Blocked Presentation Leads Participants to Overutilize Domain Familiarity as a Cue for Judgments of Learning (JOLs)


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. The Monitoring of Learning
1.1.1. Measures of Metacognitive Accuracy
1.1.2. The Overutilization of Domain Familiarity as a Cue for JOLs
1.1.3. Relative Accuracy as a Function of Domain Familiarity
1.2. The Present Studies
2. Study 1
2.1. Method
2.1.1. Participants
2.1.2. Materials
2.1.3. Design
2.1.4. Procedure
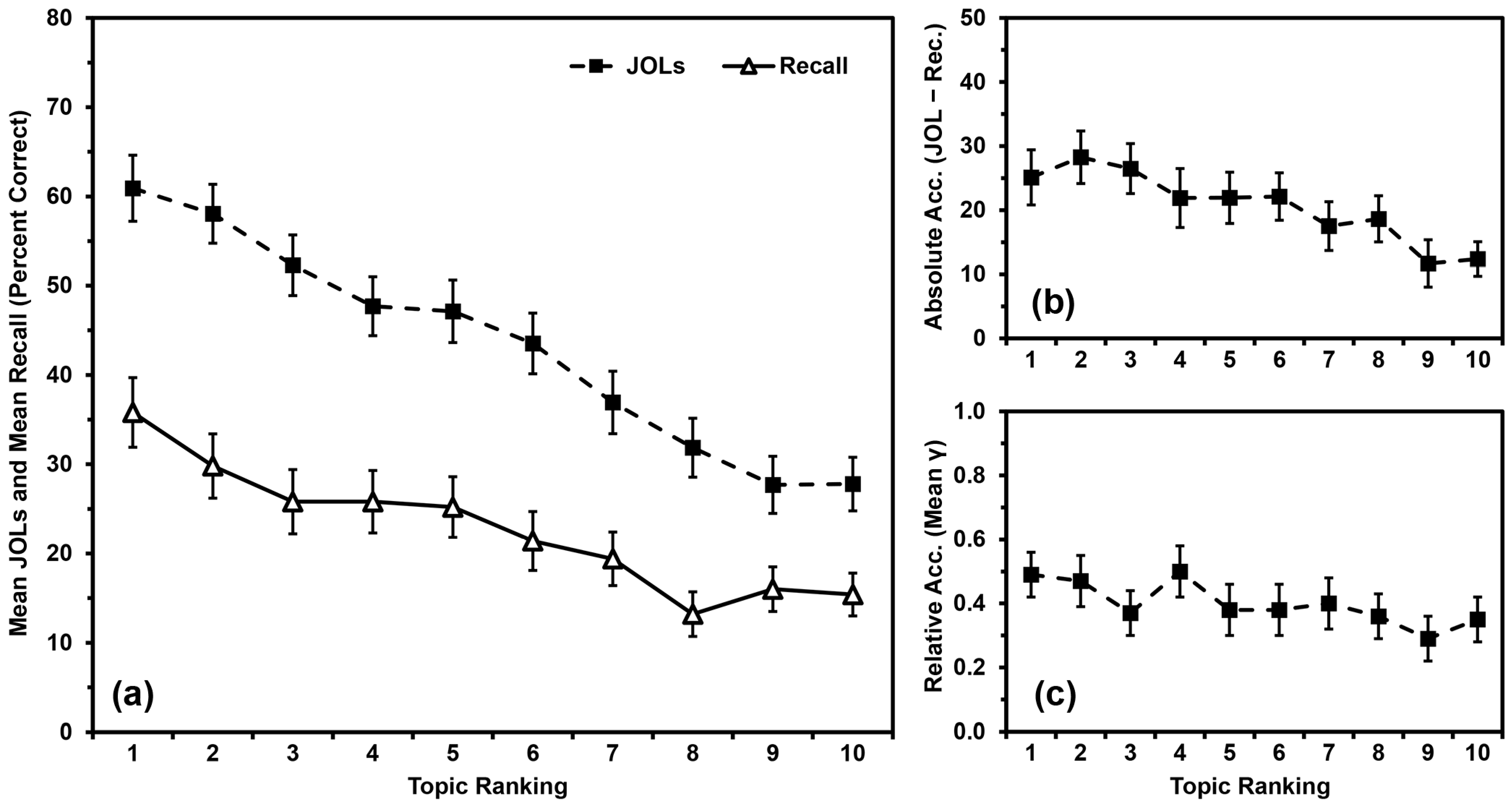
2.2. Results
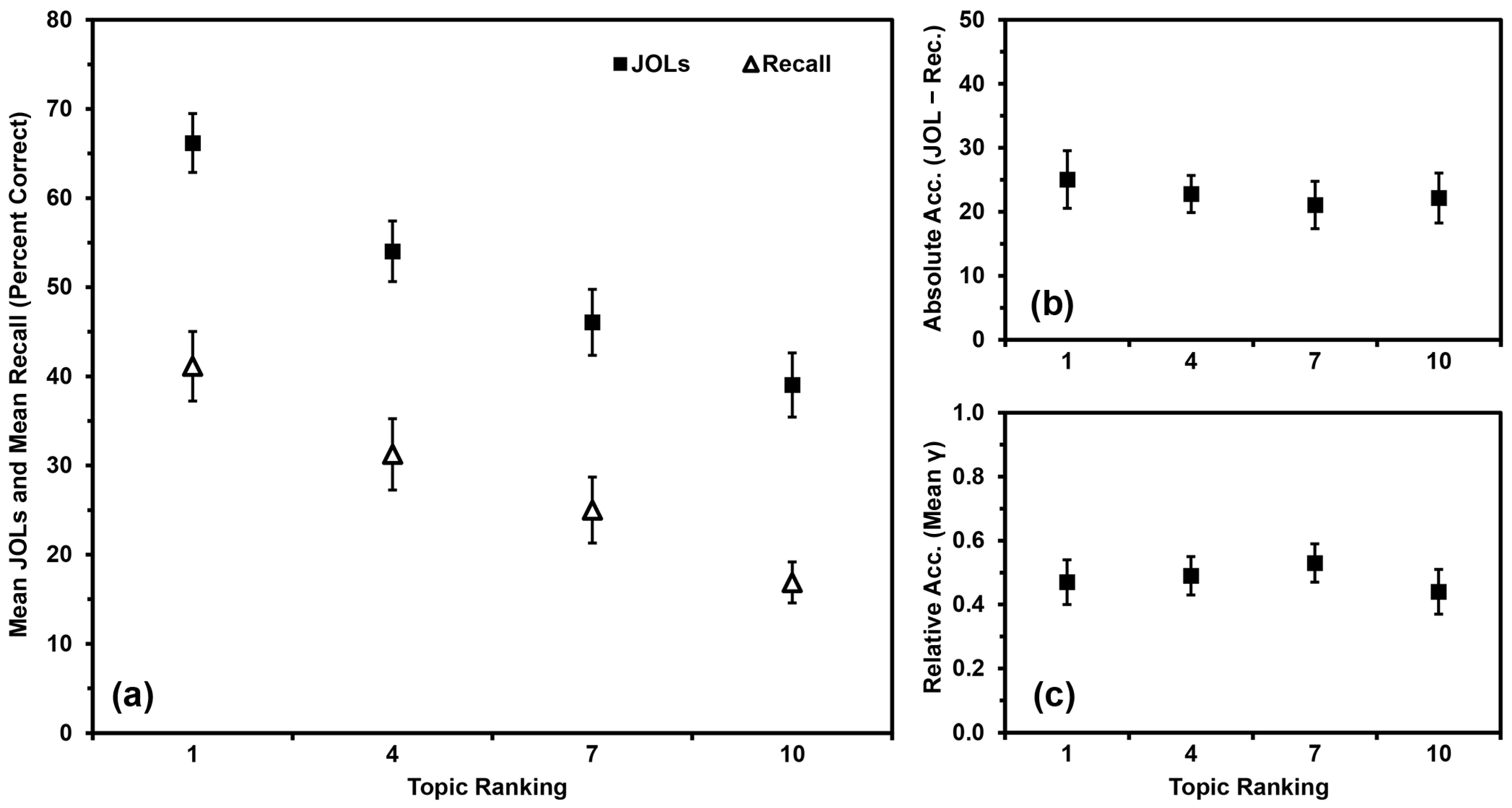
2.2.1. Recall Performance
2.2.2. JOL Magnitude
2.2.3. Absolute Accuracy
2.2.4. Relative Accuracy
2.3. Discussion
3. Study 2
3.1. Method and Materials
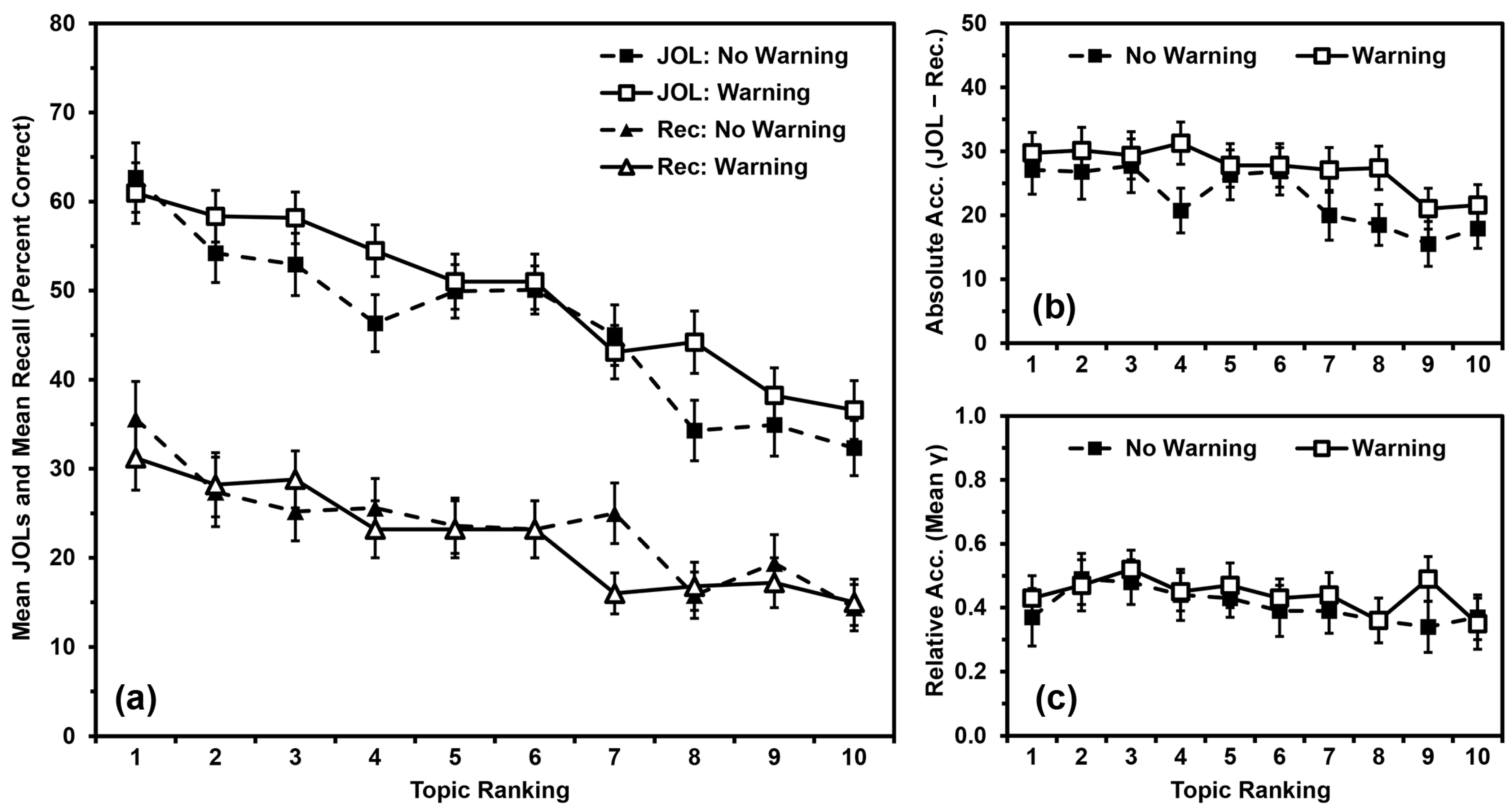
3.2. Results
3.2.1. Recall Performance
3.2.2. JOL Magnitude
3.2.3. Absolute Accuracy
3.2.4. Relative Accuracy
3.3. Discussion
4. Study 3
4.1. Method and Materials
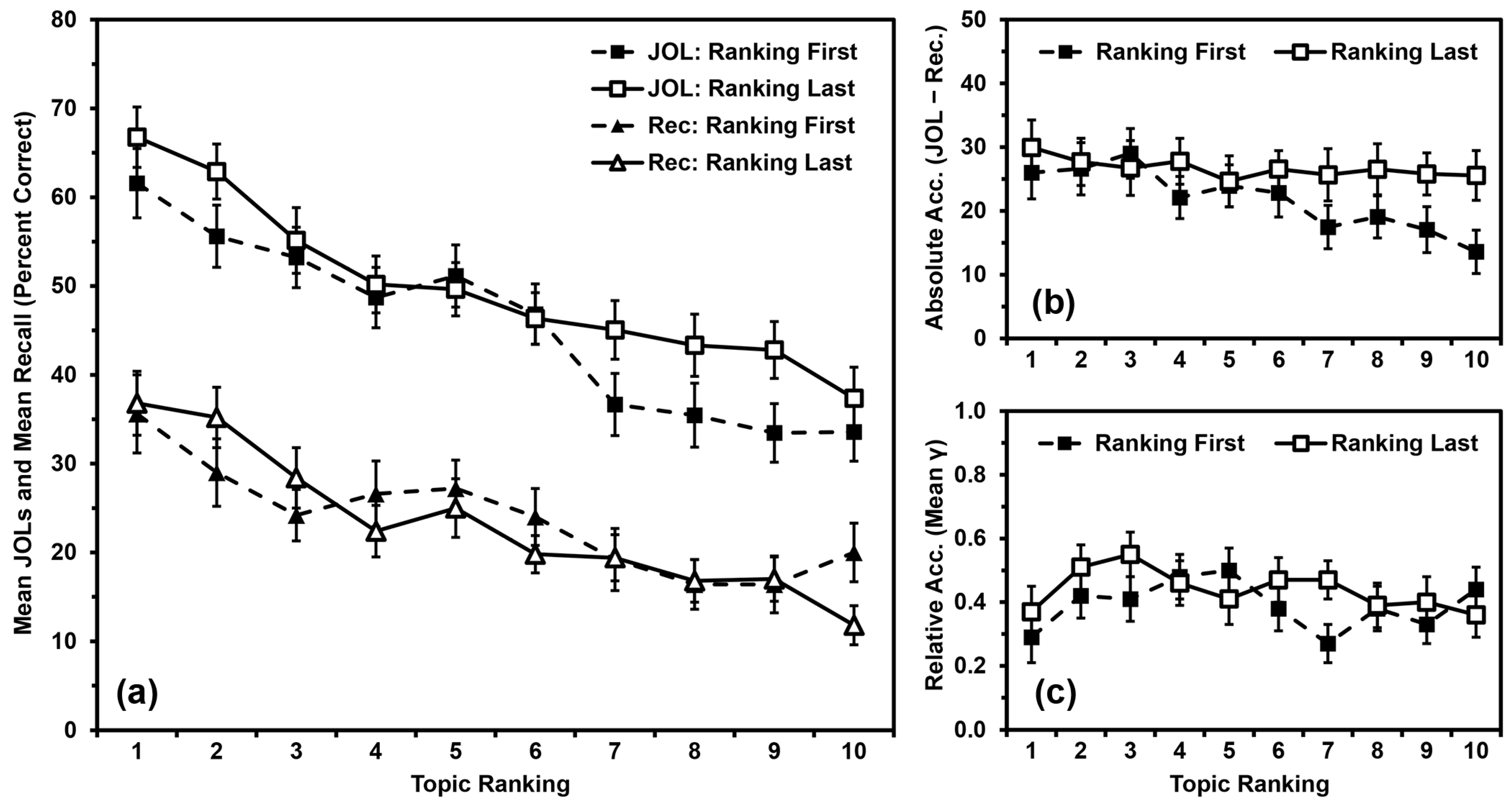
4.2. Results
4.2.1. Recall Performance
4.2.2. JOL Magnitude
4.2.3. Absolute Accuracy
4.2.4. Relative Accuracy
4.3. Discussion
5. Study 4
5.1. Method and Materials
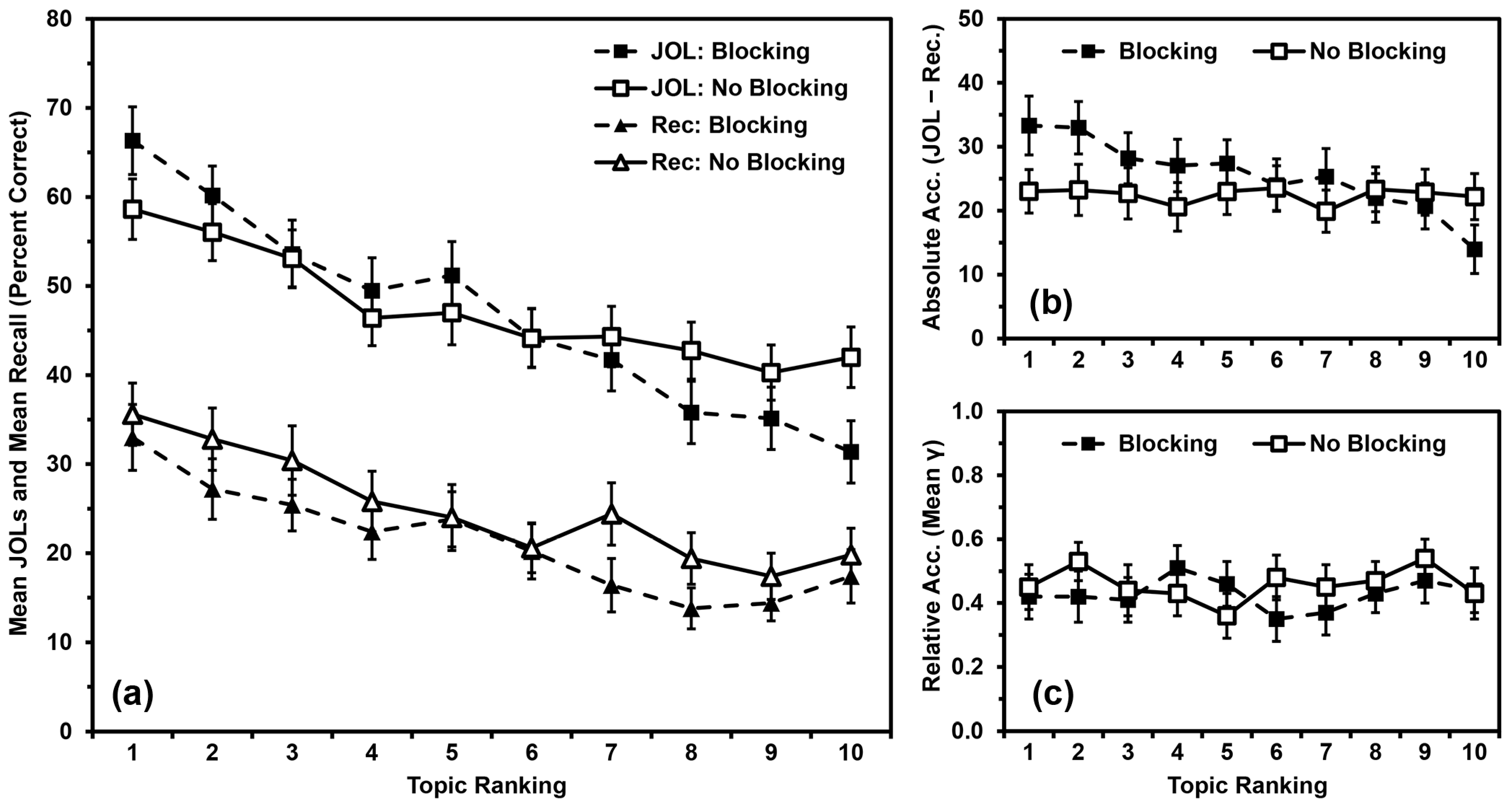
5.2. Results
5.2.1. Recall Performance
5.2.2. JOL Magnitude
5.2.3. Absolute Accuracy
5.2.4. Relative Accuracy
5.3. Discussion
6. General Discussion
6.1. Findings and Conclusions
6.1.1. Domain Familiarity as a Cue for JOLs
6.1.2. Domain Familiarity and Relative Accuracy
6.2. Alternative Accounts
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bjork, Robert A., John Dunlosky, and Nate Kornell. 2013. Self-regulated learning: Beliefs, techniques, and illusions. Annual Review of Psychology 64: 417–44. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Boscolo, Pietro, and Lucia Mason. 2003. Topic knowledge, text coherence, and interest: How they interact in learning from instructional texts. The Journal of Experimental Education 71: 126–48. [Google Scholar] [CrossRef]
- Briñol, Pablo, Richard E. Petty, and Zakary L. Tormala. 2006. The malleable meaning of subjective ease. Psychological Science 17: 200–6. [Google Scholar] [CrossRef] [PubMed]
- Burson, Katherine A., Richard P. Larrick, and Joshua Klayman. 2006. Skilled or unskilled, but still unaware of it: How perceptions of difficulty drive miscalibration in relative comparisons. Journal of Personality and Social Psychology 90: 60–77. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carpenter, Shana K., Cynthia L. Haynes, Daniel Corral, and Kam Leung Yeung. 2018. Hypercorrection of high-confidence errors in the classroom. Memory 26: 1379–84. [Google Scholar] [CrossRef] [PubMed]
- Carvalho, Paul F., and Robert L. Goldstone. 2015. What you learn is more than what you see: What can sequencing effects tell us about inductive category learning? Frontiers in Psychology 6: 505. [Google Scholar] [CrossRef] [Green Version]
- Dunlosky, John, and Janet Metcalfe. 2008. Metacognition. Thousand Oaks: Sage Publications. [Google Scholar]
- Dunlosky, John, and Katherine A. Rawson. 2012. Overconfidence produces underachievement: Inaccurate self evaluations undermine students’ learning and retention. Learning and Instruction 22: 271–80. [Google Scholar] [CrossRef]
- Dunlosky, John, and Sarah K. Tauber. 2014. Understanding people’s metacognitive judgments: An isomechanism framework and its implications for applied and theoretical research. In Handbook of Applied Memory. London: SAGE Publications Ltd., pp. 444–64. [Google Scholar]
- Dunlosky, John, Michael J. Serra, and Julie M. Baker. 2007. Metamemory Applied. In Handbook of Applied Cognition. West Sussex: Wiley, vol. 2, pp. 137–61. [Google Scholar]
- Dunlosky, John, Katherine A. Rawson, Elizabeth J. Marsh, Mitchell J. Nathan, and Daniel T. Willingham. 2013. Improving students’ learning with effective learning techniques: Promising directions from cognitive and educational psychology. Psychological Science in the Public Interest 14: 4–58. [Google Scholar] [CrossRef] [Green Version]
- Dunning, David. 2011. The Dunning–Kruger effect: On being ignorant of one’s own ignorance. In Advances in Experimental Social Psychology. Cambridge: Academic Press, vol. 44, pp. 247–96. [Google Scholar]
- Ehrlinger, Joyce, Kerri Johnson, Matthew Banner, David Dunning, and Justin Kruger. 2008. Why the unskilled are unaware: Further explorations of (absent) self-insight among the incompetent. Organizational Behavior and Human Decision Processes 105: 98–121. [Google Scholar] [CrossRef]
- England, Benjamin D., Francesca R. Ortegren, and Michael J. Serra. 2017. Framing affects scale usage for judgments of learning, not confidence in memory. Journal of Experimental Psychology: Learning, Memory, and Cognition 43: 1898–908. [Google Scholar] [CrossRef]
- Ericsson, K. Anders, and Walter Kintsch. 1995. Long-term working memory. Psychological Review 102: 211–45. [Google Scholar] [CrossRef]
- Faul, Franz, Edgar Erdfelder, Albert-Georg Lang, and Axel Buchner. 2007. G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods 39: 175–91. [Google Scholar] [CrossRef] [PubMed]
- Feltovich, Paul J., Michael J. Prietula, and K. Anders Ericsson. 2006. Studies of expertise from psychological perspectives. In Cambridge Handbook of Expertise and Expert Performance. Edited by K. Anders Ericsson, Neil Charness, Paul J. Feltovich and Robert R. Hoffman. Cambridge: Cambridge University Press, pp. 39–68. [Google Scholar]
- Finn, Bridgid. 2008. Framing effects on metacognitive monitoring and control. Memory and Cognition 36: 813–21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frank, David J., and Beatrice G. Kuhlmann. 2017. More than just beliefs: Experience and beliefs jointly contribute to volume effects on metacognitive judgments. Journal of Experimental Psychology: Learning, Memory, and Cognition 43: 680–93. [Google Scholar] [CrossRef] [PubMed]
- Gignac, Gilles E., and Marcin Zajenkowski. 2020. The Dunning-Kruger effect is (mostly) a statistical artefact: Valid approaches to testing the hypothesis with individual differences data. Intelligence 80: 101449. [Google Scholar] [CrossRef]
- Glenberg, Arthur M., and William Epstein. 1987. Inexpert calibration of comprehension. Memory and Cognition 15: 84–93. [Google Scholar] [CrossRef]
- Glenberg, Arthur M., Thomas Sanocki, William Epstein, and Craig Morris. 1987. Enhancing calibration of comprehension. Journal of Experimental Psychology: General 116: 119–36. [Google Scholar] [CrossRef]
- Griffin, Thomas D., Benjamin D. Jee, and Jennifer Wiley. 2009. The effects of domain knowledge on metacomprehension accuracy. Memory & Cognition 37: 1001–13. [Google Scholar] [CrossRef]
- Grimes, Paul W. 2002. The overconfident principles of economics student: An examination of a metacognitive skill. Journal of Economic Education 33: 15–30. [Google Scholar] [CrossRef]
- Hanczakowski, Maciej, Katarzyna Zawadzka, Tomasz Pasek, and Philip A. Higham. 2013. Calibration of metacognitive judgments: Insights from the underconfidence-with-practice effect. Journal of Memory and Language 69: 429–44. [Google Scholar] [CrossRef]
- Higham, Philip A., Katarzyna Zawadzka, and Maciej Hanczakowski. 2016. Internal mapping and its impact on measures of absolute and relative metacognitive accuracy. In Oxford Handbook of Metamemory. Edited by J. Dunlosky and S. K. Tauber. New York: Oxford University Press, pp. 39–62. [Google Scholar]
- Hu, Xiao, Tongtong Li, Jun Zheng, Ningxin Su, Zhaomin Liu, and Liang Luo. 2015. How much do metamemory beliefs contribute to the font-size effect in judgments of learning? PLoS ONE 10: e0142351. [Google Scholar] [CrossRef] [PubMed]
- Koriat, Asher. 1997. Monitoring one’s own knowledge during study: A cue-utilization approach to judgments of learning. Journal of Experimental Psychology: General 126: 349–70. [Google Scholar] [CrossRef]
- Koriat, Asher, and Rakefet Ackerman. 2010. Metacognition and mindreading: Judgments of learning for self and other during self-paced study. Consciousness and Cognition 19: 251–64. [Google Scholar] [CrossRef] [PubMed]
- Koriat, Asher, and Robert A. Bjork. 2006. Mending metacognitive illusions: A comparison of mnemonic-based and theory-based procedures. Journal of Experimental Psychology: Learning, Memory, and Cognition 32: 1133–45. [Google Scholar] [CrossRef] [PubMed]
- Koriat, Asher, Ravit Nussinson, Herbert Bless, and Nira Shaked. 2008. Information-based and experience-based metacognitive judgments: Evidence from subjective confidence. In Handbook of Metamemory and Memory. New York: Taylor & Francis, pp. 117–35. [Google Scholar]
- Koriat, Asher, Rakefet Ackerman, Kathrin Lockl, and Wolfgang Schneider. 2009. The easily learned, easily remembered heuristic in children. Cognitive Development 24: 169–82. [Google Scholar] [CrossRef]
- Kornell, Nate, and Robert A. Bjork. 2008a. Learning concepts and categories: Is spacing the “enemy of induction”? Psychological Science 19: 585–92. [Google Scholar] [CrossRef]
- Kornell, Nate, and Robert A. Bjork. 2008b. Optimising self-regulated study: The benefits—And costs—Of dropping flashcards. Memory 16: 125–36. [Google Scholar] [CrossRef]
- Kornell, Nate, and Janet Metcalfe. 2006. Study efficacy and the region of proximal learning framework. Journal of Experimental Psychology: Learning, Memory, and Cognition 32: 609–22. [Google Scholar] [CrossRef] [Green Version]
- Kornell, Nate, Alan D. Castel, Teal S. Eich, and Robert A. Bjork. 2010. Spacing as the friend of both memory and induction in young and older adults. Psychology and Aging 25: 498–503. [Google Scholar] [CrossRef] [Green Version]
- Krueger, Joachim, and Ross A. Mueller. 2002. Unskilled, unaware, or both? The better-than-average heuristic and statistical regression predict errors in estimates of own performance. Journal of Personality and Social Psychology 82: 180–88. [Google Scholar] [CrossRef]
- Kruger, Justin, and David Dunning. 1999. Unskilled and unaware of it: How difficulties in recognizing one’s own incompetence lead to inflated self-assessments. Journal of Personality and Social Psychology 77: 1121–34. [Google Scholar] [CrossRef] [PubMed]
- Kruger, Justin, and David Dunning. 2002. Unskilled and unaware—But why? A reply to Krueger and Mueller. Journal of Personality and Social Psychology 82: 189–92. [Google Scholar] [CrossRef] [PubMed]
- Lichtenstein, Sarah, Baruch Fischhoff, and Lawrence D. Phillips. 1982. Calibration of subjective probabilities: The state of the art up to 1980. In Judgment Under Uncertainty: Heuristics and Biases. Edited by Daniel Kahneman, Paul Slovjc and Amos Tversky. New York: Cambridge University Press, pp. 306–34. [Google Scholar]
- Magreehan, Debbie A., Michael J. Serra, Neil H. Schwartz, and Susanne Narciss. 2016. Further boundary conditions for the effects of perceptual disfluency on judgments of learning. Metacognition and Learning 11: 35–56. [Google Scholar] [CrossRef]
- Maki, Ruth H. 1998. Test predictions over text material. In Metacognition in Educational Theory and Practice. Edited by Douglas J. Hacker, John Dunlosky and Arthur C. Graesser. Mahwah: Erlbaum, pp. 117–44. [Google Scholar]
- Mazor, Matan, and Stephen M. Fleming. 2021. The Dunning-Kruger effect revisited. Nature Human Behaviour 5: 677–78. [Google Scholar] [CrossRef] [PubMed]
- McNamara, Danielle S., Eileen Kintsch, Nancy Butler Songer, and Walter Kintsch. 1996. Are good texts always better? Interactions of text coherence, background knowledge, and levels of understanding in learning from text. Cognition and Instruction 14: 1–43. [Google Scholar] [CrossRef]
- Metcalfe, Janet. 2002. Is study time allocated selectively to a region of proximal learning? Journal of Experimental Psychology: General 131: 349–63. [Google Scholar] [CrossRef]
- Metcalfe, Janet, and Bridgid Finn. 2008. Evidence that judgments of learning are causally related to study choice. Psychonomic Bulletin & Review 15: 174–79. [Google Scholar] [CrossRef] [Green Version]
- Miller, Lisa M. Soederberg, Elizabeth A. L. Stine-Morrow, Heather L. Kirkorian, and Michelle L. Conroy. 2004. Adult age differences in knowledge-driven reading. Journal of Educational Psychology 96: 811–21. [Google Scholar] [CrossRef]
- Mueller, Michael L., and John Dunlosky. 2017. How beliefs can impact judgments of learning: Evaluating analytic processing theory with beliefs about fluency. Journal of Memory and Language 93: 245–58. [Google Scholar] [CrossRef]
- Mueller, Michael L., Sarah K. Tauber, and John Dunlosky. 2013. Contributions of beliefs and processing fluency to the effect of relatedness on judgments of learning. Psychonomic Bulletin and Review 20: 378–84. [Google Scholar] [CrossRef]
- Mueller, Michael L., John Dunlosky, Sarah K. Tauber, and Matthew G. Rhodes. 2014. The font-size effect on judgments of learning: Does it exemplify fluency effects or reflect people’s beliefs about memory? Journal of Memory and Language 70: 1–12. [Google Scholar] [CrossRef]
- Rhodes, Matthew G., and Alan D. Castel. 2008. Memory predictions are influenced by perceptual information: Evidence for metacognitive illusions. Journal of Experimental Psychology: General 137: 615–25. [Google Scholar] [CrossRef] [Green Version]
- Sanocki, Thomas. 1987. Visual knowledge underlying letter perception: Font-specific, schematic tuning. Journal of Experimental Psychology: Human Perception and Performance 13: 267–78. [Google Scholar] [CrossRef] [PubMed]
- Serra, Michael J., and Robert Ariel. 2014. People use the memory for past-test heuristic as an explicit cue for judgments of learning. Memory and Cognition 42: 1260–72. [Google Scholar] [CrossRef]
- Serra, Michael J., and Kenneth G. DeMarree. 2016. Unskilled and unaware in the classroom: College students’ desired grades predict their biased grade predictions. Memory & Cognition 44: 1127–37. [Google Scholar] [CrossRef] [Green Version]
- Serra, Michael J., and John Dunlosky. 2010. Metacomprehension judgements reflect the belief that diagrams improve learning from text. Memory 18: 698–711. [Google Scholar] [CrossRef]
- Serra, Michael J., and Debbie A. Magreehan. 2016. Instructor fluency correlates with students’ ratings of their learning and their instructor in an actual course. Creative Education 7: 1154–65. [Google Scholar] [CrossRef] [Green Version]
- Serra, Michael J., and Debbie A. McNeely. 2020. The most fluent instructors might choreograph for Beyoncé or secretly be Batman: Commentary on Carpenter, Witherby, and Tauber. Journal of Applied Research in Memory and Cognition 9: 175–80. [Google Scholar] [CrossRef]
- Serra, Michael J., and Janet Metcalfe. 2009. Effective implementation of metacognition. In Handbook of Metacognition in Education. Edited by Douglas J. Hacker, John Dunlosky and Arthur C. Graesser. London: Routledge, pp. 278–98. [Google Scholar]
- Shanks, Lindzi L., and Michael J. Serra. 2014. Domain familiarity as a cue for judgments of learning. Psychonomic Bulletin & Review 21: 445–53. [Google Scholar] [CrossRef]
- Stinebrickner, Ralph, and Todd R. Stinebrickner. 2014. A major in science? initial beliefs and final outcomes for college major and dropout. Review of Economic Studies 81: 426–72. [Google Scholar] [CrossRef]
- Su, Ningxin, Tongtong Li, Jun Zheng, Xiao Hu, Tian Fan, and Liang Luo. 2018. How font size affects judgments of learning: Simultaneous mediating effect of item-specific beliefs about fluency and moderating effect of beliefs about font size and memory. PLoS ONE 13: e0200888. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Susser, Jonathan A., Neil W. Mulligan, and Miri Besken. 2013. The effects of list composition and perceptual fluency on judgments of learning (JOLs). Memory and Cognition 41: 1000–11. [Google Scholar] [CrossRef] [PubMed]
- Toth, Jeffrey P., Karen A. Daniels, and Lisa A. Solinger. 2011. What you know can hurt you: Effects of age and prior knowledge on the accuracy of judgments of learning. Psychology and Aging 26: 919–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wahlheim, Christopher. N., John Dunlosky, and Larry L. Jacoby. 2011. Spacing enhances the learning of natural concepts: An investigation of mechanisms, metacognition, and aging. Memory & Cognition 39: 750–63. [Google Scholar] [CrossRef] [Green Version]
- Wiley, Jennifer. 2005. A fair and balanced look at the news: What affects memory for controversial arguments? Journal of Memory and Language 53: 95–109. [Google Scholar] [CrossRef]
- Witherby, Amber E., and Shana K. Carpenter. 2022. The rich-get-richer effect: Prior knowledge predicts new learning of domain-relevant information. Journal of Experimental Psychology: Learning, Memory, and Cognition 48: 483–98. [Google Scholar] [CrossRef]
- Witherby, Amber E., Shana K. Carpenter, and Andrew M. Smith. 2023. Exploring the relationship between prior knowledge and metacognitive monitoring accuracy. Metacognition and Learning, 1–31. [Google Scholar] [CrossRef]
- Yan, Veronica X., Elizabeth Ligon Bjork, and Robert A. Bjork. 2016. On the difficulty of mending metacognitive illusions: A priori theories, fluency effects, and misattributions of the interleaving benefit. Journal of Experimental Psychology: General 145: 918–33. [Google Scholar] [CrossRef] [Green Version]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Serra, M.J.; Shanks, L.L. Blocked Presentation Leads Participants to Overutilize Domain Familiarity as a Cue for Judgments of Learning (JOLs). J. Intell. 2023, 11, 142. https://doi.org/10.3390/jintelligence11070142
Serra MJ, Shanks LL. Blocked Presentation Leads Participants to Overutilize Domain Familiarity as a Cue for Judgments of Learning (JOLs). Journal of Intelligence. 2023; 11(7):142. https://doi.org/10.3390/jintelligence11070142
Chicago/Turabian StyleSerra, Michael J., and Lindzi L. Shanks. 2023. "Blocked Presentation Leads Participants to Overutilize Domain Familiarity as a Cue for Judgments of Learning (JOLs)" Journal of Intelligence 11, no. 7: 142. https://doi.org/10.3390/jintelligence11070142
APA StyleSerra, M. J., & Shanks, L. L. (2023). Blocked Presentation Leads Participants to Overutilize Domain Familiarity as a Cue for Judgments of Learning (JOLs). Journal of Intelligence, 11(7), 142. https://doi.org/10.3390/jintelligence11070142