
Artificial Intelligence to Get Insights of Multi-Drug Resistance Risk Factors during the First 48 Hours from ICU Admission

 ,
,  and
and 
Abstract
:1. Introduction
2. Feature Selection Using Bootstrap
2.1. Test of Proportions
2.2. Test of Medians
2.3. Mutual Information
2.4. Confidence Interval
3. Machine Learning Methods
3.1. Evaluation of the Generalization Capability
3.2. Learning with Imbalanced Classes
3.3. Logistic Regression
3.4. Decision Trees
3.5. XGBoost
3.6. Artificial Neural Networks
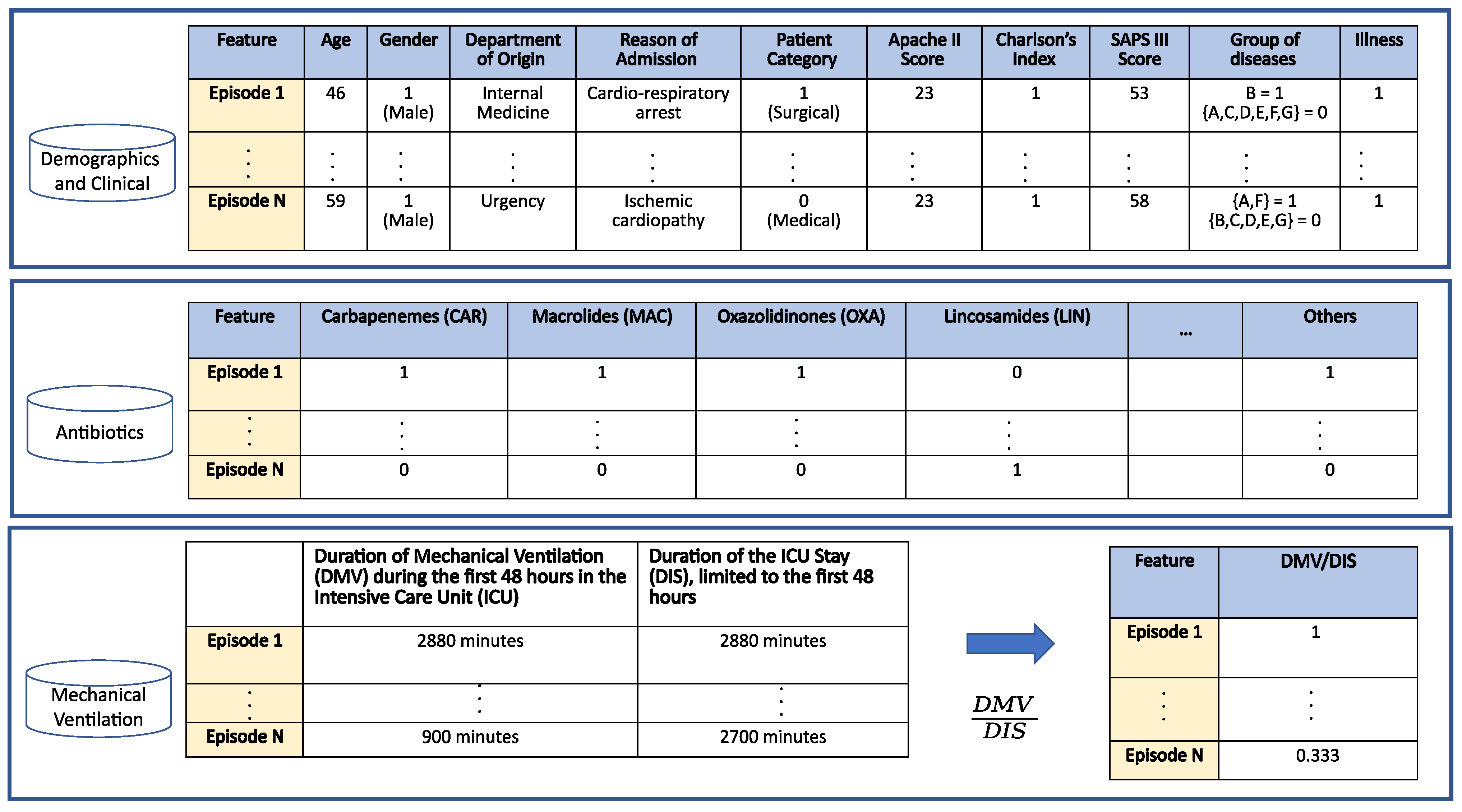
4. Database Description
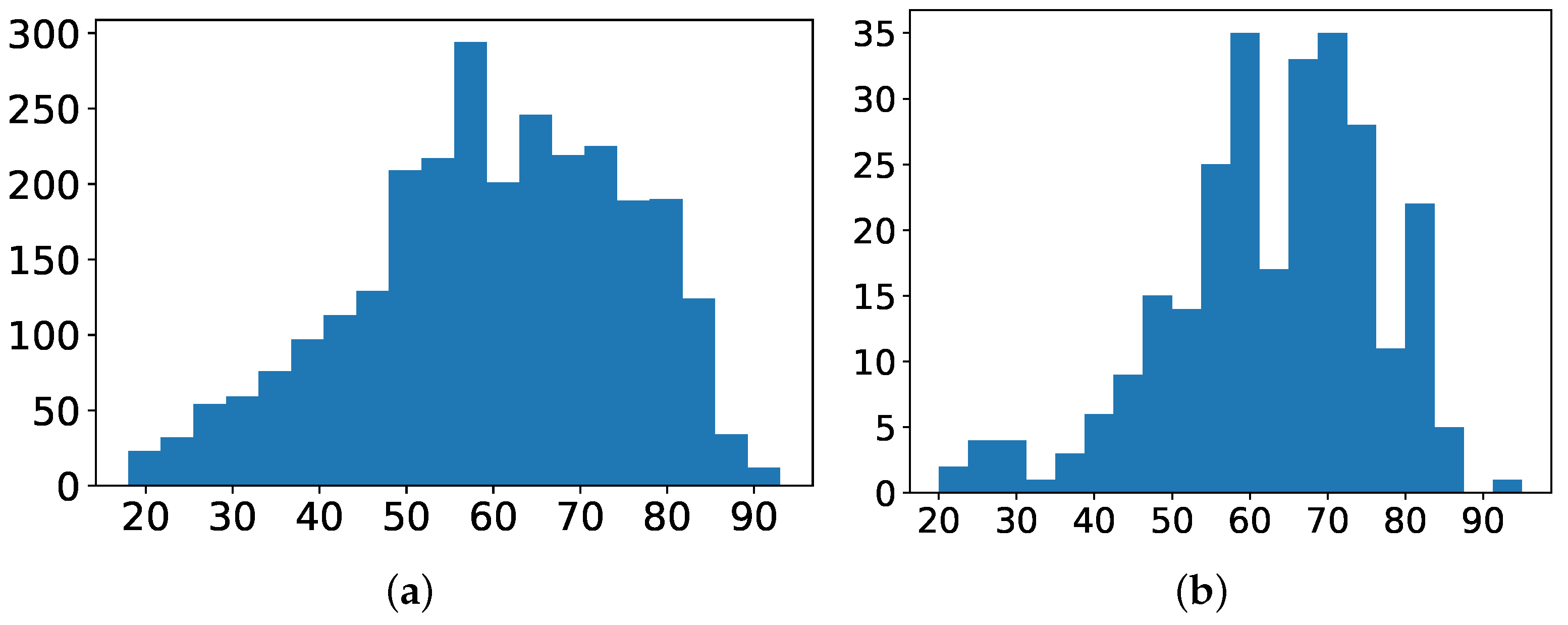
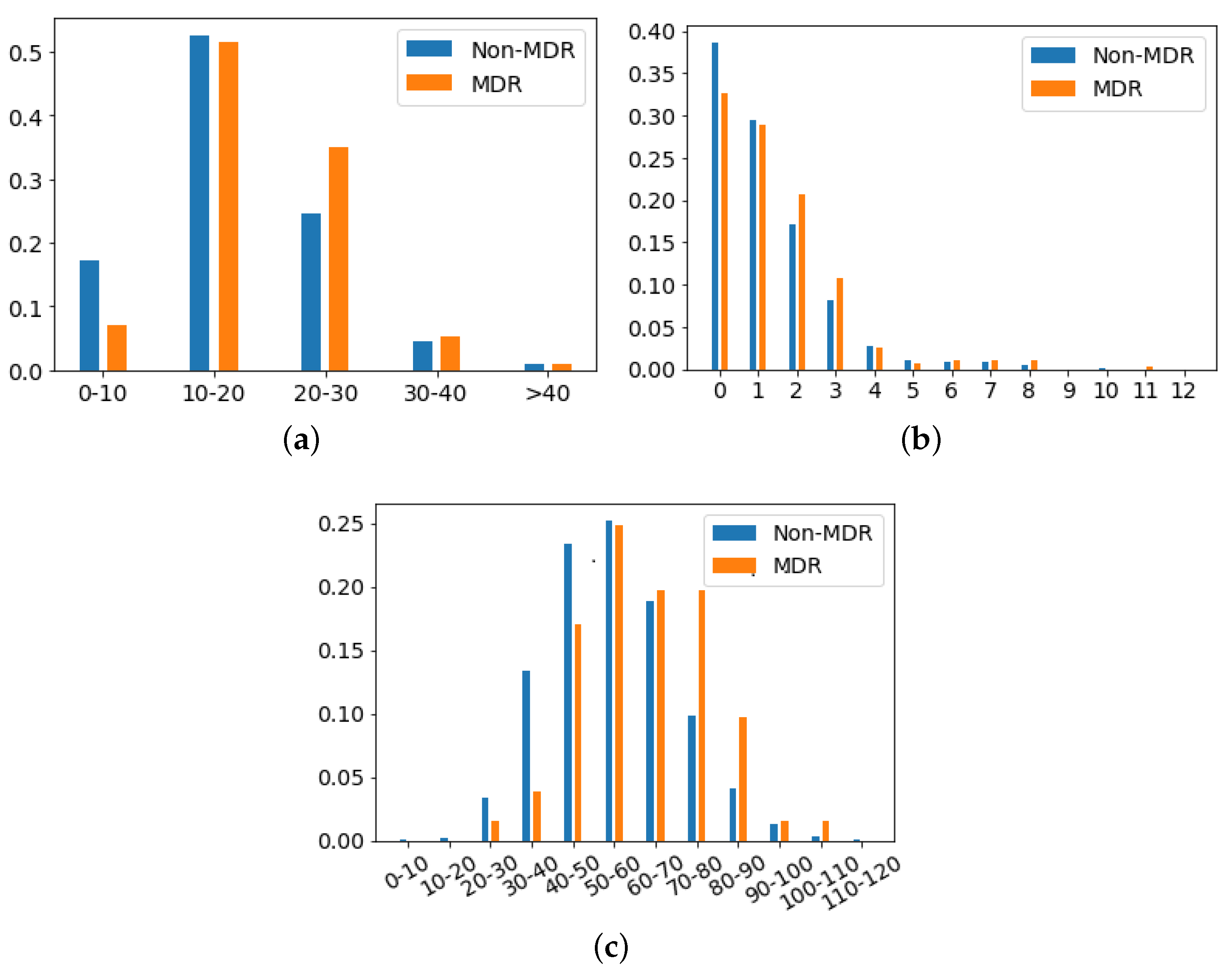
- Age: Numerical variable referred to the age of the patient at the time of the episode. Figure 4a shows the histogram of age for patients with non-MDR episodes, whereas Figure 4b is for patients with MDR episodes. The average age for patients with MDR episodes is about 63 years, while for non-MDR ones is 60 years.
- Gender: Binary variable indicating whether the gender of the patient is female or male. Among the 1159/1854 episodes associated with women/men, only about 9% of the episodes associated to each gender correspond to MDR patients during the first 48 h from ICU admission.
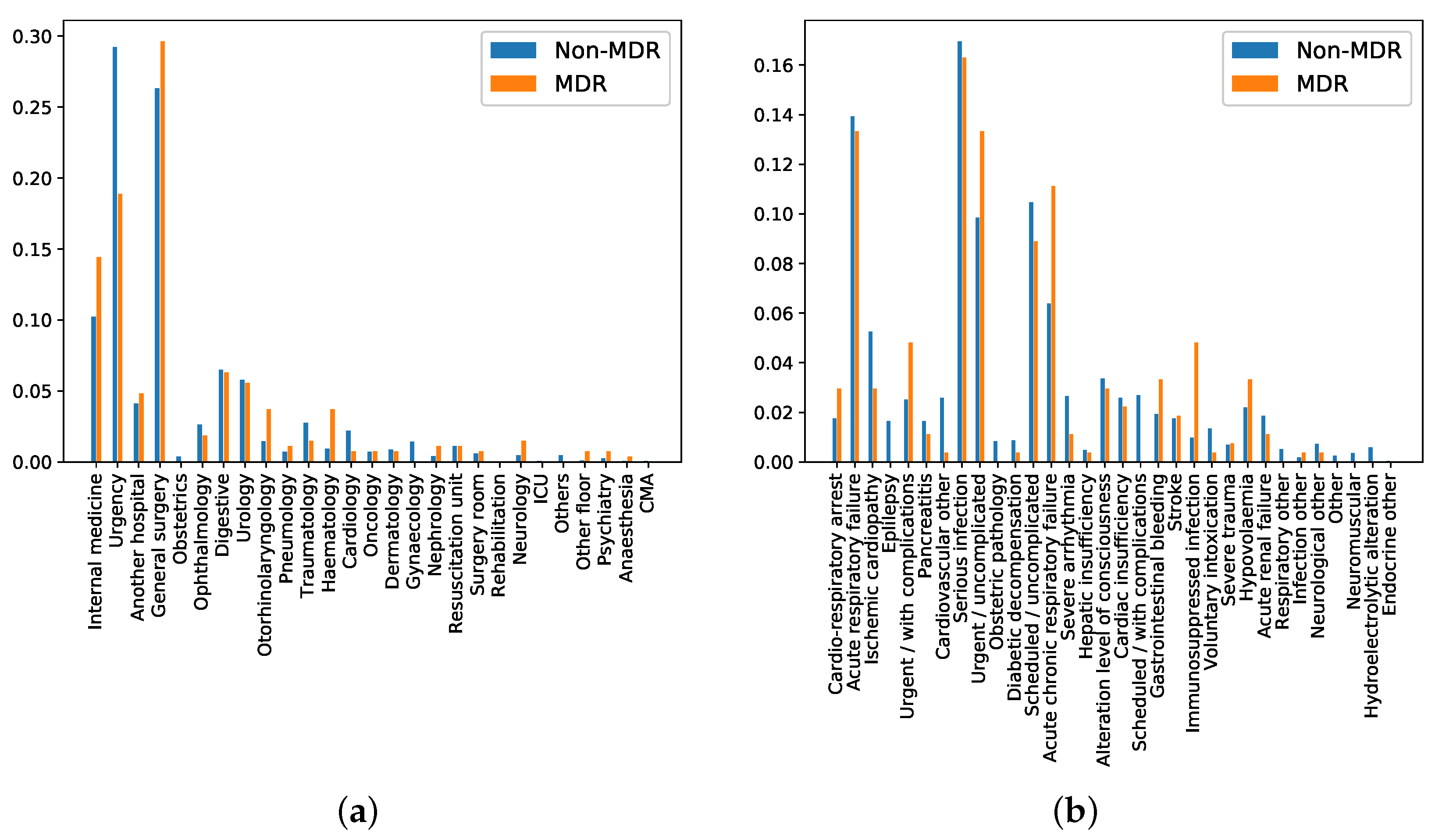
- Department of origin: Categorical feature indicating the service where the patient was admitted before his/her admission to the ICU. This feature contains 27 categories (see Figure 5a), being ‘general surgery’ and ‘emergency’ the most frequent ones. It is also remarkable that the department of origin with higher rate for MDR episodes is ‘general surgery’, while it is ‘emergency’ for non-MDR episodes.
- Reason of admission: Categorical feature indicating the main reason for the ICU admission. It contains 32 categories, shown in Figure 5b. The categories named ‘Serious infection’ and ‘Acute respiratory failure’ are the most frequent reasons for ICU admission, both for MDR and non-MDR episodes.
- Patient Category: Binary feature with values associated with ‘Surgical’ and ‘Medical’, identifying whether the patient was admitted or not in the ICU just after a surgery. In our database, 40.14% of MDR episodes are ‘Surgical’, while this percentage is 44.81% for non-MDR episodes.
- Apache II Score: Clinical score provided by a disease severity classification system named Apache (Acute Physiology and Chronic Health Evaluation), used in the ICU [57,58]. Higher scores of Apache II are associated with a higher risk of death. In our database, the average ± standard deviation of Apache II Score for MDR patient episodes is 19.17 ± 6.91, while it is 17.43 ± 7.66 for the non-MDR patient episodes. This can be visually checked in Figure 6a, which shows the distribution of values per each kind of episode.
- Charlson’s comorbidity index: Clinical score used to predict the ten-year mortality according to the age and comorbidities of the patient. In our database, the Charlson’s average and standard deviation is 1.44 ± 1.65 for MDR patient episodes, and 1.24 ± 1.52 for the non-MDR patient episodes (see the values distribution in Figure 6b).
- SAPS III: A score used to estimate the probability of mortality risk based on data registered during the first 24 h of the patient admission in the ICU [59]. Higher values of SAPS III (Simplified Acute Physiology Score III) are associated with higher mortality rates. Most values of SAPS III are between the scores 10 and 20 (51.6% of total MDR patient episodes and 52.6% of total non-MDR patient episodes). It may be remarkable that the percentage of MDR episodes is higher than that of non-MDR ones (35.0% versus 25.7%) when the SAPS III score increases. For low SAPS III scores, ratios are reversed: 0.1% for MDR versus 17.3% for non-MDR.
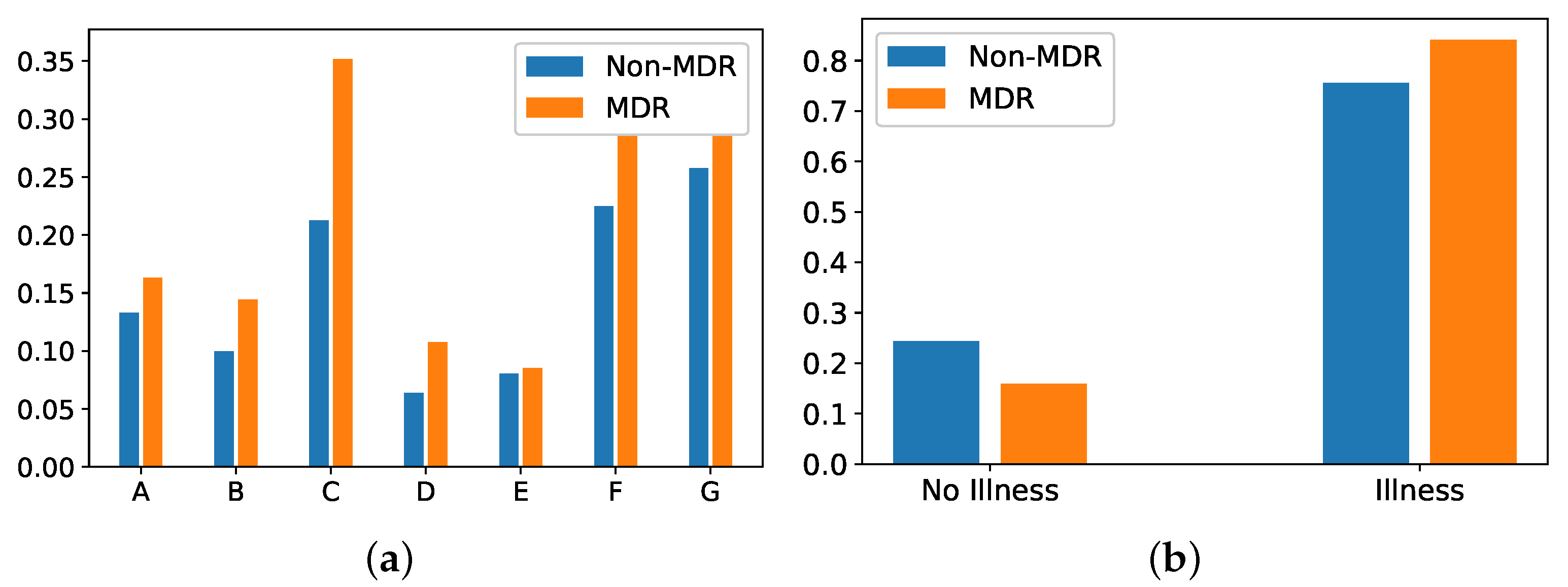
- Group of diseases: Categorical feature indicating the type of clinical comobordities a patient can suffer from. In this work, seven groups related with different diseases were considered: group A (related to cardiovascular events); group B (kidney failure, arthritis); group C (respiratory problems); group D (pancreatitis, endocrine); group E (epilepsy, dementia); group F (diabetes, arteriosclerosis); and group G (neoplasms). Figure 7a shows the corresponding rate distribution for MDR and non-MDR patient episodes.
- Illness: Binary feature indicating whether the patient presents at least one disease according to the variable Group of diseases. We show in Figure 7b the distribution of this variable for MDR and non-MDR patient episodes. Note that the illness rate is higher for patients who will develop MDR.



5. Experiments and Results
5.1. Identification of Relevant Risk Factors
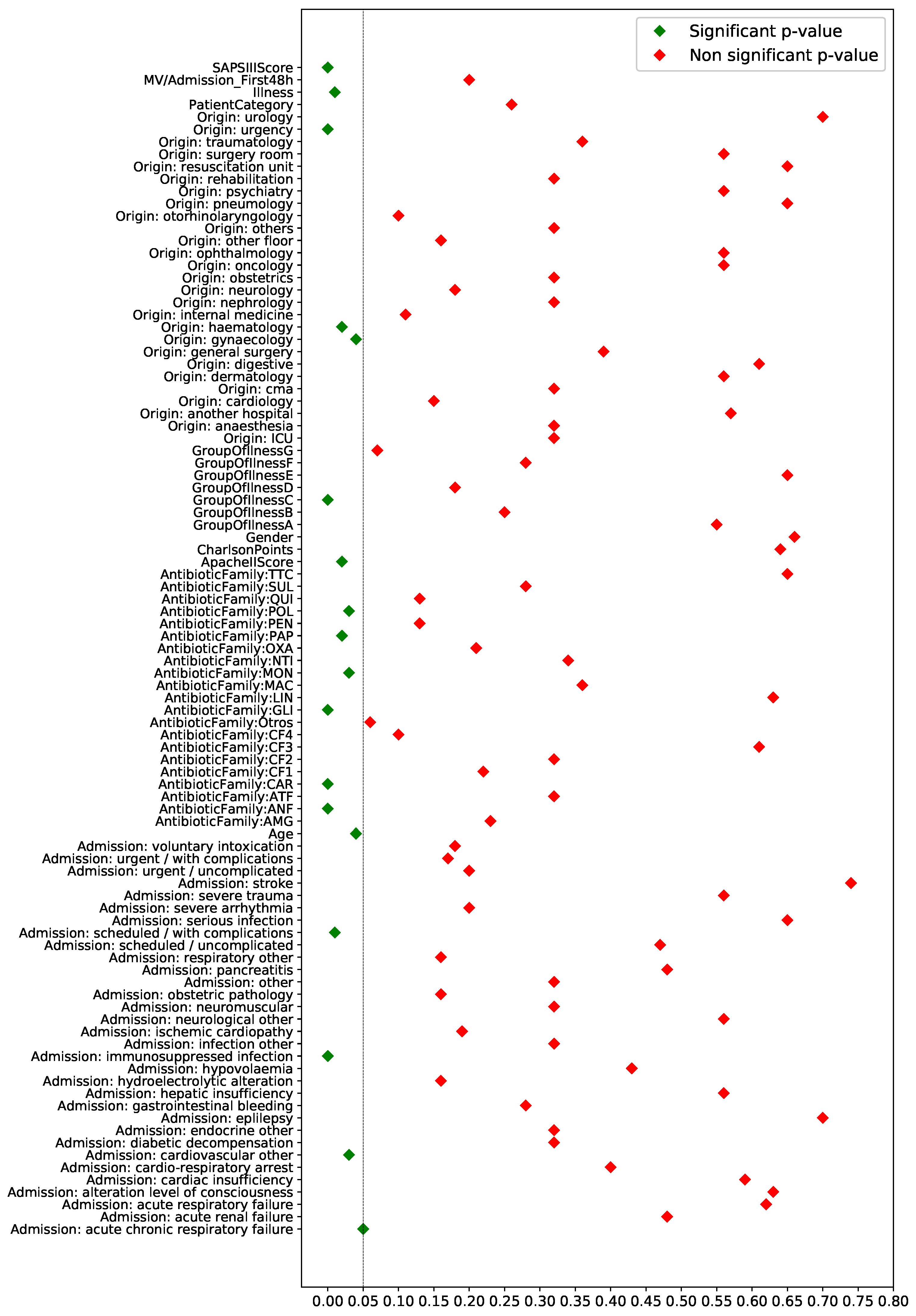
5.1.1. Based on Proportion and Median Tests
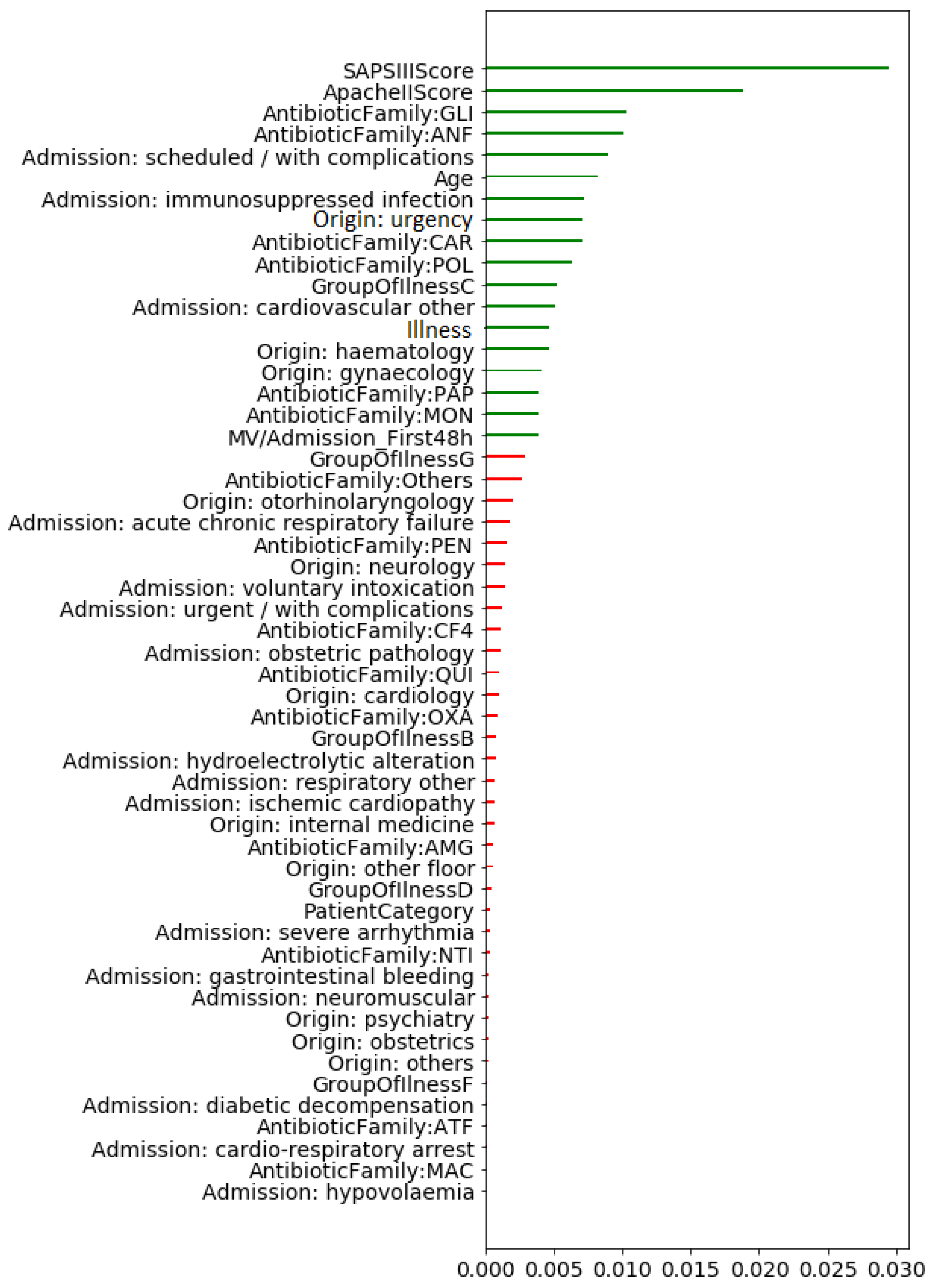
5.1.2. Based on Mutual Information
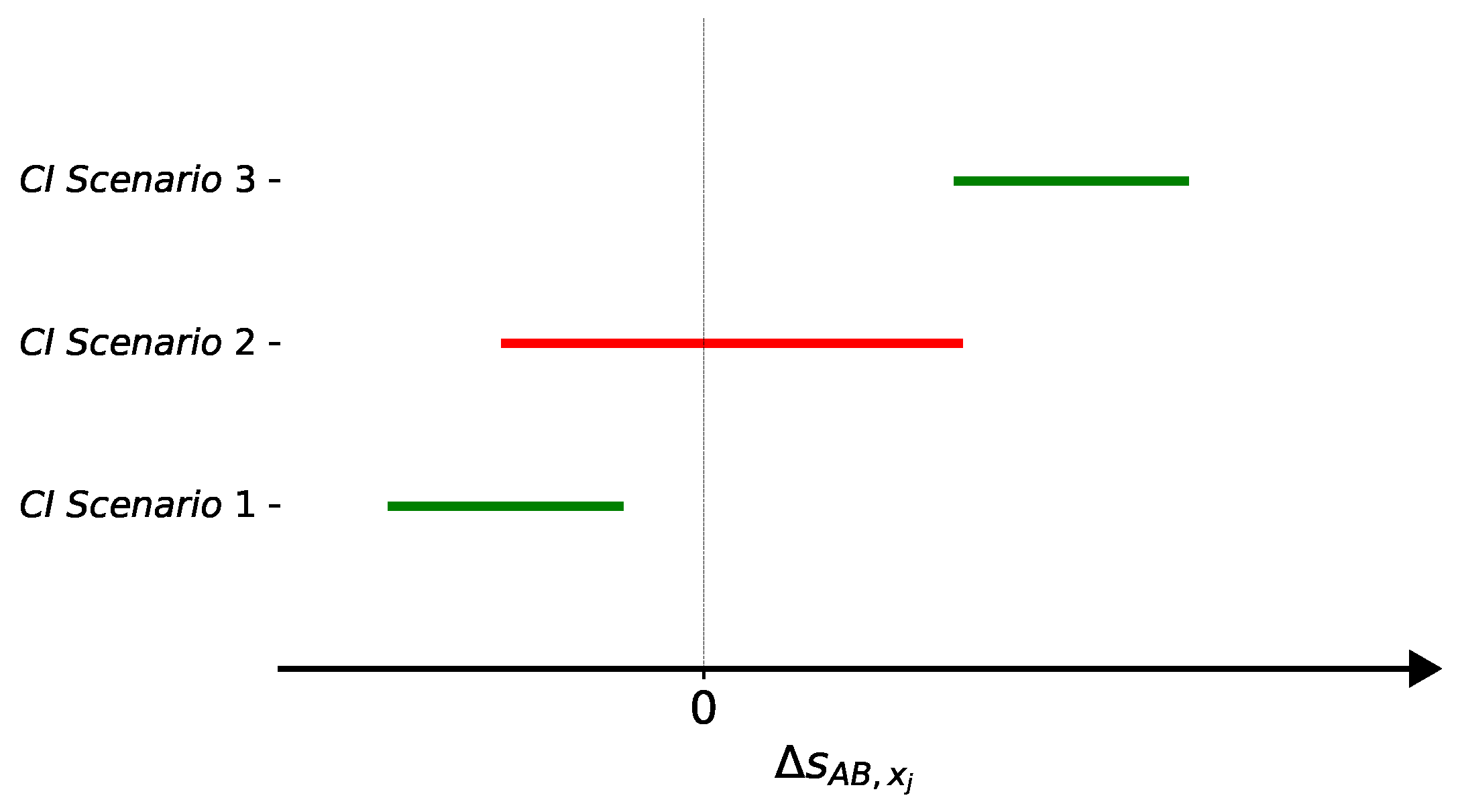
5.1.3. Based on Confidence Intervals
5.2. Artificial Intelligence Models to Predict MDR in the ICU
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- De la Bédoyère, G. The Discovery of Penicillin; Evans Brothers Ltd.: London, UK, 2005. [Google Scholar]
- Franklin, T.J.; Snow, G.A. Biochemistry of Antimicrobial Action; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Béahdy, J. Recent developments of antibiotic research and classification of antibiotics according to chemical structure. Adv. Appl. Microbiol. 1974, 18, 309–406. [Google Scholar]
- Mendelson, M.; Matsoso, M.P. The World Health Organization global action plan for antimicrobial resistance. S. Afr. Med. J. 2015, 105, 325. [Google Scholar] [CrossRef] [Green Version]
- Siegel, J.D.; Rhinehart, E.; Jackson, M.; Chiarello, L. Management of multidrug-resistant organisms in health care settings, 2006. Am. J. Infect. Control 2007, 35, S165–S193. [Google Scholar] [CrossRef] [PubMed]
- Depardieu, F.; Podglajen, I.; Leclercq, R.; Collatz, E.; Courvalin, P. Modes and modulations of antibiotic resistance gene expression. Clin. Microbiol. Rev. 2007, 20, 79–114. [Google Scholar] [CrossRef] [Green Version]
- Neu, H.C. The Crisis in Antibiotic Resistance. Science 1992, 257, 1064–1073. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Smith, R.; Coast, J. The true cost of antimicrobial resistance. BMJ Glob. Health 2013, 346, f1493. [Google Scholar] [CrossRef] [Green Version]
- Magill, S.S.; Edwards, J.R.; Bamberg, W.; Beldavs, Z.G.; Dumyati, G.; Kainer, M.A.; Lynfield, R.; Maloney, M.; McAllister-Hollod, L.; Nadle, J.; et al. Multistate point-prevalence survey of health care-associated infections. N. Engl. J. Med. 2014, 370, 1198–1208. [Google Scholar] [CrossRef] [Green Version]
- Soguero-Ruiz, C.; Hindberg, K.; Mora-Jiménez, I.; Rojo-Álvarez, J.L.; Skrøvseth, S.O.; Godtliebsen, F.; Mortensen, K.; Revhaug, A.; Lindsetmo, R.O.; Augestad, K.M.; et al. Predicting colorectal surgical complications using heterogeneous clinical data and kernel methods. J. Biomed. Inform. 2016, 61, 87–96. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Carretero, R.; Vigil-Medina, L.; Barquero-Perez, O.; Mora-Jimenez, I.; Soguero-Ruiz, C.; Goya-Esteban, R.; Ramos-Lopez, J. Logistic LASSO and elastic net to characterize vitamin D deficiency in a hypertensive obese population. Metab. Syndr. Relat. Disord. 2020, 18, 79–85. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; John Wiley & Sons: New York, NY, USA, 2001. [Google Scholar]
- Ripley, B.D. Pattern Recognition and Neural Networks; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Martínez-Agüero, S.; Mora-Jiménez, I.; Lérida-García, J.; Álvarez-Rodríguez, J.; Soguero-Ruiz, C. Machine Learning Techniques to Identify Antimicrobial Resistance in the Intensive Care Unit. Entropy 2019, 21, 603. [Google Scholar] [CrossRef] [Green Version]
- Hernàndez-Carnerero, À.; Sànchez-Marrè, M.; Mora-Jiménez, I.; Soguero-Ruiz, C.; Martínez-Agüero, S.; Álvarez Rodríguez, J. Modelling Temporal Relationships in Pseudomonas Aeruginosa Antimicrobial Resistance Prediction in Intensive Care Unit. In Proceedings of the Workshop of Singular Problems for Health Care at the 24th European Conference on Artificial, Santiago de Compostela, Spain, 4 September 2020. [Google Scholar]
- Revuelta-Zamorano, P.; Sánchez, A.; Rojo-Álvarez, J.L.; Álvarez-Rodríguez, J.; Ramos-López, J.; Soguero-Ruiz, C. Prediction of healthcare associated infections in an intensive care unit using machine learning and big data tools. In XIV Mediterranean Conference on Medical and Biological Engineering and Computing 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 840–845. [Google Scholar]
- Escudero-Arnanz, O.; Mora-Jiménez, I.; Martínez-Agüero, S.; Álvarez Rodríguez, J.; Soguero-Ruiz, C. Temporal Feature Selection for Characterizing Antimicrobial Multidrug Resistance in the Intensive Care Unit. In Proceedings of the Workshop of Singular Problems for Health Care at the 24th European Conference on Artificial, Santiago de Compostela, Spain, 4 September 2020. [Google Scholar]
- Martínez-Agüero, S.; Mora-Jiménez, I.; Álvarez Rodríguez, J.; Marqués, A.G.; Soguero-Ruiz, C. Applying LSTM Networks to Predict Multi-drug Resistance Using Binary Multivariate Clinical Sequences. In Proceedings of the STAIRS Workshop at the 24th European Conference on Artificial Intelligence, Santiago de Compostela, Spain, 29 August–8 September 2020. [Google Scholar]
- Kuhn, M.; Johnson, K. Feature Engineering and Selection: A Practical Approach for Predictive Models; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Efron, B. Bootstrap methods: Another look at the jackknife. Ann. Stat. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning with Applications in R; Springer: New York, NY, USA, 2013. [Google Scholar]
- Efron, B.; Tibshirani, R.J. An Introduction to the Bootstrap; CRC Press: Boca Raton, FL, USA, 1994. [Google Scholar]
- Soguero-Ruiz, C.; Gimeno-Blanes, F.J.; Mora-Jiménez, I.; Martínez-Ruiz, M.P.; Rojo-Álvarez, J.L. On the differential benchmarking of promotional efficiency with machine learning modeling (I): Principles and statistical comparison. Expert Syst. Appl. 2012, 39, 12772–12783. [Google Scholar] [CrossRef]
- Soguero-Ruiz, C.; Gimeno-Blanes, F.J.; Mora-Jiménez, I.; Martínez-Ruiz, M.P.; Rojo-Álvarez, J.L. On the differential benchmarking of promotional efficiency with machine learning modelling (II): Practical applications. Expert Syst. Appl. 2012, 39, 12784–12798. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Lal, T.N.; Chapelle, O.; Weston, J.; Elisseeff, A. Feature Extraction; Springer: Heidelberg, Germany, 2006. [Google Scholar]
- Talón-Ballestero, P.; González-Serrano, L.; Soguero-Ruiz, C.; Muñoz-Romero, S.; Rojo-Álvarez, J.L. Using big data from customer relationship management information systems to determine the client profile in the hotel sector. Tour. Manag. 2018, 68, 187–197. [Google Scholar] [CrossRef]
- Tang, S.; Jeong, J.H. Median tests for censored survival data; a contingency table approach. Biometrics 2012, 68, 983–989. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Carlin, J.B.; Doyle, L.W. Basic concepts of statistical reasoning: Standard errors and confidence intervals. J. Paediatr. Child Health 2001, 37, 502–505. [Google Scholar] [CrossRef]
- Rosner, B. Fundamentals of Biostatistics; Brooks/Cole Cengage Learning: Boston, MA, USA, 2011. [Google Scholar]
- Zar, J.H. Median Test; Biostatistical Analysis, 5th ed.; Prentice-Hall/Pearson: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Mood, A.M. Mood’s Median Test. Introduction to the Theory of Statistics, 3th ed.; McGraw-Hill Education: New York, NY, USA, 1950. [Google Scholar]
- Plackett, R.L. Karl Pearson and the Chi-Squared Test; International Statistical Review/Revue Internationale de Statistique: Voorburg, The Netherlands, 1983; pp. 59–72. [Google Scholar]
- Kraskov, A.; Stögbauer, H.; Erratum, G.P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [Green Version]
- Ross, B.C. Mutual information between discrete and continuous data sets. PLoS ONE 2014, 9, e87357. [Google Scholar] [CrossRef]
- Bromiley, P.A.; Thacker, N.A.; Bouhova-Thacker, E. Shannon Entropy, Renyi Entropy, and Information; Statistics and Information Series. 2004. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.330.9856&rep=rep1&type=pdf (accessed on 6 February 2021).
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Soguero-Ruiz, C.; Hindberg, K.; Rojo-Álvarez, J.L.; Skrøvseth, S.O.; Godtliebsen, F.; Mortensen, K.; Revhaug, A.; Lindsetmo, R.O.; Augestad, K.M.; Jenssen, R. Support vector feature selection for early detection of anastomosis leakage from bag-of-words in electronic health records. IEEE J. Biomed. Health Inform. 2014, 20, 1404–1415. [Google Scholar] [CrossRef] [PubMed]
- Devijver, P.A.; Kittler, J. Pattern Recognition: A Statistical Approach; Prentice Hall: Upper Saddle River, NJ, USA, 1982. [Google Scholar]
- Liu, X.Y.; Wu, J.; Zhou, Z.H. Exploratory undersampling for class-imbalance learning. IEEE Trans. Syst. Man Cybern. Syst. 2008, 39, 539–550. [Google Scholar]
- Zhu, C.; Byrd, R.H.; Lu, P.; Nocedal, J. Algorithm 778: L-BFGS-B: Fortran subroutines for large-scale bound-constrained optimization. ACM Trans. Math. Softw. 1997, 1997, 550–560. [Google Scholar] [CrossRef]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: Hoboken, NJ, USA, 2013; p. 398. [Google Scholar]
- Kotsiantis, S.B. Decision trees: A recent overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R. Classification and Regression Trees; Chapman and Hall: London, UK, 1984. [Google Scholar]
- Chen, T.; He, T. Higgs Boson Discovery with Boosted Trees. In Proceedings of the NIPS Workshop on High-energy Physics and Machine Learning, Montreal, QC, Canada, 13 December 2014; pp. 69–80. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Sarle, W.S. Neural Networks and Statistical Models. In Proceedings of the Nineteenth Annual SAS Users Group International Conference, Dallas, TX, USA, 10–13 April 1994. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef] [Green Version]
- Hassoun, M.H. Fundamentals of Artificial Neural Networks; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Bengio, Y. Gradient-based optimization of hyperparameters. Neural Comput. 2000, 12, 1889–1900. [Google Scholar] [CrossRef]
- Amari, S. Backpropagation and stochastic gradient descent method. Neurocomputing 1993, 5, 185–196. [Google Scholar] [CrossRef]
- Lee, K.C.; Orten, B.; Dasdan, A.; Li, W. Estimating conversion rate in display advertising from past performance data. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012. [Google Scholar]
- Polderman, K.H.; Girbes, A.R.J.; Thijs, L.G.; Strack van Schijndel, R.J.M. Accuracy and reliability of APACHE II scoring in two intensive care units: Problems and pitfalls in the use of APACHE II and suggestions for improvement. Anaesthesia 2001, 56, 7–50. [Google Scholar] [CrossRef] [PubMed]
- Knaus, W.A.; Draper, E.A.; Wagner, D.P.; Zimmerman, J.E. APACHE II: A severity of disease classification system. Crit. Care Med. 1985, 13, 818–829. [Google Scholar] [CrossRef]
- Metnitz, P.G.; Moreno, R.P.; Almeida, E.; Jordan, B.; Bauer, P.; Campos, R.A.; Iapichino, G.; Edbrooke, D.; Capuzzo, M.; Le Gall, J.R. SAPS 3—From evaluation of the patient to evaluation of the intensive care unit. Part 1: Objectives, methods and cohort description. Intensive Care Med. 2005, 31, 1336–1344. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Muñoz-Romero, S.; Gorostiaga, A.; Soguero-Ruiz, C.; Mora-Jiménez, I.; Rojo-Álvarez, J.L. Informative variable identifier: Expanding interpretability in feature selection. Pattern Recognit. 2020, 98, 1070–1077. [Google Scholar] [CrossRef]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson Correlation Coefficient; Springer: Berlín/Heideleberg, Germany, 2009. [Google Scholar]
- Read, C.B.; Vidakovic, B. Encyclopedia of Statistical Sciences; John Wiley & Sons: New York, NY, USA, 2006. [Google Scholar]
- Low, D.E. What is the relevance of antimicrobial resistance on the outcome of community-acquired pneumonia caused by Streptococcus pneumoniae? (Should macrolide monotherapy be used for mild pneumonia?). Infect. Dis. Clin. 2013, 27, 87–97. [Google Scholar] [CrossRef]
- French, G.L. Clinical impact and relevance of antibiotic resistance. Adv. Drug Deliv. Rev. 2005, 57, 1514–1527. [Google Scholar] [CrossRef]
- Zilahi, G.; McMahon, M.A.; Povoa, P.; Martin-Loeches, I. Duration of antibiotic therapy in the intensive care unit. J. Thorac. Dis. 2016, 8, 3774–3780. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rasmussen, C.E. Gaussian processes in machine learning. In Summer School on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2003; pp. 63–71. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Class-Balancing Strategy | Accuracy | Sensitivity | Specificity | AUC |
|---|---|---|---|---|---|
| LR | Undersampling | 0.618 ± 0.046 | 0.595 ± 0.077 | 0.646 ± 0.071 | 0.620 ± 0.047 |
| Weighted cost | 0.661 ± 0.015 | 0.614 ± 0.069 | 0.665 ± 0.019 | 0.640 ± 0.031 | |
| DT | Undersampling | 0.568 ± 0.049 | 0.559 ± 0.128 | 0.581 ± 0.134 | 0.570 ± 0.048 |
| Weighted cost | 0.558 ± 0.100 | 0.628 ± 0.132 | 0.551 ± 0.122 | 0.590 ± 0.027 | |
| XGB | Undersampling | 0.587 ± 0.047 | 0.574 ± 0.077 | 0.607 ± 0.077 | 0.590 ± 0.047 |
| Weighted cost | 0.575 ± 0.221 | 0.602 ± 0.204 | 0.572 ± 0.261 | 0.587 ± 0.048 | |
| SLP | Undersampling | 0.621 ± 0.045 | 0.599 ± 0.070 | 0.649 ± 0.069 | 0.624 ± 0.045 |
| Weighted cost | 0.660 ± 0.015 | 0.616 ± 0.067 | 0.664 ± 0.018 | 0.640 ± 0.031 | |
| MLP | Undersampling | 0.581 ± 0.050 | 0.575 ± 0.100 | 0.595 ± 0.099 | 0.585 ± 0.049 |
| Weighted cost | 0.639 ± 0.039 | 0.614 ± 0.086 | 0.642 ± 0.046 | 0.628 ± 0.036 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mora-Jiménez, I.; Tarancón-Rey, J.; Álvarez-Rodríguez, J.; Soguero-Ruiz, C. Artificial Intelligence to Get Insights of Multi-Drug Resistance Risk Factors during the First 48 Hours from ICU Admission. Antibiotics 2021, 10, 239. https://doi.org/10.3390/antibiotics10030239
Mora-Jiménez I, Tarancón-Rey J, Álvarez-Rodríguez J, Soguero-Ruiz C. Artificial Intelligence to Get Insights of Multi-Drug Resistance Risk Factors during the First 48 Hours from ICU Admission. Antibiotics. 2021; 10(3):239. https://doi.org/10.3390/antibiotics10030239
Chicago/Turabian StyleMora-Jiménez, Inmaculada, Jorge Tarancón-Rey, Joaquín Álvarez-Rodríguez, and Cristina Soguero-Ruiz. 2021. "Artificial Intelligence to Get Insights of Multi-Drug Resistance Risk Factors during the First 48 Hours from ICU Admission" Antibiotics 10, no. 3: 239. https://doi.org/10.3390/antibiotics10030239
APA StyleMora-Jiménez, I., Tarancón-Rey, J., Álvarez-Rodríguez, J., & Soguero-Ruiz, C. (2021). Artificial Intelligence to Get Insights of Multi-Drug Resistance Risk Factors during the First 48 Hours from ICU Admission. Antibiotics, 10(3), 239. https://doi.org/10.3390/antibiotics10030239