1. Introduction
The agricultural industry is currently expanding quickly. Indonesia is a country with a large amount of agricultural potential [
1]. Its location on the equator and encirclement by an ocean results in abundant rains and good land. In Indonesia, fertile soil is characterized by the presence of numerous plant species [
2]. Tomato is one of the plants that have the capacity to flourish in Indonesia [
3,
4,
5]. In addition, it has a variety of applications, ranging from food additives, coloring agents, and cosmetics to sauces, sweets, and other food industry raw materials. Therefore, the tomato plant is an economically valuable horticultural item [
6].
The production continues to expand annually. It tends to expand. A substantial growth rate necessitates consistency so that the agricultural industry does not see a decline in quality or quantity. During their growth stage, these plants require care to prevent a decline in quality and quantity [
7]. Although they are simple to cultivate, they are highly susceptible to illness. During the growth period, illnesses can be recognized by observing changes in leaf texture, such as spotting, a mosaic formation, or color alterations [
8,
9].
Approximately 85 percent of plant illnesses are caused by fungi or fungi-like organisms. The fields of biotechnology and molecular biology have transformed the diagnosis of plant diseases. There were developments in invasive diagnostic procedures, such as Western blotting, enzyme-linked immunosorbent assay (ELISA), and microarrays. Fluorescence spectroscopy, visible/near-infrared (VNIR) spectroscopy, fluorescence imaging, and hyperspectral imaging are the most popular noninvasive approaches. Cui et al. [
10] examined the benefits and drawbacks of these approaches. Golhani et al.’s research aimed to examine the applicability of hyperspectral imaging for plant disease identification [
11].
Some leaves of plants in Indonesia are affected by spotting and rotting, although it is difficult to discern between the two illnesses with the naked eye. Consequently, farmers are frequently misidentified as those responsible for crop failure. Therefore, we require the aid of computer technology employing deep learning, which is a subfield of machine learning. It is a novel viewpoint on learning models that emphasizes layer-based learning. The model closely resembles the human brain. Its neurons are coupled to one another to form interconnected networks. Deep learning employs numerous techniques, including convolutional neural networks (CNNs), recurrent neural networks (RNNs), gated recurrent units (GRUs), and long short-term memory (LSTM). As indicated in
Table 1, deep learning has been widely used in several scenarios in everyday life.
The CNN is the method with the most significant results for image recognition. It is one of the deep learning methods that are commonly used for image analysis, detection, and recognition [
13]. It attempts to mimic picture recognition processes in human visual conceptions. A CNN imitates the concept of human nerves by connecting one neuron to the next. A CNN requires parameters to characterize the properties of each network used for object detection. A CNN is comprised of neurons, each of which has a weight, bias, and activation function for identifying images. A CNN’s design consists of two layers: the layer for feature extraction and the layer for completely connected nodes [
20].
Using a CNN and the DenseNet architecture [
21], this work classified images in order to identify diseases on the leaves of tomato plants. It is one of the CNN architectures with the dense block characteristic, where blocks on each layer are indirectly connected to all layers [
22]. It has various benefits, including easing the challenge of altering a variable, enhancing feature rollout, and drastically decreasing the number of parameters. In this architecture, each dense block receives input from the pixel picture in the form of a matrix, which is subsequently processed by the batch normalization layer. This layer aids to prevent overtraining during workouts. This architecture also includes a bottleneck layer whose purpose is to limit the quantity of input feature maps in order to boost computation efficiency. This work implemented a mobile, Indonesian language application for detecting diseases on tomato plant leaves, allowing farmers in Indonesia to readily diagnose tomato plant leaf diseases.
2. Related Works
Disease detection in tomato plants has been studied a lot. The early detection and classification of diseases affecting tomato plants can help farmers avoid using costly crop pesticides and increase food production. CNNs have been widely implemented to solve this problem because of their superiority in processing images. A portion of the current research focuses not only on model design but also on preprocessing processes, classification types, and implementation platforms.
Although a lot of work has been put forth to classify illnesses that might affect tomatoes [
23], it is still a challenge to quickly locate and identify different types of tomato leaf diseases due to the striking similarities between healthy and diseased plant leaf parts. As if this were not enough to complicate things, the procedure for detecting plant leaf diseases is further hampered by the poor contrast information between the background and foreground of a suspicious sample. Tomato plant leaf disease classification is a challenging problem. This research produced a strong deep learning (DL)-based technique, called ResNet-34-based Faster-RCNN, to tackle this problem. This technique created annotations for photographs that might be suspect in order to pin down a target area. Furthermore, this technique included ResNet-34 in Faster-Feature RCNN’s extractor module alongside the convolutional block attention module (CBAM) to pull out the underlying nuggets of information. Finally, the computed features were used for training the Faster-RCNN model to detect and label the various leaf abnormalities in tomato plants. The precision was 99.97%.
The use of a CNN for the detection of tomato diseases was also carried out by Guerrero-Ibaez et al. [
24]. They used a publicly available dataset and supplemented it with images captured in the field to propose a CNN model. Generative adversarial networks were utilized to create samples that were similar to the training data without leading to overfitting. It was shown that the proposed approach was highly effective at detecting and classifying tomato illnesses. Another approach to preprocessing was described in research conducted by Chen et al. [
25]. Because of environmental noise during image acquisition, the current machine vision technology for tomato leaf disease recognition has a hard time distinguishing between diseases because their symptoms are so similar. Because of this, they recommended a new model for identifying diseases in tomato leaves. In the first step, the image is denoised and enhanced with the help of the binary wavelet transform and Retinex, which remove noise points and edge points while keeping the useful texture information. The artificial bee colony optimization of the KSW algorithm was then used to isolate the tomato leaves from the rest of the image. Finally, the images were identified using a model of a both-channel residual attention network. According to the data from 8616 images used in the application, the overall detection accuracy was close to 89%.
Agarwal et al. proposed a streamlined CNN model with only eight hidden layers [
26]. When applied to the open-source dataset PlantVillage, the proposed lightweight model outperformed both traditional machine learning methods and pre-trained models with an accuracy of 98.4%. In the PlantVillage dataset, 39 classes represent various crops such as apples, potatoes, corn and grapes, and 10 classes represent various diseases that affect tomatoes. In pretrained models, VGG16 achieved an accuracy of 93.5%, while the best accuracy obtained using traditional ML methods was 94.9% with k-NN. After image enhancement, the proposed CNN’s performance was improved through the use of image pre-processing, specifically by adjusting the image’s brightness using a random value. The proposed model achieved a remarkable level of accuracy (98.7%) across a variety of datasets, not just PlantVillage. Other architectures that were used for the detection of tomato diseases include an attention-based CNN [
27], transfer-learning-based deep convolutional neural networks [
28], Google Le-Net Inception V3 [
29], an attention-embedded residual CNN [
30], and AlexNet [
31]. Some research also mentioned the development of the platform used. The platforms that are widely used are mobile-based applications, as carried out in research by Gonzalez-Huitron et al. [
32], Elhassouny et al. [
33], Ngugi et al. [
34], and Verma et al. [
35].
3. Methodology
Data collection, preprocessing, data augmentation, data separation by separating training data, and data validation were among the stages of the research [
36]. The training data was utilized to construct the output of the model. During the model evaluation utilizing the k-fold cross-validation method, data validation was utilized. If the model had not yielded ideal results, iterations were repeated. If the optimal model had been established, it was then saved and applied in the program for the end user.
3.1. Data Collection
The data in this study was image data of diseases on tomato plant leaves taken from the Kaggle website The data were obtained by downloading it from
https://www.kaggle.com/datasets/kaustubhb999/tomatoleaf, accessed on 3 November 2022. There are 1000 types of images for each type of disease on tomato plant leaves. By taking 10 disease classes, data from 10,000 images were obtained.
Figure 1 is a sample of each disease on tomato plant leaves. Each image’s dimensions are 256 by 256. Both the horizontal and vertical resolutions are 96 dpi. The bit depth is 24.
3.2. Image Preprocessing and Augmentation
Image preprocessing is a phase that prepares image data for subsequent processing [
37]. This step must be completed in order for the data to run efficiently on the intended model. Image augmentation, meanwhile, is a method to increase the amount of data by altering the image’s shape, either by modifying the image’s rotation, position, or size [
38]. Both phases of this research are mentioned below:
Rescale is a preprocessing step that modifies the image’s size [
39]. When the image is present in the application, it is represented by a value between 0 and 255. However, rescaling is conducted if the range of values is too large for the training procedure to be executed. The image value was divided by 255 so that it fell inside the range of 0 to 1.
As depicted in
Figure 2, this is accomplished randomly by rotating the image clockwise a specified number of degrees between 0 and 90 degrees [
40]. This research employed a rotation range of forty degrees.
A shift is an enhancement technique for image movement [
41]. It is performed to provide more varied picture data for image positions. There are two sorts of shift ranges: width and height. The height and breadth are respectively vertical and horizontal position shifts.
Figure 3 and
Figure 4 depict the implementations used in this investigation.
Zoom is an augmentation technique for changing the size of an image [
42]. It is intended that the image be more diverse in terms of size, as shown in
Figure 5.
3.3. Data Splitting
Data splitting is the division of a dataset into multiple sections. In this study, the dataset was separated into training and testing data, where 10,000 training data and 1000 test data were used. The training data were used to develop the model, whilst the testing data were used to evaluate the model. In data training, data was also divided into 2 components, called data training and data validation. In order to conduct the validation, a 10-fold cross-validation technique was implemented.
3.4. Modeling
The objective of determining the proper hyperparameter is to create the ideal model. As indicated in
Table 2, this study evaluated three types of hyperparameters, namely, the hidden layer, the trainable layer, and the dropout value of the layer.
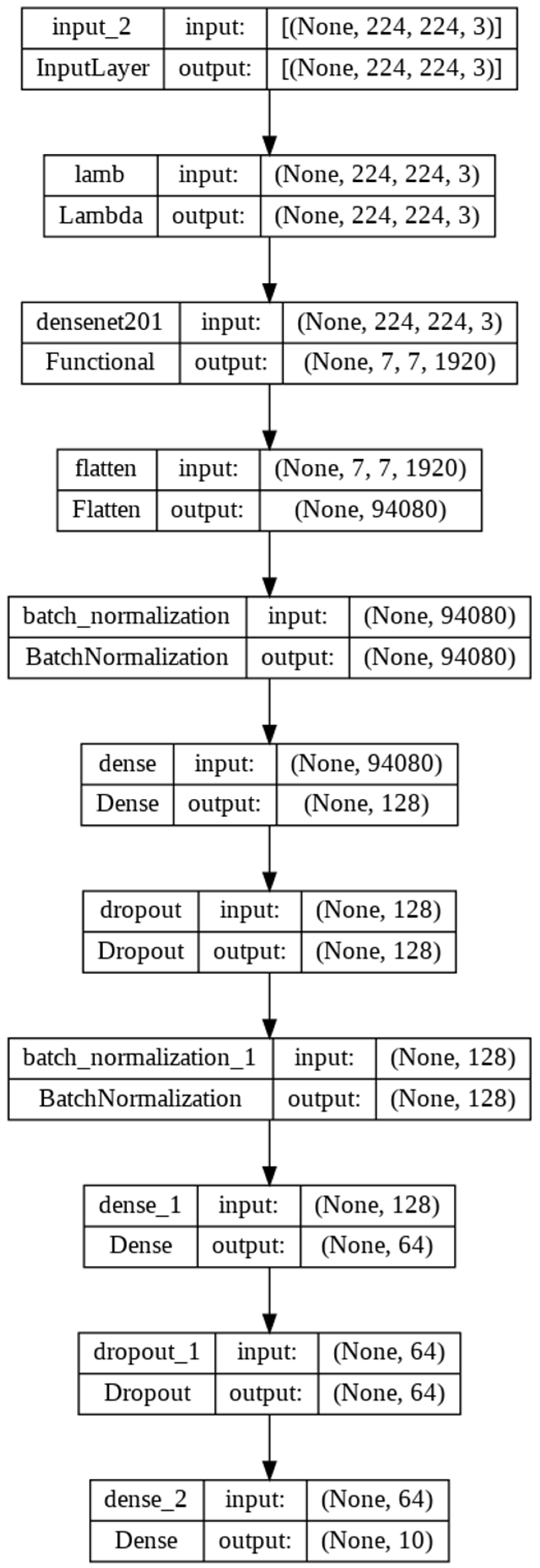
This study was constructed using Python and the Keras library. In Keras, the layers are defined progressively. The DenseNet layer, which was the initial layer, used an input value of 224 × 224. There were five levels of dense block. The first dense block layer received a 112 × 112 input and was convolved once. With a 56 × 56 input, the second dense block layer was convolved six times. With a 28 × 28 input, the third dense block layer was convolved twelve times. The fourth dense block layer was convolved 48 times with a 14 × 14 input, while the fifth dense block layer was convolved 32 times with a 7 × 7 input. The output was then applied to the flattened layer. The layer transformed data into 1-D vectors that could then be utilized by the fully connected layer. The subsequent step was to process the layer of batch normalization. This layer was used to standardize the data input. It could also accelerate the data training process and enhance the model’s performance. The following layer was the dropout layer, which was used to prevent overfitting. The dense layer comprised 10 units based on the number of classified classes. Prior to training, there were three configurations, including the loss function employing categorical cross-entropy and the Adam optimizer with a learning rate of 0.01. The structure can be seen in
Figure 6.
3.5. Evaluation
This step evaluated the model using test data. It aimed to ensure that the model ran well. If the model did not display a good performance, then the model must be repaired. This study evaluated the model based on a confusion matrix, which showed how frequently correct and incorrect detections were made during classification. There were four possible permutations of predicted and actual values. The confusion matrix contained four columns labeled with the four possible outcomes of the classification process: true positive, true negative, false positive, and false negative. Accuracy, precision, recall, and F-1 scores can be calculated using these four factors. Accuracy describes how accurately the model can correctly classify. Therefore, accuracy is the ratio of correct predictions (positive and negative) to the entire set of data. In other words, accuracy is the degree of closeness of the predicted value to the actual value. Precision describes the level of accuracy between the requested data and the predicted results provided by the model. Thus, precision is defined as the ratio of the correct positive predictions to the overall positive predictions. Recall describes the success of the model in retrieving information. Thus, recall is the ratio of the correct positive predictions compared with all of the correct positive data. The F1-score is a combination of precision and recall.
3.6. Application
After locating the ideal model, the next stage was to develop an application for end users. The construction of the application utilized the Android platform and the Flutter application development framework. We incorporated the best model from the previous phase into the Android-based application.
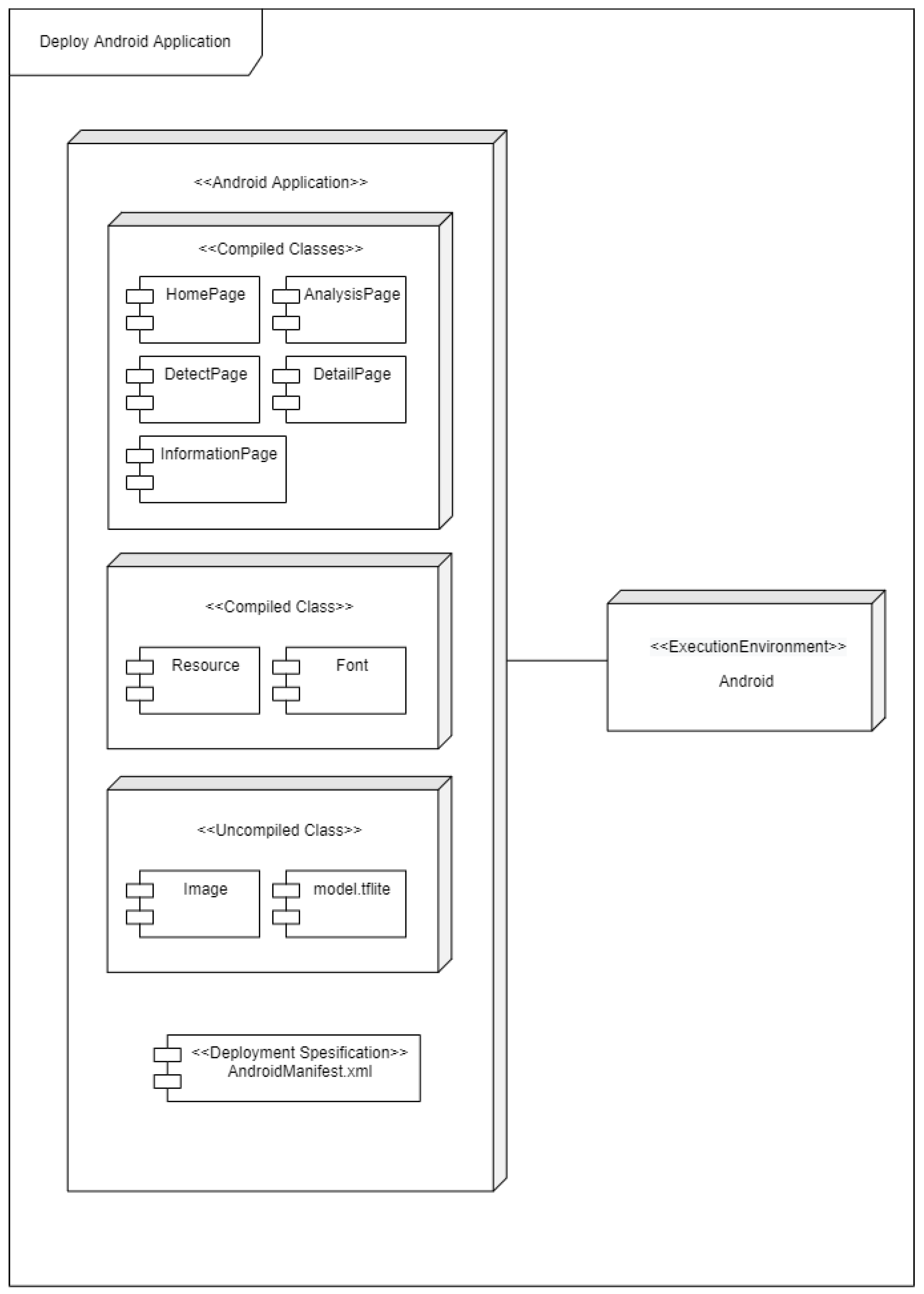
Figure 7 illustrates the deployment diagram. The Android program and the execution environment are the two nodes. There are four sections in the Android application section: compiled classes, compiled resources, uncompiled resources, and deployment specifications. This is the portion of the code that is run in the execution environment.
5. Discussion
After completing the trials on hyperparameters discussed in the preceding chapter, the research obtained values for these parameters that were deemed ideal.
Table 6 gives the ideal hyperparameter values. The model was then evaluated using the test data that had been previously separated. As shown in
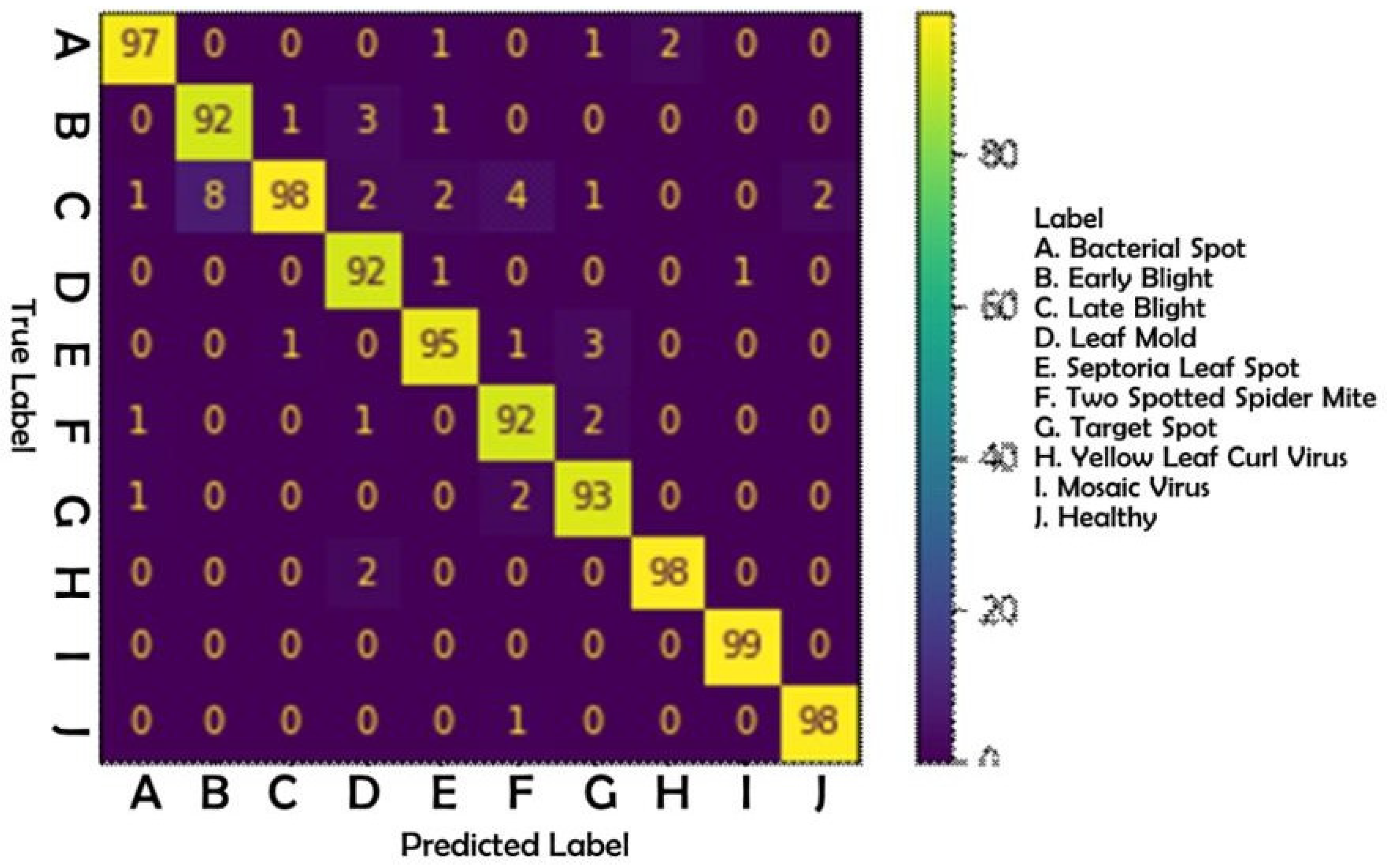
Figure 8, the results of this test were produced in the form of a confusion matrix table. Following is an examination of
Table 7:
Based on the precision value, it could be seen that mosaic virus disease received a score of 100 percent, whereas late blight disease received a score of 83 percent. The low precision value of late blight disease was caused by a high number of false positives. This occurred as a result of the detection of late blight disease in cases of other diseases. Based on the dataset at hand, the late blight illness possessed more diversified traits that resulted in misclassification.
According to the recall value, mosaic virus disease received the highest score of 99 percent, while two-spotted spider mite, leaf mold, and early blight disease received the lowest score of 92 percent. Due to a high percentage of false negatives on the label, the evaluation score for these three diseases was the lowest. This occurred due to detection errors, such as the misidentification of leaf mold illness as another disease. According to the data, two-spotted spider mites, leaf mold, and early blight likely resemble other diseases, particularly late blight.
The accuracy and F1-score in this study were 95.40% and 95.44%, respectively. With these values, along with the training, which had an accuracy of 95.79%, it can be concluded that the model had a good performance.
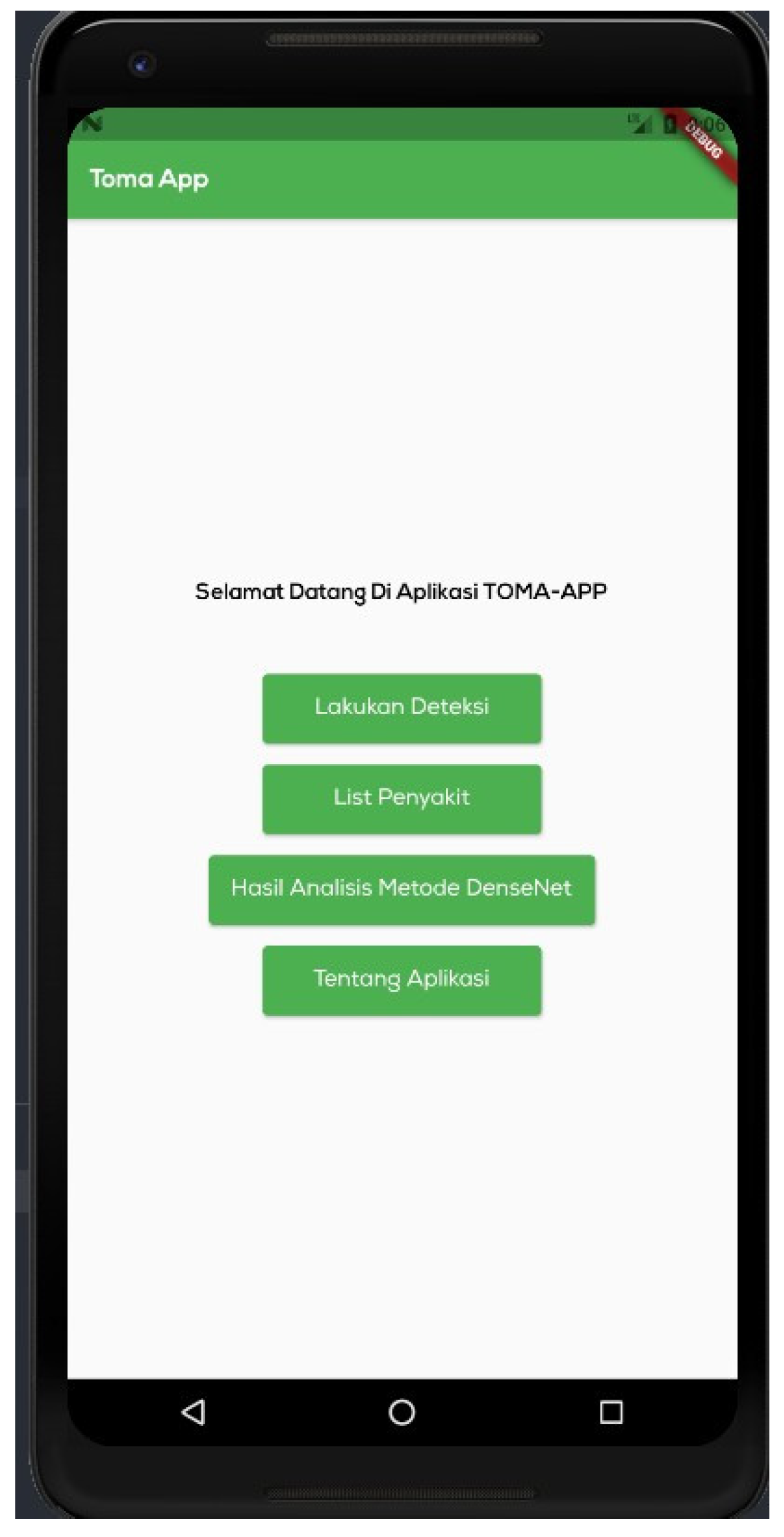
After identifying the optimal model, the authors of this study created an Android-based mobile application. The intended audience consisted of Indonesian farmers, hence the instructional language was Indonesian. Four primary menus make up the application: disease detection, disease list, analysis findings, and application description.
Figure 9 depicts the home page.
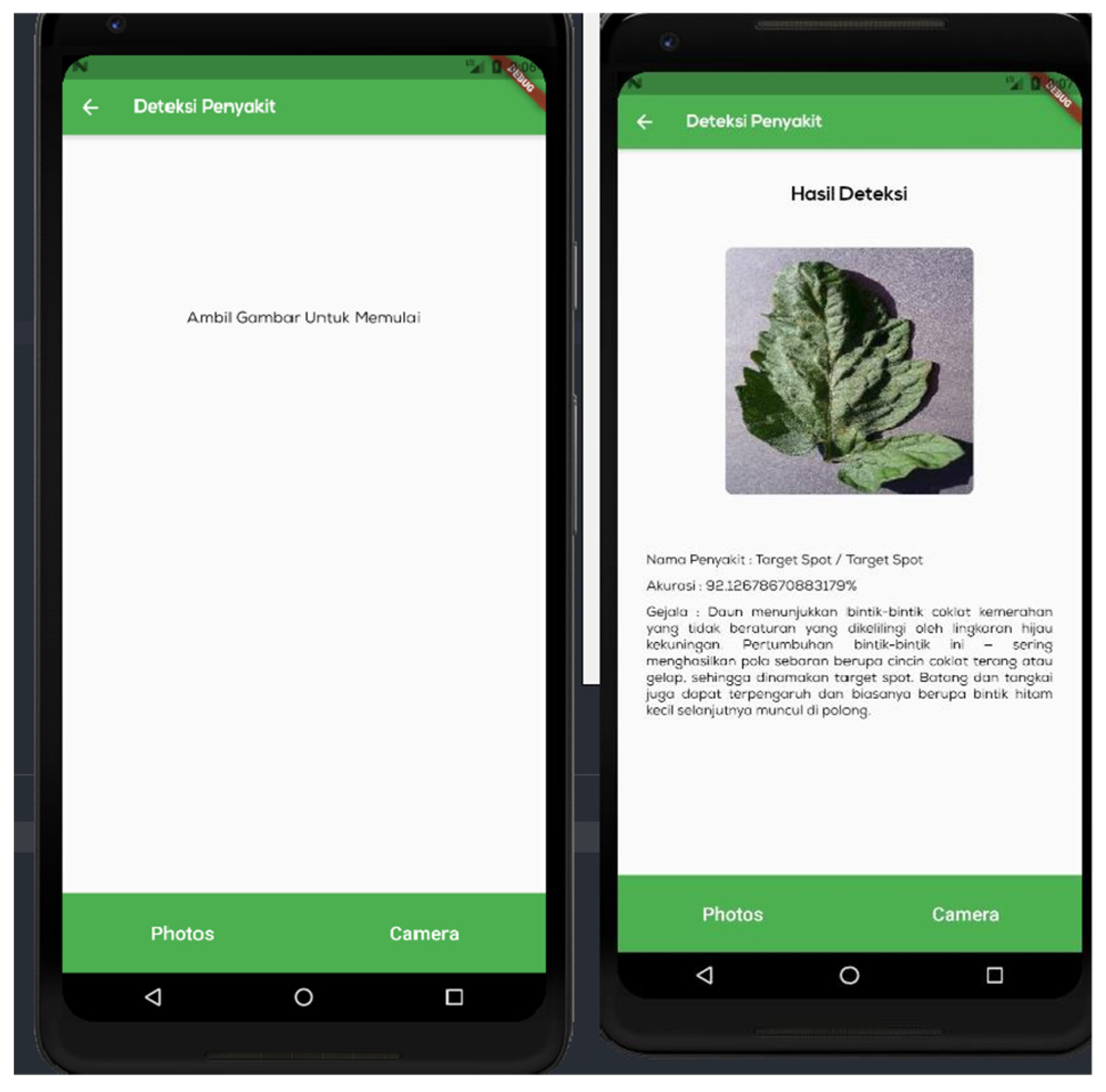
Figure 10 shows the ‘disease detection’ menu, which is a page for detecting illnesses on the leaves of tomato plants. On this page, the user will enter data to be processed by the DenseNet model. The model will detect the ailment that most closely corresponds to the visual input. There are two methods for importing photos: the camera and the gallery.
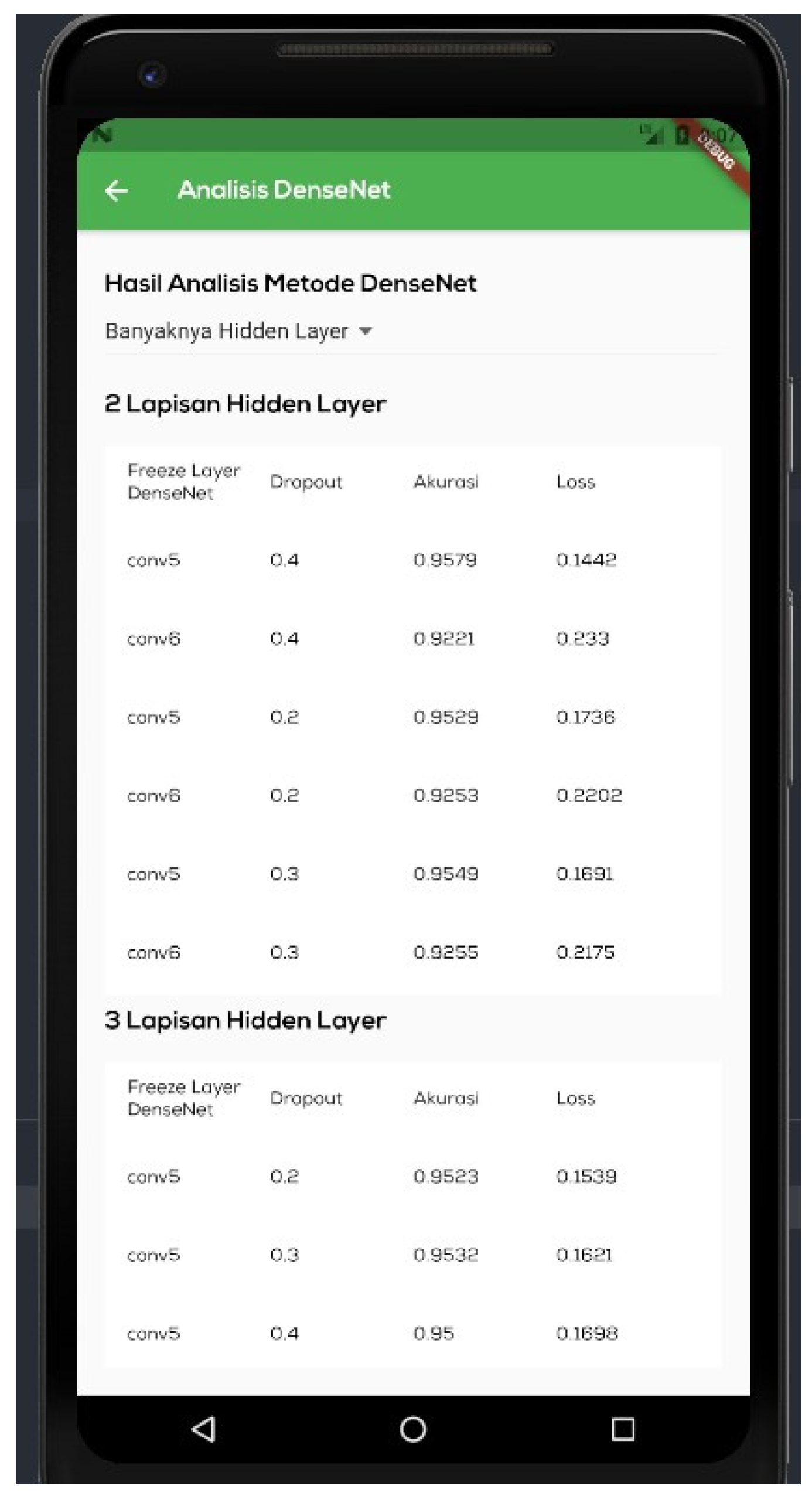
Figure 11 shows an ‘analysis results’ menu, which is the page displaying the outcomes of the conducted trials. This page contains a performance table of the model for each tested hyperparameter. Three hyperparameters, namely, the hidden layer, the dropout rate, and the trainable dense layer, are evaluated.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}