1. Introduction
In [
1], a variant of genetic programming (GP) has been proposed that uses a lattice layout of the nodes instead of a tree and is thus called Cartesian genetic programming (CGP). Since then it has become quite popular; it has been broadly adopted [
2] and applied to many different use cases and applications [
3,
4,
5].
Programs in CGP are encoded by an integer-based representation of a directed graph. In this way, the alleles encode the addresses of the other nodes, which serve as data sources for their own functions, or they encode functions by their addresses in a look-up table. The data addresses always refer to the outputs previously calculated by other function nodes that are further ahead in the execution row. Later versions have also experimented with float-based representations [
6]. In order to organize the graph in an optimized way (with respect to solving a given problem), so far, only centralized algorithms are used.
On the other hand, systems with self-organizing capabilities, such as multi-agent-based systems, are widely seen as a promising method for coordination and distributed optimization in cyber-physical systems (CPS) with a large number of distributed entities, such as sensing or operational equipment [
7,
8], and especially for horizontally distributed control tasks [
9]. Solving a genetic programming problem can also be seen as such a system [
10].
Although up to now most cyber-physical systems are primarily on a semi-autonomous level, future CPS will show a degree of autonomy that makes them hard to control (cf. [
11,
12]). The autonomy in CPS emerges, for example, from integrated concepts, such as self-organization principles, that are used for coordination inside the system as well as for reaching autonomy. Autonomy may also be achieved by the integration of artificial intelligence (AI). Looking at the example of the European Union, such AI-enabled algorithms are stipulated in [
13]. Contemporary cyber-physical systems already comprise a huge number of physical operation and sensing equipment that has to be orchestrated for secure and reliable operation. The electric energy grid, modern transportation systems, and environmental management systems [
14] are prominent examples of such large-scale CPS. Multi-agent systems and self-organization principles have now been used for many different applications. Examples can be found in [
15,
16,
17].
A growing degree of autonomy is desirable to achieve in future CPS [
18,
19] because the size of the systems, and thus the complexity, steadily grows. Thus, the sizes of the optimization problems and coordination tasks grow as well. Due to some limitations in predictability, adaptive control is desirable and often translated into self-organization approaches. Thus, self-organization seems most promising for the design of adaptive systems [
20].
A targeted design of a specific emergent behavior is difficult to achieve, especially when using just general-purpose programming languages [
21]. Consequently, the authors in [
22] proposed learning, in self-organized systems, how to solve new problems in a decentralized way. For the purpose of swarm-based optimization, the feasibility has successfully been demonstrated [
10]. So far, the evolution of learned problem-solving programs was achieved by using a centralized algorithm. On the other hand, that use case constitutes the first reason to distribute the evolution of CGP programs: to enable a swarm to achieve program evolution by itself in a likewise decentralized manner.
For the evolution of Cartesian genetic programs, a
-evolution strategy is often used. As a single operator for variation, the mutation is harnessed. A mutation may operate on all or only a subset of the active genes [
23,
24]. Although initially thought of to be of low or even no use [
1], crossover can help a lot if multiple chromosomes have independent fitness assessments [
25]. An in-depth analysis of some reasons can be found in [
10], in which the authors scrutinize the fitness landscape as an example of learning some meaningful behavior inside a swarm. This is not the case in our application, so we will also not make any use of operators, such as crossover, and restrict ourselves to the mutation. Recently, some distributed use cases have been contemplated that showed that CGP evolution can be very time-consuming when solved by a centralized algorithm [
22].
In the case of standard GP, distributed versions have already been in place for a while [
26]. Although distributed GP is closely related to CGP due to their representations, distributed CGP has been so far missing. So, another reason to distribute CGP is the acceleration by parallelization and distribution of the evolution process and thus of the computational burden.
Optimization in multi-agent systems has now been researched in various directions and brought up a multitude of synchronization concepts and [
27,
28,
29] decentralized optimization protocols [
30,
31]. A good overview can be found in [
32]. In [
33], an algorithmic level decomposition [
34] of CGP evolution has been proposed. This was achieved by using an agent-based, distributed approach to solving [
35]. In [
36] the fully decentralized, agent-based approach combinatorial optimization heuristics for distributed agents (COHDA) has been proposed as a solution to problems that can be decomposed on an algorithmic level. The general concept is closely related to cooperative coevolution [
37]. The key concept of COHDA is an asynchronous iterative approximate best-response behavior. Each agent is responsible for one dimension of the algorithmic problem decomposition. The intermediate solutions of other agents (represented by published decisions) are regarded as temporarily fixed. Thus, each agent only searches along a low-dimensional cross-section of the search space and thus has to solve merely a simplified sub-problem. Nevertheless, for evaluation of the solution, the full objective function is used after the aggregation of all agents’ contributions. In this way, the approach achieves an asynchronous coordinate descent with the additional ability to escape local minima by parallel searching different regions of the search space and because former decisions can be revised if newer information becomes available. This approach is especially suitable for large-scale problems [
38].
To adapt COHDA to CGP, the chromosome that encodes the graph representation is split up into sub-chromosomes for each node ([
33]). Assigning the best alleles to a chromosome that encodes a computation node is then regarded as the low-dimensional optimization problem of a single agent. Thus, to each node, exactly one agent is assigned. The multi-agent system jointly evolves the program with agents that can be executed independently and fully distributed.
Evolving the problem requires frequent decisions on the (probably) best assignment of the functions and the respective wiring of the inputs made by individual agents. So far, the overall approach had been tested with agents fully enumerating through the set of all possible solutions. This was feasible as the test problems were small enough, and the aim was to evaluate the overall approach without any randomness inside an agent’s decision function. Here, we extend this approach by using a heuristic for deciding the best local solutions. As this heuristic needs to be called upon many times during the agent negotiations, we chose to use the covariant matrix adaption evolution strategy (CMA-ES), which is well known for the property of using just a low budget of objective evaluations. Thus, the contributions of this paper are the adaption of CMA-ES as a solver for the local optimization of an agent’s decision routine; an analysis of the individual and time variable complexity of the local optimization problems, and additional results demonstrating the superiority of the CMA-ES approach.
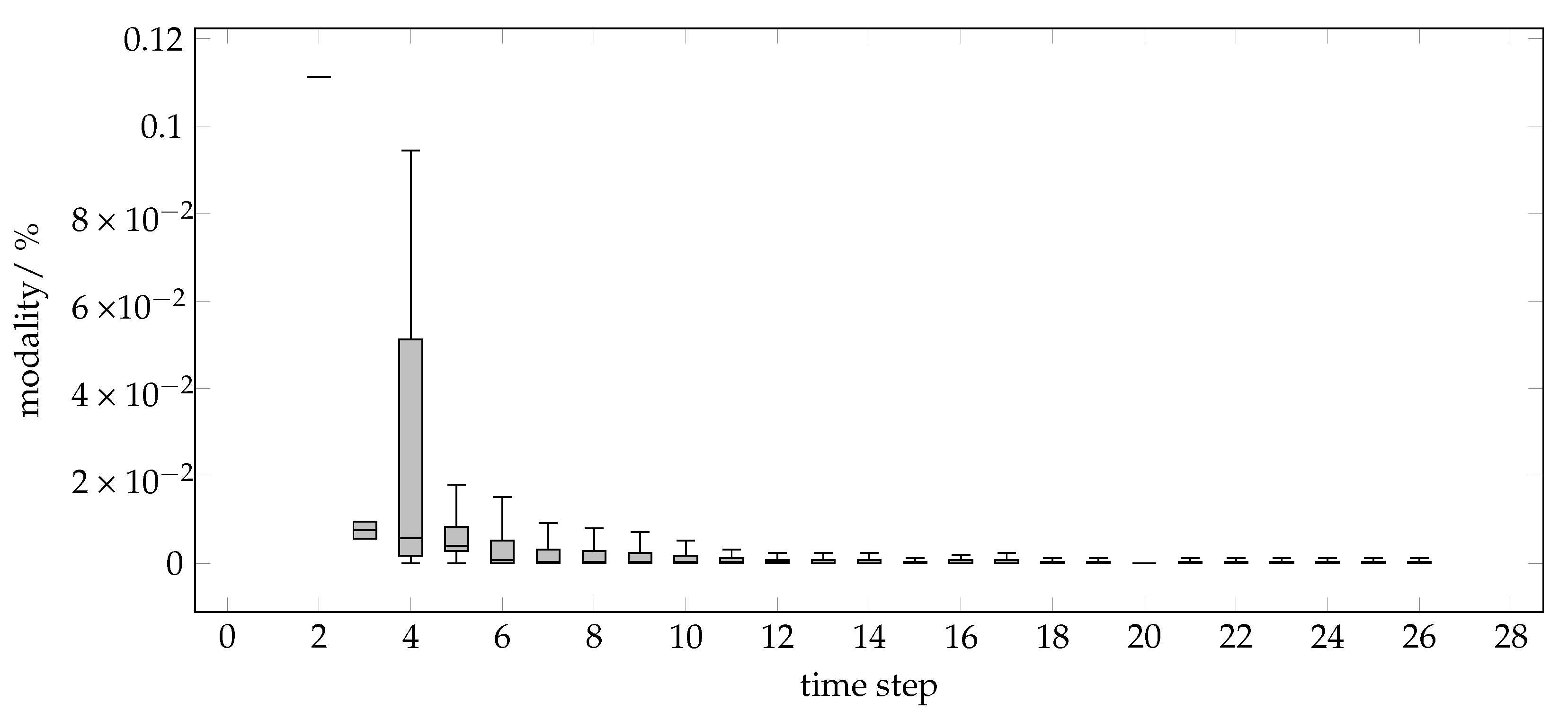
The rest of the paper is organized as follows. We start with a recap of both technologies that are combined into the distributed CGP. We describe the adaption of COHDA to CGP and how CMA-ES is adapted to suit the local optimization problem of an agent’s decision. The applicability and the effectiveness of the enumeration approach are demonstrated using problems from symbolic regression, n-parity problems, and classification problems. Finally, we demonstrate the superiority of the CMA-ES approach for larger problems. We justify the choice by analyzing the trace of the modality of the agent’s local optimization problems with a fitness landscape analysis. We conclude with a prospective view of further use cases and possible extensions.
2. Distributing Cartesian Genetic Programming
In CGP, computer programs are encoded as graph representations [
39]. In general, CGP is an enhancement of a method that was originally developed for the use case of evolving digital circuits [
40,
41]. CGP already demonstrated its capabilities in synthesizing complex functions. Several different use cases from different fields have so far been scrutinized, for example, for image processing [
42] or neural network training [
4]. Moreover, some additions to CGP have been developed. Examples comprise recurrent CGP [
23] (as in recurrent neural networks) or self-modifying CGP [
43]. The authors in [
33] used standard CGP. As the extension presented here improves the original approach in an internal sub-process, we also used standard CGP.
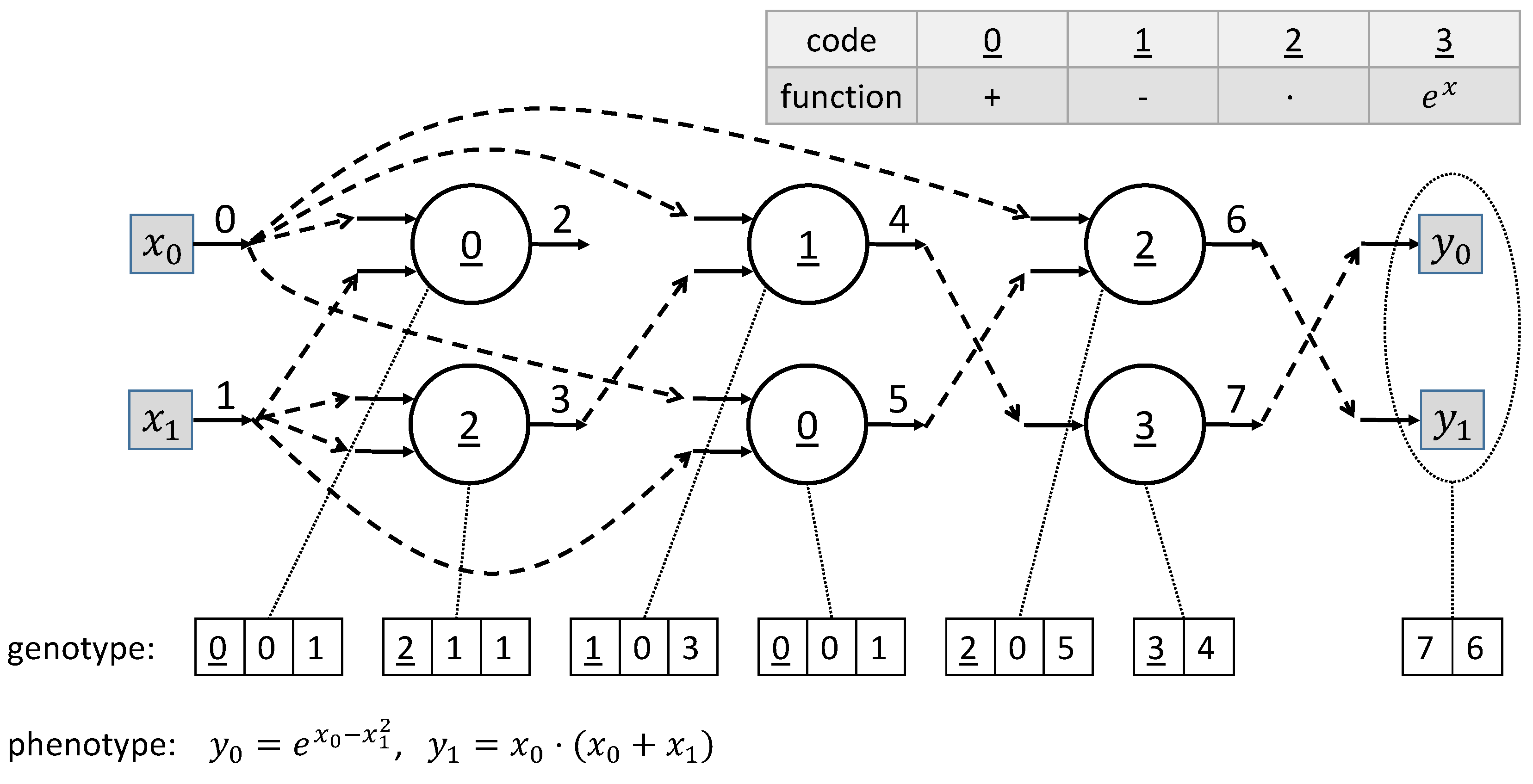
A chromosome in CGP comprises function-encoding genes and connection- and output-encoding genes. Together, they encode a computational graph (actually, a grid) that represents the executable program. The example in
Figure 1 shows a graph with six computational nodes, two inputs, and also two outputs. The allele that encodes a function represents the index in an associated look-up table (from
to
in the example) with a list of all functions.
Each computation node is encoded by a gene sequence consisting of the function look-up index and the connected input (input into the system or output of another computation node). These are the parameters that are fed into the function. Hence, the total length of each function node gene sequence is
with
n being the arity of the function plus one allele for the function index. The graph in standard CGP is an acyclic one. Parameters that are fed into a computation node may only be collected from nodes that have already been executed or from the inputs into the system. Thus, standard CGP works with a predefined execution order. Outputs can be connected to any computation node (representing the computation result of the output) or directly to any system input. Not all outputs of computational nodes are used as input for other functions. There might be no connections. Usually, many such unused computational nodes occur in evolved CGP [
40] programs. These nodes are inactive, do not contribute to the encoded program’s output, and are not executed during the interpretation of the program. Thus, they do not cause any delay in computation.
Phenotypes are of variable length. In contrast, the size of the chromosome is static. As functions may have different arities, some genes may remain unused as input connections. Using an intermediate output of an inner node is also not mandatory. In this way, the fact that evolution is mainly responsible for rewiring makes CGP special.
COHDA has been introduced as a distributed multi-agent solution to distributed energy management problems [
44]. Since then, it has been used for many different use cases. Examples include coalition structure formation [
45], global optimization [
38], trajectory optimization for unmanned air vehicles [
46], or surplus distribution based on game theory [
47].
In [
33], COHDA has been used for distributing the evolution of Cartesian genetic programs. When COHDA is executed, each participating agent reacts to updated information from other agents. This is completed by adapting the own previous decision on a possible (local) solution candidate. In the original use case, COHDA agents represented a decentralized energy unit in distributed energy management. In this way, agents had to select an energy generation scheme for their own controlled energy unit. The selection had to be carried out such that it enables a group of energy-generation units to jointly fulfill an energy product (e.g., from some energy market) as well as they can. So, each agent had to decide on the local energy-generation profile only for a single generator. All decisions were always based on (intermediate) selected production schemes of other agents.
We start by we explaining the agent protocol that is the base algorithm for CGP program evolution.
In [
36], COHDA was introduced to solve a problem known as predictive scheduling [
48]. This is a problem from the smart grid domain and serves as an example here. COHDA works with an asynchronous iterative approximate best-response behavior, which means that all agents coordinate themselves by updating knowledge and exchanging information about each other. The agents make local decisions solely based on this information. The general protocol works in three repeatedly executed steps.
However, in the beginning, the agents are drawn together first by an artificial communication topology. As a first step, a small-world topology [
49] has proven useful and is the most used topology. For this reason, we also use a small-world topology. Starting with an arbitrarily chosen agent and then passing it a message containing just the global objective, each agent repeatedly goes through three stages: perception, decision, and action (cf. [
50]).
Perception phase: In this first phase, the agent prepares for local decision-making. Each time the agent receives a message from one of the neighboring agents (which precedes the directed communication topology), the data that are contained in the message are included into their own knowledge base. The data that come with the message consist of the updated local decision of the agent that sent the message and the transient information on the decisions of other agents that led to the previous agent’s decision. After updating the local knowledge with the received information, usually, a local decision is made based on this information. In order to better escape local minima, agents may postpone a decision until more information has been collected [
51].
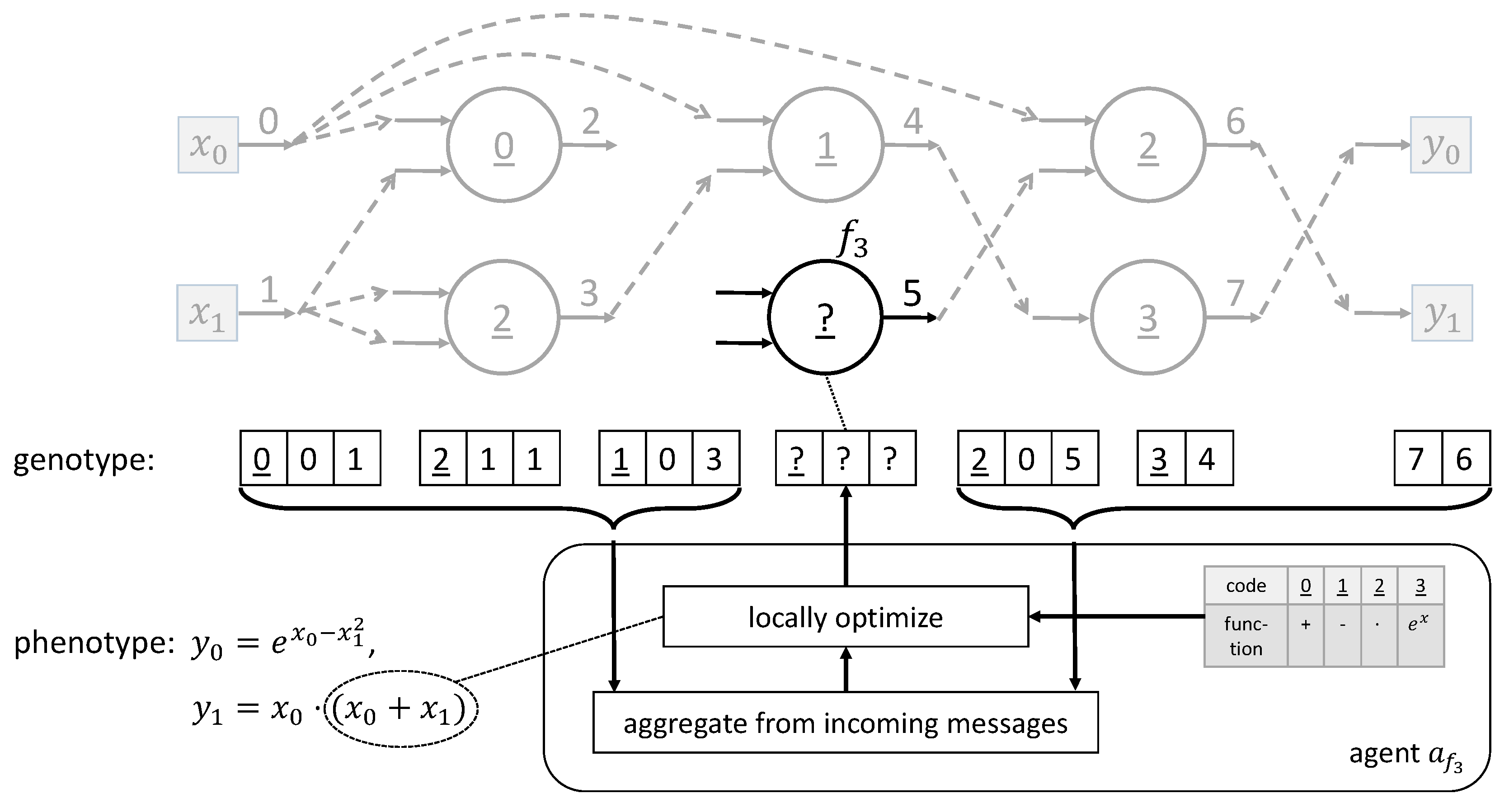
Decision phase: Here, the agent has to conduct a local optimization to yield the best decision for its own local action that puts the coalition forward as best as possible. To complete this, each agent solves a low-dimensional part of the problem. The term “dimension”, in this context, can also refer to a sub-manifold containing low-dimensional local solutions as a fraction of a much higher-dimensional global search space. In the smart grid use case, for example, a local contribution to the global solution (the energy generation profile for a large group of independently working energy resources) consists of a many-dimensional real-valued vector describing the amount of generated energy per time interval for one single device. In the CGP case, a local solution would consist of a local chromosome encoding the functions and inputs of a single node. Other agents have made local decisions before, and, based on the gathered information about the (intermediate) local decisions of these agents, a solution candidate for the local (constrained) search space is sought. To this decision phase, we added CMA-ES for better local optimization.
Action phase: In the last stage, the agent compares the fitness of the best-found solution with the previous solution. For comparison, the global objective function is used. When the new solution has a better fitness (or a lower error, depending on the specific problem setting), the agent finally broadcasts a message containing its new local solution contribution together with everything it has learned from the other agents and their current local solution contributions (the decision base) to its immediate neighbors in the communication topology. Receiving agents then execute these three phases from scratch, leading probably to revised local solution contributions and thus to further improved overall solutions.
If an agent is not able to find a local solution contribution that improves the overall solution, no message is sent. If no agent can find any improvement, the process has reached at least the local optimum and eventually ceases because no more messages are sent.
After the system has produced a series of intermediate solutions, the heuristic eventually terminates in a state where all agents know an identical solution. This one is taken as the final solution of the heuristic. Properties such as guaranteed convergence and local optimality have been formally proven [
44]. Moreover, after a short setup time, COHDA possesses the anytime property. Thus, the agent protocol may be stopped at any time with a valid (sub-optimal) solution, if necessary.
The agent approach can be adapted to CGP as follows. Each agent is responsible for a single node in the program graph. In general, there are two types of agents, the function node agents responsible for the function node and the output agents responsible for the output . The task of both agent types is rather similar but can be distinguished by the local search space. Each function node agent is responsible for exactly one node and thus internally just manages the code (look-up table address) of the function and the respective input addresses as a variable number of integers depending on the arity of the function. This list of integers is just one sub-chromosome of a complete solution. At the same time, every agent has some knowledge about the intermediate assignment of alleles to chromosomes of other agents. These are immutable for this agent. Together (their own gene set and the knowledge of others’ gene sets), the genotype of a complete solution, and, subsequently, a phenotype solution can be constructed by an agent.
If an agent that is responsible for a function node receives a message, it updates its own knowledge about the other agents. Each agent knows the most recent chromosomes from other agents. If newer information is received with the message, the outdated gene information is updated. In the case that such far unknown information arrives, additional genes are integrated into the agent’s own belief. After the data update, the agent has to make a decision about its own chromosome. This decision is a local optimization process previously solved by enumerating all of the solution candidates [
33].
The known genes of the other agents are temporarily treated as fixed for the duration of the agent’s current decision-making. Each agent may make modifications only to its own chromosome. Nevertheless, the genes of the other agents may afterward again be altered by the respective agents as a reaction to previously made alterations. If an agent makes a new local decision, it solves for the global problem of finding a good genotype but may only mutate its own local chromosome.
Figure 2 shows this situation as an example of the agent
that is responsible for the function node
.
The optimization for finding the best local decision could, in general, be completed by any algorithm; e.g., by an evolution strategy. For the test cases in [
33], the full enumeration of all solution candidates was sufficiently fast enough because each agent had just a rather limited set of choices. Nevertheless, for larger scenarios, the use of problem-specific heuristics has already been recommended in [
33]. Constraints can easily be checked as the number of functions and the arity of each function are known to the agent. Currently, we set the number of rows in the graph to one (as in [
33]). This convenient single-row representation has been shown to be no less effective [
52] and has already been frequently used, e.g., in [
53]. The levels-back parameter is set to the number of agents to allow input from all preceding nodes. Each agent knows its own index and may thus decide which other nodes (or program input) to choose as input for its own node.
As soon as the best local allele assignment has been found, the agent compares the solution quality with the quality of the previously found solution. If the new solution is better, messages are sent to neighboring agents. During our experiments, we found that it is advantageous to always send messages to the output agents in order to enable a more frequent update of the best output. The basic difference between the function and the output node agents is the local gene. The output agents just manage a single gene consisting of a single-integer allele that encodes the node that is connected to the respective output.
When no more agents can progress, no messages are sent, and the whole negotiation process finally ceases. Initially, COHDA was supposed to approach an often unknown optimum as closely as possible. For the CGP use case, on the other hand, it is also fine to drop out of the process if one agent, for the first time, finds a solution that fully satisfies a quality condition (i.e., the program does what it is supposed to do). Thus, we added an additional termination criterion. If an agent discovers a solution that constitutes a success, it sends a termination signal instead of a decision message and reports the found solution.
4. Conclusions
We presented the adaption of a distributed optimization heuristic protocol for Cartesian genetic programming and an extension using CMA-ES for improving local agent decisions. By decomposing the evolution on an algorithmic level, it becomes possible to distribute the nodes and regard the evolution process as a parallel, asynchronous execution of an individual coordinate’s descent.
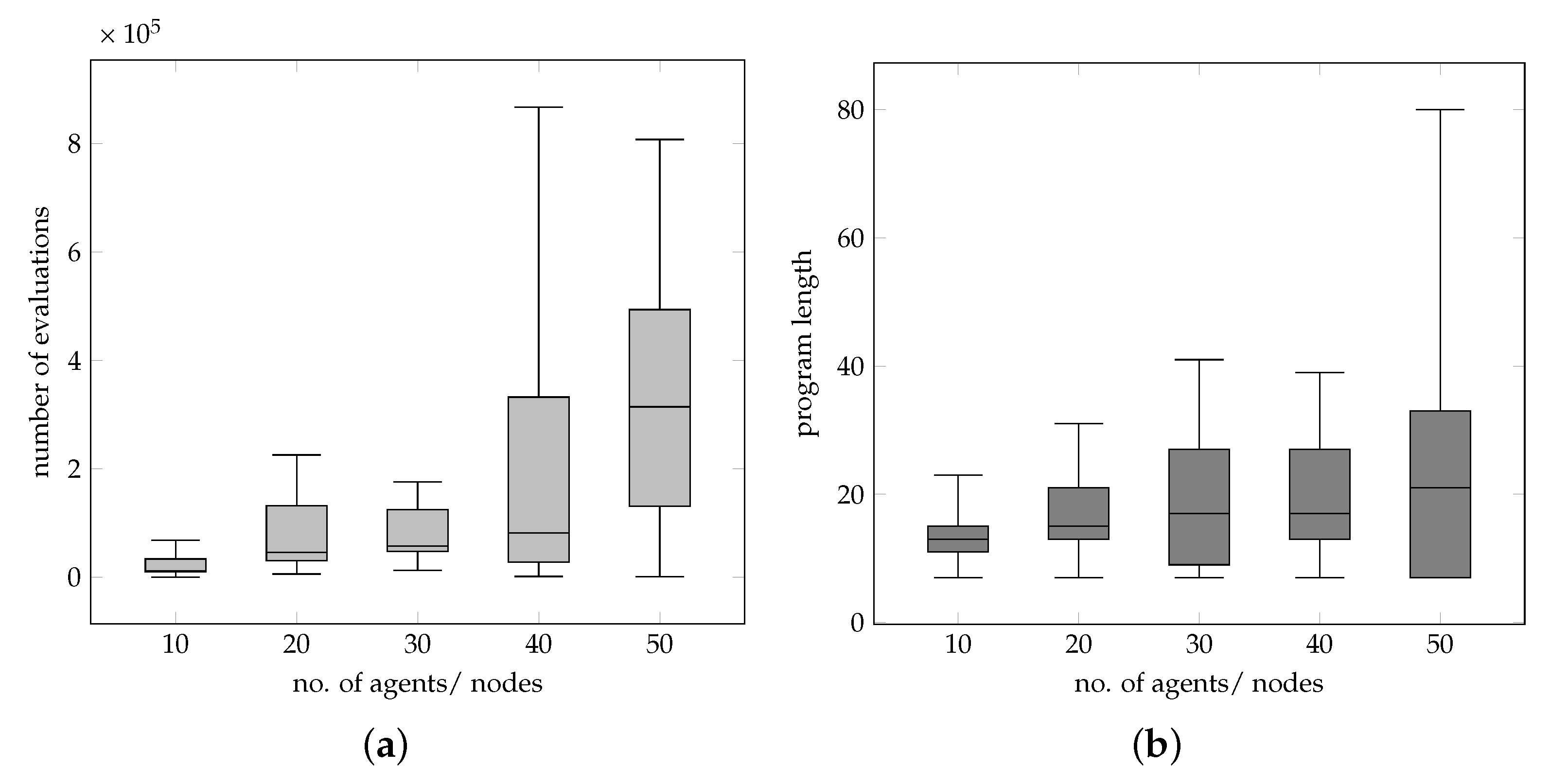
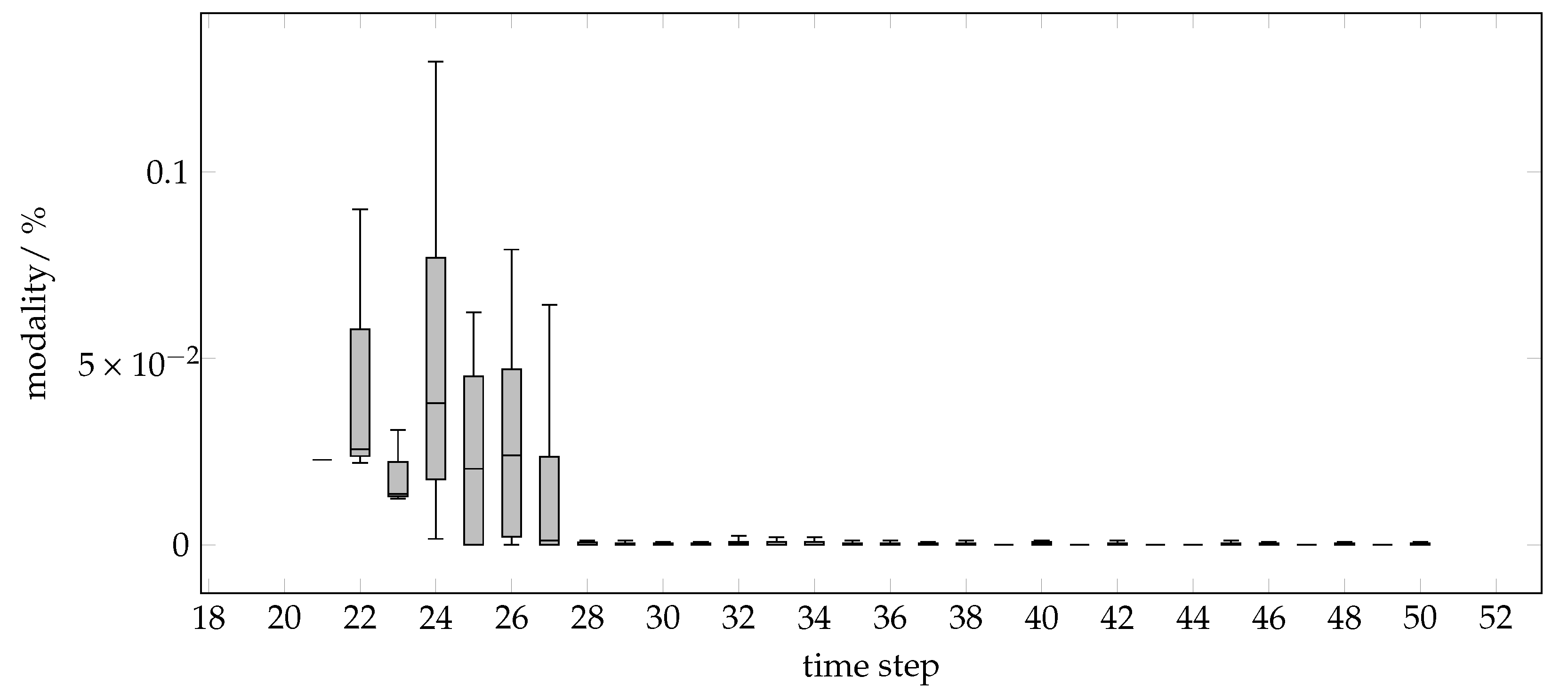
The results show that the distributed approach is competitive with regard to the evolved programs. This holds true for the solution quality as well as for the computational effort and for smaller tasks even with the full enumeration approach. A speed-up by parallel execution becomes possible and has been increased significantly here. With the extension via CMA-ES for agent-internal optimization during decision-making, the computational effort has dropped significantly, even for larger problem instances. Another advantage is the ability to distribute the computational burden. Moreover, the distributed evolution of programs enables seamless integration into distributed applications, in addition to using the example of the smart grid.
Agent-based Cartesian genetic programming constitutes a universal means to execute cooperative planning among individually acting entities. Future work will now lean toward distributed use cases. Another advantage is that different nodes may have different function sets in case they represent real-world nodes with different capabilities.
So far, we considered only the original standard CGP. Extensions such as recurrent CGP can be integrated right away now. These extensions affect basic interpretation (some also affect the execution of the phenotype) and can thus be evolved by the same distributed approach. Only an adaption of the possible choices of other agents’ output as input for its own node is necessary. In the same way, different levels-back parameterizations can be easily handled.
Further improvements are expected when agents are equipped with intelligent rules for choosing from different decision methods; i.e., optimization methods (CMA-ES, full enumeration, others) should be chosen ad hoc from a set of different methods according to the current individual’s situation.
However, even with this initial setting that has been scrutinized in this contribution for making a swarm of individually acting agents learn problem-solving via distributed CGP, the results are already very promising. Agents capable of combining individual skills to solve so-far unseen problems without any central algorithm are a major building block for large-scale future autonomous cyber-physical systems.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}