
AatMatch: Adaptive Adversarial Training in Semi-Supervised Learning Based on Data-Driven Decision-Making Models



Abstract
:1. Introduction
- Firstly, we propose a novel momentum update model specifically designed to evaluate the learning effect of each class. The traditional approach of using historical information in semi-supervised learning may lead to serious consistency problems. However, incorporating an additional model can address this issue without compromising the training process.
- Secondly, we introduce an adaptive adversarial training method that leverages course learning to generate targeted data augmentations. Specifically, we propose a new data augmentation approach that adds targeted perturbations in the gradient direction of each class based on its learning effect. This approach generates adversarial examples that are both effective and efficient in improving model performance.
- Thirdly, we propose a weight-setting mechanism that assigns weights to each unlabeled data sample based on its confidence level, effectively reducing the negative impact of low-confidence pseudo-labelling on the model.
- Lastly, we validate the effectiveness of our proposed AatMatch algorithm on several different datasets. Our experiments demonstrate that the proposed approach achieves state-of-the-art performance on CIFAR10, CIFAR100, and SVHN datasets. The results showcase the potential of our approach to overcome the challenge of limited labeled data and demonstrate its potential for practical applications in the real world.
2. Related Work
3. Methodology
3.1. Momentum Model and Adaptive Adversarial Training
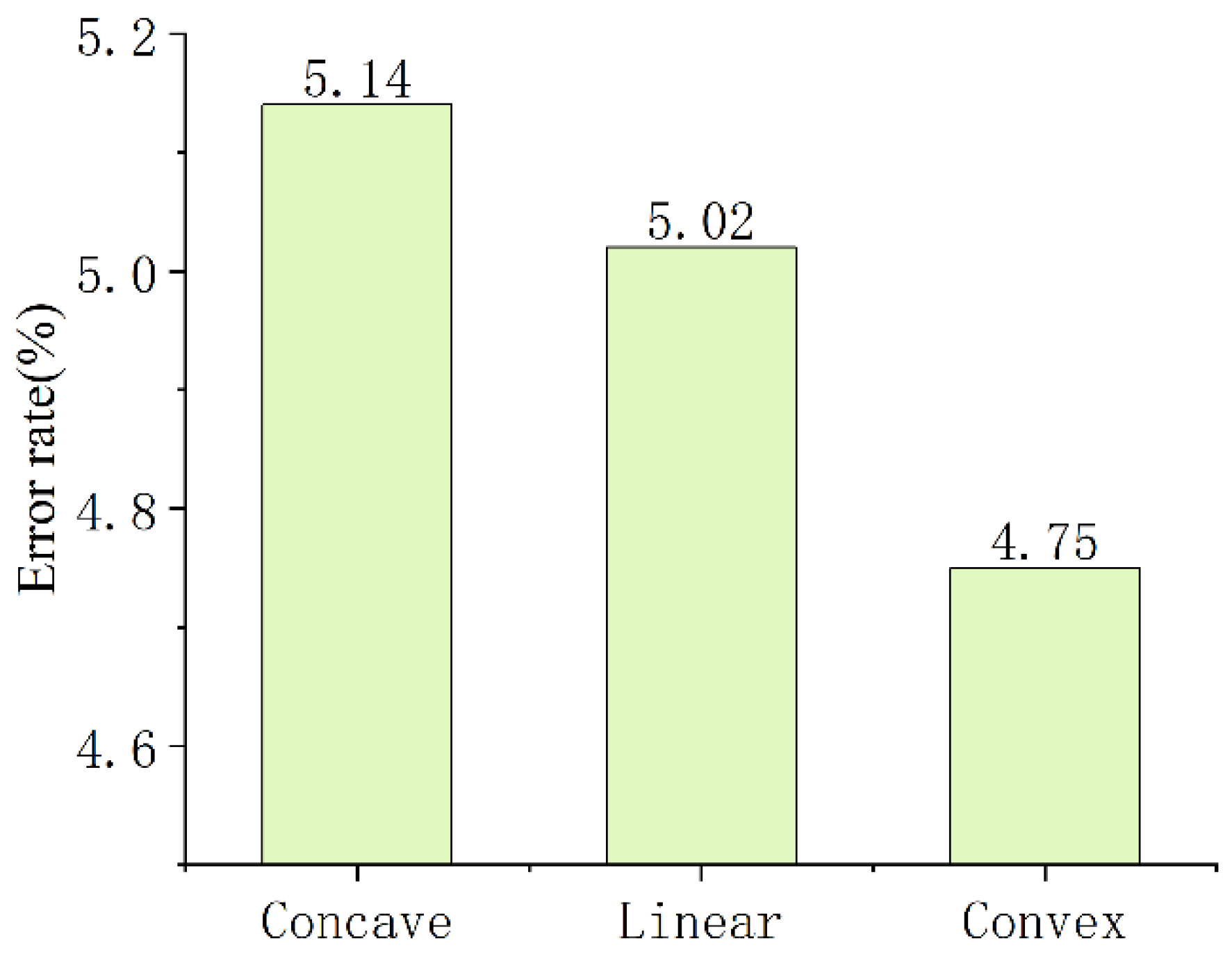
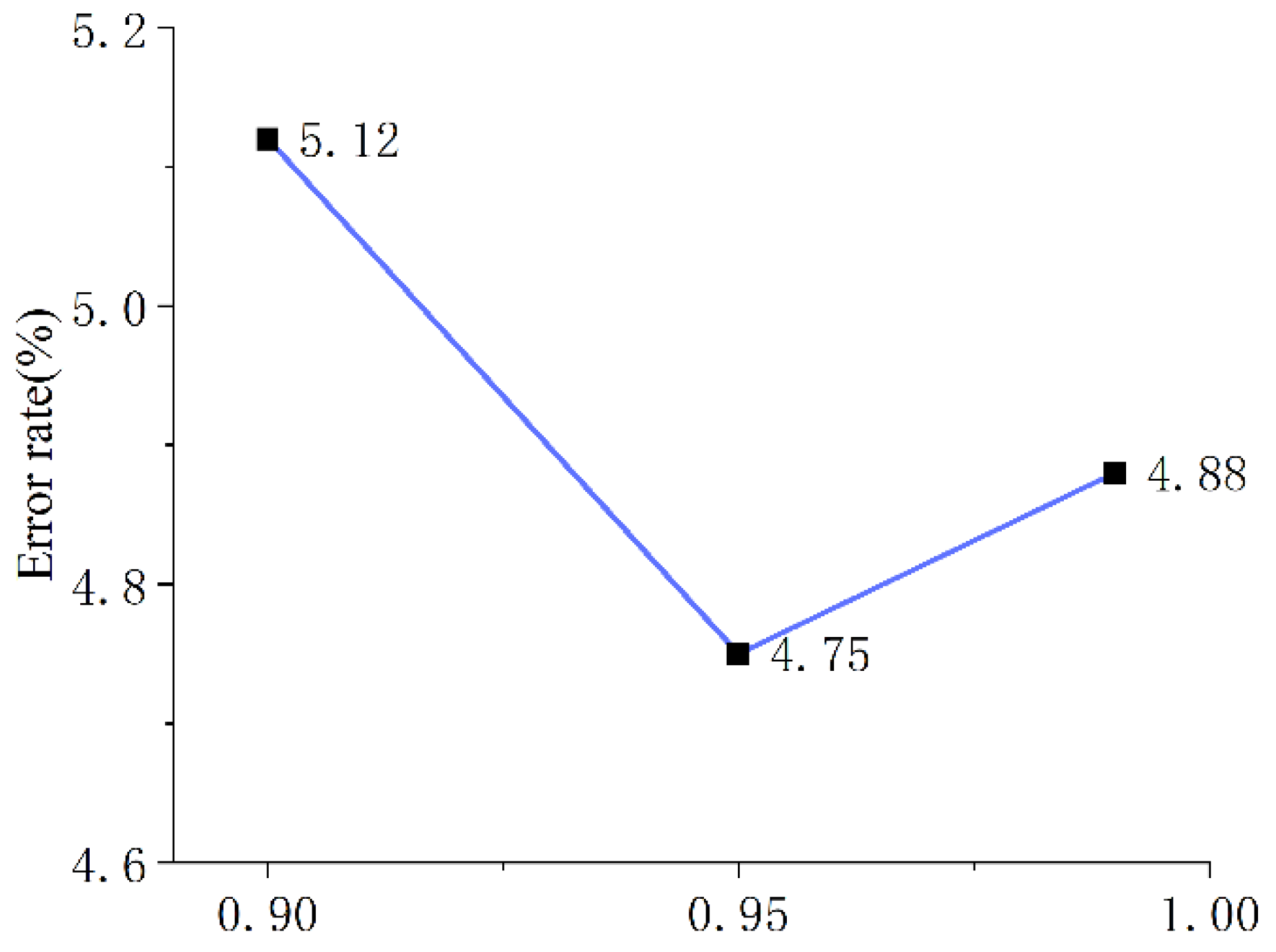
3.2. Adaptive Weight
- a linear mapping function, ;
- a concave mapping function, ;
- a convex mapping function, , where is a hyperparameter.
3.3. Total Loss Function
| Algorithm 1 AatMatch algorithm |
| Require: Batch of labeled examples and their one-hot labels , Batch of unlabeled examples : depth neural network with trainable parameters θ, Confidence threshold τ, unlabeled data ratio µ, momentum coefficient m, weak augmentation , strong augmentation perturbation magnitude ε, number of iterations T. for t = 1 in T do for b = 1 in B do end for for b = 1 in µB do end for for c = 1 to C do Calculate via Equation (2) Calculate and via Equation (3) end for Calculate based on via Equation (9) Compute the loss via Equation (12) Update θ′ via Equation (1) end for return θ |
4. Results and Discussion
4.1. Datasets
- CIFAR-10 [25] is a dataset with 60,000 images of shape 32 32 evenly distributed across 10 classes. There are 6000 images in each class, 5000 of which constitute the training set, and the remaining 1000 images are used as the test set.
- CIFAR-100 [25] is a dataset with 60,000 images of shape 32 32 evenly distributed across 100 classes. There are 600 images in each class, 500 of which constitute the training set, and the remaining 100 images are used as the test set.
- SVHN (Street View House Number) [26] is a dataset of street view house numbers, in which each example is of shape 32 32. It consists of 10 classes, 73,257 training samples, and 26,032 test samples.
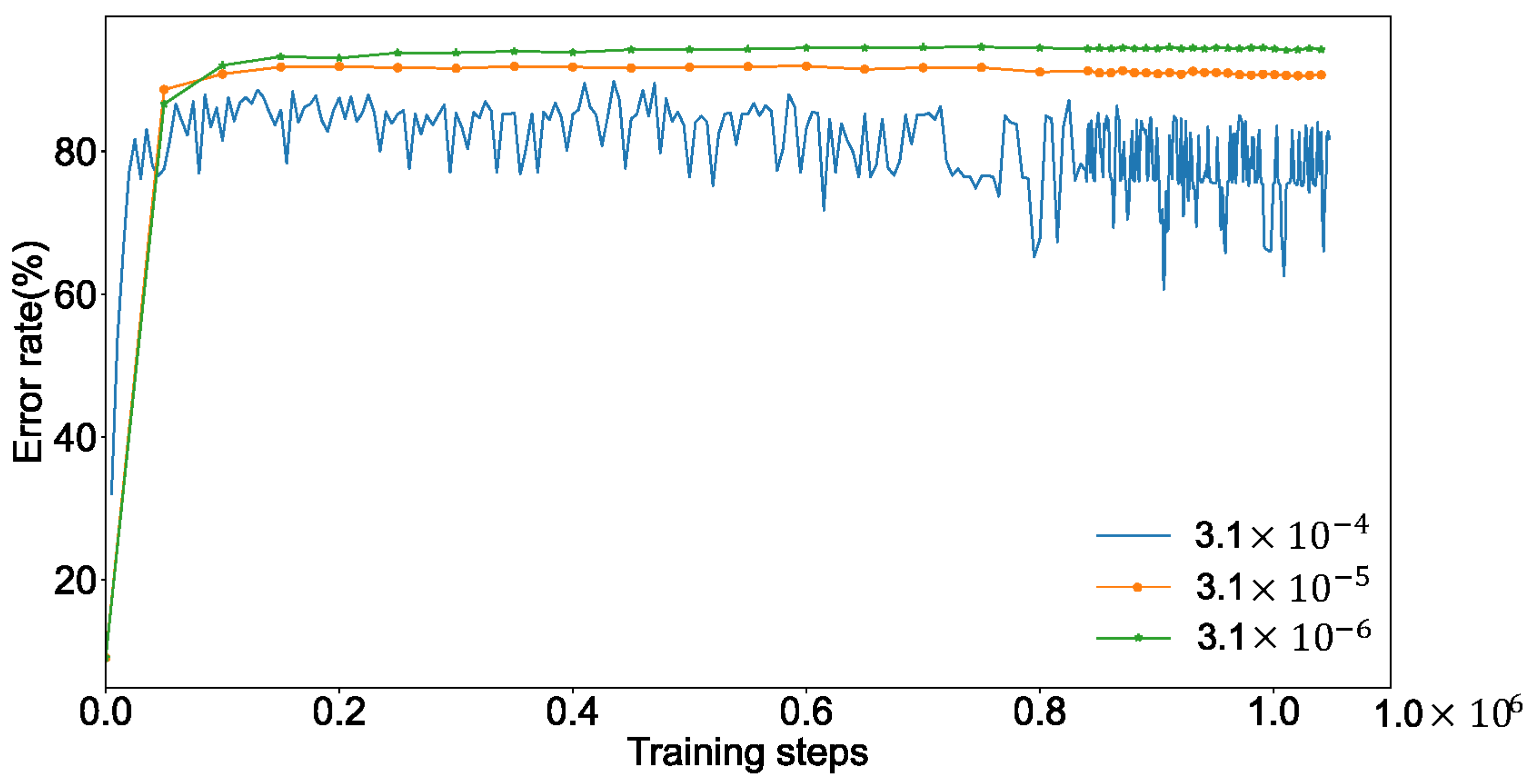
4.2. Experimental Set
4.3. Results and Analysis
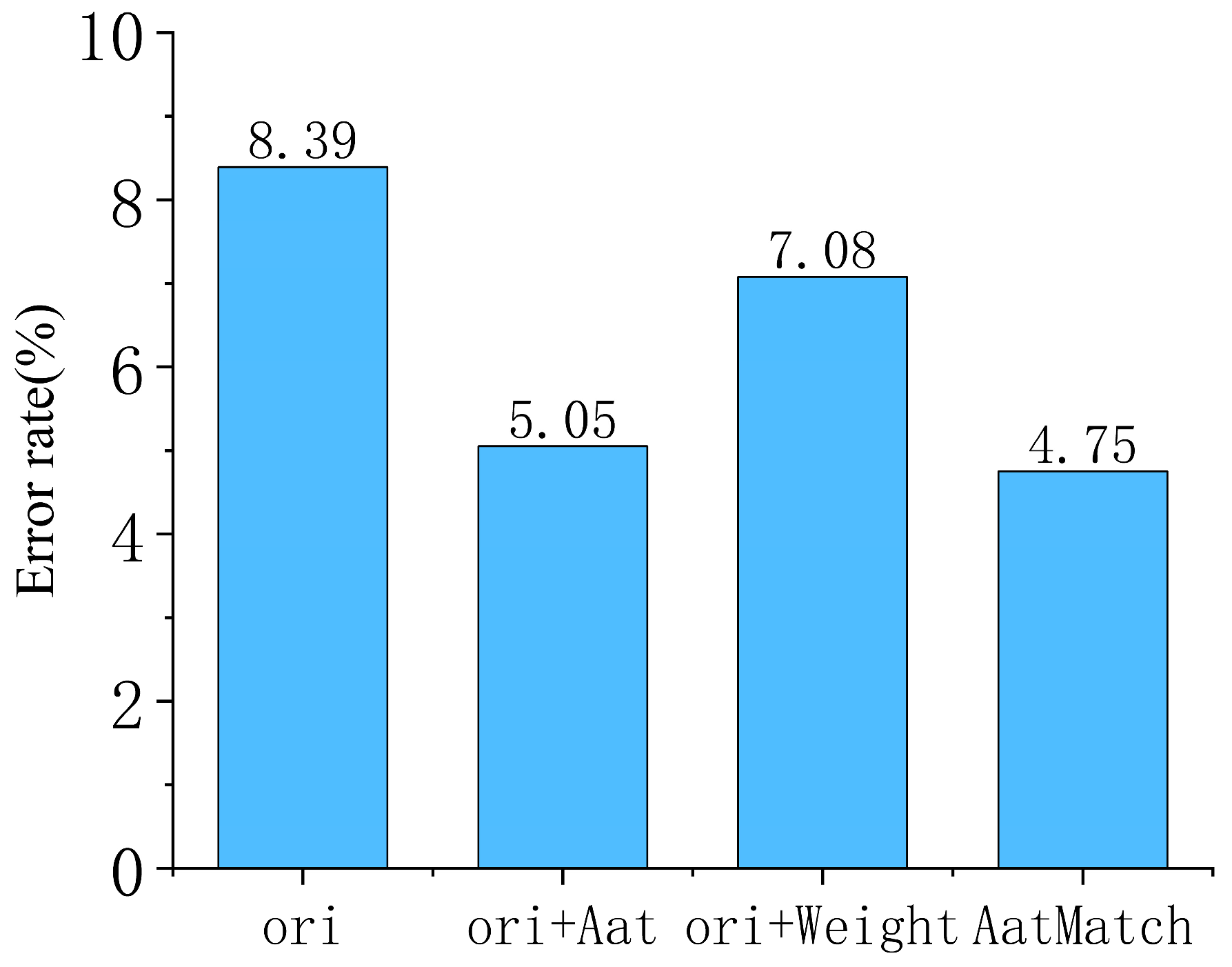
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Sindhu Meena, K.; Suriya, S. A survey on supervised and unsupervised learning techniques. In Proceedings of the 1st International Conference on Artificial Intelligence; Springer: Cham, Switzerland, 2020; pp. 627–644. [Google Scholar]
- Oliver, A.; Odena, A.; Raffel, C.A.; Cubuk, E.D.; Goodfellow, I. Realistic evaluation of deep semi-supervised learning algorithms. In Proceedings of the 32nd Annual Conference on Neural Information Processing Systems, Montréal, QC, Canada, 2–8 December 2018; pp. 3239–3250. [Google Scholar]
- Lee, D.-H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Proceedings of the Workshop on Challenges in Representation Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 2, p. 896. [Google Scholar]
- Sajjadi, M.; Javanmardi, M.; Tasdizen, T. Regularization with stochastic transformations and perturbations for deep semi-supervised learning. In Proceedings of the 30th Annual Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 1163–1171. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the 33rd IEEE Conference on Computer Vision and Pattern Recognition Workshops, Washington, DC, USA, 14–19 June 2020; pp. 702–703. [Google Scholar]
- Wang, X.; Chen, Y.; Zhu, W. A Survey on Curriculum Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4555–4576. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. In Proceedings of the 3rd International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014; pp. 1–11. [Google Scholar]
- Laine, S.; Aila, T. Temporal ensembling for semi-supervised learning. In Proceedings of the 5th International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016; pp. 1–13. [Google Scholar]
- Miyato, T.; Maeda, S.; Koyama, M.; Ishii, S. Virtual adversarial training: A regularization method for supervised and semi-supervised learning. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1979–1993. [Google Scholar] [CrossRef] [PubMed]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1195–1204. [Google Scholar]
- Verma, V.; Kawaguchi, K.; Lamb, A.; Kannala, J.; Solin, A.; Bengio, Y.; Lopez-Paz, D. Interpolation consistency training for semi-supervised learning. Neural Netw. 2022, 145, 90–106. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond empirical risk minimization. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–13. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised data augmentation for consistency training. In Proceedings of the 34th Annual Conference on Neural Information Processing Systems, Online, 6–12 December 2020; pp. 6256–6268. [Google Scholar]
- Rizve, M.N.; Duarte, K.; Rawat, Y.S.; Shah, M. In defense of pseudo-labeling: An uncertainty-aware pseudo-label selection framework for semi-supervised learning. In Proceedings of the 9th International Conference on Learning Representations, Virtual Event, Austria, 3–7 May 2021; pp. 1–20. [Google Scholar]
- Wang, X.; Gao, J.; Long, M.; Wang, J. Self-tuning for data-efficient deep learning. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10738–10748. [Google Scholar]
- Berthelot, D.; Carlini, N.; Goodfellow, I.; Papernot, N.; Oliver, A.; Raffel, C.A. MixMatch: A Holistic Approach to Semi-Supervised Learning. In Proceedings of the 33rd Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 5049–5059. [Google Scholar]
- Berthelot, D.; Carlini, N.; Cubuk, E.D.; Kurakin, A.; Sohn, K.; Zhang, H.; Raffel, C. ReMixMatch: Semi-Supervised Learning with Distribution Matching and Augmentation Anchoring. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.L. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. In Proceedings of the 34th Annual Conference on Neural Information Processing Systems, Online, 6–12 December 2020; pp. 596–608. [Google Scholar]
- Li, J.; Xiong, C.; Hoi, S.C.H. Comatch: Semi-supervised learning with contrastive graph regularization. In Proceedings of the 34th IEEE International Conference on Computer Vision, Virtual, 7–9 June 2021; pp. 9475–9484. [Google Scholar]
- Zhang, B.; Wang, Y.; Hou, W.; Wu, H.; Wang, J.; Okumura, M.; Shinozaki, T. Flexmatch: Boosting semi-supervised learning with curriculum pseudo labeling. In Proceedings of the 35th Annual Conference on Neural Information Processing Systems, Virtual, 6–14 December 2021; pp. 18408–18419. [Google Scholar]
- Yang, F.; Wu, K.; Zhang, S.; Jiang, G.; Liu, Y.; Zheng, F.; Zhang, W.; Wang, C.; Zeng, L. Class-Aware Contrastive Semi-Supervised Learning. In Proceedings of the 35th IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14421–14430. [Google Scholar]
- Zheng, M.; You, S.; Huang, L.; Wang, F.; Qian, C.; Xu, C. Simmatch: Semi-supervised learning with similarity matching. In Proceedings of the 35th IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14471–14481. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning multiple layers of features from tiny images. In Technical Report; Department of Computer Science University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading digits in natural images with unsupervised feature learning. In Proceedings of the 25th Annual Conference on Neural Information Processing Systems Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 12–14 December 2011; pp. 1–9. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. In Proceedings of the 27th British Machine Vision Conference, York, UK, 19–22 September 2016; Richard, E.R.H., Wilson, C., Smith, W.A.P., Eds.; BMVA Press: York, UK, 2016; pp. 1–12. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. In Proceedings of the 25th International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016; pp. 1–16. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | 40 Labels | 250 Labels | 4000 Labels |
|---|---|---|---|
| Fully Supervised | 4.62 ± 0.05 | ||
| Model | 74.34 ± 1.76 | 53.21 ± 1.29 | 17.41 ± 0.59 |
| Pseudo Label | 74.61 ± 0.26 | 49.98 ± 2.20 | 16.21 ± 0.19 |
| Mean Teacher | 70.09 ± 1.60 | 47.32 ± 3.30 | 10.36 ± 0.21 |
| VAT | 74.66 ± 2.12 | 36.03 ± 1.79 | 11.05 ± 0.12 |
| MixMatch | 47.54 ± 6.48 | 11.08 ± 0.59 | 6.24 ± 0.26 |
| ReMixMatch | 14.50 ± 2.58 | 9.21 ± 055 | 4.88 ± 0.05 |
| UDA | 29.05 ± 3.75 | 8.76 ± 0.06 | 5.29 ± 0.07 |
| CoMatch | 5.44 ± 0.05 | 5.33 ± 0.12 | 4.29 ± 0.04 |
| FixMatch | 8.39 ± 3.35 | 5.07 ± 0.33 | 4.31 ± 0.15 |
| FlexMatch | 5.22 ± 0.06 | 4.98 ± 0.05 | 4.29 ± 0.01 |
| AatMatch | 4.75 ± 0.32 | 4.65 ± 0.09 | 4.16 ± 0.13 |
| Method | 400 Labels | 2500 Labels | 10,000 Labels |
|---|---|---|---|
| Fully Supervised | 19.27 ± 0.03 | ||
| Model | 86.96 ± 0.8 | 58.80 ± 0.66 | 36.65 ± 0.0 |
| Pseudo Label | 87.45 ± 0.85 | 57.74 ± 0.28 | 36.55 ± 0.24 |
| Mean Teacher | 81.11 ± 1.44 | 45.17 ± 1.06 | 31.75 ± 0.23 |
| VAT | 85.20 ± 1.4 | 46.84 ± 0.79 | 32.14 ± 0.19 |
| MixMatch | 67.59 ± 0.66 | 39.76 ± 0.48 | 27.78 ± 0.29 |
| ReMixMatch | 57.10 ± 1.05 | 34.77 ± 0.45 | 26.18 ± 0.23 |
| UDA | 46.39 ± 1.59 | 33.13 ± 0.21 | 22.49 ± 0.23 |
| CoMatch | 60.98 ± 0.77 | 37.24 ± 0.24 | 28.15 ± 0.16 |
| FixMatch | 49.42 ± 0.82 | 28.64 ± 0.16 | 23.18 ± 0.12 |
| FlexMatch | 43.21 ± 1.35 | 26.49 ± 0.20 | 21.91 ± 0.15 |
| AatMatch | 40.96 ± 0.32 | 26.30 ± 0.09 | 21.64 ± 0.13 |
| Method | 40 Labels | 250 Labels | 1000 Labels |
|---|---|---|---|
| Fully Supervised | 2.13 ± 0.02 | ||
| Model | 67.48 ± 0.95 | 13.30 ± 1.12 | 7.16 ± 0.11 |
| Pseudo Label | 64.61 ± 5.60 | 15.59 ± 0.95 | 9.40 ± 0.32 |
| Mean Teacher | 36.09 ± 3.98 | 3.45 ± 0.03 | 3.27 ± 0.05 |
| VAT | 74.74 ± 3.38 | 4.33 ± 0.12 | 4.11 ± 0.2 |
| MixMatch | 42.55 ± 14.53 | 4.56 ± 0.32 | 3.69 ± 0.37 |
| ReMixMatch | 31.27 ± 18.79 | 5.34 ± 1.09 | 5.34 ± 0.45 |
| UDA | 52.63 ± 20.51 | 5.69 ± 0.76 | 2.46 ± 0.24 |
| CoMatch | 9.51 ± 5.59 | 2.21 ± 0.20 | 1.96 ± 0.07 |
| FixMatch | 7.65 ± 1.18 | 2.64 ± 0.64 | 2.36 ± 0.10 |
| FlexMatch | 8.19 ± 3.20 | 6.59 ± 2.29 | 6.72 ± 0.30 |
| AatMatch | 2.14 ± 0.29 | 2.19 ± 0.30 | 2.12 ± 0.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, K.; Lian, Q.; Gao, C.; Zhang, F. AatMatch: Adaptive Adversarial Training in Semi-Supervised Learning Based on Data-Driven Decision-Making Models. Systems 2023, 11, 256. https://doi.org/10.3390/systems11050256
Li K, Lian Q, Gao C, Zhang F. AatMatch: Adaptive Adversarial Training in Semi-Supervised Learning Based on Data-Driven Decision-Making Models. Systems. 2023; 11(5):256. https://doi.org/10.3390/systems11050256
Chicago/Turabian StyleLi, Kuan, Qianzhi Lian, Can Gao, and Fuyong Zhang. 2023. "AatMatch: Adaptive Adversarial Training in Semi-Supervised Learning Based on Data-Driven Decision-Making Models" Systems 11, no. 5: 256. https://doi.org/10.3390/systems11050256
APA StyleLi, K., Lian, Q., Gao, C., & Zhang, F. (2023). AatMatch: Adaptive Adversarial Training in Semi-Supervised Learning Based on Data-Driven Decision-Making Models. Systems, 11(5), 256. https://doi.org/10.3390/systems11050256