1. Introduction
There is a need for a computational framework that allows capturing, representingm and processing the meta-knowledge [
1] of a human in the context of the domain of discourse and study the behavioral response of a person in light of explanatory machine techniques [
2]. For example, in the legal area, it means to get an intelligent and coherent explanation of the legal analysis made by a human in a particular scenario of a previous case and find the reasons about why a particular law was used [
3] in order to support decision-making when other judges are dictating a resolution. This situation seems superfluous, but it is not, because it usually would imply navigating between a complicated set of theories that range from cognitive learning theories [
4,
5], instructional design [
6], cognitive theory [
7], and information processing theory [
8], among others. These theories reveal how a judge can learn and support decision-making using the knowledge from other judges and the sentences. In this particular investigation, there is a path that subsumes and synthesizes in some way some parts of the previous theories and focuses them on a practical point of application, and that leads directly to basal knowledge [
9], and that is the Subject-Matter Experts (SME) [
10] from which the analysis of the merits of a case (legal matter background) is the main activity of a judge. In this way, it is possible to lead efforts to work with higher-order thinking [
11] using the technology like a meta-media [
12] to manage meta-knowledge.
The study of the merits of a case involves analyzing the scenarios formed by the facts associated with a case. A legal analysis consists of a judge perceiving [
13] and analyzing the facts and evidence, according to a determined legal posture [
14,
15]. It is to emphasize that the behavioral response of a research subject, such as a judge, is diverse, so it is necessary to investigate the response when using the framework in terms of functionality, usability, and efficiency when analyzing the merits of a case.
Studying the judge’s behavior on accepting or rejecting the use of the framework is not as simple as asking the judge if they agree, like, or think it is possible to use this framework to do such work. This investigation is a complete challenge to the mental and psychological scheme because there are rules in the domain of discourse that represent substantial barriers to conduct experiments and studies in technology and human behavior inside the jurisdictional area. The main barriers are: (1) That nothing and no one can intervene in the decision-making of a judge, this is called judicial independence, and (2) the judges have a high degree of discretion to make decisions, and nothing and no one can tell them how or what decision to make [
16,
17]. So far, no research has evaluated the behavior of the judges when faced with the use of a framework that helps them with the deep analysis of a case by taking fragments of the human psyche [
18] using meta-knowledge, focusing on the perception [
13], and adapting Artificial Intelligence (AI) [
19] techniques to explain that fragments. The psyche, in this research, is understood as the processes and phenomena that make the human mind works as a unit that processes perceptions, sensations, feelings, and thoughts, rather than a metaphysical phenomenon [
18]. So, it is understandable that the psyche is exceptionally complex; however, it is possible to explore some deep traits and characteristics that can be expressed through layers of awareness [
20] or envelope [
21] of knowledge, based on the perception a human has from objects and relationships of the real-world. In this way, it is possible to express, through related meta-knowledge fragments, the meaning, and purpose of someone in a specific context.
Thus, this research aims not only to investigate the behavioral development of the judge when using new technology for in-depth analysis of cases but also to show computational advances with a high impact in cognitive and psychological fields. So, this research presents a Mixture of Experts (MOE) system [
22,
23] called RYEL [
24,
25,
26,
27]. This system was created based on CBR guidelines [
3,
28,
29,
30] and Explainable Artificial Intelligence (XAI) [
31,
32,
33] using focus-centered organization fundamentals, which means the organization of XAI and CBR is done and focus according to the perspective and approach that a human has in a domain of discourse, meaning it is human-centric [
34,
35,
36]. A human interacts with the system through Explanatory Graphical Interfaces (EGI) [
2], which are graphic modules that implement computational techniques of knowledge elicitation [
37] to capture, process, and explain the perception of a human about facts and evidence from scenarios in a context. RYEL uses the method called Interpretation-Assessment/Assessment-Interpretation (IA-AI) explained in [
2] which consists not only in explaining machine inferences but also the point of view that a human has using metadata from the real world along with statistical graphs and dynamic graphical figures.
Various investigations try to obtain knowledge from past cases using the traditional Case-Based Reasoning (CBR) approach in a legal context, such as [
3,
28,
30,
38,
39,
40,
41]. In those systems, CBR consists only of solving current cases according to how previous ones were solved, that is, in a deterministic way. This kind of solution is different in capturing the judge’s interpretation and assessment of facts and provides an intelligent simulation [
42,
43,
44,
45] that allows a legal analysis about the merits of the case. This approach is an understudied approach concerned in identifying the perception of a judge about the objects and relationships of the real world involved in a case, along with the machine’s ability for capturing and processing that information and explaining it graphically on an interface [
46].
Thus, the novelty of this research not only lies in the societal impact of using XAI and CBR to assist judges in resolving legal disputes between humans with the novel IA-AI method to analyze the merits of a case, but also the behavioral study of the judge in the face of this technology. Therefore, a balance in explaining the software design and behavioral analysis of the judges is the key to reveal essential aspects of this investigation. The following sections explain this balance.
2. Framework Design
Design Science research process proposed in [
47] allowed the creation of the computational framework of RYEL explained in [
2], implementing CBR life-cycle stages as shown in
Figure 1 as a guide to exchange and organize the information with the user. The system design was developed in [
24,
25,
26] as a hybrid system [
48,
49] implementing different machine learning techniques for every CBR stages [
28,
30,
38,
39,
41,
50,
51,
52]. An adaptation took place to implement the stages to graphical interfaces where the judge can manipulate corresponding images representing connected facts and evidence of the scenarios. How the scenarios show a definition, relationship, characterization, and description according to a legal context using images allows the machine to acquire higher-order thinking [
11] from humans dynamically and graphically. By manipulating interrelated images, a human expresses ideas and points of view. The system takes the images as inputs to carry out a legal analysis simulation and generates a graphical explanation of the laws applicable to the factual picture. Other judges use the explanations provided by the machine for decision-making support.
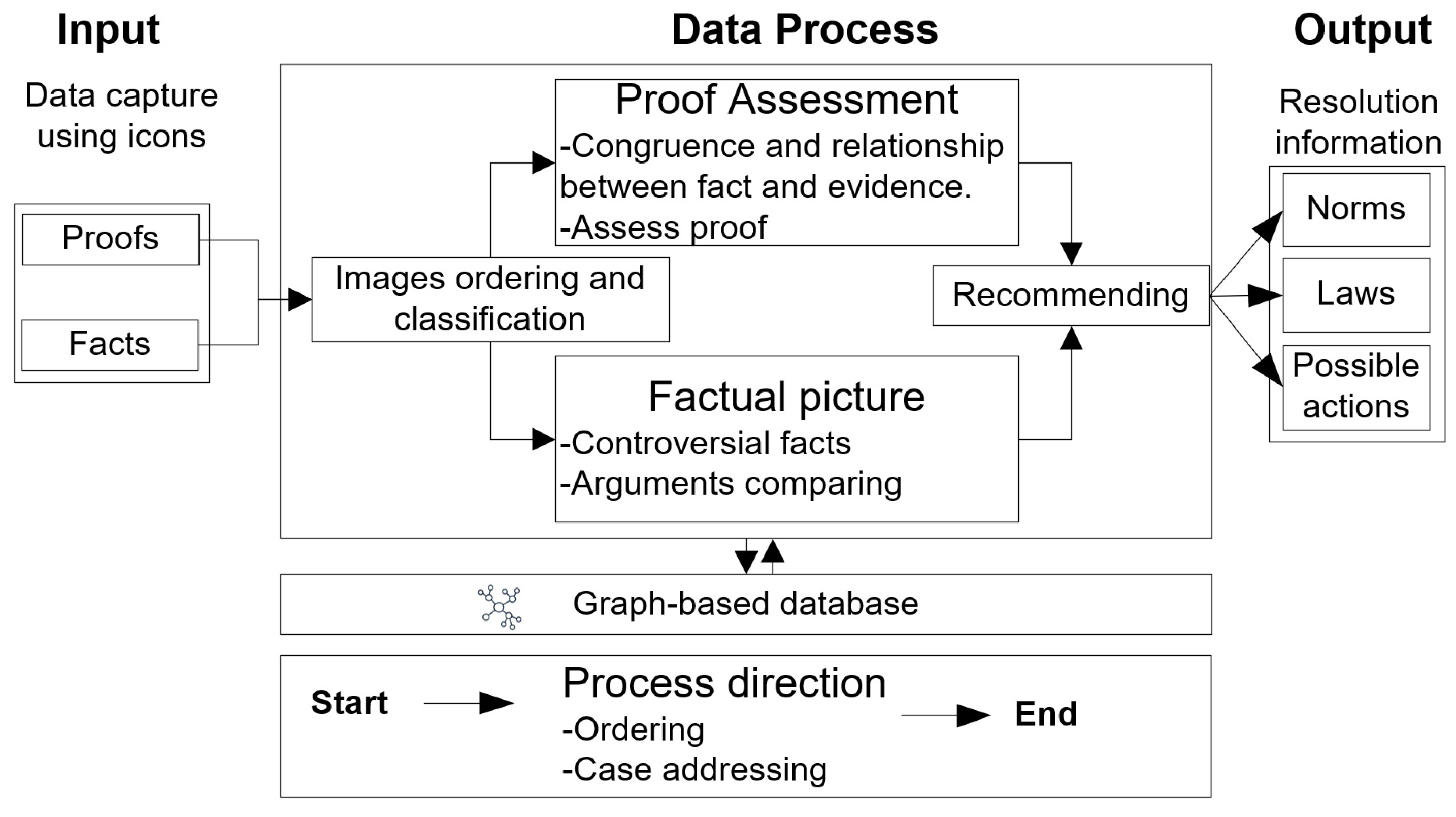
The data overview diagram of the system consists of image inputs, evidence and facts processing, norms and laws outputs, CBR articulating and processing the information between the user and machine; organizing the inputs and outputs of the system as depicted in
Figure 2. The role of EGIs is to provide graphical interfaces that are used for human interaction with a computer, called Human-Computer Interaction (HCI) [
53], an example of the interface is shown in
Figure 3. The graphical techniques of the interfaces allow the elicitation of human knowledge using the ligaments between the shape of images and the content of its attributes, as well as the relationships between images. This means a meta-media to manage higher-order thinking by combining the functionality of the EGIs, for example, by combining the functions of the interfaces of
Figure 4 with
Figure 5. This combination makes it possible to work with the range, importance level, order, and attribute links between images. The role of IA-AI is to obtain the perception of a human from the dynamic triangulation of attributes expressed with images, relationships, and unsupervised algorithms [
2].
Explanation of the system design must line up with the study of human behavior in light of the cognitive field and technology. Thus, the following points allow alignment, and the next sections explain them: (1) The cognitive environment [
54] of the judge in order to delineate the domain of discourse and understand both the computational nature of the data and the behavioral study of the judge; (2) the knowledge representation, (3) the computational legal simulation, and (4) the hybrid nature of the system.
2.1. Cognitive Environment
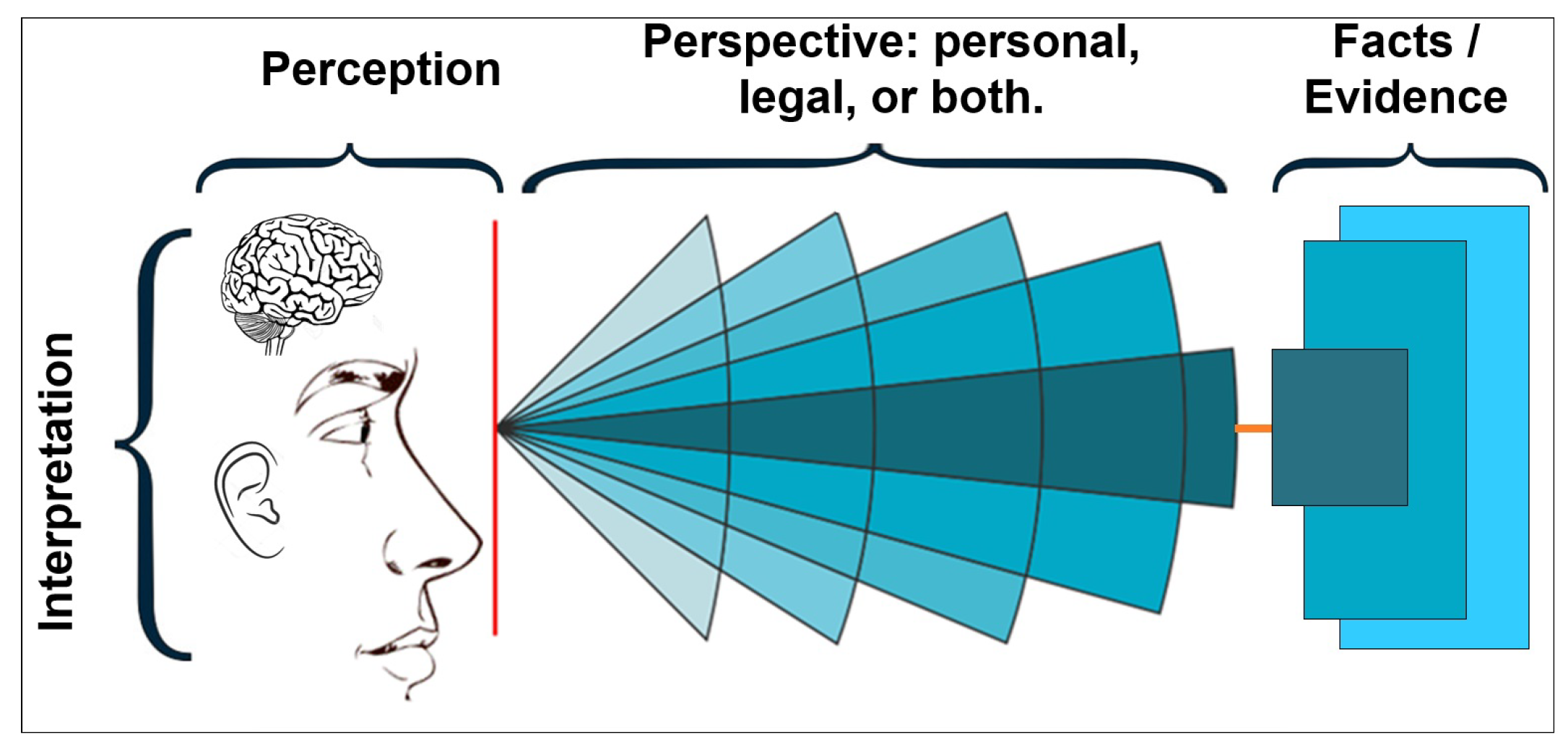
A judge may have extensive knowledge. However, the system focuses on how a judge understands information from scenarios in a context, as shown in
Figure 6. This figure explains the definition of understanding in this research in terms of (1) perception, (2) perspective, and (3) interpretation. These words seem to be standard and straightforward terms, but the system treats them as part of its nature and requires explanation.
Perception in [
13] is a mental process that involves activities such as thought, learning, memory, and others, along with a link to the state of memory and its organization. It is a subjective state where a person captures and understands, in their way, the qualities of objects and facts from the real world. Therefore, a judge may have a different perception of the information between one file and another. For example, a judge in a Domestic Violence Court has grasped, learned, and is aware that the defendant from the beginning is an alleged aggressor given a situation of vulnerability over the victim. However, a judge in Criminal Court has learned and understood that the “Principle of Innocence” must be used with a defendant, which presumes the state of not being guilty until proven otherwise.
Perspective in [
55] is the point of view from which an issue is analyzed or considered. The perspectives can influence people’s perceptions or judgments. The judges’ perceptions could change according to their attitude, position, or considerations about facts, objects, individuals, entities, or type of work. The annotations of a case, which are information from the legal file, can be analyzed using a different perspective; for example, a judge in a Criminal Tax Investigation Court may see the action of hitting a person as not so severe or even belittle it, while a judge in a Domestic Violence Court can see it as very serious.
Interpretation in [
56] means expressing or conceiving a reality personally or attributing meaning to something. Thus, the judges could conceive an annotation from the legal file according to their reality and attribute and then assign a meaning. Consider this example, shooting to a person can be interpreted by a judge in a criminal court as an act of personal defense and assess it as a reason to preserve life, while another judge, from the same court, may interpret it as an act of aggression and assess it as a reason to steal something.
The system handles the interpretation and assessment made by a judge as two separate but interacting processes. In order to understand this interaction, consider the following example; person X assesses the help a person Y gave them in a trial, but person X cannot interpret the reasons of the help, because person Y is their enemy, or else, person X interprets that their enemy helped them in a trial because they want something from him. For that reason, the help is not so valued by person X. This example shows how the interpretation and assessment interact in this investigation.
In the file, how a judge understands the facts and evidence is not recorded. Currently, a file only contains the final decision of a judge supported by motivations and underpinnings of the law, along with chunks of structured data like “the outcome”, “the considering”, and “the therefore” as described in [
17,
57]. Thus, this unrecorded information is precisely the most important to understanding the perception of a human. The graphical techniques and explainable methods [
33], in this investigation, allow to capture and detail this information.
2.2. Knowledge Graph
Internally, the system transforms images and relationships representing the scenarios of a case into directed graphs called Knowledge Graphs (KG) [
58,
59,
60], which contain object types, properties, and relationships from real criminal cases. Through graphic media, the judge can obtain information about the ontological content [
61] processed by the images. After the image transformation, each scenario is converted to a set of nodes and edges, representing facts or evidence along with the relationship that explains their bond, which translates into hermeneutical content [
62]. There may be more than one scenario per legal case. The expressive semantic nature [
63] of the KG allows for having different graphical forms [
46] to show the reasoning of a judge and to understand the use of law in a proven fact (fact whose evidence accredits it as a true) in a crime. In [
64] the KGs have been prevalent in both academic and industrial circles in these years because they are one of the most used approaches to integrate different types of knowledge efficiently.
Usually, the judge performs the mental process of relating legal concepts of the scenarios to find the meaning of the information provided by the parties in conflict. Thus, to determine whether the facts are truthful, the judge makes groups of evidence and links them to the facts. The groups, data type, and relationships in the legal scenarios mold a network that expresses meaning. Therefore, a network is generated and is visualized as Semantic Networks (SN) [
65,
66,
67] by the system.
In [
68], the SN is a directed graph composed of nodes, links, or arcs, as well as labels on the links. KG in [
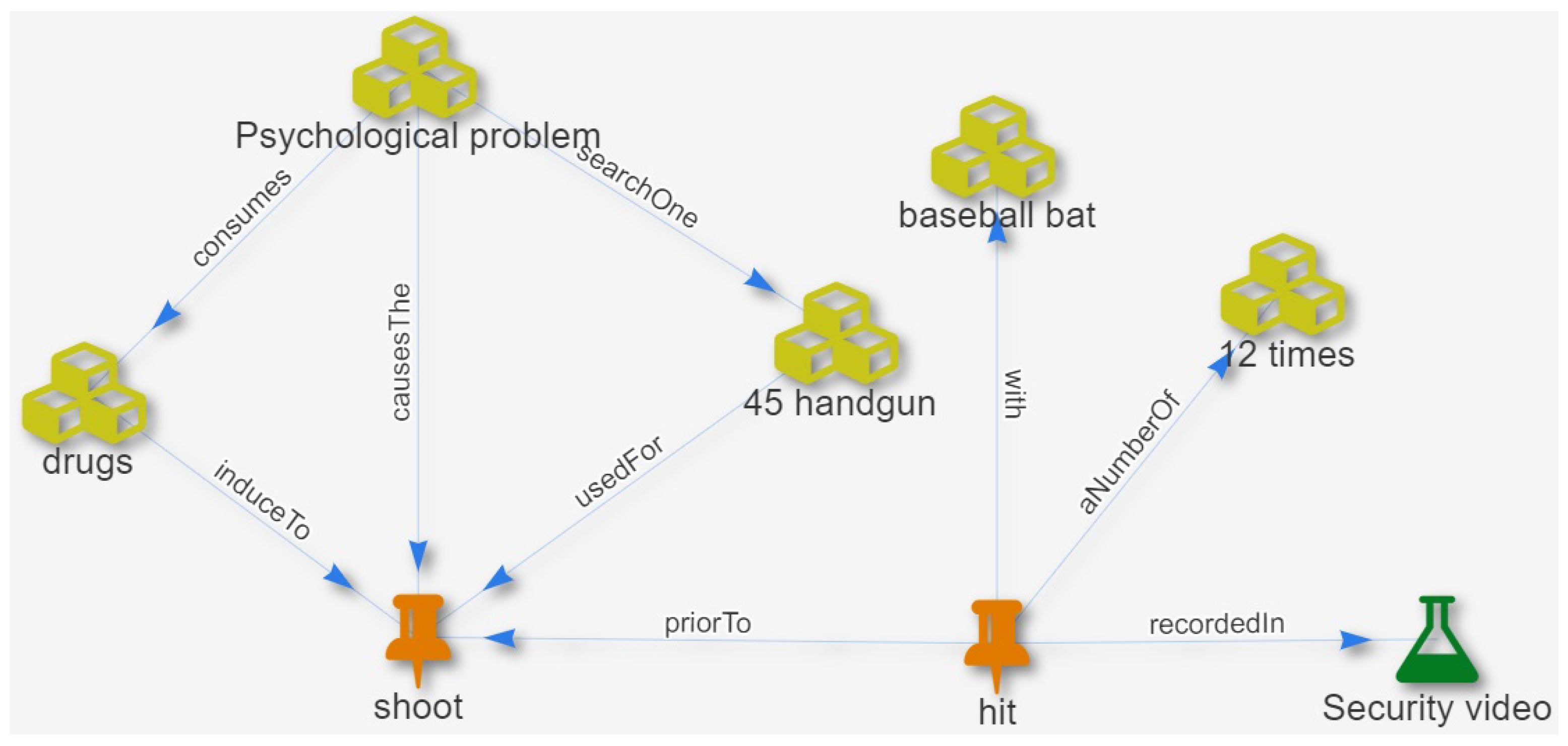
63] is a type of SN, but the difference lies in the specialization of knowledge and in creating a set of relationships. Thus, the knowledge structure depends on the domain of application, and graph structure changes according to the knowledge expressed. Since the system translated images into nodes describing physical objects, concepts, or situations in a legal context, the relationships (edges) between images are transformed into links and express a connection between objects in legal scenarios. Links have labels to specify a particular relationship between the objects of the legal case. Thus, nodes and edges are a means to make the structure of legal knowledge. In this way, the use of images and relationships allows the construction of KG that represents the judge’s knowledge after having interpreted and evaluated the facts and evidence contained in the scenarios, and this is the reason why the graphs include information about properties types and relationships between entities. An entity can be an object, a person, a fact, a proof, or the law.
Human Interaction
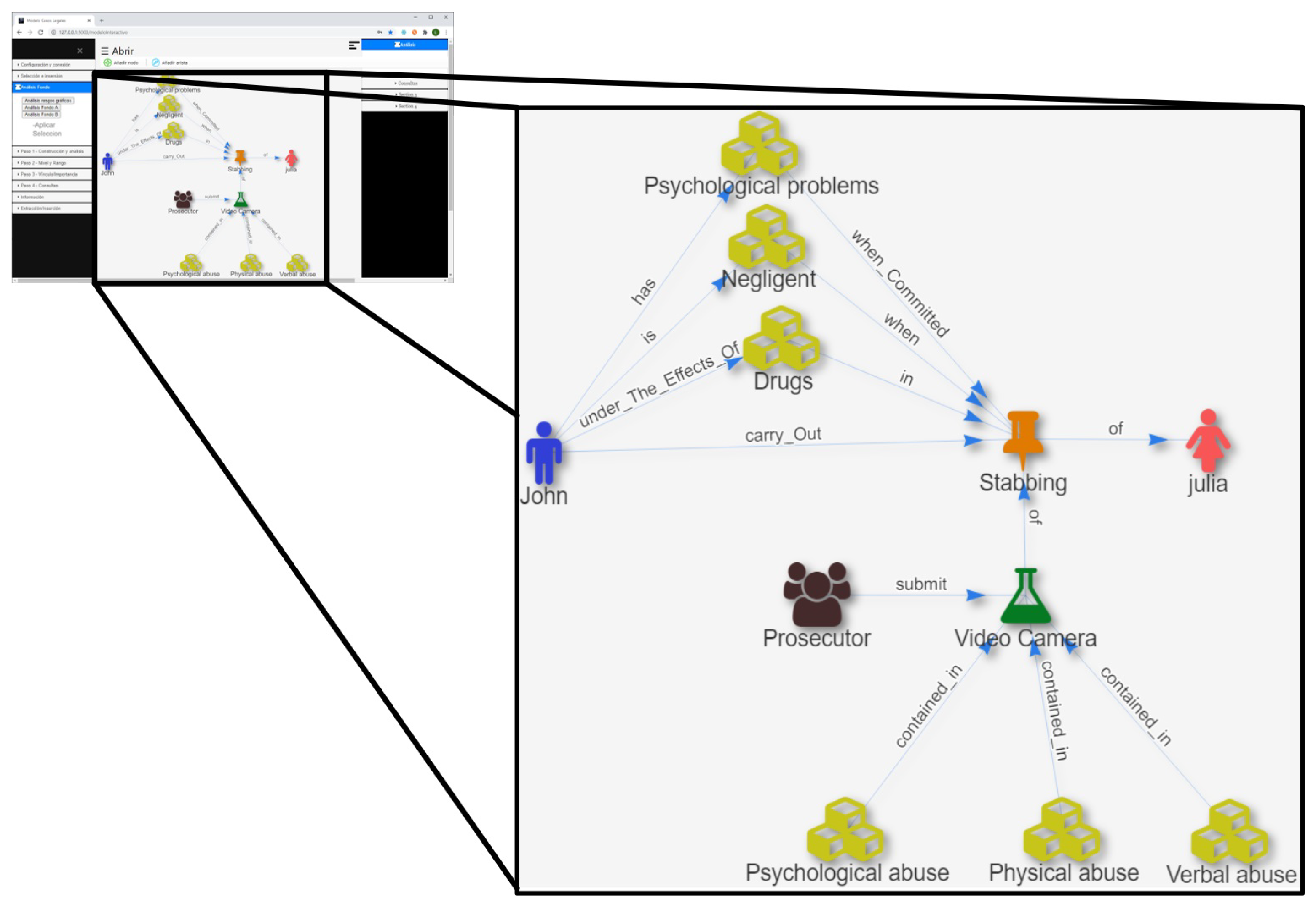
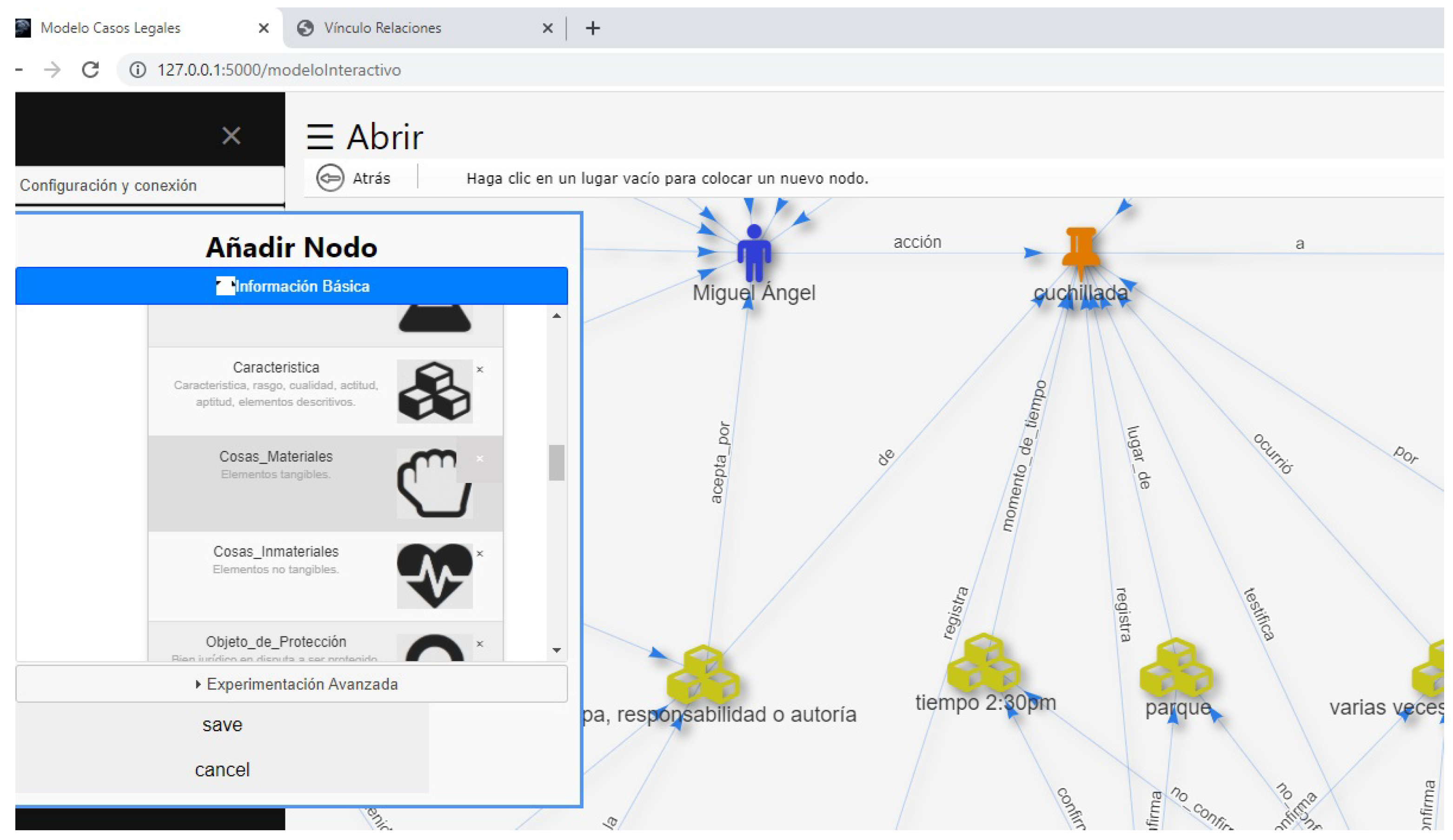
The judge can access graphic resources in the form of images representing legal elements [
16] which are pieces of juridical data made of evidence and facts, as shown in
Figure 7. An EGI offers the judge a popup menu to select the image that best reflects a record entry from the expedient. In addition, the system has a drawing area called working canvas where the judges can draw their perception of the scenarios by establishing, organizing, distributing, and relating the images that they select from the menu, as shown in
Figure 7. The KGs built with the images are stored in an unstructured database, and when this happens, they become a more specific type of graph called a Property Graph (PG) [
69,
70,
71].
The judge can change the display state of an EGI; this is between images or nodes to study the attribute representations in both states. The nodes acquire colors, sizes, and properties, to explain the details of the attributes visually. Edges acquire properties such as length, thickness, color, and orientation to explain how the nodes are linked and distributed. Both nodes, as well as edges, contain unique properties resulting from the transformation process. The system uses the IA-AI method to create properties and attributes. The method has three main processes. In the first process, after the judge has finished drawing on the working canvas, like in
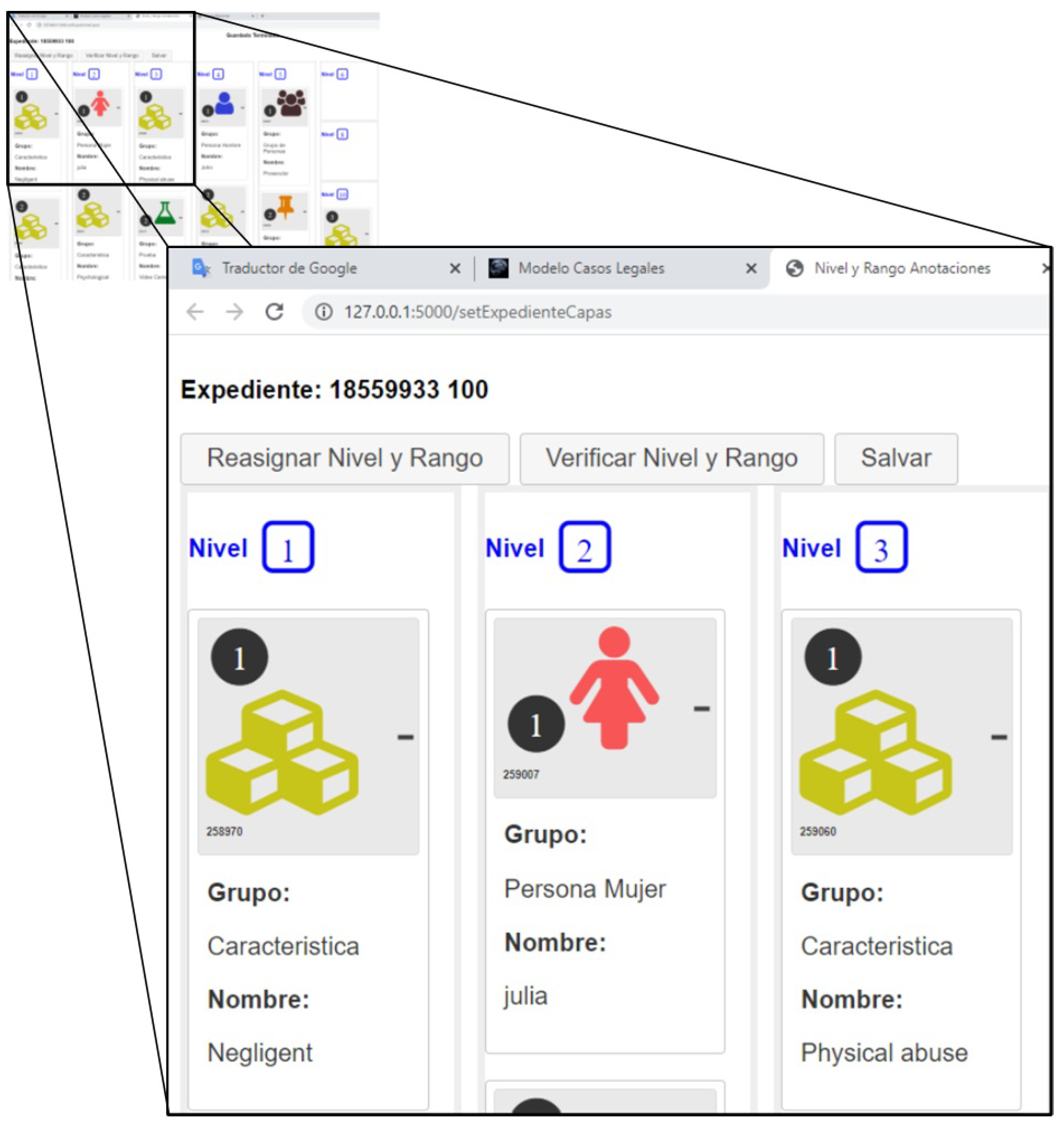
Figure 7, they can interpret and assign the levels and ranges of importance to the images drawn. The judge does it by dragging and dropping the images into previously designed graphic boxes (precedence and importance levels) as shown in
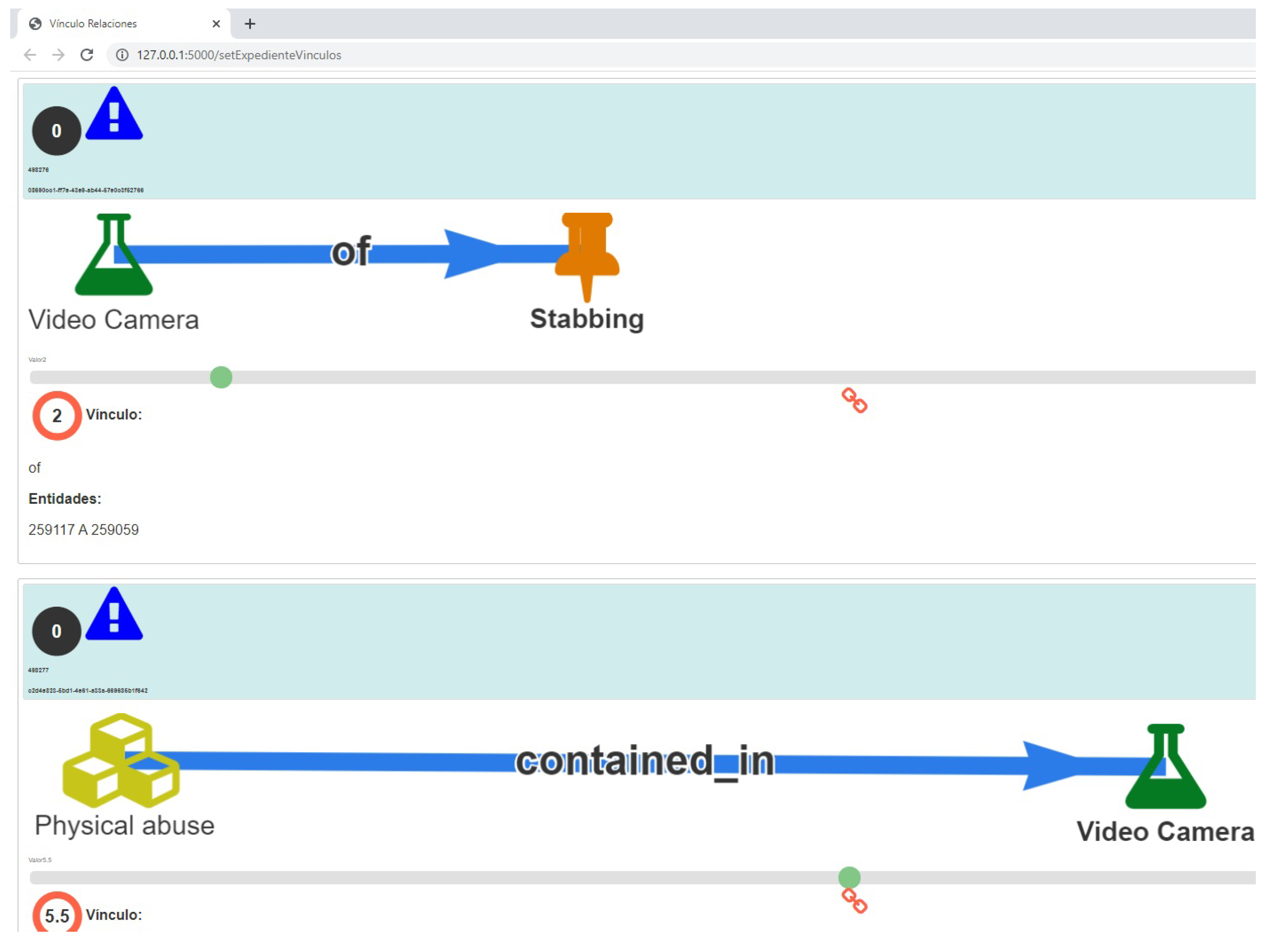
Figure 5. In the second process, other EGIs are used to assess the links between images representing the facts and evidence (proof assessment); the judge does this by hanging up the links in different positions and establishing the bond length (link) between objects as shown in
Figure 4. In the third process, another EGI is used to explain recommendations on laws and regulations concerning the factual picture depending on the context, as shown in
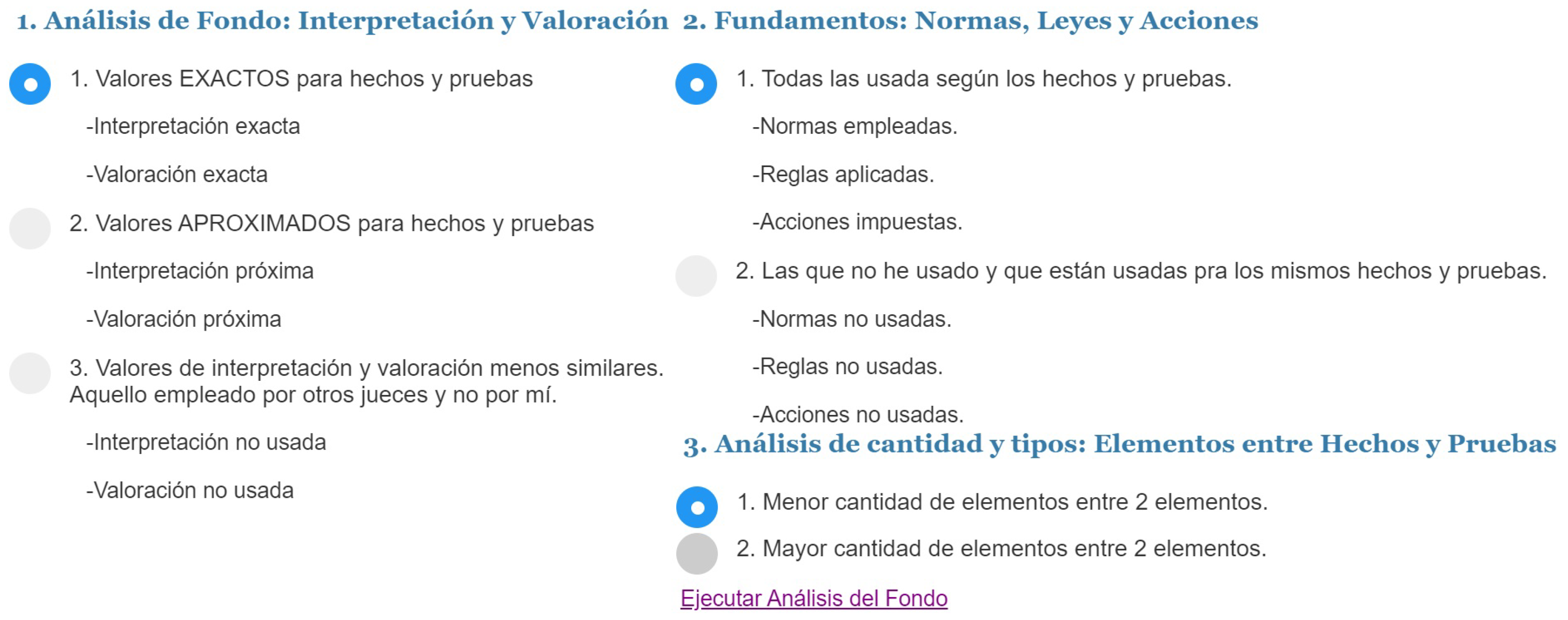
Figure 8, where the Y-axis indicates the legal taxonomy, this means the order of importance of the legal norms according to the context. The X-axis represents the level of similarity that the norms have in the factual picture of the scenarios. Finally, the machine recommends groups of norms represented by a higher or right circle in the chart, depending on what the judge is analyzing.
During a case, the judges can run legal simulations to delve into the merits of the case gradually. The simulation carried out by the system is described below.
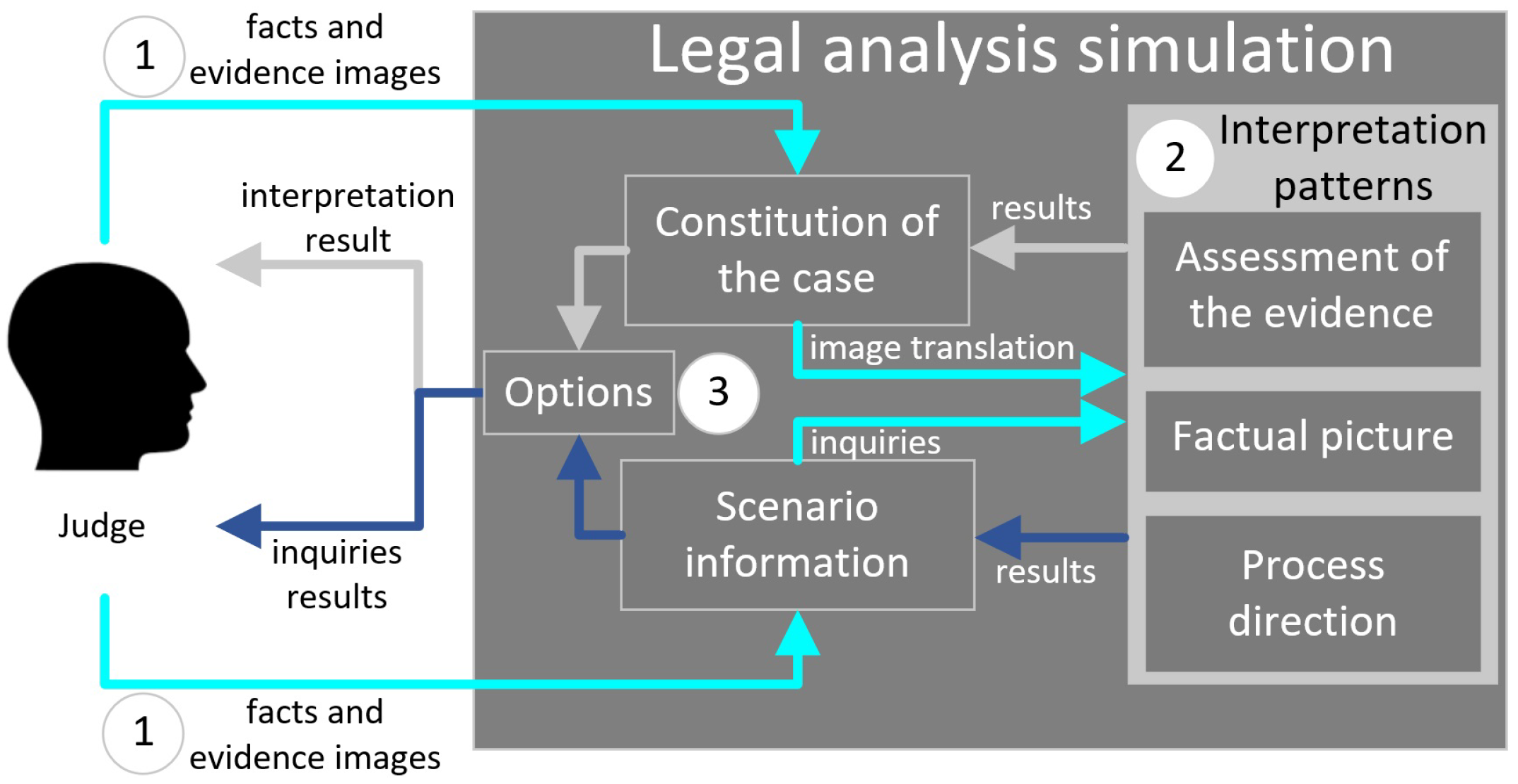
2.3. Intelligent Simulation
Figure 9 shows the legal simulation activity. There are three main processes in the simulation which are: (1) The capture of the interpretation and assessment values using EGIs [
25,
27] that a judge makes of the facts and evidence of a case, (2) identify the patterns of interpretation [
3] using CYPHER [
71] scripts to extract the semantic [
72,
73] and the ontological [
74,
75] content of the facts and evidence contained in the scenarios of a case depicted by EGIs, and (3) the options the machine offers to the judge to distill legal information from the patterns found in the graphs as shown in
Figure 10 by using unsupervised algorithms [
71], like Jaccard [
76], Cosine of Similarity [
77], and Pearson’s Correlation Coefficient [
78] applied to graphs. Then the machine provides an explanation of the results. Some examples of the information that the machine explains are: (a) A graphical explanation about a set of norms that apply to a case; (b) explain and identify the evidence that is not related to some fact; (c) detects the evidence that not evaluated; and (d) indicate what evidence has been evaluated but not related.
When judges use the system continuously, they will be able to integrate legal knowledge during a trial.
2.4. Hybrid System
RYEL uses different types of machine learning techniques therefore, it has the characteristic of being a hybrid [
48] system. Hybridization applies in a multitude of computational areas, as in [
81,
82]. However, this research focuses on the legal field, specifically on facts and evidence from a case analyzed by a judge.
The hybridization [
48] of RYEL is organized under the MOE [
22,
23] foundations based on the divide-and-conquer principle [
23,
83]. That means that different parts or segments constitute the problem space; each part corresponds to a module called an “expert” [
23]. MOE usually uses “gate network” [
23] that decides to which expert a specific task should be assigned to deal with complex and dynamic problems [
48], for example, the use of various experts for multiple label classifications using Bayesian Networks (BN) and tree structures [
22]. Supervised machine learning such as neural networks are typically used [
22,
83] in MOE, however our approach is unsupervised [
84] using KG [
25,
27], to build SN with a CBR [
3,
85,
86] and XAI [
32,
87].
2.5. Case Explicability
The implementation of XAI and CBR reveals the interconnections and characteristics of objects within the scenarios of a context. Due to the use of KG, it is possible to achieve legal exegesis [
88] by obtaining the hermeneutical content of relations and objects together with ontological data through their properties. That means that a legal interpretation is according to the content expressed by a judge; therefore, the semantic explained initially.
The adaptations of the CBR stages, shown in
Figure 1, are the following: (1) Retrieve, whereby the judges have graphical options to execute a legal analysis simulation to find patterns of interpretation of the facts and assessment of the evidence similar to the case depicted in the working canvas for a specific context; (2) reuse, whereby the system synthesizes and evaluates the patterns found, and detects the laws with which they have links in order to be considered by the judges in new cases; and (3) revise, whereby the judges of higher-hierarchy use the EGIs to make a review of the performance made by lower judges aimed to make modifications and corrections in the factual picture posed on the working canvas. In this stage, the system integrates knowledge of the judges and the parties in conflict. If the parties in conflict appeal to the resolution (legal challenge), then higher-hierarchy judges must revise the scenarios. The higher judges can also run legal analysis simulations in order to consult, verify, correct, or add new perspectives to refute or accept, in the whole or part, the analysis carried out by judges of lower-hierarchies; then, the issuance of a final resolution occurs and (4) retained, which means that the sentence is final and no further legal simulation is necessary. In the retention stage, the system incorporates cognitive information into the knowledge database because the possible errors of bias in perception were eliminated or corrected by reviewing several humans during the legal process using the system.
Figure 1 shows a list that summarizes the stages of the CBR.
Case-Base: A KG represents this;
The Problem: Is the interpretation and assessment of both facts and evidence;
Retrieve: Using CYPHER script patterns and graph similarity algorithms like Cosine, Pearson, and Jaccard;
Reuse: Consists of detecting norms and laws related to the factual picture drawn on the working canvas;
Revise: Analyze and review the work done by lower judges using KG via EGI;
Retain: Is the stage of adding to the knowledge base a correct approach to interpreting and assessing a factual picture.
2.6. Case Definition, Data Model, and Example
Formally a case is a graphical deposition of facts and evidence made by the judges according to their perspective using EGI. In one case, there are segments of information called “scenarios” that contain facts related to the evidence. Scenarios are a way to express and organize legal information.
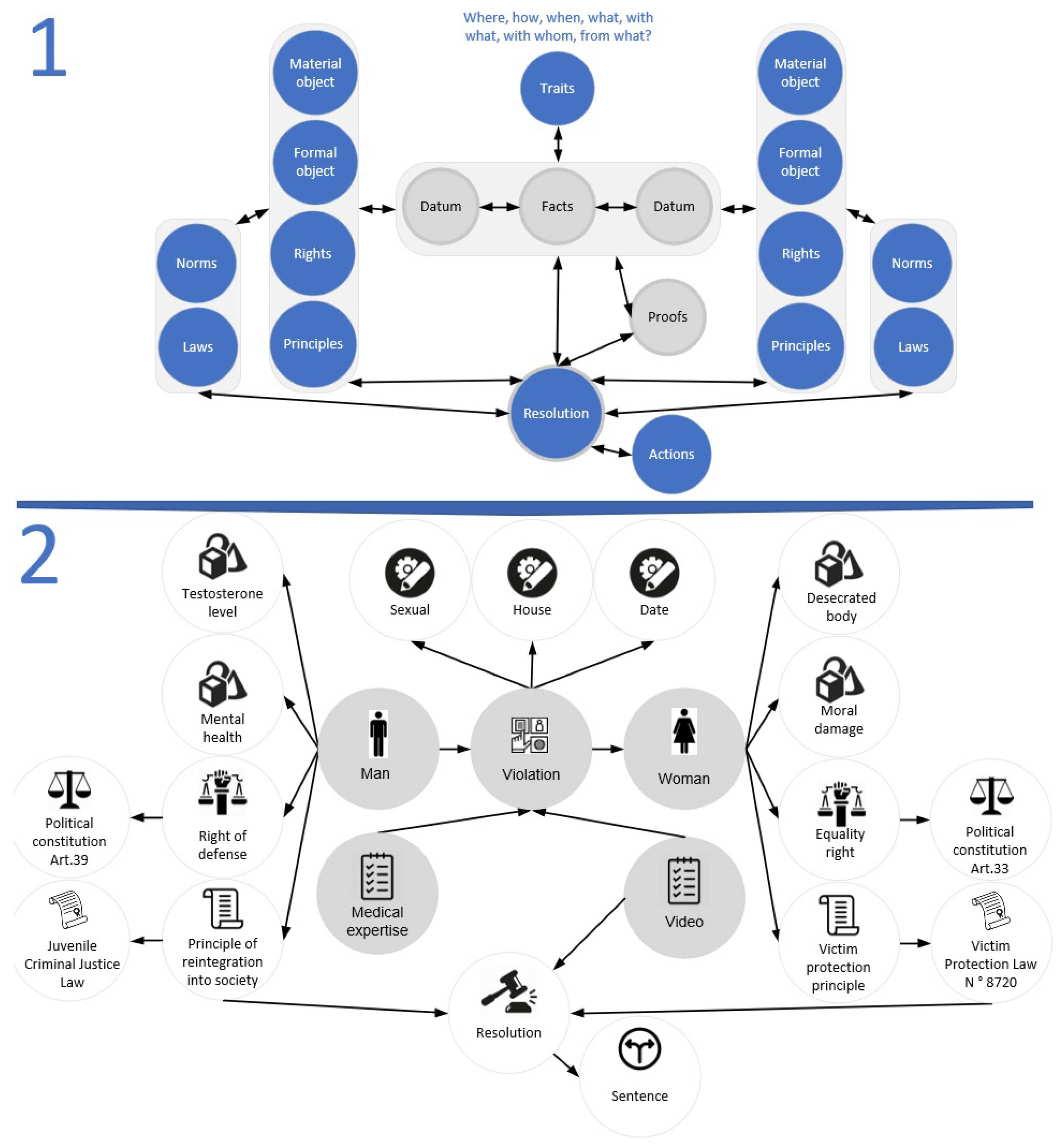
An in-depth legal analysis is the identification and description of both data and relationships within each scenario. The judges do this analysis as they work through the case during the trial. To exemplify the data and relationships, consider the data model of segment 1 in
Figure 11 where bidirectional arrows represent that a relationship can go one way or the other from concepts or objects, and it demonstrates the organization and relation of the meta-knowledge. In this figure in segment 2, a simplified real world example of a “violation case” uses the data model from segment 1. The elements called “Material Object” and “Formal Object” broach the subject of each scenario; for example, in this figure, there is a case of a man affecting a woman through the action of rape. In [
89] a formal object means carrying out a legal study, from a particular perspective, on the relationship of legal data; the material object is the matter that deals with such data, but in this case, all the relationships that describe each object are also represented and organized.
Segment 2 of
Figure 11 shows a PG where there is a removal of properties and labels in the relationships in order to simplify the example. This PG represents a judge analyzing a man from the perspective of the state of mental health that could lead him to rape a woman because of medical issues which are related to the testosterone levels in his body, and the woman from the perspective of the moral damage suffered by desecrating her body. The rest of the graph describes tests, norms, laws, rights, resolutions, and decisions related to the rape felony following the model of segment 1.
2.7. Explainable Technique
RYEL uses the explanatory technique called Fragmented Reasoning (FR) [
2]. This technique uses dynamic statistical graphics that granulate the information following a hierarchical order and importance of the information according to the interpretation and assessment made by a human of real-world objects. This technique means that the semantic and holistic constitution of objects, attributes, and vectors describing relationships between objects in a KG, as in
Figure 7, are fragmented and link up to each other to explain the human conception according to its perception in a specific domain of discourse. Therefore, this technique expresses the hermeneutical content of a case from the perspective of a human and allowed the study of a new spectrum of cognitive information treatment [
54] in the field of machine learning, associated with the human factor [
90,
91] specifically about the subjective information [
92] of a person, which in this case is specific to the judge.
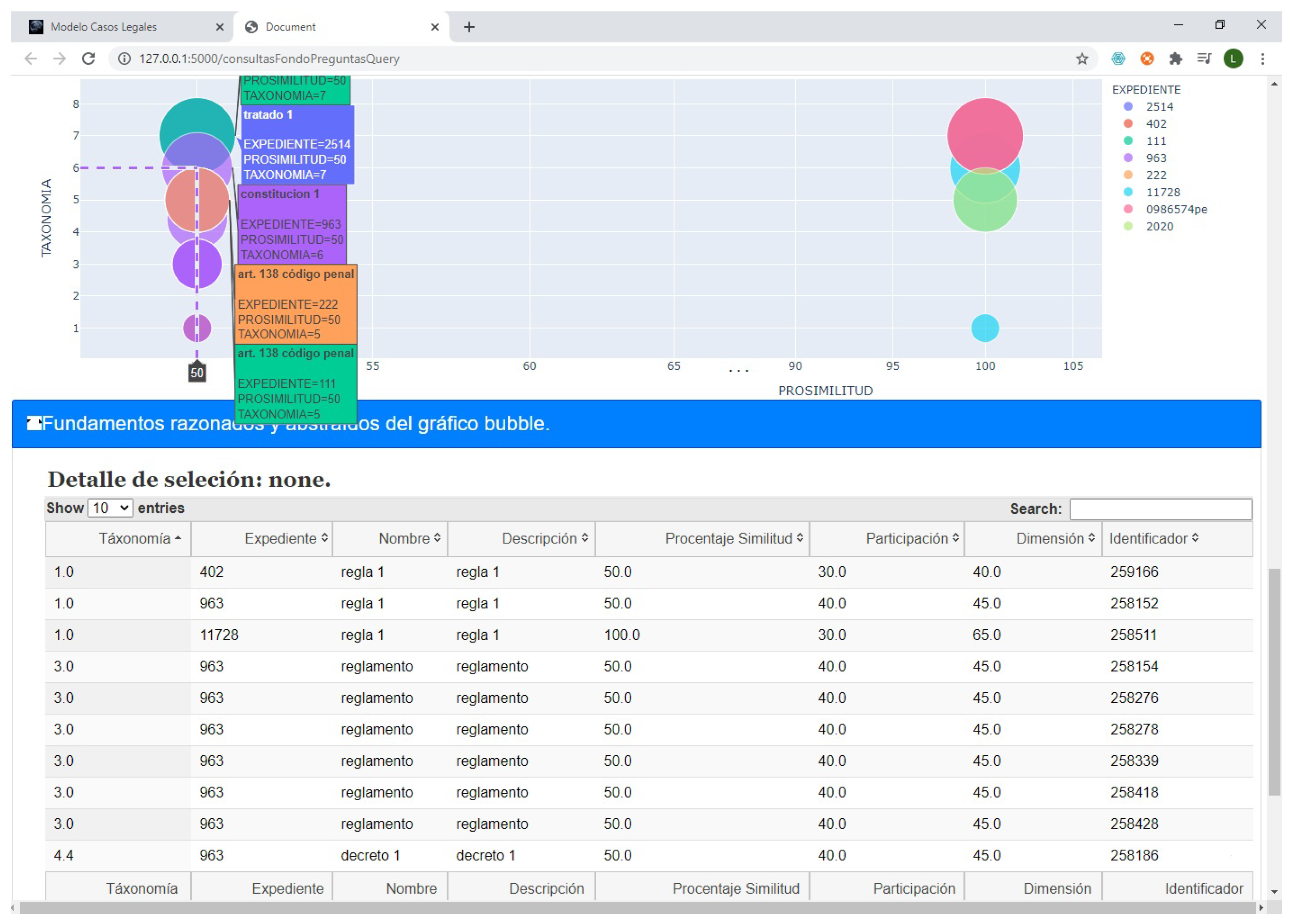
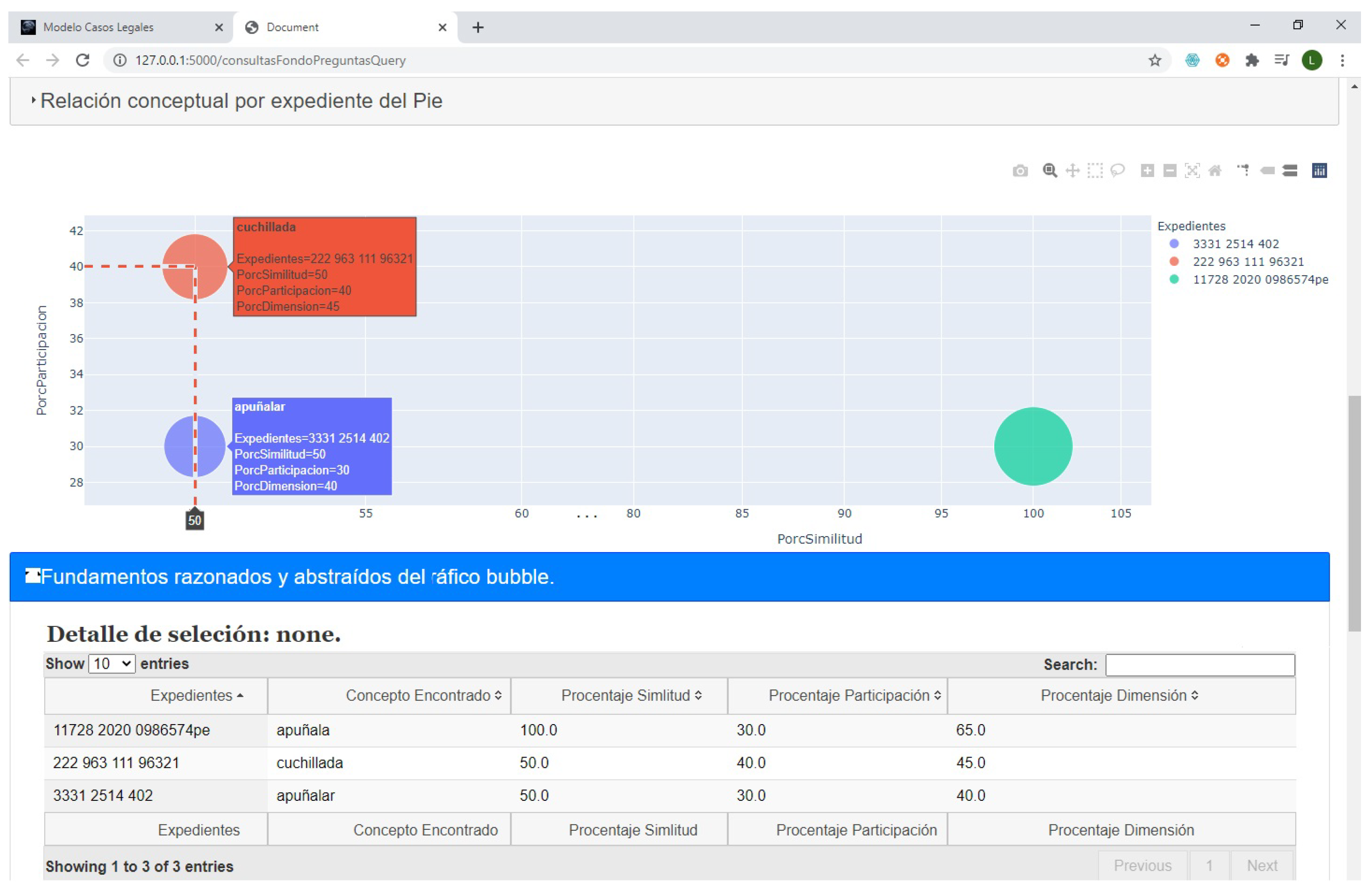
In
Figure 12, the percentage of participation represented by the Y-axis is used to explain the level at which the concepts or objects of the current case are within the factual picture of other cases. The X-axis is used to explain the level of similarity that the concepts have between the cases. The size of the circles represents the dimension or level of importance of the scenarios within the files. The machine recommends the group of files distributed and located higher or more to the right of the graph. The machine handles each fragment as a collection of nodes to describe the interpretation of juridical objects and the assessment of a juridical concept. In this way, it has been possible to investigate the legal explanations related to the inferences [
93] obtained by the system.
Internally the FR technique works using a strategic arrangement of data for each observation made by a human. FR uses the IA-AI method to get information as an input and reveals how it was interpreted and evaluated by a person.
Figure 12 shows examples of some calculations and graphical view when the system provides recommendations. A fragment is a set of cognitive information pieces represented by geometric figures, colors, sizes, positions, and distribution of data elicited from EGIs using IA-AI and KG. The system uses the fragments to manage and organize the set of objects and to be able to explain them.
A fragment
is represented by a collection of elements and the judge’s assessments. A fragment is an approximation of a set of nodes about a legal context
p where a set of juridical concepts
is in union with a set of nodes
joined with their relationships
. The variables
and
are decorating [
94] the juridical concept
. In this case, the decoration refers to the design pattern used programmatically (coding) to define a collection of objects that are capable of expressing the behavior of an individual object
dynamically, but without affecting the behavior of other objects of the same type in the same context; the programming paradigm used is Object-Orientation (OOP) to handle nodes, relationships, attributes, and properties. From the interpretation patterns, the construction of predicates occurs; imperative programming is used directly to manage the objects, and declarative programming is used indirectly to manage the assertions of the objects using CYPHER scripts. The set of objects contained in the fragments participate in (1) The Jaccard, Pearson, and Cosine formulas to work with the interpretation patterns, and (2) to organize and construct vectors from said patterns to make an inference.
3. Machine Specifications
Table A1 explains the main components, technology, formula, and concepts of the system in approximate order of operation. We will call each component with a “C” attached to a number, for example, “Component 3 = C3”.
Table 1 synthesizes and distills operations and essential functions to work with higher-order thinking and handle KGs in the system based on
Table A1. For now, the focus will be on C2, which provides the data structures that represent a KG (case) in the form of an ordered triple as shown in
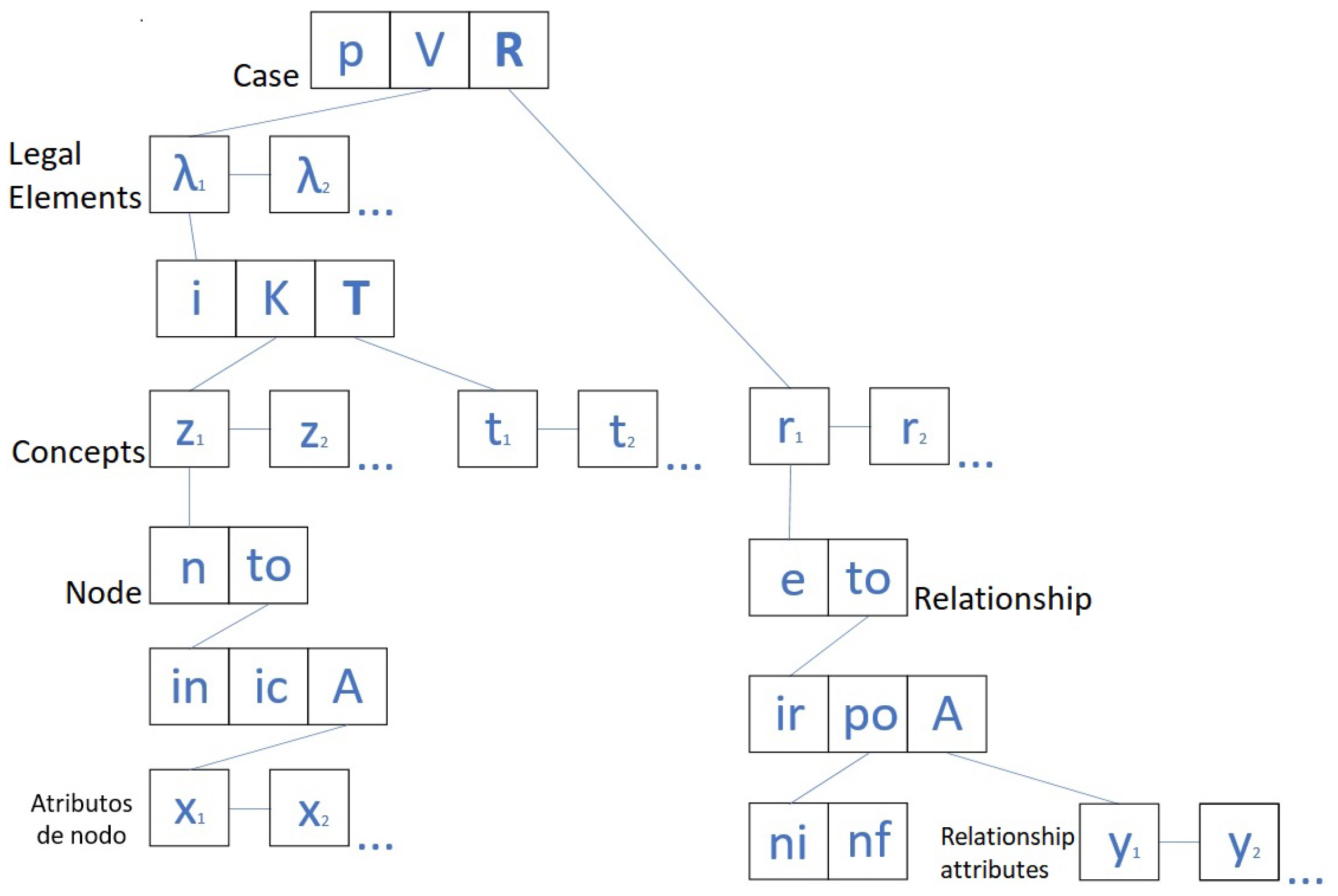
Figure A1. Equation (
1) shows the formal representation of the ordered triple, from which the extraction of elements such as concepts, nodes, and relationships is possible. The output of extraction is a list of values that represents the input for the vector construction algorithm shown in Algorithm 1. Inference generation uses vectors between scenarios. This section explains: (1) The ordered triple, (2) formulas and vector construction, and (3) a simplified real case scenario example using the formal representation of a case.
3.1. Data Structure
To explain each element in
Figure A1, consider this: Given graph
G represents an ordered pair in the form of
, where
N are the nodes and
E are the edges, the artifact handles this:
Each node or vertex (image) is an ordered pair in the form of where n is the label of the node and is an ordered triple in the form of where is the index of the node, is the index of the legal concept to which the node belongs, and . The x attributes of the node are text fields, for example, name and description of the node, and numeric values about precedence and importance levels that belong to the set of numbers ;
Each edge or arc (relations between images) is an ordered pair in the form of where e is the relation label and is an ordered triple in the form of where is the index of the relation, is an ordered pair in the form of where is the index of the start node and is the index of the final node, and . The attributes of a relationship are text fields, for example, name and description of the relationship, as well as numerical values about the link and relevance of the relationship that belongs to the set of numbers .
| Algorithm 1: Creation of vectors and related concepts in KG |
![Electronics 10 01500 i001]() |
3.2. Case, Context, and Scenarios
From
, a case
C is a ordered triple as shown in Equation (
1) where:
and is an index that identifies the context of the case assigned by the artifact;
V means the case scenarios in the form of where ;
R represents the relationships in the scenarios of a case in a given context in the form of .
Given the above, Equation (
1) shows a case with a set of relations
R for a set of nodes that constitute the legal elements
and describe the
V scenarios of the factual picture that occurs in a
p context. The relations and nodes were created from the transformation of interrelated images using the graphical interfaces of the artifact, and an index is an internal number that the machine assigns to the description of the context given by the judge, for example, “
”:
3.3. Legal Elements
A legal element is an ordered triple as shown in the Equation (
2) where:
and is an index that identifies a particular legal element assigned by the artifact;
K represents a concept in the form of where:
- (a)
,
- (b)
;
.
Equation (
2) means that in a legal element
there are relations
T for a set of nodes that form the concepts
K formed by facts or evidence, and an index
i identify them. The artifact assigns the index to each set of nodes to identify that set:
From the formal representations of the case explained previously, it is possible to supply a real, simple, and reduced example of an interpretation pattern. Consider Listing 1, this script seeks for patterns about nodes connected to the act of raping (Violation) someone under 18 years old. The pattern can be modified to look for children, older people, or undefined sex according to the rules of gender ideology. Modifications can be made to the script to apply deductive logic by taking a general aspect of a fact, evidence, or person and looking for a particular attribute pattern to canalize some legal study.
Listing 2 seeks particular attributes of people; in this case, it is a man connected with a woman, regardless of age or other characteristics, but considers the names. This script traces connection patterns up to 15 deep layers between these two people, and at the same time, extracts the shortest links between them. Deep layers mean the depth of connections between one object and another. Therefore, using this script can determine objects or events that are intermediaries between people to understand their criminal nexus.
Listing 1.
Simplified example of code about interpretation patterns related to the act of rape using CYPHER.
Listing 1.
Simplified example of code about interpretation patterns related to the act of rape using CYPHER.
Listing 2.
Simplified example of existing patterns between a node type Man and another type Woman using CYPHER.
Listing 2.
Simplified example of existing patterns between a node type Man and another type Woman using CYPHER.
MATCH (hombre:Jackie name: ’Jack Smith’ ), (mujer:Al name: ’Alice Kooper’ ), p = shortestPath((Man)-[*..15]-(Woman)) RETURN p
|
There are 3 ways to avoid ambiguities which are: (1) By using a specific context, (2) searching for a particular pattern, and (3) using vector similarity. Let us consider the following examples about patterns: (1) In contrast with Listing 1, the pattern (n)-[r]-(v:Violation)-[type]-(s:Agreement)-(y) seeks for nodes and relations connected with the violation of an “agreement” rather than a violation in “sexual” terms, and (2) if we compare the (John)-[under_TheEffects_of]->(Drugs)-[in]->(Stabbing) pattern with the (Alice)-[under_TheEffects_of]->(Drugs)-[in]->(bed) pattern, we obtain that there is no ambiguity, due to the intrinsic nature of both patterns. However, the use of the pattern (person)-[under_TheEffects_of]->(Drugs)-[]->() would serve to look for other patterns in all the database knowledge, where a person is under the influence of the drug, regardless of gender, name, or any other characteristic. In the latest pattern, the Alice and John scenarios are collected, differentiated, and explained by the system using charts and geometric figures that explain their differences. From the interpretation patterns, it is possible to extract vectors from them to compare scenarios and generate inferences.
3.4. Vector Creation
C6, explained in
Table A1, is responsible for constructing the vectors. The construction consists of 2 phases. In the first phase, attribute calculations of nodes and relationships take place. The attributes are effect (
E), link (
), and importance (
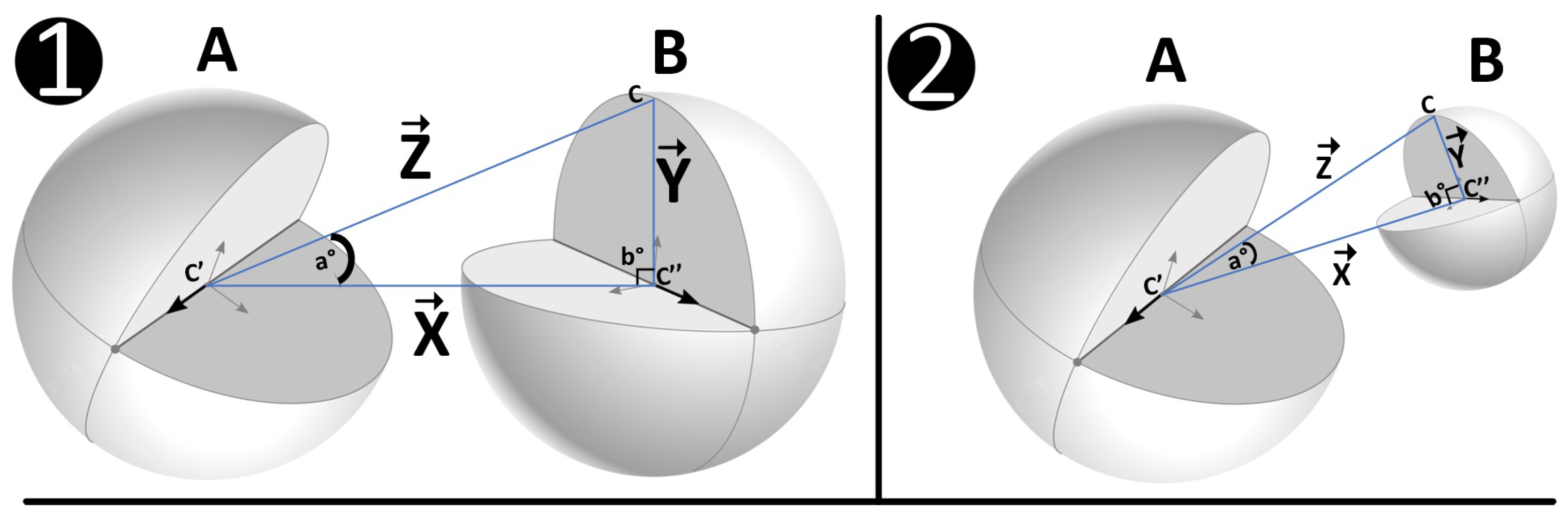
). The use of these attributes is through an adaptation of the Pythagorean formula in a Euclidean space; this formula generates values between two connected nodes by using a right triangle that is formed between their centers and the circumference of each one in a 3D plane, as shown in
Figure 13. In the second phase, by using Algorithm 1 it is possible to obtain the vector modules.
Algorithm 1 receives as input a list of nodes and relationship attributes, as well as a list of legal concepts obtained from EGIs. The input lists of object attributes are processed to create output lists of vectors. The lists of vectors represent, in a unique way, the factual pictures of the scenarios in a case. C3 is responsible for applying Natural Language Processing (NLP) techniques like the paradigmatic and syntagmatic process to the input list of concepts to detect which ones accept a replacement and which ones can be combined, respectively. NLP techniques produce output lists of paradigmatic and syntagmatic relationships of concepts used as filters in searches for interpretation patterns. The output lists of vectors and concepts from Algorithm 1 are input parameters in Algorithm 2 which make inferences.
| Algorithm 2: KG legal inference using Cosine, Jaccard, and Pearson functions |
![Electronics 10 01500 i002]() |
Part 1 from
Figure 13 represents linked nodes in a scenario. Each sphere is a node. Between the nodes, there are sets of vectors
,
, and
obtained from links, that is, the relationships of the nodes. The vector
has the origin point in
, which is the center of node
A, and the endpoint is
which is the center of node
B. The vector module
constitutes the assessment of the links between facts and evidence using the relationships between the images, for example, the links shown in
Figure 4. The vector
has the origin point in
, which is the center of node
A and the endpoint in
C, which is the circumference of node
B that represents the diameter of the node. The vector module
is built with CYPHER scripts to classify information about the importance levels obtained from interfaces like the one shown in
Figure 5.
Part 2 from
Figure 13 represents multiple variations of nodes and relationships in a scenario and represents dynamic changes in the perception of objects in the real world. For example, consider node
A as a fact and node
B as evidence. Between these nodes, there is a small increase in the distance and makes vector
have a longer link between the nodes. The “increase” of the module
means a “decrease” in the legal connection that node
B has over node
A. A longer link between the nodes reduces the ability of node
B to be able to express the influence it has on node
A. In other words, node
B is not so capable of expressing the influence on node
A. A decrease in the size of node
B implies a decrease in the module
and means a reduction in the legal importance of node
B within a scenario in which
A also participates.
3.5. Jaccard Index
Jaccard is a statistical measure that consists of measuring the similarity between finite datasets, for example, between a set of objects and . This is a division between the size of the intersection and the union of the element sets. In this case, vector modules provide a series of values to create the sets to be compared. This process provides values between 0 and 1; the first expresses inequality between vectors and the second total equality between them. This index is useful in queries to detect patterns of similar objects (nodes or relationships) within scenarios, for example, to obtain the granular similarity between sets of facts or evidence, or between attribute values that belong to different groups of scenarios, that is, to be able to obtain similarities between attributes belonging to the same type of nodes, but that belong to different scenarios:
3.6. Cosine Similarity
Cosine Similarity is a measure of similarity between two vectors, in this case, those that belong to a set of objects
and
other than zero. It means that it calculates the angle between vectors to get the cosine by multiplying the values of each vector, adding their results, and then dividing the result by multiplying the square root of each value of the vector squared. A pair of vectors oriented at 90° to each other have a similarity of 0, meaning they are not equal, and a pair of diametrically opposite vectors have a similarity of −1, meaning they are opposite. On the other hand, if both vectors point with an orientation towards the same place, they have a similarity of +1, meaning they are equal. The different values that the cosine angle acquires reflect a greater or lesser degree of similarity between the attributes of the relationships that the scenarios contain. This type of similarity is helpful in detecting assessment patterns, for example, to identify similarities between the angle produced between the link and the effect between a pair of nodes in the same scenario or indifferent ones. The angle a° produced by the assessment of the link (line connecting nodes from their centers), and the effect (line from the center of one node to the diameter of the other), are shown in
Figure 13.
3.7. Pearson’s Correlation
The Pearson Correlation Coefficient is a statistical measure to detect a linear correlation between two variables A and B. It has a value between +1 and −1. A value of +1 is a total positive linear correlation, 0 means there is no linear correlation, and −1 is a total negative linear correlation. The Pearson similarity is the covariance of the values from vector modules divided by multiplying the standard deviation of the values of the first vector by the standard deviation of the values of the second vector. This coefficient is helpful in queries about the correlation of values, for example, to calculate the correlation between the link and importance of two connected nodes in a scenario, for example, the values of a vector represents the attributes contained in the link of a node A connected with node B. A second vector represents the importance that node B has for node A. Thus, if A is a fact and B is proof, then the level of correlation between link and importance is the degree to which evidence can demonstrate that an event occurred, according to the interpretation of a judge.
3.8. Dataset Example
Figure 14 shows a composite scenario of a real murder case. The structure shown in
Figure A1 explains a piece of a set of objects of this case and describes the dataset involved. The following points summarize the example and the data structure.
The interrelated images of
Figure 14 are taken to build the nodes according to the definition
, and relationships following the specification
. This produces the structures shown in
Table A2;
Then labels, indices, and values of the nodes are obtained from step 1, as shown in
Table A3;
From step 2, information about relationships, indices, and labels from the connection of each node, is shown in
Table A4, and;
Using the information from
Table A2 about the descriptions, the artifact extracts the concepts “injure” and “disable” according to the representation
and an index is assigned to them, for example 333 and 444 respectively;
Using
Table A2 and
Table A3 and the concepts obtained from point 4, the artifact distills 2 legal elements that are shown with Equations (
3) and (
4) respectively. An index is assigned to each legal element, for example, 10,000 and 11,000, and this is done following the definition
:
The artifact assigns an index to the case, for example, “999999” and then it creates the case as shown in Equation (
5) following the definition
and according to the information obtained from the previous steps:
The artifact offers different queries to analyze the case. Depending on the query type, the Jaccard, Cosine, and Pearson formulas are executed individually or in combination. Obtaining differences is according to the type of analysis and query the judge wants to execute. The artifact shows the recommendations as in
Figure 8. At the end of this figure, the judge can select the laws and norms supplied by the system. The system automatically converts the selections into images and incorporates them into the working canvas so the judge can continue, if necessary, with the analysis of more information.
4. Research Question and Hypothesis
The following research question arises: “Is it possible to capture and represent a judge’s interpretation and assessment processes of the legal file data and apply machine learning on said processes, to generate recommendations before the resolution of a case related to jurisprudence, doctrine, and norms in different legal contexts and get a positive behavioral response from the judge?”
Thus, a secondary question arises: “Can the system can be used by a judge to support his decisions, but without being seen as a threat of decision-making [
95] bias?”
The above research questions are intimately linked to the unsolved problem, raised long ago by Berman and Hafner in 1993 [
3] on “how to represent teleological structures in CBR?” Teleology is the philosophical doctrine of final causes [
51], which means, according to Berman and Hafner, identifying the cause, purpose, or final reason for applying a law or rule to regulate (punish) an act (fact) identified as a felony. Thus, the answer to the first questions also provides a reasonably approximate answer to Berman and Hafner’s question.
As judges have hierarchies in their roles and there are types of technical criteria to study the behavioral response of a judge, the statement of the following hypotheses is as follows. (1) : The hierarchy does not affect the acceptance of the system and : The hierarchy does affect the acceptance of the system, as well as (2) : The criterion does not affect the acceptance of the system, : The criterion does affect the acceptance of the system.
5. Material and Methods
SME has defined real world legal situations to test cases with RYEL, which represent criminal conflicts in a trial and have allowed to reduce the number of cases that initially would have been necessary to carry out the experiments. The use of multi-country scenarios for laboratory testing was 83 from Costa Rica, 25 from Spain, and 5 from Argentina. In addition, experts in artificial intelligence participated from Costa Rica and Spain [
2] and were counted, to be a total of 17. As the laws are different in all countries, a norms equivalence mapping was necessary to implement, which means a set of implication rules in the form
, where
is the name of a norm in a specific country and is equivalent, but not equal, to
which belongs to another country. In this way, there was no problem analyzing the same criminal factual picture (facts and evidence) in different countries without being strictly subject to the name of a norm.
5.1. Participants
Two groups of research subjects participated in this study. The first group of judges was selected at random, belonging to courts, tribunals, and chambers in criminal justice. In addition, military-grade judges were also included randomly at the magistracy level to include data about military behavior when using this technology. Experiments in Panama [
26], Spain, and Argentina involved 16 expert judges in the criminal field, while in Costa Rica, there were 10 judges [
2] which also include Ecuador and Colombia. The second group was a sample of judges selected randomly at the national level in Costa Rica.
5.2. Design
This study is an adaptation of a 3-stage experiment. The first stage is to study the acceptance or denial behavior of the judge when using the system. The second stage compares the results obtained from the first stage with the second group of judges. The third stage consists of investigating whether the responses of the second group were affected by factors such as judges’ hierarchies (their roles) and the kind of evaluation criteria. The results of one stage are the inputs of the next.
In the first stage, the use of User Experience (UX) [
96] is a means to investigate the behavioral response of a judge in terms of accepting or rejecting the application of RYEL to analyze the merits of a case.
Table 1 shows a synthesis of the primary operations that were used by the research subjects when manipulating KG using images. The fundamentals of measurement parameters are from the quality model called Software Quality Requirements and Evaluation (SQuaRE), defined in [
97]. The characteristics of this model are adapted to investigate the degree to which a system satisfies the “stated” and “implied needs” of a human (stakeholders) and is used to measure the judge’s behavioral response. The characteristics used from the model are “functional suitability”, “usability”, and “efficiency” linked to technical criteria issued by the judge.
Table 2 shows a synthesis of the characteristics, parameters, and criteria considered in the experiment.
A quality matrix [
98] or evaluation matrix was created using
Table 2 and applied to the judges at the end of the first stage. The matrix allowed to obtain quantitative values for each of the criteria. The criteria were posed as questions and measured with a Likert Scale [
99] as 5–Totally agree, 4–Fairly agree, 3–Neither agree nor disagree, 2–Fairly disagree, 1–Totally disagree, and 0–Not started. A treatment is a legal case of homicide applied to each research subject (judge) using RYEL. The experimental unit consists of pairs of related nodes that form a KG that describes the case graphically.
The second stage consists of obtaining objective evidence [
97] to validate the results of the matrix against the criteria of another group of judges. For this, obtaining an additional random sample of 172 judges from Costa Rica was necessary to take. The total population of judges working in Costa Rica is 1390 [
100]. The sample includes all hierarchies of judges and represents 12.37% of active judges in the country. To this sample, a questionnaire was applied based on the criteria from
Table 2. This sample focused on judges that do not necessarily know each other; they have not used or have seen the system before, and they do not know or have met the investigators conducting the research. In this way, it is possible to reduce the information bias [
101] in this type of research. The judges received information on the system’s method, operation, and characteristics through the questionnaires’ descriptions and formulation. The criteria in the questionnaire were organized into groups of 10 questions and coded from 1-P to 10-P, as shown in
Table 3, for statistical purposes. The design of the questions considered the Liker scale for their answers. This design was similar to the one used in the evaluation matrix explained before. It was necessary to coordinate with the Superior Council of the Judiciary in Costa Rica to contact the judges across the country.
The third stage uses the information gathered in the sample at the national level in Costa Rica to make a Two-way Analysis of Variance (ANOVA) [
101]. This analysis was to check if there are significant statistical differences that prove the hypotheses about whether the factors like hierarchies and legal criteria affect the behavioral response of acceptance or denial of the judges about using the system. The criteria have 10 levels, one per group of questions, from 1-P to 10-P. The hierarchy has 4 levels which are: (1) Criminal courts; (2) tribunals; (3) chambers; and (4) other. The latter consider members of the superior council and interim positions of judges during designations.
5.3. Setting
Due to the circumstances caused by COVID-19 and in which the judges found themselves, the experiments were conducted either onsite (judge’s office) or remotely (virtual meeting via a shared desktop). In both cases, a Dell G5 laptop was the hardware used for experimentation. The laptop had 15.6” of full HD IPS display, 16GB RAM, and a Hard Drive of 1GB. After a legal and coordinated appointment with the judges and setting up the test environment, it was possible to proceed with the experiments.
5.4. Procedure
In the beginning, each research subject watched a video. The video explained the experiment, the operation of the system, and the function of the EGIs. The video was 2.6 min long. It used a test case A about a homicide using a dagger and another test case B about a homicide with a weapon. Various experts helped the design process of the test cases, 2 in law and 2 in artificial intelligence, who verified them.
In the first stage, N = 26 research subjects from Colombia, Ecuador, Panama, Spain, Argentina, and Costa Rica were obtained and asked to draw in the system the interpretation and assessment of the facts and evidence contained in the test case
A according to their perspective using interrelated images. At the end of the drawing, each subject produced a KG. The KGs produced were compared to each other to determine differences. Then, a division of the group of subjects
N into two groups in the form of
each took place. Test case
B was given to the first group to obtain a new KG from each member. The second group, who never saw case
B, was asked to observe and explain at least 3 KGs made by the first group to check if they were able to understand the interpretation and assessment contained in the KGs. Finally, the two groups ran legal analysis simulations with the system to determine whether it was possible to study the merits of the case. After cases
A and
B were used to explain the system, each member of the groups was allowed to use the artifact to enter new cases or vary the previous ones to test the system in depth. Then, the evaluation matrix was applied to each research subject to collect the UX that each one lived after using the system. Real life examples of the experiments with the research subjects are shown in
Figure 15 when they were using the system to analyze the merits of a case about homicide.
In the second stage, it was necessary to request a legal license from the Superior Council of the Judiciary in Costa Rica in order to be able to contact all the judges of Costa Rica and to send them a questionnaire. The criteria of
Table 2 allowed us to build the questionnaire containing 10 groups of questions.
In the third stage, 172 sample of judges responses were taken from the questionnaires sent. The data of the responses were processed and tabulated. Finally, a two-way ANOVA was applied to the data to determine if the hierarchies or criteria affect the behavioral response of the judge; if they accept or refute using the system to analyze the merits of a case.
6. Results and Discussion
The judge’s behavioral response was a tendency to accept the system, recognizing that it can help with the analysis of the merits of a case without violating judicial independence and discretionary level.
Table 4 shows an extract of the evaluation matrix by country. Out of six countries, fr showed a behavioral tendency of 90%, or more, to accept the system, reaching almost 100% in some cases. Colombia and Ecuador presented different results that are very close to 90% acceptance because some of the legal cases used for experimentation did not contain the names of regulations from those countries, and the judges belonging to them wanted to evaluate the names related to their legislation. Despite this, the acceptance of the computational method implemented by RYEL was very positive in all the countries subject to experimentation. The explanation of the system required the use of two cases, but each judge entered from five to six real life cases when allowed to test the system. If 26 judges tested the system, it means that at least 130 case variations were used in total. In adition, the 113 cases used to manufacture the system from different countries must also be added. The total number of cases was approximately 243 from various countries used to create and test the system. It is necessary to remember that the SME supplied representative cases of the discourse domain; therefore, the high amounts of data did not present an obstacle and did not determine the risk of bias that would typically occur with another approach.
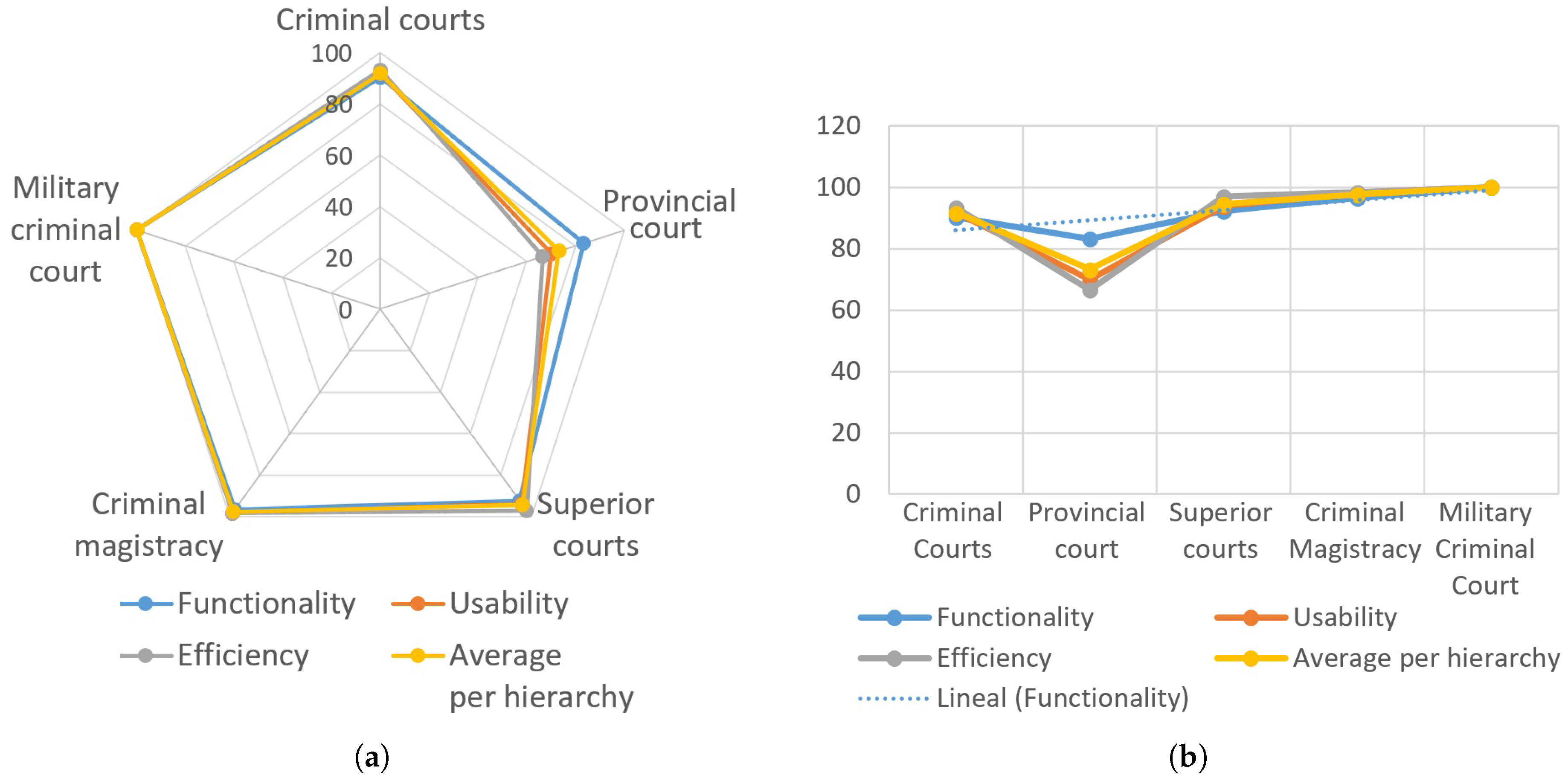
The radar graph in
Figure 16a shows the comparison of the system evaluation results according to hierarchies. The characteristics described in each vertex reveal that the distances between criminal courts, military criminal courts, criminal magistrates, and superior courts are very close to each other and with high values. The average acceptability per hierarchy on the radar places values very close to 100% of acceptance. The provincial courts had a slightly lower acceptance rate. The reason was that some judges were unable to complete the experiment as they had to attend trials, and it was not possible to reschedule the experiment, and it reflects in the usability and efficiency vertices whose values are below average. Nevertheless, the vertex of the functionality in the provincial courts has values very close to 90%, which means that this hierarchy accepts the system well, despite the other low values.
Figure 16b shows the acceptability trend of the system among the judges, according to the hierarchical order. This trend remained unknown under the ordinary conditions of legal review processes, but detection was possible during the system’s evaluation. For example, it was possible to find that when the higher-ranking judges needed to review the work done by the lower ones, it was easy for them to graphically arrange the teleological structures of the facts and evidence using KG through the EGIs to carry out the reviews of the analysis made by the lower-ranking judges. Furthermore, it was possible to reveal that lower-hierarchy judges tended to accept the system in terms of the support they received from the EGIs to perform the interpretation and assessment of facts and evidence as part of the analysis of the merits of the case. On the other hand, the higher-ranking judges showed more acceptance of the system, especially regarding the support they received from the EGIs to access the teleological and semantic approach created by the lower-hierarchy judges.
The information collected up to this point responds to the first research question, and it reveals that the system was able to capture the interpretation and assessment of facts and evidence from the perspective of a judge. Regarding the second question, the results reveal that the judge’s behavioral response was very positive and with a tendency to accept the system to analyze a case without representing a risk of bias or a threat to decision making.
The validation of the previous results was against other evaluations of judges; this evaluation required the application of questionnaires to all the active judges of Costa Rica (1390), and the random sample of 172 showed a mean of 4, a mode of 5 (Likert scale designed), and a standard deviation of 1.2988. These data are in
Table 3. It means that the judges tend to accept the approach, operation, and framework implemented by RYEL.
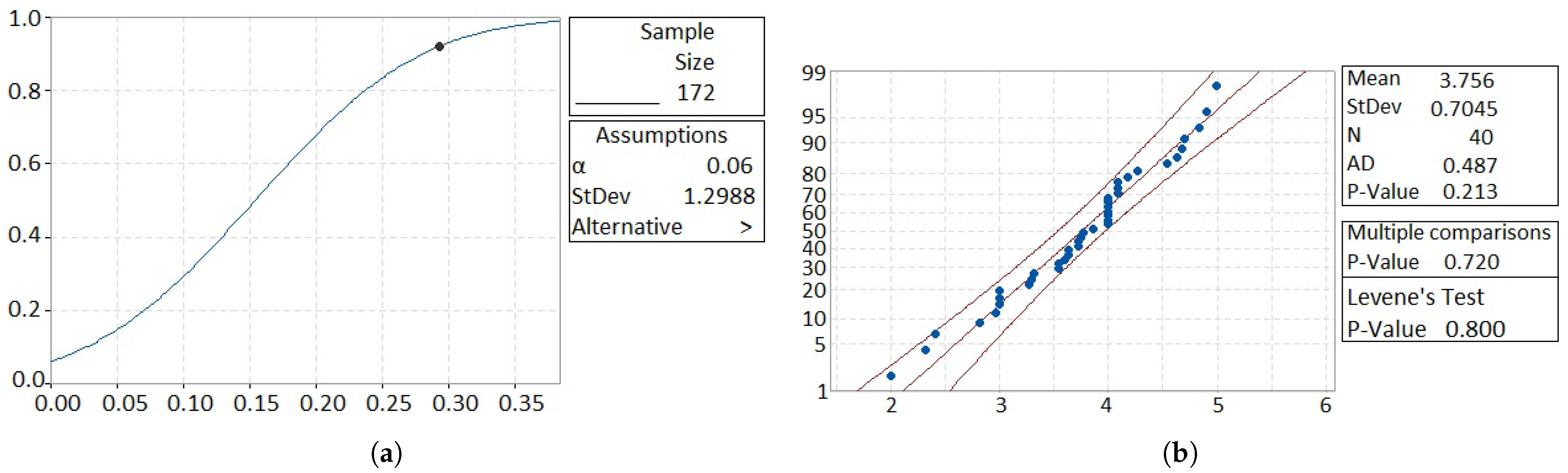
For the statistical verification of the sample and the collected results at the national level,
Figure 17a shows the 1-Sample Z test, which had 92% of statistical power, a significant percentage for samples and experiments [
101]. The statistical significance level is
, from which we can obtain 94% in the confidence intervals in the statistical tests.
Figure 17b shows that the judges’ responses comply with the normality assumption, having a
P-
= 0.213 >
where the normality hypothesis is accepted. There is a low Anderson–Darling (AD) statistic value of 0.487 which means a good fit for the data distribution. The Levene statistic is
, which means the hypothesis acceptance about equality of variances when working with the hierarchy and legal criteria of the judges in the answers of the questionnaires.
Due to the results obtained in the previous statistical analysis, connected with the need to determine if indeed the results obtained from the UX and the questionnaires were affected by the hierarchical trend shown in
Figure 16b or the criteria, a tTwo-way ANOVA was necessary to apply. The results are in
Table 5 where the hierarchy factor has a
P-
= 0.148 >
, which means that the null hypothesis that the hierarchy does not affect the response of the judge is accepted since there is sufficient statistical evidence to state with 94% confidence that the judge’ responses are not affected by the hierarchy. On the other hand, the criterion factor at the same table shows a
P-
= 0.000
and means that the null hypothesis that the criterion does not affect the response of the judge is rejected since there is significant statistical evidence with 94% confidence that the criteria do influence the judges’ response. These results reveal that the judge’s behavioral tendency to accept the system is due to the criteria discussed and analyzed, not because of a human’s position. It also means that the trend found in
Figure 16b has a 94% statistical probability that it is due to the actual operation of the system and not to the position that the judge holds.
Concerning the above,
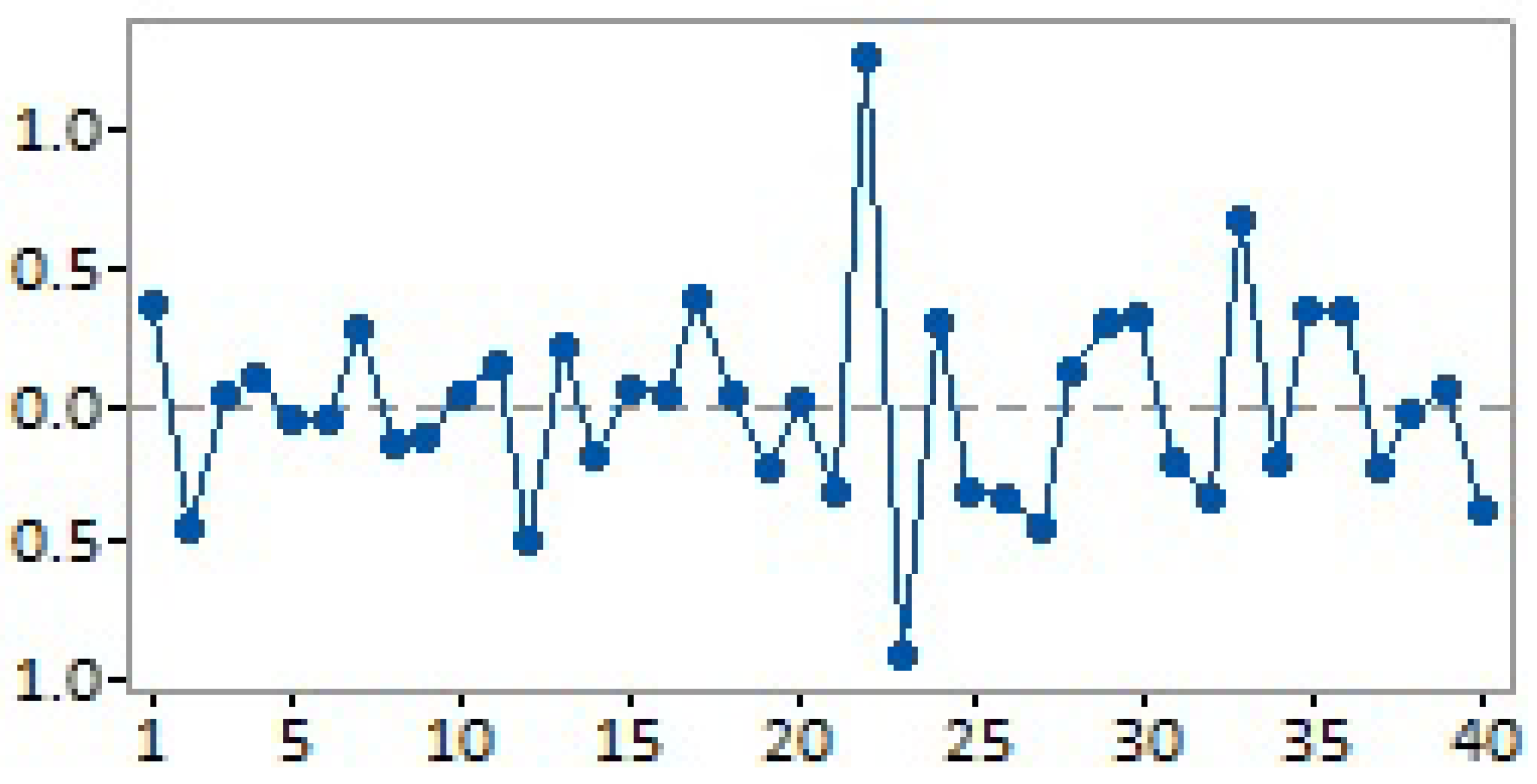
Figure 18 shows the residuals from the analysis of variance. The
represents the residual values, and the
represents the order of the observations. There are no patterns nor a fixed trend. Therefore, the data obtained from the responses on the criteria are independent, and this means that there is no codependency in the data that could affect the results.
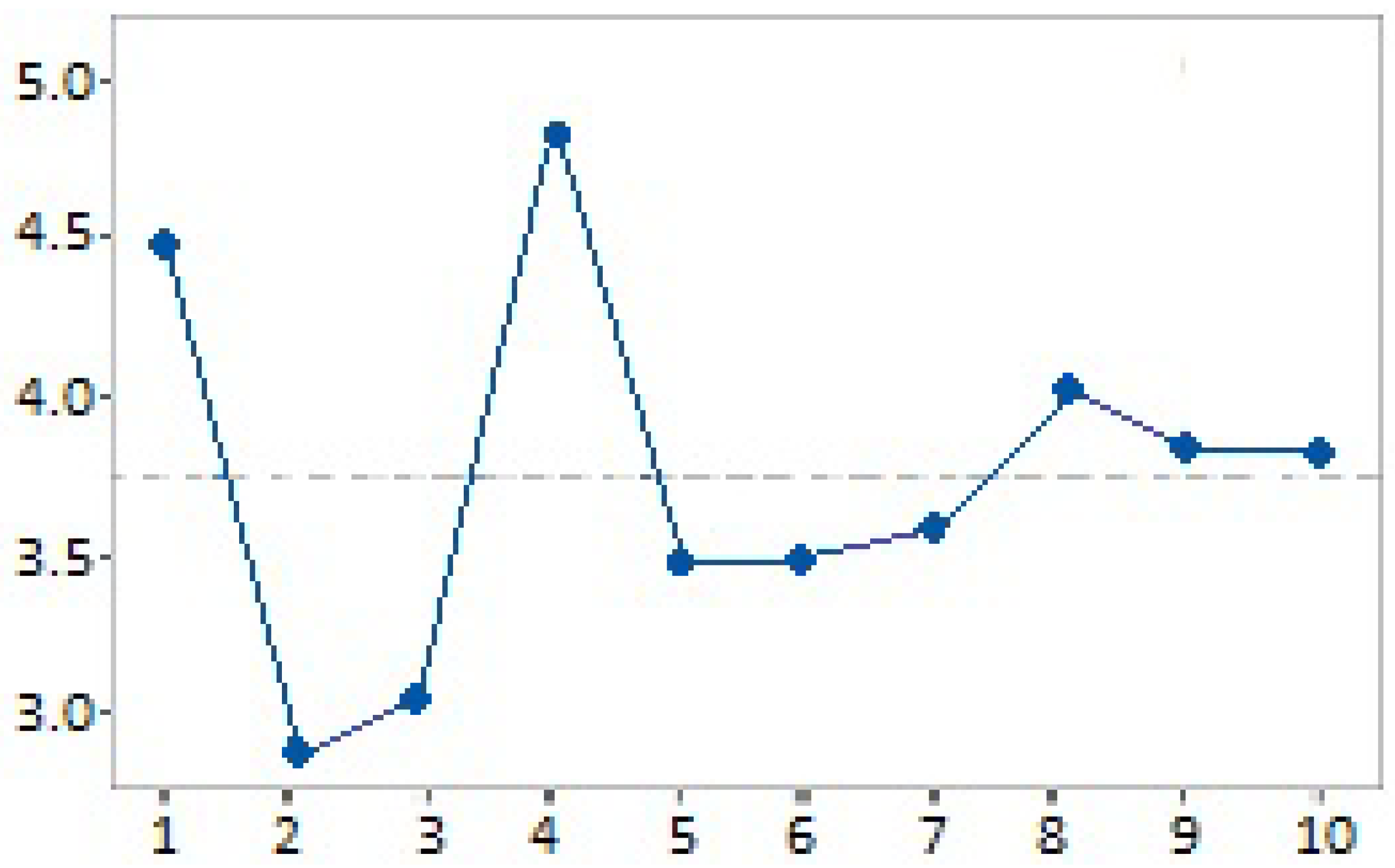
Figure 19 shows the main effects in responses to legal criteria. The
is the mean of the criteria; the
represents the criteria. Thus, criterion 2 or 2-P has the lowest main effect of all because this group of questions referred to whether a legal case must always be resolved similarly to a previous case, with more or less similar characteristics. It means that statistically, there is enough evidence to affirm with 94% confidence that the judges reject the idea of receiving help that implies always solving a case just as another similar one was solved. The 2-P group of criteria in
Figure 19 compared with
Table 3 which has a mean of 2 and a mode of 1 for the same criterion, indicates that indeed the judges do not approve the 2-P criterion. It is necessary to remember that RYEL uses the CBR stages to exchange and organize data; this means, as a guide of the information, and does not develop the traditional implementation of using strictly the same solutions from past cases to solve current ones. This implementation makes RYEL’s contribution to the domain of discourse evident.
Figure 19 shows the criterion 3 or 3-P, which is the second one to have low values and refers to whether the judges believe that IA could help them with the analysis of a case. This point deserves special attention because analyzing the extended answers made by the judges in this group of questions makes it possible to understand that the judges associate AI with the automation and repetition of legal solutions applied indiscriminately to each case, without receiving any explanation and without being in control of the machine. This situation, of course, is not the way of work of RYEL.
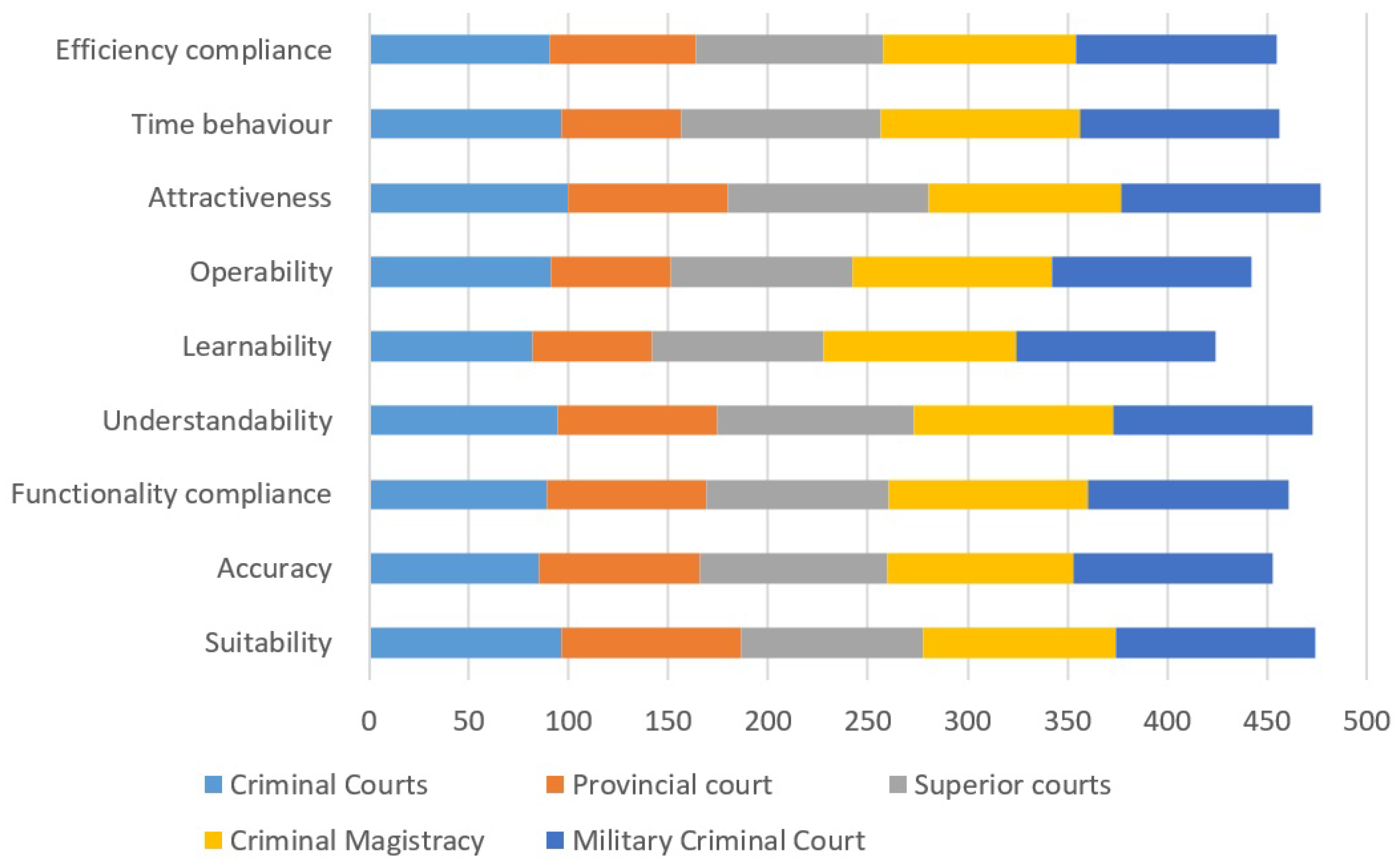
Figure 20 shows the cumulative acceptance percentages grouped by the SQuaRE-based design parameters. The lowest percentage is learning because not all people have the same abilities to learn. The highest values are attractiveness, understandability, and suitability, which translates into a motivational design consistent with the needs of the research subject and the legal domain. On average, the rest of the cumulative acceptance percentages of the system are pretty high; this means that the domain expert quantifies, according to the SQuaRE parameters, that the system is helpful in analyzing the merits of the case.
Table 6 shows the cross-check of the survey-based statistic analysis between the 4-P and 10-P criteria. The first criterion is that if, in order to analyze the merits of a case, it is essential to carry out an interpretation and assessment of facts and evidence. The second criterion is whether RYEL is novel and useful as a decision support tool. The results confirm the following: (a) No research subject marked option 1 for any of these criteria, (b) only four research subjects marked the options 2 and 3 for both criteria, which is only the 2.32% of the research subjects and it means that an insignificant number of them do not agree with the legal analysis approach and with the tool, and (c) most of the research subjects when marking options 5 and 4 for criterion 10-P also marked 4 and 5 options for criterion 4-P, which means that most of the research subjects understand and accept the legal analysis approach and the operation of RYEL.
All the results obtained show the following:
The system was able to capture the high-order thinking of a judge to assist with analyzing a case using KG through images;
The system is a novel implementation of machine learning in the legal domain;
It was possible to explore and find shortcomings in the behavioral response and position of a judge in the face of this type of technology.
6.1. Comparison with Similar Approaches
By comparing our research with works with similar approaches, we extend the results. Attention is on expert and case-based systems.
Table A6 shows the 23 most essential expert systems from 1987 to the present, which are related to our research. The table shows the key elements, computational technique, and approach. The most important results obtained when comparing our system with the systems in this table are: (1) No system works with dynamic KG, (2) they do not use graphical techniques to elicit legal meta-knowledge of a person, (3) they do not work with high-order thinking, (4) do not allow an analysis of the merits of a case, (5) they do not focus on the judge, and (6) cannot be extended to other domains of knowledge.
Table A5 shows the primary investigations focused on CBR from 1986 to the present and related to our approach. This table shows the key elements, case types, and approaches. The main results obtained when comparing these investigations with ours are: (1) They do not contemplate multiple and complex scenarios within the cases, (2) no investigation considers data processing from the perspective of a human, (3) they are only focused on lawyers or prosecutors, not to judges, and (4) none of them processes teleological, semantic, ontological, and hermeneutical information to support decision making.
6.2. Functional Limitations
The system works with data from a factual picture, direction of the legal process, and assessment of the evidence. Information about the criteria of the judge that are not typical of the analysis of facts and evidence, for example, the criteria a judge may have on the management and administration of an office, control of dates to avoid document delays, and office procedures, are not considered in this research. However, a judge can indeed consider that a case has been prescribed and request the archive of the documents. The type of data about this request is not part of the system.
6.3. Applicability
There are two fundamental aspects of a resolution that are “form” and “substance”. The form is the way to present and write a resolution complying with the requirements and formalities that the law requires, for example, a heading, covers, and numbers of pages. The substance refers to the in-depth study of the matter in conflict and then issues a resolution based on substantive law, which means a set of obligations and rights imposed by law. The applicability of this work refers to the substance of the case and not in the form.
6.4. Implications
The above results have particular implications in both the computational and legal domains. RYEL could mark a before and after in systems with a legal approach because it allows an evolution from predictive systems to systems with explanatory and analytical techniques. Some of the most relevant implications from this in the computational field are:
Due to explicability techniques, “Black Boxes” problems in machine learning could be overcome by methods like IA-AI when dealing with human perception;
The reduction and nullification of algorithmic bias and bias related to data and processes is gaining momentum because third parties do not manipulate the cases and analysis processes. Instead, the judge enters the cases in real life and commands the analysis with the options provided by the system; the latter explores the relationships and objects the judge creates, explains the inferences, and offers to the judge options to make decisions;
Judges from other hierarchies can review the sentences using RYEL in the different legal stages. This review could cause a reduction or elimination of bias related to a wrong perception, incorrect interpretation, and an erroneous assessment.
Some of the most relevant implications in the legal field are:
RYEL shows the potential to be a disruptive technology in the domain of discourse and could cause the user to resist the change;
The system allows experts to analyze the scenarios from different perspectives and reach agreements; this generates a unification of legal criteria and decreases legal uncertainty;
The system paves the way in the jurisdictional area by allowing a computational mechanism to participate in a judge’s exclusive functions when decision making takes place.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





















