
Multi-Scale Feature Fusion with Adaptive Weighting for Diabetic Retinopathy Severity Classification


Abstract
:1. Introduction
- We design a multi-scale feature extraction method aiming at the classification of DR fundus images and the classification training is carried out by fusing the feature information of different scales in the convolution neural network.
- When fusing the features, we add adaptive weights through the attention module, global average pooling (GAP), and division process, and the weight updates adaptively if each feature block changes with the training of the CNN.
- The classification performance is better than state-of-the-art models on the APTOS 2019 Kaggle benchmark datasets.
2. Related Works
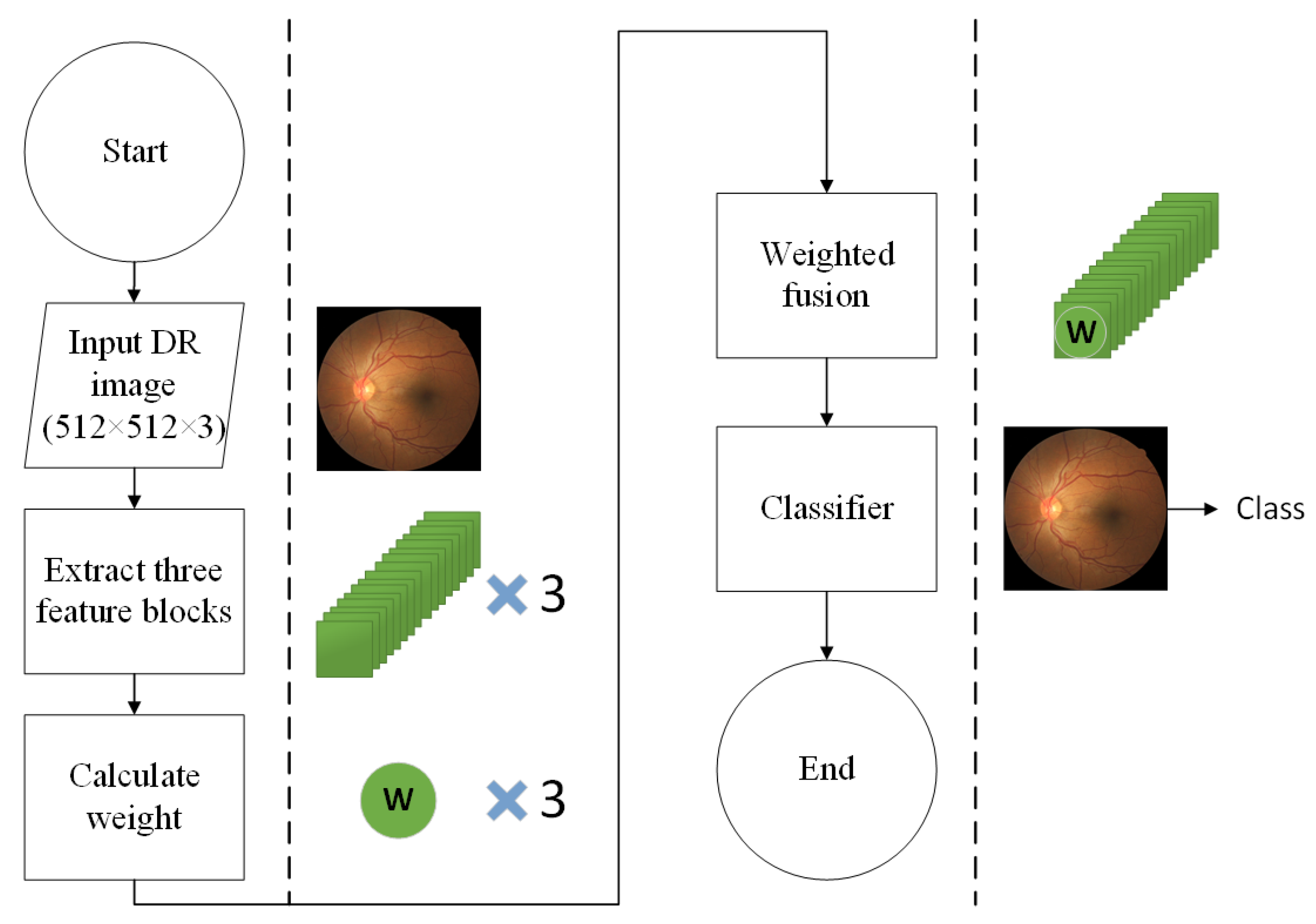
3. Proposed Method
3.1. Backbone of Model
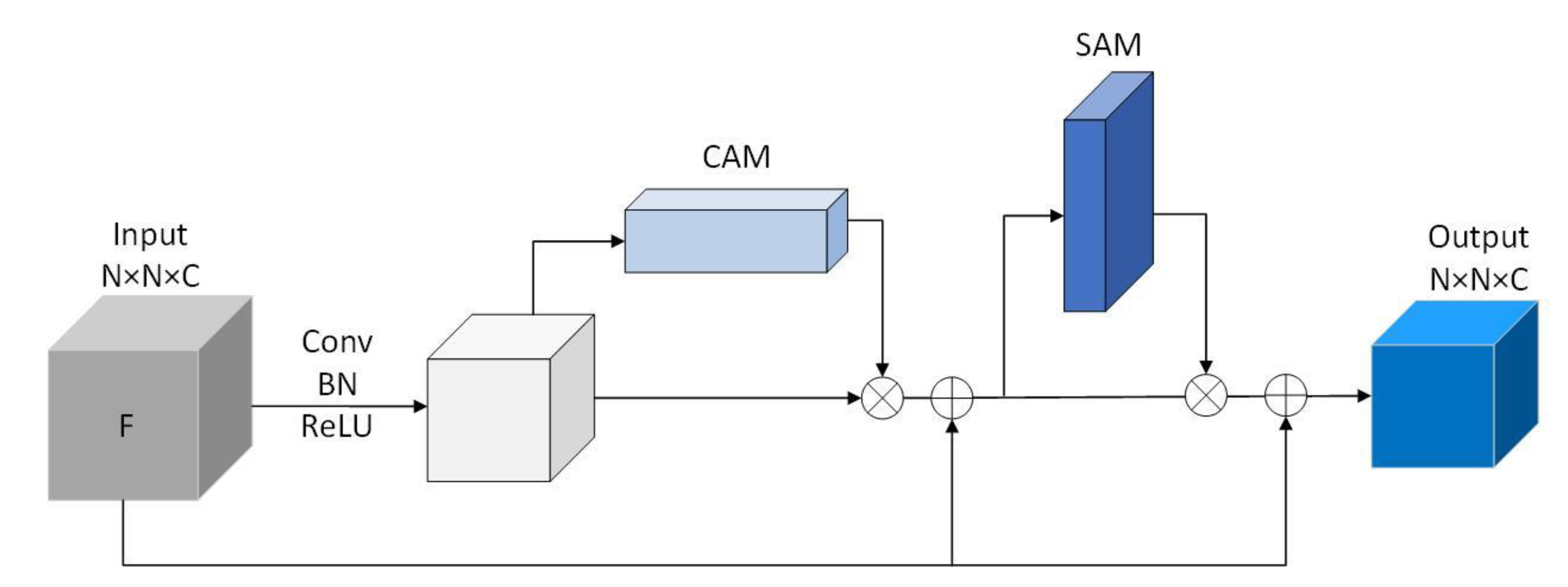
3.2. Residual Convolutional Block Attention Module
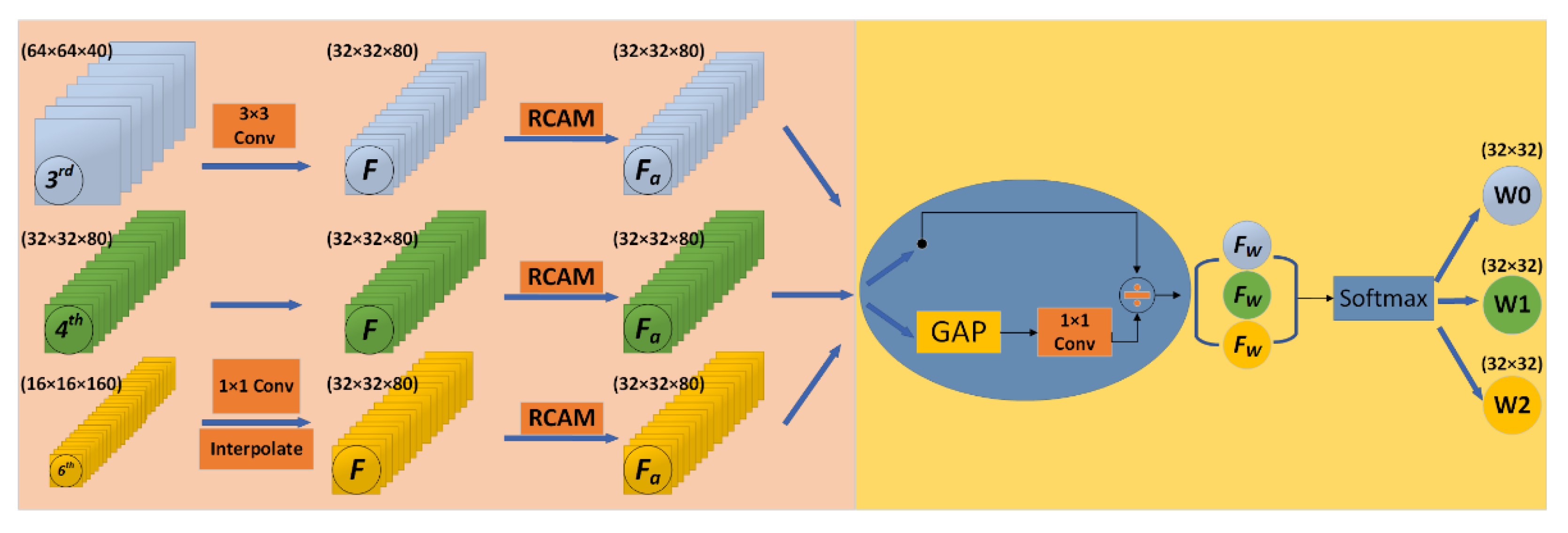
3.3. Adaptively Weighted Feature Fusion
| Algorithm 1 Identification task of DR severity using Adaptively Weighted Fusion |
| Input: Let and be the train dataset and test dataset of DR images, where . represents th color fundus image in the dataset and is the severity level of DR associated with . In the case of the DR classification task, . Output: for each Step 1: Preprocess each image in the dataset. Step 2: Feature Extraction For each preprocessed image , three different features (,,) are extracted. Feature extracted from third bottleneck layer block of MobileNet Feature extracted from fourth bottleneck layer block of MobileNet Feature extracted from sixth bottleneck layer block of MobileNet Where dimensions (W H C) of , and are 64 64 40, 32 32 80 and 16 16 160, respectively. Step 3: Feature Resizing resize the features(and) to the same shape of the feature(). For , apply a 1 1 convolution layer to compress the number of channels and then upscale with interpolation. For , apply a 3 3 convolution layer with a stride of 2. Step 4: Adaptively Weighted Fusion Let , and be the resized feature, and let be the feature extracted from attention block(RCAM) For each Let O be the merged representation. Step 5: Model Training Training dataset is prepared using the blended features , where is the feature representation of , and is the output of the softmax classifier. Train a deep neural network (DNN) using Step 6: Model evaluation The test dataset is prepared using the blended features Evaluate the performance of using the DNN in Step 5 |
3.4. Loss
4. Experimental Results
4.1. Dataset Summary
4.2. Performance Measures
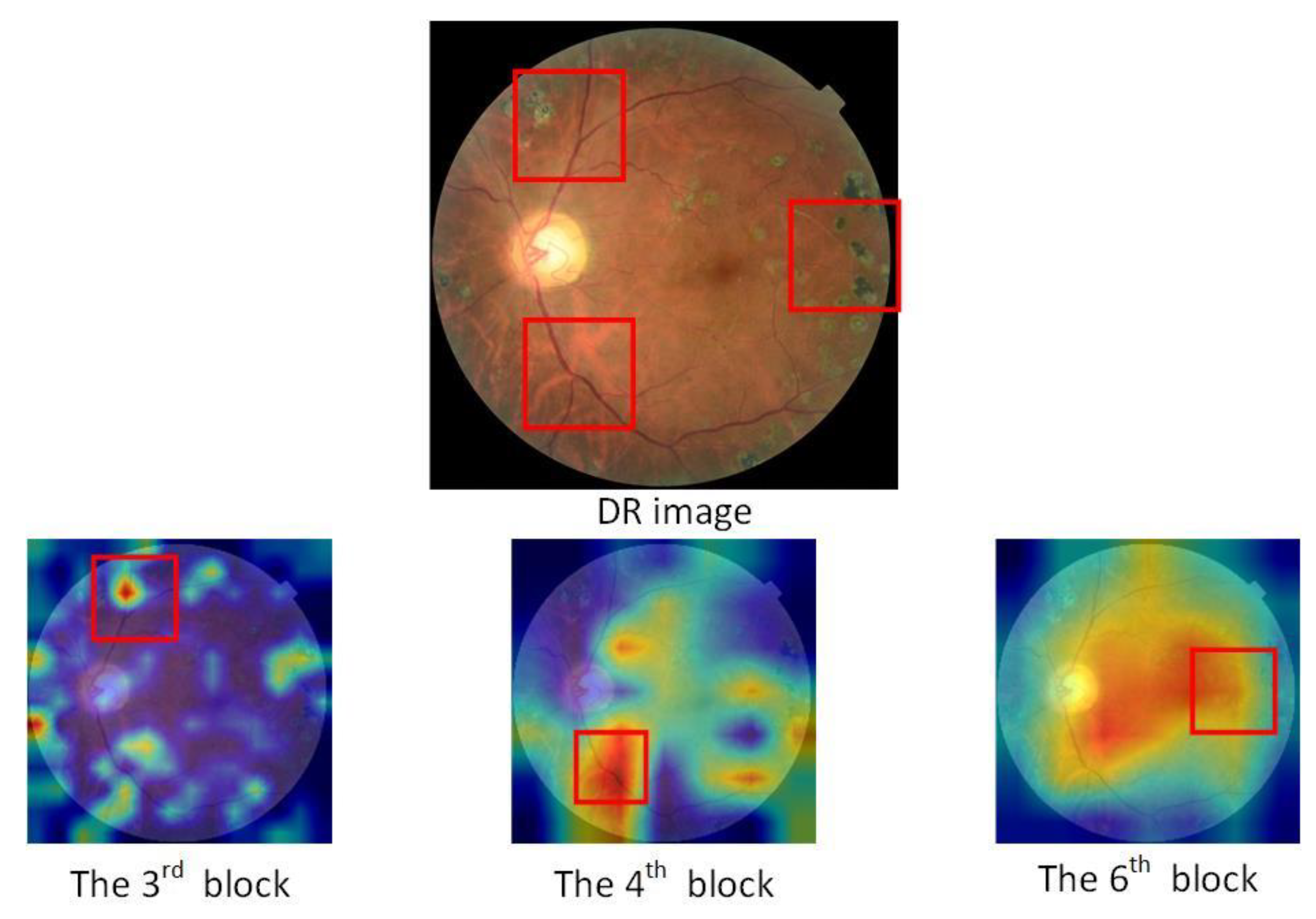
4.3. Result Analysis and Discussion
4.3.1. Comparison of Different Blocks Combination for Fusion Approaches
4.3.2. Performance Comparison of Different Weights Calculating Methods and Fusion Methods
4.3.3. Computational Complexity Comparison of the Proposed Method with Others
4.3.4. Performance Comparison of the Proposed Method with State of the Art
5. Discussion
6. Conclusion and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Guariguata, L.; Whiting, D.R.; Hambleton, I.; Beagley, J.; Linnenkamp, U.; Shaw, J.E. Global estimates of diabetes prevalence for 2013 and projections for 2035. Diabetes Res. Clin. Pract. 2014, 103, 137–149. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.H.; Yuan, B.L.; Feng, Z.; Wang, J.J. Prevalence of Diabetic Retinopathy in Rural China: The Handan Eye Study. Ophthalmology 2009, 116, 461–467. [Google Scholar] [CrossRef] [PubMed]
- Doshi, D.; Shenoy, A.; Sidhpura, D.; Gharpure, P. Diabetic retinopathy detection using deep convolutional neural networks. In Proceedings of the 2016 International Conference on Computing, Analytics and Security Trends (CAST), Pune, India, 11 July 2016. [Google Scholar]
- Williams, R.; Airey, M.; Baxter, H.; Forrester, J.; Kennedy-Martin, T.; Girach, A. Epidemiology of diabetic retinopathy and macular oedema: A systematic review. Eye 2004, 18, 963–983. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kayte, S. Automated diagnosis non-proliferative diabetic retinopathy in fundus images using support vector machine. Inter.-Natl. J. Comput. Appl. 2015, 125, 4. [Google Scholar]
- Gargeya, R.; Leng, T. Automated Identification of Diabetic Retinopathy Using Deep Learning. Ophthalmology 2017, 124, 962–969. [Google Scholar] [CrossRef] [PubMed]
- Quellec, G.; Russell, S.; Abramoff, M. Optimal Filter Framework for Automated, Instantaneous Detection of Lesions in Retinal Images. IEEE Trans. Med. Imaging 2010, 30, 523–533. [Google Scholar] [CrossRef] [PubMed]
- Soares, J.V.B.; Leandro, J.J.G.; Cesar, R., Jr.; Jelinek, H.F.; Cree, M.J. Retinal vessel segmentation using the 2-D Gabor wavelet and supervised classification. IEEE Trans. Med. Imaging 2006, 25, 1214–1222. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Srivastava, R.; Duan, L.; Wong, D.W.; Liu, J.; Wong, T.Y. Detecting retinal microaneurysms and hemorrhages with robustness to the presence of blood vessels. Comput. Methods Programs Biomed. 2017, 138, 83–91. [Google Scholar] [CrossRef] [PubMed]
- Nayak, J.; Bhat, P.S.; Acharya, R.; Lim, C.M.; Kagathi, M. Automated identification of diabetic retinopathy stages using digital fundus images. J. Med. Syst. 2008, 32, 107–115. [Google Scholar] [CrossRef] [PubMed]
- Adarsh, P.; Jeyakumari, D. Multiclass SVM-based automated diagnosis of diabetic retinopathy. In Proceedings of the 2013 International Conference on Communication and Signal Processing, Melmaruvathur, India, 3–5 April 2013. [Google Scholar]
- Roychowdhury, S.; Koozekanani, D.D.; Parhi, K.K. DREAM: Diabetic Retinopathy Analysis Using Machine Learning. IEEE J. Biomed. Health Inform. 2014, 18, 1717–1728. [Google Scholar] [CrossRef] [PubMed]
- Priya, R.; Aruna, P. SVM and Neural Network based Diagnosis of Diabetic Retinopathy. Int. J. Comput. Appl. 2012, 41, 6–12. [Google Scholar] [CrossRef]
- Pratt, H.; Coenen, F.; Broadbent, D.M.; Harding, S.P.; Zheng, Y. Convolutional neural networks for diabetic retinopathy. Procedia Comput. Sci. 2016, 90, 200–205. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Yin, Y.; Shi, J.; Fang, W.; Li, H.; Wang, X. Zoom-in-Net: Deep Mining Lesions for Diabetic Retinopathy Detection. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention 2017, Quebec City, QC, Canada, 11–13 September 2017; pp. 267–275. [Google Scholar]
- Bravo, M.A.; Arbelaez, P. Automatic diabetic retinopathy classification. In Proceedings of the 13th International Conference on Medical Information Processing and Analysis, San Andres Island, Colombia, 5–7 October 2017; p. 105721. [Google Scholar]
- Zhao, Z.; Zhang, K.; Hao, X.; Tian, J.; Chua, M.C.H.; Chen, L.; Xu, X. BiRA-Net: Bilinear Attention Net for Diabetic Retinopathy Grading. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1385–1389. [Google Scholar]
- Abbas, Q.; Fondon, I.; Sarmiento, A.; Jiménez, S.; Alemany, P. Automatic recognition of severity level for diagnosis of diabetic retinopathy using deep visual features. Med. Biol. Eng. Comput. 2017, 55, 1959–1974. [Google Scholar] [CrossRef] [PubMed]
- Orujov, F.; Maskeliūnas, R.; Damaševičius, R.; Wei, W. Fuzzy based image edge detection algorithm for blood vessel detection in retinal images. Appl. Soft Comput. 2020, 94, 106452. [Google Scholar] [CrossRef]
- Das, S.; Kharbanda, K.; Raman, R. Deep learning architecture based on segmented fundus image features for classification of diabetic retinopathy. Biomed. Signal. Process. Control. 2021, 68, 102600. [Google Scholar] [CrossRef]
- Ramasamy, L.K.; Padinjappurathu, S.G.; Kadry, S.; Damaševičius, R. Detection of diabetic retinopathy using a fusion of textural and ridgelet features of retinal images and sequential minimal optimization classifier. PeerJ Comput. Sci. 2021, 7, e456. [Google Scholar] [CrossRef] [PubMed]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Kassani, S.H.; Kassani, P.H.; Khazaeinezhad, R.; Wesolowski, M.J.; Schneider, K.A.; Deters, R. Diabetic retinopathy classifi-cation using a modified xception architecture. In Proceedings of the 2019 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Ajman, United Arab Emirates, 10–12 December 2019; pp. 1–6. [Google Scholar]
- Nguyen, Q.H.; Muthuraman, R.; Singh, L.; Sen, G.; Tran, A.C.; Nguyen, B.P.; Chua, M. Diabetic Retinopathy Detection using Deep Learning. In Proceedings of the 4th International Conference on Machine Learning and Soft Computing; ACM, Haikou, China, 15–17 January 2022; pp. 103–107. [Google Scholar]
- Bodapati, J.D.; Shaik, N.S.; Naralasetti, V. Deep convolution feature aggregation: An application to diabetic retinopathy se-verity level prediction. Signal Image Video Process. 2021, 1–8. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.-C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep net-works via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.B.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kaggle Diabetic Retinopathy Detection Competition. Available online: https://www.kaggle.com/c/aptos2019-blindness-detection (accessed on 19 March 2021).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Sensitivity | Specificity | Accuracy |
|---|---|---|---|
| Nayak et al. [10] | 0.90 | 1.00 | 0.93 |
| Adarsh et al. [11] | 0.90 | 0.93 | 0.95 |
| Roychowdhury et al. [12] | 1.00 | 0.53 | - |
| Priya et al. [13] | 0.98 | 0.96 | 0.97 |
| Pratt et al. [14] | 0.95 | - | 0.75 |
| Wang et al. [15] | - | - | 0.90 |
| Abbas et al. [18] | 0.92 | 0.94 | - |
| Das et al. [20] | 0.96 | 0.95 | 0.96 |
| Gulshan et al. [22] | 0.97 | 0.93 | - |
| Kassani et al. [23] | 0.88 | 0.87 | 0.83 |
| Nguyen et al. [24] | 0.80 | 0.82 | 0.82 |
| Bodapati et al. [25] | - | - | 0.84 |
| Level of Severity | Samples |
|---|---|
| Normal (class-0) | 1805 |
| Mild (class-1) | 370 |
| Moderate (class-2) | 999 |
| Severe (class-3) | 193 |
| Proliferate (class-4) | 295 |
| Convolution Block | Accuracy | Kappa Score | F1 Score |
|---|---|---|---|
| 3 and 4 (add) | 58.33% | 47.22% | 57.15% |
| 3 and 5 (add) | 67.28% | 56.41% | 67.22% |
| 3 and 6 (add) | 73.37% | 64.24% | 73.21% |
| 4 and 5 (add) | 69.35% | 58.89% | 69.37% |
| 4 and 6 (add) | 75.84% | 67.92% | 75.81% |
| 3, 4 and 5 (add) | 79.98% | 70.87% | 79.93% |
| 3, 4 and 5 (proposed) | 83.15% | 72.87% | 83.11% |
| 3, 4 and 6 (add) | 83.51% | 74.65% | 83.48% |
| 3, 4 and 6 (proposed) | 85.32% | 77.26% | 85.30% |
| Calculate Weight | Accuracy | Kappa Score |
|---|---|---|
| Model (with 1 1 Conv) | 84.51% | 76.61% |
| Model (with 3 3 Conv) | 83.87% | 75.34% |
| Model (with RCAM) | 85.32% | 77.26% |
| Fusion Method | Accuracy | Kappa Score |
|---|---|---|
| Model (add) | 83.51% | 74.65% |
| Model (concat) | 80.25% | 70.81% |
| Model (designed weight) 1 | 83.89% | 73.44% |
| Model (proposed) | 85.32% | 77.26% |
| Model | Parameters | Madds | FLOPs |
|---|---|---|---|
| Vgg-16 | 5.481 M | 160.7 G | 80.48 G |
| ResNet-50 | 25.5 M | 42.93 G | 21.5 G |
| Inception-V3 | 23.8 M | 35.1 G | 17.5 G |
| Xception | 9.5 M | 25.08 G | 12.6 G |
| MobileNetV2 | 3.5 M | 3.27 G | 1.67 G |
| MobileNetV3 | 4.2 M | 2.32 G | 1.18 G |
| Proposed | 6.78 M | 5.83 G | 3.54 G |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, R.; Liu, Y.; Zhang, R. Multi-Scale Feature Fusion with Adaptive Weighting for Diabetic Retinopathy Severity Classification. Electronics 2021, 10, 1369. https://doi.org/10.3390/electronics10121369
Fan R, Liu Y, Zhang R. Multi-Scale Feature Fusion with Adaptive Weighting for Diabetic Retinopathy Severity Classification. Electronics. 2021; 10(12):1369. https://doi.org/10.3390/electronics10121369
Chicago/Turabian StyleFan, Runze, Yuhong Liu, and Rongfen Zhang. 2021. "Multi-Scale Feature Fusion with Adaptive Weighting for Diabetic Retinopathy Severity Classification" Electronics 10, no. 12: 1369. https://doi.org/10.3390/electronics10121369
APA StyleFan, R., Liu, Y., & Zhang, R. (2021). Multi-Scale Feature Fusion with Adaptive Weighting for Diabetic Retinopathy Severity Classification. Electronics, 10(12), 1369. https://doi.org/10.3390/electronics10121369