1. Introduction
Nowadays, financial markets represent the backbone of the modern societies, as the world economy is closely related to their behavior [
1]. In this context, the investors play a main role, since their decisions drive the financial markets. Differently from the past, nowadays there are several information and communication technologies that have been employed within the financial domain, so investors are now supported by many artificial intelligence instruments that help them to take decisions. Such instruments can exploit a diverse number of techniques [
2], from simple statistical approaches to those more sophisticated based on Deep Learning, Social Media Analysis, Natural Language Processing, Sentiment Analysis, and so on [
3,
4,
5,
6,
7,
8].
The literature reports two main methodologies largely used to analyze and predict the behavior of financial markets. The first is based on fundamental analysis, which takes into account the economic elements that may affect the market activities. The second is based on technical analysis [
9], which takes into account the historical behavior of the market prices, as it relies on the consideration that the stock prices already include all the fundamental information that could affect it. Moreover, the technical analysis considers the financial asset behavior as a time series, and it is based on the consideration that some behaviors tend to occur again in the future [
10,
11].
Machine learning solutions have been widely adopted in the context of financial time series forecasting. They usually operate by using a supervised strategy, where classifiers (e.g., Naive Bayes, Decision Trees, Support Vector Machines, etc.) label the data in order to learn their behavior and classify new data into a number of classes (i.e., in the stock market, such classes can be considered as prices going up and down). There are also methods known in statistical analysis that perform regression, which consists of a set of statistical processes for estimating the relationships among variables [
12], with the goal of predicting the exact stock price for a day. Although both technical and fundamental data can be used as input data to machine learning approaches, fundamental analysis data do not allow a reliable and high frequency trading for two reasons: (i) these types of information are published at periodic times (e.g., every trimester); and (ii) they are the responsibility of companies, so they can be liable to fraud. Therefore, most of the machine learning approaches do not rely on fundamental information, using diverse other information from technical analysis such as lagged prices, returns, technical indicators, and even news. One more difference between technical and fundamental analysis is that the latter might often use sensitive data (e.g., revenue of companies) and policy procedures should be defined to guarantee privacy, protection, and not disclosure of the data.
In recent years, machine learning approaches have been validated to perform stock market predictions on the basis of historical time series, but, despite the numerous and sophisticated techniques available today, such a task continues to be considered challenging [
13]. There are several reasons to explain that: (i) existing methods employ classifiers whose intrinsic parameters are tuned without a general approach but are based on values heavily depending on the used classifier and the target data [
4,
14]; (ii) the lack of a general technique to set the hyper-parameters (e.g., training and test set sizes, lags, and walks dimension) for the experiments usually makes them not reproducible and thus difficult to assess and to compare with baselines or other approaches [
14]; (iii) several works in literature do not specify whether they are performing their test analysis on in-sample or out-of-sample data, and this is a further reason for confusion [
4,
15,
16]; (iv) several works employ classifiers without stating clearly which is the best and under which conditions. This may bring to the common sense that each proposed classifier exploits the peculiarities of the presented market data. Therefore, this does not help understanding whether the method is effective or there are ad hoc classifiers and data choices to report best results only [
17,
18]; (v) different combinations of feature selection techniques have been explored in financial forecasting, but a framework that can be designed with the goal to get as input any feature and generate the optimal number of output features that is still missing [
19]; (vi) for the evaluation step, several metrics have been proposed, but there have not been precise explanations on the adoption of one with respect to the other. This further introduces confusion on the overall analysis and on which metric should be prioritized [
20,
21,
22,
23]; and (vii) to define trading strategies, parameters such as those for the data preparation, algorithm definition, training methodology and forecasting evaluation must be the choices to be made by the trading systems architect [
1]. To the best of our knowledge, the literature does not offer financial market forecasting approaches based on a systematic strategy, able to model automatically itself with regard to these parameters and chosen market in order to perform well the forecasting task no matter the market considered.
With all of these limitations in mind, we introduce in this paper a general approach for technical analysis of financial forecasting based on an ensemble of predictors automatically created, considering any kind of classifiers and adjustable to any kind of market. In our ensemble, each market will have two sets of parameters tuned: the time series (hyper) parameters and classifier (intrinsic) parameters, no matter the classifiers considered in the ensemble. These parameters are tuned in late past (in-sample) and early past (out-of-sample) datasets, respectively. The input data of such an ensemble are transformed by the Independent Component Analysis, whose parameters are also optimized to make it general enough to return the optimal number of output signals. Therefore, our approach is different from the literature as it is composed of an ensemble of classifiers that can include any classifier and can be maximized for more than one market. To do that, we study the performance of our data-driven ensemble construction by considering different performance metrics in known data in order to tune ensemble parameters over the space of features by using the Independent Component Analysis (ICA) feature selection, parameters (parameters of classifiers, or intra-parameters), and also in the space of time (parameters of the time series). Experiments performed in several futures markets show the effectiveness of the proposed approach with respect to both buy-and-hold strategy and other literature approaches, highlighting the use of such a technique especially by conservative and beginner investors who aim to do safe investment diversification.
The contributions of this paper are therefore the following:
We formalize a general ensemble construction method, which can be evolved by considering any kind of different classifiers and can be applied to any market.
We propose an auto-configurable nature, or data-driven nature of such an ensemble. Our approach seeks for hyper (time series) and intrinsic (classifiers) parameters in late and early past data, respectively, generating a final ensemble no matter the market considered.
We discuss the use of an optimized ICA method as feature selection of the ensemble input, in order to produce the best number of selected features given any number of input signals.
We perform a performance study by using different metrics based on classification, risk and return, comparing our approach to the well established Buy and Hold methodology and several canonical state-of-the-art solutions.
In order to reduce the risk that the general strategy optimization phase would lead to results affected by overfitting bias, we systematically rely on the concepts of strictly separated in-sample and out-of-sample datasets for an efficient two-step ensemble parameter tuning, aimed to trade in financial markets.
The remainder of the paper is organized into the following sections.
Section 2 introduces basic concepts and related work in stock market forecasting using individual and ensemble approaches. Our self-configurable ensemble method is discussed in
Section 3.
Section 4 gives details on the experimental environments (datasets), adopted metrics, and implementation details of the proposed method and competitors;
Section 5 reports the results on the basis of several metrics in four different markets and, finally,
Section 6 provides some concluding remarks and points out some further directions for research where we aim to head as future work.
2. Background and Related Work
The futures market (also known as futures exchange) is an auction market in which investors buy and sell futures contracts for delivery at a specified future date. Some examples of the futures market are the German DAX, the Italian FTSE MIB, the American S&P500, among others. Nowadays, as it happens in almost all markets, all buy and sell operations are made electronically.
In the futures market, the futures contracts represent legal agreements to buy or sell, at a predetermined price and time in the future, a specific commodity or asset. They have been standardized in terms of quality and quantity in order to make easy the trading on the futures exchange. Whoever buys a futures contract assumes an obligation to purchase the underlying asset when the related futures contract expires, whereas whoever sells it assumes an obligation to provide the underlying asset when the related futures contract expires.
Several strategies can be used in order to trade futures contracts. In this paper, we assume an intra-day trading strategy. This methodology to trade stocks, also called day trading, consists of buying and selling stocks and other financial instruments within the same day. In other words, all positions are squared-off (i.e., the trader or portfolio has no market exposure) before the market closes, and there is no change in ownership of shares as a result of the trades. Such a strategy allows the investors to be protected against the possibility of negative overnight events that have an impact on financial markets (i.e., the exit of a country from a commercial agreement, a trade embargo, a declaration of war, and so on). Like other trading strategies, a stop-loss trigger forcing the interruption of the operation when the loss reaches a predetermined value should be adopted to contain risk. Some disadvantages of the intra-day trading strategy are instead the short time available to increase the profit and the commission costs related to the frequent operations (i.e., buy and sell).
Futures market contract prices are published periodically for the general public access. They are usually in the form of comma separated values’ text files, containing the following information: date, open value, highest open value, close value, highest close value, exchange volume. These data are updated in a specific time resolution (5 min, 1 h, 1 day, etc.). This set of observations taken at different times is considered a time series data, and is of crucial importance in many applications related to the financial domain [
24,
25,
26,
27,
28,
29].
Several researchers have explored such time series data with the goal of forecasting future market behavior. The main advantage offered by the approaches based on the technical analysis [
9] is related to their capability to simplify the prediction by facing it like a pattern recognition problem. By following this strategy, the input data are given by the historical prices and technical indexes, while the output (forecasting) is generated by using an evaluation model defined on the basis of the past data [
15]. Both the statistical and more recent machine-learning-based techniques work by defining their evaluation models considering historical market data as time series. This way, it is possible to analyze the historical data of the stock market, making predictions for the future by using a large number of state-of-the-art techniques and strategies designed to work with time series data [
30].
Many machine learning approaches have been deployed in order to analyze this specific kind of time series, which has a non-randomicity and nonlinearity nature [
31,
32], in order to predict different market prices and returns. Most of these approaches are aimed to predict the single price and/or the prices behavior. The work in [
33] used standardized technical indicators to forecast rise or fall of market prices with the AdaBoost algorithm, which is used to optimize the weight of these technical indicators. In [
34,
35], the authors used an Auto Regressive Integrated Moving Average (ARIMA) in pre-processed time series data in order to predict prices. The authors in [
36] proposed a hybrid approach, based on Deep Recurrent Neural Networks and ARIMA in a two-step forecasting technique to predict and smooth the predicted prices. Another hybrid approach is proposed in [
37], which uses a sliding-window metaheuristic optimization with the firefly algorithm (MetaFA) and Least Squares Support Vector Regression (LSSVR) to forecast the prices of construction corporate stocks. The MetaFA is chosen to optimize, enhance the efficiency, and reduce the computational burden of LSSVR. The work in [
38] used Principal Component Analysis to reduce the dimensionality of the data, Discrete Wavelet Transform to reduce noise, and an optimized Extreme Gradient Boosting to trade in financial markets. The work in [
39] validated an extension of Support Vector Regression, called Twin Support Vector Regression, for financial time series forecasting. The work in [
40] proposed a novel fuzzy rule transfer mechanism for constructing fuzzy inference neural networks to perform two-class classification, such as what happens in financial forecasting (e.g., buy or sell). Finally, the authors in [
41] proposed a novel learning model, called the Quantum-inspired Fuzzy Based Neural Network, for classification. This learning happens using concepts of Fuzzy c-Means clustering. The reader should notice that fuzzy learning is commonly used to reduce uncertainty in the data [
42], so such solutions can be useful for financial forecasting. Several other interesting studies have been carried out in the literature, such as a comparison of deep learning technologies to price prediction [
43], the use of deep learning and statistical approaches to forecast crisis in the stock market [
44], and the use of reward-based classifiers such as Deep Reinforcement Learning [
45], among others.
However, it is usually known that single classifiers/hybrid approaches can obtain better performance than that of their single versions when applied in an ensemble model [
46,
47]. With that in mind, the literature also reports many approaches that exploit a set of different classification algorithms [
46,
48,
49] whose results are combined according to a certain criterion (e.g., full agreement, majority voting, weighted voting, among others). An ensemble process can work in two ways: by adopting a
dependent framework (i.e., in this case, the result of each approach depends on the output of the previous one), or by adopting an
independent framework (i.e., in this case, the result of each approach is independent) [
50]. In this sense, the work in [
51] proposed a novel multiscale nonlinear ensemble leaning paradigm, incorporating Empirical Mode Decomposition and Least Square Support Vector Machine with kernel function for price forecasting. The work in [
52] fits the same Support Vector Machines classifier multiple times on different sets of training data, increasing its performance to predict new data. The authors of [
53] combined results of bivariate empirical mode decomposition, interval Multilayer Perceptrons, and an interval exponential smoothing method to predict crude oil prices. Other interesting approaches using ensembles are the use of multiple feed forward neural networks [
54], multiple artificial neural networks with model selection [
55], among others.
Notwithstanding, it should be observed that the improvement of ensembles does not represent the norm because certain ensemble configurations can bring a decreasing of the classification performance [
56], so a smarter way to select classifiers in the ensemble must be done. Additionally, literature solutions have used ensembles of classifiers with fixed hyper-parameters, such as how to dispose the data to train the ensemble, how to select the parameters of the feature selection approach, among others. In addition, several works employ classifiers without stating with clarity which is the best and under which conditions. This may bring the belief that each classifier exploits peculiarities of the presented market data and, therefore, this does not help with understanding whether the method is effective or the used ensemble has been chosen specifically for the considered market [
17,
18]. Finally, the use of more diverse classifiers is not extensively studied in the proposed ensembles and neither is a flexible ensemble approach that is adjustable to any kind of market. We show how we tackle these issues with our proposed method in the next section.
3. Proposed Approach
With the previous limitations of literature approaches in mind, we propose in this paper an auto-configurable ensemble, composed of any number of classifiers and adjustable to any market. This ensemble is created automatically after optimizing two sets of parameters: hyper and intrinsic. Once optimized in In-Sample late past (IS) data, hyper-parameters are transferred to the training part of early past data, which we call Out-of-Sample (OOS) data. These hyperparameters will help to find another set of parameters, called intrinsic (classifier) parameters that are optimized in order to update the ensemble of classifiers to more recent data. Then, any new data can be tested. This reduces the problem of creating ad hoc ensembles for specific markets, as our ensemble method outputs a pool of best classifiers for any market as soon the market data are in the IS and training part of OOS sets. Additionally, we allow any number and type of classifiers technologies in the proposed ensemble, minimizing the brute force search for specific classifiers in an ensemble.
Our proposed auto-configurable ensemble is composed of three steps, as follows:
Feature Selection: data from the target market are pre-processed, with parameters being learned in the IS data.
Two-Step-Auto Adjustable Parameters Ensemble Creation: with the auto-configurable optimized sets of hyper and intrinsic parameters found in IS data, the approach outputs the set of hyper-parameters only, which will be transferred to a new optimization round. This new optimization step is done in the training part of the OOS data, and will find final intrinsic parameters in recent data to build the final ensemble of classifiers.
Policy for Trading: we define how to use the created ensemble to trade.
Detailed discussions of these steps are done in the next subsections.
3.1. Feature Selection
In order to reduce noise from the data, the literature reports some approaches able to better generalize the involved information by selecting only the characteristics that best represent the domain taken into account (e.g., the stock market). Although other feature selection techniques could be used by our proposed approach, we considered the Independent Component Analysis (ICA) in our approach, as it was, as far as we know, not fully explored in the financial market context. This feature selection approach is able to extract independent streams of data from a dataset composed of several unknown sources, without the need to know any criteria used to join them [
57].
The idea of ICA is to project the
d-dimensional input space into a lower dimensional space
. It does this by finding a linear representation of non-Gaussian data, so the components are statistically independent. Let us assume a
d-dimensional observation vectors
composed of zero mean random variables. Let
be the
d-dimensional transform of
x. Then, the problem is to determine a constant weight matrix
W so that the linear transformation of the observed variables
has certain properties. This means that the input
x can be written in terms of the independent components, or
where
A is the inverse (or the pseudo-inverse) of the
W transform matrix.
The ICA Based dimensionality reduction algorithm is based on the idea that the features that are least important are the ones whose contribution to the independent components are the least. The least important features are then eliminated and the independent components are recalculated based on the remaining features. The degree of contribution of a feature is approximated as the sum of the absolute values of the transform matrix
W entries associated with that feature. The ICA process considers the input data as a nonlinear combination of independent components by assuming that such a configuration is true in many real-world scenarios, which are characterized by a mixture of many nonlinear latent signals [
58,
59]. A more rigorous formalization of ICA is provided in [
60], where it has adopted a statistical
latent variables model. It assumes that we observe
n linear mixtures of
n independent components.
In our optimized ICA approach, we select the best possible number of parameters to be used by this technique, no matter the market considered. This is done by adjusting hyper-parameters, a step further discussed in the next subsection.
3.2. Two-Step Auto Adjustable Parameters’ Ensemble Creation
This section discusses the proposed method of generating automatically an ensemble of several classifiers to trade in any kind of market. We start by giving an overview of the approach; then, we show how we perform optimization of parameters and, finally, we describe the parameters to be learned in order to output the final ensemble.
3.2.1. Overview
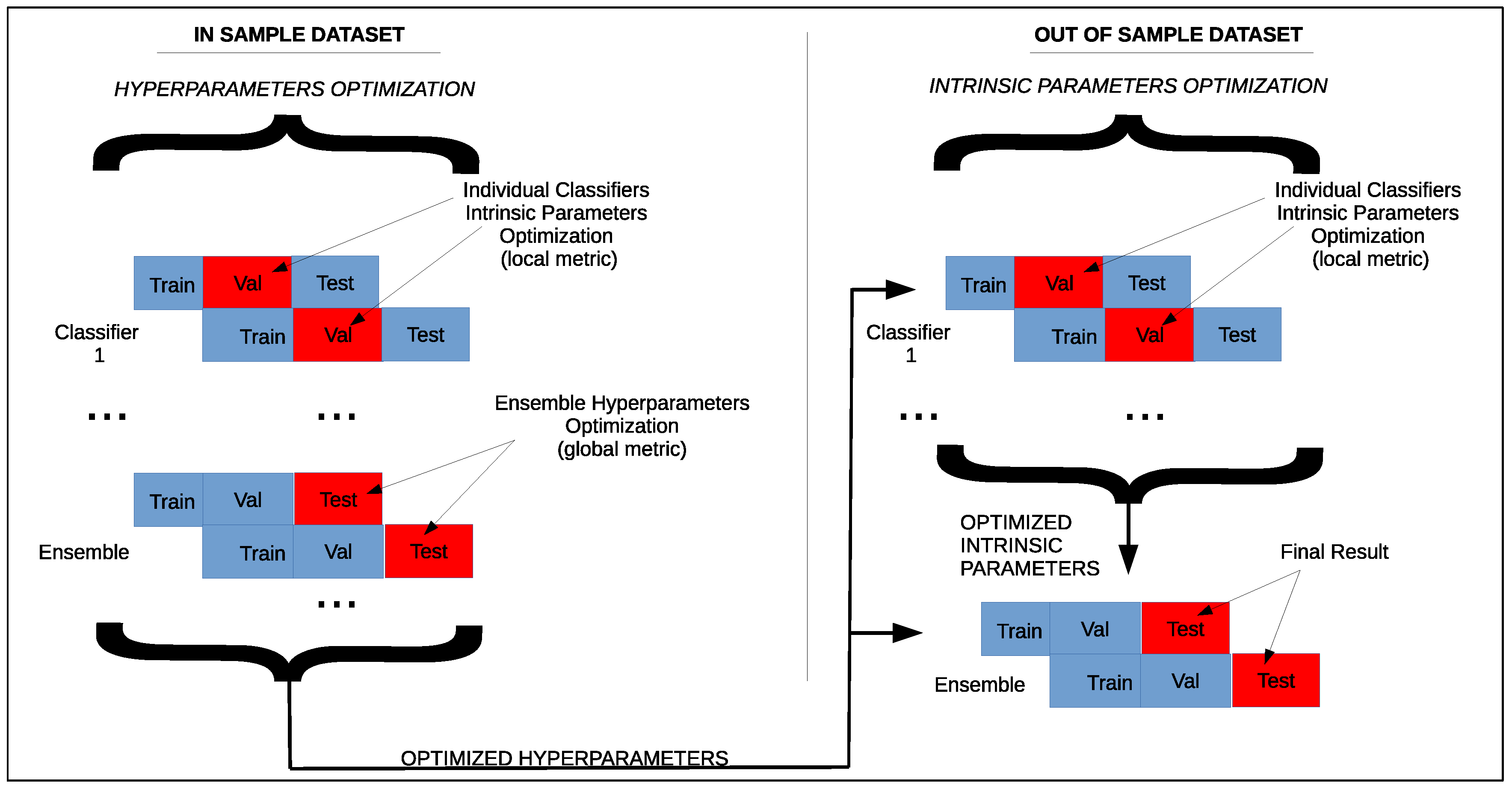
Our method is a self-configurable ensemble of classifiers whose pipeline can be seen in
Figure 1. In our approach, hyperparameters (time-series-based) are optimized through performances metrics calculated for the ensemble in the IS data, and are transferred to the training set of OOS (more recent past) data. Finally, intrinsic (classifiers) parameters are found for the classifiers of the final ensemble, considering more recent past data and the ensemble is updated to test any kind of new data.
The performance metrics we consider in our study lie within the machine learning and the economic domains. The rationale behind that is that, in addition to a mere evaluation of the percentage of correct predictions (i.e., accuracy), it is also necessary to estimate the impact of them at the economic level. For instance, the measurement of a good accuracy in the predictions related to a period of five years is not significant if, for some intervals of this period (e.g., two consecutive years), we suffered huge economic losses that, certainly, in a real-world scenario, would have stopped any further investment. For this reason, together with the
Accuracy metric, we adopted as evaluation metrics the
Maximum Drawdown, the
Coverage, and the
Return Over Maximum Drawdown, whose formalization will be provided later in
Section 4.2.
To illustrate the benefits of our proposed auto-configurable ensemble method, we build it considering three basic state-of-the-art classifiers [
3,
61,
62]:
Gradient Boosting (GB),
Support Vector Machines (
SVM), and
Random Forests (
RF), although any other kinds of classifiers may either replace those or be plugged in. Our method has two sets of parameters to be learned, through a methodology described in detail in the next subsection.
3.2.2. Walk-Forward Optimization
One of the most used optimization approaches within a financial forecasting process for the detection of the best parameters to adopt in the trading strategy is called
Walk Forward Optimization (
WFO) [
63]. We adopt such a strategy to find the best ensemble hyperparameters in the IS data and intrinsic parameters in part of OOS data. It works by isolating the IS time series into several segments, or walks, where each segment is divided in two parts:
Training and
Testing sets. The parameters optimization for the used trading strategy is then performed by (i) using several combinations of parameters to train the model in the training part of a segment; and (ii) declare the best (optimized) parameters the ones that yield best performance in the testing set of the same segment. The process is then repeated on the other segments. The performance obtained in the testing set of each segment is not biased as we are not using unknown data, but just IS data. The
Walk Forward Optimization can be performed by following two methodologies, described as follows:
Non-anchored Walk Forward Optimization: this approach creates walks of the same size. For example, let us assume we have a dataset composed of 200 days that we want to divide into six walks of 100 days. One way is to consider the first 80 days of each walk as the training set and the remaining 20 days as the testing set, as shown on the left side of
Table 1.
Anchored Walk Forward Optimization: in this scenario, the starting point of all segments is the same. Additionally, the training set of each segment is longer than the training set of the previous one; therefore, the length of each walk is longer than the length of the previous one, as shown on the right side of
Table 1.
In our approach, we consider the
non-anchored modality of the
Walk Forward process, a widely used approach in the literature for financial markets [
64]. Additionally, the non-anchored WFO used in our approach further subdivides the training data in
Table 1 into training and validation data, where the validation data are 30% of the training data. Then, the performance in the validation data will help find a set of intrinsic parameters of the classifiers of the ensemble, whereas the performance in the testing data will find the hyper-parameters of the ensemble. We discuss such auto-configurable parameters in the next section.
3.2.3. Transferable Self Configurable Parameters
With the information of the classifiers used and the optimization methodology in mind, we finally describe the parameters to be found in order to generate the final ensemble. The first set of parameters to be learned through non-anchored WFO comes from the classifiers and are reported in
Table 2, along with a list of values that must be
grid searched within the process. Other values and even other parameters can be added too, making the classifiers even more robust to the uncertainties in the training data. Such values are optimized according to the performances in the validation data, a fraction of the
training data discussed before in
Section 3.2.2.
The second set of parameters to be tuned is represented by the hyper-parameters, which are not from the classifiers anymore, but are related to the non-anchored WFO and ICA feature selection.
Table 3 shows the hyper-parameters that need to be optimized according to the chosen metric. They are (i) the dimension of the window for each walk; (ii) the training set size; (iii) lag size; and (iv) number of output signals of the considered ICA feature selection approach. These hyper-parameters are optimized through the chosen performance metrics after ensemble classification of
testing data, where
. These hyperparameters’ self-configuration step of our approach is carried out only within the IS part of our dataset, according to a considered metric. Once the hyperparameters and intrinsic parameters are found in the IS data, the algorithm transfers the hyperparameters only to the OOS dataset. Then, only the intrinsic parameters of the ensemble are optimized and, thus, the ensemble is ready to test new data.
Algorithm 1 describes the proposed approach of multi-classifiers’ auto-configurable ensemble. The algorithm has three main variables: (i) (initialized in step 7 of the algorithm), which will be used in step 28 to check which hyperparameter has the best ensemble performance metric; (ii) (initialized in step 8 of the algorithm), which will sum up the metric of applying the ensemble in test part of IS data in all walks; and (iii) (initialized in step 14 of the algorithm), which will be used to optimize classifiers intrinsic parameters in the validation data of each walk. The algorithm starts by, given a combination of hyperparameters , building the walks W (step 10) and, for each walk , it builds and transforms features (steps 12 and 13), doing a grid search in all the classifiers’ intrinsic parameters combinations in order to find the best classifier for each walk (steps 16–22). After the best of each classifier is found for a walk, we apply the ensemble of them accumulating the performance metric in the testing data for all the walks (step 26). After this is done for each hyperparameter combination, we verify, in steps 28–30, if the total metric of the ensemble in all the walks is the highest possible. When all the hyperparameter combinations h have their ensemble tested and with their accumulated metrics on the testing data calculated, in step 33, the algorithm is sure that it found the best possible hyperparameter , which is returned by the algorithm.
After the hyperparameters are found in the IS data, we start the search for the intrinsic parameters of the ensemble in recent past data, and then our ensemble is ready and can already trade. Such procedure is reported in Algorithm 2. In this algorithm, just two metrics are necessary: (i) the variable (step 12 of the algorithm) to tune the intrinsic parameters of the classifiers in the new OOS data; and (ii) (step 8 of the algorithm) to calculate the final metrics of the ensemble trading on unseen OOS data. The process is similar to Algorithm 1, with the difference being the fact that hyperparameters are not searched anymore and the testing data are used to report trading real-time results. The algorithm returns the mean metric, considering the whole testing period.
| Algorithm 1 Proposed hyperparameter search approach. |
Require: - 1:
= time series from in sample data - 2:
I = list of intra-parameters as shown in Table 2 - 3:
H = list of hyperparameters as shown in Table 3 - 4:
C = list of classifiers from the ensemble
Ensure: - 5:
= Optimized hyperparameters - 6:
procedureReturn_Hyperparameters(, I, H, C) - 7:
- 8:
- 9:
for h in H do ▹for each hyperparameter combination - 10:
▹ Starts non-anchored WF0 - 11:
for w in do ▹ for each walk - 12:
▹ get features - 13:
▹ transform features - 14:
- 15:
for c in C do ▹ for each classifier - 16:
for i in I do ▹ for each intrinsic parameter, train and validate - 17:
- 18:
- 19:
if then - 20:
- 21:
- 22:
end if - 23:
end for - 24:
end for - 25:
- 26:
- 27:
end for - 28:
if then - 29:
- 30:
- 31:
end if - 32:
end for - 33:
return - 34:
end procedure
|
| Algorithm 2 Proposed intrinsic parameter search approach and ensemble trading |
Require:- 1:
= time series from in sample data - 2:
I = list of intra-parameters as shown in Table 2 - 3:
= best hyperparameter found in Algorithm 1 - 4:
C = list of classifiers from the ensemble
Ensure: - 5:
= Mean performance of trading - 6:
procedureEnsemble_Trading(, I, , C) - 7:
▹ Starts non-anchored WFO - 8:
▹ Metric used to report testing results - 9:
for w in Wdo ▹for each walk - 10:
▹ get features - 11:
▹ transform features - 12:
- 13:
for c in Cdo ▹ for each classifier - 14:
for i in I do ▹ for each intrinsic parameter, train and validate - 15:
- 16:
- 17:
if then - 18:
- 19:
- 20:
end if - 21:
end for - 22:
end for - 23:
- 24:
- 25:
end for - 26:
- 27:
return - 28:
end procedure
|
Doing the search of parameters this way, the hyper-parameters of the final ensemble will be optimized in the IS data through non-anchored WFO. Then, these hyperparameters are transferred to the non-anchored WFO of the OOS data, and intrinsic parameters are now optimized in the validation data only. Thus, an auto adjustable ensemble approach is built in such a way that will return an ensemble of the best possible classifiers for any market, as long as their IS and training and validation OOS data are fed to the algorithm, being this way a data-driven optimization approach.
3.3. Policy for Trading
Many literature studies [
65,
66] demonstrate the effectiveness of ensemble approaches that implement different algorithms and feature subsets. Ensemble approaches [
67] usually get the best results in many prestigious machine learning competitions (e.g., Kaggle, Netflix Competition, KDD, and so on).
Therefore, in this paper, we are adopting an
ensemble learning approach, which means that the final result (i.e., the prediction) is obtained by combining the outputs made by single algorithms in the ensemble. As stated before in
Section 2, such an ensemble process can work in a dependent or independent fashion. The approach we choose is the independent framework, so each classifier decision may represent a vote that is independent from the others. We apply such an approach using three selected algorithms (i.e.,
Gradient Boosting,
Support Vector Machines, and
Random Forests) with their ensemble hyperparameters initially found in the IS data, and whose individual classifiers intrinsic parameters are found in the OOS data. We adopt in our ensemble approach the aggregation criterion called
complete agreement, meaning that we make our prediction to
buy or
sell only if there is a total agreement among all the algorithm predictions, otherwise we do not make a prediction for the related futures market (
hold). This is an approach that usually leads towards better predictive performance, compared to that of each single algorithm. Such an approach for the future day prediction is better illustrated in Algorithm 3.
| Algorithm 3 Future day prediction |
Require:A = Set of algorithms, D = Past classified trading days, = Day to predict Ensure: = Day prediction - 1:
procedurePrediction(A, D, ) - 2:
- 3:
- 4:
if == ∧ == then - 5:
← - 6:
else if == ∧ == 1 then - 7:
← - 8:
else - 9:
← - 10:
end if - 11:
return - 12:
end procedure
|
4. Experimental Setup
In this section, we discuss the setup chosen to guide the experiments performed to validate our ensemble approach against some baselines from the literature. We start discussing the datasets, the performance metrics, and implementation aspects of our proposed method and of the competitors.
4.1. Datasets
To verify our approach performance against some baselines, we selected four datasets based on stock futures markets (
SP500,
DAX and
FIB) and one future of commodity (
CL). As far as the stock futures markets are concerned, we included the
FIB market, which is characterized by an atypical behavior with respect to the other stock futures markets in the years taken into account during the experiments. We based our choice on the observation that stock markets behavior is usually different from that of the bond markets, as there usually exists an inverse correlation between them. Indeed, the stock futures are frequently characterized by a strong upward bias (e.g.,
SP500 and
DAX), with some exceptions related to some particular economic scenarios, as it happened for the Italian
FIB in recent years. Details of such datasets are reported in
Table 4.
These datasets can be easily found at different time resolutions (e.g., 5-min, 10-min, 1-h, etc.). In this work, we further transform the futures market datasets by adopting a 1-day resolution. It means that, starting from the original resolution that characterizes the dataset (e.g., 5-min, 10-min, 1-h, among others), the data have been opportunely joined in order to obtain for each day included in the dataset the following new information I = {date, open value, highest value, lowest value, close value, exchange volume}, where each record of the new dataset corresponds to one day. As the SP500 market has a point value of 50 USD, the DAX market has a point value of 25 EURO, the FIB market has a point value of 5 EURO and the CL market has a point value of 1000 USD, in order to simplify, we do not convert the points to their corresponding currency values, keeping such information in points.
In these datasets, we denote a set of data composed of a series of consecutive trading days as , and a set of features that compose each and if the of the next day is greater than or equal to zero, and , otherwise. We also label the buy operation to 1, and sell operation to , as they represent the operations allowed on the futures markets taken into consideration in this paper.
It should be observed that, according to the aforementioned definition of , a trading day can only belong to one class , where . We also denote as the components of each trading day , obtained by transforming the original data through a feature selection process, which in our case is ICA. Finally, we denote a set of of operations allowed on a futures market, where means that no operation of buy or sell has been performed. The reader notices that a buy operation corresponds to a long trade (), where a trader buys an asset hoping the price will go up at the end of the day. On the other hand, a sell operation corresponds to a short trade (). In such a case, a trader sells an asset before buying it hoping that its price will go down.
Given the previous definitions, for each trading day
x (i.e., each dataset row), we add a further data field
next, which corresponds to the target class related to the next trading day
, and is defined according to the notation reported in Equation (
3):
We let the reader observe that the time series resolution may be set even to a finer scale, e.g., hours or minutes. In such a case, a record in a given time interval would consist of a group features {time, open value, highest value, lowest value, close value} for each considered interval, ended with the next class, as defined above.
To train our prediction models with more than a day of the features market (
lags hyper-parameter in
Table 3), we can arbitrarily aggregate more days, obtaining a series of vectors
V composed of ICA components of
N days, with the
next value as target class. As an example, assuming we have to aggregate three days
, each of them characterized by two ICA components
, we would obtain the vector shown in Equation (
4):
In our experiments, we report the experiments considering the period from 2016 to 2018 as OOS data, where we have updated and tested our approach after the auto-configuration and tuning of the hyperparameters in the IS data, which uses the remaining years.
4.2. Evaluation Metrics
In this subsection, besides the canonical performance evaluation metrics such as Accuracy, we added in our study other financial performance metrics, such as Maximum Drawdown, Coverage, Return Over Maximum Drawdown, and Equity Curve. In the following, we detail each of them.
4.2.1. Accuracy
This metric gives us information about the number of instances correctly classified, compared to the total number of them. It provides an overview of the classification performance. Formally, given a set of
X closing trading days to be predicted, it is calculated as shown in Equation (
5), where
stands for the number of trading days and
stands for the number of those correctly classified:
As our approach only acts in the market when there is a total agreement of votes between the classifiers considered, we calculate the accuracy only when our proposed ensemble takes decisions (i.e., no hold operations are done). This happens because our trader does not enter the market all the time, so the accuracy of our trader is considered a different metric than the same used for baselines, which enter the market all the time. Therefore, we use the accuracy metric in the experiments not for benchmarking all approaches, but rather for two tasks: (i) compare the individual original and boosted classifiers in order to highlight the benefits of the data-driven nature of our approach; and (ii) assess the accuracy of our proposed approach according to its total trading actions in the market.
4.2.2. Maximum Drawdown (MDD)
Such a metric represents the largest drop from a peak to a trough before a new peak is reached. It indicates the downside risk in a the time period taken into account [
68]. A low maximum drawdown is preferred as this indicates that losses from investment were small. If an investment never lost a penny, the maximum drawdown would be zero. Formally, denoting as
P the peak value before the largest drop, and as
L the lowest value before a new high is established, its formal notation can be simplified as shown in Equation (
6):
As stated before, low MDDs mean that losses in a trading strategy are low. Therefore, we use the Maximum Drawdown in our experiments as a measure to quantify how risky are the algorithms evaluated.
4.2.3. Coverage (COV)
The coverage metric reports the percentage of times we carried out an operation [
69] (i.e.,
buy or
sell) on the futures market (i.e.,
) compared to the number of days taken into consideration (i.e.,
), as shown in Equation (
7). It gives us important information, since in addition to predicting a buy or sell operation, an algorithm can also predict to not buy and not sell anything (
hold):
In our experiments, we use the metric to quantify how many times our proposed trading system decides to act in the market (i.e, perform Long or Short operations).
4.2.4. Return over Maximum Drawdown (RoMaD)
The RoMaD is a metric largely used within the financial field in order to evaluate the gain or loss in a certain period of time, such as the
Sharpe Ratio or the
Sortino Ratio [
70,
71]. More formally, it represents the average return for a portfolio expressed as a proportion of the
Maximum Drawdown level, as shown in Equation (
8), where
Portfolio Return denotes the difference between the final capital and the initial one:
In practice, investors want to see maximum drawdowns that are half or less the annual portfolio return. This means that, if the maximum drawdown is 10% over a given period, investors want a return of 20% (RoMaD = 2).
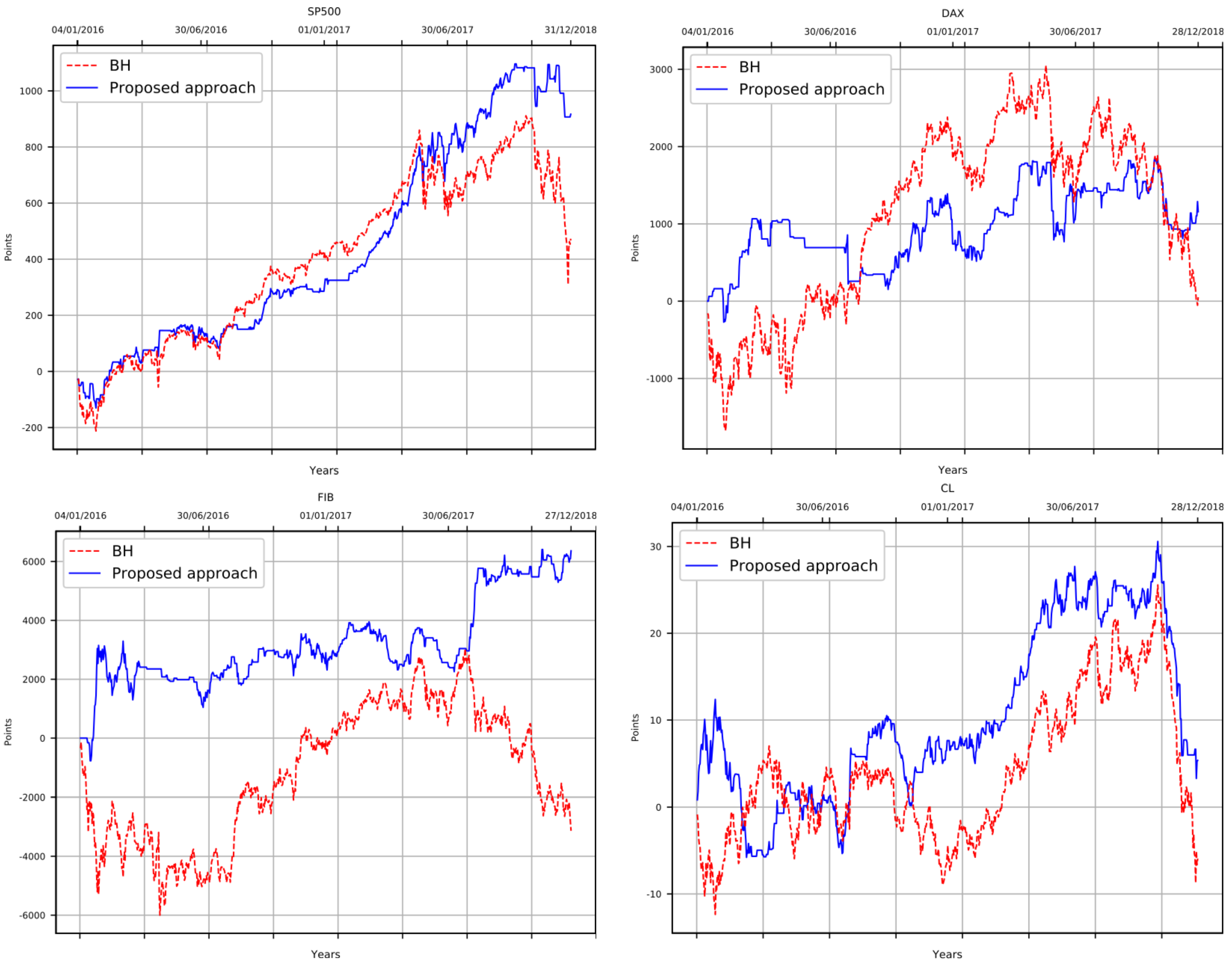
4.2.5. Equity Curve
The
Equity Curve (
EC) reports the change in the value of a trading account in the time period graphically [
72]. A significant positive slope usually indicates the effectiveness of the adopted trading strategy, while negative slopes indicate that such a strategy generates negative returns. For instance, given an
Initial Investment II to trade a
number of futures that have a certain
entry price and
exit price, and also considering the related
trade commission, we can calculate the points
that we need to plot in the
Equity Curve as shown in Equation (
9):
We use the EC in our experiments to compare the evolution of gains and losses of all the evaluated algorithms over time.
4.3. Technical Details
The approach proposed in this paper has been developed in
Python, as well as the implementation of the state-of-the-art classification techniques used to define our ensemble approach, which are based on
scikit-learn (
http://scikit-learn.org). In order to make our experimental results reproducible, we have set to zero the seed of the pseudo-random number generator used by the
scikit-learn evaluation algorithms. The machine where all the experiments have been performed is an
Intel i7-3770S, octa-core(
3.10 GHz ×
8) with a
Linux 64-bit Operating System (
Debian Stretch) with
8 GB of
RAM.
As for the competitors, we firstly considered the common Buy and Hold baseline strategy. It represents a passive investment strategy in which the investors buy futures and hold them for a long period, regardless of the market’s fluctuation. Such a strategy is largely used in literature as a baseline to evaluate the profitability of an investment strategy. In addition, we performed the future market predictions by using single predictors (i.e.,
GB,
SVM, and
RF), configuring their default hyper-parameters according to some common values in the literature:
of the IS dataset as walk size, of which
is used as training set and the remaining
as validation set with 5 day-lags [
15,
16,
73,
74,
75]. Finally, we also used a recent approach to perform trading [
39], which we call
TSVR in the remaining of this paper. For this approach, we used both the linear (
LIN) and nonlinear (
NONLIN) kernel. As described in in [
39], we have used 10-fold cross validation in the training data to find the kernel parameters that yielded the best mean squared error in all markets. As this approach is proposing to predict the closing price (regression problem), we mapped the problem consistently with ours and changed the output so that for each day we have either a long or short operation. As with our approach, final results are reported in terms of classification performance in the testing part of the OOS dataset.
Regarding time consumption related to our approach, we can observe from the pipeline showed in
Figure 1 that it is strictly related to the canonical time spent by each algorithm that composes the ensemble, multiplied by the intrinsic parameters involved in the auto-tuning process plus the time spent by other processes (i.e.,
walk-forward and
ICA Feature Selection), since the detection process of the optimal hyper-parameters has been previously (one time) performed in the in-sample part of the datasets; therefore, it does not need to be repeated at each prediction.
More formally, assuming
t being the execution time of each ensemble algorithm,
the number of algorithms in the ensemble,
the number of parameters involved in the auto-tuning process and
the execution time related to the other processes, the total time consumption
can be formalized as shown in Equation (
10):
For example, with a previous information that the proposed approach involves three algorithms (i.e.,
Gradient Boosting,
Support Vector Machine, and
Random Forests) with, respectively, three, four, and three intrinsic parameters, and by using a machine with the software and hardware characteristics reported in
Section 4.3, the average time consumption for each prediction on the markets taken into account is reported in
Table 5.
It should be observed that such a running time can be effectively reduced by parallelism of the process over several machines, both along algorithms and markets, by exploiting large scale distributed computing models such as MapReduce [
76,
77]. This improves the approach scalability in the context of applications that deal with frequency trading.
6. Conclusions
The high degree of complexity, dynamism, and the non-stationary nature of data involved in the futures markets makes the definition of an effective prediction model a challenge. In order to face this problem, this paper introduced an auto-configurable ensemble approach to significantly improve the performance of trading. This is done through optimizing two sets of parameters in late and early past data, returning customized ensembles that act by a complete agreement strategy in any kind of market.
By following a methodological experimental approach, our proposed automatic ensemble method starts auto-tuning hyper parameters in late past data. Among these hyperparameters, we tune feature selection parameters, which will return the best possible inputs for each classifier in the ensemble and also time series parameters, which will present the best disposal of features for the classifiers. As the last step, we tuned intrinsic classifiers parameters, creating powerful ensembles with classifiers trained with recent past data. Such an automatic ensemble fine-tune model returns an ensemble of best possible individual classifiers found in the training data, which can be applied for different markets. All these parameters optimizations are done through a Walk Forward Optimization approach considering the non-anchored modality. Results of trading in an out-of-sample data, spanning years 2016, 2017, and 2018 show that, despite the data complexity, the proposed ensemble model is able to get good performance in the context of positive returns in all the markets taken into consideration, being a good strategy for conservative investors who want to diversify, but keeping their investments profitable. It also turned out that, in one market, the proposed approach fails at achieving better trading performance than baselines. We believe that, in addition to select ad hoc hyper-parameters and intra-parameters for each market, an automatic selection of new ad hoc classifiers to be used by our proposed approach must also be done. We believe that this additional step can find new classifiers useful to understand different natures of data from different markets.
As future works for this research, a straightforward direction in which we are already heading lies within the domain of the Deep Learning ensembles. In fact, we are currently developing different models of deep neural networks, with the aim of creating an ensemble of them and testing them on the same out of sample markets data. Additionally, the investigation of other feature selection optimizations and even the creation of an ad hoc methodology is in our future research goals. One more path we are already exploring consists of applying the results of our ensemble to real trading platforms. The goal is, on the one hand, to simulate the real earnings we would have obtained on the past data and on a desired market. With the test being robust, on the other hand, the next step would be to perform real-time trading in a certain number of markets. The platform we are already playing with is MultiCharts (
https://www.multicharts.com/). Moreover, one more possible future work can involve the definition of multi-markets strategies, able to improve the prediction performance by diversifying the investments or by using information about the behavior of many markets, in order to fine-tune the kind of classifiers used or their predictions. Finally, as stated before, a
data-driven selection of classifiers for the ensemble, rather than just intrinsic and hyper parameters, is a promising research direction to be done.








{kind=link}
{kind=link}