1. Introduction
Chemotaxis is the phenomenon of organisms directing their movements upon certain chemical stimulation. Every motile organism exhibits some type of chemotaxis. Mathematically, there are two mainstream mathematical models used to describe this phenomenon: one at the macroscopic population level and the other at the mesoscopic level.
The most famous model in the first category is the Keller–Segel equation, introduced in [
1,
2,
3]. The equation traces the evolution of bacteria density when chemical stimulation is introduced to the system:
where
is the cell density at location
x at time
. In this equation, both the advection term and the diffusion process integrate the external chemical density information, meaning that both the diffusion matrix
and the drift vector
, as functions of
, are determined by the chemoattractant’s density function
. This function
c serves as a meta-parameter determining the
dependence of
.
However, the model is inaccurate in certain regimes. It overlooks the bacteria’s complex reaction to the chemoattractants and is thus macroscopic in nature. This inspires the second category of modeling, where the motion of individual bacteria is accounted for. The associated modeling is thus mesoscopic. When bacterial movements are composed of two states, running in a straight line with a given velocity
v and tumbling from one velocity
v to another
, the according mathematical model is termed the run-and-tumble model. It is described by the mesoscopic chemotaxis equation [
4,
5,
6]:
In the equation,
is the population density of bacteria with velocity
v in some velocity space
at space point
at time
. The tumbling kernel
encodes the probability of bacteria changing from velocity
to
v. The shape of this probability depends on the chemoattractant’s density function
c.
Abbreviating the notation and calling
and
as in [
5], the tumbling term on the right-hand side of Equation (
2) reads
Because bacteria are usually assumed to move with constant speed, conventionally, we have
. Moreover, since the cell doubling time is much longer than the chemotaxis time scale, we remove the birth–death effect from the equation.
Both models above are empirical in nature. The coefficients, such as
D,
and
K, which encode the way in which bacteria respond to the environment, are typically unknown ahead of time. Since the chemoattractant concentration
c depends on space and time, so do
D,
and
K. However, except for very few well-studied bacteria, these quantities are not explicitly known and cannot be measured directly. One thus needs to design experiments and use measurable quantities to infer the information. This constitutes the inverse problem that we study. One such experiment was reported in [
7], where the authors studied phototaxis and used video recording of seaweed motion (
in time) to infer
D and
in (
1).
There are various ways to conduct inverse problems, and, in this paper, we take the viewpoint of Bayesian inference. This is to assume that the coefficients are not uniquely configured in reality but, rather, follow a certain probability distribution. The measurements are taken to infer this probability. In the process of such inference, one nevertheless needs to incorporate the forward model. The two different forward models described above then lead to two distinctive posterior distributions as the inference.
One natural question is to understand the relation between the two resulting posterior distributions. In this article, we answer this question by asymptotic analysis. To be specific, we will show that the two models are asymptotically equivalent in the long-time and large-space regime, and can be uniquely determined by a given K. As such, the associated two inverse problems are asymptotically equivalent too. The equivalence is characterized by the distance (we use both the Kullback–-Leibler divergence and the Hellinger distance) between the two corresponding posterior distributions. We show that this distance vanishes asymptotically as the Knudsen number, a quantity that measures the mean free path between two subsequent tumbles, becomes arbitrarily small.
One goal of this paper is to provide a theoretical foundation for developing an efficient kinetic inverse solver. All inverse solvers involve iterative forward solvers, and thus the computational complexity can be reduced significantly if the forward solver is cheap. While it is costly to compute kinetic equations on the phase space, the Keller–Segel diffusion limit is a good surrogate. Our result suggests that the solution to the Keller–Segel inverse problem is close to the kinetic result and thus qualifies as a ‘good’ initial guess, for the full reconstruction on the kinetic level.
The rest of the paper is organized as follows: in
Section 2, we present the asymptotic relation between the two forward models. This can be seen as an adaption of the results in [
5] to our setting. The analysis serves as the foundation to link the two inverse problems. In
Section 3, we formulate the Bayesian inverse problems corresponding to the scaled chemotaxis equation and the Keller–Segel model as underlying models. The well-posedness and convergence of the two corresponding posterior distributions are shown in
Section 4. The results are summarized and discussed in
Section 5.
We should stress that both the mathematical modeling of chemotaxis and Bayesian inference are active research areas. In formulating our problems, we select the most widely accepted models and methods.
For modeling chemotaxis, the two models (
1)–(
2) are the classical ones, and were derived from the study of a biased random walk [
1,
6]. They assume that the organisms passively depend on the environment. When bacteria actively respond to and change the environment, a parabolic or elliptic equation for
c can be added to describe such feedback to the environment [
2,
3,
8]. The coupled system consisting of Equation (
1) and a parabolic equation for
c, where the chemoattractant is assumed to be produced by the bacteria population, can exhibit blow-up solutions. Therefore, some particular forms of
,
are proposed in order to eliminate the unwanted behavior. These models include volume filling [
9], quorum sensing models [
10] or the flux-limited Keller–Segel system [
11]. On the kinetic level, additional variables were introduced to describe the intracellular responses of the bacteria to the chemoattractant in the signaling pathway [
12,
13,
14,
15]. The asymptotic limit of the newer models sometimes reveals interesting phenomena, such as fractional diffusion [
16]. The asymptotic equivalence of the classical model to the Keller–Segel model was extensively studied, e.g., in [
5,
6,
17,
18]. In particular, the current paper heavily depends on the techniques shown in [
5].
There is also vast literature on inverse problems. For the Bayesian inference perspective in scientific computing, interested readers are referred to monographs [
19,
20] and the references therein. In comparison, linking two or multiple inverse problems in different regimes is relatively rare. In [
21], the authors studied the asymptotic equivalence between the inverse kinetic radiative transport equations and its macroscopic counterpart, the diffusion equation. In [
22], the convergence of Bayesian posterior measures for a parametrized elliptic PDE forward model was shown in a similar fashion.
2. Asymptotic Analysis for Kinetic Chemotaxis Equations and the Keller–Segel Model
The two problems we will be using are chemotaxis kinetic equation and the Keller–Segel equation. We review these two models in this section and study their relation. This serves as a cornerstone for building the connection of the two associated inverse problems.
Throughout the paper, we assume that the chemoattractant density c is one given and fixed function of and is not produced or consumed by the bacteria. While this is an approximation, it is valid in many experiments where one has tight control over the matrix environment. Because c is fixed, we drop the dependence of on c in the notation.
We claim, and will show below, that the two Equations (
1) and (
2) are asymptotically equivalent in the long-time large-space regime. We denote by
the scaling parameter; then, in a parabolic scaling, the chemotaxis equation to be considered has the following form:
Formally, when
, the tumbling term dominates the equation and we expect, in the leading order:
where
can be viewed as the limiting operator as
. This means that the limiting solution is almost in the null space of the limiting tumbling operator. Furthermore, due to the specific form of the tumbling operator, one can show that, under certain conditions, such null space is one-dimensional; compare, e.g., [
5] Lemma 2 and the following derivations. We thus formally write
and denote
. Conventionally, we call
F the local equilibrium. Due to the form of
, this is a function only of
v. Inserting this formula back into (
3) and performing asymptotic expansion up to the second order, and following [
5], we find that
satisfies the Keller–Segel equation:
A rigorous proof of the convergence of a subsequence of
can be found in [
5], Theorem 3, where the authors discussed a nonlinear extension of the present model.
From now on, we confine ourselves to kernels having the form of
Remark 1. Because our aim is to compare the posterior distributions of for the kinetic model (3) and the macroscopic model (4), this choice is reasonable. As shown in [5], higher-order terms in ε would not affect the macroscopic equation. Therefore, they would not be reconstructable by the macroscopic inverse problem. In order to rigorously justify the above intuition on the convergence
and ensure the existence of solutions to Equations (
3) and (
4), we suppose
to be an element of the admissible set
for some preset constants
. Defining
as the volume of
V, it is straightforward to show that for any
,
Remark 2. With assumed to be symmetric and antisymmetric, the local equilibrium F in (7) is explicit and simple. This is, e.g., the case for one typical choice of the tumbling kernel: with antisymmetric ϕ, which represents a special case of the models extensively studied in [5]. For better readability, we assume the symmetry properties of the tumbling kernel stated in (6) throughout the paper. We should mention, however, that it is possible to relax this assumption on the tumbling kernel while maintaining the same macroscopic limit. In particular, if there exists one uniform velocity distribution that is positive, bounded and satisfiesfor all considered in the admissible set, then all statements and arguments provided in this paper still hold true. Note that, by these requirements, assumption (A0) in Chalub et al. [5] is satisfied. Suppose that the initial data are smooth in the sense that
. Then we have the following theorem on convergence which can be viewed as an adaption of the results in [
5].
Theorem 1. Suppose that has the form of (5) with and suppose the initial condition ; then, the solution to the chemotaxis Equation (3) satisfies the following: - (a)
For sufficiently small ε, the solution of Equation (3) exists and is bounded in for . - (b)
The solution converges to in , with ρ satisfying the Keller–Segel Equation (4) with coefficients Here, θ and κ solve the cell problems: where for .
- (c)
The boundedness and the convergence is uniform in .
Sketch of proof.
- (a)
First of all, we have the maximum principle so that
and, following the same arguments as in [
5], we integrate in time for
Noting that
and
for sufficiently small
, we have:
Calling the Grönwall lemma, one obtains a bound on
. Since the only role that
plays is its boundedness by
C, as in (
11), the estimate that we obtain is uniform in
and is independent of
for a sufficiently small
.
- (b)
We show that
is a Cauchy sequence in
. For this purpose, we call
and
the solutions of the chemotaxis Equation (
3) with the scaling being
and
. We also denote the difference
. Subtracting the two equations, we have:
with trivial initial data
. This is an equation with a source term
S. Using the argument as in (a), the
boundedness of the time and spatial derivative
in
S can be shown, meaning that
S is of order
. Running (
11) again with this extra source term, we have
Hence, is a Cauchy sequence, and thus converges to some .
It remains to prove
almost everywhere in
with
satisfying the Keller–Segel Equation (
4) with
D,
, as given in Equations (
8) and (9). This follows by arguments rather similar to those in [
5], and is therefore omitted from here. Since only the boundedness of
is seen in the proof, the convergence is uniform in
.
□
3. Bayesian Inverse Problem Setup
Associated with the two forward models, there are two inverse problems. We describe the inverse problem setup and present them with the Bayesian inference formulation.
In the lab setup, it is assumed that the bacteria plate is large enough so that the boundary plays a negligible role. At the initial time, the bacteria cells are distributed on the plate. One then injects chemoattractants onto the plate through a controlled manner, so to have explicitly given, forcing , and to be functions of or only. The bacteria density at location x at time t is then measured.
Measuring is usually done by taking high-resolution photos of the plate at time
t and counting the bacteria in a small neighborhood of location
x. Another possibility is taking a sample of the bacteria at location
x and measuring the bacteria density of the sample by classical techniques such as optical density OD 600 or flow cytometry, see, e.g., [
23,
24]. This, however, describes an invasive technique and thus allows measurements at only one time
t.
The whole experiment is to take data of the following operator:
if the dynamics of the bacteria are modeled by (
3), and
if the dynamics of the bacteria are modeled by (
4). Noting that
are uniquely determined by
by Equations (
8) and (9), we can equate
with
. Although the more natural macroscopic inverse problem would be to recover the diffusion and drift coefficients
in (
4), we choose to formulate the inverse problem for the tumbling kernel
. This allows us to compare the solution for both the kinetic and the macroscopic inverse problem.
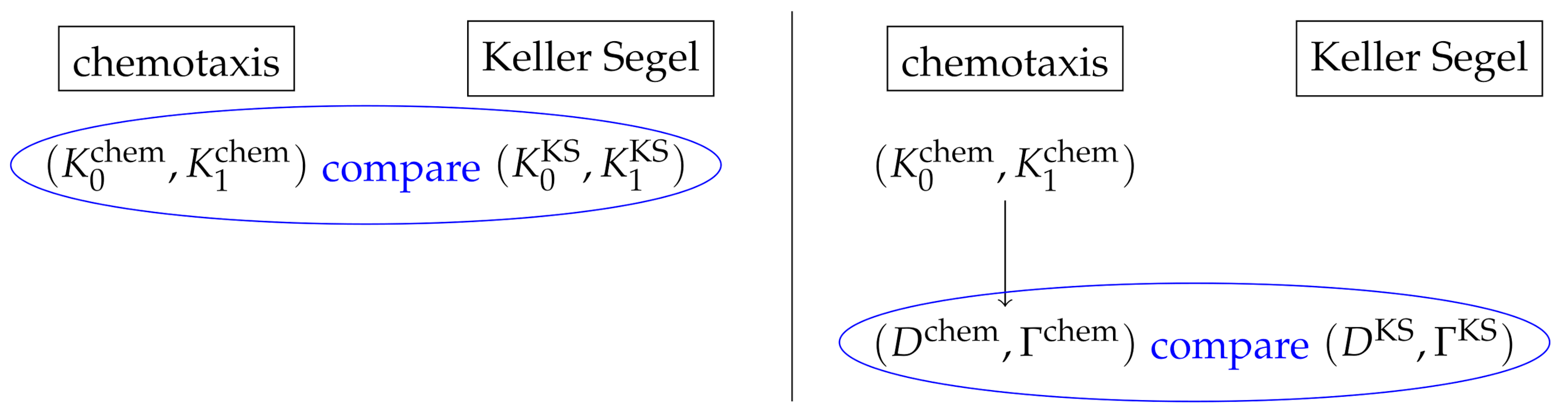
Remark 3. In order to reasonably compare the solutions to the inverse problems, the solutions have to be of the same kind. We choose to reconstruct in both the kinetic and macroscopic inverse problem; see Figure 1 (left). The macroscopic inverse problem is thus also formulated for , which is a function of. Alternatively, one could also reconstruct from both models. In the kinetic setting, this would mean to reconstruct and then transform to values of by Equations (8) and (9); see Figure 1 (right). We do not choose this alternative, because the information on the tumbling kernel is microscopic and thus more detailed. Furthermore, with a fixed , can be uniquely determined, and thus the convergence can be viewed as a mere consequence; see also Remark 5.
Multiple experiments can be conducted using different initial profiles, but the same controlled
is used to ensure that the to-be-reconstructed
is unchanged from experiment to experiment. Denoting by
the indices of the different initial data setups, and denoting by
the indices of the measuring time and location, with
being the measuring time, and
being the spatial test function, then, with (
3) and (
4) being the forward models, we take the measurements, respectively:
where
are the measuring operators with corresponding test functions
. One can consider
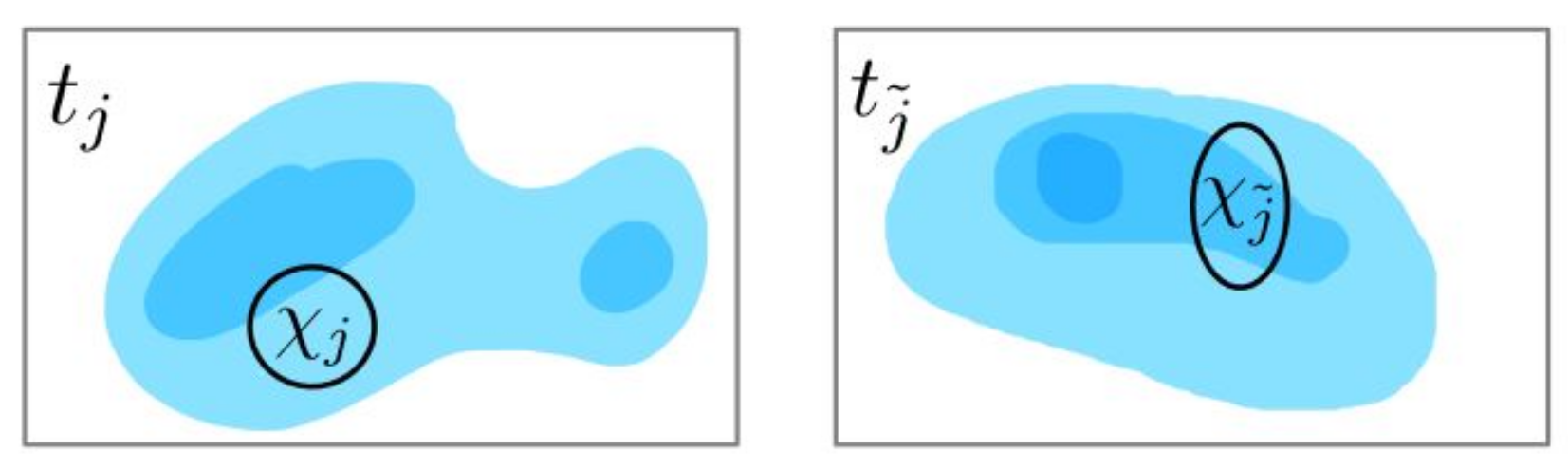
a compactly supported blob function concentrated at a certain location, meaning that all the bacterial cells in a small neighborhood are counted towards this particular measurement; see
Figure 2. This is a reasonable model when counting bacteria in a small neighborhood or taking samples with a pipette.
Throughout the paper, we assume that the initial data and the measuring operators are controlled:
Remark 4. The measurements are formulated in a rather general form in Equations (14) and (15) due to the freedom in the choice of the test function . However, all subsequent derivations also hold true for the specific case of pointwise measurements with and . The measurements would then be and , which would correspond to measuring operators with test functions .
Since measuring error is not avoidable in the measuring process, we assume that it introduces an additive error and collect the data of the form
where the noise
is assumed to be a random variable independently drawn from a Gaussian distribution
of known variance
.
In the Bayesian form, the to-be-reconstructed parameter
is assumed to be a random variable, and the goal is to reconstruct its distribution. Suppose a priori that we know that the parameter is drawn from the distribution
; then, the Bayesian posterior distributions for
should be
using (
3) as the forward model, and
using (
4) as the forward model. In the formula,
is the normalization constant to ensure
and
is the likelihood of observing the data
y from a model with a tumbling kernel or diffusion and drift term derived by
.
In
Section 4, we specify the conditions on
to ensure the well-definedness of
.
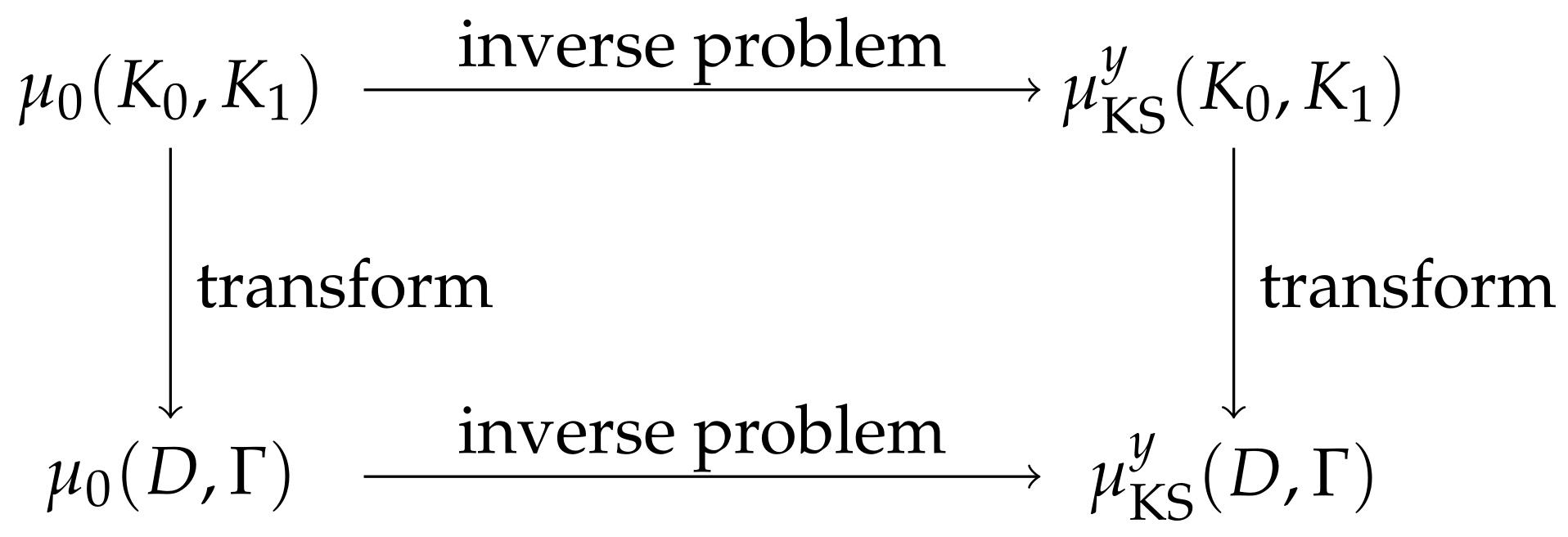
Remark 5. Since the macroscopic model does not explicitly depend on , the distribution of is of interest in the macroscopic description (4). There are two ways to derive it starting with a prior distribution on : The natural way would be to transform the prior distribution to a prior on by Equations (8) and (9) and then consider the inverse problem of reconstructing . This approach is displayed by the lower path in Figure 3. If, however, the posterior distribution is calculated ahead of the transformation (as in our case), one could instead transform this posterior distribution directly to a distribution in the space following the upper path in Figure 3. Naturally, the question arises of whether the two ways lead to the same posterior distribution. It turns out that they do. Considering the second possibility, we see that the likelihood and thus the normalization constant only depend on , because we are in the macroscopic model. Hence, only the prior distribution is transformed, as is the case for the first possibility. 4. Convergence of Posterior Distributions
One natural question arises. The two different forward models provide two different posterior distribution functions of . Which distribution is the correct one, or, rather, what is the relation between the two posterior distributions?
As discussed in
Section 2, the two forward models are asymptotically equivalent in the long-time large-space regime, so it is expected that the two posterior distributions converge as well. This suggests that the amount of information given by the measurements is equally presented by the two forward models. However, this convergence result is not as straightforward as it may seem. One issue comes from the control of initial data and the measurement operator. For each initial datum, the solution converges in
; we now have a list of initial data, and the solutions are tested on a set of measuring operators, so we need a uniform convergence when tested on the dual space. Furthermore, to show the convergence of two distribution functions, a certain metric needs to be given on the probability function space. The issue of how the convergence for one set of fixed
translates to the convergence on the entire admissible set also needs to be addressed.
By choosing the admissible set (
6), we formulated an assumption on the tumbling kernels
ahead of time. With this a priori knowledge, we showed the uniform boundedness and convergence of the solutions
to the chemotaxis Equation (
3) over the function set
in Theorem 1. This will play a crucial role in the convergence proof for the inverse problem. From here on, we assume that the prior distribution
is supported on
.
Before we show the convergence, as an a priori estimate, we first show the well-posedness of the Bayesian posterior distributions in Lemma 1, following [
19,
20].
Lemma 1. If the initial conditions and the test functions satisfy (16), then the following properties of the posterior distributions hold true: - (a)
The measurements and are uniformly bounded on (and uniformly in ε).
- (b)
For small enough ε, the measurements and are Lipschitz continuous with respect to the tumbling kernels under the norm on .
- (c)
The posterior distributions are well-posed and absolutely continuous with regard to each other.
Proof. - (a)
For every
, we have:
where we use the density conservation:
for all
t. Analogously, we have
. Note that this bound is independent of
.
- (b)
For the chemotaxis model, we have for
where
and
are solutions to the initial value problem (
3) with initial condition
and tumbling kernels
and
, respectively. Their difference
satisfies the scaled difference equation:
Here,
denotes the tumbling operator with kernel
. Integration in
s at
shows
This yields
since one has
for small enough
and
is bounded in
uniformly on
by Theorem 1 (a). Additionally,
can be chosen to be independent of
k by inserting the uniform boundedness of
in (
16) into Equation (
12). The Grönwall lemma thus gives
with some coefficient
L depending on
T,
C and
. Inserting this into Equation (
19) results in the desired Lipschitz continuity.
We similarly study the Lipschitz continuity of the Keller–Segel measurements
. The proof strategy is almost the same. With some computational effort, one can see:
where
are the drift and diffusion terms derived by the collision operators defined by
and
, respectively, by Equations (
8) and (9). The constant
c monotonously depends on the
norms of
and
, which are bounded uniformly on
. By the linear relation between
D and
and
and
, this directly translates to
with constant
depending only on
V. Finally, the Lax–Milgram theorem shows the continuous dependence of
where
only depends on
.
- (c)
By (a), the likelihoods are bounded away from zero and bounded uniformly on (and in ). Thus, the normalization constants Z are too. Part (b) guarantees the measurability of the likelihoods. In total, this shows that the posterior distributions are well-defined and continuous with respect to each other. Since the likelihoods are continuous in y, the well-posedness of the posterior distributions is given.
□
We are now ready to show the convergence of the two posterior measures. There are two quantities that we use to measure the difference between two distributions:
Kullback–Leibler divergence
The two metrics both evaluate the distance between the two probability measures
and
, which are either absolutely continuous with respect to each other or with respect to a third probability measure
. Both are frequently used for comparing two distribution functions, e.g., in machine learning [
25,
26,
27,
28,
29,
30] or inverse problem settings [
21,
22]. Even though the Kullback–Leibler divergence lacks the symmetry and triangle-inequality properties of a metric, it has gained popularity due to its close connection to several information concepts, such as the Shannon entropy or the Fisher information metric [
31]. Conversely, the Hellinger metric is a true metric. Although it does not have a demonstrative interpretation as does the Kullback–Leibler divergence, its strength lies in the fact that convergence in the Hellinger metric implies convergence of the expectation of any polynomially bounded function with respect to either of the posterior distributions, as explained in [
19]. In particular, the mean, covariance and further moments of the distributions converge.
Before comparing the posterior measures, we need to have a look at the convergence of the measurements .
Lemma 2. Assuming that the initial and testing functions satisfy (16), the chemotaxis measurements converge to the Keller–Segel measurements uniformly on as . Proof. Theorem 1 shows the convergence of
to
in
uniformly on
. As a consequence, we have the convergence of the measurements:
where we use the form
. By the uniform convergence of
to
, this holds uniformly on
. Since the initial data and measuring test functions satisfy (
16), we have the uniform convergence over
as well. □
We can now prove the following theorem on the asymptotic equivalence of the two posterior measures describing the distribution of the tumbling kernels
if the dynamics of the bacteria are modeled by the kinetic (
3) or macroscopic Equation (
4).
Theorem 2. Let the measurement of the macroscopic bacteria density be of the form (14) and (15) for an underlying kinetic chemotaxis model or a Keller–Segel model, respectively. The measuring test functions and initial data are assumed to satisfy (16). Given a prior distribution on and an additive centered Gaussian noise in the data, the posterior distributions for the tumbling kernel derived from the kinetic chemotaxis equation and the macroscopic Keller–Segel equation as underlying models are asymptotically equivalent in the Kullback–Leibler divergence Proof of Theorem 2.
With the above lemmas, one can proceed as in the proof in [
21]. The integrand of the Kullback–Leibler divergence is by the definition of the normalization constants of order
Thus, we estimate
for the Lipschitz constant
of
and
The first factor is bounded uniformly on
and in
by Lemma 1 (a) and Lemma 2 shows that the second factor converges to 0 uniformly on
. It follows that
□
The boundedness of the the Hellinger metric by the Kullback–Leibler divergence
as shown in Lemma 2.4 in [
32] together with Theorem 2 yields the asymptotic equivalence of the posterior distributions also in the Hellinger metric.
Corollary 1. In the framework of Theorem 2, one has 


{kind=link}
{kind=link}
{kind=link}


