; Smyth, P.; Welling, M. Fast Collapsed Gibbs Sampling for Latent Dirichlet Allocation. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’08), Las Vegas, NV, USA, 24–27 August 2008; ACM Press: New York, NY, USA, 2008; pp. 569–577. [Google Scholar] [CrossRef]
- Griffths, T.L.; Steyvers, M. Finding scientific topics. Proc. Natl. Acad. Sci. USA 2004, 101 (Suppl. S1), 5228–5235. [Google Scholar] [CrossRef]
- Chang, J.; Gerrish, S.; Wang, C.; Boyd-Graber, J.L.; Blei, D.M. Reading tea leaves: How humans interpret topic models. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2009; pp. 288–296. [Google Scholar]
- Xiong, H.; Cheng, Y.; Zhao, W.; Liu, J. Analyzing scientific research topics in manufacturing field using a topic model. Comput. Ind. Eng. 2019, 135, 333–347. [Google Scholar] [CrossRef]
- Nature Index. Available online: https://www.natureindex.com/annual-tables/2021/country/all/all (accessed on 19 March 2022).
- Wilder-Smith, A.; Osman, S. Public health emergencies of international concern: A historic overview. J. Travel Med. 2020, 27, taaa227. [Google Scholar] [CrossRef] [PubMed]
- Greenberg, M.E.; Lai, M.H.; Hartel, G.F.; Wichems, C.H.; Gittleson, C.; Bennet, J.; Basser, R.L. Response to a monovalent 2009 influenza A (H1N1) vaccine. New Eng. J. Med. 2009, 361, 2405–2413. [Google Scholar] [CrossRef] [PubMed]
- Borba, M.G.S.; Val, F.F.A.; Sampaio, V.S.; Alexandre, M.A.A.; Melo, G.C.; Brito, M.; Lacerda, M.V.G. Effect of high vs low doses of chloroquine diphosphate as adjunctive therapy for patients hospitalized with severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) infection: A randomized clinical trial. JAMA Netw. Open 2020, 3, e208857. [Google Scholar] [CrossRef] [PubMed]
- Horbach, S.P. Pandemic publishing: Medical journals strongly speed up their publication process for COVID-19. Quant. Sci. Stud. 2020, 1, 1056–1067. [Google Scholar] [CrossRef]
- Dewan, H.; Nishan, M.; Sainudeen, S.; Sanskriti Jha, K.; Mahobia, A.; Tiwari, R.V.C. COVID 19 Scoping: A Systematic Review and Meta-Analyisis. J. Pham. Bioallied Sci. 2021, 13, S938. [Google Scholar] [CrossRef]
- Darsono, D.; Rohmana, J.A.; Busro, B. Against COVID-19 Pandemic: Bibliometric Assessment of World Scholars’ International Publications related to COVID-19. J. Komun. Ikat. Sarj. Komun. Indones. 2020, 5, 75–89. [Google Scholar] [CrossRef]
- Funding Opportunities Specific to COVID-19. National Institutes of Health. U.S. Department of Health and Human Services. Available online: https://grants.nih.gov/grants/guide/COVID-Related.cfm (accessed on 10 April 2022).
- Liu, Q.; Zheng, Z.; Zheng, J.; Chen, Q.; Liu, G.; Chen, S.; Ming, W.K. Health communication through news media during the early stage of the COVID-19 outbreak in China: Digital topic modeling approach. J. Med. Internet Res. 2020, 22, e19118. [Google Scholar] [CrossRef]
- Abd-Alrazaq, A.; Alhuwail, D.; Househ, M.; Hamdi, M.; Shah, Z. Top concerns of tweeters during the COVID-19 pandemic: Infoveillance study. J. Med. Internet Res. 2020, 22, e19016. [Google Scholar] [CrossRef]
- Han, X.; Wang, J.; Zhang, M.; Wang, X. Using social media to mine and analyze public opinion related to COVID-19 in China. Int. J. Environ. Res. Public Health 2020, 17, 2788. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Result | |
|---|---|---|
| Main information about data | Timespan | February 2020: January 2022 |
| Sources | 7040 | |
| Documents | 126,334 | |
| Average years from publication | 1.46 | |
| Document contents | Keywords plus (id) | 13,001 |
| Author’s keywords (de) | 112,867 | |
| Authors | Authors | 440,259 |
| Author appearances | 960,863 | |
| Authors of single-authored Documents | 5374 | |
| Authors of multi-authored Documents | 434,885 | |
| Authors collaboration | Single-authored documents | 6698 |
| Documents per author | 0.287 | |
| Authors per document | 3.48 | |
| Co-authors per documents | 7.61 | |
| Collaboration index | 3.64 |
| Month | Year | Number | Accumulated |
|---|---|---|---|
| February | 2020 | 101 | 101 |
| March | 2020 | 558 | 659 |
| April | 2020 | 2082 | 2741 |
| May | 2020 | 3476 | 6217 |
| June | 2020 | 4255 | 10,472 |
| July | 2020 | 4685 | 15,157 |
| August | 2020 | 4307 | 19,464 |
| September | 2020 | 4819 | 24,283 |
| October | 2020 | 5193 | 29,476 |
| November | 2020 | 4765 | 34,241 |
| December | 2020 | 4718 | 38,959 |
| January | 2021 | 17,640 | 56,599 |
| February | 2021 | 6345 | 62,944 |
| March | 2021 | 5984 | 68,928 |
| April | 2021 | 5421 | 74,349 |
| May | 2021 | 5578 | 79,927 |
| June | 2021 | 5803 | 85,730 |
| July | 2021 | 6121 | 91,851 |
| August | 2021 | 5529 | 97,380 |
| September | 2021 | 5736 | 103,116 |
| October | 2021 | 5880 | 108,996 |
| November | 2021 | 5546 | 114,542 |
| December | 2021 | 5593 | 120,135 |
| January | 2022 | 6199 | 126,334 |
| Source | Abbreviation | n | (%) |
|---|---|---|---|
| International Journal of Environmental Research and Public Health | Int. J. Environ. Res. Public Health | 3304 | 2.62 |
| PLoS ONE | PLoS ONE | 2057 | 1.63 |
| Scientific Reports | Sci. Rep. | 1348 | 1.07 |
| Frontiers in Psychology | Front. Psychol. | 997 | 0.79 |
| BMJ Open | BMJ Open | 923 | 0.73 |
| Journal of Clinical Medicine | J. Clin. Med. | 900 | 0.71 |
| Journal of Medical Virology | J. Med. Virol. | 865 | 0.68 |
| Cureus | Cureus | 817 | 0.65 |
| Frontiers in Public Health | Front. Public Health | 813 | 0.64 |
| International Journal of Infectious Diseases | Int. J. Infect. Dis. | 786 | 0.62 |
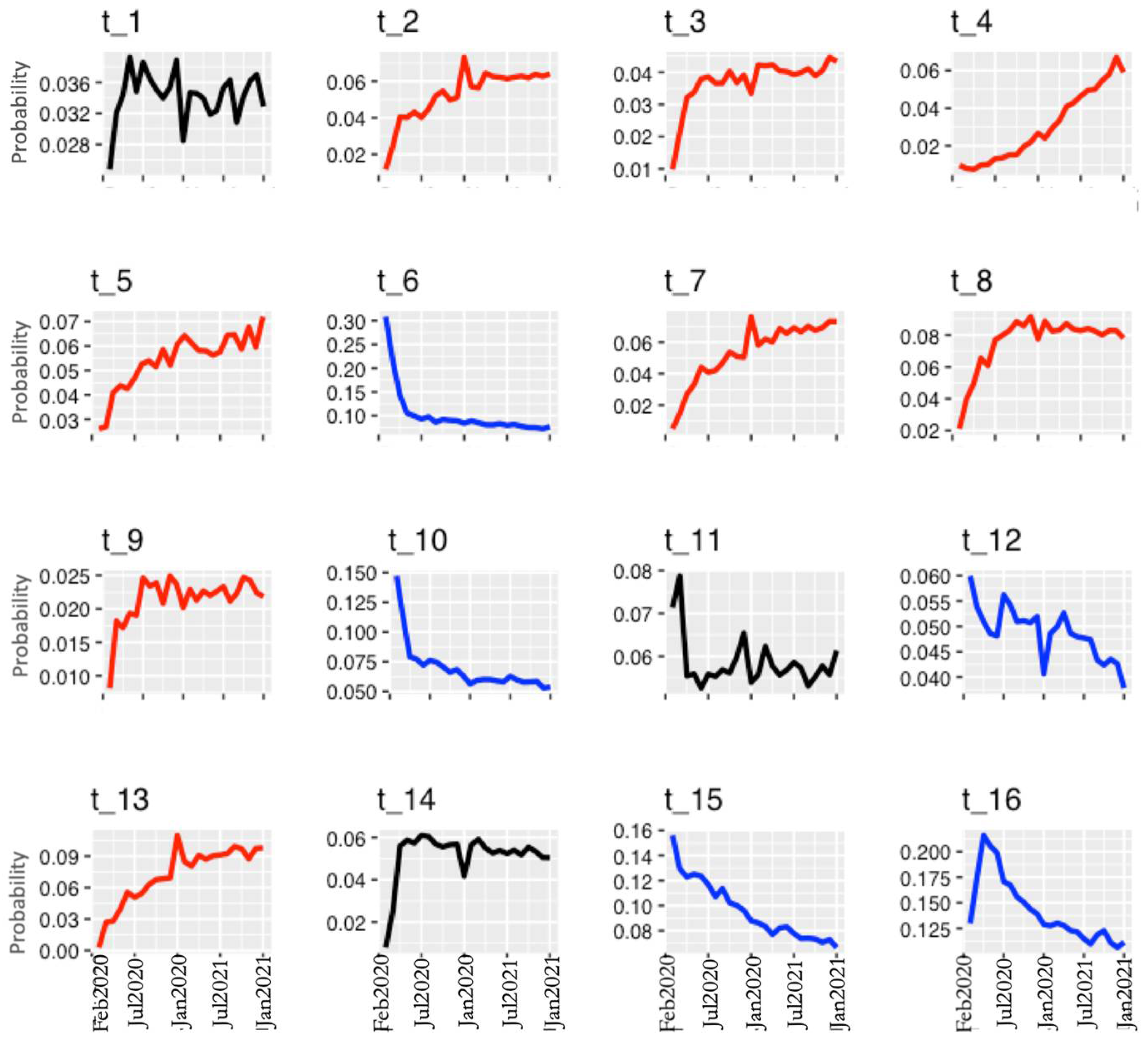
| Topic | Label | Top_terms | Articles n (%) |
|---|---|---|---|
| t_1 | Therapeutics | treatment, trial, clinic, group, therapi, control, drug, effect, treat, clinic_trial, dose, efficaci, receiv, improv, random | 3671 (2.91) |
| t_2 | Prevention | survei, worker, particip, health, risk, healthcar, associ, prevent, cross, pandem, section, cross_section, factor, behavior, protect | 6380 (5.05) |
| t_3 | Telemedicine | servic, women, pandem, clinic, provid, telemedicin, visit, telehealth, health, pregnant, access, deliveri, person, consult, medic | 4857 (3.84) |
| t_4 | Vaccine inmunity | vaccin, antibodi, immun, respons, dose, igg, neutral, infect, anti, effect, hesit, mrna, individu, receiv, level | 4146 (3.28) |
| t_5 | Machine learning | model, base, predict, method, data, perform, propos, mask, develop, learn, imag, system, valid, time, detect | 6781 (5.37) |
| t_6 | Epidemiology | case, infect, countri, data, rate, number, transmiss, model, death, popul, spread, measur, epidem, diseas, outbreak | 10,784 (8.54) |
| t_7 | Academic parameters | student, pandem, educ, nurs, onlin, learn, medic, experi, social, train, school, particip, resid, program, media | 7693 (6.09) |
| t_8 | Risk factors and morbidity and mortality | mortal, risk, associ, sever, outcom, diseas, hospit, icu, higher, admiss, factor, death, cohort, group, clinic | 10,665 (8.44) |
| t_9 | Information synthesis methods | review, systemat, search, analysi, systemat_review, includ, meta, literatur, report, meta_analysi, databas, evid, data, pubm, identifi | 1955 (1.55) |
| t_10 | COVID-19 pathology complications | symptom, case, diseas, sever, clinic, report, infect, ct, children, present, group, find, pneumonia, includ, acut | 7655 (6.06) |
| t_11 | Pharmacological and therapeutic target | protein, drug, viral, human, viru, cell, target, bind, ac, spike, infect, potenti, activ, genom, variant | 7467 (5.91) |
| t_12 | Diagnostic test | test, posit, detect, pcr, sampl, infect, rt, neg, rt_pcr, assai, sensit, viral, diagnost, respiratori, swab | 5635 (4.46) |
| t_13 | Mental health | pandem, health, mental, anxieti, mental_health, stress, depress, psycholog, symptom, associ, social, impact, level, particip, increas | 12,236 (9.69) |
| t_14 | Repercusion health services | pandem, period, cancer, surgeri, compar, lockdown, impact, increas, emerg, time, surgic, decreas, number, chang, march | 6412 (5.08) |
| t_15 | Etiopathogenesis | infect, diseas, sever, respiratori, syndrom, acut, cell, acut_respiratori, immun, respiratori_syndrom, sever_acut, respons, system, inflammatori, associ | 12,080 (9.56) |
| t_16 | Political and health factors | health, pandem, public, system, manag, challeng, respons, global, commun, diseas, develop, emerg, public_health, provid, impact | 17,917 (14.18) |
| Country | t_1 | t_2 | t_3 | t_4 | t_5 | t_6 | t_7 | t_8 | t_9 | t_10 | t_11 | t_12 | t_13 | t_14 | t_15 | t_16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| USA | ||||||||||||||||
| China | ||||||||||||||||
| Italy | ||||||||||||||||
| United Kingdom | ||||||||||||||||
| India | ||||||||||||||||
| Spain | ||||||||||||||||
| Canada | ||||||||||||||||
| Germany | ||||||||||||||||
| Iran | ||||||||||||||||
| Turkey | ||||||||||||||||
| Brazil | ||||||||||||||||
| Australia | ||||||||||||||||
| France | ||||||||||||||||
| Japan | ||||||||||||||||
| South Korea | ||||||||||||||||
| Saudi Arabia | ||||||||||||||||
| Netherlands | ||||||||||||||||
| Poland | ||||||||||||||||
| Israel | ||||||||||||||||
| Pakistan | ||||||||||||||||
| Switzerland | ||||||||||||||||
| Greece | ||||||||||||||||
| Mexico | ||||||||||||||||
| Egypt | ||||||||||||||||
| Singapore | ||||||||||||||||
| Belgium | ||||||||||||||||
| Taiwan | ||||||||||||||||
| Sweden | ||||||||||||||||
| Bangladesh | ||||||||||||||||
| Austria | ||||||||||||||||
| South Africa | ||||||||||||||||
| Ireland | ||||||||||||||||
| Malaysia | ||||||||||||||||
| Portugal | ||||||||||||||||
| Indonesia |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
De La Hoz-M, J.; Mendes, S.; Fernández-Gómez, M.J.; González Silva, Y. Capturing the Complexity of COVID-19 Research: Trend Analysis in the First Two Years of the Pandemic Using a Bayesian Probabilistic Model and Machine Learning Tools. Computation 2022, 10, 156. https://doi.org/10.3390/computation10090156
De La Hoz-M J, Mendes S, Fernández-Gómez MJ, González Silva Y. Capturing the Complexity of COVID-19 Research: Trend Analysis in the First Two Years of the Pandemic Using a Bayesian Probabilistic Model and Machine Learning Tools. Computation. 2022; 10(9):156. https://doi.org/10.3390/computation10090156
Chicago/Turabian StyleDe La Hoz-M, Javier, Susana Mendes, María José Fernández-Gómez, and Yolanda González Silva. 2022. "Capturing the Complexity of COVID-19 Research: Trend Analysis in the First Two Years of the Pandemic Using a Bayesian Probabilistic Model and Machine Learning Tools" Computation 10, no. 9: 156. https://doi.org/10.3390/computation10090156
APA StyleDe La Hoz-M, J., Mendes, S., Fernández-Gómez, M. J., & González Silva, Y. (2022). Capturing the Complexity of COVID-19 Research: Trend Analysis in the First Two Years of the Pandemic Using a Bayesian Probabilistic Model and Machine Learning Tools. Computation, 10(9), 156. https://doi.org/10.3390/computation10090156