
Matching Biomedical Ontologies through Adaptive Multi-Modal Multi-Objective Evolutionary Algorithm




Abstract
:Simple Summary
Abstract
1. Introduction
- Two evaluation metrics on the alignment’s quality are proposed to calculate the alignment’s f-measure and its conservativity. On this basis, a novel multi-objective optimization model is built for the biomedical ontology matching problem;
- A problem-specific aMMOEA is presented to match two biomedical ontologies, which uses the GMs to adaptively ensure the algorithm’s convergence and diversity in both the objective space and decision space;
- The proposed aMMOEA is employed on three biomedical tracks provided by the Ontology Alignment Evaluation Initiative (OAEI) (http://oaei.ontologymatching.org, accessed on 6 December 2021); the results reveal that aMMOEA is able to effectively determine the diverse solutions for DMs.
2. Related Work
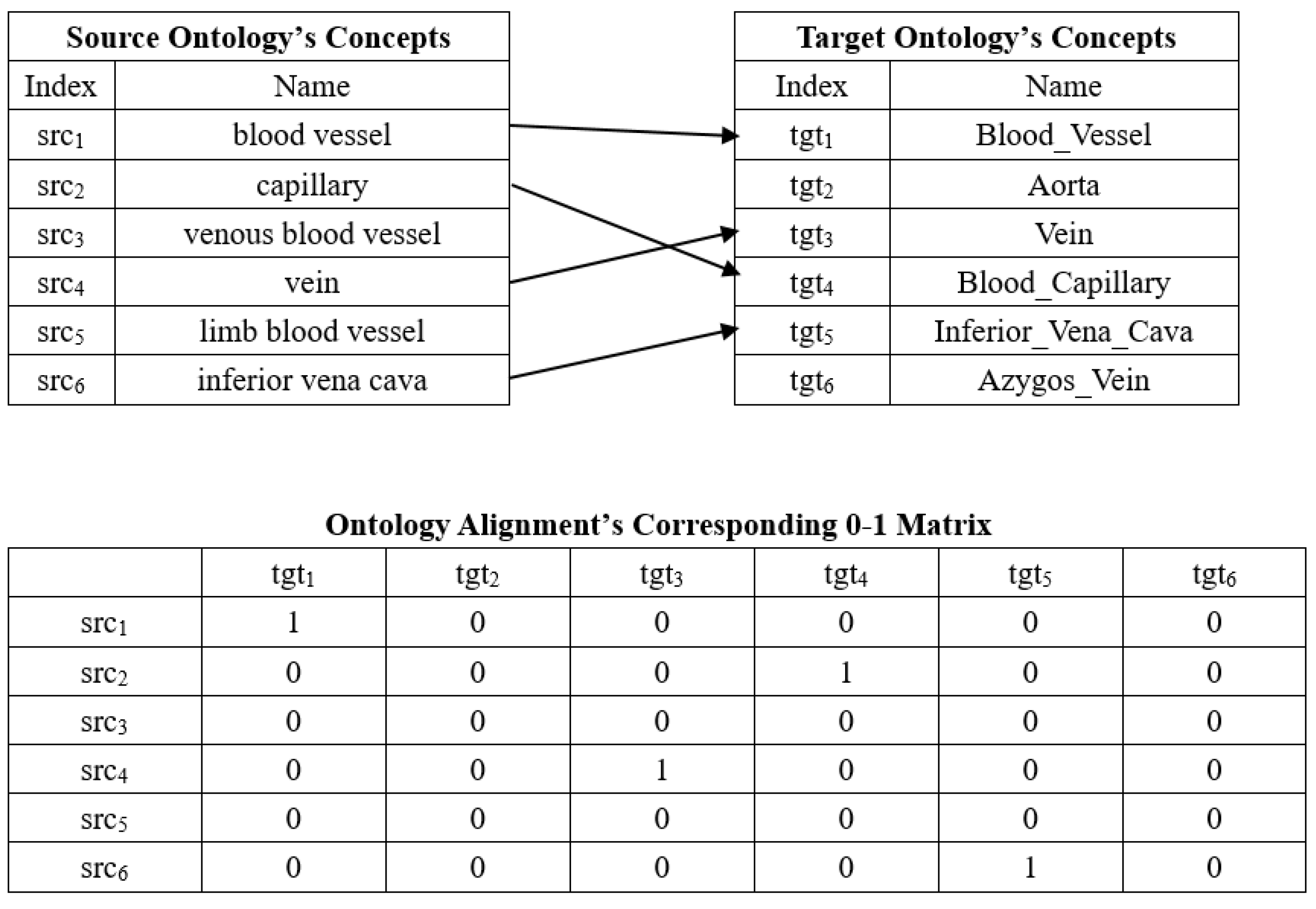
3. Optimization Model on Biomedical Ontology Matching Problem
4. Adaptive Multi-Modal Multi-Objective Evolutionary Algorithm
4.1. Matching Matrix and Guiding Matrix
| Algorithm 1: The framework of adaptive multi-modal multi-objective evolutionary algorithm. |
|
4.2. Initialization
4.3. Update Guiding Matrix
| Algorithm 2: Initialization. |
|
4.4. Guiding Matrix-Based Evolutionary Operators
| Algorithm 3: Crossover operator. |
|
4.5. Adaptive Population Maintenance
| Algorithm 4: Mutation operator. |
|
| Algorithm 5: Selection operator. |
|
| Algorithm 6: Adaptive population maintenance. |
|
5. Experiment
5.1. Experimental Setup
5.2. Experimental Results
5.3. Computational Complexity on Adaptive Multi-Modal Multi-Objective Evolutionary Algorithm
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Donnelly, K. SNOMED-CT: The advanced terminology and coding system for eHealth. Stud. Health Technol. Inf. 2006, 121, 279. [Google Scholar]
- Coronado, S.D.; Haber, M.W.; Sioutos, N.; Tuttle, M.S.; Wright, L.W. NCI Thesaurus: Using Science-Based Terminology to Integrate Cancer Research Results; MEDINFO 2004; IOS Press: Amsterdam, The Netherlands, 2004; pp. 33–37. [Google Scholar]
- Rosse, C.; Mejino, J.L., Jr. A reference ontology for biomedical informatics: The Foundational Model of Anatomy. J. Biomed. Inf. 2003, 36, 478–500. [Google Scholar] [CrossRef] [Green Version]
- Bodenreider, O. Biomedical ontologies in action: Role in knowledge management, data integration and decision support. Yearb. Med. Inf. 2008, 17, 67–79. [Google Scholar] [CrossRef] [Green Version]
- Hoehndorf, R.; Schofield, P.N.; Gkoutos, G.V. The role of ontologies in biological and biomedical research: A functional perspective. Briefings Bioinform. 2015, 16, 1069–1080. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Oliveira, D.; Pesquita, C. Improving the interoperability of biomedical ontologies with compound alignments. J. Biomed. Semant. 2018, 9, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Eiben, A.E.; Smith, J.E. What is an evolutionary algorithm? In Introduction to Evolutionary Computing; Springer: Berlin/Heidelberg, Germany, 2015; pp. 25–48. [Google Scholar]
- Acampora, G.; Loia, V.; Vitiello, A. Enhancing ontology alignment through a memetic aggregation of similarity measures. Inf. Sci. 2013, 250, 1–20. [Google Scholar] [CrossRef]
- Xue, X.; Chen, J. Matching biomedical ontologies through Compact Differential Evolution algorithm with compact adaption schemes on control parameters. Neurocomputing 2021, 458, 526–534. [Google Scholar] [CrossRef]
- Xingsi, X.; Chao, J. Matching Sensor Ontologies with Multi-Context Similarity Measure and Parallel Compact Differential Evolution Algorithm. IEEE Sens. J. 2021, 21, 24570–24578. [Google Scholar]
- Rijsberge, C.J.V. Information Retrieval; University of Glasgow: Butterworth, UK, 1975. [Google Scholar]
- Rudolph, G. On a multi-objective evolutionary algorithm and its convergence to the pareto set. In Proceedings of the 1998 IEEE International Conference on Evolutionary Computation, IEEE World Congress on Computational Intelligence (Cat. No. 98TH8360), Anchorage, AK, USA, 4–9 May 1998; pp. 511–516. [Google Scholar]
- Sebag, M.; Tarrisson, N.; Teytaud, O.; Lefevre, J.; Baillet, S. A Multi-Objective Multi-Modal Optimization Approach for Mining Stable Spatio-Temporal Patterns. In Proceedings of the 19th International Joint Conference in Artificial Intelligence, Edinburgh, UK, 30 July–5 August 2005; pp. 859–864. [Google Scholar]
- Martinez-Gil, J.; Montes, J.F.A. Evaluation of two heuristic approaches to solve the ontology meta-matching problem. Knowl. Inf. Syst. 2011, 26, 225–247. [Google Scholar] [CrossRef] [Green Version]
- Ginsca, A.L.; Iftene, A. Using a genetic algorithm for optimizing the similarity aggregation step in the process of ontology alignment. In Proceedings of the 9th Roedunet International Conference, Sibiu, Romania, 24–26 June 2010; pp. 118–122. [Google Scholar]
- Xue, X.; Wang, Y. Using memetic algorithm for instance coreference resolution. IEEE Trans. Knowl. Data Eng. 2015, 28, 580–591. [Google Scholar] [CrossRef]
- Xue, X.; Liu, J.; Tsai, P.W.; Zhan, X.; Ren, A. Optimizing ontology alignment by using compact genetic algorithm. In Proceedings of the 2015 11th International Conference on Computational Intelligence and Security (CIS), Shenzhen, China, 19–20 December 2015; pp. 231–234. [Google Scholar]
- Wang, J.; Ding, Z.; Jiang, C. GAOM: Genetic algorithm based ontology matching. In Proceedings of the IEEE Asia-Pacific Conference on Services Computing, Guangzhou, China, 12–15 December 2006; pp. 617–620. [Google Scholar]
- Alves, A.; Revoredo, K.; Baião, F. Ontology alignment based on instances using hybrid genetic algorithm. In Proceedings of the 7th International Conference on Ontology Matching—Volume 946, CEUR-WS.org, Boston, MA, USA, 11 November 2012; pp. 242–243. [Google Scholar]
- Xue, X.; Pan, J.S. A segment-based approach for large-scale ontology matching. Knowl. Inf. Syst. 2017, 52, 467–484. [Google Scholar] [CrossRef]
- Xue, X.; Zhang, J. Matching large-scale biomedical ontologies with central concept based partitioning algorithm and adaptive compact evolutionary algorithm. Appl. Soft Comput. 2021, 106, 107343. [Google Scholar] [CrossRef]
- Chu, S.C.; Xue, X.; Pan, J.S.; Wu, X. Optimizing ontology alignment in vector space. J. Internet Technol. 2020, 21, 15–22. [Google Scholar]
- Xue, X.; Chen, J. Using Compact Evolutionary Tabu Search algorithm for matching sensor ontologies. Swarm Evol. Comput. 2019, 48, 25–30. [Google Scholar] [CrossRef]
- Acampora, G.; Kaymak, U.; Loia, V.; Vitiello, A. Applying NSGA-II for solving the ontology alignment problem. In Proceedings of the 2013 IEEE International Conference on Systems, Man, and Cybernetics, Washington, DC, USA, 13–16 October 2013; pp. 1098–1103. [Google Scholar]
- Xue, X.; Wang, Y.; Hao, W.; Hou, J. Optimizing ontology alignments through NSGA-II without using reference alignment. Comput. Inf. 2014, 33, 857–876. [Google Scholar]
- Xue, X.; Wang, Y.; Hao, W. Using MOEA/D for optimizing ontology alignments. Soft Comput. 2014, 18, 1589–1601. [Google Scholar] [CrossRef]
- Xue, X.; Liu, J. Optimizing ontology alignment through compact MOEA/D. Int. J. Pattern Recognit. Artif. Intell. 2017, 31, 1759004. [Google Scholar] [CrossRef]
- Xue, X.; Wang, Y. Improving the efficiency of NSGA-II based ontology aligning technology. Data Knowl. Eng. 2017, 108, 1–14. [Google Scholar] [CrossRef]
- Xue, X.; Tsai, P.W.; Feng, G. Efficient Ontology Meta-Matching Based on Metamodel-assisted Compact MOEA/D. J. Inf. Hiding Multim. Signal Process. 2017, 8, 1021–1028. [Google Scholar]
- Acampora, G.; Ishibuchi, H.; Vitiello, A. A comparison of multi-objective evolutionary algorithms for the ontology meta-matching problem. In Proceedings of the 2014 IEEE Congress on Evolutionary Computation (CEC), Beijing, China, 6–11 July 2014; pp. 413–420. [Google Scholar]
- Atig, Y.; Zahaf, A.; Bouchiha, D. Conservativity Principle Violations for Ontology Alignment: Survey and Trends. Int. J. Inf. Technol. Comput. Sci. (IJITCS) 2016, 8, 61–71. [Google Scholar] [CrossRef]
- Xue, X.; Wang, Y. Optimizing ontology alignments through a Memetic Algorithm using both MatchFmeasure and Unanimous Improvement Ratio. Artif. Intell. 2015, 223, 65–81. [Google Scholar] [CrossRef]
- Tian, Y.; Liu, R.; Zhang, X.; Ma, H.; Tan, K.C.; Jin, Y. A Multi-Population Evolutionary Algorithm for Solving Large-Scale Multi-Modal Multi-Objective Optimization Problems. IEEE Trans. Evol. Comput. 2020, 2020, 3044711. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Xue, X.; Wang, Y.; Hao, W. Optimizing Ontology Alignments by using NSGA-II. Int. Arab. J. Inf. Technol. (IAJIT) 2015, 12, 176–182. [Google Scholar]
- Deb, K.; Gupta, S. Towards a link between knee solutions and preferred solution methodologies. In Proceedings of the International Conference on Swarm, Evolutionary, and Memetic Computing, Chennai, India, 16–18 December 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 182–189. [Google Scholar]
- Milton, J.S.; Arnold, J.C. Introduction to Probability and Statistics; McGraw-Hill: New York, NY, USA, 1990; Volume 4. [Google Scholar]


{kind=link}
| Track ID | Ontologies | Tasks |
|---|---|---|
| Anatomy Track (http://oaei.ontologymatching.org/2021/anatomy/index.html, accessed on 6 December 2021) | Adult Mouse Anatomy (MA)-2744 classes Human Anatomy (HA)-3304 classes | MA-HA |
| Large Biomed Track (http://www.cs.ox.ac.uk/isg/projects/SEALS/oaei/, accessed on 6 December 2021) | Foundation Model of Anatomy (FMA)-78,989 classes Systemized Nomenclature of Medicine (SNOMED)-122,464 classes National Cancer Institute thesaurus (NCI)-66,724 classes | FMA-NCI FMA-SNOMED SNOMED-NCI |
| Disease and Phenotype Track (https://sws.ifi.uio.no/oaei/phenotype/, accessed on 6 December 2021) | Human Phenotype Ontology (HP)-33,205 classes Mammalian Phenotype Ontology (MP)-32,298 classes | HP-MP |
| Human Disease Ontology (DOID)-24,034 classes Orphanet Rare Disease Ontology (ORDO)-68,009 classes | DOID-ORDO |
| Population Size | Selection Rate | Crossover Rate | Mutation Rate | Maximum Generations | |
|---|---|---|---|---|---|
| NSGA-II | 201 | 0.8 | 0.98 | 0.05 | 300 |
| MOEA/D | 201 | 0.8 | 0.98 | 0.05 | 300 |
| ine Testing Case | NSGA-II | MOEA/D | aMMOEA | |||
|---|---|---|---|---|---|---|
| ine | (, ) | (, ) | (, ) | |||
| ine Anatomy | 0.85 (0.89, 0.76) | 0.02 (0.02, 0.02) | 0.85 (0.89, 0.84) | 0.02 (0.02, 0.01) | 0.92 (0.94, 0.96) | 0.01 (0.02, 0.01) |
| FMA-NCI | 0.87 (0.86, 0.86) | 0.02 (0.02, 0.02) | 0.84 (0.88, 0.78) | 0.02 (0.02, 0.02) | 0.93 (0.95, 0.98) | 0.02 (0.02, 0.02) |
| FMA-SNOMED | 0.71 (0.77, 0.63) | 0.02 (0.02, 0.01) | 0.65 (0.62, 0.75) | 0.01 (0.01, 0.01) | 0.84 (0.86, 0.88) | 0.01 (0.02, 0.01) |
| NCI-SNOMED | 0.68 (0.69, 0.64) | 0.01 (0.01, 0.02) | 0.68 (0.65, 0.70) | 0.02 (0.02, 0.03) | 0.77 (0.77, 0.80) | 0.01 (0.01, 0.01) |
| HP-MP | 0.55 (0.47, 0.57) | 0.02 (0.02, 0.01) | 0.71 (0.68, 0.72) | 0.02 (0.02, 0.02) | 0.85 (0.78, 0.89) | 0.01 (0.01, 0.02) |
| DOID-ORDO | 0.81 (0.83, 0.80) | 0.01 (0.01, 0.01) | 0.84 (0.83, 0.85) | 0.02 (0.03, 0.01) | 0.93 (0.93, 0.97) | 0.02 (0.02, 0.02) |
| ine | ||||||
| ine Testing Case | t-Value | t-Value |
|---|---|---|
| ine | (NSGA-II, aMMOEA) | (MOEA/D, aMMOEA) |
| f-measure (recall, precision) | f-measure (recall, precision) | |
| ine Anatomy | −17.14 (−9.68, −48.98) | −17.14 (−9.68, −46.47) |
| FMA-NCI | −11.61 (−17.42, −23.23) | −17.42 (−13.55, −38.72) |
| FMA-SNOMED | −31.84 (−17.42, −6.82) | −73.58 (−58.78, −50.34) |
| NCI-SNOMED | −34.85 (−30.98, −39.19) | −22.04 (−29.39, −17.32) |
| HP-MP | −73.48 (−75.93, −78.38) | −34.29 (−24.49, −32.92) |
| DOID-ORDO | −29.39 (−24.49, −41.64) | −17.42 (−15.19, −29.39) |
| ine |
| ine Testing Case | p-Value | p-Value |
|---|---|---|
| ine | (NSGA-II, aMMOEA) | (MOEA/D, aMMOEA) |
| f-measure (recall, precision) | f-measure (recall, precision) | |
| ine Anatomy | 0.0185 (0.0327, 0.0064) | 0.0185 (0.0327, 0.0068) |
| FMA-NCI | 0.0273 (0.0182, 0.0136) | 0.0182 (0.0234, 0.0082) |
| FMA-SNOMED | 0.0099 (0.0182, 0.0463) | 0.0043 (0.0054, 0.0063) |
| NCI-SNOMED | 0.0091 (0.0102, 0.0051) | 0.0144 (0.0108, 0.0183) |
| HP-MP | 0.0043 (0.0041, 0.0040) | 0.0092 (0.0129, 0.0096) |
| DOID-ORDO | 0.0108 (0.0129, 0.0076) | 0.0182 (0.0209, 0.0108) |
| ine |
| ine Testing Case | AML | LogMap | XMap | DOME | POMAP++ | aMMOEA |
|---|---|---|---|---|---|---|
| ine Anatomy | 0.94 | 0.89 | 0.89 | 0.76 | 0.89 | 0.92 |
| FMA-NCI | 0.93 | 0.92 | 0.86 | 0.86 | 0.88 | 0.93 |
| FMA-SNOMED | 0.83 | 0.79 | 0.77 | 0.33 | 0.40 | 0.84 |
| NCI-SNOMED | 0.80 | 0.77 | 0.69 | 0.64 | 0.68 | 0.77 |
| HP-MP | 0.84 | 0.85 | 0.47 | 0.47 | 0.68 | 0.85 |
| DOID-ORDO | 0.64 | 0.84 | 0.70 | 0.60 | 0.83 | 0.93 |
| ine Average | 0.83 | 0.84 | 0.73 | 0.61 | 0.72 | 0.87 |
| ine |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, X.; Tsai, P.-W.; Zhuang, Y. Matching Biomedical Ontologies through Adaptive Multi-Modal Multi-Objective Evolutionary Algorithm. Biology 2021, 10, 1287. https://doi.org/10.3390/biology10121287
Xue X, Tsai P-W, Zhuang Y. Matching Biomedical Ontologies through Adaptive Multi-Modal Multi-Objective Evolutionary Algorithm. Biology. 2021; 10(12):1287. https://doi.org/10.3390/biology10121287
Chicago/Turabian StyleXue, Xingsi, Pei-Wei Tsai, and Yucheng Zhuang. 2021. "Matching Biomedical Ontologies through Adaptive Multi-Modal Multi-Objective Evolutionary Algorithm" Biology 10, no. 12: 1287. https://doi.org/10.3390/biology10121287
APA StyleXue, X., Tsai, P. -W., & Zhuang, Y. (2021). Matching Biomedical Ontologies through Adaptive Multi-Modal Multi-Objective Evolutionary Algorithm. Biology, 10(12), 1287. https://doi.org/10.3390/biology10121287