1. Introduction
Social manufacturing [
1,
2,
3] is based on the information-physical-social interconnection of social manufacturing resources (SMR), as well as the self-organization of social resources and collaborative interaction and information sharing. It is a future-oriented service-oriented manufacturing model that covers the deep participation of distributed producers and consumers in the whole life cycle of products. In the social manufacturing model, decentralized social manufacturing resources collaboratively perform multiple manufacturing tasks based on multiple interest coordination and social mechanisms; in other words, their processing tasks are distributed through crowdsourcing and performed by discrete social manufacturing resources. As a new SOM model, social manufacturing has the characteristics of small and microenterprises, social resources, interconnection and interaction, product personalization, organization decentralization, and distribution. Among them, decentralization is an important feature of social manufacturing that is different from other manufacturing modes. With the continuous enhancement of the flat self-organized dynamic manufacturing community, the core enterprise no longer has the dominant power in the manufacturing network, and the traditional seller’s market has gradually transferred to the buyer’s market [
1,
4]. The task scheduling of processing crowdsourcing is an important link in the social manufacturing mode. The core of the problem to be solved lies in the reasonable allocation of effective resources and the necessary optimization means. The purpose is to arrange the crowdsourcing tasks into SMRs in a reasonable and balanced way and to make a reasonable plan for the processing sequence of tasks on SMRs. Because task scheduling is a process with a complex environment and many uncertain factors, the quality of scheduling directly affects the competitiveness of social manufacturing resources involved in product manufacturing in the market. Therefore, an algorithm is needed for task scheduling and planning of SMR for collaborative manufacturing crowdsourcing tasks. In this context, the problem of processing crowdsourcing task scheduling in socialized manufacturing is proposed.
In general, except for manufacturing units that are socially dispersed, the processing crowdsourcing task scheduling problem in communalized manufacturing can usually be classified as the flexible job shop scheduling problem (FJSP) [
5], and the FJSP problem has been proven to be an NP-hard problem [
6]. For this difficult problem, experts and scholars have conducted decades of research and proposed many methods to solve it. Among them, the classical methods include the Lagrangian relaxation algorithm [
7], dynamic programming [
8], and branch-and-bound algorithm [
9]; however, these classical solution methods have more or less some restrictions, such as requiring the function to be derivable, or convex, or the solution size cannot be too large, which restrict their applications. To overcome these shortcomings, scholars have developed heuristic algorithms, such as genetic algorithms [
10,
11], differential evolutionary algorithms [
12], ant colony algorithms [
13], particle swarm algorithms [
14,
15,
16], artificial bee colony algorithms [
17], and other intelligent optimization algorithms; however, traditional heuristic algorithms often have the disadvantages of slow running speed and easy to fall into local optimality in the late iteration. To address these drawbacks, experts and scholars at home and abroad have proposed many improvements in using them to solve FJSP, e.g., Wang et al. [
18] designed three heuristic strategies and proposed a new artificial bee colony algorithm HMABC to achieve scheduling of practical production activities; Yuan et al. [
19] developed a new transformation mechanism to enable differential evolutionary algorithms on continuous domains to explore discrete FJP problems; Sun et al. [
20] proposed a method for combining crossover and variational operators considering machine load balancing and designed an improved hybrid genetic algorithm HGA-VNS for local search of critical processes on critical paths.
Currently, the research for FJSP is mainly in considering novel conditions such as uncertainties and green low-carbon requirements and constructing novel solution algorithms such as multiobjective intelligent optimization and deep learning. For example, Xu et al. [
21] proposed a load-balancing-based step-size adaptive discrete particle swarm algorithm (LS-DPSO) to solve the G-FSP model. Wang et al. [
22] considered the maximum completion time, total delay time, and total energy consumption of the job and used the hybrid adaptive differential evolution algorithm (HADE) to solve it. Lou et al. [
23] combined adaptive local search and a multiobjective evolutionary algorithm and proposed a multiobjective modal algorithm based on learning decomposition (MOMA-LD) to solve the model. Yan et al. [
24] studied the FJP problem with the objectives of maximum completion time, total workload, critical machine workload, and minimum advance/delay penalties and proposed an improved ant colony algorithm to solve the problem. Tian et al. [
25] established an algorithm with the objectives of work duration, total machine load, machine on/off times, and tool change times as the objectives of a multiobjective optimization model and solved the model using NSGA-II.
Although more research has been conducted for FJSP, it has mainly focused on scheduling production lines within a single plant. Due to the similarity of work conditions, it has gradually been applied in recent years in areas such as aerospace materials manufacturing [
18] and distributed factory production scheduling [
26], while further research is needed in processing crowdsourcing task scheduling. The objective of this study is to develop a mixed-integer programming model for scheduling processing crowdsourcing tasks in community-based manufacturing and to design algorithms to solve it in order to improve the productivity of processing crowdsourcing tasks. In this task scheduling optimization problem, one or more SMRs with the ability to provide specialized manufacturing services externally are regarded as social manufacturing units (SMU), which are characterized by socialization, decentralization, and specialization. SMRs may come from traditional large- and medium-sized enterprises that decompose and reorganize their internal manufacturing resources into several small and microenterprises with independent manufacturing service capabilities or from emerging small and microenterprises in market segments, start-up companies, or individuals with professional skills [
3]. Each individual crowdsourced task will be coordinated by multiple decentralized SMUs to produce a complex product. For this purpose, the manufacturing task of the product is decomposed, and the manufacturing of a collection of parts or components in the product is defined as tasks, and the collection of manufacturing operations of parts or components is defined as subtasks. The manufacturing of a product can be decomposed into multiple tasks, and each task can be further decomposed into more subtasks; each subtask can be processed by multiple SMUs, and all subtasks of the same task have a serial order constraint relationship with each other. Then, all subtasks are matched with SMUs according to the optimization objective to get the optimal scheduling scheme.
Figure 1 shows a conceptual model for processing crowdsourced task scheduling in social manufacturing.
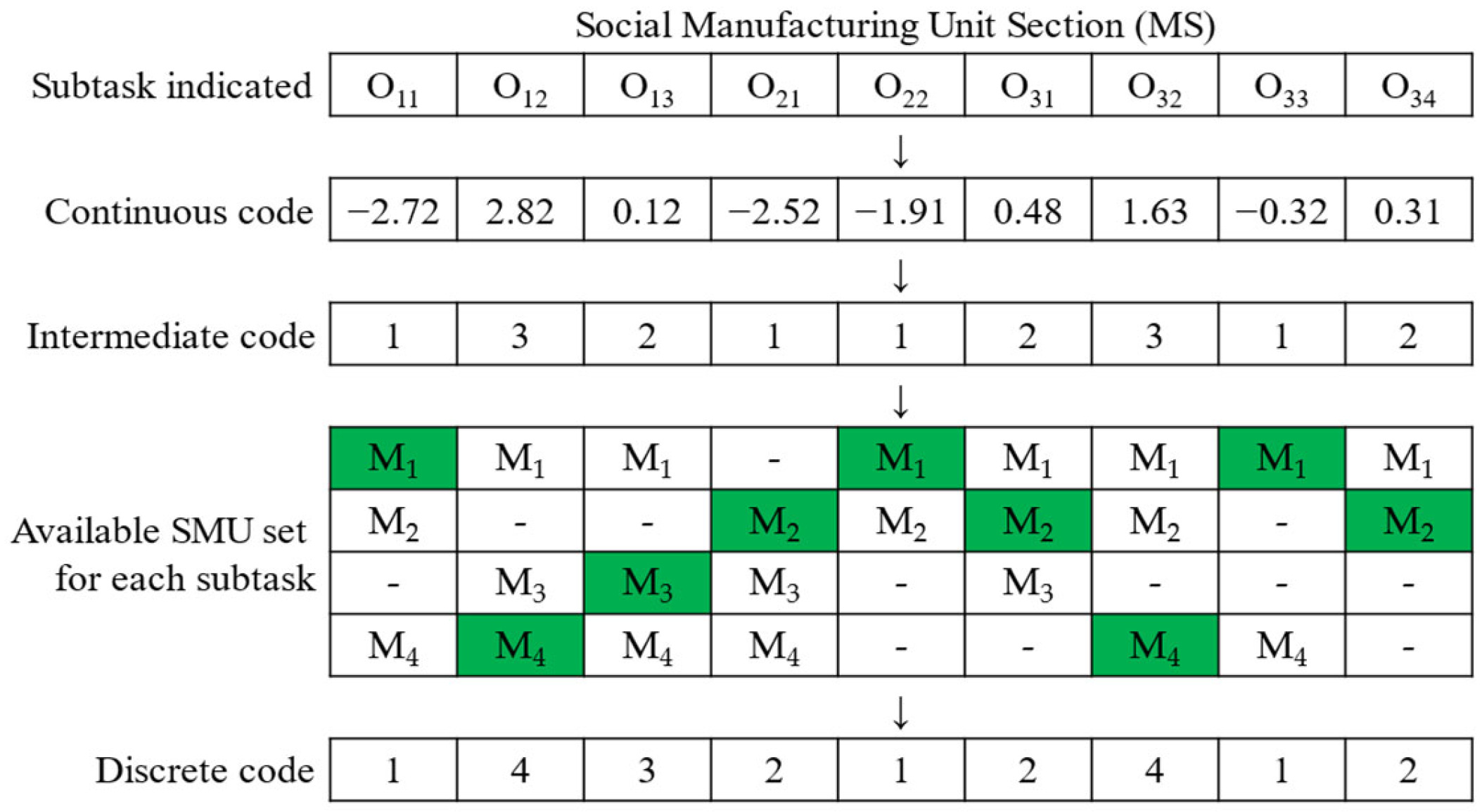
This study addresses the scheduling problem of processing crowdsourcing tasks in socialized manufacturing, establishes a mathematical model of scheduling with the objective of minimizing the maximum completion time, and proposes an improved artificial hummingbird algorithm (IAHA) to solve it. For its discrete characteristics, we divide the problem into two subproblems—social manufacturing unit selection and subtask sequence—and encode them separately according to the subproblem characteristics, match different decoding for the two encodings, and use greedy decoding methods to improve the quality of the solution. To improve the quality of the initial population of the IAHA, we used the initialization rules of global selection, local selection, and random selection (GLR). To enhance the merit-seeking ability of the IAHA, we used the Levy flight to improve the guided foraging and territorial foraging of the IAHA and the simplex search strategy (SSS) to improve the migration foraging of the IAHA. We designed four experiments, and the experiment results proved the superiority and effectiveness of the IAHA.
The rest of the paper is organized as follows:
Section 2 defines the processing crowdsourcing task scheduling problem in social manufacturing and develops a mathematical model of the problem.
Section 3 illustrates the IAHA in detail with a problem case.
Section 4 conducts four experiments and discusses the results of the IAHA’s experiments on the benchmark and crowdsourcing case.
Section 5 summarizes the main contents of the paper and points out future research directions.
4. Experimental Results and Discussion
Four sets of experiments are conducted in the section: (1) designing orthogonal experiments to configure the optimal combination of parameters for the IAHA; (2) discussing the performance improvement of the improved strategy of the IAHA over the AHA and its variants; (3) comparing the performance with algorithms proposed by other scholars in a standard algorithm; (4) simulating a real processing crowdsourcing environment for scheduling. And the first three sets of experiments are checked for significant differences in the experimental results by the Friedman test [
36]. At present, there is no public crowdsourcing task data set in the research of social manufacturing, so this paper adopts Kacem [
37] and Brandimarte [
38] standard cases, which are commonly used in FJSP, in the first three experiments. Kacem and Brandimarte belong to total FJSP(T-FJSP) and partial FJSP(P-FJSP), respectively. The expression of T-FJSP and P-FJSP in this paper is that subtasks can be processed on any SMU, and subtasks can only be processed on some SMU, respectively. T-FJSP belongs to the P-FJSP category.
The hardware environment for the simulation experiments in the study is Intel(R) Core (TM) i5-10400 CPU @ 2.90 GHz; RAM 16 GB; software environment is Windows 10, written in Python, simulation platform PyCharm 2020.1.
4.1. Comparison of Orthogonal Experiments of Parameters
The size of the parameters has a large impact on the performance of the IAHA. Therefore, we need a reasonable configuration. The main parameters of the IAHA are shown in
Table 3.
In the IAHA, r1, r2, and r3 determine the choice of flight skill each time foraging is performed, and the sum of the three parameters is one, which can actually be considered as two parameters. f1 and f2 determine the foraging mode chosen each time, and the sum of f1 and f2 is 1, which can be considered as one parameter. The IAHA only performs migration foraging once every m iteration, so the influence of γ and β in SSS on the IAHA’s foraging performance is low, and in order to balance the convergence speed of SSS with the foraging performance, γ = 2 and β = 0.5 are often taken. Finally, there are five important parameters that have a great influence on the performance of the IAHA, which are δ, r1, r2, f1, and m.
We designed orthogonal experiments to configure the best parameter combinations, and the above five parameters are set as five factors with four levels for each factor. According to the principle of orthogonal experimental design, only 16(4
2 = 16) sets of parameter combinations need to be tested to find the best parameter configuration. The orthogonal test table
L16(4
5) is shown in
Table 4.
In the orthogonal experiments, the number of iterations of the algorithm is 200, and the population size is 200. Five cases of the standard test case Kacem [
37] are used for the experiments to adjust the parameters, and 10 experiments are conducted for each case to take the average value as the experimental results;
Table 5 shows the experimental results of the orthogonal experiments.
Friedman’s ranking of the experimental results was performed, and the sum of the result ranking of each experimental scheme in each case was calculated to obtain the final ranking of the schemes. The ranking and final ranking of each experimental scheme are shown in
Table 6, which shows that the final ranking of experiment 10 is better than the other experimental schemes.
Significance tests were performed on the ranking results of this orthogonal test scheme. The original hypothesis H0: there are no significant differences in the results of the orthogonal experiment. The alternative hypothesis H1: there are significant differences in the results of the orthogonal experiment.
The results of the Friedman statistics of the program are shown in
Table 7. From
Table 7, the Friedman statistic is
χ2 = 46.17, and the degree of freedom is
k-1 = 15. When the significance level
α is 0.05, querying the chi-square distribution table yields
= 25. Since
χ2 >
,
H0 is rejected, and
H1 is accepted: there are significant differences in the results of the orthogonal experiment. When the significance level
α is 0.01, the chi-square distribution table
= 30.58. Since
χ2 >
,
H0 is rejected, and
H1 is accepted: there are significant differences in the results of the orthogonal experiment.
In summary, the results of the Friedman test with two significance levels of 0.05 and 0.01, in turn, showed that there are significant differences in the results obtained from this orthogonal test scheme, and the best performance was achieved with the parameter combination of test 10. Therefore, the parameter combination in test 10 was used as the algorithm parameter values for the IAHA in the later experiments with δ = 4, r1 = 0.27, r2 = 0.30, f1 = 0.55, and m = 10.
4.2. Comparison of IAHA and Other Variants of AHA
To verify the effects of the improvements made on the performance of the IAHA, variants of the AHA were constructed for comparison experiments, as shown in
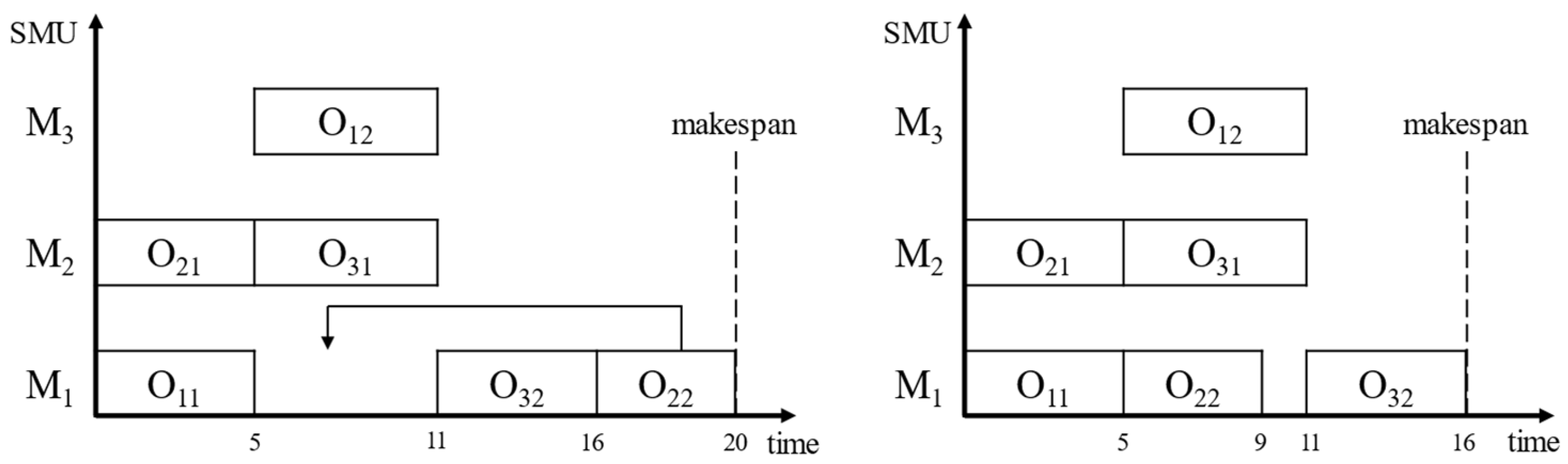
Table 8. Four improvement strategies were used to improve the AHA in three aspects where the GDM is an improvement of the decoding method, GLR is the initialization of the population using GLR, and the Levy flight and SSS are improvements of the foraging method for hummingbirds.
In the comparison experiments, the number of iterations of all algorithms is 500, and the population size is 300. Five cases of the standard case Kacem are used for experiments to compare the effect of the improved method on the performance of the algorithm. Ten experiments are conducted for each case, and the mean square error (
MSE) is calculated by Equation (22) and used as the experimental results along with the mean (
Mean), as shown in
Table 9.
where
n = 10;
ri is the maximum completion time obtained for each experiment;
rmin is the optimal value of the maximum completion time known to be studied for each case, The
rmin of Kacem 1–5 [
37] are 11, 14, 11, 7, and 11, respectively [
38].
According to the experimental results, the AHA deviates from other algorithms in Mean and has difficulty in searching rmin due to its relatively simple foraging method, which leads to its poor performance on MSE. The AHA-Levy-SSS improves the foraging method, the global and local search ability of the algorithm is enhanced, and, finally, outperforms the AHA on MSE. The AHA-GDM and AHA-GLR optimized the decoding method and initial population; the performance was slightly better than the AHA but still inferior to the AHA-Levy-SSS due to its relatively poor foraging ability. The IAHA achieved the best performance on both Mean and MSE.
Friedman’s ranking was performed based on the
Mean of the experimental results, and the sum of the result ranking of each algorithm in each case was calculated to derive the final ranking of the scheme. The ranking and final ranking of each algorithm are shown in
Table 10.
Significance tests were performed on the ranking results of five algorithms. The original hypothesis H0: there are no significant differences in the performance of each algorithm. The alternative hypothesis H1: there are significant differences in the performance of each algorithm.
The results of Friedman’s statistics for the comparison experiments are shown in
Table 11. From
Table 11, the Friedman statistic is
χ2 = 18.64, and the degree of freedom is
k − 1 = 4. When the significance level
α is 0.05, querying the chi-square distribution table yields
= 9.49. Since
χ2 >
,
H0 is rejected, and
H1 is accepted: there are significant differences in the performance of each algorithm. When the significance level
α is 0.01, the chi-square distribution table
= 13.28. Since
χ2 >
,
H0 is rejected, and
H1 is accepted: there are significant differences in the performance of each algorithm.
To observe the specific performance of the algorithms during iterations,
Figure 7 plots the convergence curves of the maximum completion time (makespan) with the number of iterations for the five algorithms in one iteration of Kacem case 5. The populations diverge at the first generation of individuals. The IAHA and AHA-GLR with GLR showed excellent makespan, demonstrating that GLR significantly improved the quality of the initial populations. As iterations increase, the AHA-Levy-SSS, with its excellent search capability, quickly closes the gap with the AHA and AHA-GDM and surpasses the AHA-GLR after 50 iterations, proving that Levy and SSS enhance the search capability of the AHA and accelerate the convergence speed. Although the AHA-GDM is inferior to the AHA-GLR and AHA-Levy-SSS, it is always ahead of the AHA throughout the iterations, and the AHA-Levy-SSS, which lacks the GDM, always lags behind the IAHA at iteration number 100–200 due to the lack of GDM’s ability to optimize the scheduling results, proving that the GDM has the ability to optimize the scheduling results.
In summary, the results of the Friedman test with two significance levels of 0.05 and 0.01 show that the results obtained by the five algorithms are significantly different, and the IAHA achieves the best performance. The four strategies play major roles in different stages of the IAHA. In the early IAHA, the prepopulation quality is optimized mainly by GLR so that the IAHA can find relatively good scheduling results without too many iterations; in the middle IAHA iteration, the optimization-seeking ability of the algorithm is enhanced mainly by Levy and SSS to make it converge quickly; in the late IAHA iteration, the quality of scheduling results is improved mainly by the GDM.
4.3. Comparison of IAHA and Other Algorithms
To verify the effectiveness and superiority of the IAHA in solving crowdsourced task scheduling problems, the first 10 cases from the standard Brandimarte case [
38] and 5 cases from Kacem [
37], which are more commonly studied, are selected for experiments. The IAHA adjusts the population size and the number of iterations appropriately according to the case size, and the adjustment results are shown in
Table 12, where n is the number of tasks and m is the SMU number.
The IAHA was run five times independently on each case to take the optimal solution, and the experimental results were compared with other algorithms, as in
Table 13, where
C* indicates the optimal value of makespan currently searched for that case in the literature and the optimal solution searched for by each of the Cmax algorithms, and “-” indicates that the algorithm did not provide data for that arithmetic case. The comparison algorithms are HA by Ziaee [
39], PHMH by Bozejko [
40], NIMASS by Xiong [
41], ADCSO by Jiang [
42], HLO-PSO by Ding [
43], SLGA by Chen [
44], and IAHA by the paper, where the experimental results of the comparison algorithms are from the original data in the literature.
Figure 8 shows the Gantt chart of the scheduling results obtained by the IAHA on the Mk10 case, respectively. In
Figure 8, the first number on the block represents the task number, and the second number represents the subtask number
Since the IAHA searches for C* in all five Kacem cases and many algorithms do not provide results, the comparison between the IAHA and other algorithms will not be discussed later.
To facilitate a visual comparison of the performance of the IAHA with other algorithms on the Brandimarte cases, the experimental results are converted into relative percentage deviation (
RPD).
RPD is the percentage deviation of the algorithm result with respect to
C*, which denotes the closeness of
Cmax to
C*, and is calculated as follows:
Table 14 shows the
RPD results of the seven algorithms on the test cases. The average
RPD of the IAHA achieves the smallest value, which indicates that the IAHA performs the best among the seven algorithms, especially on the Mk6 and Mk10 cases. The performance of the IAHA pulls away from the other algorithms by a large gap.
Friedman’s ranking was performed on the
RPD, and the sum of the resultant rankings of each algorithm was calculated for each case to obtain the final ranking of the solutions. The ranking and final ranking of each experimental scheme are shown in
Table 15, which shows that the final Friedman ranking of the IAHA is the best among the seven algorithms.
Significance tests were performed on the ranking results of seven algorithms. The original hypothesis H0: there are no significant differences in the performance of each algorithm. The alternative hypothesis H1: there are significant differences in the performance of each algorithm.
The results of Friedman’s statistics for the comparison experiments are shown in
Table 16. From
Table 16, the Friedman statistic is
χ2 = 26.76, and the degree of freedom is
k − 1 = 6. When the significance level
α is 0.05, querying the chi-square distribution table yields
= 12.59. Since
χ2 >
,
H0 is rejected, and
H1 is accepted: there are significant differences in the performance of each algorithm. When the significance level
α is 0.01, the chi-square distribution table
= 16.81. Since
χ2 >
,
H0 is rejected, and
H1 is accepted: there are significant differences in the performance of each algorithm.
In summary, the results of Friedman’s test with two significance levels of 0.05 and 0.01, respectively, show that there are significant differences in the performance of HA, PHMH, NIMASS, ADCSO, HLO-PSO, SLGA, and IAHA, and the IAHA has the best performance.
4.4. Application to Processing Crowdsourcing Task Scheduling
In order to further verify the effectiveness of the model and algorithm in this paper, we used 30 local small- and medium-sized manufacturing enterprises as SMUs, set the processing time of subtasks according to the enterprise scale, and simulated 15 processing crowdsourcing task data as cases. The processing crowdsourcing task case size is 15 × 30. The AHA and IAHA were used to simulate and solve them, respectively, and the parameter settings follow the results of the 4.1 orthogonal test; the number of populations is 300, and the number of iterations is 500.
The convergence curves can be obtained using the IAHA and AHA for the above case, as shown in
Figure 9. It can be seen that the makespan of the IAHA and AHA converge at 105 and 116, respectively. The IAHA obtains a significantly better solution than the AHA and has a better performance in this processing crowdsourcing case. The IAHA, due to its unique initialization method, is already significantly in the lead in the early iterations of the algorithm and plays a key role in guiding the evolutionary direction of the population. In the late iteration of the algorithm, the IAHA is more likely to obtain better solutions due to its superior foraging method improvement strategy.
Figure 10 shows the Gantt chart of the scheduling solution obtained by the IAHA.
5. Conclusions
In the social manufacturing model, dispersed manufacturing resources accomplish multiple manufacturing tasks collaboratively under multiple interest coordination and social mechanisms. In the study, a mixed-integer programming model with the optimization objective of minimizing the maximum completion time is developed for the mathematical formulation of the processing crowdsourcing task scheduling problem in social manufacturing. To solve the problem, the study proposes an improved artificial hummingbird algorithm (IAHA) as a solution algorithm for the processing crowdsourcing task scheduling problem based on a novel bionic optimization algorithm artificial hummingbird algorithm (AHA). For the discrete characteristics of the problem, the problem is divided into two subproblems: social manufacturing unit selection and subtask sequence. Suitable encodings are designed for the two subproblems, different decoding methods are matched for the two encodings, and greedy decoding methods are used to improve the quality of understanding. To improve the quality of the initial population and speed up the convergence, the IAHA used the initialization rules of global selection, local selection, and random selection. To enhance the merit-seeking ability of the IAHA, the Levy flight was used to improve the guided foraging and territorial foraging of the IAHA, and the simplex search strategy was used to improve the migration foraging of the IAHA.
Four different experiments are designed in this study: (1) the optimal combination of parameters for the IAHA in the scheduling problem is obtained through parameter orthogonality experiments; (2) the effectiveness of various improvement strategies of the IAHA is verified through comparison experiments among the IAHA and other variants of the AHA; (3) the superiority of the IAHA is demonstrated through comparison experiments between the IAHA and algorithms proposed by other scholars on standard cases; (4) the performance of the IAHA on a simulated processing crowdsourcing task case demonstrates that the IAHA can obtain a more efficient and economical scheduling solution.
The IAHA still has some limitations, such as the following: (1) The IAHA has good performance when facing relatively small-scale manufacturing environments, but the complexity of the IAHA increases when facing very large-scale environments; the solution time explodes, so the use of deep reinforcement learning and other methods should be considered to reduce the solution time. (2) The demand for low carbon in today’s society is increasing, so the multiobjective optimization problem of adding some green performance and other indicators should be considered.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}