3.3. Data Preprocessing
In order to remove the interference information in the instances, specific preprocessing steps were applied as follows:
3.3.1. Remove User Identity
In online texts, user names are frequently placed after the “@” symbol to forward the tweet to a specified user. This results in the fact that a tweet often contains a part of “@ username”. Even when a meaningful word appears as a user name, its meaning should not be considered for emotional annotation for sentences as well as full tweets. In order to avoid the bias of the subsequent emotion word matching and weight calculation that might be brought by the usernames, this study removed the username by deleting the string starting with “@” and ending with a space in the regular matching text.
3.3.2. Remove Other Noise Information
The emotional words matched in the emotional weight calculation method are all in English. This study removed the punctuation, numbers, special characters, and other contents in the texts to avoid their impacts on the efficiency of matching. However, the content behind a “#” generally refers to annotation and often contains words with a strong emotional tendency. Such contents would be contained as emotional words to participate in subsequent matching and emotional weight calculation.
3.3.3. Delete Strings Shorter Than Three Words
A major feature of the NRC dictionary is that the length of the emotional string is not less than three words. It means strings shorter than three words could not be successfully matched in the emotional dictionary and would cause invalid iteration through the dictionary. In order to avoid invalid iteration and speed up the overall matching speed, this study deleted strings shorter than three words in preprocessing. As shown in
Figure 3, “opinionated = ‘N’” means the sentence (good night) would not be included in the following analysis since the words in this sentence are less than three.
3.3.4. Word Correction
Compared with the traditional text corpus, short texts on the Internet are more colloquial. The original data in the Twitter corpus are open-access texts published by real users, containing a large number of words such as “cooooool” and “whyyyyyyyy.” These words need to be included in the judgment of emotional tendency as they express strong emotion. However, such words could not match with any words in the emotion dictionary and would result in a low accurate rate of matching. In this study, the letters that appear more than three times in a word were identified and replaced with two letters. For example, “cooooool” is restored to “cool” and “whyyyyyy” is restored to “whyy”. For the words that are still in the wrong form after the correction, spell checking would adjust them into the right words as the difference between the wrong and right forms is reduced to one letter.
3.3.5. Spell Check
Spelling problems are frequently met in the instances in the Twitter corpus and would also lead to the failure of word matching. Checking and correcting spelling is an important step in preprocessing. The main principle and basis of English spelling checking in this paper are the Bayesian algorithm and editing distance:
The study records the correct spelling as
C (for correct) and the wrong spelling as
W (for wrong). The task of spell checking is to infer that a
C given a
W occurs, which also means finding the most likely
C from several alternatives on the premise that W is known. According to the Bayesian theorem, the task is to find the Maximum value of
in Formula (1):
In this formula, indicates the probability of the occurrence of a correct word, which can be simulated based on the text library. The higher the frequency of a word in the text library, the bigger its frequency . indicates the probability of misspelling as W for the original word C. In order to simplify the problem, this study assumes that the probability of misspelling increases as the two words look more similar to each other. This assumption turns the misspelling problem into an edit distance problem. Spelling check is thus to check the frequency of all words similar to the spelled word in the text library. The word with the highest probability is the right word that the user really wants to input.
3.3.6. Word Stemming
There are a large number of word inflections in English vocabulary. For example, the words “interest”, “interesting”, and “interested” share the same stem, “interest”, but have different expressions. For such inflected words, extracting their stems can effectively improve the efficiency of word matching. Word stemming refers to the process of removing the prefix and suffix of a word to obtain the stems. It also includes converting words to their original general forms according to the dictionary when the difference between the inflected and the original word is not a prefix or suffix.
In this study, the stem was extracted by snowball method in the NLTK library.
3.4. Automatic Emotion Annotation
The main principle of the emotion labelling method proposed in this paper is based on the word matching and weight calculation of the emotion dictionary. Through the discrimination method proposed, the emotional tendency of each instance is judged and automatically labelled if the emotional tendency is obvious. Otherwise, a manual check would be carried out until, eventually, an accurate emotional corpus is obtained. The specific matching and discrimination methods are introduced as follows.
3.4.1. Words Matching
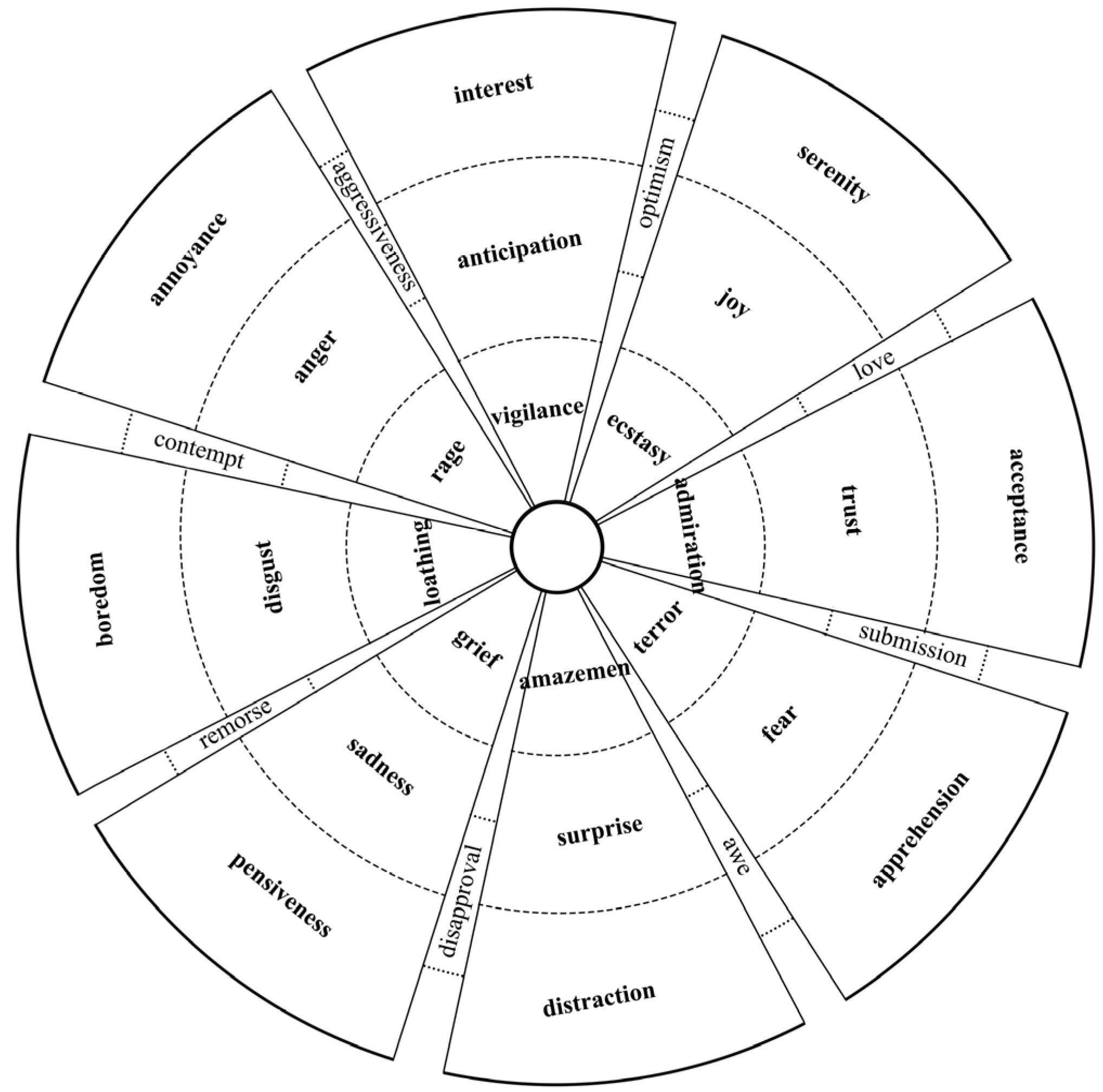
When matching, each piece of instance is regarded as a set of words. In this study, the words separated by spaces in the instance are marked in sequence with , where i represents the position of the word in the corresponding instance. In order to match the words, the i-th word is compared with the English column of the emotional dictionary. The item that is successfully matched is marked with for the result of positive emotional polarity judgement, for negative emotional polarity, for anticipation, for joy, for surprise, for trust, for anger, for disgust, for fear, and for sadness. If the composite word cannot be matched, the word is considered not to contain the emotional tendency weight value and the corresponding weight values of are all recorded as 0.
For each text, a vocabulary weight value set is obtained after matching in the form of a set of vectors with a length of 10, as shown in Formula (2).
3.4.2. Calculation of the Weight of Emotions
For each piece of short text, the study calculates the overall emotional polarity weight vector and emotional tendency weight vector separately:
3.4.3. Judgment of Emotional Polarity
The proportional value of positive and negative emotional polarity is calculated according to Formulas (5) and (6):
Here, represents the proportional value of positive emotional polarity; represents the proportional value of negative emotional polarity; and and represent the first term and the second term of the emotion weight vector , respectively.
This study sets the intensity threshold k0. If , in which is constant, the text is regarded to have positive emotional polarity. If , the text is considered negative; otherwise, it is neutral, and the text does not have strong emotional polarity.
3.4.4. Judgment of Emotional Tendency
This study calculates the sum of emotional tendencies with Formula (7).
The weight ratio corresponding to each emotional tendency is calculated according to Formula (8), where
is the set of all weights.
is the maximum value in the set
.
is the minimum value in the set
.
The study sets the upper limit of the emotional tendency threshold and the lower limit of the emotional tendency threshold , and calculates the extreme difference . For the above threshold value, the value of was set to be 0.20 and is 0.07 in this study, based on the preliminary study of the emotional tendency of the randomly chosen 500 tweets. This means that, out of the percentage of all emotional tendency weights, if the difference between the strongest emotion and the weakest emotion reaches 20 percent or more of the overall emotional tendencies, it can be determined that the emotional tendency of the text is the tendency with a larger weight. If the difference between the strongest emotion and the weakest emotion does not reach 7 percent of the overall emotional tendency, it is considered that the text has no obvious emotional tendency.
If and the emotional tendency weight value is , it means that there is only one emotional tendency. At this time, the research marks the emotional tendency value corresponding to the instance as the value corresponding to the emotional tendency with the emotional tendency value . When , the emotional tendency of the text is marked as 0, representing neutral. If or r ≥ k1, and multiple emotional tendencies with the weight value of exist, the emotional tendency of the instance would be set to 9, indicating that further manual verification is needed.
3.6. Verification
Since we semi-automatically annotated 6500 tweets that were manually labelled in the origin corpus (Sentiment140), the results of the original manual annotation could be used to test the performance of the semi-automatic annotation.
In order to evaluate the performance of the emotional polarity annotation, indicators of accuracy rate (Accuracy), precision rate (Precision), recall rate (Recall), and F Score (F-Score) were calculated. The specific definition and calculation methods are as follows:
Accuracy refers to the ratio of the number of tweets whose semi-automatic annotation results are consistent with the corpus annotation results to the total number of tweets. It is calculated with Formula (9).
Precision refers to the ratio of the number of tweets semi-automatically labelled as positive emotions to the number of tweets originally labelled as emotional tweets. It is calculated with Formula (10).
Recall refers to the ratio of the number of semi-automatically labelled tweets with emotional polarity to the number of tweets with emotions in the original corpus. It is calculated with Formula (11).
F-Score refers to the harmonic mean of precision and recall. It is calculated with Formula (12).
In the above four formulas, machine_correct represents the number of semi-automatically labelled tweets that are consistent with the original corpus, machine_marked represents the number of semi-automatically labelled tweets, and manual represents manual annotation (in this case, the result of annotation in the original corpus).
In order to evaluate the validity of emotional tendency annotation, indicators include
Precision,
Recall, and
F-Score at both micro and macro levels. The specific calculation methods are as follows:
Again, here represents the number of semi-automatically annotated tweets that are consistent with the original corpus, represents the number of semi-automatically annotated tweets, represents manual annotation (in this case, the result of annotation in the original corpus), and represents one of the eight emotional tendencies annotated.
The selection of threshold impacts the annotation results to some extent: the annotation of emotional polarities will be affected by the value of the threshold
, and the annotation of emotional tendencies will be affected by the values of the threshold
and threshold
. The selection of thresholds has no empirical formula but is rather customised and refined according to the characteristics of the corpus. As shown in the explanation of Formula (8), setting the value of
as 0.20 and
as 0.07 constitutes the best-performing threshold in the preliminary study of the emotional tendency of the randomly chosen 500 tweets. This threshold is set as Group 1. In order to better verify the effectiveness of the annotation method, the study selects two sets of thresholds for semi-automatic annotation to analyse and compare the annotation results. Group 2 is the second-best combination of thresholds in the preliminary study of the randomly chosen 500 tweets. The specific threshold selection is shown in
Table 2.




 ,
, 






{kind=link}
{kind=link}
{kind=link}