DeepReco: Deep Learning Based Health Recommender System Using Collaborative Filtering

 ,
,  and
and
Abstract
:1. Introduction
2. Background
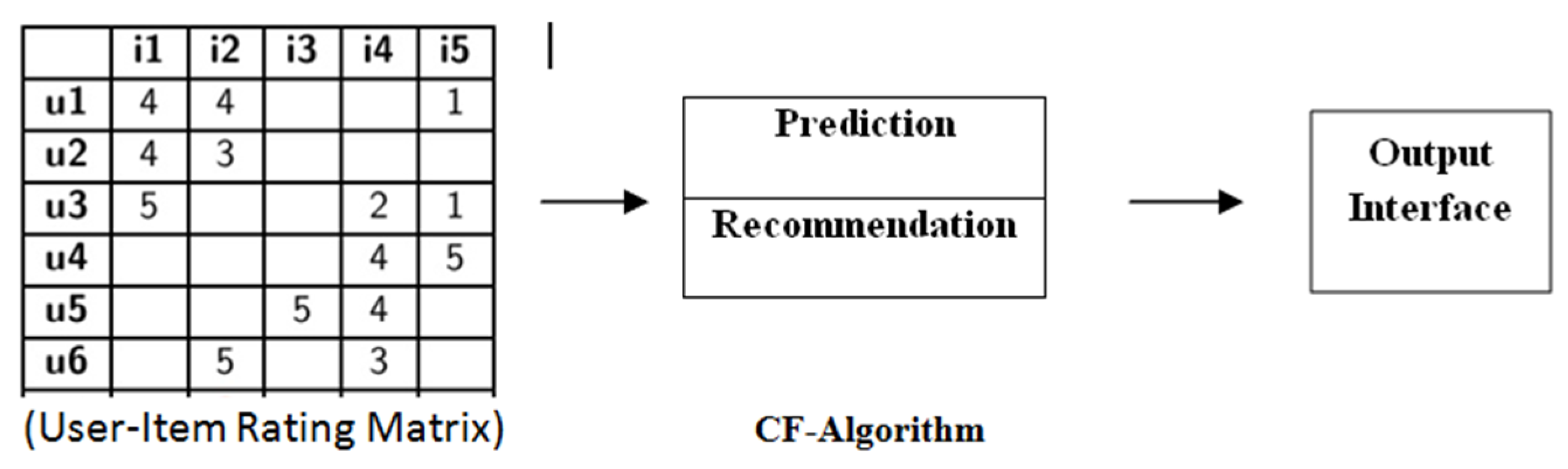
2.1. Preliminaries and Basic Concepts of Recommender System
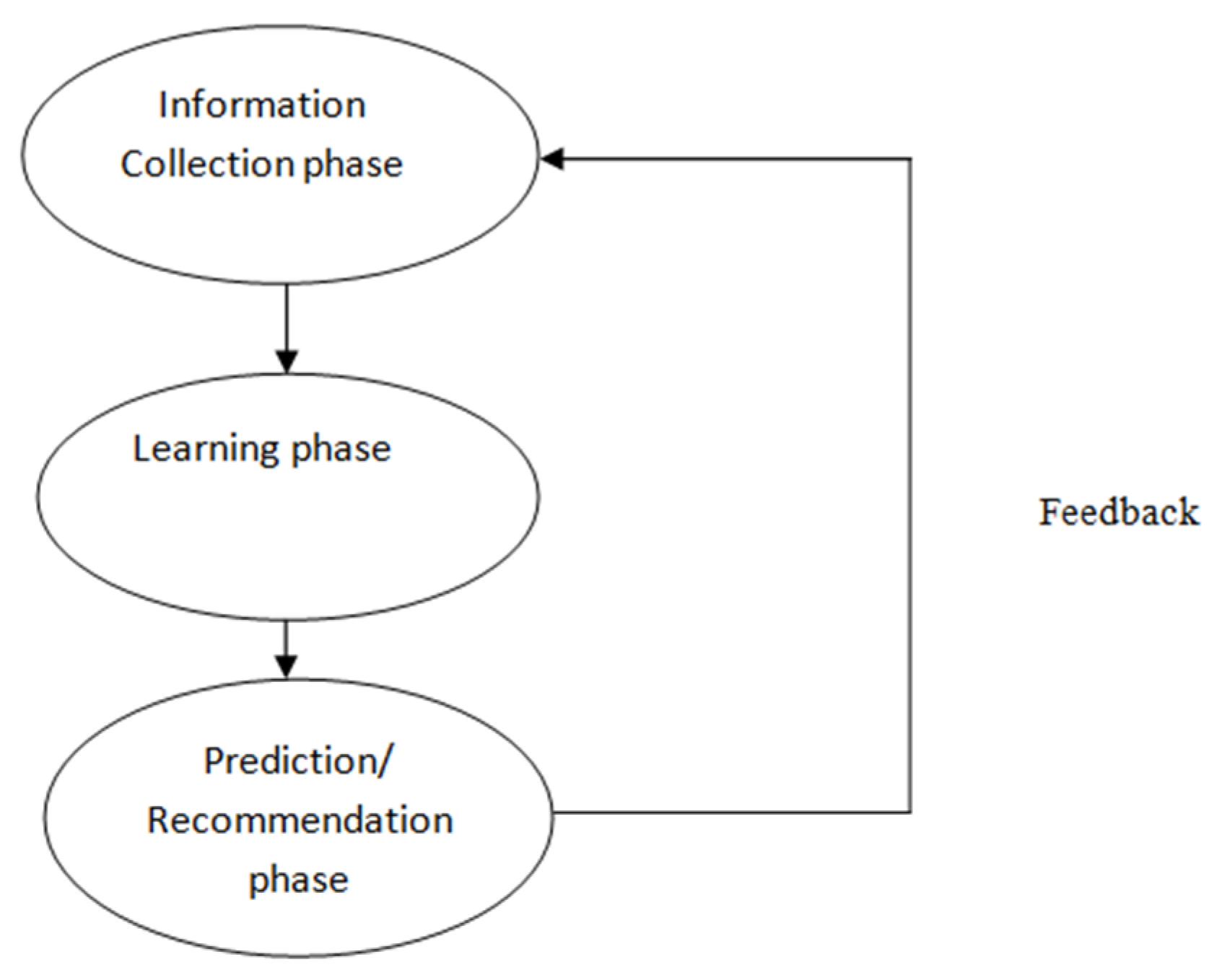
2.2. Phases of Recommender System
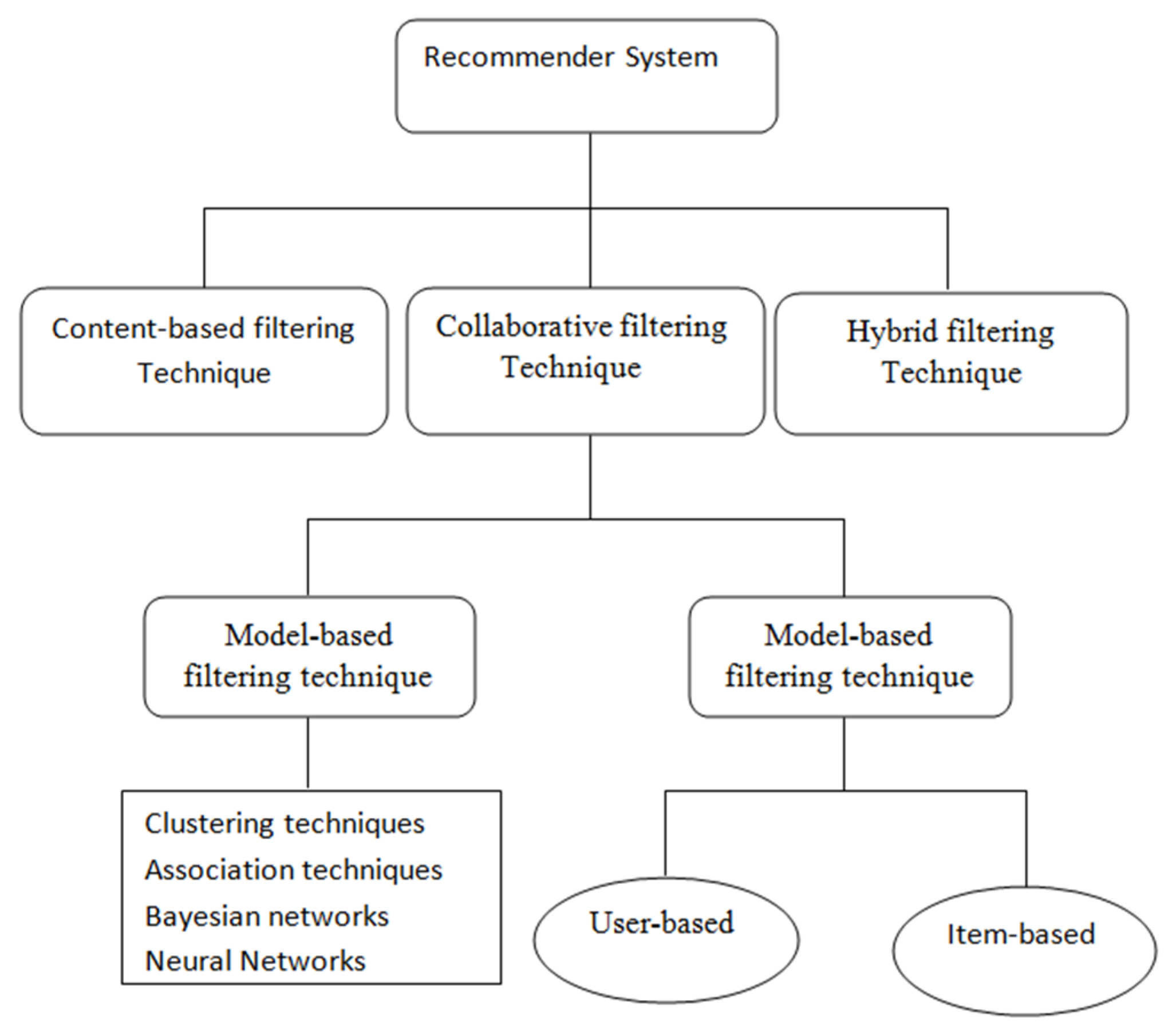
2.3. Different Types of Filtering Based Recommender System
3. Related Works
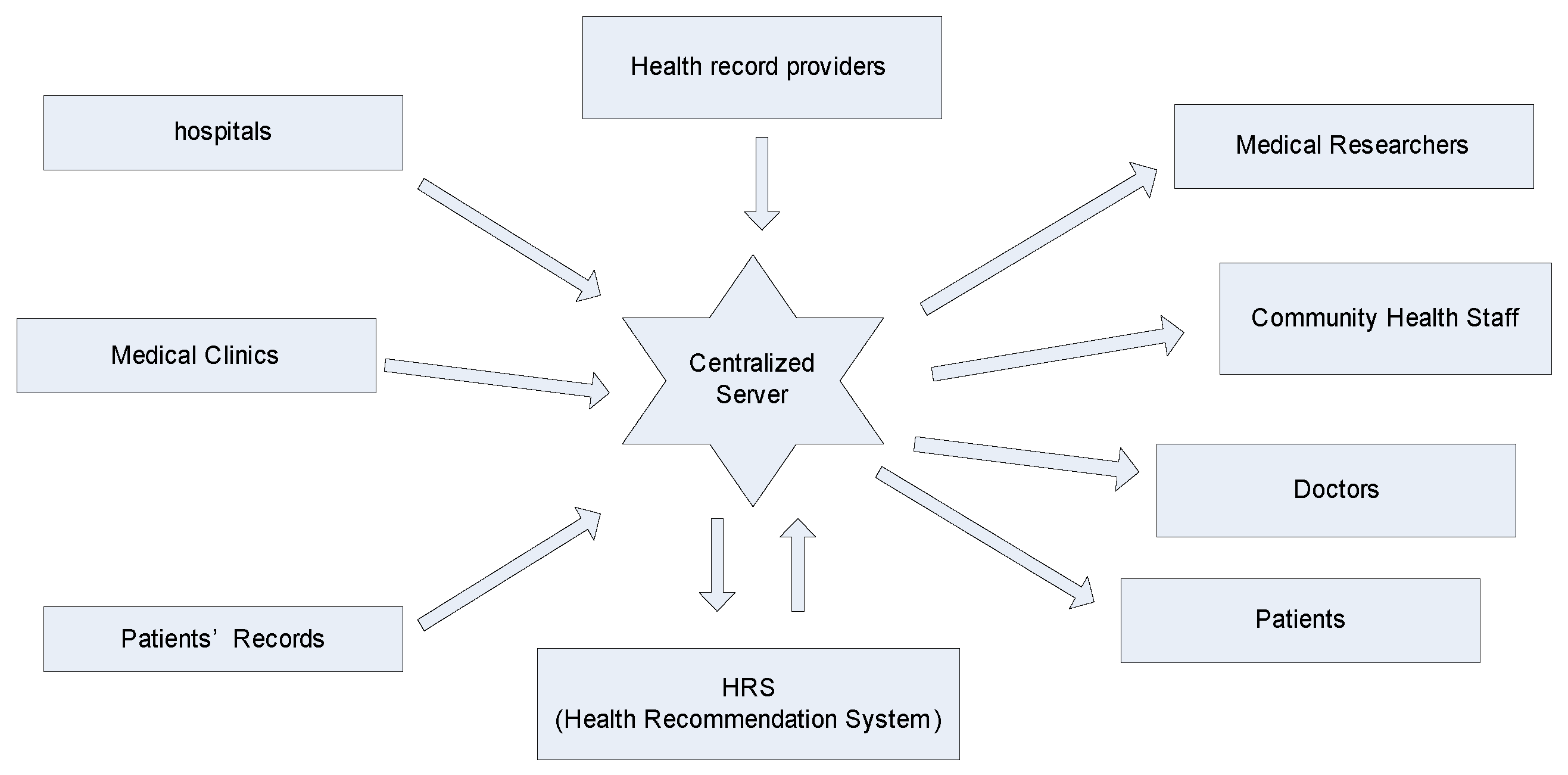
3.1. Health Recommender System
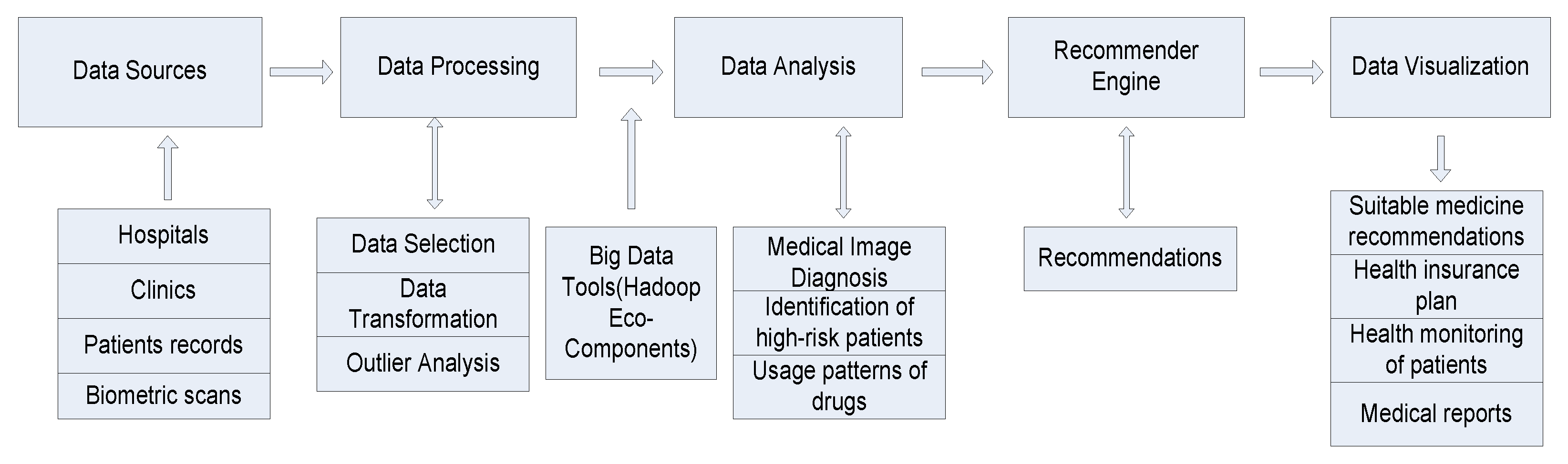
3.2. Designing Health Recommender System
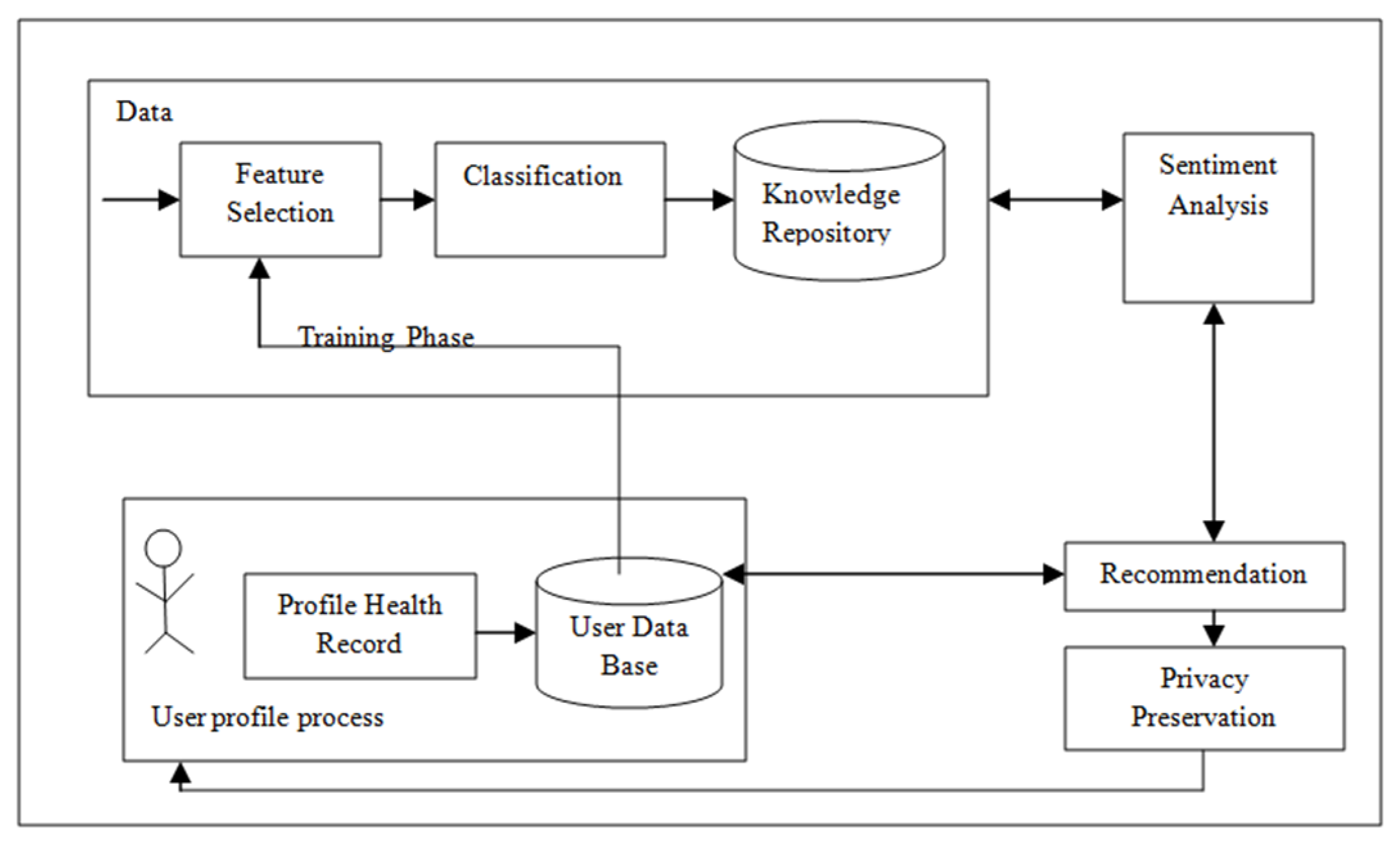
3.3. Framework for HRS
- Physical exercise: Generating recommendations on what type of yoga and physical exercise the patients should do for quick recovery based on patients’ requirements. The patient’s requirements may include location, disease-related, weather, etc.
- Diagnosis: Generating recommendations on the diagnosis of patients by the doctor based on symptoms shown in similar cases.
- Therapy/Medication: Generating recommendations about different types of medication for a particular disease or patient-specific therapy.
- Training Phase
- Patient Profile Generation
- Sentiment analysis
- Recommender
- Privacy preservation
3.4. Methods to Design HRS
3.5. Evaluation of HRS
- i.
- Precision: The measure of retrieved instances that are relevant.
- ii.
- Recall: The fraction of correctly recommended items that are also part of the collection of useful recommended items.
- iii.
- F-Measure: It is a measure of a test’s accuracy and is defined as the weighted harmonic mean of the precision and recall of the test.
- iv.
- ROC-Curve: ROC Curve is a way to compare diagnostic tests. It is a plot of the true positive rate against the false positive rate. It is used to represent the relationship between sensitivity and specificity.
- v.
- RSME: This measure defines the standard deviation of the residual errors, i.e., differences between predicted values and known values.
4. Different Approaches Used in Health Recommender System
4.1. Matrix Factorization
4.2. Singular Value Decomposition
4.3. Variable Weighted BSVD (WBSD)
4.4. Deep Learning Method
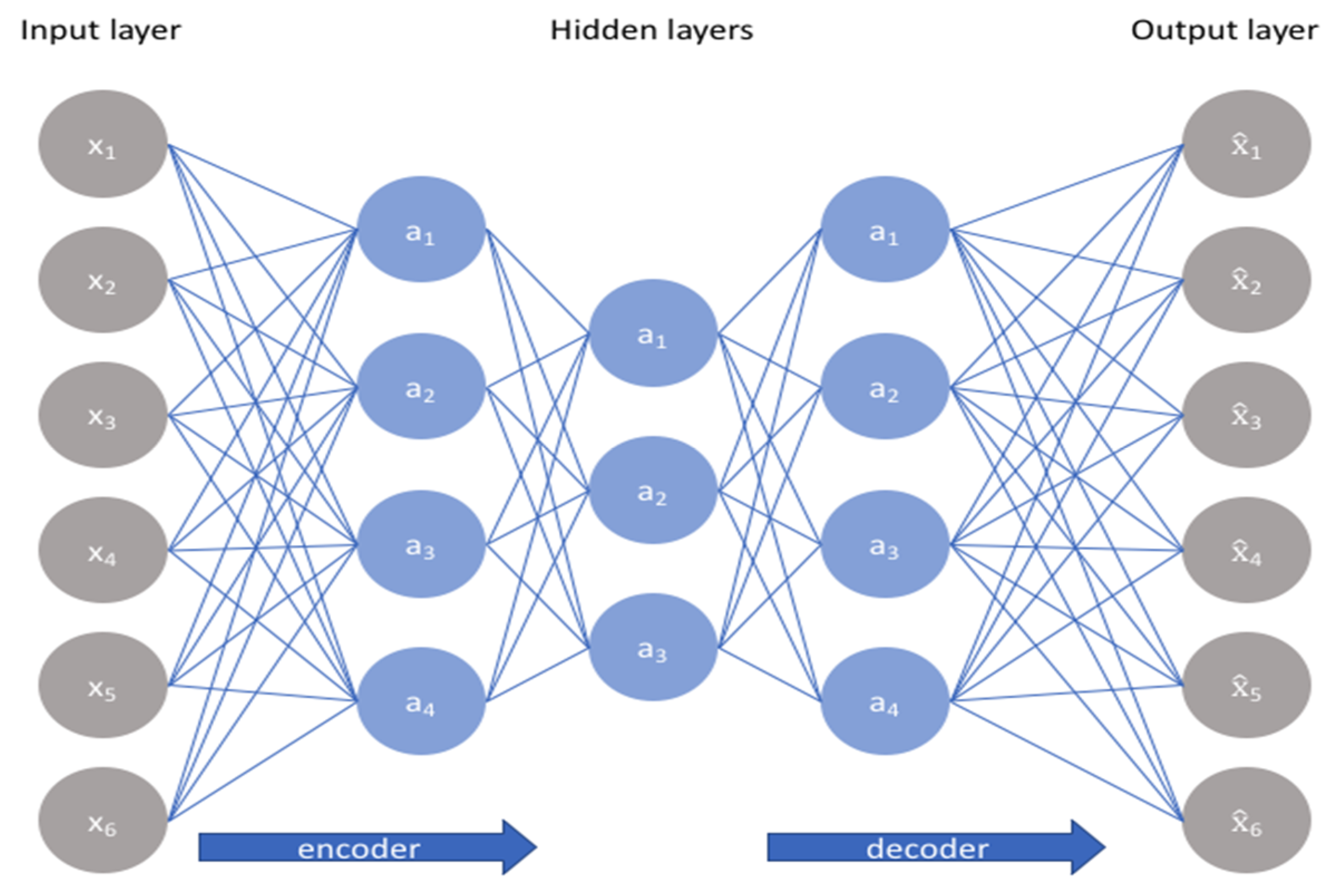
4.4.1. Multilayer Perceptron with Auto-Encoder
4.4.2. Convolutional Neural Network (CNN)
4.4.3. Restricted Boltzmann Machine (RBM)
4.4.4. Adversarial Networks (AN)
4.4.5. Neural Autoregressive Distribution Estimation
5. Proposed RBM-CNN Based Health Recommender System
- Load the healthcare dataset and also passheader=none since files don’t contain any headers.
- Load the ratings dataset
- After that, rename our columns in these data frames so we can convey their data better.
- Verify the changes done to the data frames.
- Data Correction and Formatting.
- Merge no. of hospitals with ratings by hospital ID.
- Display the result.
- Number of patients used for training.
- Creating the training list.
- (a)
- For each patient in the group for patientID.
- (b)
- Create a temp that stores every health care’s rating.
- (c)
- For each health care in curPatient’s health care list for num.
- (d)
- Divide the rating by 5.
- (e)
- Add the list of ratings into the training list.
- (f)
- We will verify that we have finished adding in the number of patients for training and setting the model parameters.
- Train RBM with CNN 15 Epochs, with each epoch using 10 batches with size 100.
- After training, the error is printed out by epoch size wise.
- Select the input patient.
- Feeding in the patient and reconstructing the input.
- List the 20 most recommended hospitals for our mock patient by sorting it by their scores given by our model.
- Find the mock patient’s PatientID from the data.
- Find all hospitals the mockpatient has visited before.
- Merge all hospitals that our sample patients have visited with predicted scores based on his historical data.
- Merging hospitals.
- Dropping unnecessary columns.
6. Experimental Result and Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Isinkaye, F.O.; Folajimi, Y.O.; Ojokoh, B.A. Recommender systems: Principles, methods and evaluation. Egypt. Inform. J. 2015, 16, 261–273, ISSN 1110-8665. [Google Scholar] [CrossRef]
- Burke, R.; Felfernig, A.; Goker, M.H. Recommender Systems: An Overview. AI Mag. 2011, 32, 13–18, ISSN 0738-4602. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Kawale, J.; Fu, Y. Deep collaborative filtering via marginalized denoising auto-encoder. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; pp. 811–820. [Google Scholar]
- Riyaz, P.A.; Varghese, S.M. A Scalable Product Recommenders using Collaborative Filtering in Hadoop for Bigdata. Procedia Technol. 2016, 24, 1393–1399. [Google Scholar] [CrossRef]
- Priyadarshini, R.; Barik, R.K.; Panigrahi, C.; Dubey, H.; Mishra, B.K. An investigation into the efficacy of deep learning tools for big data analysis in health care. Int. J. Grid High Perform. Comput. 2018, 10, 1–13. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-Based Collaborative Filtering Recommender Algorithms. In Proceedings of the ACM Digital Library International World Wide Web Conferences, Hong Kong, China, 1–5 May 2001; pp. 285–295, ISBN 1-58113-348-0. [Google Scholar]
- Wang, Y.; Hajli, N. Exploring the path to big data analytics success in healthcare. J. Bus. Res. 2017, 70, 287–299. [Google Scholar] [CrossRef]
- Babar, M.I.; Jehanzeb, M.; Ghazali, M.; Jawawi, D.N.A.; Sher, F.; Ghayyur, S.A.K. Big data survey in healthcare and a proposal for intelligent data diagnosis framework. In Proceedings of the 2016 2nd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 14–17 October 2016; pp. 7–12. [Google Scholar]
- Lafta, R.; Zhang, J.; Tao, X.; Li, Y.; Tseng, V.S.; Luo, Y.; Chen, F. An intelligent recommender system based on the predictive analysis in the telehealthcare environment. Web Intell. 2016, 14, 325–336. [Google Scholar] [CrossRef]
- Priyadarshini, R.; Barik, R.; Dubey, H. DeepFog: Fog Computing-Based Deep Neural Architecture for Prediction of Stress Types, Diabetes and Hypertension Attacks. Computation 2018, 6, 62. [Google Scholar] [CrossRef]
- Martínez-Pérez, B.; De La Torre-Díez, I.; López-Coronado, M. Privacy and security in mobile health APPs: A review and recommendations. J. Med. Syst. 2015, 39, 181. [Google Scholar] [CrossRef]
- Mu, R.; Zeng, X.; Han, L. A Survey of Recommender Systems Based on Deep Learning. IEEE Access 2018, 6, 69009–69022. [Google Scholar] [CrossRef]
- Gope, J.; Jain, S.K. A survey on solving cold start problem in recommender systems. In Proceedings of the 2017 International Conference on Computing, Communication, and Automation (ICCCA), Greater Noida, India, 5–6 May 2017; pp. 133–138. [Google Scholar]
- Jooa, J.H.; Bangb, S.W.; Parka, G.D. Implementation of a Recommender System usingAssociation Rules and Collaborative Filtering. Inf. Technol. Quant. Manag. Procedia Comput. Sci. 2016, 91, 944–952. [Google Scholar] [CrossRef]
- Ponnam, L.T.; Punyasamudram, S.D. Health care Recommender System using Item Based Collaborative Filtering Technique. In Proceedings of the International Conference on Emerging Trends in Engineering, Technology and Science, Pudukkottai, India, 24–26 February 2016; Volume 1, pp. 56–60. [Google Scholar]
- Hoseini, E.; Hashemi, S.; Hamzeh, A. SPCF: A stepwise partitioning for collaborative filtering to alleviate sparsity problems. J. Inf. Sci. 2012, 38, 578–592. [Google Scholar] [CrossRef]
- Ma, X.; Lu, H.; Gan, Z.; Zeng, J. An explicit trust and distrust clustering based collaborative filtering recommender approach. Electron. Commer. Res. Appl. 2017, 25, 29–39. [Google Scholar] [CrossRef]
- Kaur, H.; Kumar, N.; Batra, S. An efficient multi-party scheme for privacy preserving collaborative filtering for healthcare recommender system. Future Gener. Comput. Syst. 2018, 86, 297–307. [Google Scholar] [CrossRef]
- Archenaa1, J.; Mary Anita, E.A. Health Recommender System using Big data analytics. J. Manag. Sci. Bus. Intell. 2017, 2, 17–24. [Google Scholar]
- Behera, R.K.; Sahoo, A.K.; Pradhan, C.R. Big Data Analytics in Real Time—Technical Challenges and Its Solutions. In Proceedings of the 2017 International Conference on Information Technology (ICIT), Bhubaneswar, India, 21–23 December 2017; pp. 30–35. [Google Scholar] [CrossRef]
- Yang, C.C.; Jiang, L. Enriching User Experience in Online Health Communities Through Thread Recommendations and Heterogeneous Information Network Mining. IEEE Trans. Comput. Soc. Syst. 2018, 5, 1049–1060. [Google Scholar] [CrossRef]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anil, R. Wide & deep learning for recommender systems (DLRS 2016). In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Paul, P.K.; Dey, J.L. Data Science Vis-à-Vis efficient healthcare and medical systems: A techno-managerial perspective. In Proceedings of the 2017 Innovations in Power and Advanced Computing Technologies (i-PACT), Vellore, India, 21–22 April 2017; pp. 1–8. [Google Scholar]
- Calero Valdez, A.; Ziefle, M.; Verbert, K.; Felfernig, A.; Holzinger, A. Recommender Systems for Health Informatics: State-of-the-Art and Future Perspective. In Machine Learning for Health Informatics; Holzinger, A., Ed.; Lecture Notes in Computer Science LNCS 9605; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Sahoo, A.K.; Pradhan, C.R. A Novel Approach to Optimized Hybrid Item-based Collaborative Filtering Recommender Model using R. In Proceedings of the 2017 9th International Conference on Advanced Computing (ICoAC), Chennai, India, 14–16 December 2017; pp. 468–472. [Google Scholar]
- Baldominos, A.; De Rada, F.; Saez, Y. DataCare: Big Data Analytics Solution for Intelligent Healthcare Management. Int. J. Interact. Multimed. Artif. Intell. 2018, 4, 13–20. [Google Scholar] [CrossRef]
- Sharma, D.; Shadabi, F. The potential use of multi-agent and hybrid data mining approaches in social informatics for improving e-Health services. In Proceedings of the 4th IEEE International Conference on Big Data and Cloud Computing, Sydney, NSW, Australia, 3–5 December 2014; IEEE: New York, NY, USA, 2014; pp. 350–354. [Google Scholar]
- Harsh, K.; Ravi, S. Big Data Security and Privacy Issues in Healthcare. In Proceedings of the 2014 IEEE International Congress on Big Data, Anchorage, AK, USA, 27 June–2 July 2014; pp. 762–765. [Google Scholar]
- Portugal, I.; Alencar, P.; Cowan, D. The use of machine learning algorithms in recommender systems: A systematic review. Expert Syst. Appl. 2018, 97, 205–227. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Gao, C.; Du, J. A NMF-based privacy-preserving recommender algorithm. In Proceedings of the 2009 First International Conference on Information Science and Engineering, Nanjing, China, 26–28 December 2009; pp. 754–757. [Google Scholar]
- Chen, J.; Li, K.; Rong, H.; Bilal, K.; Yang, N.; Li, K. A diagnosis and treatment recommender system based on big data mining and Cloud computing. Inf. Sci. 2018, 435, 124–149. [Google Scholar] [CrossRef]
- Fernández-Alemán, J.L.; Señor, I.C.; Lozoya, P.Á.O.; Toval, A. Security and privacy in electronic health records: A systematic literature review. J. Biomed. Inf. 2013, 46, 541–562. [Google Scholar] [CrossRef] [PubMed]
- Yuan, W.; Li, C.; Guan, D.; Han, G.; Khattak, A.M. Socialized healthcare service recommendation using deep learning. Neural Comput. Appl. 2018, 30, 2071–2082. [Google Scholar] [CrossRef]
- Wang, Y.; Kung, L.; Byrd, T.A. Big data analytics: Understanding its capabilities and potential benefits for healthcare organizations. Technol. Forecast. Soc. Chang. 2018, 126, 3–13. [Google Scholar] [CrossRef]
- Zhou, X.; He, J.; Huang, G.; Zhang, Y. SVD-based incremental approaches for recommender systems. J. Comput. Syst. Sci. 2015, 81, 717–733. [Google Scholar] [CrossRef]
- Canny, J. Collaborative filtering with privacy via factor analysis. In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Tampere, Finland, 11–15 August 2002; pp. 238–245. [Google Scholar]
- Harper, F.M.; Konstan, J.A. The health care datasets: History and context. ACM Trans. Interact. Intell. Syst. 2015, 5, 19:1–19:19. [Google Scholar] [CrossRef]
- Palanisamy, V.; Thirunavukarasu, R. Implications of big data analytics in developing healthcare frameworks—A review. J. King Saud Univ.-Comput. Inf. Sci. 2017. [Google Scholar] [CrossRef]
- Raghupathi, W.; Raghupathi, V. Big data analytics in healthcare: promise and potential. Health Inf. Sci. Syst. 2014, 2, 3. [Google Scholar] [CrossRef]
- Ortega, F.; Hernando, A.; Bobadilla, J.; Kang, J.H. Recommending items to group of patients using Matrix Factorization based Collaborative Filtering. Inf. Sci. 2016, 345, 313–324. [Google Scholar] [CrossRef]
- Ambika, M.; Latha, K. Intelligence Based Recommender System for Healthcare: A Patient-Centered Framework. In Proceedings of the 2nd International Conference on Advanced Theoretical Computer Applications, Ho Chi Minh City, Vietnam, 9–11 December 2015; pp. 245–255. [Google Scholar]
- He, X.; Chua, T.S. Neural factorization machines for sparse predictive analytics. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 355–364. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web (WWW ’17), Perth, Australia, 3–17 April 2017; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2017; pp. 173–182. [Google Scholar]
- Wu, J.; Yang, L.; Li, Z. Variable Weighted BSVD-Based Privacy-Preserving Collaborative Filtering. In Intelligent Systems and Knowledge Engineering (ISKE), Proceedings of the 2015 10th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Taipei, Taiwan, 24–27 November 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 144–148. [Google Scholar]
- Adams, R.J.; Sadasivam, R.S.; Balakrishnan, K.; Kinney, R.L.; Houston, T.K.; Marlin, B.M. PERSPeCT: Collaborative filtering for tailored health communications. In Proceedings of the 8th ACM Conference on Recommender systems (RecSys ’14), Foster City, Silicon Valley, CA, USA, 6–10 October 2010; pp. 329–332. [Google Scholar]
- Sahoo, A.K.; Pradhan, C.; Mishra, B.S.P. SVD based Privacy Preserving Recommendation Model using Optimized Hybrid Item-based Collaborative Filtering. In Proceedings of the 2019 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 4–6 April 2019; pp. 294–298. [Google Scholar]
- Wei, J.; He, J.; Chen, K.; Zhou, Y.; Tang, Z. Collaborative filtering and deep learning Based recommender system for cold start items. Expert Syst. Appl. 2017, 69, 29–39. [Google Scholar] [CrossRef]
- Dai, Y.; Wang, G. A deep inference learning framework for healthcare. Pattern Recognit. Lett. 2018. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Nie, L.; Chua, T.S. Item silk road: Recommending items from information domains to social users. In Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 185–194. [Google Scholar]
- Jiang, L.; Yang, C.C. User recommendation in healthcare social media by assessing user similarity in heterogeneous network. Artif. Intel. Med. 2017, 81, 63–77. [Google Scholar] [CrossRef]
- Yedder, H.B.; Zakia, U.; Ahmed, A.; Trajkovic, L. Modeling prediction in recommender systems using restricted boltzmann machine. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017. [Google Scholar]
- Belle, A.; Thiagarajan, R.; Soroushmehr, S.M.; Navidi, F.; Beard, D.A.; Najarian, K. Big data analytics in healthcare. Biomed Res. Int. 2015, 2015, 370194. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
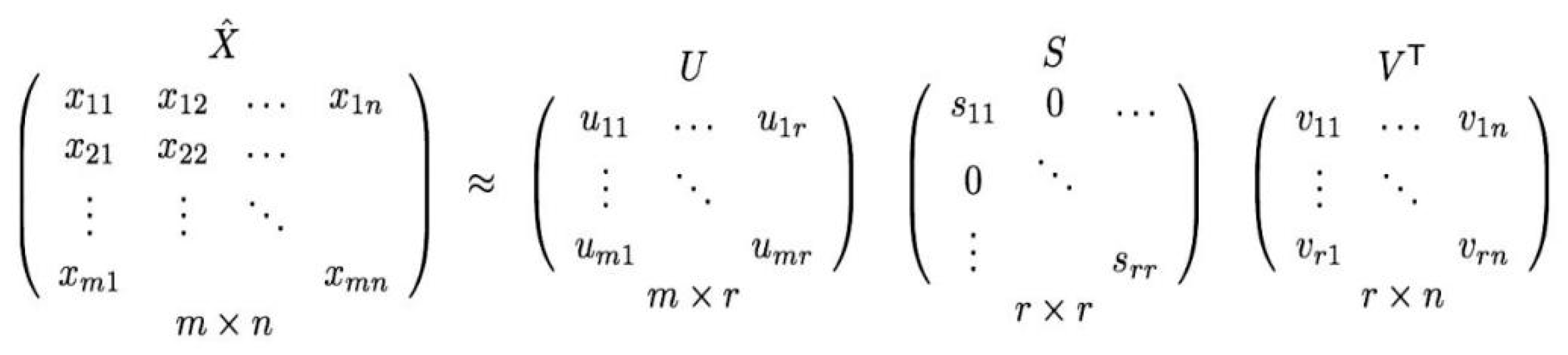{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Steps | Description |
|---|---|
| Concept statement | Establish the need for big data analytics in healthcare based on the “4Vs”. |
| Proposal | What is the problem being addressed? |
| Why use a big data analytics approach? | |
| Background | |
| Methodology | Objectives |
| Variable selection and Data collection | |
| Data transformation | |
| Platform tool selection | |
| Analytic techniques, association, clustering, classification, neural network etc. | |
| Results | |
| Deployment | Evaluation |
| Testing |
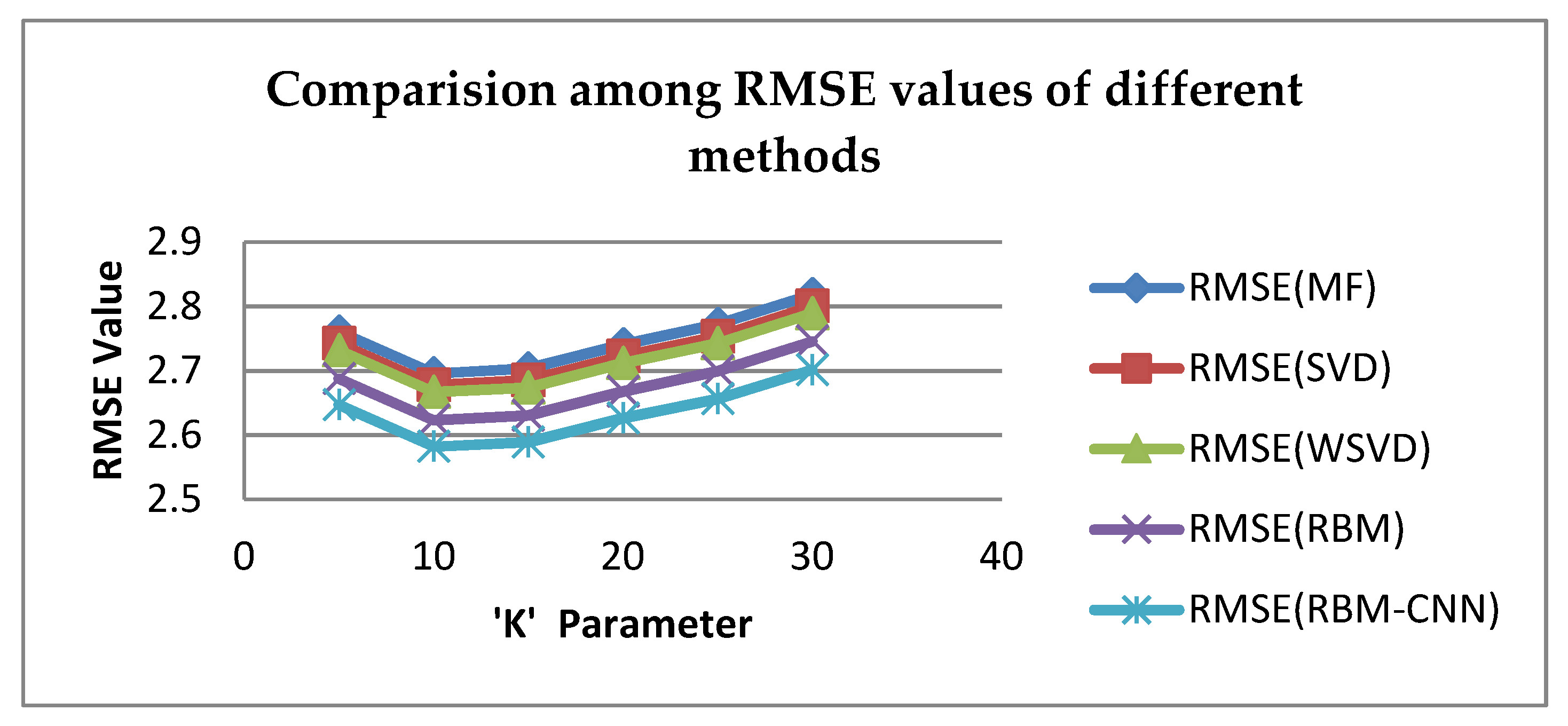
| K | MF | SVD | WSVD | RBM | Proposed RBM-CNN |
|---|---|---|---|---|---|
| 5 | 2.76137 | 2.74313 | 2.73219 | 2.68828 | 2.64707 |
| 10 | 2.69592 | 2.67776 | 2.66688 | 2.62337 | 2.58216 |
| 15 | 2.70339 | 2.6852 | 2.67413 | 2.63062 | 2.58931 |
| 20 | 2.74089 | 2.72274 | 2.71169 | 2.66818 | 2.62657 |
| 25 | 2.77257 | 2.75391 | 2.74288 | 2.69937 | 2.65616 |
| 30 | 2.81879 | 2.80047 | 2.78935 | 2.74584 | 2.70136 |
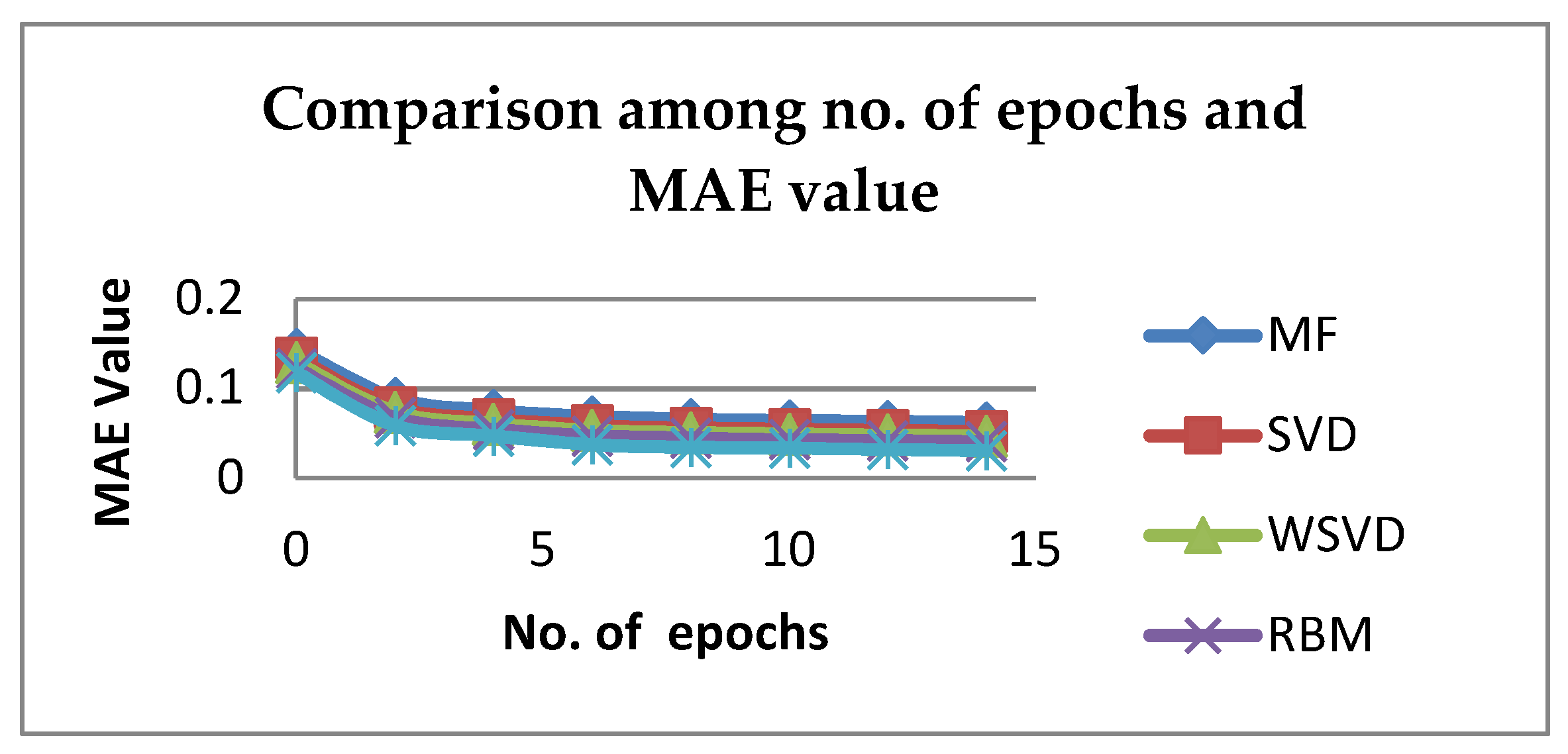
| No. of Epochs | MF | SVD | WSVD | RBM | Proposed RBM-CNN |
|---|---|---|---|---|---|
| 0 | 0.14412752 | 0.13432652 | 0.12912452 | 0.12286516 | 0.11785 |
| 2 | 0.08904246 | 0.07924146 | 0.07403946 | 0.0677801 | 0.05876 |
| 4 | 0.07580589 | 0.06600489 | 0.06080289 | 0.05454353 | 0.04734 |
| 6 | 0.068728 | 0.058927 | 0.053725 | 0.04746564 | 0.03748 |
| 8 | 0.06597785 | 0.05617685 | 0.05097485 | 0.04471549 | 0.03471 |
| 10 | 0.06439402 | 0.05459302 | 0.04939102 | 0.04313166 | 0.03368 |
| 12 | 0.063298018 | 0.053497018 | 0.048295018 | 0.042035658 | 0.03206 |
| 14 | 0.062187785 | 0.052386785 | 0.047184785 | 0.040925425 | 0.03095 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sahoo, A.K.; Pradhan, C.; Barik, R.K.; Dubey, H. DeepReco: Deep Learning Based Health Recommender System Using Collaborative Filtering. Computation 2019, 7, 25. https://doi.org/10.3390/computation7020025
Sahoo AK, Pradhan C, Barik RK, Dubey H. DeepReco: Deep Learning Based Health Recommender System Using Collaborative Filtering. Computation. 2019; 7(2):25. https://doi.org/10.3390/computation7020025
Chicago/Turabian StyleSahoo, Abhaya Kumar, Chittaranjan Pradhan, Rabindra Kumar Barik, and Harishchandra Dubey. 2019. "DeepReco: Deep Learning Based Health Recommender System Using Collaborative Filtering" Computation 7, no. 2: 25. https://doi.org/10.3390/computation7020025
APA StyleSahoo, A. K., Pradhan, C., Barik, R. K., & Dubey, H. (2019). DeepReco: Deep Learning Based Health Recommender System Using Collaborative Filtering. Computation, 7(2), 25. https://doi.org/10.3390/computation7020025