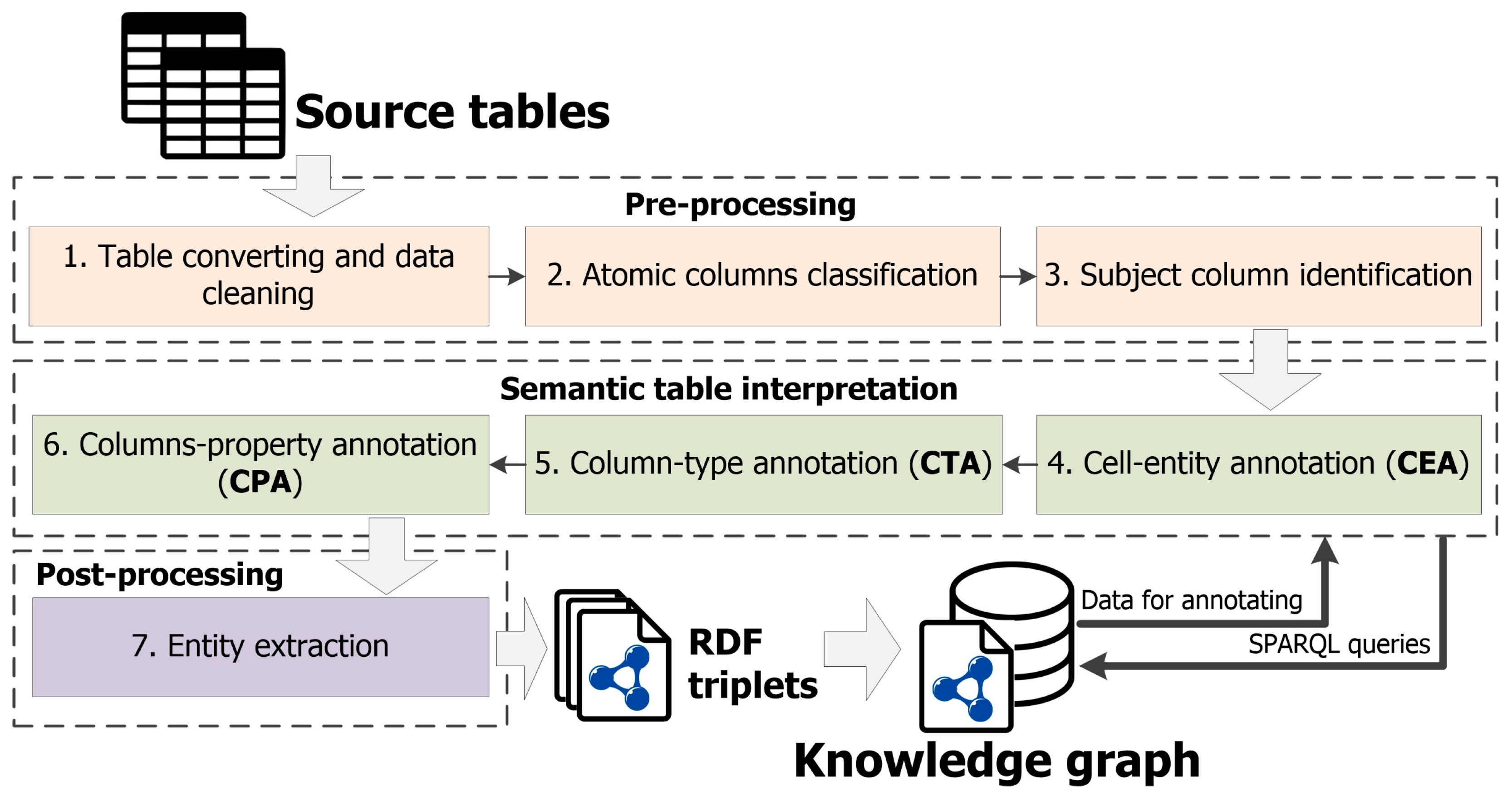
3.2. Main Stages
The approach can be represented as a sequence of main stages (see
Figure 2).
Next, let us take a closer look at these stages:
Stage 1. Table converting and data cleaning. Source tables are converted from various formats (e.g., CSV, XLSX, and JSON) to an object model representation (e.g., in Python). At the same time, tabular data is cleared for further correct table processing. For example, the ftfy library [
60] is used to restore incorrect Unicode characters and HTML tags. Moreover, multiple spaces and various “garbage” characters are removed.
Stage 2. Atomic columns classification. At this stage, named entity columns and literal columns are defined using Stanford NER (Named-Entity Recognizer) [
61], which is an open-source library for natural language processing. This recognizer identifies various named entities, such as persons, companies, locations, and others, in a source text. Stanford NER has many NER classes for this purpose. These classes are assigned to each cell in a source table, so classes characterize the data contained in the cells. Depending on the assigned NER class, a cell can be either categorical or literal.
Table 1 shows the mappings between NER classes and atomic types (categorical or literal) of cell values. Thus, the atomic column type is determined based on the total number of defined categorical and literal cells.
However, Stanford NER does not perform well on short texts presented in the cells. For this reason, the regular expression mechanism and the Haskell library, namely Duckling [
62], are used to refine an undefined NER class “NONE” and a numeric NER class “CARDINAL”. Duckling supports many languages and defines a set of various dimensions (e.g., AmountOfMoney, CreditCardNumber, Distance, Duration, Email, Numeral, Ordinal, PhoneNumber, Quantity, Temperature, Time, Url, Volume). We also used the DateParser open-source library [
63] for better determination of the date and time in various formats. In addition, specific NER classes are introduced to define identifiers and a pair of alphabetic or numeric characters represented in a cell. Thus, all additional clarifying NER classes belong to a literal cell type and are presented in
Table 2.
Stage 3. Subject column identification. The purpose of this stage is to automatically determine a subject column from named entity columns. We use special main heuristics [
36] and our own additional heuristics to solve this task:
Fraction of empty cells (emc) is the number of empty cells divided by the number of rows in a named entity column;
Fraction of cells with acronyms (acr) is the number of cells containing acronyms divided by the number of rows in a named entity column;
Fraction of cells with unique content (uc) is the number of cells with unique text content divided by the number of rows in a named entity column;
Distance from the first named entity column (df) is calculated as the left offset of the current named entity column relative to the first candidate subject column;
The average number of words (aw) is calculated as the average number of words in the cells of each named entity column. The best candidate is a column with the highest average number of words per cell;
Prepositions in column header (hpn). If a header name is a preposition, then a named entity column is probably not a subject column but most likely forms a relationship with this column.
It should be noted that uc and aw are the main indicative characteristics of a subject column in a source table. aw can potentially be very large because a named entity column can contain a large text with a description. In this case, we introduce a threshold factor k that determines a long text in column cells. By default, k = 10. Thus, if current aw ≤ k, then new aw = the average number of words in a cell/k. However, if current aw > k, then new aw = 0.
Heuristics of emc, acr, and hpn are penalized, and the overall score for a target column is normalized by its distance from the leftmost named entity column (df).
The score of all heuristics takes a value in the [0, 1] range.
The overall aggregated score can be calculated using all six heuristics with the aid of the subcol function. This score determines the final probability that a certain named entity column
mj is most suitable as a subject column. Thus, a named entity column with the highest score of the subcol function is defined as a subject column. We also use special weighting factors that balance the importance of each heuristic.
where
wuc,
waw,
wemc,
warc,
whpn are weighting factors. By default,
wuc = 2 and all other weighting factors are 1.
Stage 4. Cell-entity annotation. At this stage, the procedure of entity linking is carried out, and it includes two consecutive steps:
An example of SPARQL query for lexical matching N-grams of a cell value with entities from DBpedia knowledge graph is shown below:
SELECT DISTINCT (str(?subject) as ?subject) (str(?label) as ?label) (str(?comment) as ?comment)
WHERE {
?subject a ?type.
?subject rdfs:comment ?comment.
?subject rdfs:label ?label.
?label <bif:contains> ‘<cell value 1>‘ AND ‘<cell value 2>‘ ….
FILTER NOT EXISTS { ?subject dbo:wikiPageRedirects ?r2 }.
FILTER (lang(?label) = “en”).
FILTER (lang(?comment) = “en”)
}
ORDER BY ASC(strlen(?label))
LIMIT 100
Since a cell value can refer to multiple entities from a set of candidates, it is quite difficult to choose the most suitable (relevant) entity from this set. We propose an aggregated method for disambiguation between candidate entities and a cell value. This method consists of the sequential application of various heuristics and combining the scores (ranks) obtained with each heuristic. Let us take a closer look at the proposed heuristics:
String similarity. A relevant entity from a set of candidates for a cell value is selected based on lexical matching. We use the edit distance metric, in particular, the Levenshtein distance, for the maximum similarity of a sequence of characters:
where
f1(
ek) is a string similarity function based on the Levenshtein distance; e
k is a k-entity from a set of candidates.
The absolute score of the Levenshtein distance is a natural number, including zero. Therefore, we use the MinMax method to normalize this score to the range [0, 1]:
where
Xnorm is a normalized value;
X is a non-normalized source value;
Xmin is a minimum value from the possible range of acceptable values; and
Xmax is a maximum value from the possible range of acceptable values.
Using (3) and (4), we define the normalized string similarity function:
where
fn1(
ek) is a normalized string similarity function based on the Levenshtein distance;
max f1(
ek) is the maximum number of characters in
ek or
cv(i,j);
min f1(
ek) is the lower limit of the function range, while
min f1(
ek)
= 0.
This heuristic is a fairly simple and intuitive way to determine the similarity between a cell value and an entity from a set of candidates. However, text mentions of entities presented in the cells and candidate entities may differ significantly. Thus, this does not provide a sufficient level of correspondence, and additional information may be required (e.g., relationships of entities from a current set of candidates with candidate entities from other sets).
NER-based similarity. This heuristic is based on information about already recognized named entities (NER classes for the categorical cell type from
Table 1) in the cells at the stage of atomic column classification. We mapped these NER classes to corresponding classes from DBpedia (see
Table 3). It should be noted that it is not possible to match some target class from DBpedia to the undefined NER class “
NONE”.
Next, the correspondence between classes that type an entity from a set of candidates and classes from
Table 3 is determined. In this case, hierarchical relationships between classes can be used. For example, an entity “dbr:Team_Spirit” is only an instance of the class “dbo:MilitaryConflict” and has no direct relationship with the class “dbo:Event”, but this relationship can be restored through a hierarchical dependency of subclasses (“rdfs:subClassOf” is used), in particular: “dbo:MilitaryConflict”
“dbo:SocietalEvent”
“dbo:Event”. In other words, for each entity from a set of candidates, the nesting depth (remote distance) of its most specific class to a target class from
Table 3 is determined. The following SPARQL query is used to obtain this distance:
SELECT COUNT DISTINCT ?type
WHERE {
‘<candidate-entity>‘ rdf:type/rdfs:subClassOf* ?type.
?type rdfs:subClassOf* ?c.
FILTER (?c IN (‘<target-classes>‘))
}
If the obtained distance is greater than zero, then a NER-based similarity function f2(ek) = 1, and f2(ek) = 0 otherwise.
Entity embeddings-based similarity. This heuristic is based on the idea that data in a table column is usually of the same type, i.e., entities contained in a column usually belong to a single semantic type (class). Accordingly, in order to select a relevant entity, we have to select an entity from a set of candidates for which a semantic type (class) will be consistent with other types (classes) for other entities from a list of candidate sets that have been formed for different cell values in the same column of a source table. In other words, a candidate entity for some cell must be semantically similar to other entities in the same column.
For this purpose, we use the technique of knowledge graph embedding [
67]. Knowledge graph embedding aims to embed the entities and relationships of a target knowledge graph in low-dimensional vector spaces, which can be widely applied to many tasks. In particular, the RDF2vec approach [
68] is used to create vector representations of a list of candidate entity sets represented in the RDF format.
RDF2vec takes as input a knowledge graph, represented as triples of (subject, predicate, object), where entities and relations are represented by unique identifiers. RDF2vec uses random walk-based approaches to generate sequences of entities and then applies word2vec-like techniques to learn embeddings from these sequences. In particular, similar entities are closer in the vector space than dissimilar ones, which makes those representations ideal for learning patterns about those entities. Thus, RDF2Vec is a technique used in the context of knowledge graph embeddings. It aims to learn continuous vector representations (embeddings) of entities and relations in a knowledge graph in contrast to the word2vec technique, which is aimed at learning vector representations of words from large text corpora (i.e., used for word embeddings in natural language processing). RDF2Vec embeddings are useful in tasks like link prediction, entity classification, and semantic similarity in knowledge graphs. Word2vec embeddings are widely used in various NLP tasks, such as word similarity, language modeling, and information retrieval.
Since training RDF2vec from scratch can take quite a lot of time, we used pre-trained models from the KGvec2go project [
69]. KGvec2go is a semantic resource consisting of RDF2Vec knowledge graph embeddings trained currently on five different knowledge graphs (DBpedia 2016-10, WebIsALOD, CaLiGraph, Wiktionary, and WordNet). We selected DBpedia embeddings and the following model settings: 500 walks, 8 depth, SG algorithm, and 200 dimensions.
Thus, we get embeddings for all sets of candidate entities and then make a pair-wise comparison using the cosine similarity between entity vectors:
where
f3(
ek) is an entity embeddings-based similarity function based on the RDF2vec technique;
ek is a
k-entity from a set of candidates; and
Eall is a set of candidate entities for all other columns of a source table.
Thus, a relevant entity is selected from a set of candidates based on the maximum similarity score.
Context based similarity. This heuristic is based on the idea that a cell and a relevant entity from a set of candidates have a common context. For this purpose, the context of a cell is defined by neighboring cells in a row and a column. The context for a candidate entity is a set of other entities with which this entity is associated in a target knowledge graph. The following SPARQL query is used to search for such RDF triples:
SELECT ?subject ?object
WHERE {
{ ‘<value>‘ ?property ?object.
} UNION { ?subject ?property ‘<value>‘.
}
}
The context for a candidate entity can also be its description (“rdfs:comment” is used) from the DBpedia knowledge graph. We present the obtained contexts for a cell and a candidate entity as documents, where each context element is concatenated with a space.
Next, we use the document embedding approach, in particular, the Doc2vec algorithm [
70] for embedding documents in vector spaces. Doc2vec represents each document as a paragraph vector. Then we apply the cosine similarity between vectors to find the maximum correspondence documents (contexts):
where
f4(
ek) is a context based similarity function built using the Doc2vec technique;
ek is a
k-entity from a set of candidates;
ctcell is a context for a table cell;
cte is a context for a candidate entity.
Thus, a relevant entity is also selected from a set of candidates based on the maximum similarity score.
An overall aggregated score can be defined using all four disambiguation heuristics:
where
fagg is a function that calculates an overall aggregated score for an entity from a set of candidates;
w1,
w2,
w3, and
w4 are weighting factors that balance the importance of scores obtained using all four disambiguation heuristics. By default, all weighting factors are 1, but they can be selected based on the analyzed source tables. In particular, the string similarity heuristic may be inaccurate if cell mentions are very different from the relevant entity labels represented in a target knowledge graph. For example, a source table describes various financial indicators, where all currencies are presented using the ISO 4217 standard [
71] that defines alpha codes and numeric codes for the representation of currencies and provides information about the relationships between individual currencies and their minor units. Therefore, Russian rubles or United States Dollars in this table are represented as RUR and USD, respectively. Whereas the relevant entities will be “dbr:Russian_ruble” and “dbr:United_States_dollar”. Thus, these weighting factors must be determined by the user before starting the analysis of the tables.
This score represents the final probability that a certain entity from a set of candidates is most suitable (relevant) for a particular cell value from a source table.
Stage 5. Column-type annotation. The purpose of this stage is to automatically determine semantic types for table columns.
First, we try to automatically find the most suitable (relevant) classes from the DBpedia knowledge graph for each named entity column, including a subject column, based on an ensemble of five methods:
Majority voting. This method uses a frequency count of classes that have been obtained by reasoning from each relevant entity for a target column:
where
mmv(
ci) is a majority voting method to calculate the score for
i-class; and
Cj is a set of derived classes based on each relevant entity in
j-column.
The following SPARQL query is used to get these classes:
SELECT ?type
WHERE {
‘<relevant-entity>‘ a ?type.
}
The absolute score for the majority voting is a natural number. We also use the MinMax method from (3) to normalize this score to the range [0, 1]. A class with the highest normalized frequency value is determined as the best match and assigned to a target column.
Heading similarity. This method uses lexical matching between a header column name and a set of candidate classes. In this case, a set of candidate classes from the DBpedia knowledge graph is formed based on
N-grams of a header column name. We also use the Levenshtein distance metric for the maximum similarity of a sequence of characters between a header column name and a candidate class:
where
mhs(
ci) is a heading similarity method based on the Levenshtein distance;
ci is an
i-class from a set of candidates; and
hcnj is a header name for a
j-column.
As in the case of cell-entity annotation, we use the MinMax method from (3) to normalize this score to the range [0, 1]:
where
mnhs(
ci) is a normalized heading similarity based on the Levenshtein distance;
max mhs(
ci) is a maximum number of characters in
ci or
hcnj; and
min mhs(
ci) is the lower limit of the range, while
min mhs(
ci)
= 0.
Note that the majority voting and heading similarity methods are baseline heuristic solutions.
NER-based similarity. Similar to the heuristic for annotating cells, this additional method uses mapping between NER classes and DBpedia classes defined in
Table 3. We count the frequency of occurrence for each DBpedia class in a target column:
where
mnbs(
ci) is a NER-based similarity method that delivers the frequency for
i-class;
Cj is a set of classes from DBpedia obtained using the matching with NER classes for
j-column.
The normalization based on the MinMax algorithm is used to convert the frequency value into the range [0, 1]. A class with the highest normalized frequency value is determined as the best match and assigned to a target column.
CNN-based column class prediction. This method uses the ColNet framework [
43] based on word embedding and CNNs to predict the most suitable (relevant) class for each named entity column, including a subject column. This method consists of two main steps:
A candidate search. Each textual mention of an entity in a cell from a target column is compared with entities from the DBpedia knowledge graph. A set of candidate entities is determined by using the DBpedia lookup service. The classes and their super-classes for each entity from a set of candidates are derived by reasoning from the DBpedia knowledge graph using the DBpedia SPARQL Endpoint and are used as candidate classes for further processing;
Sampling and prediction. The ColNet framework automatically extracts labeled samples from the DBpedia knowledge graph during training. The input data for prediction is a synthetic column that is formed by concatenating all the cells. After that, both positive and negative training samples are created for each candidate class. A selection is defined as positive if each object in its synthetic column is inferred as an entity of a candidate class and negative otherwise. Next, a vector representation of a synthetic column is performed based on the word2vec approach. Each entity label is first cleared (e.g., punctuation is removed) and split into a sequence of words. Then the word sequences of all entities in a synthetic column are combined into one. Thus, ColNet uses the trained CNNs of the candidate classes to predict a relevant class for each named entity column. A final score is calculated for each candidate class of a given column:
where
mcolnet(
ci) is a CNN-based column class prediction method to calculate the score for
i-class;
Cj is a set of candidate classes obtained for
j-column.
The majority voting and CNN-based column class prediction methods are completely based on the CEA task result, and the NER-based similarity method depends on the stage of atomic column classification, so they do not guarantee a high degree of matching the selected class. In turn, the heading similarity method relies on metadata such as column headers, which are often unavailable in real tabular data. Thus, the following method is based on machine learning techniques, in particular, a pre-trained language model. This method uses only the data in the table itself.
BERT-based column class prediction. This method uses the Doduo framework [
47], which takes the entire table as input data and predicts semantic types for named entity columns including a subject column. Doduo includes a table context using the Transformer architecture and multi-task learning. Doduo uses a pre-trained language model, in particular, a basic 12-layer BERT (a single-column model) that can be fine-tuned using training data for a specific task. This framework contains two main models, “sato” and “turl” that were trained on the WebTables and WikiTables datasets. The first dataset is one of the collections included in the VizNet project [
72]. This dataset contains 78,733 tables, in which 119,360 columns were annotated with 78 different semantic types (classes and properties from DBpedia). The second dataset is a corpus of tables collected from Wikipedia and includes 580,171 tables. These tables are divided into training (570,171) evaluation (5036), and test (4964). Of these tables, 406,706 are used in the CTA task using 255 semantic types taken from the FreeBase knowledge graph. The models trained by them occupy approximately 1.2 GB.
It should be noted that Doduo does not assign a score (probability) for each class from a set of semantic types for a target column but immediately selects a relevant semantic type depending on the certain model (sato or turl). In this case, the BERT-based column class prediction method for a sato-model: msato(ci) = 1, and msato(ci) = 0 otherwise, where ci Csato, Csato is a set of 78 semantic types from DBpedia; for a turl-model: mturl(ci) = 1, and mturl(ci) = 0 otherwise, where ci Cturl, Cturl is a set of 255 semantic types from Freebase.
Thus, a relevant class is selected from a set of candidates using the scores of all five methods:
where
magg is an aggregated method that delivers an overall score for a class from a set of candidates;
mnmv(
ci) is a normalized majority voting method;
mnnbs(
ci) is a normalized NER-based similarity method;
mdoduo(
ci) is a BERT-based column class prediction based on the Doduo framework (
msato(
ci) or
mturl(
ci));
wmv, whs, wnbs, wcolnet, and wdoduo are weighting factors that balance the importance of scores obtained using all five annotation methods. By default, all weighting factors are 1, but they can also be selected based on the analyzed source tables, as in Formula (8).
A candidate class with the highest overall score is determined to be the best match and assigned to the current target column.
In addition to this aggregated method, we have developed a special algorithm to correct the selection of the relevant classes for the CTA task. This algorithm is inspired by the Probabilistic Graphical Model (PGM), in particular the undirected graphical model called the Markov random field, which involves the use of variable nodes for the representation of current states of table column annotations. Each variable node has the following properties:
“semantic type” is a current class from a set of candidates that is selected as a target annotation based on the use of all five methods;
“score” is an overall score assigned to this candidate class;
“column” is a column number;
“coherence” is a connectivity level of a current variable node with other variable nodes;
“change” is a flag that indicates whether this variable node should be changed.
At the beginning of the proposed algorithm, variable nodes are initialized. In particular, a set of candidate classes for each named entity column, including a subject column, is sorted by an overall score obtained via our methods described above. A candidate class with the highest overall score is assigned to “semantic type”, and its score is assigned to “score”. “coherence” is zero by default, and “change” is True for all variable nodes. Further, we try to find such a combination of variable nodes where their “coherence” is non-zero (if possible), but their “score” is also taken into account. In this case, variable nodes are iteratively updated with the next candidate classes from a set. Ultimately, a class from a set of candidates with the highest “coherence” and “score” is determined to be the most suitable (relevant) class and is assigned to a current target column as a final semantic annotation.
Next, we try to automatically find the most suitable (relevant) datatype from the XML Schema [
73] for each literal column based on information about already recognized literal NER classes.
Table 4 shows the mappings between literal NER classes and the corresponding XML Schema datatypes. Thus, a relevant datatype is determined based on the total number of literal NER classes defined for each cell in a target column.
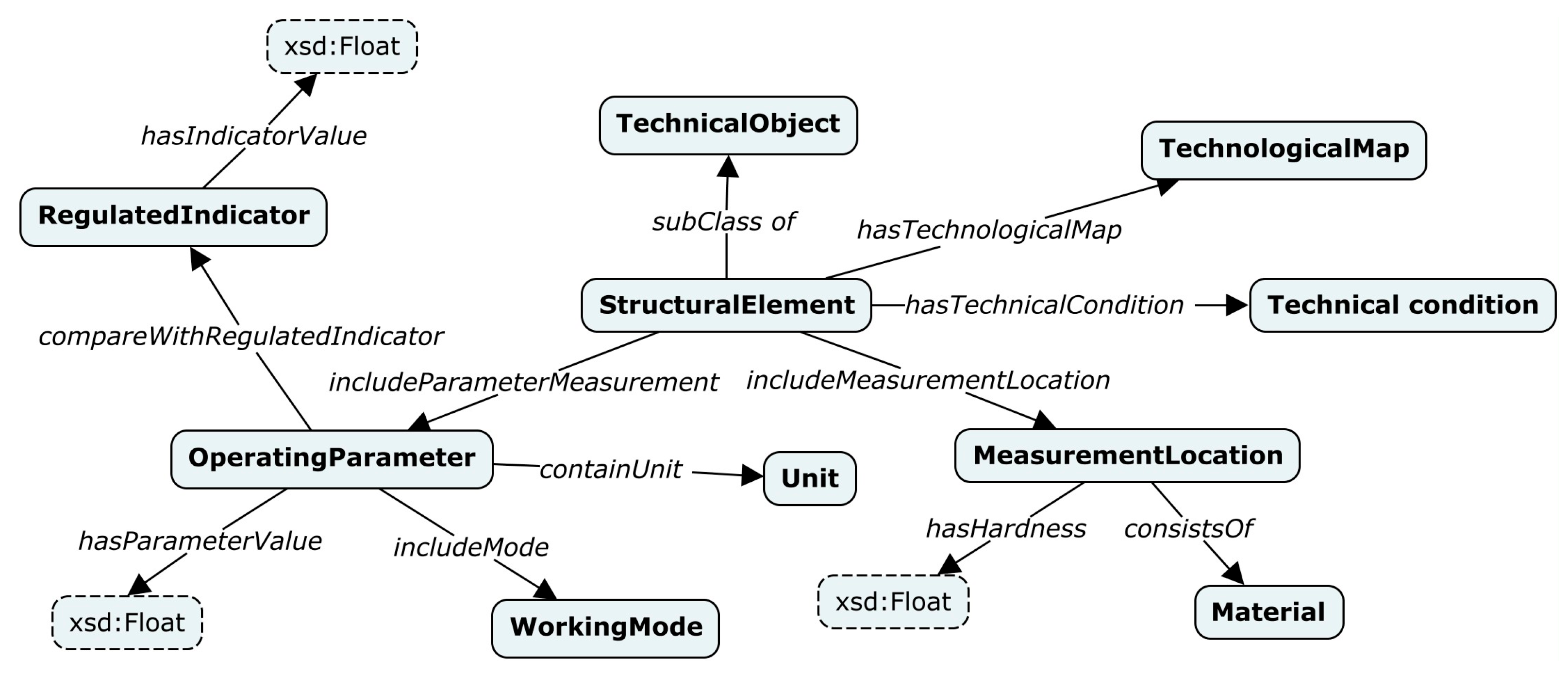
Stage 6. Columns-property annotation. At this stage, properties from a target knowledge graph are used as relationships between a subject column and other named entities or literal columns to define the general semantic meaning of a source table. A set of candidate properties for each pair of such columns is formed using a search for relationships between relevant classes and datatypes that were determined. The DBpedia SPARQL Endpoint service is also used for this. The baseline solution, called the majority voting method, is proposed. This method employs the same principle as the method from Stage 5. A property with the highest normalized frequency value is determined as the best match and assigned to target pair columns.
The result of the semantic interpretation of a source table (see Stage 4–6) is a set of annotated tabular data that can be used for further high-level machine processing. In particular, new specific entities (facts) can be extracted from annotated tables.
Stage 7. Entity extraction. At the last stage, a row-to-fact extraction is carried out based on defined annotations for columns and relationships between them. This stage is performed only for those cells whose annotations were not defined at Stage 4. A specific entity with a reference (rdf:type) to a relevant class is extracted for each cell of a subject column. This entity is associated with other entities or literals that are extracted from named entities and literal columns in the same row. In this case, a defined property between columns is set as the target relationship for such an association. It should be noted that the entity extraction algorithm uses an already defined ontology schema and does not identify new relationships.
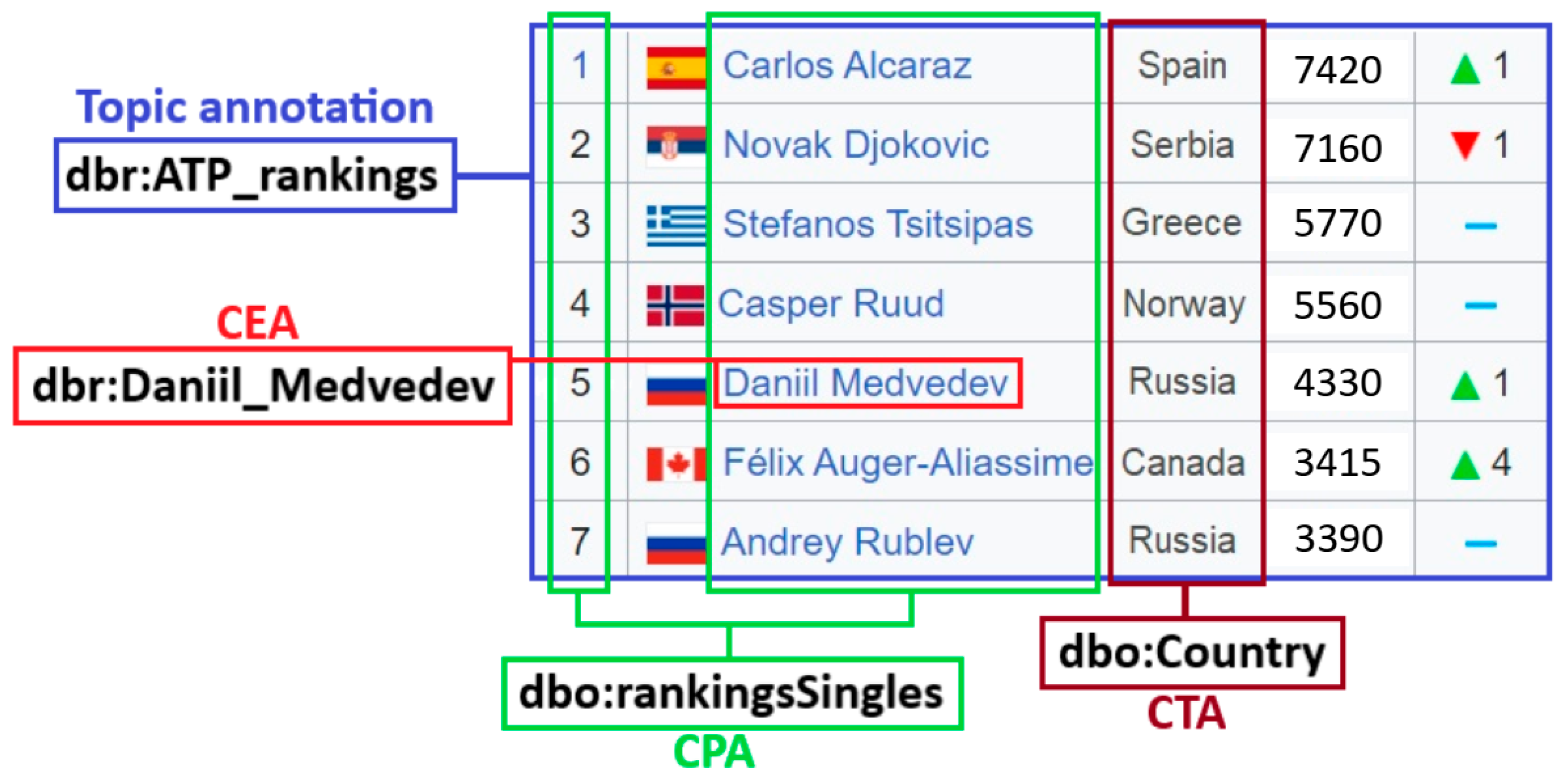
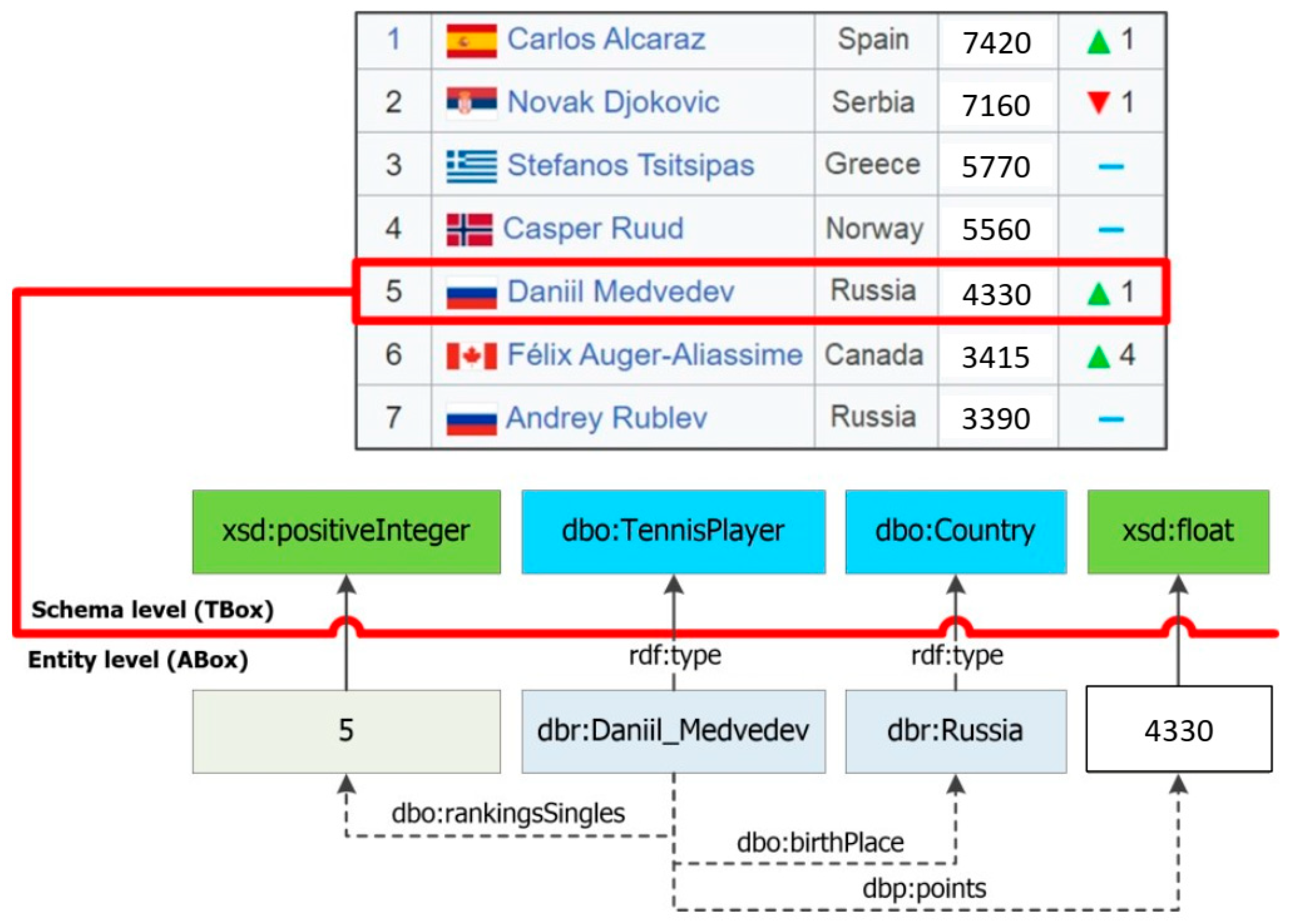
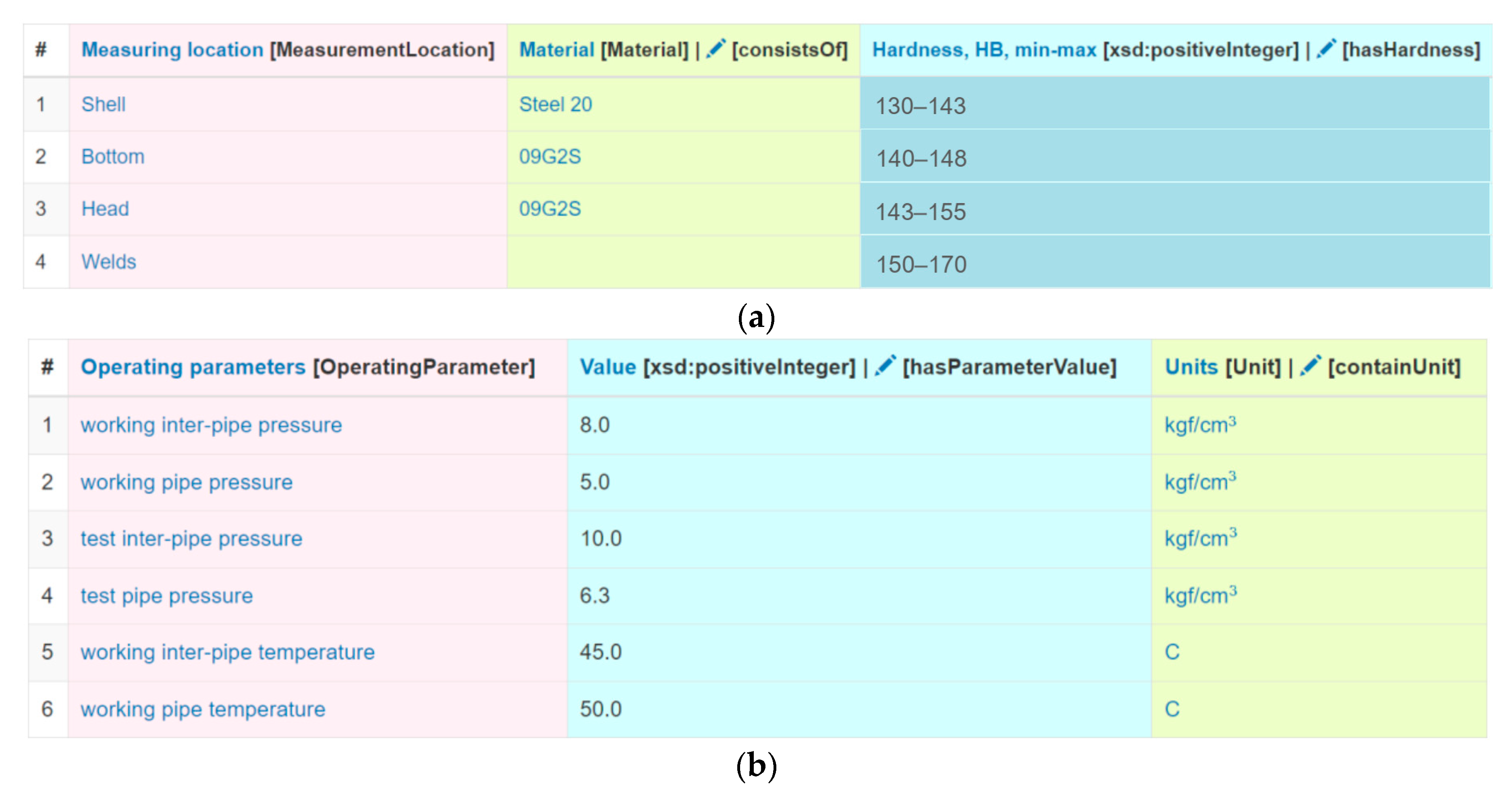
Thus, the RDF triples that contain extracted, specific entities and their properties (facts) are generated at the output. An example of row-to-fact extraction for annotated tabular data with the rating of tennis players “
ATP rankings (singles) as of 20 March 2023” is presented in
Figure 3. The entities extracted in this way can populate a target knowledge graph or ontology schema at the assertion level (ABox level).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}