
An Improved Multilabel k-Nearest Neighbor Algorithm Based on Value and Weight

Abstract
:1. Introduction
2. Related Work
3. Methods
3.1. Related Definitions
3.2. Proposed Algorithm
| Algorithm 1: VWML-kNN | |
| Input: A multi-label dataset D, test instance x | |
| 1. | For i = 1 to m do: |
| 2. | Identify k nearest neighbors N(xi) of xi |
| 3. | end for |
| 4. | For j = 1 to q do: |
| 5. | Calculate the IR and MeanIR according to Equations (1) and (3) |
| 6. | Estimate the prior probabilities P(yj= 1) and P(yj= 0) according to Equations (5) and (6) |
| 7. | If the label j of xi is 1 (yij = 1) and xi has z nearest neighbors containing label j |
| 8. | hj[z] = hj[z] + 1 and hj[z] = hj[z]−1 |
| 9. | Else h’j[z] = h′j[z] + 1 and hj[z] = hj[z]−1 |
| 10. | end for |
| 11. | Identify k nearest neighbors N(x) of x |
| 12. | For j = 1 to q do: |
| 13. | Calculate Cj(x) according to Equation (4) |
| 14. | Calculate the hj[z] and h’j[z] of x according to step 7 to step 9 |
| 15. | If j = = majority label, return y according to Equations (11) and (12) |
| 16. | If j = = minority label, calculate the distance (s, d′) between NconSet and x. |
| 17. | Convert distance to weight according to Equation (13) |
| 18. | Return y according to Equation (15) |
| 19. | end for |
| 20. | end |
3.3. Evaluation Metrics
3.4. Datasets
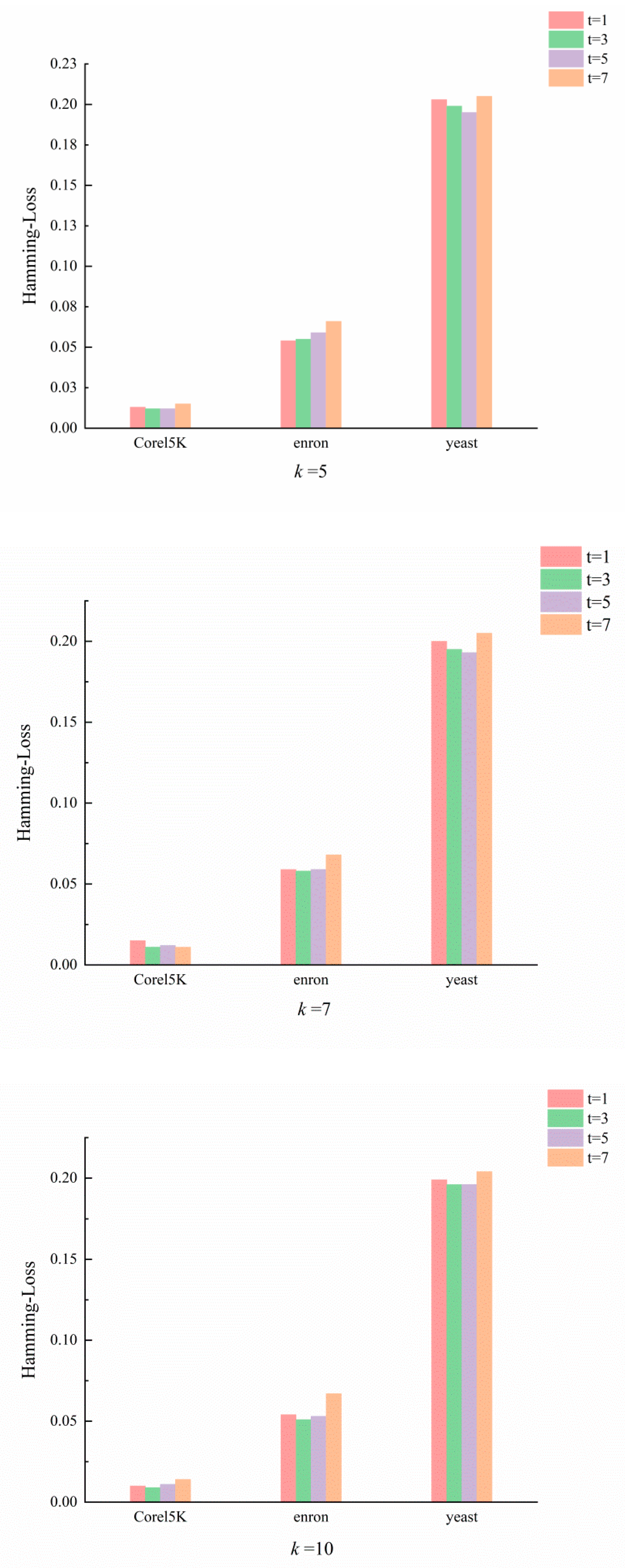
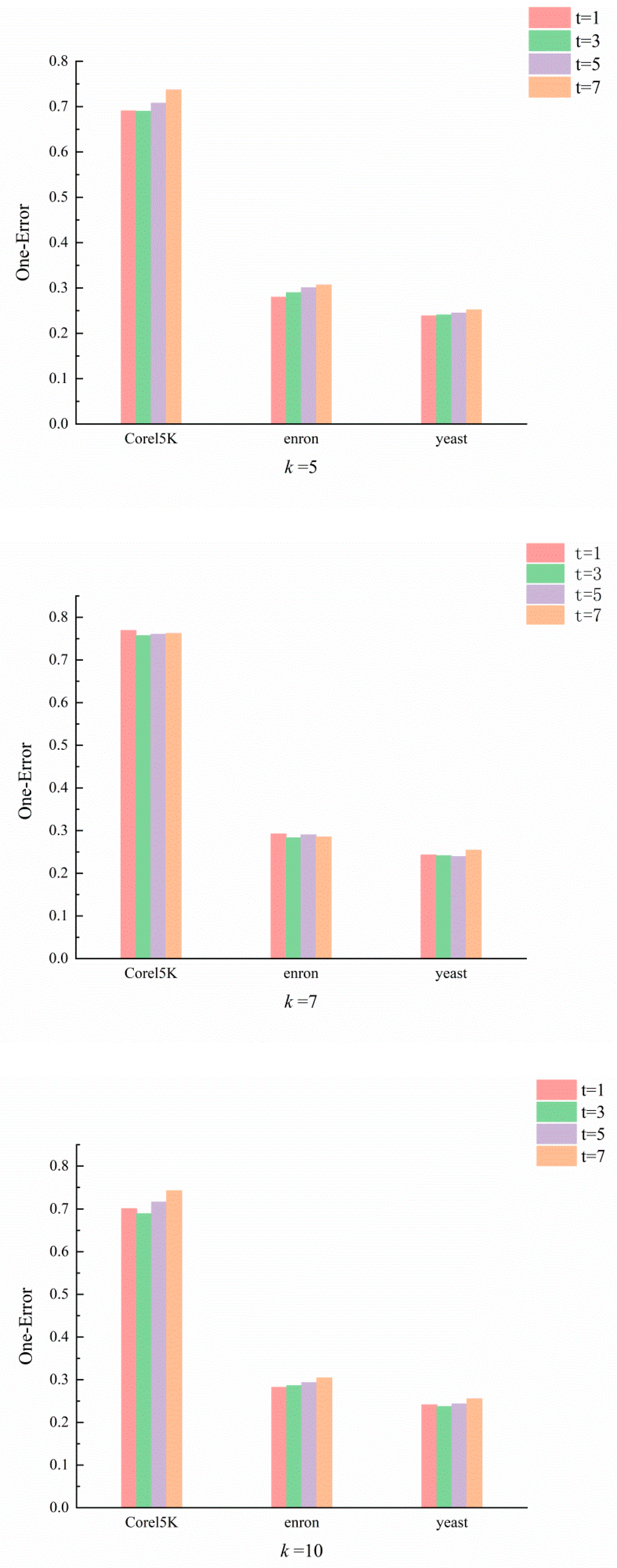
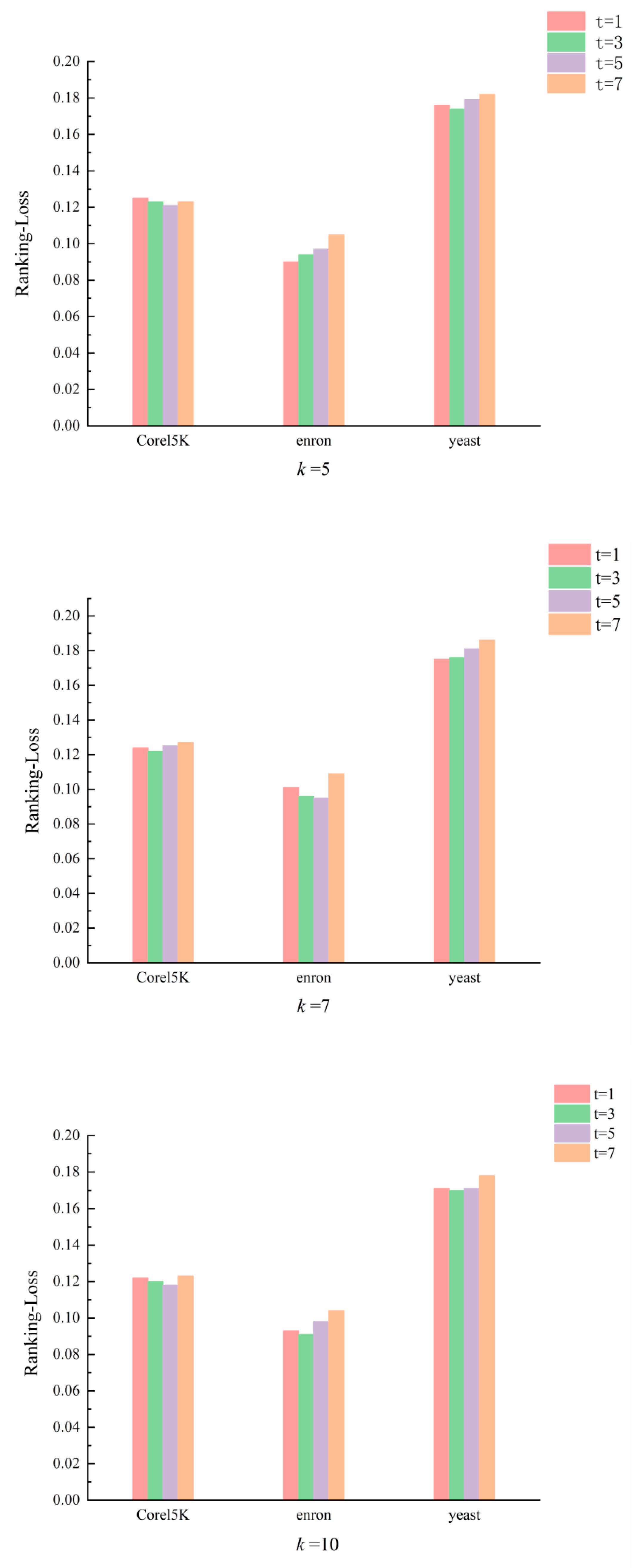
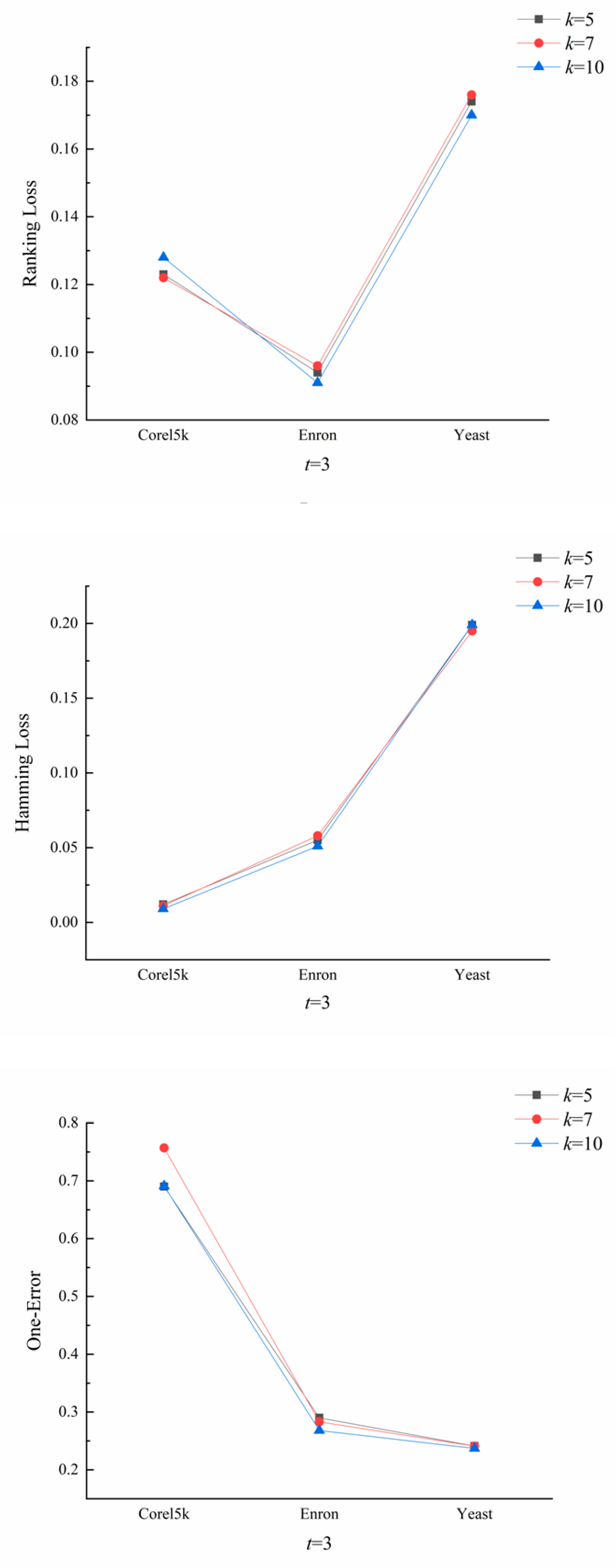
4. Results and Discussion
4.1. Optimal Values of k and t
4.2. Experiments and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qian, W.; Huang, J.; Wang, Y.; Xie, Y. Label distribution feature selection for multi-label classification with rough set. Int. J. Approx. Reason. 2021, 128, 32–35. [Google Scholar] [CrossRef]
- Maser, M.; Cui, A.; Ryou, S.; Delano, T.; Yue, Y.; Reisman, S. Multilabel Classification Models for the Prediction of Cross-Coupling Reaction Conditions. J. Chem. Inf. Model. 2021, 61, 156–166. [Google Scholar] [CrossRef]
- Bashe, A.; Mclaughlin, R.J.; Hallam, S.J. Metabolic pathway inference using multi-label classification with rich pathway features. PLoS Comput. Biol. 2020, 16, e1008174. [Google Scholar]
- Che, X.; Chen, D.; Mi, J.S. A novel approach for learning label correlation with application to feature selection of multi-label data. Inf. Sci. 2019, 512, 795–812. [Google Scholar] [CrossRef]
- Huang, M.; Sun, L.; Xu, J.; Zhang, S. Multilabel Feature Selection Using Relief and Minimum Redundancy Maximum Relevance Based on Neighborhood Rough Sets. IEEE Access 2020, 8, 62011–62031. [Google Scholar] [CrossRef]
- Chen, Z.M.; Wei, X.S.; Jin, X.; Guo, Y.W. Multi-label image recognition with joint class-aware map disentangling and label correlation embedding. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo, Shanghai, China, 8–12 July 2019; pp. 622–627. [Google Scholar]
- Ben-Cohen, A.; Zamir, N.; Ben-Baruch, E.; Friedman, I.; Zelnik-Manor, L. Semantic Diversity Learning for Zero-Shot Multi-Label Classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montral, QC, Canada, 10–17 October 2021; pp. 640–650. [Google Scholar]
- Yu, G.; Domeniconi, C.; Rangwala, H.; Zhang, G.; Yu, Z. Transductive multi-label ensemble classification for protein function prediction. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2018; pp. 1077–1085. [Google Scholar]
- Maltoudoglou, L.; Paisios, A.; Lenc, L.; Martinek, J.; Kral, P.; Papadopoulos, H. Well-calibrated confidence measures for multi-label text classification with a large number of labels. Pattern Recognit. 2022, 122, 108271. [Google Scholar] [CrossRef]
- Maragheh, H.K.; Gharehchopogh, F.S.; Majidzadeh, K.; Sangar, A.B. A new hybrid based on long short-term memory network with spotted hyena optimization algorithm for multi-label text classification. Mathematics 2022, 10, 488. [Google Scholar] [CrossRef]
- Bhusal, D.; Panday, S.P. Multi-label classification of thoracic diseases using dense convolutional network on chest radiographs. arXiv 2022, arXiv:2202.03583. [Google Scholar]
- Xu, H.; Cai, Z.; Li, W. Privacy-preserving mechanisms for multi-label image recognition. ACM Trans. Knowl. Discov. Data 2022, 16, 1–21. [Google Scholar] [CrossRef]
- García-Pedrajas, N.E. ML-k’sNN: Label Dependent k Values for Multi-Label k-Nearest Neighbor Rule. Mathematics 2023, 11, 275. [Google Scholar]
- Crammer, K.; Singer, Y. On the algorithmic implementation of multiclass kernel-based vector machines. J. Mach. Learn. Res. 2002, 2, 265–292. [Google Scholar]
- Gao, B.B.; Zhou, H.Y. Learning to Discover Multi-Class Attentional Regions for Multi-Label Image Recognition. IEEE Trans. Image Process. 2021, 30, 5920–5932. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.W.; Shie, B.E.; Yu, P.S.; Tseng, V.S. Mining top-K high utility itemset. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 78–86. [Google Scholar]
- Godbole, S.; Sarawag, S.I. Discriminative methods for multi-labeled classification. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 26–28 May 2004; pp. 22–30. [Google Scholar]
- Boutell, M.R.; Luo, J.; Shen, X.; Brown, C.M. Learning multi-label scene classification. Pattern Recognit. 2004, 37, 1757–1771. [Google Scholar] [CrossRef]
- Elisseeff, A.E.; Weston, J. A kernel method for multi-labelled classification. In Proceedings of the 14th International Conference on Neural Information Processing Systems: Natural and Synthetic, Vancouver, BC, Canada, 3–8 December 2001; pp. 681–687. [Google Scholar]
- Zhang, M.L.; Zhou, Z.H. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognit. 2007, 40, 2038–2048. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Zhou, Z. A Review on Multi-Label Learning Algorithms. IEEE Trans. Knowl. Data Eng. 2014, 26, 1819–1837. [Google Scholar] [CrossRef]
- Li, J.; Li, P.; Hu, X.; Yu, K. Learning common and label-specific features for multi-Label classification with correlation information. Pattern Recognit. 2022, 121, 108259. [Google Scholar] [CrossRef]
- Younes, Z.; Abdallah, F.; Denoeu, T.X. Multi-label classification algorithm derived from k-nearest neighbor rule with label dependencies. In Proceedings of the 2008 16th European Signal Processing Conference, Lausanne, Switzerland, 25–29 August 2008; pp. 1–5. [Google Scholar]
- Cheng, W.; Hüllermeier, E. Combining instance-based learning and logistic regression for multilabel classification. Mach. Learn. 2009, 76, 211–225. [Google Scholar] [CrossRef]
- Xu, J. Multi-label weighted k-nearest neighbor classifier with adaptive weight estimation. In Proceedings of the 18th International Conference on Neural Information Processing, Shanghai, China, 13–17 November 2011; pp. 79–88. [Google Scholar]
- Zhang, M. An Improved Multi-Label Lazy Learning Approach. J. Comput. Res. Dev. 2012, 49, 2271–2282. [Google Scholar]
- Reyes, O.; Morell, C.; Ventura, S. Evolutionary feature weighting to improve the performance of multi-label lazy algorithms. Integr. Comput. Aided Eng. 2014, 21, 339–354. [Google Scholar] [CrossRef]
- Zeng, Y.; Fu, H.M.; Zhang, Y.P.; Zhao, X.Y. An Improved ML-kNN Algorithm by Fusing Nearest Neighbor Classification. DEStech Trans. Comput. Sci. Eng. 2017, 1, 193–198. [Google Scholar] [CrossRef]
- Vluymans, S.; Cornelis, C.; Herrera, F.; Saeys, Y. Multi-label classification using a fuzzy rough neighborhood consensus. Inf. Sci. 2018, 433–434, 96–114. [Google Scholar] [CrossRef]
- Wang, D.; Wang, J.; Hu Fei Li, L.; Zhang, X. A Locally Adaptive Multi-Label k-Nearest Neighbor Algorithm. In Proceedings of the Pacific-Asia conference on knowledge discovery and data mining, Melbourne, Australia, 3–6 June 2018; pp. 81–93. [Google Scholar]
- Charte, F.; Rivera, A.; Del Jesus, M.J. Addressing imbalance in multilabel classification: Measures and random resampling algorithms. Neurocomputing 2015, 163, 3–16. [Google Scholar] [CrossRef]
- Madjarov, G.; Kocev, D.; Gjorgjevikj, D.; Dzeroski, S. An extensive experimental comparison of methods for multi-label learning. Pattern Recognit. 2012, 45, 3084–3104. [Google Scholar] [CrossRef]
- Charte, F.; Rivera, A.; Del Jesus, M.J.; Herrera, F. Dealing with difficult minority labels in imbalanced multilabel data sets. Neurocomputing 2019, 326, 39–53. [Google Scholar] [CrossRef]
- Tsoumakas, G.; Spyromitros-Xioufis, E.; Vilcek, J.; Vlahavas, I. Mulan: A java library for multi-label learning. J. Mach. Learn. Res. 2011, 12, 2411–2414. [Google Scholar]
- Zhou, S.; Li, X.; Dong, Y.; Xu, H. A Decoupling and Bidirectional Resampling Method for Multilabel Classification of Imbalanced Data with Label Concurrence. Sci. Program. 2020, 2020, 8829432. [Google Scholar] [CrossRef]
- Charte, F.; Rivera, A.; Del Jesus, M.J.; Herrera, F. Concurrence among imbalanced labels and its influence on multilabel resampling algorithms. In Proceedings of the International Conference on Hybrid Artificial Intelligence Systems, Salamanca, Spain, 11–13 June 2014; pp. 110–121. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Instances | Labels | Dens | Card | MeanIR | TCS |
|---|---|---|---|---|---|---|
| Enron | 1702 | 53 | 0.064 | 3.378 | 73.953 | 17.503 |
| Corel5k | 5000 | 374 | 0.009 | 3.522 | 189.568 | 20.200 |
| Yeast | 2417 | 14 | 0.303 | 4.240 | 7.200 | 12.560 |
| Algorithm | Hloss | Rloss | O-e |
|---|---|---|---|
| BR | 0.056 | 0.168 | 0.453 |
| LAML-kNN | 0.052 | 0.092 | 0.264 |
| DML-kNN | 0.053 | 0.093 | 0.285 |
| ML-kNN | 0.053 | 0.093 | 0.281 |
| VWML-kNN | 0.051 | 0.091 | 0.268 |
| Algorithm | Hloss | Rloss | O-e |
|---|---|---|---|
| BR | 0.011 | 0.146 | 0.742 |
| LAML-kNN | 0.010 | 0.129 | 0.706 |
| DML-kNN | 0.010 | 0.132 | 0.732 |
| ML-kNN | 0.009 | 0.134 | 0.727 |
| VWML-kNN | 0.009 | 0.128 | 0.691 |
| Algorithm | Hloss | Rloss | O-e |
|---|---|---|---|
| BR | 0.203 | 0.205 | 0.240 |
| LAML-kNN | 0.201 | 0.170 | 0.241 |
| DML-kNN | 0.203 | 0.172 | 0.242 |
| ML-kNN | 0.201 | 0.170 | 0.235 |
| VWML-kNN | 0.199 | 0.170 | 0.237 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Xu, H.; Zhou, P.; Xiao, G. An Improved Multilabel k-Nearest Neighbor Algorithm Based on Value and Weight. Computation 2023, 11, 32. https://doi.org/10.3390/computation11020032
Wang Z, Xu H, Zhou P, Xiao G. An Improved Multilabel k-Nearest Neighbor Algorithm Based on Value and Weight. Computation. 2023; 11(2):32. https://doi.org/10.3390/computation11020032
Chicago/Turabian StyleWang, Zhe, Hao Xu, Pan Zhou, and Gang Xiao. 2023. "An Improved Multilabel k-Nearest Neighbor Algorithm Based on Value and Weight" Computation 11, no. 2: 32. https://doi.org/10.3390/computation11020032
APA StyleWang, Z., Xu, H., Zhou, P., & Xiao, G. (2023). An Improved Multilabel k-Nearest Neighbor Algorithm Based on Value and Weight. Computation, 11(2), 32. https://doi.org/10.3390/computation11020032