
Light-Weight Self-Attention Augmented Generative Adversarial Networks for Speech Enhancement



Abstract
:1. Introduction
2. Related Works
3. Self-Attention Mechanism
4. Self-Attention Speech Enhancement GANs
4.1. Speech Enhancement GANs
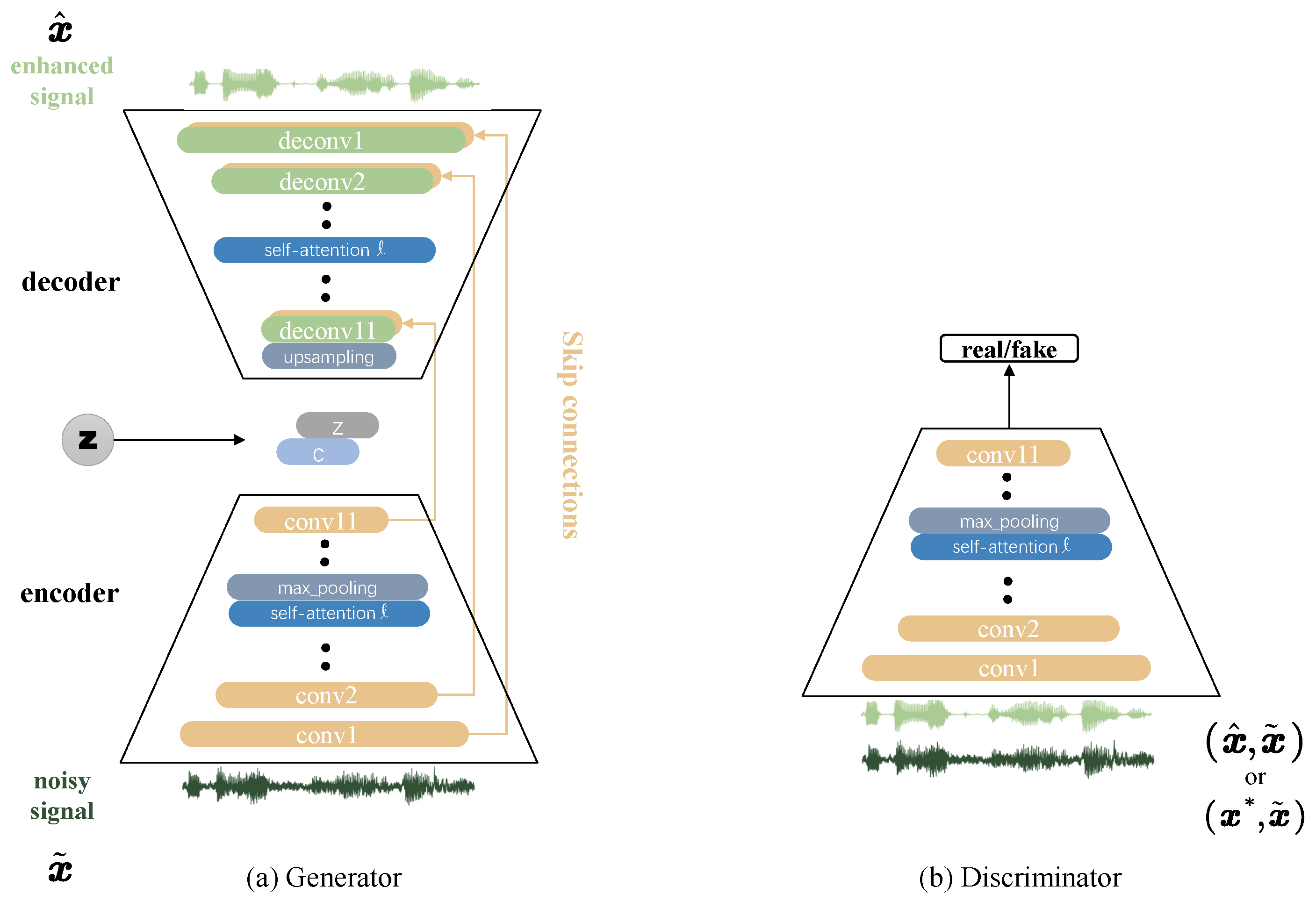
4.2. Stand-Alone Self-Attention Speech Enhancement GANs
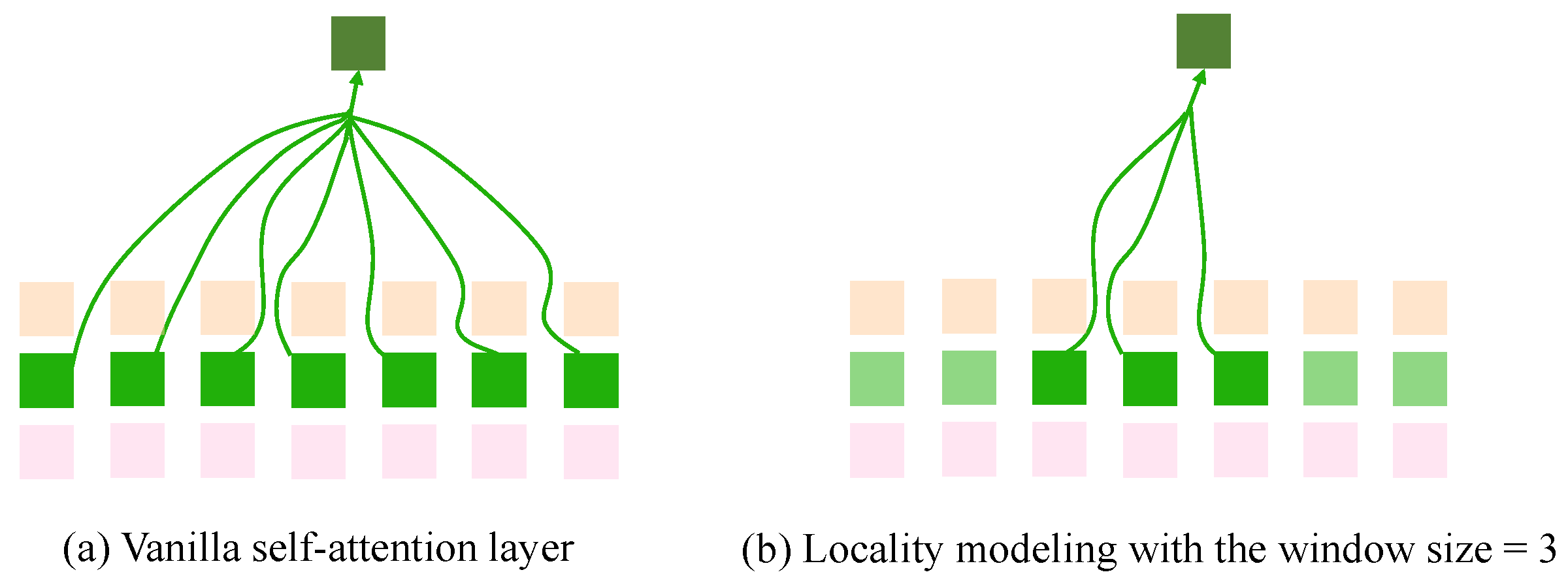
4.3. Locality Modeling for Stand-Alone Self-Attention Layers
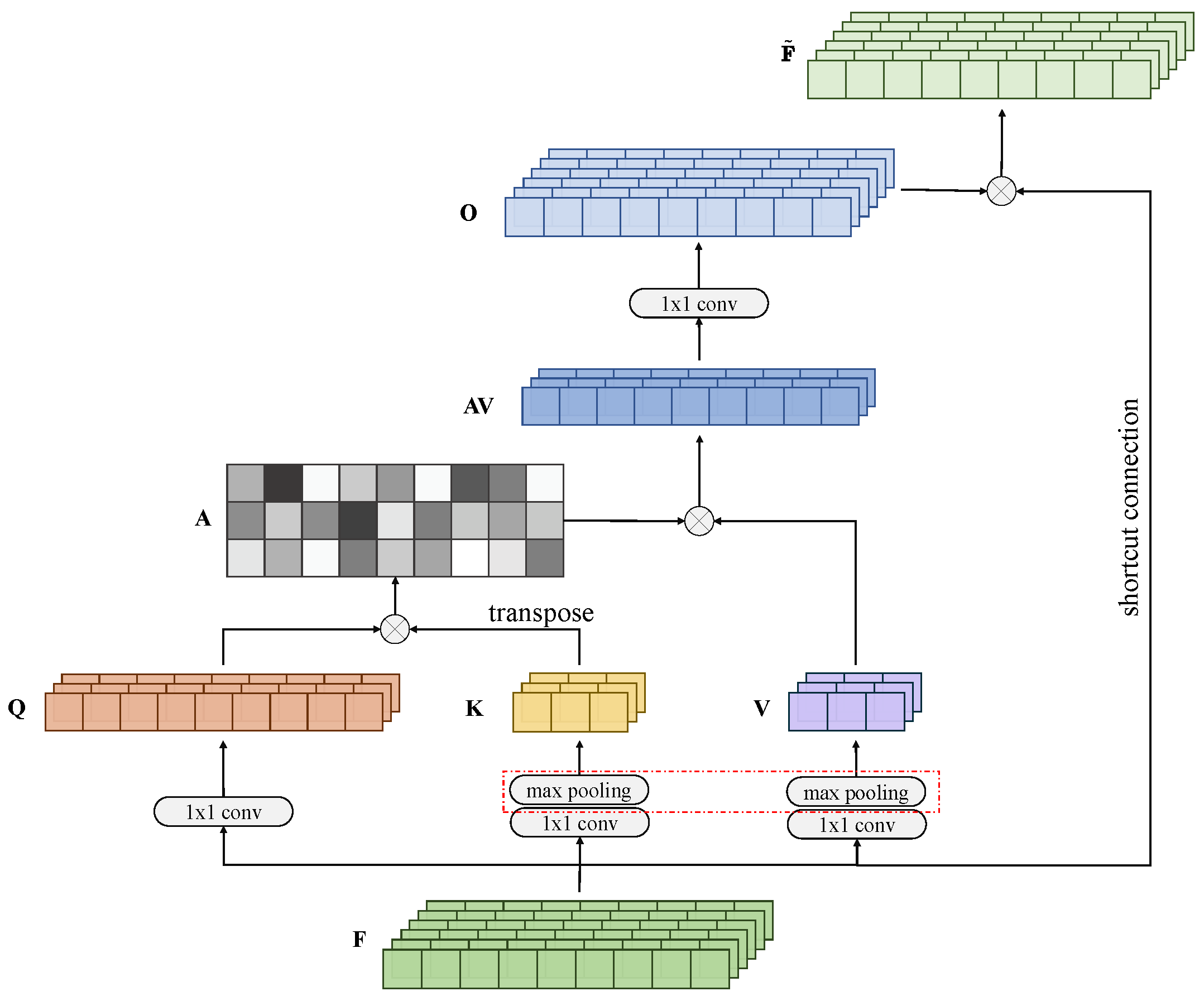
4.4. Attention Augmented Convolutional SEGAN
5. Experimental Setups
5.1. Dataset
5.2. Evaluation Criteria
- SSNR: Segmental SNR [45] (in the range of [0, ));
- STOI: Short-time objective intelligibility [46] (in the range of [0, 100]);
- CBAK: Mean opinion score (MOS) prediction of the intrusiveness of background noises [47] (in the range of [1, 5]);
- CSIG: MOS prediction of the signal distortion attending only to the speech signal [47] (in the range of [1, 5]);
- COVL: MOS prediction of the overall effect [47] (in the range of [1, 5]);
- PESQ: Perceptual evaluation of speech quality, using the wide-band version recommended in ITU-T P.862.2 [48] (in the range of [−0.5, 4.5]).
5.3. Network Architecture
5.3.1. SEGAN with Stand-Alone Self-Attention Layers
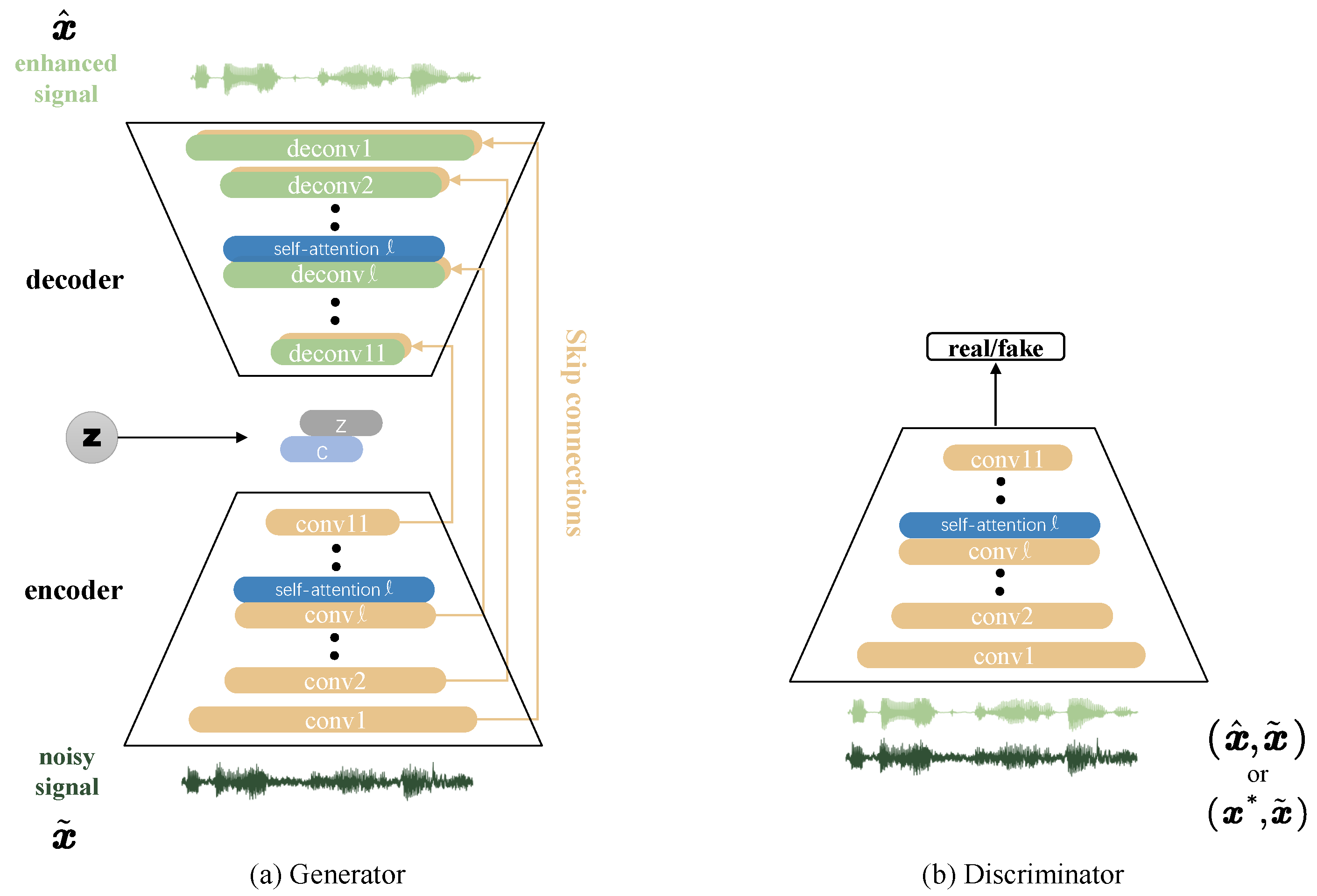
5.3.2. Stand-Alone Self-Attention Layer with Locality Modeling
5.3.3. Attention Augmented Convolutional SEGAN
5.4. Baseline Systems
5.5. Configurations
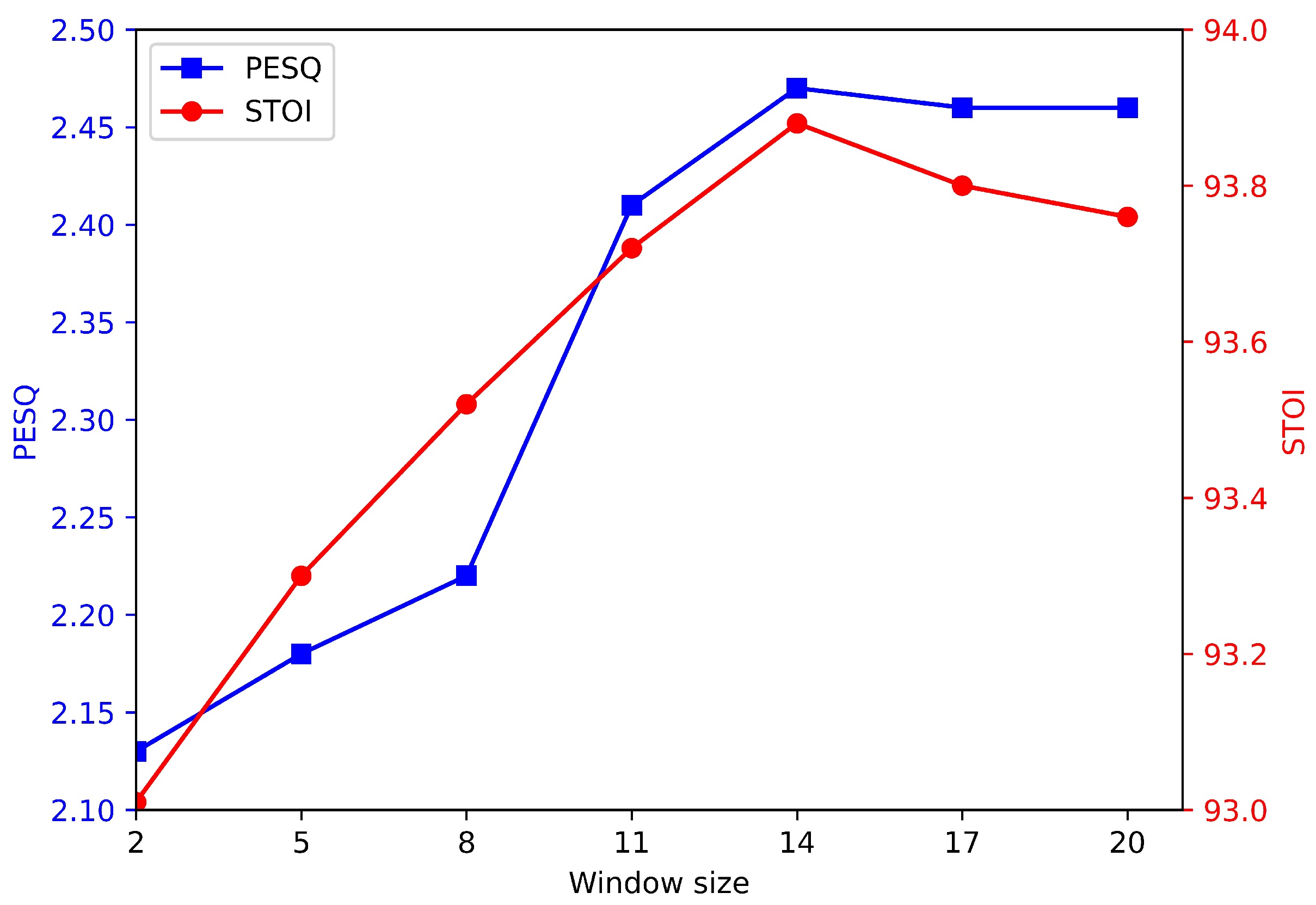
6. Results
7. Discussion
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DNN | deep neural network |
| CNN | convolutional neural network |
| RNN | recurrent neural network |
| GAN | generative adversarial network |
| SEGAN | speech enhancement generative adversarial network |
| G | generator |
| D | discriminator |
| SNR | signal-to-noise ratio |
| MOS | mean opinion score |
| SSNR | segmental SNR |
| STOI | short-time objective intelligibility |
| CBAK | MOS prediction of the intrusiveness of background noises |
| CSIG | MOS prediction of the signal distortion attending only to the speech signal |
| COVL | MOS prediction of the overall effect |
| PESQ | perceptual evaluation of speech quality |
References
- Loizou, P.C. Speech Enhancement: Theory and Practice; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Weninger, F.; Erdogan, H.; Watanabe, S.; Vincent, E.; Le Roux, J.; Hershey, J.R.; Schuller, B. Speech enhancement with LSTM recurrent neural networks and its application to noise-robust ASR. In International Conference on Latent Variable Analysis and Signal Separation; Springer: Berlin, Germany, 2015; pp. 91–99. [Google Scholar]
- Taherian, H.; Wang, Z.Q.; Chang, J.; Wang, D. Robust speaker recognition based on single-channel and multi-channel speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1293–1302. [Google Scholar] [CrossRef]
- Avila, A.R.; Alam, M.J.; O’Shaughnessy, D.D.; Falk, T.H. Investigating Speech Enhancement and Perceptual Quality for Speech Emotion Recognition. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018; pp. 3663–3667. [Google Scholar]
- Lai, Y.H.; Zheng, W.Z. Multi-objective learning based speech enhancement method to increase speech quality and intelligibility for hearing aid device users. Biomed. Signal Process. Control. 2019, 48, 35–45. [Google Scholar] [CrossRef]
- Wang, D.; Hansen, J.H. Speech enhancement for cochlear implant recipients. J. Acoust. Soc. Am. 2018, 143, 2244–2254. [Google Scholar] [CrossRef]
- Lim, J.; Oppenheim, A. All-pole modeling of degraded speech. IEEE Trans. Acoust. Speech Signal Process. 1978, 26, 197–210. [Google Scholar] [CrossRef]
- Nie, S.; Liang, S.; Xue, W.; Zhang, X.; Liu, W. Two-stage multi-target joint learning for monaural speech separation. In Proceedings of the INTERSPEECH, Dresden, Germany, 6–10 September 2015; pp. 1503–1507. [Google Scholar]
- Erdogan, H.; Hershey, J.R.; Watanabe, S.; Le Roux, J. Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 708–712. [Google Scholar]
- Nie, S.; Liang, S.; Liu, W.; Zhang, X.; Tao, J. Deep learning based speech separation via nmf-style reconstructions. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 2043–2055. [Google Scholar] [CrossRef]
- Xu, Y.; Du, J.; Dai, L.R.; Lee, C.H. A regression approach to speech enhancement based on deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 23, 7–19. [Google Scholar] [CrossRef]
- Park, S.R.; Lee, J. A fully convolutional neural network for speech enhancement. arXiv 2016, arXiv:1609.07132. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Pascual, S.; Bonafonte, A.; Serra, J. SEGAN: Speech enhancement generative adversarial network. arXiv 2017, arXiv:1703.09452. [Google Scholar]
- Pascual, S.; Serrà, J.; Bonafonte, A. Towards generalized speech enhancement with generative adversarial networks. arXiv 2019, arXiv:1904.03418. [Google Scholar]
- Soni, M.H.; Shah, N.; Patil, H.A. Time-Frequency Masking-Based Speech Enhancement Using Generative Adversarial Network. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5039–5043. [Google Scholar] [CrossRef]
- Michelsanti, D.; Tan, Z.H. Conditional generative adversarial networks for speech enhancement and noise-robust speaker verification. arXiv 2017, arXiv:1709.01703. [Google Scholar]
- Li, P.; Jiang, Z.; Yin, S.; Song, D.; Ouyang, P.; Liu, L.; Wei, S. PAGAN: A Phase-Adapted Generative Adversarial Networks for Speech Enhancement. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6234–6238. [Google Scholar] [CrossRef]
- Higuchi, T.; Kinoshita, K.; Delcroix, M.; Nakatani, T. Adversarial training for data-driven speech enhancement without parallel corpus. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 40–47. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Dong, L.; Xu, S.; Xu, B. Speech-transformer: A no-recurrence sequence-to-sequence model for speech recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 5884–5888. [Google Scholar]
- Pham, N.Q.; Nguyen, T.S.; Niehues, J.; Müller, M.; Stüker, S.; Waibel, A. Very deep self-attention networks for end-to-end speech recognition. arXiv 2019, arXiv:1904.13377. [Google Scholar]
- Sperber, M.; Niehues, J.; Neubig, G.; Stüker, S.; Waibel, A. Self-attentional acoustic models. arXiv 2018, arXiv:1803.09519. [Google Scholar]
- Katona, J. Examination and comparison of the EEG based Attention Test with CPT and TOVA. In Proceedings of the 2014 IEEE 15th International Symposium on Computational Intelligence and Informatics (CINTI), Budapest, Hungary, 19–21 November 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 117–120. [Google Scholar]
- Katona, J.; Ujbanyi, T.; Sziladi, G.; Kovari, A. Examine the effect of different web-based media on human brain waves. In Proceedings of the 2017 8th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Debrecen, Hungary, 11–14 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 000407–000412. [Google Scholar]
- Katona, J.; Kovari, A. The evaluation of BCI and PEBL-based attention tests. Acta Polytech. Hung. 2018, 15, 225–249. [Google Scholar]
- Cheng, J.; Liang, R.; Zhao, L. DNN-based speech enhancement with self-attention on feature dimension. Multimed. Tools Appl. 2020, 79, 32449–32470. [Google Scholar] [CrossRef]
- Koizumi, Y.; Yaiabe, K.; Delcroix, M.; Maxuxama, Y.; Takeuchi, D. Speech enhancement using self-adaptation and multi-head self-attention. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 181–185. [Google Scholar]
- Pandey, A.; Wang, D. Dense CNN with self-attention for time-domain speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1270–1279. [Google Scholar] [CrossRef] [PubMed]
- Phan, H.; Nguyen, H.L.; Chén, O.Y.; Koch, P.; Duong, N.Q.; McLoughlin, I.; Mertins, A. Self-Attention Generative Adversarial Network for Speech Enhancement. arXiv 2020, arXiv:2010.09132. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 7354–7363. [Google Scholar]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J. Stand-alone self-attention in vision models. arXiv 2019, arXiv:1906.05909. [Google Scholar]
- Cordonnier, J.B.; Loukas, A.; Jaggi, M. On the Relationship between Self-Attention and Convolutional Layers. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Yang, B.; Wang, L.; Wong, D.F.; Chao, L.S.; Tu, Z. Convolutional Self-Attention Networks. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, Minnesota, 2019; pp. 4040–4045. [Google Scholar]
- Guo, Q.; Qiu, X.; Xue, X.; Zhang, Z. Low-Rank and Locality Constrained Self-Attention for Sequence Modeling. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 2213–2222. [Google Scholar] [CrossRef]
- Xu, M.; Wong, D.F.; Yang, B.; Zhang, Y.; Chao, L.S. Leveraging local and global patterns for self-attention networks. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 3069–3075. [Google Scholar]
- Phan, H.; McLoughlin, I.V.; Pham, L.; Chén, O.Y.; Koch, P.; De Vos, M.; Mertins, A. Improving GANs for speech enhancement. IEEE Signal Process. Lett. 2020, 27, 1700–1704. [Google Scholar] [CrossRef]
- Zhang, Z.; Deng, C.; Shen, Y.; Williamson, D.S.; Sha, Y.; Zhang, Y.; Song, H.; Li, X. On Loss Functions and Recurrency Training for GAN-Based Speech Enhancement Systems. In Proceedings of the Interspeech 2020, Shanghai, China, 14–18 September 2020; pp. 3266–3270. [Google Scholar]
- Baby, D.; Verhulst, S. Sergan: Speech enhancement using relativistic generative adversarial networks with gradient penalty. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 106–110. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Valentini-Botinhao, C.; Wang, X.; Takaki, S.; Yamagishi, J. Investigating RNN-based speech enhancement methods for noise-robust Text-to-Speech. In Proceedings of the SSW, Sunnyvale, CA, USA, 13–15 September 2016; pp. 146–152. [Google Scholar]
- Veaux, C.; Yamagishi, J.; King, S. The voice bank corpus: Design, collection and data analysis of a large regional accent speech database. In Proceedings of the 2013 International Conference Oriental COCOSDA Held Jointly with 2013 Conference on Asian Spoken Language Research and Evaluation (O-COCOSDA/CASLRE), Gurgaon, India, 25–27 November 2013; pp. 1–4. [Google Scholar] [CrossRef]
- Thiemann, J.; Ito, N.; Vincent, E. The Diverse Environments Multi-channel Acoustic Noise Database (DEMAND): A database of multichannel environmental noise recordings. In Proceedings of the Meetings on Acoustics ICA2013, Acoustical Society of America, Montreal, QC, Canada, 2–7 June 2013; Volume 19, p. 035081. [Google Scholar]
- Quackenbush, S.R. Objective Measures of Speech Quality. Ph.D. Thesis, Georgia Institute of Technology, Atlanta, GA, USA, 1995. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An algorithm for intelligibility prediction of time—Frequency weighted noisy speech. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- Hu, Y.; Loizou, P.C. Evaluation of objective quality measures for speech enhancement. IEEE Trans. Audio Speech Lang. Process. 2007, 16, 229–238. [Google Scholar] [CrossRef]
- International Telecommunication Union. P. 862.2: Wideband Extension to Recommendation P. 862 for the Assessment of Wideband Telephone Networks and Speech Codecs. 2005. Available online: https://www.itu.int/rec/T-REC-P.862.2 (accessed on 1 May 2021).
- Wang, D.; Lim, J. The unimportance of phase in speech enhancement. IEEE Trans. Acoust. Speech Signal Process. 1982, 30, 679–681. [Google Scholar] [CrossRef]
- Paliwal, K.; Wójcicki, K.; Shannon, B. The importance of phase in speech enhancement. Speech Commun. 2011, 53, 465–494. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the ICML, Atlanta, GA, USA, 16–21 June 2013; Volume 30, p. 3. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers); Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 2227–2237. [Google Scholar]
- Raganato, A.; Tiedemann, J. An analysis of encoder representations in transformer-based machine translation. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP; The Association for Computational Linguistics: New Orleans, LA, USA, 2018. [Google Scholar]
- Yu, A.W.; Dohan, D.; Luong, M.T.; Zhao, R.; Chen, K.; Norouzi, M.; Le, Q.V. QANet: Combining local convolution with global self-attention for reading comprehension. arXiv 2018, arXiv:1804.09541. [Google Scholar]
- Yang, B.; Tu, Z.; Wong, D.F.; Meng, F.; Chao, L.S.; Zhang, T. Modeling localness for self-attention networks. arXiv 2018, arXiv:1810.10182. [Google Scholar]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3286–3295. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Shen, T.; Zhou, T.; Long, G.; Jiang, J.; Zhang, C. Bi-directional block self-attention for fast and memory-efficient sequence modeling. arXiv 2018, arXiv:1804.00857. [Google Scholar]
- Yu, A.W.; Dohan, D.; Le, Q.; Luong, T.; Zhao, R.; Chen, K. Fast and Accurate Reading Comprehension by Combining Self-Attention and Convolution. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Vaswani, A.; Ramachandran, P.; Srinivas, A.; Parmar, N.; Hechtman, B.; Shlens, J. Scaling local self-attention for parameter efficient visual backbones. In Proceedings of the CVPR, Virtual, 19–25 June 2021; Available online: https://openaccess.thecvf.com/content/CVPR2021/papers/Vaswani_Scaling_Local_Self-Attention_for_Parameter_Efficient_Visual_Backbones_CVPR_2021_paper.pdf (accessed on 1 May 2021).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture | Params (M) | Metric | |||||
|---|---|---|---|---|---|---|---|
| PESQ | CSIG | CBAK | COVL | SSNR | STOI | ||
| Noisy | - | 1.97 | 3.35 | 2.43 | 2.63 | 1.69 | 92.10 |
| SEGAN [14] | 294 | 2.16 | 3.48 | 2.94 | 2.79 | 7.66 | 93.12 |
| ISEGAN [37] | 294 | 2.24 | 3.23 | 2.93 | 2.68 | 8.19 | 93.29 |
| DSEGAN [37] | 513 | 2.35 | 3.56 | 3.10 | 2.94 | 8.70 | 93.25 |
| SASEGAN-avg [30] | 295 | 2.33 | 3.52 | 3.05 | 2.90 | 8.08 | 93.33 |
| SASEGAN-all [30] | 310 | 2.35 | 3.55 | 3.10 | 2.91 | 8.30 | 93.49 |
| standalone-4 | 293 | 2.49 * | 3.54 | 3.62 * | 3.11 * | 7.70 | 93.72 |
| standalone-6 | 292 | 2.41 | 3.54 | 3.07 | 2.96 | 8.10 | 93.63 |
| standalone-11 | 103 | 2.43 | 3.74 * | 3.01 | 3.07 | 7.11 | 93.55 |
| standalone-6,10 | 274 | 2.39 | 3.59 | 3.12 | 2.98 | 8.71 * | 93.66 |
| standalone-10,11 | 51 | 2.37 | 3.57 | 3.00 | 2.95 | 7.71 | 93.54 |
| standalone-4,6,10 | 275 | 2.45 | 3.61 | 3.10 | 3.01 | 8.30 | 93.73 |
| standalone-9,10,11 | 28 | 2.43 | 3.50 | 2.97 | 2.88 | 8.51 | 93.90 * |
| standalone-6–11 | 3 | 2.01 | 3.36 | 2.62 | 2.64 | 6.98 | 93.32 |
| Architecture | Params (M) | Metric | |||||
|---|---|---|---|---|---|---|---|
| PESQ | CSIG | CBAK | COVL | SSNR | STOI | ||
| standalone-{4} | 293 | 2.50 | 3.55 | 3.64 | 3.13 | 8.10 | 93.83 |
| standalone-{6} | 292 | 2.41 | 3.54 | 3.08 | 2.96 | 7.90 | 93.68 |
| standalone-{6},10 | 274 | 2.40 | 3.59 | 3.12 | 2.99 | 8.70 | 93.76 |
| standalone-{4},{6},10 | 275 | 2.45 | 3.58 | 3.11 | 3.03 | 8.30 | 93.88 |
| Architecture | Params (M) | Metric | |||||
|---|---|---|---|---|---|---|---|
| PESQ | CSIG | CBAK | COVL | SSNR | STOI | ||
| augmentation-4,6 | 293 | 2.43 | 3.64 | 3.11 | 3.02 | 8.20 | 93.99 |
| augmentation-6,10 | 299 | 2.47 | 3.58 | 3.15 | 3.01 | 8.87 | 93.61 |
| augmentation-4,10 | 298 | 2.45 | 3.58 | 3.10 | 3.00 | 7.86 | 93.61 |
| augmentation-4,6,10 | 299 | 2.39 | 3.50 | 3.08 | 2.92 | 8.41 | 93.68 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Lu, Z.; Watzel, T.; Kürzinger, L.; Rigoll, G. Light-Weight Self-Attention Augmented Generative Adversarial Networks for Speech Enhancement. Electronics 2021, 10, 1586. https://doi.org/10.3390/electronics10131586
Li L, Lu Z, Watzel T, Kürzinger L, Rigoll G. Light-Weight Self-Attention Augmented Generative Adversarial Networks for Speech Enhancement. Electronics. 2021; 10(13):1586. https://doi.org/10.3390/electronics10131586
Chicago/Turabian StyleLi, Lujun, Zhenxing Lu, Tobias Watzel, Ludwig Kürzinger, and Gerhard Rigoll. 2021. "Light-Weight Self-Attention Augmented Generative Adversarial Networks for Speech Enhancement" Electronics 10, no. 13: 1586. https://doi.org/10.3390/electronics10131586
APA StyleLi, L., Lu, Z., Watzel, T., Kürzinger, L., & Rigoll, G. (2021). Light-Weight Self-Attention Augmented Generative Adversarial Networks for Speech Enhancement. Electronics, 10(13), 1586. https://doi.org/10.3390/electronics10131586