


Credit Card Fraud Detection Based on Unsupervised Attentional Anomaly Detection Network



Abstract
:1. Introduction
- Reframe the problem of credit card fraud detection as anomaly detection of fraudulent transactions, and propose a new credit card Fraud Detection framework based on Unsupervised Attentional Anomaly Detection Network (UAAD-FDNet).
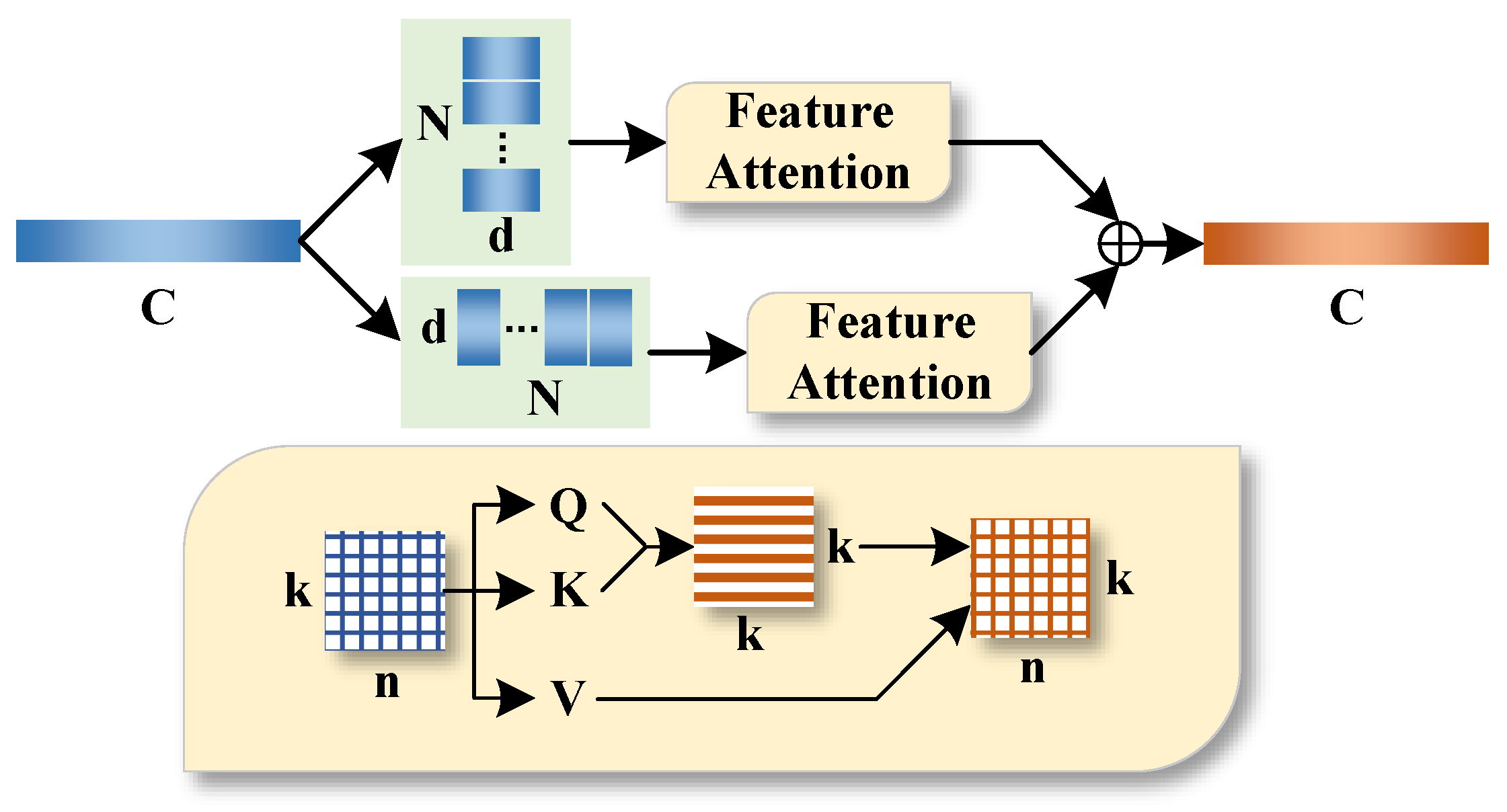
- A channel-wise feature attention is proposed. This module enables the network to effectively capture the interdependence between feature channels to better learn how to reconstruct normal transaction samples.
- A hybrid weighted loss function is proposed to enable the model to learn an effective encoding method for hidden vectors and reconstruct samples as realistically as possible. In the test phase, fraudulent transactions are identified by calculating the hidden vectors and the characteristic distance between the reconstructed samples and the input samples.
- Experimental results on Kaggle Credit Card Fraud Detection Dataset and IEEE-CIS Fraud Detection Dataset show that our method outperforms existing machine learning-based and deep learning-based fraud detection methods.
2. Background and Related Work
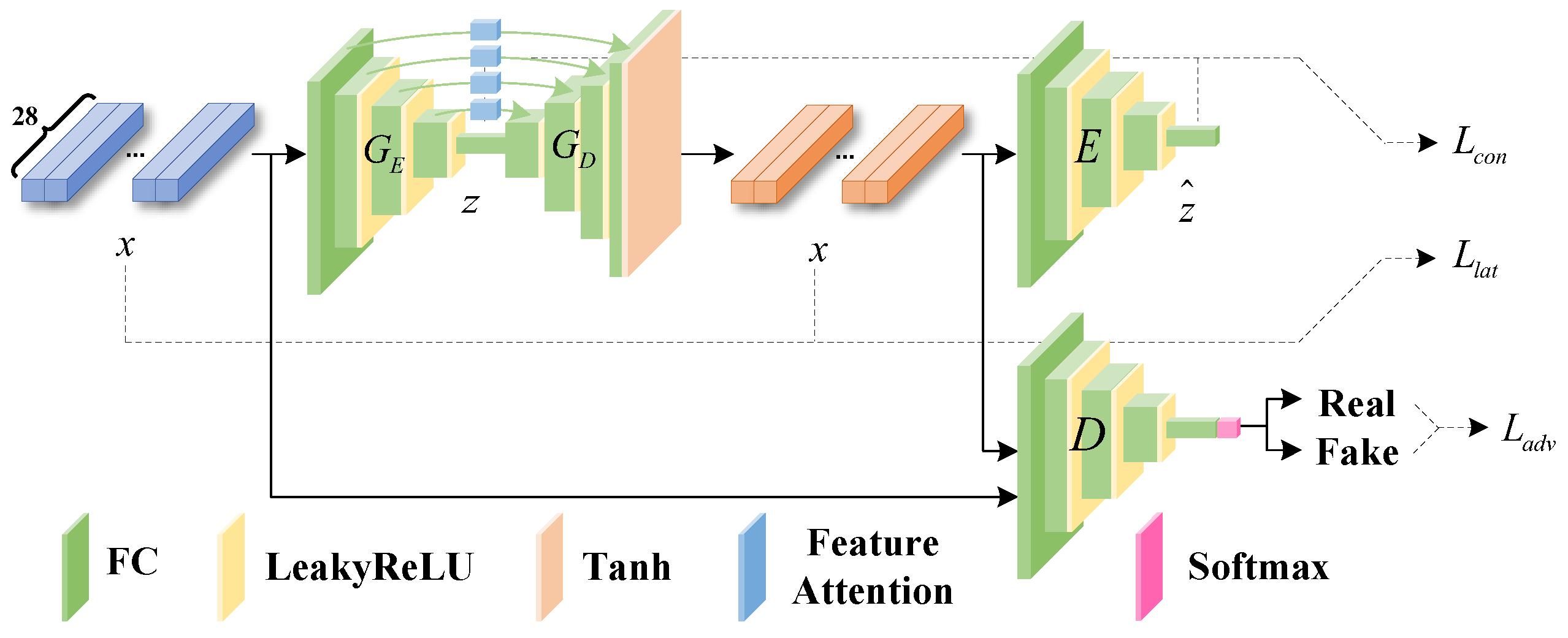
3. Methodology
3.1. Proposed Model
3.2. Model Training
- Adversarial Loss : In our framework, the goal of the adversarial loss is to make the samples generated by G as close as possible to the distribution of real normal transaction data samples, so that D cannot accurately distinguish generated samples from real samples. In other words, the adversarial loss is an objective function for adversarial training by maximizing the misjudgment rate of D for generated samples while minimizing the misjudgment rate of G. Its mathematical expression is as follows:
- Context Loss : In order to make the samples generated by G closer to the original data distribution in terms of eigenvalues to produce more realistic samples, the context loss is introduced into the training phase of the model. It minimizes the distance between the generated samples and the original normal transaction data samples in the feature space, so that G can preserve the semantic and structural information of the input features as much as possible when generating samples. Its mathematical definition is as follows:
- Latent Loss : In addition to the above two loss functions, this paper also introduces a Latent Loss. This function ensures that G can produce similar latent space representations by minimizing the distance of two latent vectors of G in the feature space. In other words, Latent Loss enables G to learn effective encoding methods for normal transaction data from generated samples. In the testing stage, when encountering never-before-seen fraudulent transaction samples, the encoding method of G may fail, resulting in a large feature difference between z and . For such sample data, we can classify it as an abnormal sample (fraudulent transaction sample). The mathematical expression of Latent Loss is as follows:
4. Experiments
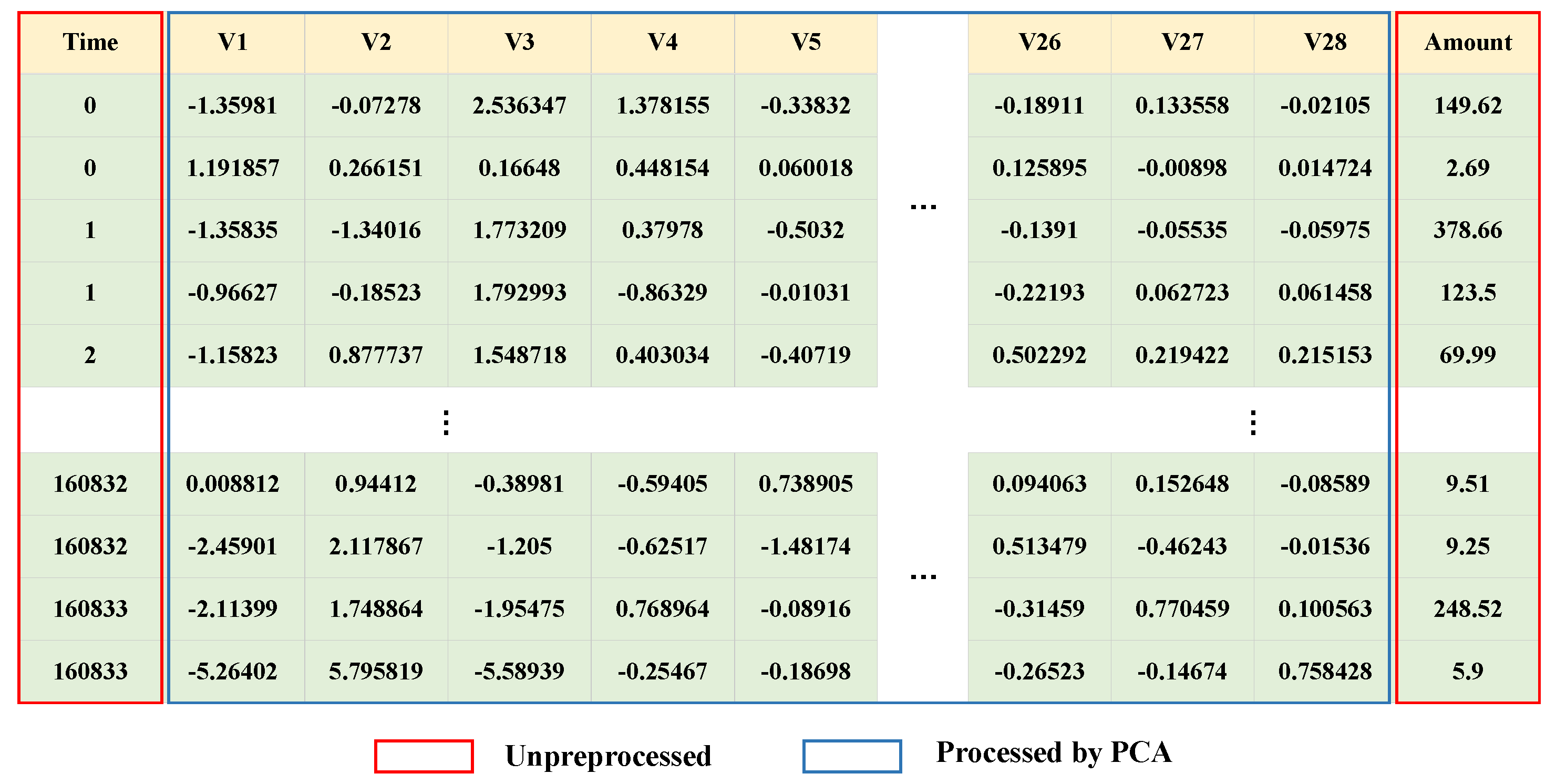
4.1. Dataset
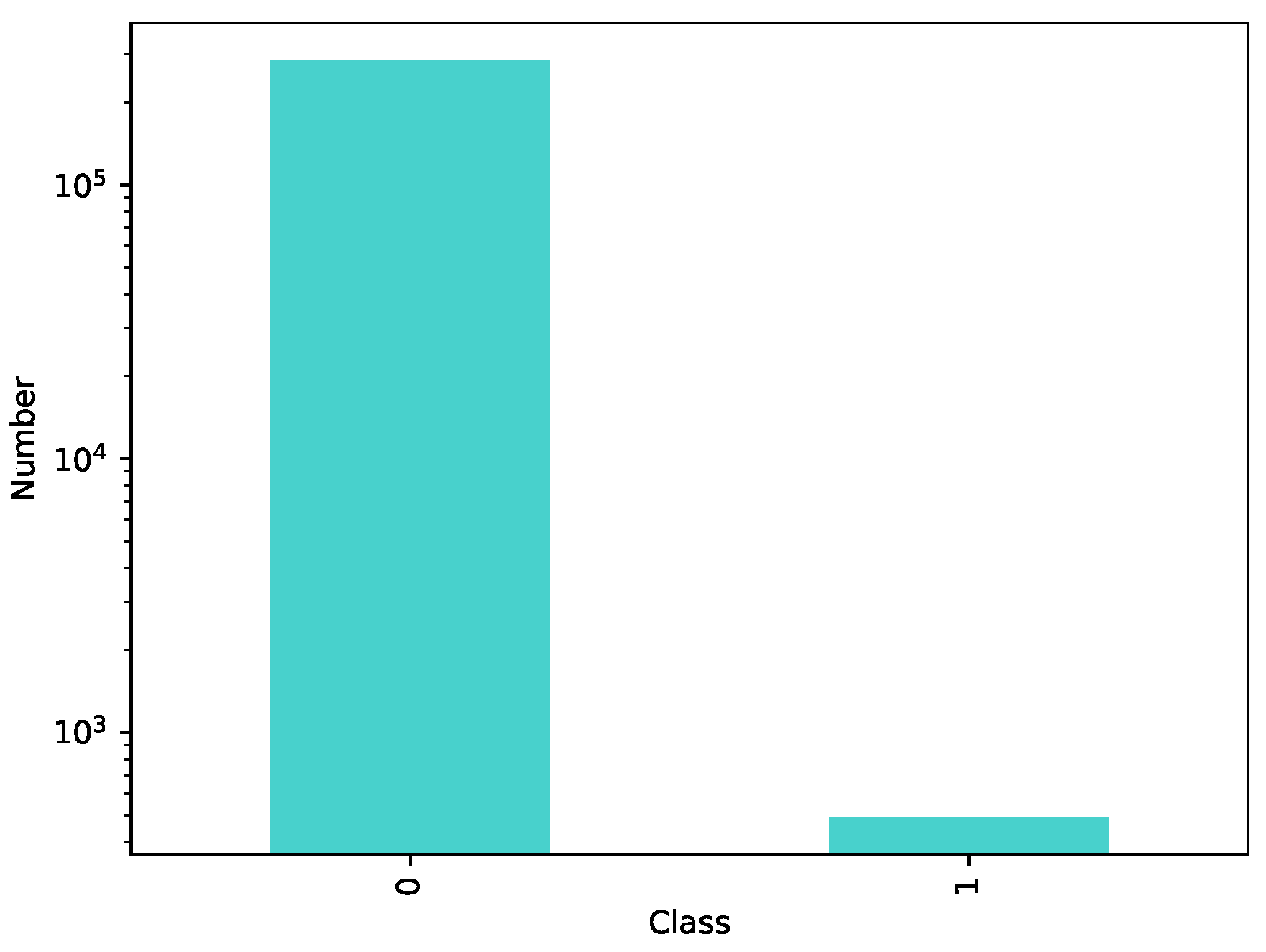
4.1.1. Credit Card Fraud Detection Dataset
4.1.2. IEEE-CIS Fraud Detection Dataset
4.2. Experimental Setup
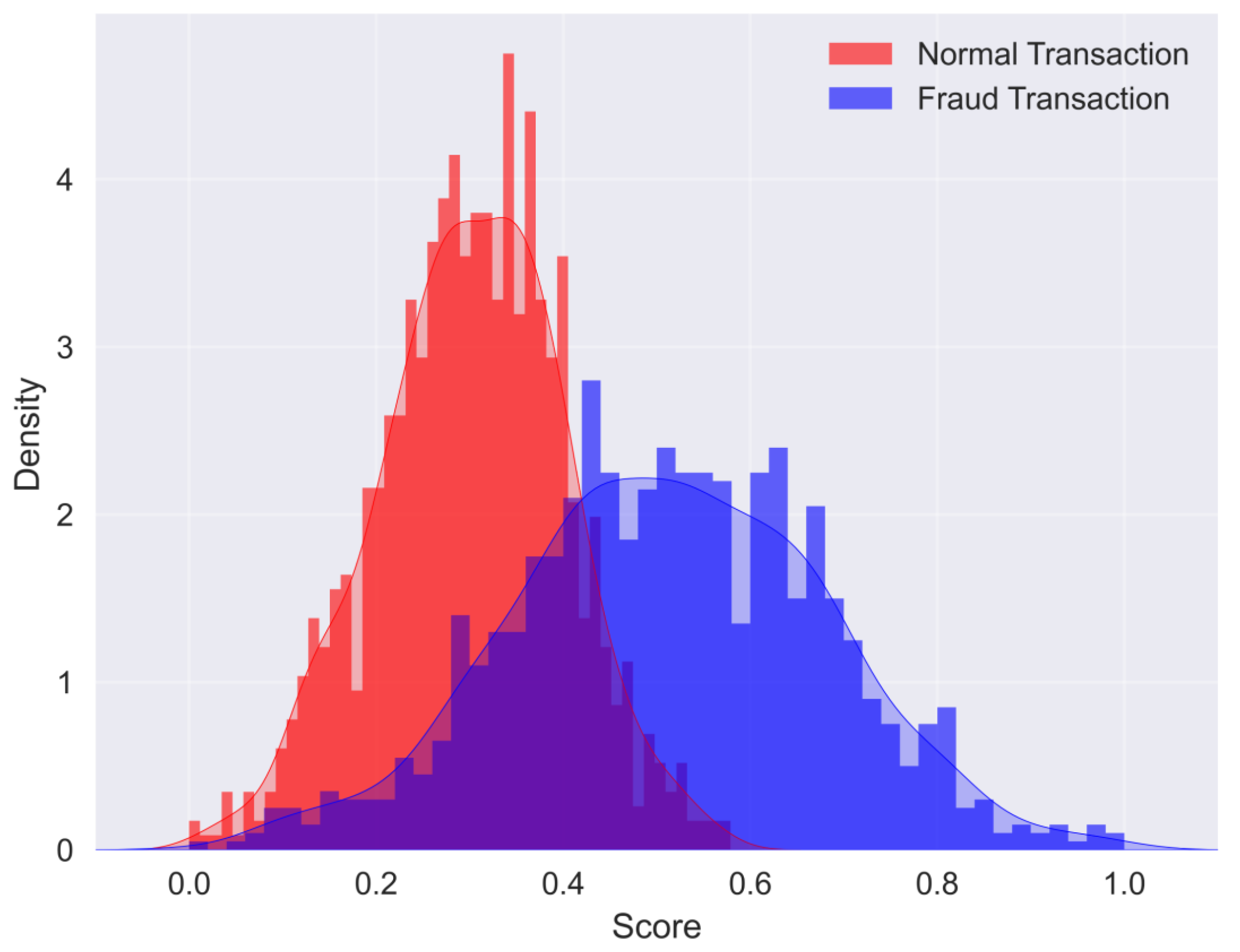
4.3. Threshold Setting
4.4. Model Comparison Experiment
4.4.1. Comparative Experiment on Kaggle Credit Card Fraud Detection Dataset
4.4.2. Comparative Experiment on IEEE-CIS Fraud Detection Dataset
4.5. Model Ablation Experiment
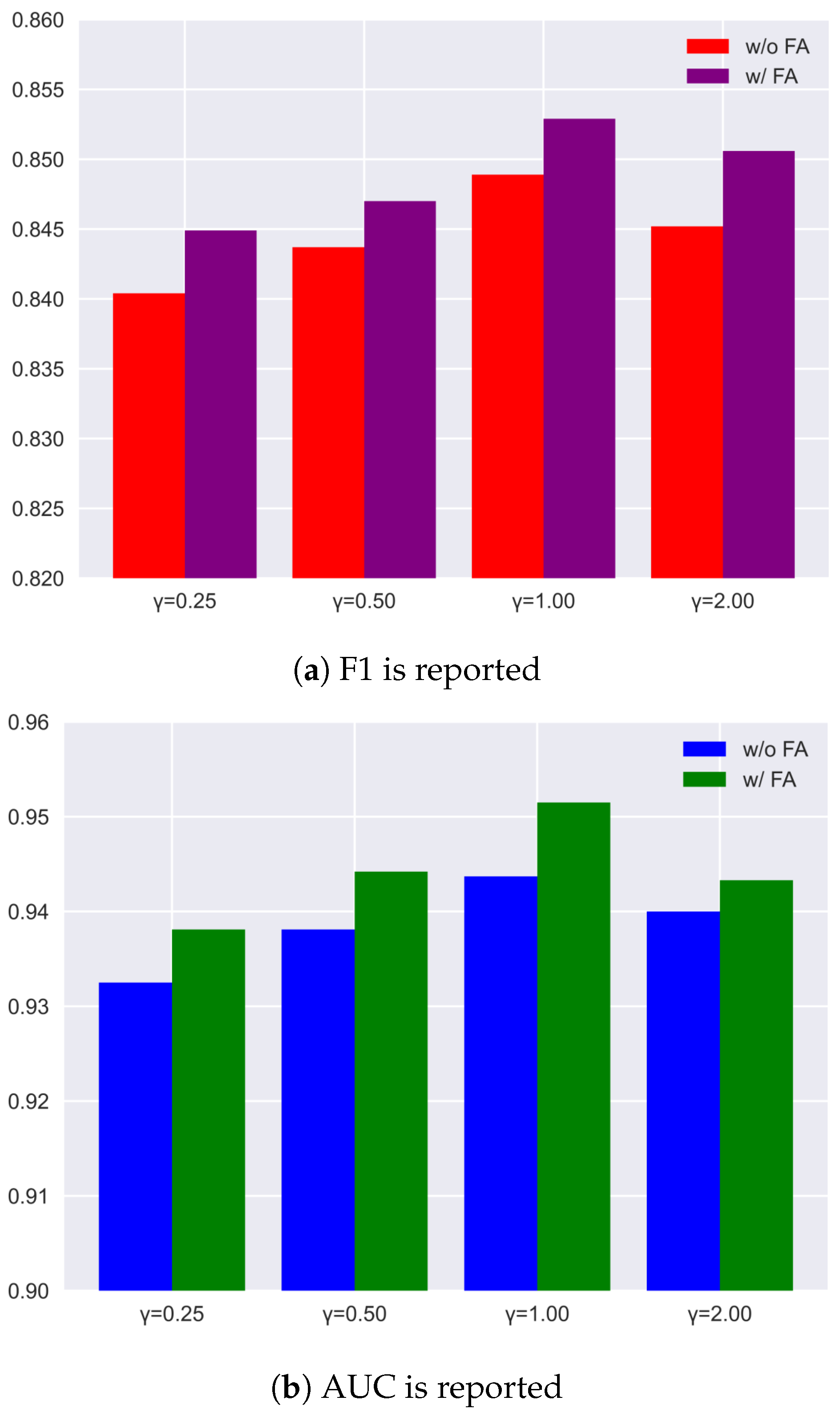
4.5.1. Ablation for Channel
4.5.2. Ablation for Loss Function
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Haoxiang, W.; Smys, S. Overview of configuring adaptive activation functions for deep neural networks-a comparative study. J. Ubiquitous Comput. Commun. Technol. 2021, 3, 10–22. [Google Scholar]
- Zhang, R.; Zheng, F.; Min, W. Sequential behavioral data processing using deep learning and the Markov transition field in online fraud detection. arXiv 2018, arXiv:1808.05329. [Google Scholar]
- Sun, W.; Yang, C.G.; Qi, J.X. Credit risk assessment in commercial banks based on support vector machines. In Proceedings of the 2006 International Conference on Machine Learning and Cybernetics, Dalian, China, 13–16 August 2006; pp. 2430–2433. [Google Scholar]
- Smys, S.; Raj, J.S. Analysis of deep learning techniques for early detection of depression on social media network-a comparative study. J. Trends Comput. Sci. Smart Technol. 2021, 3, 24–39. [Google Scholar]
- Thennakoon, A.; Bhagyani, C.; Premadasa, S.; Mihiranga, S.; Kuruwitaarachchi, N. Real-time credit card fraud detection using machine learning. In Proceedings of the 2019 9th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 10–11 January 2019; pp. 488–493. [Google Scholar]
- Sailusha, R.; Gnaneswar, V.; Ramesh, R.; Rao, G.R. Credit card fraud detection using machine learning. In Proceedings of the 2020 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 13–15 May 2020; pp. 1264–1270. [Google Scholar]
- Rtayli, N.; Enneya, N. Enhanced credit card fraud detection based on SVM-recursive feature elimination and hyper-parameters optimization. J. Inf. Secur. Appl. 2020, 55, 102596. [Google Scholar] [CrossRef]
- Ileberi, E.; Sun, Y.; Wang, Z. A machine learning based credit card fraud detection using the GA algorithm for feature selection. J. Big Data 2022, 9, 24. [Google Scholar] [CrossRef]
- Kim, E.; Lee, J.; Shin, H.; Yang, H.; Cho, S.; Nam, S.k.; Song, Y.; Yoon, J.A.; Kim, J.I. Champion-challenger analysis for credit card fraud detection: Hybrid ensemble and deep learning. Expert Syst. Appl. 2019, 128, 214–224. [Google Scholar] [CrossRef]
- Maniraj, S.; Saini, A.; Ahmed, S.; Sarkar, S. Credit card fraud detection using machine learning and data science. Int. J. Eng. Res. 2019, 8, 110–115. [Google Scholar] [CrossRef]
- Tiwari, P.; Mehta, S.; Sakhuja, N.; Kumar, J.; Singh, A.K. Credit card fraud detection using machine learning: A study. arXiv 2021, arXiv:2108.10005. [Google Scholar]
- Eckerli, F.; Osterrieder, J. Generative adversarial networks in finance: An overview. arXiv 2021, arXiv:2106.06364. [Google Scholar] [CrossRef]
- Zou, J.; Zhang, J.; Jiang, P. Credit card fraud detection using autoencoder neural network. arXiv 2019, arXiv:1908.11553. [Google Scholar]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-supervised learning: Generative or contrastive. IEEE Trans. Knowl. Data Eng. 2021, 35, 857–876. [Google Scholar] [CrossRef]
- Albahli, S.; Nazir, T.; Mehmood, A.; Irtaza, A.; Alkhalifah, A.; Albattah, W. AEI-DNET: A novel densenet model with an autoencoder for the stock market predictions using stock technical indicators. Electronics 2022, 11, 611. [Google Scholar] [CrossRef]
- Chen, R.C.; Chen, T.S.; Lin, C.C. A new binary support vector system for increasing detection rate of credit card fraud. Int. J. Pattern Recognit. Artif. Intell. 2006, 20, 227–239. [Google Scholar] [CrossRef]
- Khan, A.; Singh, T.; Sinhal, A. Implement credit card fraudulent detection system using observation probabilistic in hidden markov model. In Proceedings of the 2012 Nirma University International Conference on Engineering (NUiCONE), Ahmedabad, India, 6–8 December 2012; pp. 1–6. [Google Scholar]
- Zareapoor, M.; Shamsolmoali, P. Application of credit card fraud detection: Based on bagging ensemble classifier. Procedia Comput. Sci. 2015, 48, 679–685. [Google Scholar] [CrossRef] [Green Version]
- Yee, O.S.; Sagadevan, S.; Malim, N.H.A.H. Credit card fraud detection using machine learning as data mining technique. J. Telecommun. Electron. Comput. Eng. 2018, 10, 23–27. [Google Scholar]
- Lu, C.; Xia, M.; Lin, H. Multi-scale strip pooling feature aggregation network for cloud and cloud shadow segmentation. Neural Comput. Appl. 2022, 34, 6149–6162. [Google Scholar] [CrossRef]
- Qu, Y.; Xia, M.; Zhang, Y. Strip pooling channel spatial attention network for the segmentation of cloud and cloud shadow. Comput. Geosci. 2021, 157, 104940. [Google Scholar] [CrossRef]
- Wang, Z.; Xia, M.; Lu, M.; Pan, L.; Liu, J. Parameter Identification in Power Transmission Systems Based on Graph Convolution Network. IEEE Trans. Power Deliv. 2022, 37, 3155–3163. [Google Scholar] [CrossRef]
- Chen, J.; Xia, M.; Wang, D.; Lin, H. Double Branch Parallel Network for Segmentation of Buildings and Waters in Remote Sensing Images. Remote Sens. 2023, 15, 1536. [Google Scholar] [CrossRef]
- Zhang, C.; Weng, L.; Ding, L.; Xia, M.; Lin, H. CRSNet: Cloud and Cloud Shadow Refinement Segmentation Networks for Remote Sensing Imagery. Remote Sens. 2023, 15, 1664. [Google Scholar] [CrossRef]
- Ma, Z.; Xia, M.; Lin, H.; Qian, M.; Zhang, Y. FENet: Feature enhancement network for land cover classification. Int. J. Remote Sens. 2023, 44, 1702–1725. [Google Scholar] [CrossRef]
- Wang, D.; Weng, L.; Xia, M.; Lin, H. MBCNet: Multi-Branch Collaborative Change-Detection Network Based on Siamese Structure. Remote Sens. 2023, 15, 2237. [Google Scholar] [CrossRef]
- Fu, K.; Cheng, D.; Tu, Y.; Zhang, L. Credit card fraud detection using convolutional neural networks. In Proceedings of the Neural Information Processing: 23rd International Conference, ICONIP 2016, Kyoto, Japan, 16–21 October 2016; Proceedings, Part III 23; Springer: Berlin/Heidelberg, Germany, 2016; pp. 483–490. [Google Scholar]
- Chouiekh, A.; Haj, E.H.I.E. Convnets for fraud detection analysis. Procedia Comput. Sci. 2018, 127, 133–138. [Google Scholar] [CrossRef]
- Saia, R.; Carta, S. Evaluating Credit Card Transactions in the Frequency Domain for a Proactive Fraud Detection Approach. In Proceedings of the SECRYPT, Madrid, Spain, 26–28 July 2017; pp. 335–342. [Google Scholar]
- Fiore, U.; De Santis, A.; Perla, F.; Zanetti, P.; Palmieri, F. Using generative adversarial networks for improving classification effectiveness in credit card fraud detection. Inf. Sci. 2019, 479, 448–455. [Google Scholar] [CrossRef]
- Saia, R.; Carta, S. Evaluating the benefits of using proactive transformed-domain-based techniques in fraud detection tasks. Future Gener. Comput. Syst. 2019, 93, 18–32. [Google Scholar] [CrossRef] [Green Version]
- Esenogho, E.; Mienye, I.D.; Swart, T.G.; Aruleba, K.; Obaido, G. A neural network ensemble with feature engineering for improved credit card fraud detection. IEEE Access 2022, 10, 16400–16407. [Google Scholar] [CrossRef]
- Mohmad, Y.A. Credit Card Fraud Detection Using LSTM Algorithm. Wasit J. Comput. Math. Sci. 2022, 1, 39–53. [Google Scholar]
- Schapire, R.E. A brief introduction to boosting. In Proceedings of the Ijcai, Stockholm, Sweden, 31 July–6 August 1999; Volume 99, pp. 1401–1406. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Zhang, S.; Wang, L. STPGTN—A Multi-Branch Parameters Identification Method Considering Spatial Constraints and Transient Measurement Data. Comput. Model. Eng. Sci. 2023, 136, 2635–2654. [Google Scholar] [CrossRef]
- Najadat, H.; Altiti, O.; Aqouleh, A.A.; Younes, M. Credit card fraud detection based on machine and deep learning. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; pp. 204–208. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. C4. 5: Programs for Machine Learning; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Meng, C.; Zhou, L.; Liu, B. A case study in credit fraud detection with SMOTE and XGboost. J. Phys. Conf. Ser. 2020, 1601, 052016. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.I.Z.; Lai, K.L. Deep convolution neural network model for credit-card fraud detection and alert. J. Artif. Intell. 2021, 3, 101–112. [Google Scholar]
- Kasasbeh, B.; Aldabaybah, B.; Ahmad, H. Multilayer perceptron artificial neural networks-based model for credit card fraud detection. Indones. J. Electr. Eng. Comput. Sci. 2022, 26, 362–373. [Google Scholar] [CrossRef]
- Fanai, H.; Abbasimehr, H. A novel combined approach based on deep Autoencoder and deep classifiers for credit card fraud detection. Expert Syst. Appl. 2023, 217, 119562. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Value |
|---|---|
| Total Number of Transactions | 284,807 |
| Number of Fraudulent Transactions | 492 |
| Percentage of Fraudulent Transactions | 0.172% |
| Number of Transaction Data Columns | 31 |
| PCA Principal Components Feature Quantity | 28 |
| Number of Labels | 1 |
| Split | Training | Test | Total | ||
|---|---|---|---|---|---|
| Class | Normal | Fraud | Normal | Fraud | Both |
| Number | 227,452 | 0 | 56,863 | 492 | 284,807 |
| Method | Model | PR | RC | F1 | AUC |
|---|---|---|---|---|---|
| Machine Learning | SVM | 0.8854 | 0.7215 | 0.7951 | 0.8586 |
| DT | 0.8837 | 0.7269 | 0.7977 | 0.8598 | |
| XG Boost | 0.8955 | 0.7280 | 0.8031 | 0.8649 | |
| KNN | 0.9032 | 0.7268 | 0.8055 | 0.8709 | |
| RF | 0.9112 | 0.7343 | 0.8132 | 0.8827 | |
| Deep Learning | LSTM | 0.9073 | 0.7391 | 0.8146 | 0.8845 |
| CNN | 0.9217 | 0.7453 | 0.8242 | 0.9075 | |
| MLP | 0.9262 | 0.7461 | 0.8265 | 0.9094 | |
| AE | 0.9528 | 0.7495 | 0.8390 | 0.9279 | |
| UAAD-FDNet w/o FA (Ours) | 0.9756 | 0.7514 | 0.8489 | 0.9437 | |
| UAAD-FDNet w/ FA (Ours) | 0.9795 | 0.7553 | 0.8529 | 0.9515 |
| Method | Model | PR | RC | F1 | AUC |
|---|---|---|---|---|---|
| Machine Learning | SVM | 0.9091 | 0.1906 | 0.3151 | 0.5783 |
| DT | 0.5206 | 0.5470 | 0.5335 | 0.7622 | |
| XG Boost | 0.9447 | 0.5915 | 0.7275 | 0.7892 | |
| KNN | 0.8358 | 0.3711 | 0.5140 | 0.6730 | |
| RF | 0.9713 | 0.5024 | 0.6623 | 0.7405 | |
| Deep Learning | LSTM | 0.8525 | 0.5854 | 0.6941 | 0.7802 |
| CNN | 0.8779 | 0.5952 | 0.7094 | 0.7837 | |
| MLP | 0.9159 | 0.5796 | 0.7099 | 0.8241 | |
| AE | 0.9055 | 0.5873 | 0.7125 | 0.8181 | |
| UAAD-FDNet w/o FA (Ours) | 0.9415 | 0.6027 | 0.7349 | 0.8390 | |
| UAAD-FDNet w/ FA (Ours) | 0.9337 | 0.6281 | 0.7510 | 0.8556 |
| PR | RC | F1 | AUC | |||
|---|---|---|---|---|---|---|
| ✓ | 0.7532 | 0.6451 | 0.6950 | 0.7443 | ||
| ✓ | ✓ | 0.9088 | 0.7306 | 0.8100 | 0.8769 | |
| ✓ | ✓ | 0.9152 | 0.7375 | 0.8168 | 0.8964 | |
| ✓ | ✓ | ✓ | 0.9795 | 0.7553 | 0.8529 | 0.9515 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, S.; Dong, R.; Wang, J.; Xia, M. Credit Card Fraud Detection Based on Unsupervised Attentional Anomaly Detection Network. Systems 2023, 11, 305. https://doi.org/10.3390/systems11060305
Jiang S, Dong R, Wang J, Xia M. Credit Card Fraud Detection Based on Unsupervised Attentional Anomaly Detection Network. Systems. 2023; 11(6):305. https://doi.org/10.3390/systems11060305
Chicago/Turabian StyleJiang, Shanshan, Ruiting Dong, Jie Wang, and Min Xia. 2023. "Credit Card Fraud Detection Based on Unsupervised Attentional Anomaly Detection Network" Systems 11, no. 6: 305. https://doi.org/10.3390/systems11060305
APA StyleJiang, S., Dong, R., Wang, J., & Xia, M. (2023). Credit Card Fraud Detection Based on Unsupervised Attentional Anomaly Detection Network. Systems, 11(6), 305. https://doi.org/10.3390/systems11060305