
HFCVO-DMN: Henry Fuzzy Competitive Verse Optimizer-Integrated Deep Maxout Network for Incremental Text Classification

Abstract
:1. Introduction
2. Literature Survey
Major Challenges
- In [1], the technique required a large amount of time for classifying the text labels. When an unannotated text collection is given, it is very complex for users to identify what label to produce and how to represent the very first training set for categorization.
- Most of the neural classifiers failed to integrate the possibility of a complex environment. This may cause a sudden failure of trained neural networks, resulting in insufficient classification. Hence, most of the neural networks faced the limitations of inefficient classification and incapability of learning the newly arrived unknown classes.
- The SGrC-based DBN developed in [10] provided accurate outcomes for text categorization but, it was not capable of performing the tasks, such as web page classification and email classification.
- The computational complexity of this method was high. Moreover, the accuracy of the Rough set MS-SVNN must be enhanced [6].
- The connectionist-based categorization method considered a dynamic dataset for categorization purposes such that the network had enough potential to learn the model based on the arrival of the new database. However, the method had an ineffective similarity measure [29].
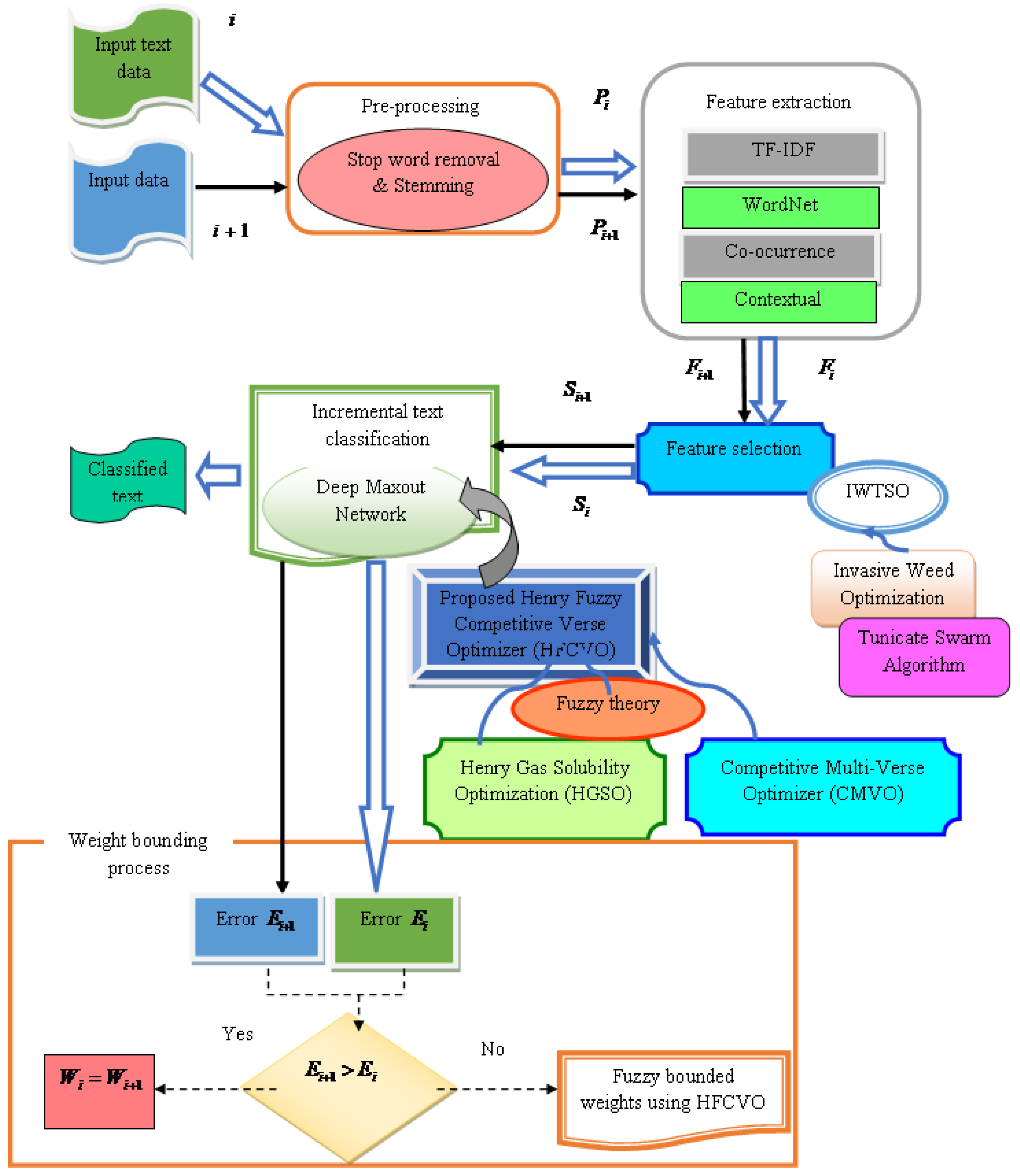
3. Proposed Method for Incremental Text Classification Using Henry Fuzzy Competitive Verse Optimizer
3.1. Acquisition of Input Text Data
3.2. Pre-Processing Using Stop Word Removal and Stemming
3.2.1. Stop Word Removal
3.2.2. Stemming
3.3. Feature Extraction
3.3.1. Wordnet-Based Features
3.3.2. Co-Occurrence-Based Features
3.3.3. TF–IDF
3.3.4. Contextual-Based Features
3.4. Feature Selection
| Algorithm 1. Pseudocode of proposed IWTSO. | |
| Sl. No | Pseudocode of IWTSO |
| 1 | Input:, |
| 2 | Output: |
| 3 | Initialize the weed population |
| 4 | Determine fitness function |
| 5 | Update the solution using Equation (14) |
| 6 | Determine the feasibility |
| 7 | Termination |
3.5. Arrival of New Data
3.6. Incremental Text Classification Using HFCVO-Based DMN
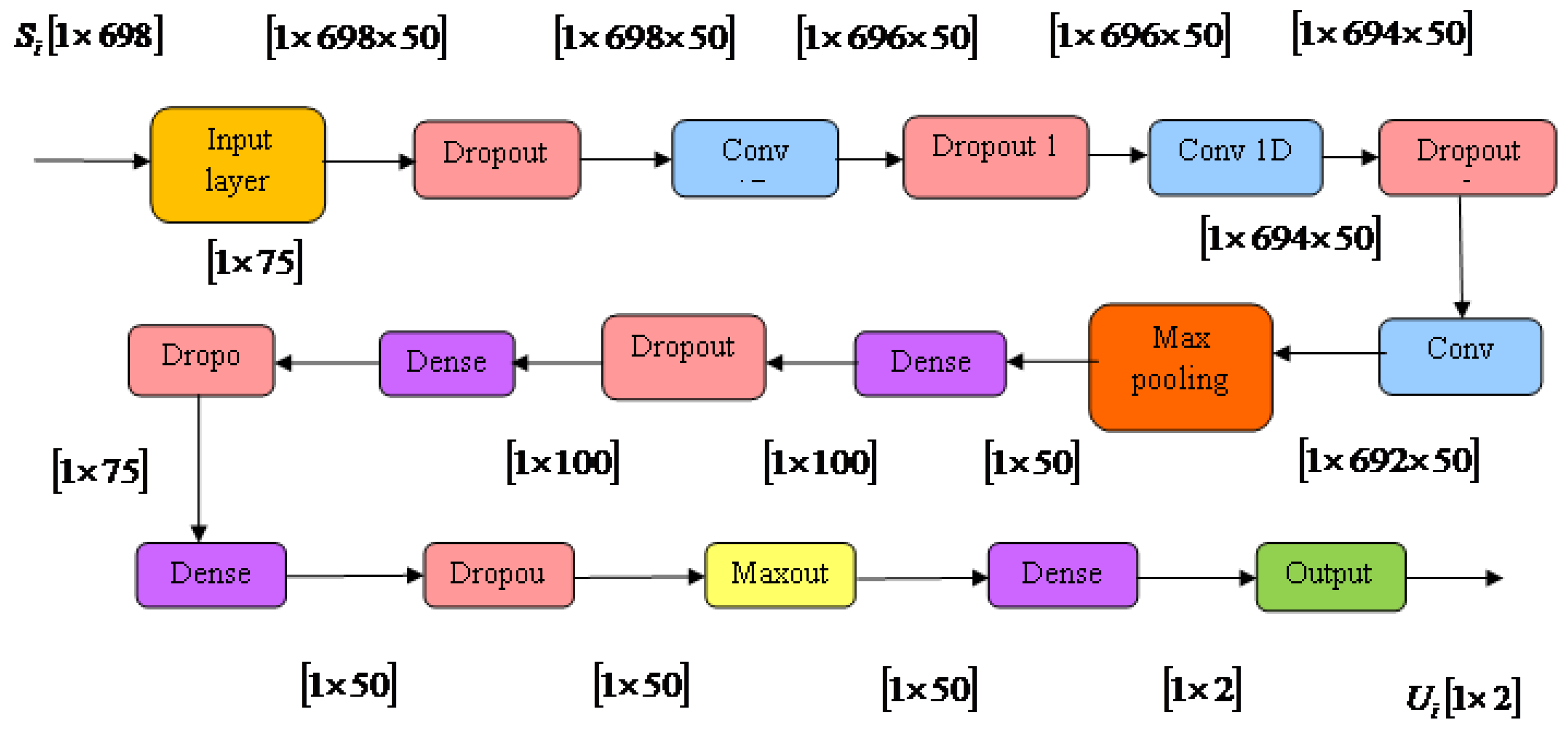
3.6.1. Architecture of Deep Maxout Network
3.6.2. Error Estimation
3.6.3. Fuzzy Bound-Based Incremental Learning
3.6.4. Weight Update Using Proposed HFCVO
| Algorithm 2. Pseudocode of proposed HFCVO. | |
| SL. No. | Pseudocode of HFCVO |
| 1 | Input:, , , , and Output: |
| 2 | Begin |
| 3 | The population agents are divided into various gas kinds using Henry’s constant value |
| 4 | Determine each cluster |
| 5 | Obtain the best gas in each cluster and optimal search agent |
| 6 | for search agent do |
| 7 | Update all search agents’ positions using equation (50) |
| 8 | end for |
| 9 | Update each gas type’s Henry’s coefficient using Equation (34) |
| 10 | Utilizing Equation (35), update the solubility of gas |
| 11 | Utilizing Equation (51), arrange and select the number of worst agents |
| 12 | Using Equation (52), update the location of the worst agents |
| 13 | Update the best gas and best search agent |
| 14 | end while |
| 15 | |
| 16 | Return |
| 17 | Terminate |
4. Results and Discussion
4.1. Experimental Setup
4.2. Dataset Description
4.3. Performance Analysis
4.3.1. Analysis Using Reuter Dataset
4.3.2. Analysis Using 20Newsgroup Dataset
4.3.3. Analysis Using Real-Time Dataset
4.4. Comparative Methods
4.5. Comparative Analysis
4.5.1. Analysis Using Reuter Dataset
4.5.2. Analysis Using 20Newsgroup Dataset
4.5.3. Analysis Using Real-Time Dataset
4.6. Analysis Based on Optimization Techniques
4.6.1. Analysis Using Reuter Dataset
4.6.2. Analysis Using 20Newsgroup Dataset
4.6.3. Analysis Using Real-Time Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| Abbreviations | Descriptions |
| HFCVO | Henry Fuzzy Competitive Multi-verse Optimizer |
| DMN | Deep Maxout Network |
| IWTSO | Invasive Weed Tunicate Swarm Optimization |
| DMN | Deep Maxout Network |
| IWO | Invasive Weed Optimization |
| NB | Naïve Bayes |
| TSA | Tunicate Swarm Algorithm |
| DMN | Deep Maxout Network |
| HGSO | Henry Gas Solubility Optimization |
| CMVO | Competitive Multi-Verse Optimizer |
| WWW | World Wide Web |
| ML | Machine Learning |
| TNR | True Negative Rate |
| SVM | Support Vector Machine |
| FNR | False Negative Rate |
| KNN | K-Nearest Neighbor |
| AC | Associative Classification |
| SGrC-based DBN | Spider Grasshopper Crow Optimization Algorithm-based Deep Belief Neural network |
| SMO | Spider Monkey Optimization |
| GCOA | Grasshopper Crow Optimization Algorithm |
| RL | Reinforcement Learning |
| SVNN | Support Vector Neural Network |
| LSTM | Long Short-Term Memory |
| MB–FF-based NN | Monarch Butterfly optimization–FireFly optimization-based Neural Network |
| TF–IDF | Term Frequency–Inverse Document Frequency |
| ST | Sequential Targeting |
| COA | Cuckoo Optimization Algorithm |
| Gibbs MedLDA | Interactive visual assessment model depending on a semi-supervised topic modeling technique called allocation. |
| SG–CAV-based DBN | Stochastic Gradient–CAViaR-based Deep Belief Network |
| ReLU | Rectified Linear Unit |
| RBM | Restricted Boltzmann Machines |
| MVO | Multi-Verse Optimizer algorithm |
| NN | Neural Network |
| TPR | True Positive Rate |
| RF | Random Forest |
| NLP | Natural Language Processing |
References
- Yan, Y.; Tao, Y.; Jin, S.; Xu, J.; Lin, H. An Interactive Visual Analytics System for Incremental Classification Based on Semi-supervised Topic Modeling. In Proceedings of the IEEE Pacific Visualization Symposium (PacificVis), Bangkok, Thailand, 23–26 April 2019; pp. 148–157. [Google Scholar]
- Chander, S.; Vijaya, P.; Dhyani, P. Multi kernel and dynamic fractional lion optimization algorithm for data clustering. Alex. Eng. J. 2018, 57, 267–276. [Google Scholar] [CrossRef]
- Jadhav, A.N.; Gomathi, N. DIGWO: Hybridization of Dragonfly Algorithm with Improved Grey Wolf Optimization Algorithm for Data Clustering. Multimed. Res. 2019, 2, 1–11. [Google Scholar]
- Tan, A.H. Text mining: The state of the art and the challenges. In Proceedings of the Pakdd 1999 Workshop on Knowledge Discovery from Advanced Databases, Beijing, China, 26–28 April 1999; Volume 8, pp. 65–70. [Google Scholar]
- Yadav, P. SR-K-Means clustering algorithm for semantic information retrieval. Int. J. Invent. Comput. Sci. Eng. 2014, 1, 17–24. [Google Scholar]
- Sailaja, N.V.; Padmasree, L.; Mangathayaru, N. Incremental learning for text categorization using rough set boundary based optimized Support Vector Neural Network. In Data Technologies and Applications; Emerald Publishing Limited: Bingley, UK, 2020. [Google Scholar]
- Kaviyaraj, R.; Uma, M. Augmented Reality Application in Classroom: An Immersive Taxonomy. In Proceedings of the 2022 4th International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20 January 2022; pp. 1221–1226. [Google Scholar]
- Vidyadhari, C.; Sandhya, N.; Premchand, P. A Semantic Word Processing Using Enhanced Cat Swarm Optimization Algorithm for Automatic Text Clustering. Multimed. Res. 2019, 2, 23–32. [Google Scholar]
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. 2022, 34, 1–47. [Google Scholar] [CrossRef] [Green Version]
- Srilakshmi, V.; Anuradha, K.; Bindu, C.S. Incremental text categorization based on hybrid optimization-based deep belief neural network. J. High Speed Netw. 2021, 27, 1–20. [Google Scholar] [CrossRef]
- Jo, T. K nearest neighbor for text categorization using feature similarity. Adv. Eng. ICT Converg. 2019, 2, 99. [Google Scholar]
- Sheu, J.J.; Chu, K.T. An efficient spam filtering method by analyzing e-mail’s header session only. Int. J. Innov. Comput. Inf. Control. 2009, 5, 3717–3731. [Google Scholar]
- Ghiassi, M.; Olschimke, M.; Moon, B.; Arnaudo, P. Automated text classification using a dynamic artificial neural network model. Expert Syst. Appl. 2012, 39, 10967–10976. [Google Scholar] [CrossRef]
- Wang, Q.; Fang, Y.; Ravula, A.; Feng, F.; Quan, X.; Liu, D. WebFormer: The Web-page Transformer for Structure Information Extraction. In Proceedings of the ACM Web Conference (WWW ’22), Lyon, France, 25–29 April 2022; pp. 3124–3133. [Google Scholar]
- Yan, L.; Ma, S.; Wang, Q.; Chen, Y.; Zhang, X.; Savakis, A.; Liu, D. Video Captioning Using Global-Local Representation. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6642–6656. [Google Scholar] [CrossRef]
- Liu, D.; Cui, Y.; Tan, W.; Chen, Y. SG-Net: Spatial Granularity Network for One-Stage Video Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 21 June 2021. [Google Scholar]
- Al-diabat, M. Arabic text categorization using classification rule mining. Appl. Math. Sci. 2012, 6, 4033–4046. [Google Scholar]
- Srinivas, K. Prediction of e-learning efficiency by deep learning in E-khool online portal networks. Multimed. Res. 2020, 3, 12–23. [Google Scholar] [CrossRef]
- Alzubi, A.; Eladli, A. Mobile Payment Adoption-A Systematic Review. J. Posit. Psychol. Wellbeing 2021, 5, 565–577. [Google Scholar]
- Rupapara, V.; Narra, M.; Gunda, N.K.; Gandhi, S.; Thipparthy, K.R. Maintaining Social Distancing in Pandemic Using Smartphones With Acoustic Waves. IEEE Trans. Comput. Soc. Syst. 2022, 9, 605–611. [Google Scholar] [CrossRef]
- Rahul, V.S.; Kosuru; Venkitaraman, A.K. Integrated framework to identify fault in human-machine interaction systems. Int. Res. J. Mod. Eng. Technol. Sci. 2022, 4, 1685–1692. [Google Scholar]
- Gali, V. Tamil Character Recognition Using K-Nearest-Neighbouring Classifier based on Grey Wolf Optimization Algorithm. Multimed. Res. 2021, 4, 1–24. [Google Scholar] [CrossRef]
- Shirsat, P. Developing Deep Neural Network for Learner Performance Prediction in EKhool Online Learning Platform. Multimed. Res. 2020, 3, 24–31. [Google Scholar] [CrossRef]
- Shan, G.; Xu, S.; Yang, L.; Jia, S.; Xiang, Y. Learn#: A novel incremental learning method for text classification. Expert Syst. Appl. 2020, 147, 113198. [Google Scholar]
- Kayest, M.; Jain, S.K. An Incremental Learning Approach for the Text Categorization Using Hybrid Optimization; Emerald Publishing Limited: Bingley, UK, 2019. [Google Scholar]
- Jang, J.; Kim, Y.; Choi, K.; Suh, S. Sequential Targeting: An incremental learning approach for data imbalance in text classification. arXiv 2020, arXiv:2011.10216. [Google Scholar]
- Nihar, M.R.; Midhunchakkaravarthy, J. Evolutionary and Incremental Text Document Classifier using Deep Learning. Int. J. Grid Distrib. Comput. 2021, 14, 587–595. [Google Scholar]
- Srilakshmi, V.; Anuradha, K.; Bindu, C.S. Stochastic gradient-CAViaR-based deep belief network for text categorization. Evol. Intell. 2020, 14, 1727–1741. [Google Scholar] [CrossRef]
- Nihar, M.R.; Rajesh, S.P. LFNN: Lion fuzzy neural network-based evolutionary model for text classification using context and sense based features. Appl. Soft Comput. 2018, 71, 994–1008. [Google Scholar]
- Liu, Y.; Sun, C.J.; Lin, L.; Wang, X.; Zhao, Y. Computing semantic text similarity using rich features. In Proceedings of the 29th Pacific Asia Conference on Language, Information and Computation, Shanghai, China, 30 October–1 November 2015; pp. 44–52. [Google Scholar]
- Wu, D.; Yang, R.; Shen, C. Sentiment word co-occurrence and knowledge pair feature extraction based LDA short text clustering algorithm. J. Intell. Inf. Syst. 2020, 56, 1–23. [Google Scholar] [CrossRef]
- Zhou, Y.; Luo, Q.; Chen, H.; He, A.; Wu, J. A discrete invasive weed optimization algorithm for solving traveling salesman problem. Neurocomputing 2015, 151, 1227–1236. [Google Scholar] [CrossRef]
- Sang, H.Y.; Duan, P.Y.; Li, J.Q. An effective invasive weed optimization algorithm for scheduling semiconductor final testing problem. Swarm Evol. Comput. 2018, 38, 42–53. [Google Scholar] [CrossRef]
- Kaur, S.; Awasthi, L.K.; Sangal, A.L.; Dhiman, G. Tunicate Swarm Algorithm: A new bio-inspired based metaheuristic paradigm for global optimization. Eng. Appl. Artif. Intell. 2020, 90, 103541. [Google Scholar] [CrossRef]
- Sun, W.; Su, F.; Wang, L. Improving deep neural networks with multi-layer maxout networks and a novel initialization method. Neurocomputing 2018, 278, 34–40. [Google Scholar] [CrossRef]
- Hashim, F.A.; Houssein, E.H.; Mabrouk, M.S.; Al-Atabany, W.; Mirjalili, S. Henry gas solubility optimization: A novel physics-based algorithm. Future Gener. Comput. Syst. 2019, 101, 646–667. [Google Scholar] [CrossRef]
- Benmessahel, I.; Xie, K.; Chellal, M. A new competitive multiverse optimization technique for solving single-objective and multi-objective problems. Eng. Rep. 2020, 2, e12124. [Google Scholar]
- Reuters-21578 Text Categorization Collection Data Set. Available online: https://archive.ics.uci.edu/ml/datasets/reuters-21578+text+categorization+collection (accessed on 23 January 2022).
- 20 Newsgroup Dataset. Available online: https://www.kaggle.com/crawford/20-newsgroups (accessed on 23 January 2022).




{kind=link}
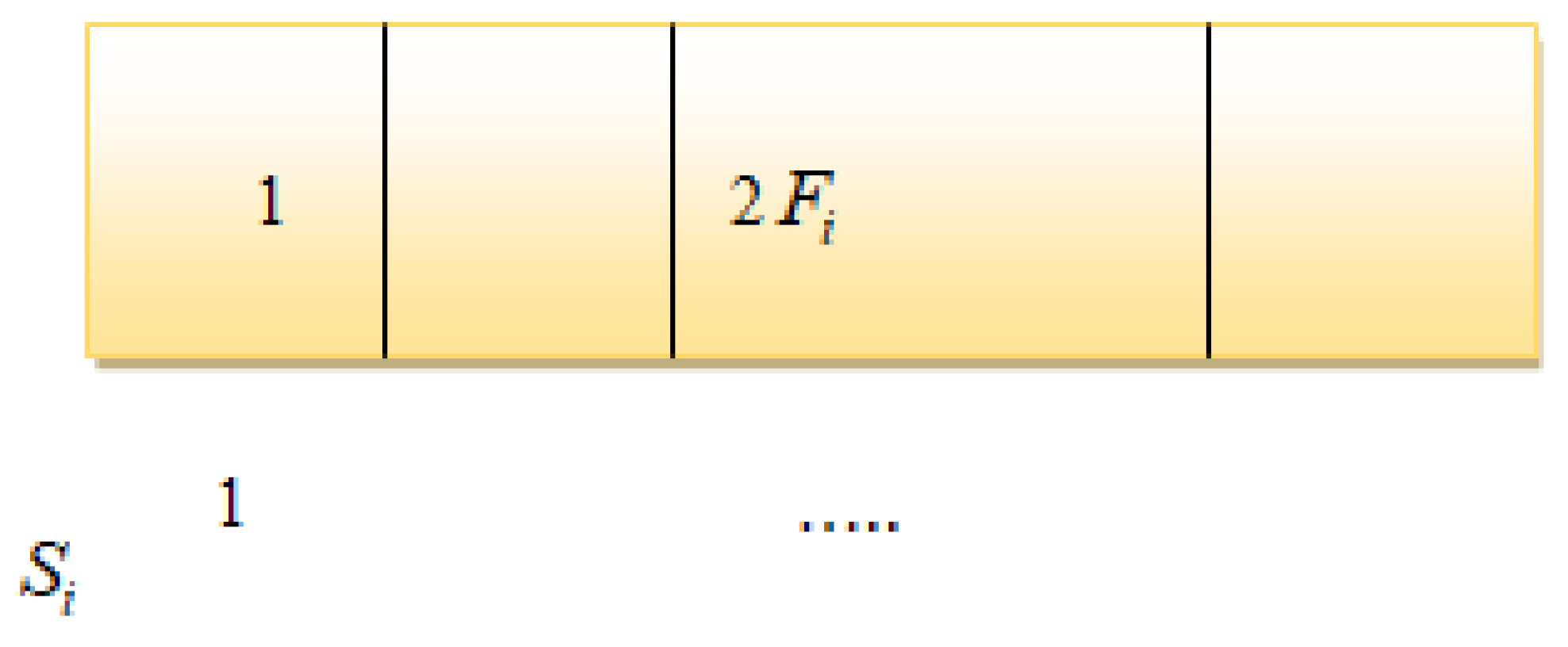{kind=link}
{kind=link}
| PYTHON Libraries Name | Version |
|---|---|
| matplotlib | 3.5.0 |
| numpy | 1.21.4 |
| PySimpleGUI | 4.33.0 |
| pandas | 1.3.4 |
| scikit-learn | 1.0.1 |
| Keras-Applications | 1.0.8 |
| Pillow | 9.2.0 |
| tensorboard | 2.9.1 |
| tensorboard-plugin-wit | 1.8.1 |
| tensorboard-data-server | 0.6.1 |
| tensorflow | 2.9.1 |
| tensorflow-estimator | 2.9.0 |
| Keras | 2.3.1 |
| tensorflow-io-gcs-filesystem | 0.26.0 |
| Keras-Preprocessing | 1.1.2 |
| Training Data(%) | Proposed HFCVO-Based DMN with Feature Size 100 | Proposed HFCVO-Based DMN with Feature Size 200 | Proposed HFCVO-Based DMN with Feature Size 300 | Proposed HFCVO-Based DMN with Feature Size 400 | Proposed HFCVO-Based DMN with Feature Size 500 |
|---|---|---|---|---|---|
| TPR | |||||
| 60 | 0.824 | 0.837 | 0.846 | 0.868 | 0.885 |
| 70 | 0.847 | 0.865 | 0.874 | 0.881 | 0.895 |
| 80 | 0.862 | 0.872 | 0.900 | 0.905 | 0.925 |
| 90 | 0.873 | 0.897 | 0.901 | 0.928 | 0.935 |
| TNR | |||||
| 60 | 0.808 | 0.812 | 0.835 | 0.842 | 0.854 |
| 70 | 0.812 | 0.834 | 0.846 | 0.857 | 0.865 |
| 80 | 0.835 | 0.853 | 0.874 | 0.894 | 0.901 |
| 90 | 0.858 | 0.874 | 0.896 | 0.902 | 0.925 |
| FNR | |||||
| 60 | 0.176 | 0.163 | 0.154 | 0.132 | 0.115 |
| 70 | 0.153 | 0.135 | 0.126 | 0.119 | 0.105 |
| 80 | 0.138 | 0.128 | 0.100 | 0.095 | 0.075 |
| 90 | 0.127 | 0.103 | 0.099 | 0.072 | 0.065 |
| Precision | |||||
| 60 | 0.868 | 0.886 | 0.895 | 0.904 | 0.929 |
| 70 | 0.875 | 0.884 | 0.903 | 0.912 | 0.938 |
| 80 | 0.880 | 0.897 | 0.913 | 0.940 | 0.953 |
| 90 | 0.883 | 0.909 | 0.923 | 0.947 | 0.970 |
| Accuracy | |||||
| 60 | 0.824 | 0.835 | 0.845 | 0.858 | 0.863 |
| 70 | 0.839 | 0.846 | 0.857 | 0.868 | 0.872 |
| 80 | 0.846 | 0.858 | 0.877 | 0.895 | 0.907 |
| 90 | 0.857 | 0.878 | 0.898 | 0.905 | 0.924 |
| Training Data(%) | Proposed HFCVO-Based DMN with Feature Size 100 | Proposed HFCVO-Based DMN with Feature Size 200 | Proposed HFCVO-Based DMN with Feature Size 300 | Proposed HFCVO-Based DMN with Feature Size 400 | Proposed HFCVO-Based DMN with Feature Size 500 |
|---|---|---|---|---|---|
| TPR | |||||
| 60 | 0.867 | 0.884 | 0.909 | 0.928 | 0.946 |
| 70 | 0.877 | 0.897 | 0.918 | 0.938 | 0.950 |
| 80 | 0.881 | 0.896 | 0.919 | 0.938 | 0.955 |
| 90 | 0.894 | 0.913 | 0.935 | 0.947 | 0.963 |
| TNR | |||||
| 60 | 0.846 | 0.868 | 0.877 | 0.888 | 0.898 |
| 70 | 0.857 | 0.861 | 0.879 | 0.898 | 0.902 |
| 80 | 0.867 | 0.875 | 0.887 | 0.907 | 0.923 |
| 90 | 0.878 | 0.888 | 0.909 | 0.919 | 0.939 |
| FNR | |||||
| 60 | 0.133 | 0.116 | 0.091 | 0.072 | 0.054 |
| 70 | 0.123 | 0.103 | 0.082 | 0.062 | 0.050 |
| 80 | 0.119 | 0.104 | 0.081 | 0.062 | 0.045 |
| 90 | 0.106 | 0.087 | 0.065 | 0.053 | 0.037 |
| Precision | |||||
| 60 | 0.855 | 0.877 | 0.895 | 0.919 | 0.936 |
| 70 | 0.864 | 0.884 | 0.916 | 0.930 | 0.942 |
| 80 | 0.888 | 0.908 | 0.928 | 0.945 | 0.966 |
| 90 | 0.891 | 0.918 | 0.938 | 0.955 | 0.974 |
| Accuracy | |||||
| 60 | 0.835 | 0.858 | 0.861 | 0.881 | 0.899 |
| 70 | 0.846 | 0.865 | 0.887 | 0.905 | 0.929 |
| 80 | 0.862 | 0.885 | 0.904 | 0.901 | 0.944 |
| 90 | 0.871 | 0.899 | 0.918 | 0.938 | 0.956 |
| Training Data(%) | Proposed HFCVO-Based DMN with Feature Size 100 | Proposed HFCVO-Based DMN with Feature Size 200 | Proposed HFCVO-Based DMN with Feature Size 300 | Proposed HFCVO-Based DMN with Feature Size 400 | Proposed HFCVO-Based DMN with Feature Size 500 |
|---|---|---|---|---|---|
| TPR | |||||
| 60 | 0.834 | 0.854 | 0.876 | 0.896 | 0.918 |
| 70 | 0.848 | 0.869 | 0.896 | 0.912 | 0.938 |
| 80 | 0.858 | 0.879 | 0.912 | 0.938 | 0.946 |
| 90 | 0.869 | 0.897 | 0.929 | 0.949 | 0.968 |
| TNR | |||||
| 60 | 0.824 | 0.846 | 0.868 | 0.877 | 0.897 |
| 70 | 0.835 | 0.858 | 0.872 | 0.898 | 0.912 |
| 80 | 0.858 | 0.878 | 0.898 | 0.907 | 0.924 |
| 90 | 0.865 | 0.886 | 0.908 | 0.926 | 0.941 |
| FNR | |||||
| 60 | 0.166 | 0.146 | 0.124 | 0.104 | 0.082 |
| 70 | 0.152 | 0.131 | 0.104 | 0.088 | 0.062 |
| 80 | 0.142 | 0.121 | 0.088 | 0.062 | 0.054 |
| 90 | 0.131 | 0.103 | 0.071 | 0.051 | 0.032 |
| Precision | |||||
| 60 | 0.845 | 0.868 | 0.887 | 0.908 | 0.927 |
| 70 | 0.858 | 0.873 | 0.899 | 0.912 | 0.938 |
| 80 | 0.869 | 0.888 | 0.909 | 0.925 | 0.946 |
| 90 | 0.878 | 0.892 | 0.919 | 0.939 | 0.954 |
| Accuracy | |||||
| 60 | 0.848 | 0.865 | 0.885 | 0.892 | 0.907 |
| 70 | 0.869 | 0.879 | 0.896 | 0.912 | 0.924 |
| 80 | 0.875 | 0.895 | 0.912 | 0.929 | 0.935 |
| 90 | 0.884 | 0.901 | 0.928 | 0.944 | 0.955 |
| Training Data(%) | SGrC-Based DBN | MB–FF-Based NN | LFNN | SVNN | Proposed HFCVO-Based DMN |
|---|---|---|---|---|---|
| TPR | |||||
| 60 | 0.745 | 0.765 | 0.785 | 0.825 | 0.885 |
| 70 | 0.754 | 0.785 | 0.799 | 0.848 | 0.895 |
| 80 | 0.775 | 0.804 | 0.825 | 0.854 | 0.925 |
| 90 | 0.804 | 0.845 | 0.875 | 0.895 | 0.935 |
| TNR | |||||
| 60 | 0.725 | 0.745 | 0.765 | 0.785 | 0.854 |
| 70 | 0.735 | 0.765 | 0.799 | 0.814 | 0.865 |
| 80 | 0.765 | 0.785 | 0.814 | 0.835 | 0.901 |
| 90 | 0.798 | 0.814 | 0.837 | 0.854 | 0.925 |
| FNR | |||||
| 60 | 0.255 | 0.235 | 0.215 | 0.175 | 0.115 |
| 70 | 0.246 | 0.215 | 0.201 | 0.152 | 0.105 |
| 80 | 0.225 | 0.196 | 0.175 | 0.146 | 0.075 |
| 90 | 0.196 | 0.155 | 0.125 | 0.105 | 0.065 |
| Precision | |||||
| 60 | 0.725 | 0.755 | 0.793 | 0.852 | 0.929 |
| 70 | 0.743 | 0.765 | 0.817 | 0.874 | 0.938 |
| 80 | 0.765 | 0.782 | 0.824 | 0.888 | 0.953 |
| 90 | 0.774 | 0.784 | 0.835 | 0.908 | 0.970 |
| Accuracy | |||||
| 60 | 0.724 | 0.743 | 0.764 | 0.804 | 0.863 |
| 70 | 0.745 | 0.764 | 0.784 | 0.835 | 0.872 |
| 80 | 0.763 | 0.794 | 0.815 | 0.843 | 0.907 |
| 90 | 0.785 | 0.831 | 0.854 | 0.882 | 0.924 |
| Training Data(%) | SGrC-Based DBN | MB–FF-Based NN | LFNN | SVNN | Proposed HFCVO-Based DMN |
|---|---|---|---|---|---|
| TPR | |||||
| 60 | 0.757 | 0.785 | 0.816 | 0.883 | 0.946 |
| 70 | 0.767 | 0.797 | 0.829 | 0.898 | 0.950 |
| 80 | 0.775 | 0.808 | 0.835 | 0.905 | 0.955 |
| 90 | 0.827 | 0.856 | 0.889 | 0.909 | 0.963 |
| TNR | |||||
| 60 | 0.738 | 0.764 | 0.784 | 0.835 | 0.898 |
| 70 | 0.754 | 0.773 | 0.805 | 0.846 | 0.902 |
| 80 | 0.802 | 0.823 | 0.842 | 0.870 | 0.923 |
| 90 | 0.836 | 0.860 | 0.889 | 0.909 | 0.939 |
| FNR | |||||
| 60 | 0.243 | 0.215 | 0.184 | 0.117 | 0.054 |
| 70 | 0.233 | 0.203 | 0.171 | 0.102 | 0.050 |
| 80 | 0.225 | 0.192 | 0.165 | 0.095 | 0.045 |
| 90 | 0.173 | 0.144 | 0.111 | 0.091 | 0.037 |
| Precision | |||||
| 60 | 0.736 | 0.765 | 0.805 | 0.879 | 0.936 |
| 70 | 0.759 | 0.773 | 0.825 | 0.886 | 0.942 |
| 80 | 0.772 | 0.804 | 0.836 | 0.895 | 0.966 |
| 90 | 0.785 | 0.798 | 0.855 | 0.917 | 0.974 |
| Accuracy | |||||
| 60 | 0.749 | 0.775 | 0.798 | 0.844 | 0.899 |
| 70 | 0.752 | 0.798 | 0.813 | 0.857 | 0.929 |
| 80 | 0.799 | 0.839 | 0.852 | 0.872 | 0.944 |
| 90 | 0.818 | 0.844 | 0.878 | 0.898 | 0.956 |
| Training Data(%) | SGrC-Based DBN | MB–FF-Based NN | LFNN | SVNN | Proposed HFCVO-Based DMN |
|---|---|---|---|---|---|
| TPR | |||||
| 60 | 0.768 | 0.798 | 0.827 | 0.868 | 0.918 |
| 70 | 0.798 | 0.813 | 0.850 | 0.879 | 0.938 |
| 80 | 0.819 | 0.835 | 0.856 | 0.889 | 0.946 |
| 90 | 0.838 | 0.863 | 0.899 | 0.912 | 0.968 |
| TNR | |||||
| 60 | 0.744 | 0.777 | 0.786 | 0.844 | 0.897 |
| 70 | 0.774 | 0.797 | 0.825 | 0.855 | 0.912 |
| 80 | 0.794 | 0.818 | 0.838 | 0.868 | 0.924 |
| 90 | 0.802 | 0.824 | 0.855 | 0.897 | 0.941 |
| FNR | |||||
| 60 | 0.232 | 0.202 | 0.173 | 0.132 | 0.082 |
| 70 | 0.202 | 0.187 | 0.150 | 0.121 | 0.062 |
| 80 | 0.181 | 0.165 | 0.144 | 0.111 | 0.054 |
| 90 | 0.162 | 0.137 | 0.101 | 0.088 | 0.032 |
| Precision | |||||
| 60 | 0.744 | 0.776 | 0.818 | 0.909 | 0.927 |
| 70 | 0.752 | 0.783 | 0.824 | 0.912 | 0.938 |
| 80 | 0.775 | 0.798 | 0.838 | 0.928 | 0.946 |
| 90 | 0.786 | 0.803 | 0.846 | 0.937 | 0.954 |
| Accuracy | |||||
| 60 | 0.755 | 0.786 | 0.812 | 0.856 | 0.907 |
| 70 | 0.788 | 0.809 | 0.836 | 0.867 | 0.924 |
| 80 | 0.809 | 0.824 | 0.848 | 0.873 | 0.935 |
| 90 | 0.824 | 0.854 | 0.886 | 0.906 | 0.955 |
| Training Data(%) | TSO+DMN | IIWO+DMN | IWTSO+DMN | HGSO+DMN | CMVO+DMN | HFCO+DMN |
|---|---|---|---|---|---|---|
| TPR | ||||||
| 60 | 0.814 | 0.835 | 0.854 | 0.865 | 0.875 | 0.885 |
| 70 | 0.825 | 0.845 | 0.865 | 0.875 | 0.887 | 0.895 |
| 80 | 0.841 | 0.854 | 0.875 | 0.887 | 0.905 | 0.925 |
| 90 | 0.865 | 0.875 | 0.887 | 0.899 | 0.914 | 0.935 |
| TNR | ||||||
| 60 | 0.785 | 0.799 | 0.814 | 0.835 | 0.854 | 0.854 |
| 70 | 0.799 | 0.814 | 0.825 | 0.841 | 0.854 | 0.865 |
| 80 | 0.825 | 0.837 | 0.848 | 0.865 | 0.886 | 0.901 |
| 90 | 0.835 | 0.854 | 0.865 | 0.887 | 0.905 | 0.925 |
| FNR | ||||||
| 60 | 0.186 | 0.165 | 0.146 | 0.135 | 0.125 | 0.115 |
| 70 | 0.175 | 0.155 | 0.135 | 0.125 | 0.113 | 0.105 |
| 80 | 0.159 | 0.146 | 0.125 | 0.113 | 0.095 | 0.075 |
| 90 | 0.135 | 0.125 | 0.113 | 0.101 | 0.086 | 0.065 |
| Precision | ||||||
| 60 | 0.833 | 0.854 | 0.875 | 0.895 | 0.905 | 0.929 |
| 70 | 0.841 | 0.865 | 0.887 | 0.914 | 0.925 | 0.938 |
| 80 | 0.854 | 0.875 | 0.895 | 0.920 | 0.927 | 0.953 |
| 90 | 0.865 | 0.887 | 0.905 | 0.925 | 0.948 | 0.970 |
| Accuracy | ||||||
| 60 | 0.804 | 0.814 | 0.825 | 0.837 | 0.848 | 0.863 |
| 70 | 0.814 | 0.825 | 0.837 | 0.847 | 0.854 | 0.872 |
| 80 | 0.833 | 0.845 | 0.854 | 0.876 | 0.887 | 0.907 |
| 90 | 0.854 | 0.865 | 0.875 | 0.898 | 0.905 | 0.924 |
| Training Data(%) | TSO+DMN | IIWO+DMN | IWTSO+DMN | HGSO+DMN | CMVO+DMN | HFCO+DMN |
|---|---|---|---|---|---|---|
| TPR | ||||||
| 60 | 0.841 | 0.865 | 0.875 | 0.897 | 0.925 | 0.946 |
| 70 | 0.854 | 0.870 | 0.899 | 0.914 | 0.925 | 0.950 |
| 80 | 0.865 | 0.887 | 0.905 | 0.924 | 0.937 | 0.955 |
| 90 | 0.887 | 0.904 | 0.914 | 0.933 | 0.954 | 0.963 |
| TNR | ||||||
| 60 | 0.802 | 0.825 | 0.847 | 0.865 | 0.885 | 0.898 |
| 70 | 0.814 | 0.837 | 0.854 | 0.875 | 0.895 | 0.902 |
| 80 | 0.824 | 0.848 | 0.865 | 0.887 | 0.905 | 0.923 |
| 90 | 0.841 | 0.865 | 0.885 | 0.895 | 0.925 | 0.939 |
| FNR | ||||||
| 60 | 0.159 | 0.135 | 0.125 | 0.103 | 0.075 | 0.054 |
| 70 | 0.146 | 0.130 | 0.101 | 0.086 | 0.075 | 0.050 |
| 80 | 0.135 | 0.113 | 0.095 | 0.076 | 0.063 | 0.045 |
| 90 | 0.113 | 0.096 | 0.086 | 0.067 | 0.046 | 0.037 |
| Precision | ||||||
| 60 | 0.854 | 0.865 | 0.887 | 0.905 | 0.914 | 0.936 |
| 70 | 0.865 | 0.875 | 0.895 | 0.925 | 0.937 | 0.942 |
| 80 | 0.887 | 0.905 | 0.925 | 0.933 | 0.954 | 0.966 |
| 90 | 0.897 | 0.925 | 0.941 | 0.951 | 0.962 | 0.974 |
| Accuracy | ||||||
| 60 | 0.825 | 0.845 | 0.854 | 0.865 | 0.887 | 0.899 |
| 70 | 0.835 | 0.854 | 0.865 | 0.895 | 0.905 | 0.929 |
| 80 | 0.841 | 0.865 | 0.875 | 0.924 | 0.935 | 0.944 |
| 90 | 0.857 | 0.875 | 0.885 | 0.937 | 0.941 | 0.956 |
| Training Data(%) | TSO+DMN | IIWO+DMN | IWTSO+DMN | HGSO+DMN | CMVO+DMN | HFCO+DMN |
|---|---|---|---|---|---|---|
| TPR | ||||||
| 60 | 0.824 | 0.841 | 0.861 | 0.887 | 0.901 | 0.918 |
| 70 | 0.835 | 0.854 | 0.875 | 0.895 | 0.914 | 0.938 |
| 80 | 0.854 | 0.865 | 0.887 | 0.905 | 0.925 | 0.946 |
| 90 | 0.875 | 0.885 | 0.904 | 0.925 | 0.941 | 0.968 |
| TNR | ||||||
| 60 | 0.802 | 0.833 | 0.854 | 0.875 | 0.885 | 0.897 |
| 70 | 0.821 | 0.854 | 0.875 | 0.895 | 0.902 | 0.912 |
| 80 | 0.841 | 0.865 | 0.887 | 0.905 | 0.914 | 0.924 |
| 90 | 0.865 | 0.875 | 0.895 | 0.921 | 0.933 | 0.941 |
| FNR | ||||||
| 60 | 0.176 | 0.159 | 0.139 | 0.113 | 0.099 | 0.082 |
| 70 | 0.165 | 0.146 | 0.125 | 0.105 | 0.086 | 0.062 |
| 80 | 0.146 | 0.135 | 0.113 | 0.095 | 0.075 | 0.054 |
| 90 | 0.125 | 0.115 | 0.075 | 0.059 | 0.032 | 0.032 |
| Precision | ||||||
| 60 | 0.833 | 0.854 | 0.875 | 0.895 | 0.905 | 0.927 |
| 70 | 0.854 | 0.865 | 0.895 | 0.914 | 0.925 | 0.938 |
| 80 | 0.875 | 0.885 | 0.905 | 0.925 | 0.935 | 0.946 |
| 90 | 0.897 | 0.905 | 0.924 | 0.935 | 0.941 | 0.954 |
| Accuracy | ||||||
| 60 | 0.814 | 0.837 | 0.854 | 0.875 | 0.887 | 0.907 |
| 70 | 0.825 | 0.841 | 0.865 | 0.899 | 0.904 | 0.924 |
| 80 | 0.841 | 0.865 | 0.887 | 0.914 | 0.925 | 0.935 |
| 90 | 0.865 | 0.885 | 0.895 | 0.926 | 0.935 | 0.955 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Singh, G.; Nagpal, A. HFCVO-DMN: Henry Fuzzy Competitive Verse Optimizer-Integrated Deep Maxout Network for Incremental Text Classification. Computation 2023, 11, 13. https://doi.org/10.3390/computation11010013
Singh G, Nagpal A. HFCVO-DMN: Henry Fuzzy Competitive Verse Optimizer-Integrated Deep Maxout Network for Incremental Text Classification. Computation. 2023; 11(1):13. https://doi.org/10.3390/computation11010013
Chicago/Turabian StyleSingh, Gunjan, and Arpita Nagpal. 2023. "HFCVO-DMN: Henry Fuzzy Competitive Verse Optimizer-Integrated Deep Maxout Network for Incremental Text Classification" Computation 11, no. 1: 13. https://doi.org/10.3390/computation11010013
APA StyleSingh, G., & Nagpal, A. (2023). HFCVO-DMN: Henry Fuzzy Competitive Verse Optimizer-Integrated Deep Maxout Network for Incremental Text Classification. Computation, 11(1), 13. https://doi.org/10.3390/computation11010013