GPU Computing with Python: Performance, Energy Efficiency and Usability †


Abstract
:1. Introduction
2. Related Work
3. GPU Computing in Python
3.1. CUDA
3.2. OpenCL
3.3. GPU Computing from Python
1 import numpy as np 2 import scipy.linalg.blas as blas 3 N = 2048 4 A = np.ones((N,N)) 5 C = blas.dgemm(alpha=1.0, a=A.T, b=A)
| Listing 1: Programming example that shows how to fill an array with the numbers 1 to N using PyCUDA. The corresponding C++ code is much longer. | |
| 1 | import pycuda.autoinit |
| 2 | import pycuda.driver as drv |
| 3 | import pycuda.compiler as compiler |
| 4 | import numpy as np |
| 5 | |
| 6 | module = compiler.SourceModule(""" |
| 7 | __global__ void fill(float ∗dest) { |
| 8 | int i = blockIdx.x∗blockDim.x+threadIdx.x; |
| 9 | dest[i] = i+1; |
| 10 | } """) |
| 11 | fill = module.get_function("fill") |
| 12 | |
| 13 | N = 200 |
| 14 | cpu_data = np.empty(N, dtype=np.float32) |
| 15 | fill(drv.Out(cpu_data), block=(N,1,1), grid=(1,1,1)) |
| 16 | print(cpu_data) |
- Prototype and develop code in a Jupyter Notebook;
- Clean up code in the notebook;
- Move code from notebook to separate Python modules.
3.4. C++ Versus Python
//Loop until iterations or until it diverges
while (|z| < 2.0 && n < iterations) {
z = z∗z + c;
++n;
}
4. Porting, Profiling, and Benchmarking Performance and Energy Efficiency
- A linear finite difference scheme;
- A nonlinear finite difference scheme; and
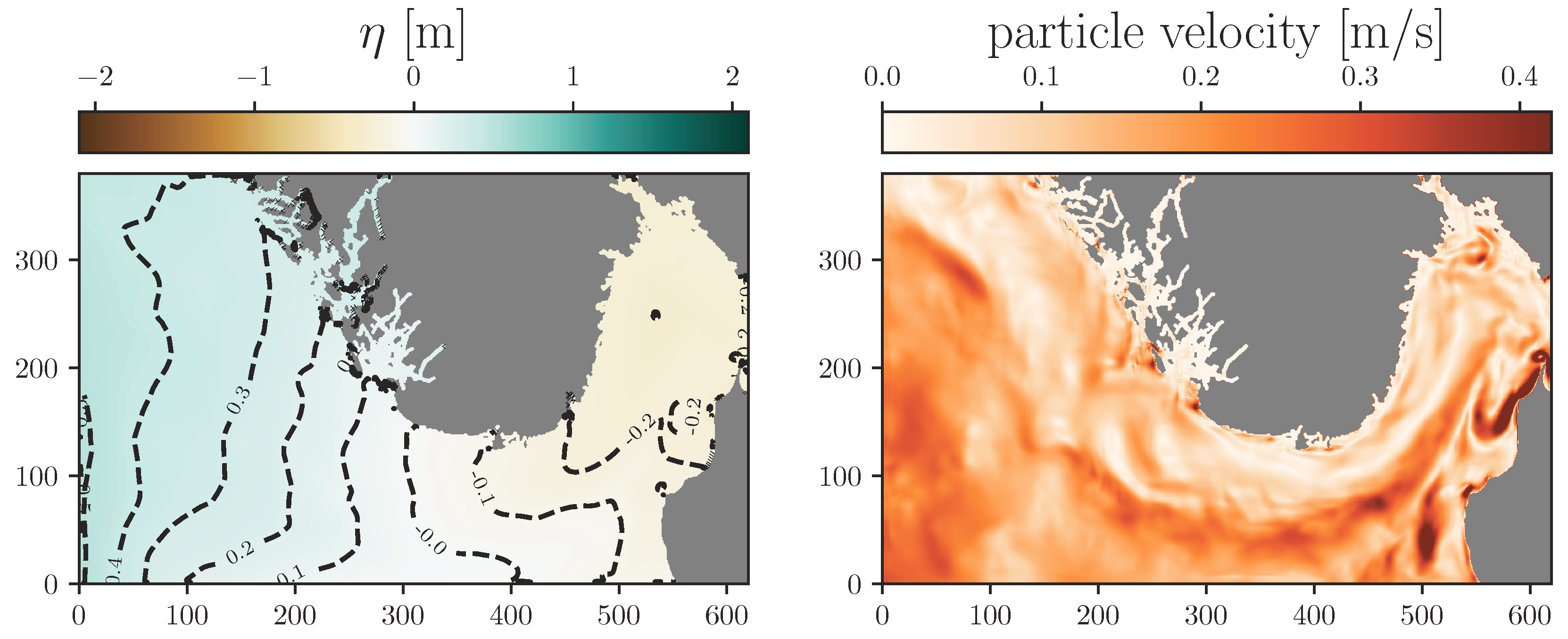
- A high-resolution finite volume scheme.
4.1. Porting from PyOpenCL to PyCUDA
- Import PyCUDA instead of PyOpenCL;
- Change API calls from PyOpenCL to PyCUDA, paying extra attention to context and stream synchronization;
- Adjust kernel launch parameters. Block sizes for PyCUDA need to be 3D, and global sizes are given in number of blocks instead of total number of threads;
- Use CUDA indexing in the kernels. Note that gridDim needs to be multiplied with blockDim to get the CUDA-equivalent of OpenCL get_global_size();
- Search and replace the remaining keywords in the kernels. Note that GPU functions in OpenCL have no special qualifier and that GPU main memory pointers need no qualifier for function arguments in CUDA.
4.2. Profile-Driven Optimization
4.2.1. The High-Resolution Finite Volume Scheme
- Recomputing bathymetry in cell intersections instead of storing ;
- Recomputing face bathymetry instead of storing and ;
- Reusing buffer for physical variables Q for storing the reconstruction variables R;
- Recomputing fluxes along the abscissa instead of storing F;
- Recomputing fluxes along the ordinate instead of storing G;
- Reusing the buffer for derivatives along the abscissa, , and derivatives along the ordinate, .
4.2.2. The Nonlinear Finite Difference Scheme
4.2.3. The Linear Finite Difference Scheme
4.3. Backporting Optimizations to OpenCL
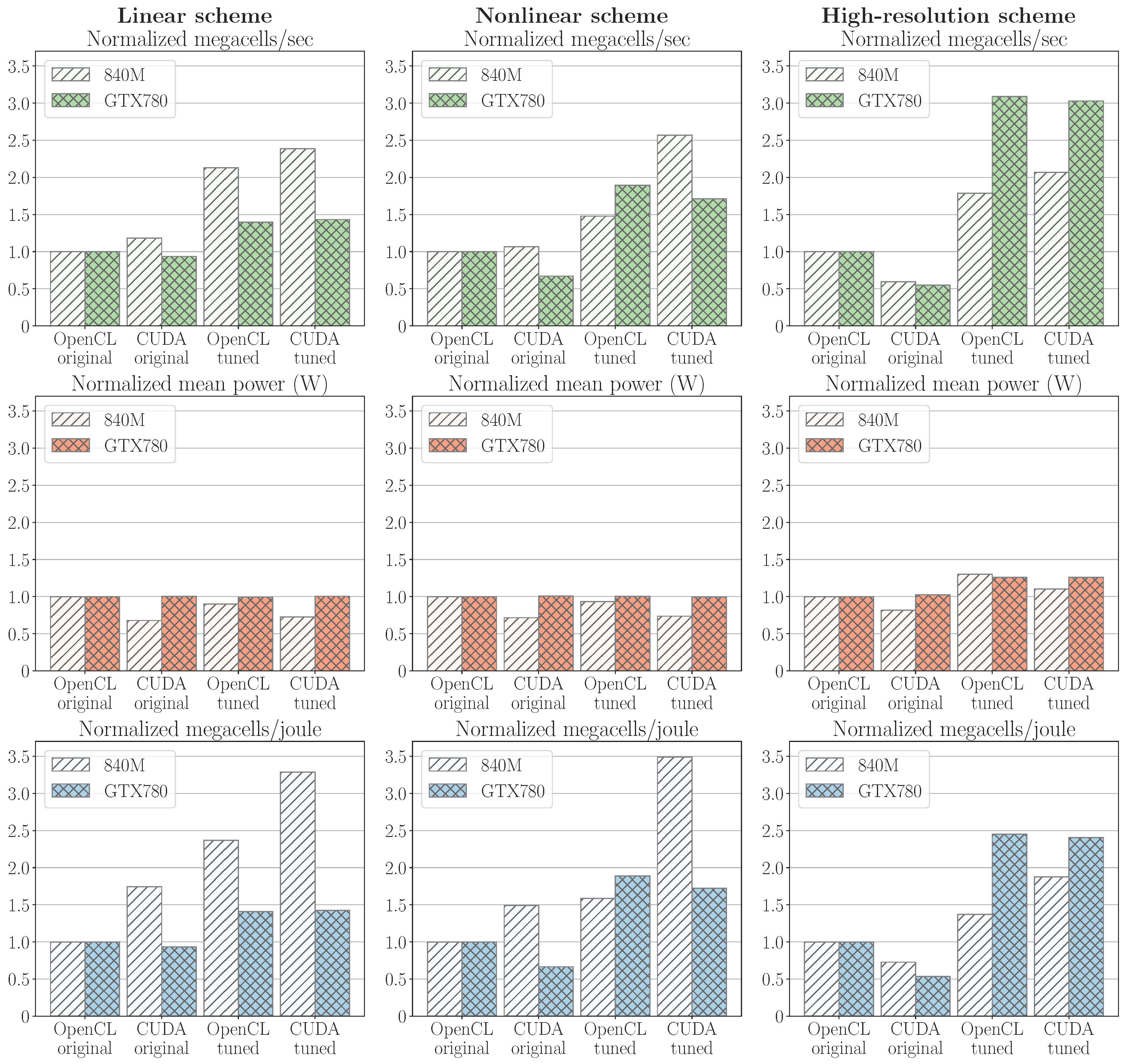
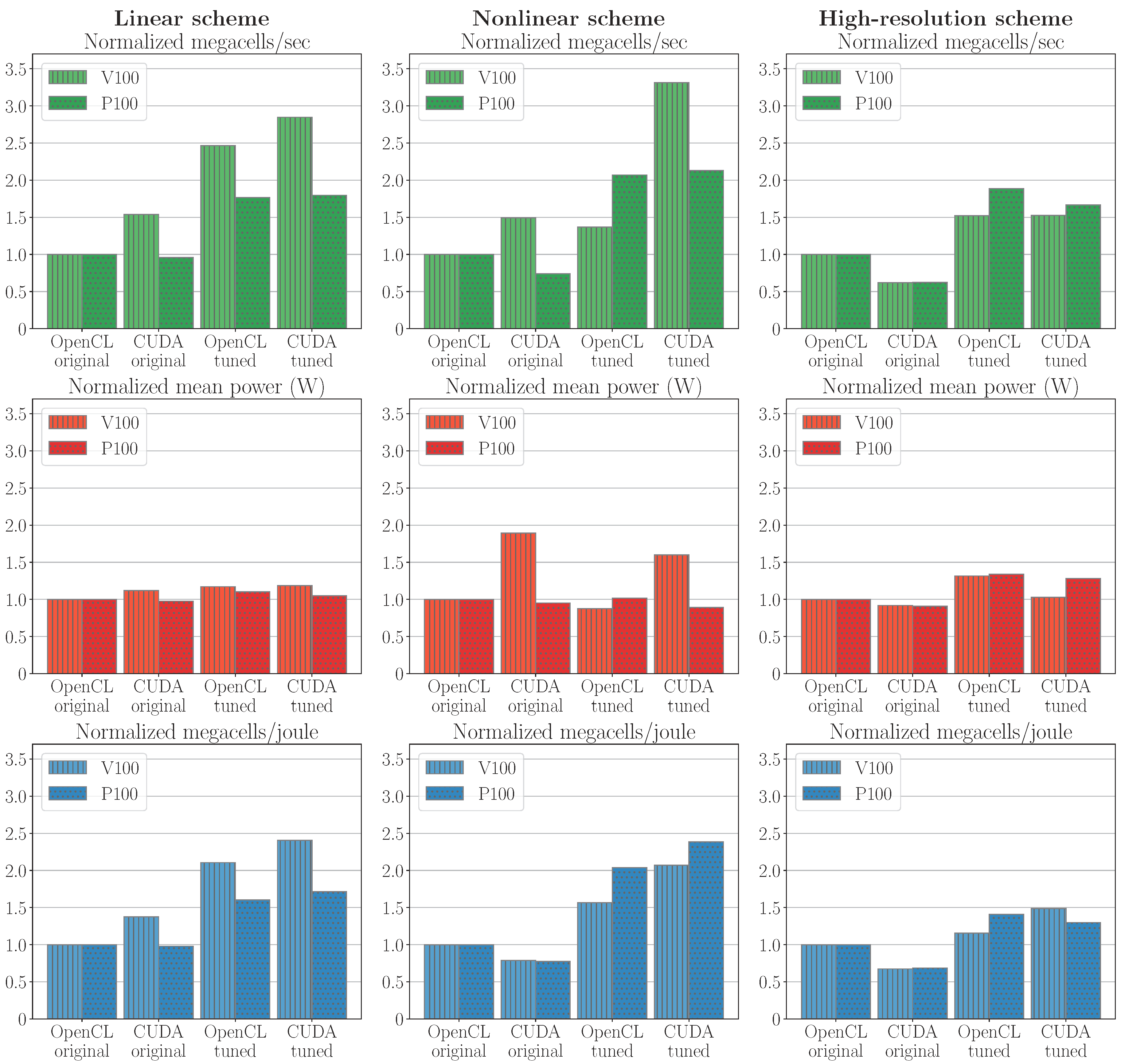
4.4. Comparing Performance
4.5. Measuring Power Consumption
4.6. Comparing Energy Efficiency
4.7. Tuning Block Size Configuration for Energy Efficiency
5. Summary
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| GPU | Graphics Processing Unit |
| HPC | High-Performance Computing |
| CPU | Central Processing Unit |
| CUDA | Compute Unified Device Architecture |
| OpenCL | Open Compute Language |
| FPGA | Field-Programmable Gate Array |
| ICD | Installable Client Driver |
| SDK | Software Development Kit |
| API | Application Programming Interface |
| SWIG | Simplified Wrapper and Interface Generator |
| DSP | Digital Signal Processors |
| BLAS | Basic Linear Algebra Subprograms |
| DGEMM | Dense General Matrix Multiplication |
| REPL | Read-Eval-Print Loop |
| FLOPS | Floating Point Operations per Second |
| NVRTC | Nvidia Runtime Compilation Library |
References
- Larsen, E.; McAllister, D. Fast matrix multiplies using graphics hardware. In Proceedings of the 2001 ACM/IEEE Conference on Supercomputing, SC’01, Denver, CO, USA, 10–16 November 2001. [Google Scholar] [CrossRef] [Green Version]
- Owens, J.; Luebke, D.; Govindaraju, N.; Harris, M.; Krüger, J.; Lefohn, A.; Purcell, T. A Survey of General-Purpose Computation on Graphics Hardware. Comput. Graph. Forum 2007, 26, 80–113. [Google Scholar] [CrossRef] [Green Version]
- Nanz, S.; Furia, C. A Comparative Study of Programming Languages in Rosetta Code. In Proceedings of the IEEE International Conference on Software Engineering, Florence, Italy, 16–24 May 2015; Volume 1, pp. 778–788. [Google Scholar] [CrossRef] [Green Version]
- Klöckner, A.; Pinto, N.; Lee, Y.; Catanzaro, B.; Ivanov, P.; Fasih, A. PyCUDA and PyOpenCL: A Scripting-Based Approach to GPU Run-Time Code Generation. Parallel Comput. 2012, 38, 157–174. [Google Scholar] [CrossRef] [Green Version]
- Asanović, K.; Bodik, R.; Catanzaro, B.; Gebis, J.; Husbands, P.; Keutzer, K.; Patterson, D.; Plishker, W.; Shalf, J.; Williams, S.; et al. The Landscape of Parallel Computing Research: A View from Berkeley; Technical Report; EECS Department, University of California: Berkeley, CA, USA, 2006. [Google Scholar]
- Brodtkorb, A. Simplified Ocean Models on the GPU. Available online: https://sintef.brage.unit.no/sintef-xmlui/bitstream/handle/11250/2565319/500-Article2bText-1025-1-10-20180815.pdf?sequence=2&isAllowed=y (accessed on 7 January 2020).
- Holm, H.; Brodtkorb, A.; Christensen, K.; Broström, G.; Sætra, M. Evaluation of Selected Finite-Difference and Finite-Volume Approaches to Rotational Shallow-Water Flow. Commun. Comput. Phys. 2019, accepted. [Google Scholar]
- Hagen, T.; Henriksen, M.; Hjelmervik, J.; Lie, K.A. How to Solve Systems of Conservation Laws Numerically Using the Graphics Processor as a High-Performance Computational Engine. In Geometric Modelling, Numerical Simulation, and Optimization: Applied Mathematics at SINTEF; Hasle, G., Lie, K.A., Quak, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 211–264. [Google Scholar] [CrossRef]
- Brodtkorb, A.; Sætra, M.; Altinakar, M. Efficient Shallow Water Simulations on GPUs: Implementation, Visualization, Verification, and Validation. Comput. Fluids 2012, 55, 1–12. [Google Scholar] [CrossRef]
- de la Asunción, M.; Mantas, J.; Castro, M. Simulation of one-layer shallow water systems on multicore and CUDA architectures. J. Supercomput. 2011, 58, 206–214. [Google Scholar] [CrossRef]
- Brodtkorb, A.; Sætra, M. Explicit shallow water simulations on GPUs: Guidelines and best practices. In Proceedings of the XIX International Conference on Computational Methods for Water Resources, Urbana-Champaign, IL, USA, 17–21 June 2012; pp. 17–22. [Google Scholar]
- Holewinski, J.; Pouchet, L.N.; Sadayappan, P. High-performance Code Generation for Stencil Computations on GPU Architectures. In Proceedings of the 26th ACM International Conference on Supercomputing, Venice, Italy, June 25–29 2012. [Google Scholar] [CrossRef] [Green Version]
- OpenACC-Standard.org. The OpenACC Application Programming Interface Version 2.7. Available online: https://www.openacc.org/sites/default/files/inline-files/APIGuide2.7.pdf (accessed on 7 January 2020).
- NVIDIA. NVIDIA CUDA C Programming Guide Version 10.1. Available online: https://docs.nvidia.com/cuda/archive/10.1/cuda-c-programming-guide/index.html (accessed on 7 January 2020).
- Khronos OpenCL Working Group. The OpenCL Specification v. 2.2. Available online: https://www.khronos.org/registry/OpenCL/specs/2.2/pdf/OpenCL_API.pdf (accessed on 7 January 2020).
- Brodtkorb, A.; Dyken, C.; Hagen, T.; Hjelmervik, J.; Storaasli, O. State-of-the-art in heterogeneous computing. Sci. Program. 2010, 18, 1–33. [Google Scholar] [CrossRef]
- Huang, S.; Xiao, S.; Feng, W.C. On the energy efficiency of graphics processing units for scientific computing. In Proceedings of the 2009 IEEE International Symposium on Parallel & Distributed Processing, Rome, Italy, 23–29 May 2009; pp. 1–8. [Google Scholar]
- Qi, Z.; Wen, W.; Meng, W.; Zhang, Y.; Shi, L. An energy efficient OpenCL implementation of a fingerprint verification system on heterogeneous mobile device. In Proceedings of the 2014 IEEE 20th International Conference on Embedded and Real-Time Computing Systems and Applications, Chongqing, China, 20–22 August 2014; pp. 1–8. [Google Scholar]
- Dong, T.; Dobrev, V.; Kolev, T.; Rieben, R.; Tomov, S.; Dongarra, J. A step towards energy efficient computing: Redesigning a hydrodynamic application on CPU-GPU. In Proceedings of the 2014 IEEE 28th International Parallel and Distributed Processing Symposium, Phoenix, AZ, USA, 19–23 May 2014; pp. 972–981. [Google Scholar]
- Klôh, V.; Yokoyama, D.; Yokoyama, A.; Silva, G.; Ferro, M.; Schulze, B. Performance and Energy Efficiency Evaluation for HPC Applications in Heterogeneous Architectures. In Proceedings of the 2018 Symposium on High Performance Computing Systems (WSCAD), São Paulo, Brazil, 1–3 October 2018. [Google Scholar]
- Memeti, S.; Li, L.; Pllana, S.; Kołodziej, J.; Kessler, C. Benchmarking OpenCL, OpenACC, OpenMP, and CUDA: programming productivity, performance, and energy consumption. In Proceedings of the 2017 Workshop on Adaptive Resource Management and Scheduling for Cloud Computing, Washington, DC, USA, 28 July 2017. [Google Scholar]
- Du, P.; Weber, R.; Luszczek, P.; Tomov, S.; Peterson, G.; Dongarra, J. From CUDA to OpenCL: Towards a performance-portable solution for multi-platform GPU programming. Parallel Comput. 2012, 38, 391–407. [Google Scholar] [CrossRef] [Green Version]
- Fang, J.; Varbanescu, A.; Sips, H. A Comprehensive Performance Comparison of CUDA and OpenCL. In Proceedings of the 2011 International Conference on Parallel Processing, Taipei City, Taiwan, 13–16 September 2011; pp. 216–225. [Google Scholar] [CrossRef]
- Gimenes, T.; Pisani, F.; Borin, E. Evaluating the Performance and Cost of Accelerating Seismic Processing with CUDA, OpenCL, OpenACC, and OpenMP. In Proceedings of the 2018 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Vancouver, BC, Canada, 21–25 May 2018; pp. 399–408. [Google Scholar] [CrossRef]
- Karimi, K.; Dickson, N.; Hamze, F. A Performance Comparison of CUDA and OpenCL. arXiv 2011, arXiv:1005.2581. [Google Scholar]
- Martinez, G.; Gardner, M.; Feng, W.-c. CU2CL: A CUDA-to-OpenCL Translator for Multi- and Many-Core Architectures. In Proceedings of the 2011 IEEE 17th International Conference on Parallel and Distributed Systems, Tainan, Taiwan, 7–9 December 2011; pp. 300–307. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Dao, T.; Jung, J.; Joo, J.; Lee, J. Bridging OpenCL and CUDA: a comparative analysis and translation. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Austin, TX, USA, 15–20 November 2015; pp. 1–12. [Google Scholar] [CrossRef]
- Holm, H.; Brodtkorb, A.; Sætra, M. Performance and Energy Efficiency of CUDA and OpenCL for GPU Computing using Python. Proceedings of The International Conference on Parallel Computing ParCo2019, Prague, Czech Republic, 10–13 September 2019. [Google Scholar]
- Kaeli, D.; Mistry, P.; Schaa, D.; Zhang, D. Heterogeneous Computing with OpenCL 2.0; Morgan Kaufmann: Burlington, MA, USA, 2015. [Google Scholar]
- Sanders, J.; Kandrot, E. CUDA by Example: An Introduction to General-Purpose GPU Programming; Addison-Wesley Professional: Boston, MA, USA, 2010. [Google Scholar]
- University of Mannheim; University of Tennessee; NERSC/LBNL. Top 500 Supercomputer Sites. Available online: http://www.top500.org (accessed on 7 January 2020).
- AMD Developer Tools Team. CodeXL Quick Start Guide. Available online: https://github.com/GPUOpen-Tools/CodeXL/releases/download/v2.0/CodeXL_Quick_Start_Guide.pdf (accessed on 7 January 2020).
- Intel. Intel SDK for OpenCL Applications. Available online: https://software.intel.com/en-us/opencl-sdk (accessed on 7 January 2020).
- Intel. Intel VTune Amplifier. Available online: https://software.intel.com/en-us/vtune (accessed on 7 January 2020).
- Apple Inc. Metal Programming Guide. Available online: https://developer.apple.com/library/archive/documentation/Miscellaneous/Conceptual/MetalProgrammingGuide/Introduction/Introduction.html (accessed on 7 January 2020).
- Wilson, G.; Aruliah, D.; Brown, C.; Hong, N.; Davis, M.; Guy, R.; Haddock, S.; Huff, K.; Mitchell, I.; Plumbley, M.; et al. Best Practices for Scientific Computing. PLoS Biol. 2014, 12, e1001745. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Prechelt, L. An Empirical Comparison of C, C++, Java, Perl, Python, Rexx, and Tcl for a Search/string-Processing Program; Technical Report; Karlsruhe Institute of Technology: Karlsruhe, Germany, 2000. [Google Scholar]
- Lam, S.; Pitrou, A.; Seibert, S. Numba: A LLVM-based Python JIT Compiler. In Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC, LLVM ’15, Austin, TX, USA, 15 November 2015; pp. 7:1–7:6. [Google Scholar] [CrossRef]
- Behnel, S.; Bradshaw, R.; Seljebotn, D. Cython tutorial. In Proceedings of the 8th Python in Science Conference, Pasadena, CA, USA, 18–23 August 2009; Varoquaux, G., van der Walt, S., Millman, J., Eds.; pp. 4–14. [Google Scholar]
- Kaehler, A.; Bradski, G. Learning OpenCV: Computer Vision in C++ with the OpenCV Library; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Okuta, R.; Unno, Y.; Nishino, D.; Hido, S.; Loomis, C. CuPy: A NumPy-Compatible Library for NVIDIA GPU Calculations. Proceedings of Workshop on Machine Learning Systems (LearningSys) in The Thirty-First Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 19 May 2017. [Google Scholar]
- Kluyver, T.; Ragan-Kelley, B.; Pérez, F.; Granger, B.; Bussonnier, M.; Frederic, J.; Kelley, K.; Hamrick, J.; Grout, J.; Corlay, S.; et al. Jupyter Notebooks—A publishing format for reproducible computational workflows. In Positioning and Power in Academic Publishing: Players, Agents and Agendas; IOS Press BV: Amsterdam, The Netherlands, 2016; pp. 87–90. [Google Scholar] [CrossRef]
- Hunter, J. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Singh, R.; Wood, P.; Gupta, R.; Bagchi, S.; Laguna, I. Snowpack: Efficient Parameter Choice for GPU Kernels via Static Analysis and Statistical Prediction. In Proceedings of the 8th Workshop on Latest Advances in Scalable Algorithms for Large-Scale Systems, Denver, CO, USA, 13 November 2017; ACM: New York, NY, USA, 2017; pp. 8:1–8:8. [Google Scholar]
- Price, J.; McIntosh-Smith, S. Analyzing and Improving Performance Portability of OpenCL Applications via Auto-tuning. In Proceedings of the 5th International Workshop on OpenCL, Toronto, ON, Canada, 16–18 May 2017; ACM: New York, NY, USA, 2017; pp. 14:1–14:4. [Google Scholar]
- Falch, T.; Elster, A. Machine learning-based auto-tuning for enhanced performance portability of OpenCL applications. Concurr. Comput. Pract. Exp. 2017, 29, e4029. [Google Scholar] [CrossRef]
- Brodtkorb, A.; Hagen, T.; Sætra, M. Graphics processing unit (GPU) programming strategies and trends in GPU computing. J. Parallel Distrib. Comput. 2013, 73, 4–13. [Google Scholar] [CrossRef] [Green Version]
- Chertock, A.; Dudzinski, M.; Kurganov, A.; Lukácová-Medvidová, M. Well-balanced schemes for the shallow water equations with Coriolis forces. Numer. Math. 2017. [Google Scholar] [CrossRef]
- Sielecki, A. An Energy-Conserving Difference Scheme for the Storm Surge Equations. Mon. Weather Rev. 1968, 96, 150–156. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| C++ | Python | |||
|---|---|---|---|---|
| CUDA | OpenCL | CUDA | OpenCL | |
| API version | 10.0 | 1.2 / 2.0 | 10.0 | 1.2 |
| Development time | Medium | Medium | Fast | Fast |
| Approximate lines of code | 145 | 130 | 100 | 100 |
| Compilation time | ∼5 s | ∼5 s | ∼5 s | Interactive |
| Kernel launch overhead | 13 s | 318 s | 19 s | 377 s |
| Download overhead | 9 s | 4007 s | 52 s | 8872 s |
| Kernel GPU time | 480 ms | 446 ms | 478 ms | 444 ms |
| Download GPU time | 4.0 ms | 3.9 ms | 4.0 ms | 8.8 ms |
| Wall time | 24.2 s | 22.5 s | 24.1 s | 22.7 s |
| Model | Class | Architecture (Year) | Memory | GFLOPS | Bandwidth | Power Device |
|---|---|---|---|---|---|---|
| Tesla M2090 | Server | Fermi (2011) | 6 GiB | 1331 | 178 GB/s | N.A. |
| Tesla K20 | Server | Kepler (2012) | 6 GiB | 3524 | 208 GB/s | N.A. |
| GeForce GTX780 | Desktop | Kepler (2013) | 3 GiB | 3977 | 288 GB/s | Watt meter |
| Tesla K80 | Server | Kepler (2014) | GiB | GB/s | N.A. | |
| GeForce 840M | Laptop | Maxwell (2014) | 4 GiB | 790 | 16 GB/s | Watt meter |
| Tesla P100 | Server | Pascal (2016) | 12 GiB | 9523 | 549 GB/s | nvidia-smi |
| Tesla V100 | Server | Volta (2017) | 16 GiB | 14,899 | 900 GB/s | nvidia-smi |
| CUDA | OpenCL |
|---|---|
| Function qualifiers | |
| __global__ | __kernel |
| __device__ | N/A |
| Variable qualifiers | |
| __constant__ | __constant |
| __device__ | __global |
| __shared__ | __local |
| Indexing | |
| gridDim | get_num_groups() |
| blockDim | get_local_size() |
| blockIdx | get_group_id() |
| threadIdx | get_local_id() |
| blockIdx∗blockDim+threadIdx | get_global_id() |
| gridDim∗blockDim | get_global_size() |
| Synchronization | |
| __syncthreads() | barrier() |
| __threadfence() | N/A |
| __threadfence_block() | mem_fence() |
| API calls | |
| kernel<<<...>>>() | clEnqueueNDRangeKernel() |
| cudaGetDeviceProperties() | clGetDeviceInfo() |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Holm, H.H.; Brodtkorb, A.R.; Sætra, M.L. GPU Computing with Python: Performance, Energy Efficiency and Usability. Computation 2020, 8, 4. https://doi.org/10.3390/computation8010004
Holm HH, Brodtkorb AR, Sætra ML. GPU Computing with Python: Performance, Energy Efficiency and Usability. Computation. 2020; 8(1):4. https://doi.org/10.3390/computation8010004
Chicago/Turabian StyleHolm, Håvard H., André R. Brodtkorb, and Martin L. Sætra. 2020. "GPU Computing with Python: Performance, Energy Efficiency and Usability" Computation 8, no. 1: 4. https://doi.org/10.3390/computation8010004
APA StyleHolm, H. H., Brodtkorb, A. R., & Sætra, M. L. (2020). GPU Computing with Python: Performance, Energy Efficiency and Usability. Computation, 8(1), 4. https://doi.org/10.3390/computation8010004