
Machine Reading at Scale: A Search Engine for Scientific and Academic Research



Abstract
:1. Introduction
2. Related Work
3. Proposed Solution
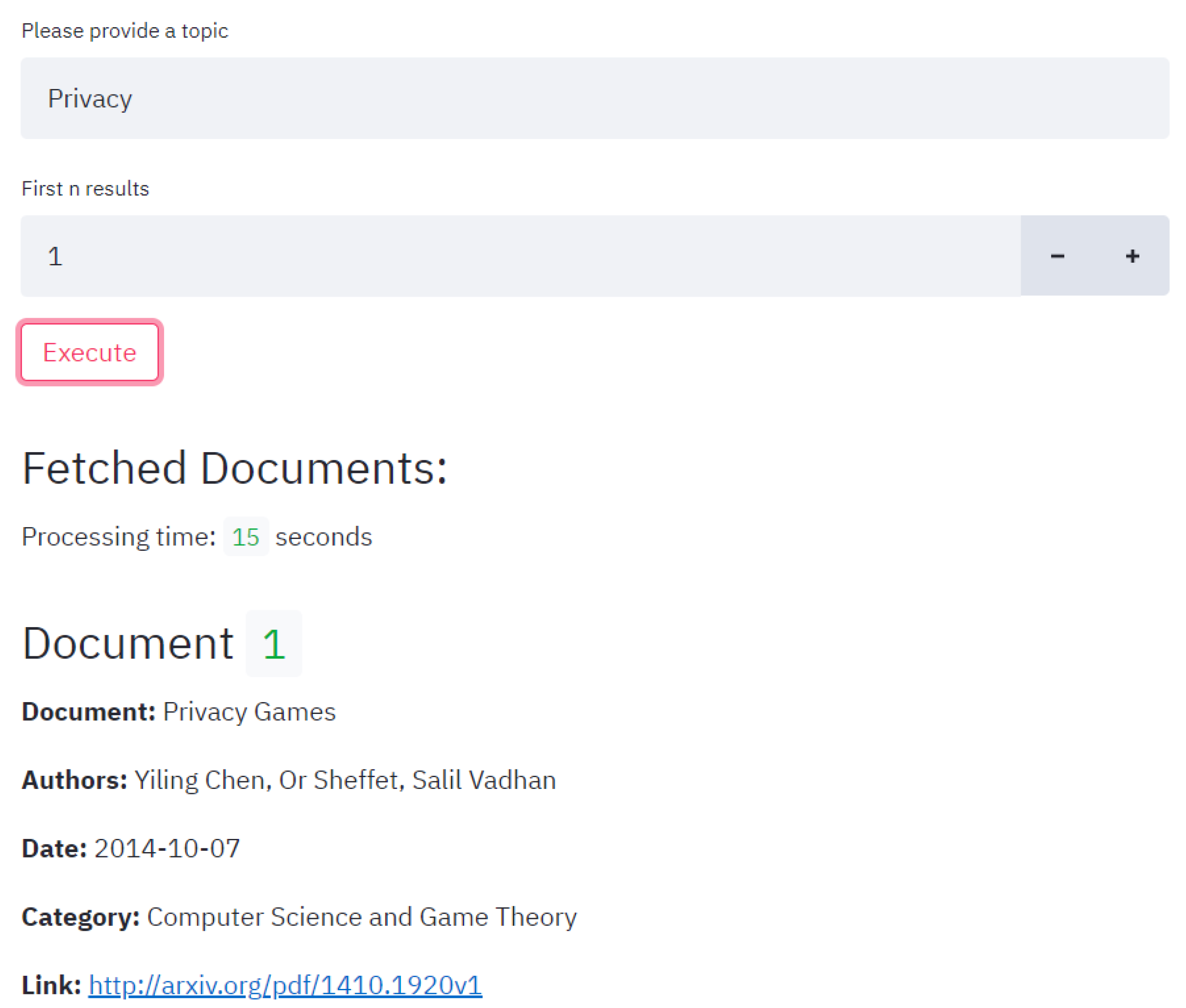
- UC1—Fetching Scientific Publications: This use case is further divided into more fine-grained sub-tasks such as downloading publications from a given source (in this case arXiv.org), preprocessing each document and indexing the resultant data into the document store. The user starts by specifying a given search topic and the maximum number of articles to be downloaded. Then, the crawler tries to find articles related to the specified topic and downloads all of them until the maximum threshold is reached. If the number of articles is inferior to the specified threshold, all articles related to the specified subject are downloaded. After downloading the documents, these are preprocessed—empty lines are removed, consecutive whitespaces are truncated and pdf headers and footers are discarded. The text of each document is also split into several search chunks of 500 words with respect to sentence continuity, so that the search process can be optimal. Finally, each resulting chunk is indexed, along with the document meta-data, in the document database, increasing the knowledge base of the Q & A system. Chunks of the document database that share the same foreign key can be traced back to the original unsplit document that was downloaded and preprocessed.
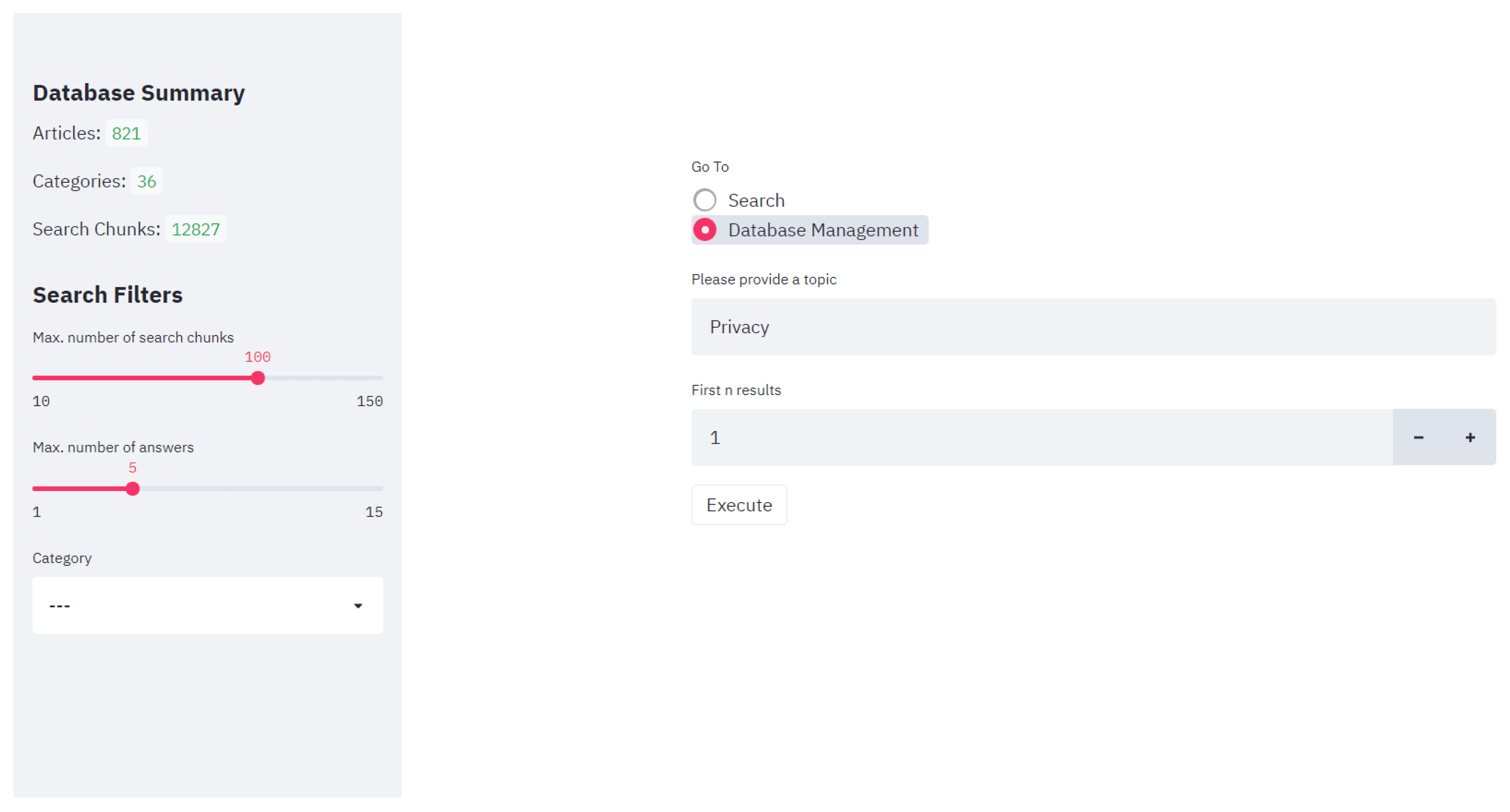
- UC2—Consulting Database Summary: So that the user can keep track of the continuous changes to the available corpus, a summary of the document database content is displayed in the main dashboard of the graphical interface. This summary is comprised of several pieces of information, such as the number of downloaded articles, search chunks and document categories.
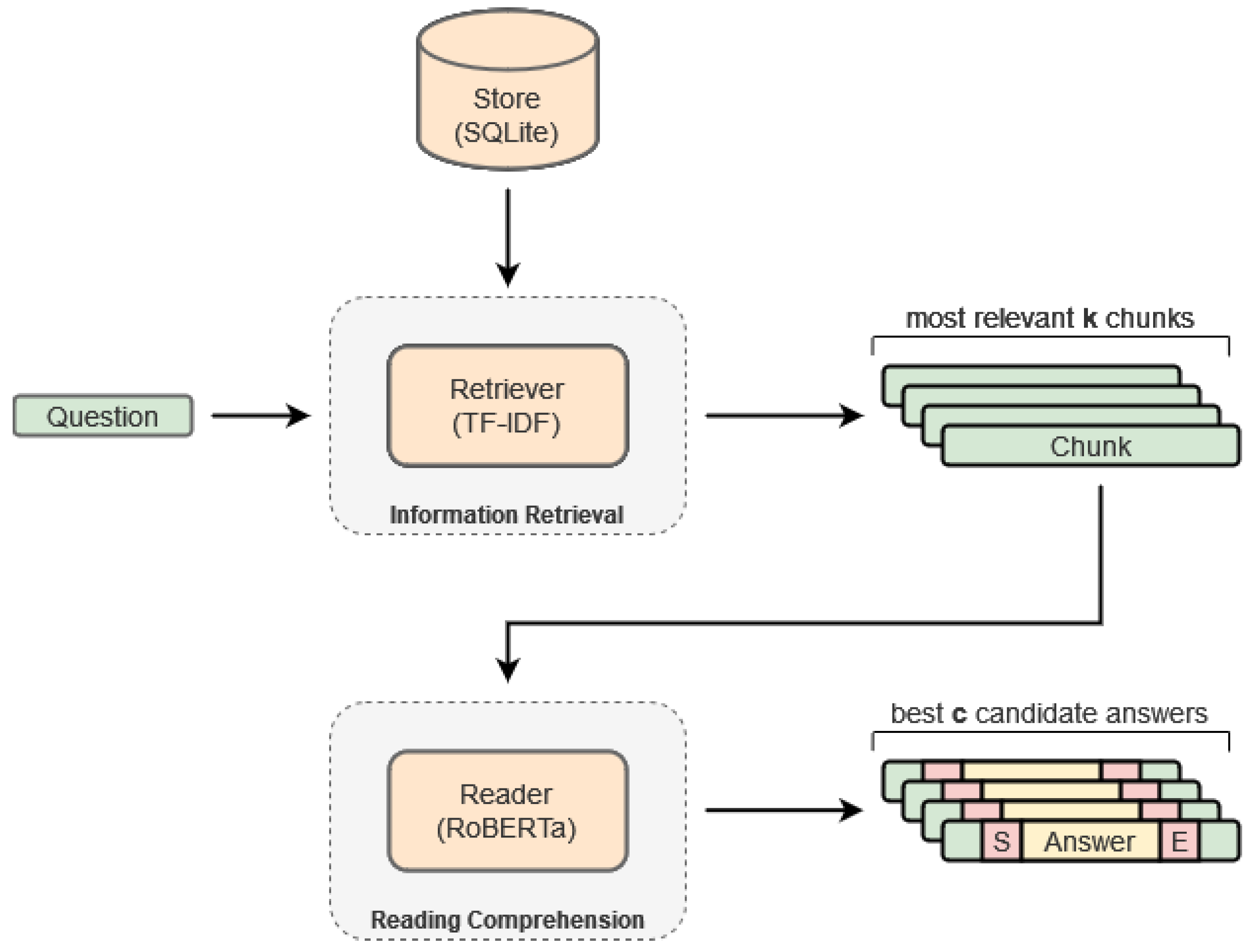
- UC3—Finding Candidate Answers: This use case is arguably the most important one as it focuses on the answer-finding process by means of intelligent algorithms. The proposed search pipeline works by considering two different components, a retriever and a reader. First, the user poses a question to the system and specifies several search parameters such as a category filter, the number of candidate answers to be displayed, c, and the maximum number of relevant search chunks to be found by the retriever, k. Then, the system executes the retriever, a TF-IDF-based retriever, returning the most relevant k chunks. Finally, the reader, a RoBERTa model, will try to find the best c answers in the selected k chunks according to a confidence metric.
3.1. Pipeline Description
3.1.1. Retriever
3.1.2. Reader
4. Case Study
4.1. Results
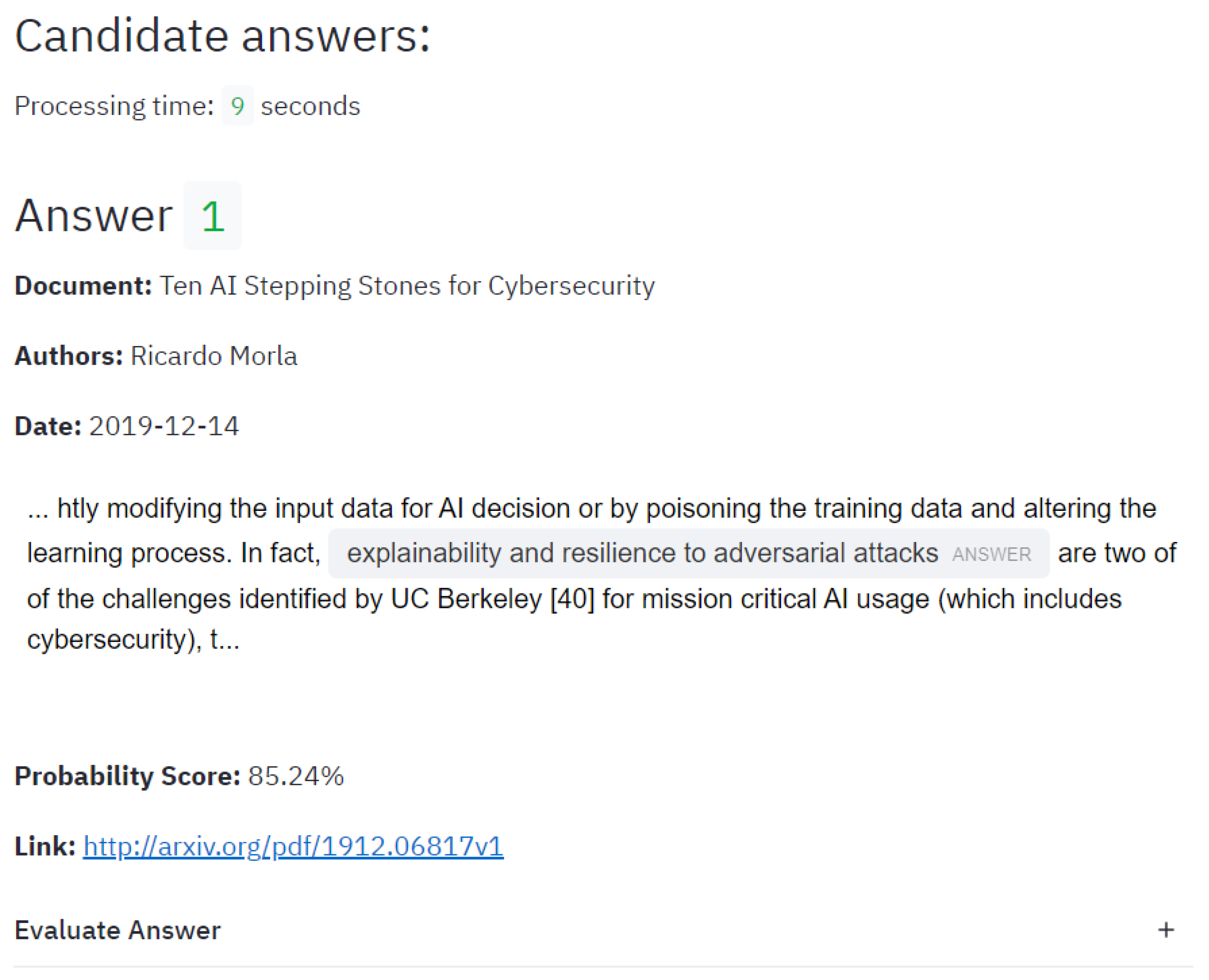
4.1.1. Cybersecurity
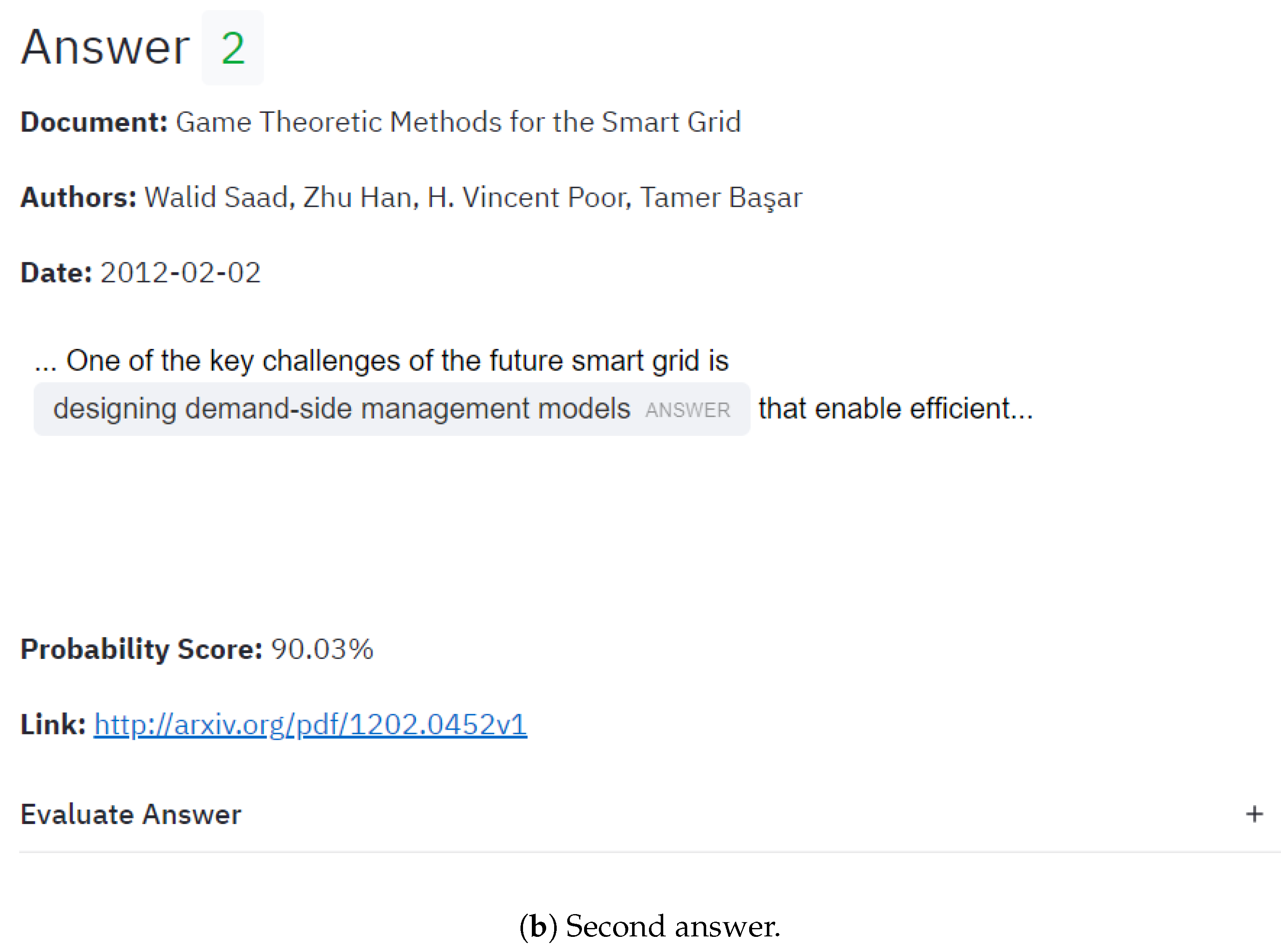
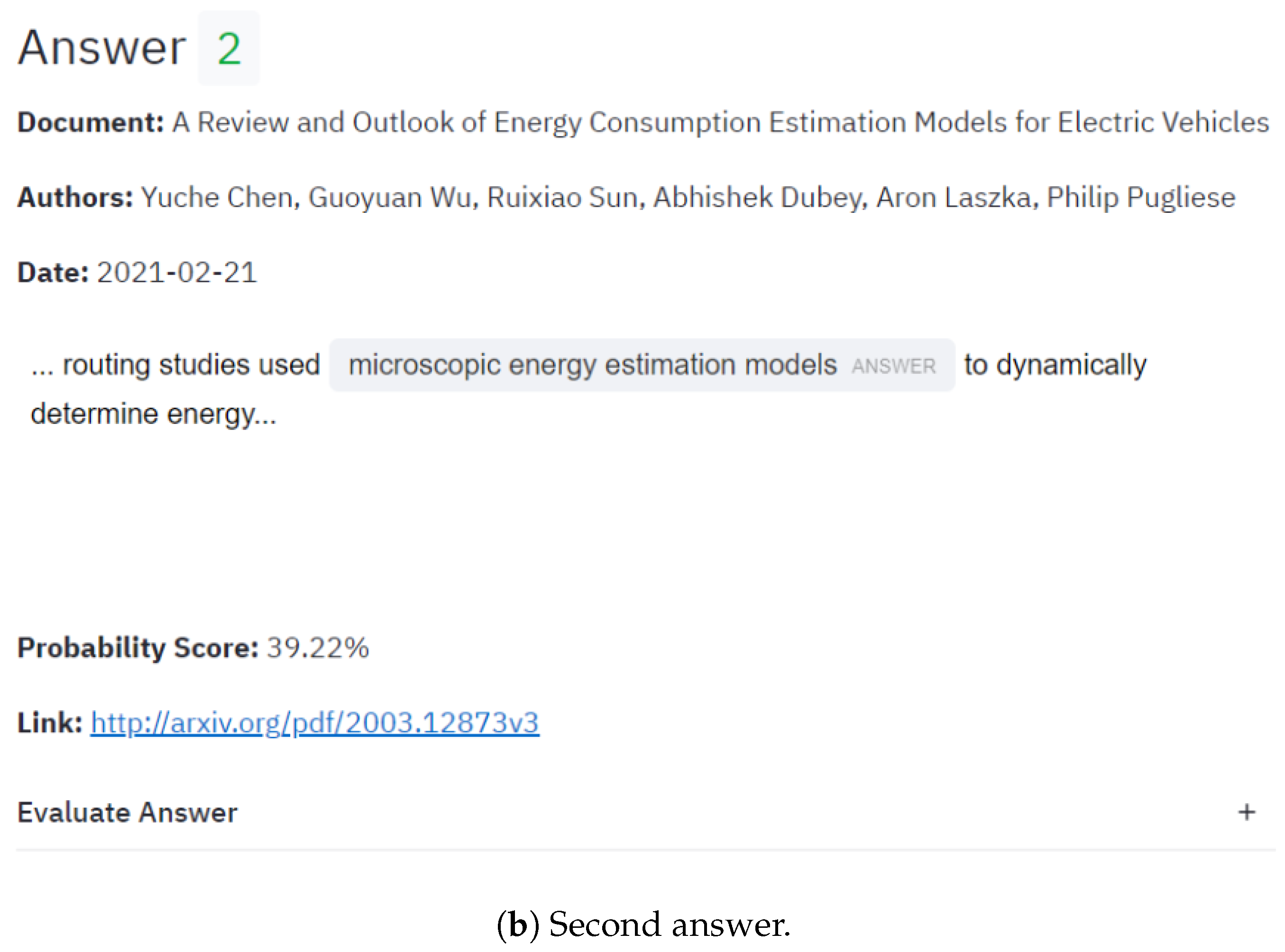
4.1.2. Energy
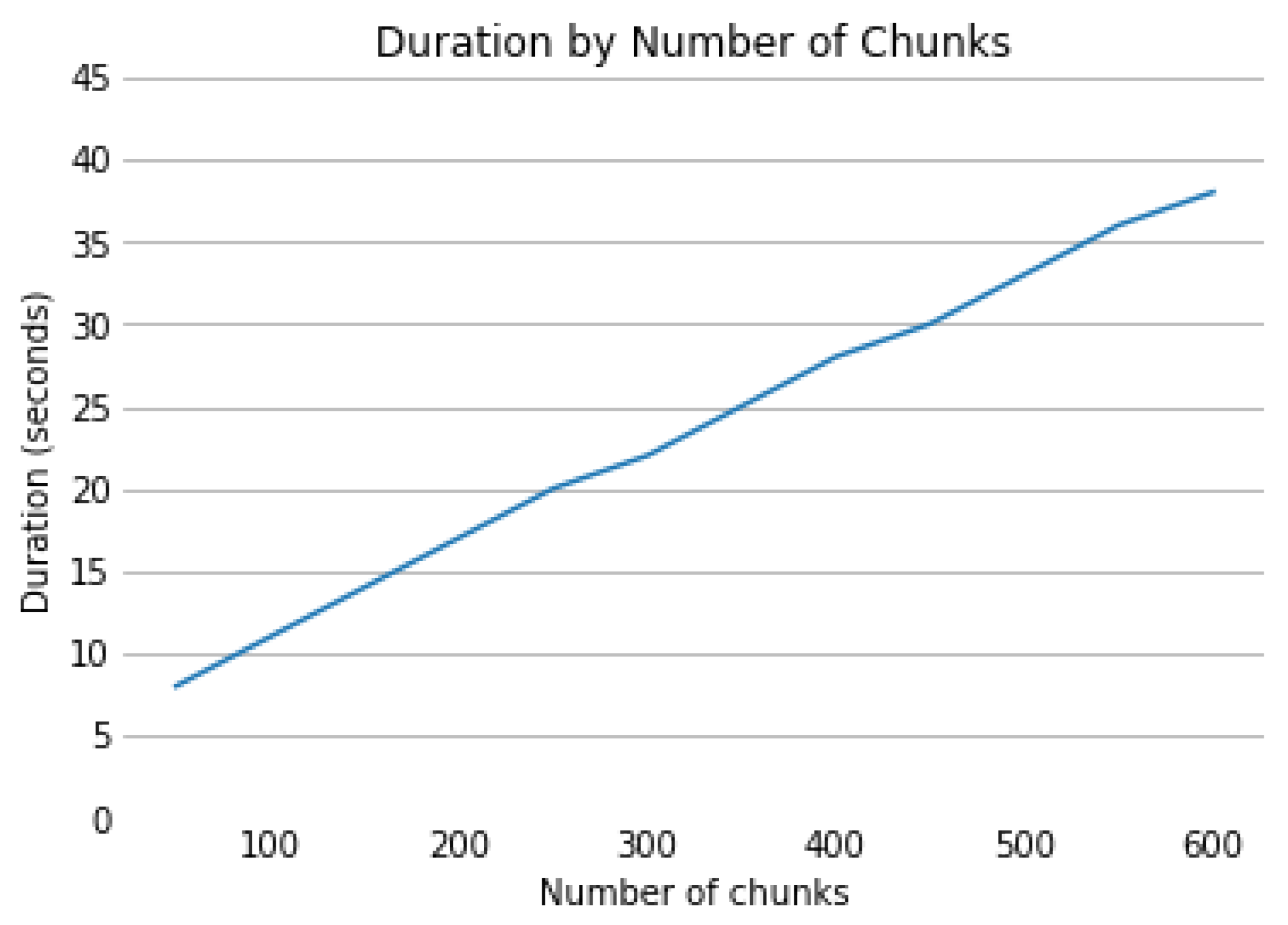
4.1.3. Complexity
4.1.4. Conclusions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, W.; Zhao, X.; Zhao, L.; Yin, D.; Yang, G.H.; Beutel, A. Deep Reinforcement Learning for Information Retrieval: Fundamentals and Advances. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 2468–2471. [Google Scholar]
- Klapp, O.E. Overload and Boredom: Essays on the Quality of Life in the Information Society; Greenwood Publishing Group Inc.: Westport, CT, USA, 1986. [Google Scholar]
- Saxena, D.; Lamest, M. Information overload and coping strategies in the big data context: Evidence from the hospitality sector. J. Inf. Sci. 2018, 44, 287–297. [Google Scholar] [CrossRef]
- Huang, J.T.; Sharma, A.; Sun, S.; Xia, L.; Zhang, D.; Pronin, P.; Padmanabhan, J.; Ottaviano, G.; Yang, L. Embedding-Based Retrieval in Facebook Search. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 2553–2561. [Google Scholar]
- Li, H.; Xu, J. Semantic Matching in Search. Found. Trends Inf. Retr. 2014, 7, 343–469. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, N.; Sousa, N.; Praça, I. A Search Engine for Scientific Publications: A Cybersecurity Case Study. In Proceedings of the International Symposium on Distributed Computing and Artificial Intelligence, Salamanca, Spain, 6–8 October 2021; pp. 108–118. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; Association for Computational Linguistics: Austin, TX, USA, 2016; pp. 2383–2392. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Chan, B.; Möller, T.; Pietsch, M.; Soni, T. Deepset Roberta-Base-Squad2. Available online: https://huggingface.co/deepset/roberta-base-squad2 (accessed on 6 May 2021).
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, U.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Aggarwal, C.C.; Zhai, C. A Survey of Text Classification Algorithms. In Mining Text Data; Springer US: Boston, MA, USA, 2012; pp. 163–222. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Mishra, S.; Brynjolfsson, E.; Etchemendy, J.; Ganguli, D.; Grosz, B.J.; Lyons, T.; Manyika, J.; Niebles, J.C.; Sellitto, M.; et al. The AI Index 2021 Annual Report. arXiv 2021, arXiv:2103.06312. [Google Scholar]
- Bevendorff, J.; Stein, B.; Hagen, M.; Potthast, M. Elastic ChatNoir: Search Engine for the ClueWeb and the Common Crawl. In Proceedings of the European Conference on Information Retrieval (ECIR), Grenoble, France, 26–29 March 2018. [Google Scholar]
- Semantic Scholar. 2022. Available online: https://www.semanticscholar.org/ (accessed on 23 March 2022).
- Singh, A.K.; Kumar, P.R. A comparative study of page ranking algorithms for information retrieval. Int. J. Electr. Comput. Eng. 2009, 4, 469–480. [Google Scholar]
- Nimmani, P.; Vodithala, S.; Polepally, V. Neural Network Based Integrated Model for Information Retrieval. In Proceedings of the 2021 5th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 6–8 May 2021; pp. 1286–1289. [Google Scholar] [CrossRef]
- Yoon, S.; Dernoncourt, F.; Kim, D.S.; Bui, T.; Jung, K. A Compare-Aggregate Model with Latent Clustering for Answer Selection. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM’19), Beijing, China, 3–7 November 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 2093–2096. [Google Scholar] [CrossRef] [Green Version]
- Shtekh, G.; Kazakova, P.; Nikitinsky, N.; Skachkov, N. Applying Topic Segmentation to Document-Level Information Retrieval. In Proceedings of the 14th Central and Eastern European Software Engineering Conference Russia (CEE-SECR’18), Moscow, Russia, 12–13 October 2018; Association for Computing Machinery: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Du, L.; Buntine, W.; Johnson, M. Topic segmentation with a structured topic model. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 190–200. [Google Scholar]
- Alkılınç, A.; Arslan, A. A Comparison of Recent Information Retrieval Term-Weighting Models Using Ancient Datasets. In Proceedings of the 2018 International Conference on Artificial Intelligence and Data Processing (IDAP), Malatya, Turkey, 28–30 September 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Sanderson, M. Test Collection Based Evaluation of Information Retrieval Systems; Now Publishers Inc.: Hanover, MA, USA, 2010. [Google Scholar]
- Petersen, C.; Simonsen, J.G.; Järvelin, K.; Lioma, C. Adaptive Distributional Extensions to DFR Ranking. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management (CIKM’16), Indianapolis, IN, USA, 24–28 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 2005–2008. [Google Scholar] [CrossRef] [Green Version]
- Priyadarsini Panda, S.; Prasad Mohanty, J. A Domain Classification-based Information Retrieval System. In Proceedings of the 2020 IEEE International Women in Engineering (WIE) Conference on Electrical and Computer Engineering (WIECON-ECE), Bhubaneswar, India, 26–27 December 2020; pp. 122–125. [Google Scholar] [CrossRef]
- Hayat, S.; Li, Y.; Riaz, M. Automatic Recovery of Broken Links Using Information Retrieval Techniques. In Proceedings of the 2nd International Conference on Natural Language Processing and Information Retrieval (NLPIR 2018), Bangkok, Thailand, 7–9 September 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 32–36. [Google Scholar] [CrossRef]
- Manzoor, A.; Jannach, D. Generation-Based vs Retrieval-Based Conversational Recommendation: A User-Centric Comparison. In Proceedings of the Fifteenth ACM Conference on Recommender Systems, Amsterdam, The Netherlands, 27 September–1 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 515–520. [Google Scholar]
- Qaiser, S.; Ali, R. Text mining: Use of TF-IDF to examine the relevance of words to documents. Int. J. Comput. Appl. 2018, 181, 25–29. [Google Scholar] [CrossRef]
- Beel, J.; Gipp, B.; Langer, S.; Breitinger, C. Research-paper recommender systems: A literature survey. Int. J. Digit. Libr. 2016, 17, 305–338. [Google Scholar] [CrossRef] [Green Version]
- Neto, J.L.; Santos, A.D.; Kaestner, C.A.; Freitas, A.A. Document Clustering and Text Summarization. In Proceedings of the Fourth International Conference on the Practical Application of Knowledge Discovery and Data Mining, New York, NY, USA, 27–31 August 1998; Mackin, N., Ed.; The Practical Application Company: Woburn, MA, USA, 2000; pp. 41–55. [Google Scholar]
- Ge, L.; Moh, T. Improving text classification with word embedding. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 1796–1805. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar]
- Karpukhin, V.; Oğuz, B.; Min, S.; Wu, L.; Edunov, S.; Chen, D.; Yih, W.T. Dense passage retrieval for open-domain question answering. arXiv 2020, arXiv:2004.04906. [Google Scholar]
- Lee, K.; Chang, M.W.; Toutanova, K. Latent retrieval for weakly supervised open domain question answering. arXiv 2019, arXiv:1906.00300. [Google Scholar]
- Kwiatkowski, T.; Palomaki, J.; Redfield, O.; Collins, M.; Parikh, A.; Alberti, C.; Epstein, D.; Polosukhin, I.; Devlin, J.; Lee, K.; et al. Natural questions: A benchmark for question answering research. Trans. Assoc. Comput. Linguist. 2019, 7, 453–466. [Google Scholar] [CrossRef]
- Zhou, X. A Study of Machine Reading Comprehension Based on Attention Mechanism. In Proceedings of the 2021 6th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, 9–11 April 2021; pp. 1058–1061. [Google Scholar] [CrossRef]
- Shan, J.; Nishihara, Y.; Maeda, A.; Yamanishi, R. Extraction of Question-related Sentences for Reading Comprehension Tests via Attention Mechanism. In Proceedings of the 2020 International Conference on Technologies and Applications of Artificial Intelligence (TAAI), Taipei, Taiwan, 3–5 December 2020; pp. 23–28. [Google Scholar] [CrossRef]
- Matsuyoshi, Y.; Takiguchi, T.; Ariki, Y. User’s Intention Understanding in Question-Answering System Using Attention-based LSTM. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; pp. 1752–1755. [Google Scholar] [CrossRef]
- Cai, J.; Zhu, Z.; Nie, P.; Liu, Q. A Pairwise Probe for Understanding BERT Fine-Tuning on Machine Reading Comprehension. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’20), Xi’an, China, 25–30 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1665–1668. [Google Scholar] [CrossRef]
- Xu, Y.; Zhong, X.; Yepes, A.J.J.; Lau, J.H. Forget Me Not: Reducing Catastrophic Forgetting for Domain Adaptation in Reading Comprehension. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Hu, S.; Zou, L.; Yu, J.X.; Wang, H.; Zhao, D. Answering Natural Language Questions by Subgraph Matching over Knowledge Graphs (Extended Abstract). In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; pp. 1815–1816. [Google Scholar] [CrossRef]
- Nishida, K.; Saito, I.; Otsuka, A.; Asano, H.; Tomita, J. Retrieve-and-Read: Multi-Task Learning of Information Retrieval and Reading Comprehension. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management (CIKM’18), Turin, Italy, 22–26 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 647–656. [Google Scholar] [CrossRef] [Green Version]
- Seo, M.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bidirectional attention flow for machine comprehension. arXiv 2016, arXiv:1611.01603. [Google Scholar]
- Chen, D.; Fisch, A.; Weston, J.; Bordes, A. Reading Wikipedia to Answer Open-Domain Questions. arXiv 2017, arXiv:1704.00051. [Google Scholar]
- Haystack. 2020. Available online: https://haystack.deepset.ai/ (accessed on 6 May 2021).
- Cambazoglu, B.B.; Sanderson, M.; Scholer, F.; Croft, B. A review of public datasets in question answering research. In ACM SIGIR Forum; ACM: New York, NY, USA, 2021; Volume 54, pp. 1–23. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Jiao, X.; Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Li, L.; Wang, F.; Liu, Q. Tinybert: Distilling bert for natural language understanding. arXiv 2019, arXiv:1909.10351. [Google Scholar]
- Chan, B.; Möller, T.; Pietsch, M.; Soni, T.; Bartels, M. Deepset Tinyroberta-Squad2. Available online: https://huggingface.co/deepset/tinyroberta-squad2 (accessed on 25 March 2022).
- Möller, T.; Risch, J.; Pietsch, M.; Bartels, M. Deepset Tinybert-6L-768D-Squad2. Available online: https://huggingface.co/deepset/tinybert-6l-768d-squad2 (accessed on 25 March 2022).
- Möller, T.; Risch, J.; Pietsch, M.; Bartels, M. Deepset Bert-Medium-Squad2-Distilled. Available online: https://huggingface.co/deepset/bert-medium-squad2-distilled (accessed on 25 March 2022).
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Morla, R. Ten AI Stepping Stones for Cybersecurity. arXiv 2019, arXiv:1912.06817. [Google Scholar]
- Kayan, H.; Nunes, M.; Rana, O.; Burnap, P.; Perera, C. Cybersecurity of Industrial Cyber-Physical Systems: A Review. arXiv 2021, arXiv:2101.03564. [Google Scholar] [CrossRef]
- Gardner, C.; Waliga, A.; Thaw, D.; Churchman, S. Using Camouflaged Cyber Simulations as a Model to Ensure Validity in Cybersecurity Experimentation. arXiv 2019, arXiv:1905.07059. [Google Scholar]
- Priya, V.; Thaseen, I.S.; Gadekallu, T.R.; Aboudaif, M.K.; Nasr, E.A. Robust Attack Detection Approach for IIoT Using Ensemble Classifier. Comput. Mater. Contin. 2021, 66, 2457–2470. [Google Scholar] [CrossRef]
- Shah, S.A.R.; Issac, B. Performance comparison of intrusion detection systems and application of machine learning to Snort system. Future Gener. Comput. Syst. 2018, 80, 157–170. [Google Scholar] [CrossRef]
- Fang, X.; Yang, D.; Xue, G. Wireless communications and networking technologies for smart grid: Paradigms and challenges. arXiv 2011, arXiv:1112.1158. [Google Scholar]
- Saad, W.; Han, Z.; Poor, H.V.; Basar, T. Game-theoretic methods for the smart grid: An overview of microgrid systems, demand-side management, and smart grid communications. IEEE Signal Process. Mag. 2012, 29, 86–105. [Google Scholar] [CrossRef]
- Kaur, D.; Islam, S.N.; Mahmud, M.; Dong, Z. Energy forecasting in smart grid systems: A review of the state-of-the-art techniques. arXiv 2020, arXiv:2011.12598. [Google Scholar]
- Rostamnia, N.; Rashid, T.A. Investigating the effect of competitiveness power in estimating the average weighted price in electricity market. Electr. J. 2019, 32, 106628. [Google Scholar] [CrossRef] [Green Version]
- Lenzi, A.; de Souza, C.P.E.; Dias, R.; Garcia, N.L.; Heckman, N.E. Analysis of Aggregated Functional Data from Mixed Populations with Application to Energy Consumption. Environmetrics 2014, 28, e2414. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Wu, G.; Sun, R.; Dubey, A.; Laszka, A.; Pugliese, P. A Review and Outlook of Energy Consumption Estimation Models for Electric Vehicles. arXiv 2020, arXiv:2003.12873. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Link | Original | Exact Match | F1-Score |
|---|---|---|---|---|
| RoBERTa | [9] | [46] | 79.9 | 82.1 |
| TinyRoBERTa | [48] | - | 78.7 | 81.9 |
| TinyBERT | [49] | [47] | 71.9 | 76.36 |
| DistilBERT | [50] | [51] | 68.6 | 72.8 |
| Adversarial Attack | 200 |
| Attack Detection | 175 |
| Cyberphysical Systems | 200 |
| Cybersecurity | 129 |
| Intrusion Detection Systems | 130 |
| Total Used | 834 |
| Corrupted | −6 |
| Duplicates | −7 |
| Total Articles in Corpus | 821 |
| Smart Grids | 200 |
| Electricity Markets | 156 |
| Energy Forecasting | 13 |
| Intelligent Buildings | 5 |
| Energy Consumption | 197 |
| Total Used | 571 |
| Corrupted | −6 |
| Duplicates | 0 |
| Total Articles in Corpus | 565 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sousa, N.; Oliveira, N.; Praça, I. Machine Reading at Scale: A Search Engine for Scientific and Academic Research. Systems 2022, 10, 43. https://doi.org/10.3390/systems10020043
Sousa N, Oliveira N, Praça I. Machine Reading at Scale: A Search Engine for Scientific and Academic Research. Systems. 2022; 10(2):43. https://doi.org/10.3390/systems10020043
Chicago/Turabian StyleSousa, Norberto, Nuno Oliveira, and Isabel Praça. 2022. "Machine Reading at Scale: A Search Engine for Scientific and Academic Research" Systems 10, no. 2: 43. https://doi.org/10.3390/systems10020043
APA StyleSousa, N., Oliveira, N., & Praça, I. (2022). Machine Reading at Scale: A Search Engine for Scientific and Academic Research. Systems, 10(2), 43. https://doi.org/10.3390/systems10020043