
Multi-Feature Fusion Based Deepfake Face Forgery Video Detection



Abstract
:1. Introduction
2. Related Works
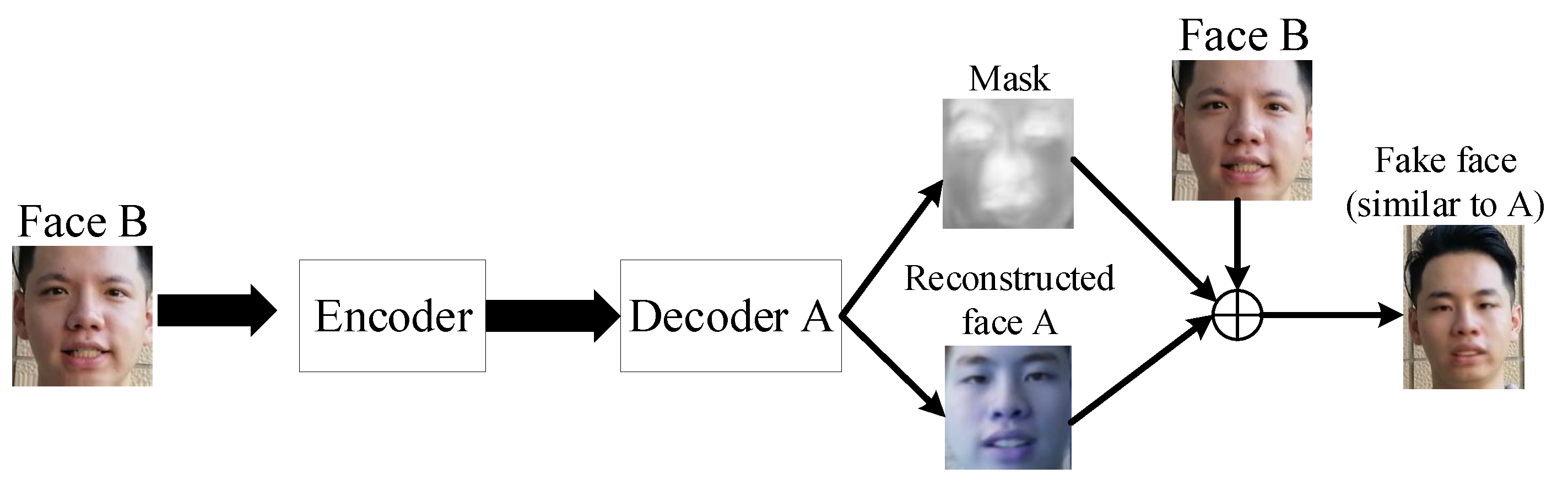
2.1. Generation Method of Deep Forged Face Video
2.2. Deep Forged Face Video Database
2.3. Deep Forgery Face Video Detection Method
3. Multi-Feature Fusion Based Deep Forgery Face Video Detection Method
3.1. Detection Framework
3.2. Data Pre-Processing
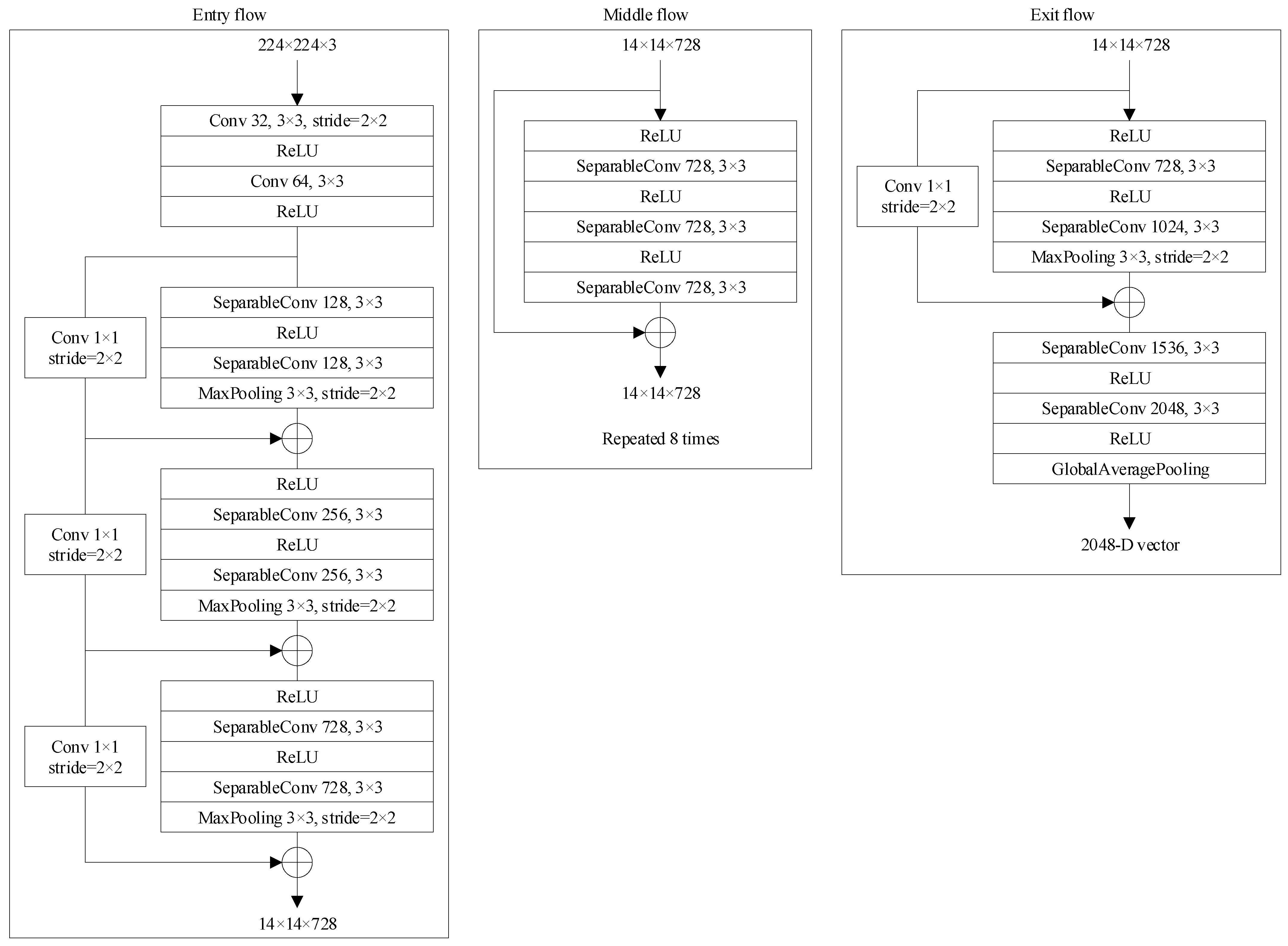
3.3. Xception Feature Extraction Network
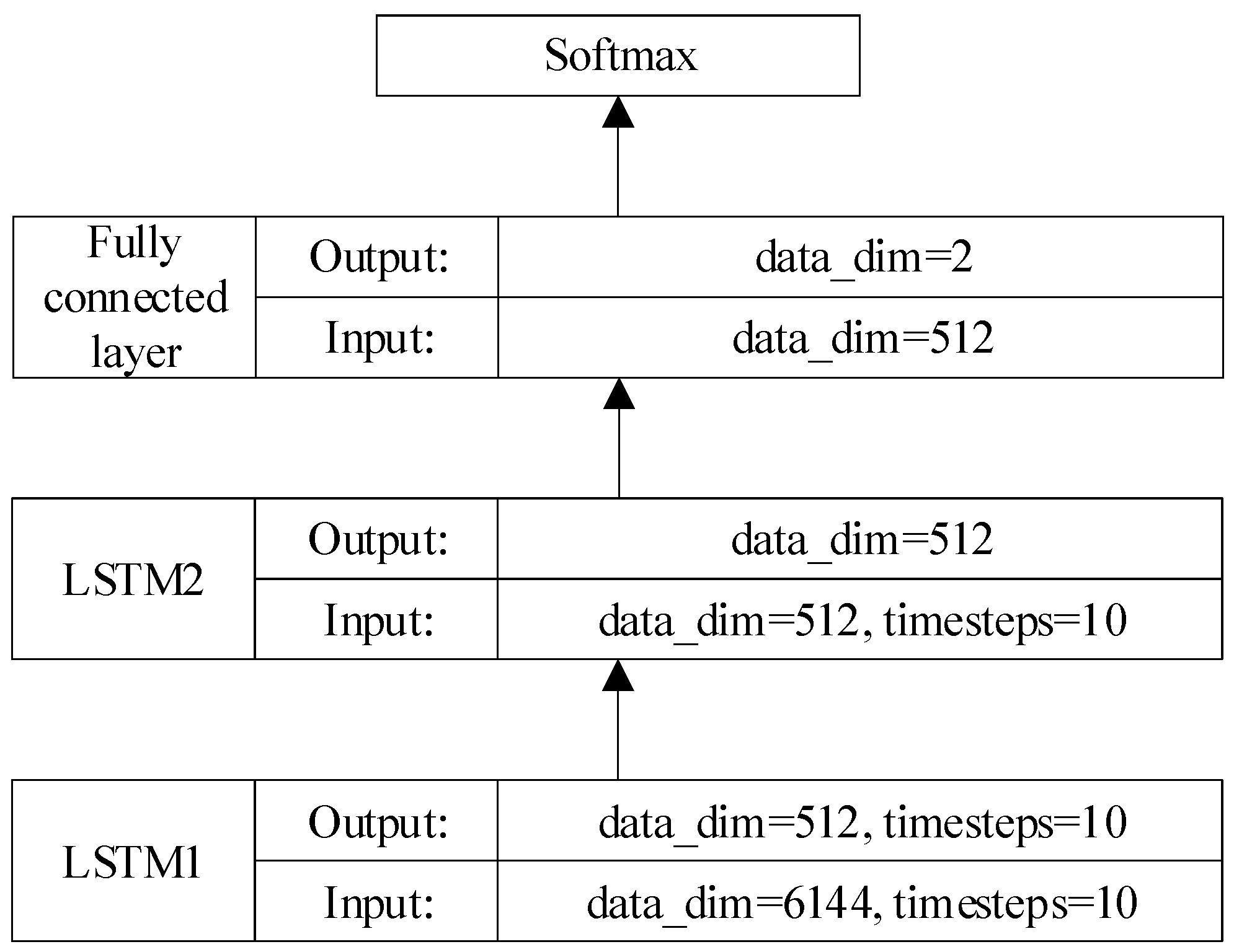
3.4. Double-Layer LSTM Time Domain Feature Extraction Network
4. Experimental Results and Analysis
4.1. Introduction of Experimental Database
4.2. Experimental Settings
4.3. Ablation Experiment
4.4. Comparing with Other Algorithms
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Marcolin, F.; Vezzetti, E.; Monaci, M.G. Face perception foundations for pattern recognition algorithms. Neurocomputing 2021, 443, 302–319. [Google Scholar] [CrossRef]
- Payal, P.; Goyani, M.M. A comprehensive study on face recognition: Methods and challenges. Imaging Sci. J. 2020, 68, 114–127. [Google Scholar] [CrossRef]
- Ulrich, L.; Vezzetti, E.; Moos, S.; Marcolin, F. Analysis of RGB-D camera technologies for supporting different facial usage scenarios. Multimed. Tools Appl. 2020, 79, 29375–29398. [Google Scholar] [CrossRef]
- Keck, M.; Davis, J.W. Recovery and reasoning about occlusions in 3D using few cameras with applications to 3D tracking. Int. J. Comput. Vis. 2011, 95, 240–264. [Google Scholar] [CrossRef] [Green Version]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. Deepfakes and beyond: A survey of face manipulation and fake detection. Inf. Fusion 2020, 64, 131–148. [Google Scholar] [CrossRef]
- Katarya, R.; Lal, A. A Study on Combating Emerging Threat of Deepfake Weaponization. In Proceedings of the 2020 Fourth International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 7–9 October 2020; pp. 485–490. [Google Scholar]
- FaceSwap. Available online: https://github.com/MarekKowalski/FaceSwap (accessed on 30 January 2022).
- faceswap. Available online: https://github.com/deepfakes/faceswap (accessed on 30 January 2022).
- Korshunov, P.; Marcel, S. Vulnerability assessment and detection of deepfake videos. In Proceedings of the 2019 International Conference on Biometrics (ICB), Crete, Greece, 4–7 June 2019; pp. 1–6. [Google Scholar]
- Khodabakhsh, A.; Ramachandra, R.; Raja, K.; Wasnik, P.; Busch, C. Fake face detection methods: Can they be generalized? In Proceedings of the 2018 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 26–28 September 2018; pp. 1–6. [Google Scholar]
- Rössler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. FaceForensics++: Learning to detect manipulated facial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1–11. [Google Scholar]
- Contributing Data to Deepfake Detection Research. Available online: https://ai.googleblog.com/2019/09/contributing-data-to-deepfake-detection.html (accessed on 30 January 2022).
- Zhang, Y.; Zheng, L.; Thing, V.L.L. Automated face swapping and its detection. In Proceedings of the 2017 IEEE 2nd International Conference on Signal and Image Processing (ICSIP), Singapore, 4–6 August 2017; pp. 15–19. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8261–8265. [Google Scholar]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face manipulations. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 83–92. [Google Scholar]
- Koopman, M.; Rodriguez, A.M.; Geradts, Z. Detection of deepfake video manipulation. In Proceedings of the 20th Irish Machine Vision and Image Processing Conference (IMVIP), Belfast, Ireland, 29–31 August 2018; pp. 133–136. [Google Scholar]
- Frank, J.; Eisenhofer, T.; Schönherr, L.; Fischer, A.; Kolossa, D.; Holz, T. Leveraging Frequency Analysis for Deep Fake Image Recognition. arXiv 2020, arXiv:2003.08685. [Google Scholar]
- Habeeba, M.A.S.; Lijiya, A.; Chacko, A.M. Detection of Deepfakes Using Visual Artifacts and Neural Network Classifier. In Innovations in Electrical and Electronic Engineering; Springer: Singapore, 2021; pp. 411–422. [Google Scholar]
- Zhou, P.; Han, X.; Morariu, V.I.; Davis, L.S. Two-stream neural networks for tampered face detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1831–1839. [Google Scholar]
- Yu, C.M.; Chang, C.T.; Ti, Y.W. Detecting Deepfake-forged contents with separable convolutional neural network and image segmentation. arXiv 2019, arXiv:1912.12184. [Google Scholar]
- Li, X.; Yu, K.; Ji, S.; Wang, Y.; Wu, C.; Xue, H. Fighting against deepfake: Patch and pair convolutional neural networks (PPCNN). In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 88–89. [Google Scholar]
- Dolhansky, B.; Howes, R.; Pflaum, B.; Baram, N.; Ferrer, C.C. The deepfake detection challenge (dfdc) preview dataset. arXiv 2019, arXiv:1910.08854. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: A compact facial video forgery detection network. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; pp. 1–7. [Google Scholar]
- Bayar, B.; Stamm, M.C. Constrained convolutional neural networks: A new approach towards general purpose image manipulation detection. Trans. Inf. Forensics Secur. 2018, 13, 2691–2706. [Google Scholar] [CrossRef]
- Tariq, S.; Lee, S.; Kim, H.; Shin, Y.; Woo, S.S. Detecting both machine and human created fake face images in the wild. In Proceedings of the 2nd International Workshop on Multimedia Privacy and Security, Toronto, ON, Canada, 15 October 2018; pp. 81–87. [Google Scholar]
- Li, X.; Lang, Y.; Chen, Y.; Mao, X.; He, Y.; Wang, S.; Xue, H.; Lu, Q. Sharp Multiple Instance Learning for DeepFake Video Detection. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1864–1872. [Google Scholar]
- Dang, H.; Liu, F.; Stehouwer, J.; Liu, X.; Jain, A.K. On the detection of digital face manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5781–5790. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Data Set | DFD (C23) | |||
|---|---|---|---|---|
| Test Data Set | DFD (C23) | FF++ (C0) | FF++ (C0) | TIMIT |
| Only spatial | 4.68 | 17.69 | 22.87 | 20.18 |
| Only frequency | 10.47 | 24.17 | 27.88 | 27.05 |
| Only PLGF | 6.85 | 19.26 | 24.69 | 22.19 |
| Without LSTM | 3.57 | 16.18 | 21.17 | 17.69 |
| Complete method | 2.91 | 14.17 | 18.32 | 15.34 |
| Training Data Set | DFD (C23) | |||
|---|---|---|---|---|
| Test Data Set | DFD (C23) | FF++ (C0) | FF++ (C23) | TIMIT |
| MesoInception [25] | 7.26 | 21.54 | 25.76 | 35.88 |
| MISLnet [26] | 3.26 | 5.75 | 16.21 | 18.73 |
| ShallowNet [27] | 5.84 | 19.34 | 21.44 | 27.45 |
| Xception [23] | 4.38 | 18.84 | 22.31 | 20.60 |
| S-MIL-Vb [28] | 3.66 | 22.51 | 21.88 | 30.56 |
| S-MIL-Fb [28] | 6.29 | 25.39 | 26.34 | 34.43 |
| FFD-Vgg-16 [29] | 3.22 | 19.63 | 24.19 | 34.86 |
| Proposed algorithm | 2.91 | 14.17 | 18.32 | 15.34 |
| Training Data Set | F++ (C0 and C23) | |||
|---|---|---|---|---|
| Test Data Set | DFD (C23) | FF++ (C0) | FF++ (C23) | TIMIT |
| MesoInception [25] | 3.08 | 8.14 | 28.11 | 22.29 |
| MISLnet [26] | 0.72 | 1.98 | 25.06 | 24.26 |
| ShallowNet [27] | 1.76 | 4.37 | 28.27 | 25.55 |
| Xception [23] | 0.95 | 1.88 | 26.61 | 21.46 |
| S-MIL-Vb [28] | 1.09 | 2.58 | 17.23 | 13.14 |
| S-MIL-Fb [28] | 2.85 | 4.03 | 12.75 | 33.84 |
| FFD-Vgg-16 [29] | 1.25 | 2.77 | 27.48 | 28.97 |
| Proposed algorithm | 1.24 | 2.25 | 24.34 | 25.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lai, Z.; Wang, Y.; Feng, R.; Hu, X.; Xu, H. Multi-Feature Fusion Based Deepfake Face Forgery Video Detection. Systems 2022, 10, 31. https://doi.org/10.3390/systems10020031
Lai Z, Wang Y, Feng R, Hu X, Xu H. Multi-Feature Fusion Based Deepfake Face Forgery Video Detection. Systems. 2022; 10(2):31. https://doi.org/10.3390/systems10020031
Chicago/Turabian StyleLai, Zhimao, Yufei Wang, Renhai Feng, Xianglei Hu, and Haifeng Xu. 2022. "Multi-Feature Fusion Based Deepfake Face Forgery Video Detection" Systems 10, no. 2: 31. https://doi.org/10.3390/systems10020031
APA StyleLai, Z., Wang, Y., Feng, R., Hu, X., & Xu, H. (2022). Multi-Feature Fusion Based Deepfake Face Forgery Video Detection. Systems, 10(2), 31. https://doi.org/10.3390/systems10020031