Appendix A
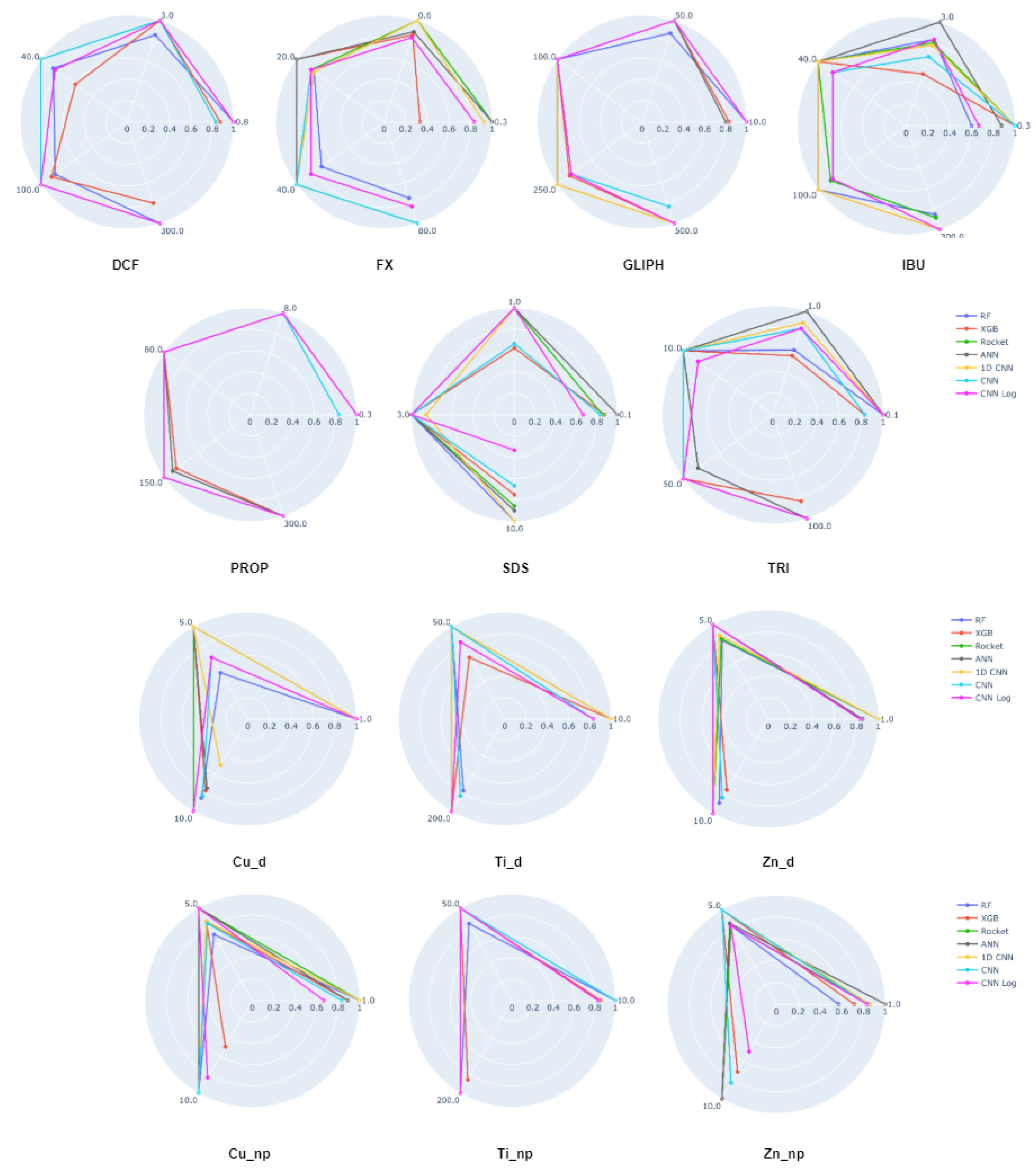
Table A1.
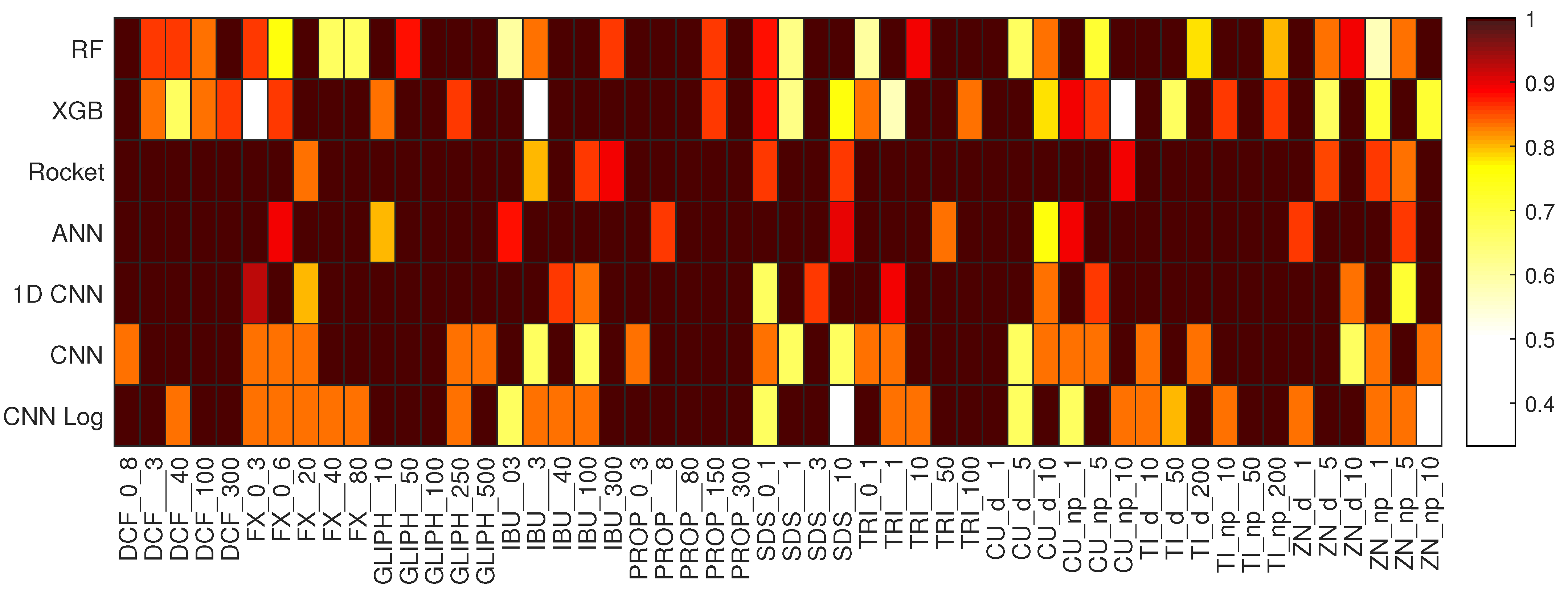
Kruskal–Wallis p-values comparing all methods of the EC prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
Table A1.
Kruskal–Wallis p-values comparing all methods of the EC prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
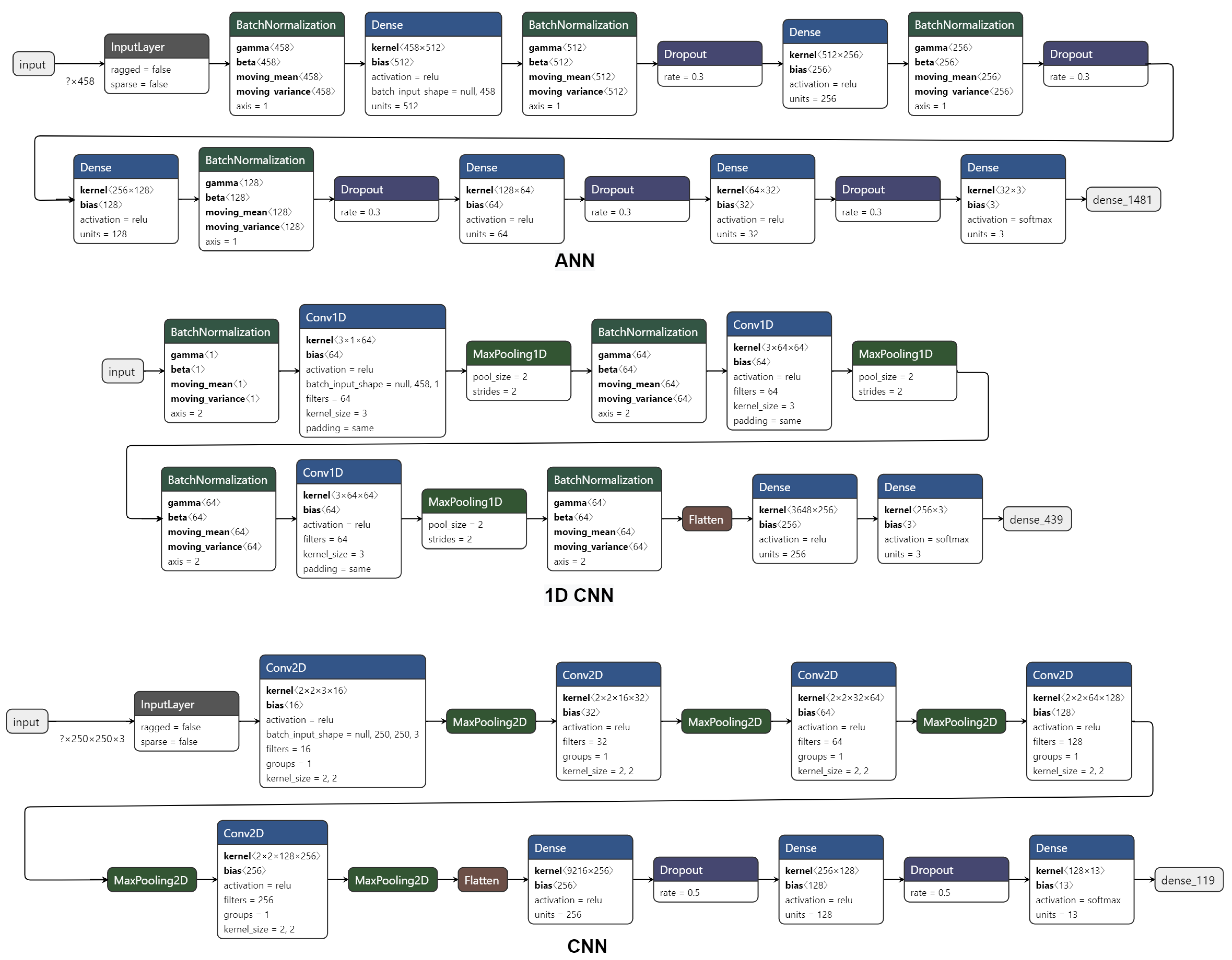
| EC | RF | XG | Rocket | ANN | 1D CNN | CNN | CNN Log | |
|---|
| RF | ――― | | | | | | | Test |
| XG | | ――― | | | | | |
| Rocket | | | ――― | | | | |
| ANN | | | | ――― | | | |
| 1D CNN | | | | | ――― | | |
| CNN | | | | | | ――― | |
| CNN Log | | | | | | | ――― |
| Training |
Table A2.
Kruskal–Wallis p-values comparing all methods of the DCF concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
Table A2.
Kruskal–Wallis p-values comparing all methods of the DCF concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
| EC | RF | XG | Rocket | ANN | 1D CNN | CNN | CNN Log | |
|---|
| RF | ――― | | | | | | | Test |
| XG | | ――― | | | | | |
| Rocket | | | ――― | | | | |
| ANN | | | | ――― | | | |
| 1D CNN | | | | | ――― | | |
| CNN | | | | | | ――― | |
| CNN Log | | | | | | | ――― |
| Training |
Table A3.
Kruskal–Wallis p-values comparing all methods of the FX concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
Table A3.
Kruskal–Wallis p-values comparing all methods of the FX concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
| FX | RF | XG | Rocket | ANN | 1D CNN | CNN | CNN Log | |
|---|
| RF | ――― | | | | | | | Test |
| XG | | ――― | | | | | |
| Rocket | | | ――― | | | | |
| ANN | | | | ――― | | | |
| 1D CNN | | | | | ――― | | |
| CNN | | | | | | ――― | |
| CNN Log | | | | | | | ――― |
| Training |
Table A4.
Kruskal–Wallis p-values comparing all methods of the GLIPH concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
Table A4.
Kruskal–Wallis p-values comparing all methods of the GLIPH concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
| GLIPH | RF | XG | Rocket | ANN | 1D CNN | CNN | CNN Log | |
|---|
| RF | ――― | | | | | | | Test |
| XG | | ――― | | | | | |
| Rocket | | | ――― | | | | |
| ANN | | | | ――― | | | |
| 1D CNN | | | | | ――― | | |
| CNN | | | | | | ――― | |
| CNN Log | | | | | | | ――― |
| Training |
Table A5.
Kruskal–Wallis p-values comparing all methods of the IBU concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
Table A5.
Kruskal–Wallis p-values comparing all methods of the IBU concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
| IBU | RF | XG | Rocket | ANN | 1D CNN | CNN | CNN Log | |
|---|
| RF | ――― | | | | | | | Test |
| XG | | ――― | | | | | |
| Rocket | | | ――― | | | | |
| ANN | | | | ――― | | | |
| 1D CNN | | | | | ――― | | |
| CNN | | | | | | ――― | |
| CNN Log | | | | | | | ――― |
| Training |
Table A6.
Kruskal–Wallis p-values comparing all methods of the PROP concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
Table A6.
Kruskal–Wallis p-values comparing all methods of the PROP concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
| PROP | RF | XG | Rocket | ANN | 1D CNN | CNN | CNN Log | |
|---|
| RF | ――― | | | | | | | Test |
| XG | | ――― | | | | | |
| Rocket | | | ――― | | | | |
| ANN | | | | ――― | | | |
| 1D CNN | | | | | ――― | | |
| CNN | | | | | | ――― | |
| CNN Log | | | | | | | ――― |
| | Training |
Table A7.
Kruskal–Wallis p-values comparing all methods of the SDS concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
Table A7.
Kruskal–Wallis p-values comparing all methods of the SDS concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
| SDS | RF | XG | Rocket | ANN | 1D CNN | CNN | CNN Log | |
|---|
| RF | ――― | | | | | | | Test |
| XG | | ――― | | | | | |
| Rocket | | | ――― | | | | |
| ANN | | | | ――― | | | |
| 1D CNN | | | | | ――― | | |
| CNN | | | | | | ――― | |
| CNN Log | | | | | | | ――― |
| | Training |
Table A8.
Kruskal–Wallis p-values comparing all methods of the TRI concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
Table A8.
Kruskal–Wallis p-values comparing all methods of the TRI concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
| TRI | RF | XG | Rocket | ANN | 1D CNN | CNN | CNN Log | |
|---|
| RF | ――― | | | | | | | Test |
| XG | | ――― | | | | | |
| Rocket | | | ――― | | | | |
| ANN | | | | ――― | | | |
| 1D CNN | | | | | ――― | | |
| CNN | | | | | | ――― | |
| CNN Log | | | | | | | ――― |
| | Training |
Table A9.
Kruskal–Wallis p-values comparing all methods of the Cu_d concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
Table A9.
Kruskal–Wallis p-values comparing all methods of the Cu_d concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
| Cu_d | RF | XG | Rocket | ANN | 1D CNN | CNN | CNN Log | |
|---|
| RF | ――― | | | | | | | Test |
| XG | | ――― | | | | | |
| Rocket | | | ――― | | | | |
| ANN | | | | ――― | | | |
| 1D CNN | | | | | ――― | | |
| CNN | | | | | | ――― | |
| CNN Log | | | | | | | ――― |
| | Training |
Table A10.
Kruskal–Wallis p-values comparing all methods of the Cu_np concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
Table A10.
Kruskal–Wallis p-values comparing all methods of the Cu_np concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
| Cu_np | RF | XG | Rocket | ANN | 1D CNN | CNN | CNN Log | |
|---|
| RF | ――― | | | | | | | Test |
| XG | | ――― | | | | | |
| Rocket | | | ――― | | | | |
| ANN | | | | ――― | | | |
| 1D CNN | | | | | ――― | | |
| CNN | | | | | | ――― | |
| CNN Log | | | | | | | ――― |
| | Training |
Table A11.
Kruskal–Wallis p-values comparing all methods of the Ti_d concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
Table A11.
Kruskal–Wallis p-values comparing all methods of the Ti_d concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
| Ti_d | RF | XG | Rocket | ANN | 1D CNN | CNN | CNN Log | |
|---|
| RF | ――― | | | | | | | Test |
| XG | | ――― | | | | | |
| Rocket | | | ――― | | | | |
| ANN | | | | ――― | | | |
| 1D CNN | | | | | ――― | | |
| CNN | | | | | | ――― | |
| CNN Log | | | | | | | ――― |
| | Training |
Table A12.
Kruskal–Wallis p-values comparing all methods of the Ti_np concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
Table A12.
Kruskal–Wallis p-values comparing all methods of the Ti_np concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
| Ti_np | RF | XG | Rocket | ANN | 1D CNN | CNN | CNN Log | |
|---|
| RF | ――― | | | | | | | Test |
| XG | | ――― | | | | | |
| Rocket | | | ――― | | | | |
| ANN | | | | ――― | | | |
| 1D CNN | | | | | ――― | | |
| CNN | | | | | | ――― | |
| CNN Log | | | | | | | ――― |
| | Training |
Table A13.
Kruskal–Wallis p-values comparing all methods of the Zn_d concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
Table A13.
Kruskal–Wallis p-values comparing all methods of the Zn_d concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
| Zn_d | RF | XG | Rocket | ANN | 1D CNN | CNN | CNN Log | |
|---|
| RF | ――― | | | | | | | Test |
| XG | | ――― | | | | | |
| Rocket | | | ――― | | | | |
| ANN | | | | ――― | | | |
| 1D CNN | | | | | ――― | | |
| CNN | | | | | | ――― | |
| CNN Log | | | | | | | ――― |
| Training |
Table A14.
Kruskal–Wallis p-values comparing all methods of the zn_np concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
Table A14.
Kruskal–Wallis p-values comparing all methods of the zn_np concentration prediction task. Above the diagonal, we have the results for the test set, and below for the training set. Significant results () are represented in green or red when the method on the left is significantly better or worse, respectively.
| Zn_np | RF | XG | Rocket | ANN | 1D CNN | CNN | CNN Log | |
|---|
| RF | ――― | | | | | | | Test |
| XG | | ――― | | | | | |
| Rocket | | | ――― | | | | |
| ANN | | | | ――― | | | |
| 1D CNN | | | | | ――― | | |
| CNN | | | | | | ――― | |
| CNN Log | | | | | | | ――― |
| | Training |


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






