
Context-Aware Neural Machine Translation for Korean Honorific Expressions

Abstract
:1. Introduction
- We show that the NMT model with a contextual encoder improves the quality of the honorific translation regardless of the model structure. In our experiments, even the simplest model that concatenates all the contextual sentences with the source sentence can improve honorific accuracy. We also show that the NMT model with contextual encoder also outperforms the sentence-level model even when the model is explicitly controlled to translate to a specific honorific style.
- In addition to the contextual encoder, we demonstrate that the CAPE can improve honorifics of both the sentence-level NMT and contextual NMT by exploiting contextual sentences of the target language. Our qualitative analysis also reveals the ability of CAPE to improve the inconsistent use of honorifics of the NMT model with a contextual encoder.
- We also develop an automatic data annotation heuristics for labeling Korean sentences as honorific and non-honorific style. Our heuristics utilize Korean morphology to precisely determine the honorific style of a given sentence. We labeled our test set by using the heuristics and used it to validate the improvements of our proposed method.
2. Related Works
2.1. Neural Machine Translation
2.2. Controlling the Styles in NMT
2.3. Context-Aware NMT
3. Addressing Korean Honorifics in Context
3.1. Overview of Korean Honorifics System
- 철수가 방에 들어가다. (cheol-su-ga bang-e deul-eo-ga-da; Cheolsoo goes to the room.)
- 어머니께서 방에 들어가신다. (eo-meo-ni-kke-seo bang-e deul-eo-ga-sin-da; My mother goes to the room.)
- (a)
- 철수는 잘 모르는 것이 있으면 항상 아버지께 여쭌다. (cheol-su-neun jal mo-leu-neun geos-i iss-eu-myeon hang-sang a-beo-ji-kke yeo-jjun-da; Cheolsoo always ask his father about something that he doesn’t know well.)
- (b)
- 아버지는 휴대폰에 대해 잘 모르는 게 있으면 항상 철수에게 묻는다. (a-beo-ji-neun hyu-dae-pon-e dae-hae jal mo-leu-neun ge iss-eu-myeon hang-sang cheol-su-e-ge mud-neun-da; Cheolsoo’s father always ask him about mobile phones that he doesn’t know well.)
3.2. The Role of Context on Choosing Honorifics
4. Context-Aware NMT Frameworks
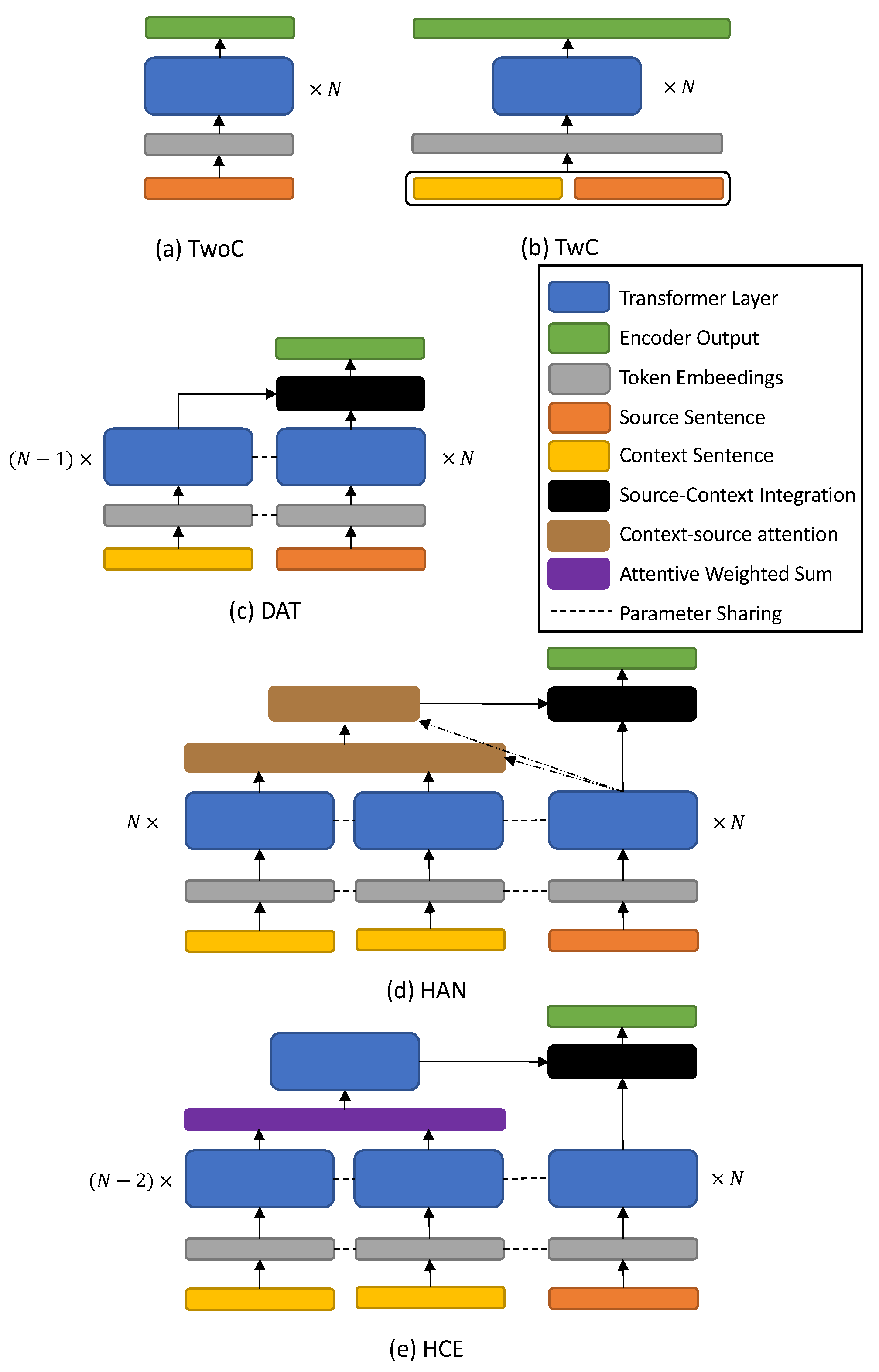
4.1. NMT Model with Contextual Encoders
- Transformer without contexts (TwoC): As a baseline, we have experimented with the TwoC model which has the same structure as [4]. TwoC does not use any contextual sentences and only incorporates the input and the target sentences.
- Transformer with contexts (TwC): This is the simplest approach to incorporate contextual sentences with the Transformer [27]. TwC concatenates all contextual sentences and an input sentence and considers the concatenated sentence as a single-input sentence. Then, the output of the TwoC encoder is the output of a stacked Transformer encoder with concatenated source and contextual sentences.
- Discourse Aware Transformer (DAT) [6]: DAT handles a single contextual sentence with an extra context encoder that is also a stacked Transformer encoder. To handle multiple contextual sentences, we slightly modified DAT such that the contextual encoder takes a concatenation of contextual sentences. The context encoder has the same structure as the source encoder and even shares its weights. Encoded contextual sentences are integrated with an encoded source sentence by using a source-to-context attention mechanism and a gated summation.
- Hierarchical Attention Networks (HAN) [28]: HAN has a hierarchical structure with two-stage at every hidden layer in their contextual encoder. At the first level of the hierarchy, HAN first encodes each of the contextual sentences to sentence-level tensors using the stacked Transformer encoder as in [4]. Then each encoded sentence is summarized by word-level context-source attention, resulting in sentence-level representations. These sentence-level vectors are concatenated and again encoded with sentence-level context-source attention. Finally, encoded contextual sentences are integrated using a gated summation.
- Hierarchical Context Encoder (HCE) [34]: HCE also exploits a similar hierarchical structure as HAN but uses different method to summarize word-level and sentence-level information. In the lower part of the hierarchy, the encoded sentence-level tensor is compressed into a sentence-level vector by a self-attentive weighted sum module, which is similar to that of [35]. The collection of sentence-level vectors is fed into another Transformer encoder layer that is the upper part of the hierarchy to encode the entirety of contextual information into a single tensor. Finally, the contextual information tensor is combined with the source encoder in a similar fashion as DAT.
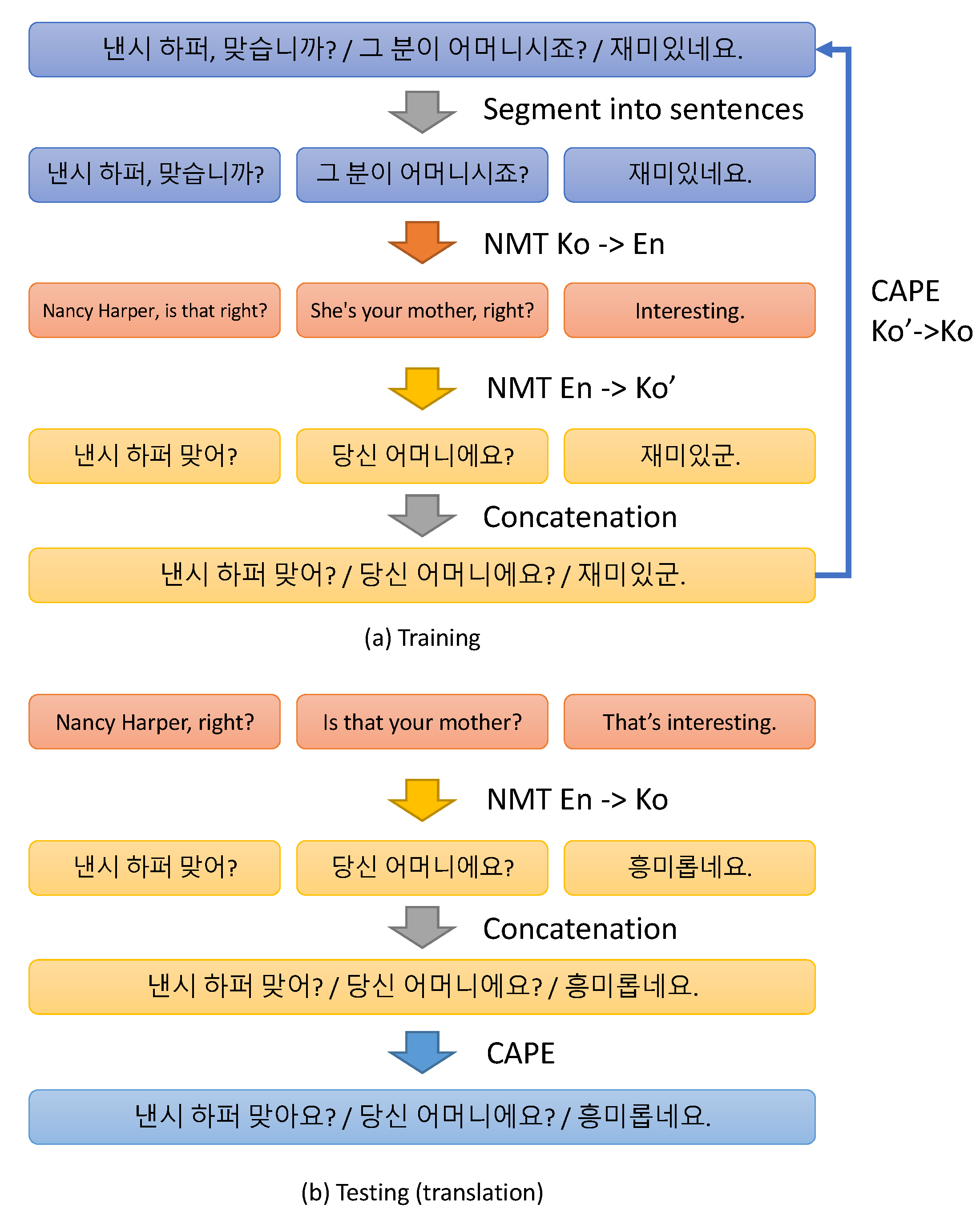
4.2. Context-Aware Post Editing (CAPE)
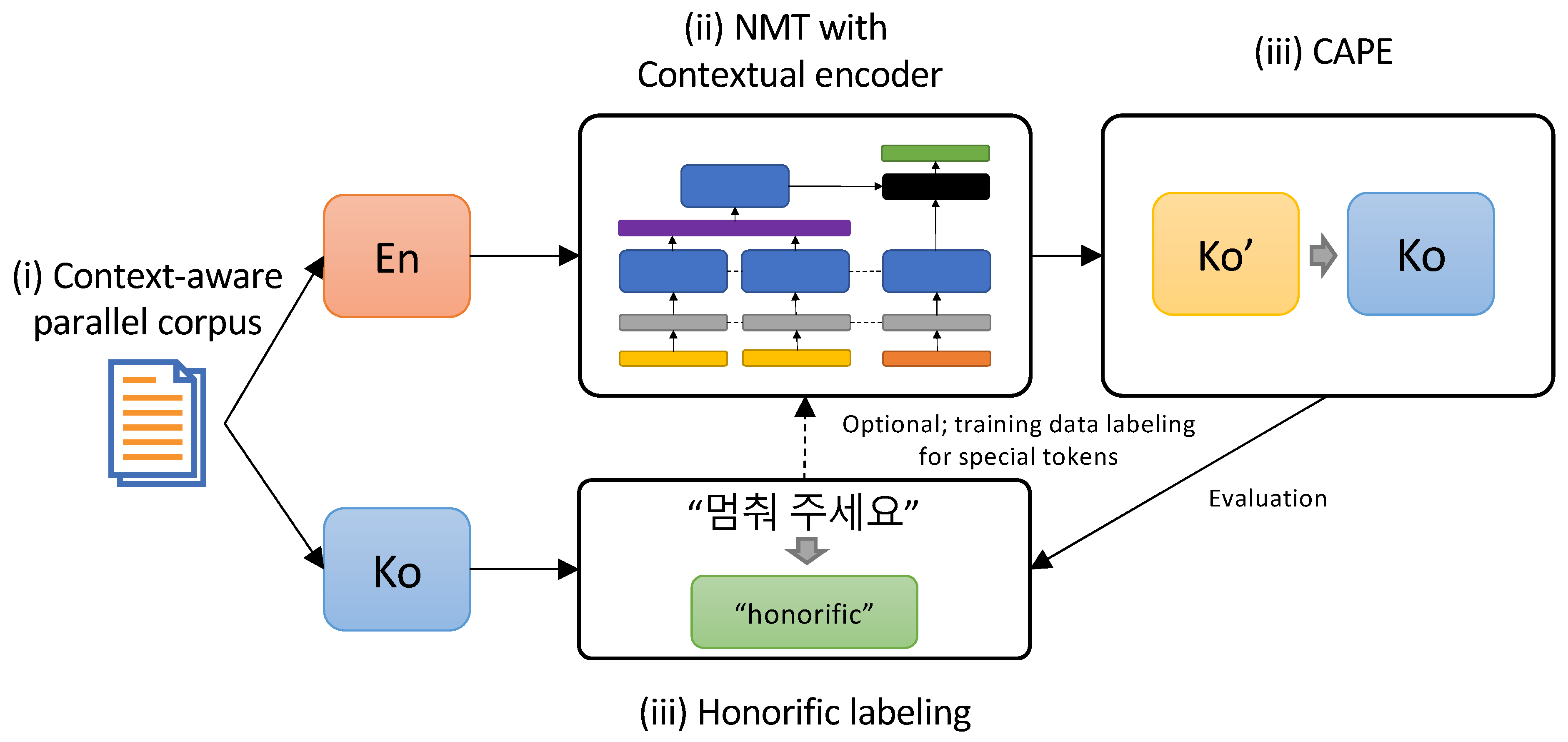
5. Our Proposed Method—Context-Aware NMT for Korean Honorifics
5.1. Using NMT with Contextual Encoder and CAPE for Honorific-Aware Translation
5.2. Scope of Honorific Expressions
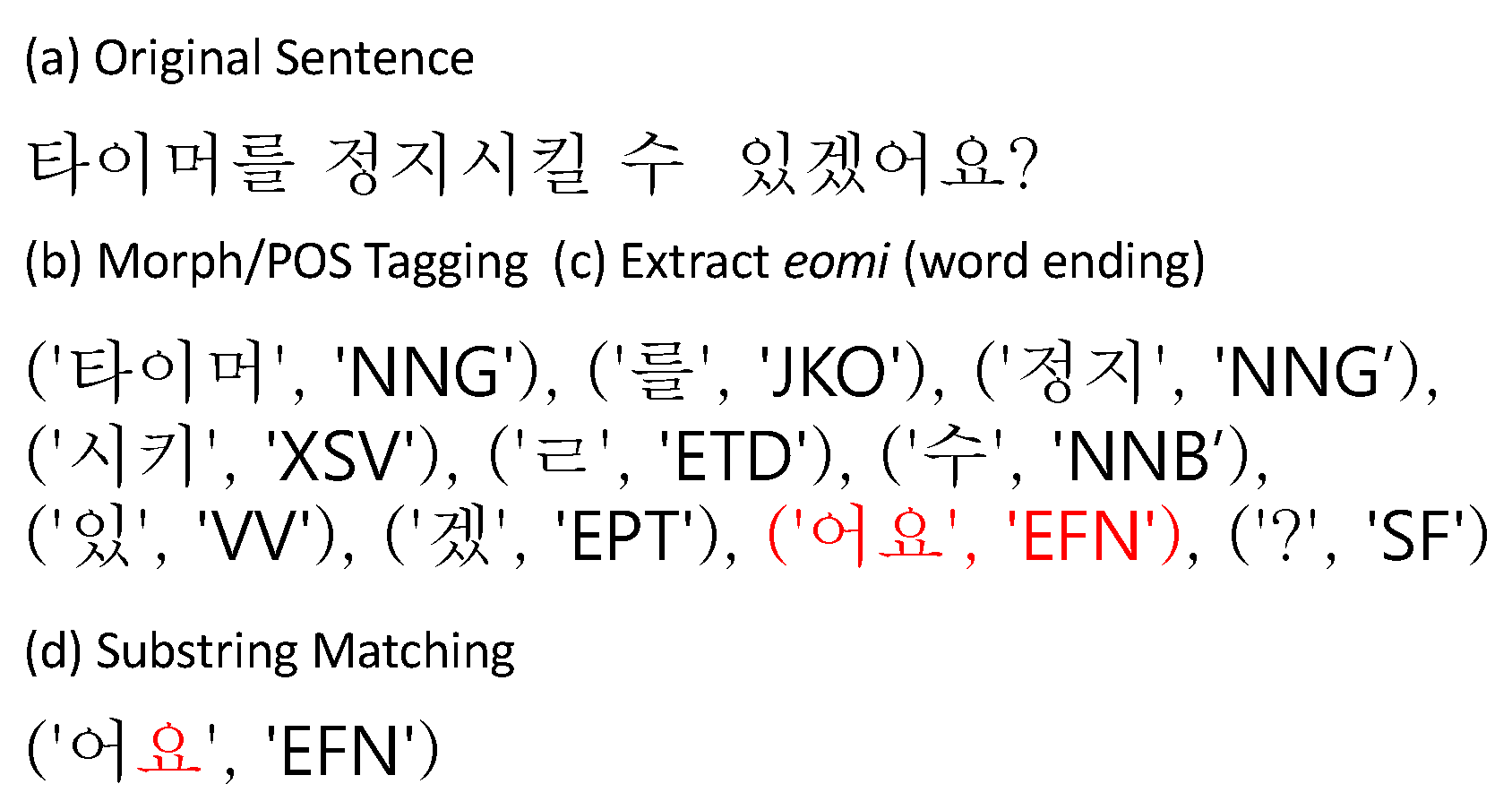
5.3. Automatic Honorific Labeling
6. Experiments
6.1. Dataset and Preprocessing
6.2. Model Training Details
6.3. Metrics
6.4. Results
6.4.1. Effect of Contextual Encoders
6.4.2. Effect of the Number of Contextual Sentences
6.4.3. Effect of CAPE
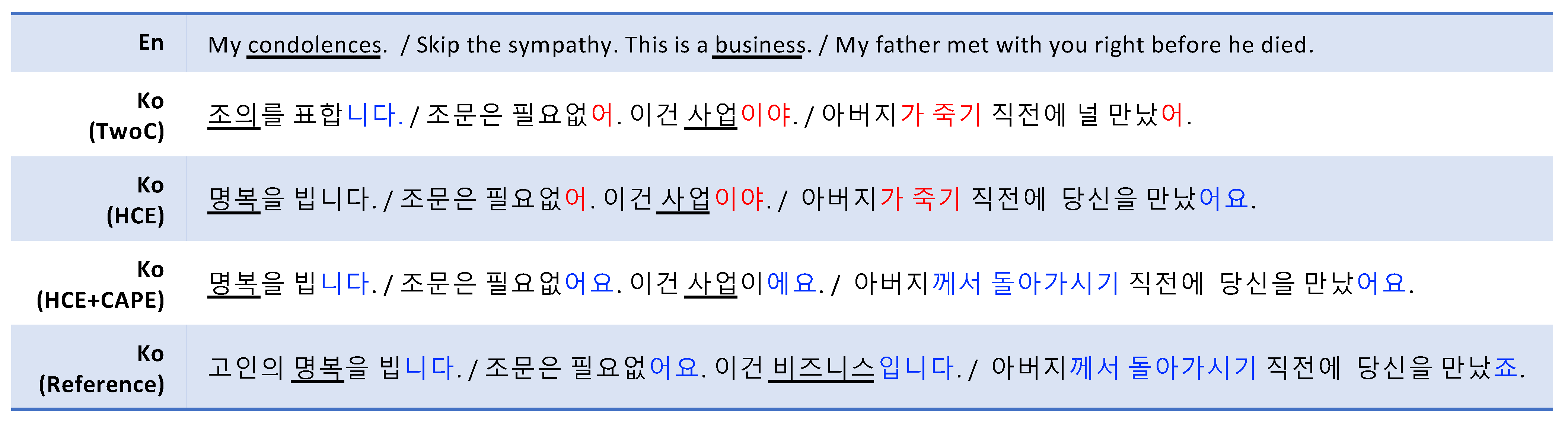
6.5. Translation Examples and Analysis
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Esplà, M.; Forcada, M.; Ramírez-Sánchez, G.; Hoang, L. ParaCrawl: Web-scale parallel corpora for the languages of the EU. In Proceedings of the MT Summit XVII, Dublin, Ireland, 19–23 August 2019; pp. 118–119. [Google Scholar]
- Cho, K.; Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS), Montréal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. [Online]. September 2016. Available online: https://arxiv.org/abs/1609.08144 (accessed on 30 June 2021).
- Voita, E.; Serdyukov, P.; Sennrih, R.; Titov, I. Context-Aware Neural Machine Translation Learns Anaphora Resolution. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), Melbourne, Australia, 15–20 July 2018; pp. 1264–1274. [Google Scholar]
- Viswanathan, A.; Wang, V.; Kononova, A. Controlling Formality and Style of Machine Translation Output Using AutoML. In Annual International Symposium on Information Management and Big Data; Springer: Cham, Switzerland, 2019; pp. 306–313. [Google Scholar]
- Brown, L. Questions of appropriateness and authenticity in the representation of Korean honorifics in textbooks for second language learners. Lang. Cult. Curric. 2010, 23, 35–50. [Google Scholar] [CrossRef]
- Xiao, Z.; McEnery, A. Two approaches to genre analysis: Three genres in modern american english. J. Engl. Linguist. 2005, 33, 62–82. [Google Scholar] [CrossRef] [Green Version]
- Voita, E.; Sennrich, R.; Ivan, T. Context-Aware Monolingual Repair for Neural Machine Translation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 877–886. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Improving Neural Machine Translation Models with Monolingual Data. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL), Berlin, Germany, 7–12 August 2016; pp. 86–96. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Song, K.; Tan, X.; Qin, T.; Lu, J.; Liu, T.-Y. MASS: Masked Sequence to Sequence Pre-training for Language Generation. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 10–15 June 2019; pp. 5926–5936.
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Xu, G.; Ko, Y.; Seo, J. Low-resource Machine Translation by utilizing Multilingual, Out-domain Resources. J. KIISE 2019, 40, 649–651. [Google Scholar]
- Jeong, Y.; Park, C.; Lee, C.; Kim, J.s. English-Korean Neural Machine Translation using MASS. In Proceedings of the 31st Annual Conference on Human & Cognitive Language Technology (HCLT), Busan, Korea, 11–12 October 2019; pp. 236–238. [Google Scholar]
- Nguyen, Q.-P.; Anh, D.; Shin, J.C.; Tran, P.; Ock, C.Y. Korean-Vietnamese Neural Machine Translation System With Korean Morphological Analysis and Word Sense Disambiguation. IEEE Access 2019, 7, 32602–32616. [Google Scholar] [CrossRef]
- Park, C.; Yang, Y.; Park, K.; Lim, H. Decoding Strategies for Improving Low-Resource Machine Translation. Electronics 2020, 9, 1562. [Google Scholar] [CrossRef]
- Sennrich, R.; Haddow, B.; Birch, A. Controlling Politeness in Neural Machine Translation via Side Constraints. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), San Diego, CA, USA, 12–17 June 2016; pp. 35–40. [Google Scholar]
- Chu, C.; Dabre, R.; Kurohashi, S. An Empirical Comparison of Domain Adaptation Methods for Neural Machine Translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 385–391. [Google Scholar]
- Wang, L.; Tu, M.; Zhai, M.; Wang, H.; Liu, S.; Kim, S.H. Neural Machine Translation Strategies for Generating Honorific-style Korean. In Proceedings of the 2019 International Conference on Asian Language Processing (IALP), Shanghai, China, 15–17 November 2019; pp. 450–455. [Google Scholar]
- Michel, P.; Neubig, G. Extreme Adaptation for Personalized Neural Machine Translation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), Melbourne, Australia, 15–20 July 2018; pp. 312–318. [Google Scholar]
- Niu, X.; Rao, S.; Carpuat, M. Multi-Task Neural Models for Translating Between Styles Within and Across Languages. In Proceedings of the 27th International Conference on Computational Linguistics (COLING), Santa Fe, NM, USA, 20–26 August 2018; pp. 1008–1021. [Google Scholar]
- Niu, X.; Carpuat, M. Controlling Neural Machine Translation Formality with Synthetic Supervision. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Feely, W.; Hasler, E.; Gispert, A. Controlling Japanese Honorifics in English-to-Japanese Neural Machine Translation. In Proceedings of the 6th Workshop on Asian Translation (WAT), Hong Kong, China, 4 November 2019; pp. 45–53. [Google Scholar]
- Tiedemann, J.; Scherrer, Y. Neural Machine Translation with Extended Context. In Proceedings of the Third Workshop on Discourse in Machine Translation (DiscoMT), Copenhagen, Denmark, 8 September 2017; pp. 82–92. [Google Scholar]
- Miculicich, L.; Ram, D.; Pappas, N.; Henderson, J. Document-Level Neural Machine Translation with Hierarchical Attention Networks. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), Brussels, Belgium, 31 October–4 November 2018; pp. 2947–2954. [Google Scholar]
- Maruf, S.; Martins, A.; Haffari, G. Selective Attention for Context-aware Neural Machine Translation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Minneapolis, MN, USA, 2–7 June 2019; pp. 3092–3102. [Google Scholar]
- Xiong, H.; He, Z.; Wu, H.; Wang, H. Modeling Coherence for Discourse Neural Machine Translation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HW, USA, 27 January–1 February 2019. [Google Scholar]
- Voita, E.; Sennrich, R.; Titov, I. When a Good Translation is Wrong in Context: Context-Aware Machine Translation Improves on Deixis, Ellipsis, and Lexical Cohesion. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), Florence, Italy, 28 July–2 August 2019; pp. 1198–1212. [Google Scholar]
- Müller, M.; Rios, A.; Voita, E.; Sennrich, R. A Large-Scale Test Set for the Evaluation of Context-Aware Pronoun Translation in Neural Machine Translation. In Proceedings of the Third Conference on Machine Translation (WMT), Brussels, Belgium, 31 October–1 November 2018; pp. 61–72. [Google Scholar]
- Byon, A.S. Teaching Korean Honorifics. Korean Lang. Am. 2000, 5, 275–289. [Google Scholar]
- Yun, H.; Hwang, Y.; Jung, K. Improving Context-Aware Neural Machine Translation Using Self-Attentive Sentence Embedding. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Lin, Z.; Feng, M.; Yu, M.; Xiang, B.; Zhou, B.; Bengio, Y. A structured self-attentive sentence embedding. In Proceedings of the 5th International Conference on Learning Representations (ICLR), Toulon, France, 24-26 April 2017. [Google Scholar]
- Vu, T.; Haffari, G. Automatic Post-Editing of Machine Translation: A Neural Programmer-Interpreter Approach. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3048–3053. [Google Scholar]
- Lee, D.; Yeon, J.; Hwang, I.; Lee, S. KKMA: A Tool for Utilizing Sejong Corpus based on Relational Database. J. Kiise Comput. Pract. Lett. 2010, 16, 1046–1050. [Google Scholar]
- Lison, P.; Tiedemann, J.; Kouylekov, M. OpenSubtitles2018: Statistical Rescoring of Sentence Alignments in Large, Noisy Parallel Corpora. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Vaswani, A.; Bengio, S.; Brevdo, E.; Chollet, F.; Gomez, A.; Gouws, S.; Jones, L.; Kaiser, Ł.; Kalchbrenner, N.; Parmar, N.; et al. Tensor2Tensor for Neural Machine Translation. March 2018. Available online: http://arxiv.org/abs/1803.07416 (accessed on 30 June 2021).
- Papineni, P.; Roukos, S.; Ward, T.; Zhu, W. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Koehn, P.; Hoang, H.; Birch, A.; Callison-Burch, C.; Federico, M.; Bertoldi, N.; Cowan, B.; Shen, W.; Moran, C.; Zens, R.; et al. Moses: Open Source Toolkit for Statistical Machine Translation. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics (ACL) Demo and Poster Sessions, Prague, Czech Republic, 24–29 June 2007; pp. 177–180. [Google Scholar]
- Jung, Y.; Park, C.; Lee, C.; Kim, J. English-Korean Neural Machine Translation using MASS with Relative Position Representation. J. Kiise 2020, 47, 1038–1043. [Google Scholar] [CrossRef]
- Kang, X.; Zhao, Y.; Zhang, J.; Zong, C. Dynamic Context Selection for Document-level Neural Machine Translation via Reinforcement Learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 2242–2254. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Style and Name | Politeness | Formality | Example |
|---|---|---|---|
| 합쇼체 | High | High | 날씨가 춥습니다. |
| (Hapsio-che; Deferential) | nal-ssi-ga chub-seub-ni-da | ||
| 해요체 | High | Low | 날씨가 추워요. |
| (Haeyo-che; Polite) | nal-ssi-ga chu-wo-yo | ||
| 하오체 | Neutral | High | 날씨가 춥소. |
| (Hao-che; Semiformal) | nal-ssi-ga chub-so | ||
| 하게체 | Neutral | Low | 날씨가 춥네. |
| (Hagae-che; Familiar) | nal-ssi-ga chub-ne | ||
| 반말체 | Low | High | 날씨가 추워. |
| (Banmal-che; Intimate) | nal-ssi-ga chu-wo | ||
| 해라체 | Low | Low | 날씨가 춥다. |
| (Haela-che; Plain) | nal-ssi-ga chub-da |
| Models | BLEU | Accuracy | Accuracy | |
|---|---|---|---|---|
| En-Ko | Ko-En | All Test Set | Polite Targets | |
| TwoC | 9.16/12.45 | 23.81 | 64.34 | 39.27 |
| TwC | 9.6/13.2 | 24.35 | 66.85 | 44.08 |
| DAT [6] | 9.36/12.98 | 23.96 | 65.12 | 38.7 |
| HAN [28] | 9.50/13.08 | 24.54 | 66.3 | 42.26 |
| HCE [34] | 10.23/14.75 | 26.63 | 67.94 | 42.42 |
| Models | BLEU | Accuracy | Accuracy |
|---|---|---|---|
| All Test Set | Polite Targets | ||
| TwoC + Special Token | 9.36/12.68 | 99.46 | 98.91 |
| HCE + Special Token | 10.83/14.79 | 99.49 | 99.04 |
| # Contextual Sents. | BLEU | Accuracy | Accuracy |
|---|---|---|---|
| All Test Set | Polite Targets | ||
| 1 | 9.23/12.88 | 65.42 | 40.31 |
| 2 | 10.23/14.75 | 67.94 | 42.42 |
| 3 | 9.83/13.49 | 66.56 | 41.93 |
| 4 | 9.31/12.92 | 64.8 | 39.27 |
| 5 | 8.98/12.09 | 63.3 | 36.48 |
| Models | # Contextual Sents. | BLEU | Accuracy | Accuracy |
|---|---|---|---|---|
| All Test Set | Polite Targets | |||
| TwC | 2 | 9.6/13.2 | 66.85 | 44.08 |
| 5 | 8.23/11.41 | 61.21 | 38.05 | |
| DAT | 2 | 9.36/12.98 | 65.12 | 38.7 |
| 5 | 8.02/11.2 | 60.94 | 33.2 | |
| HAN | 2 | 9.5/13.08 | 66.3 | 42.26 |
| 5 | 8.55/11.74 | 63.1 | 36.6 | |
| HCE | 2 | 10.23/14.75 | 67.94 | 42.42 |
| 5 | 8.98/12.09 | 63.3 | 36.48 |
| Models | BLEU | Accuracy | Accuracy |
|---|---|---|---|
| All Test Set | Polite Targets | ||
| TwoC | 9.16/12.45 | 64.34 | 39.27 |
| +CAPE | 10.03/14.38 | 67.5 | 43.81 |
| HCE | 10.23/14.65 | 67.94 | 42.42 |
| +CAPE | 10.55/15.03 | 69.16 | 46.51 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hwang, Y.; Kim, Y.; Jung, K. Context-Aware Neural Machine Translation for Korean Honorific Expressions. Electronics 2021, 10, 1589. https://doi.org/10.3390/electronics10131589
Hwang Y, Kim Y, Jung K. Context-Aware Neural Machine Translation for Korean Honorific Expressions. Electronics. 2021; 10(13):1589. https://doi.org/10.3390/electronics10131589
Chicago/Turabian StyleHwang, Yongkeun, Yanghoon Kim, and Kyomin Jung. 2021. "Context-Aware Neural Machine Translation for Korean Honorific Expressions" Electronics 10, no. 13: 1589. https://doi.org/10.3390/electronics10131589
APA StyleHwang, Y., Kim, Y., & Jung, K. (2021). Context-Aware Neural Machine Translation for Korean Honorific Expressions. Electronics, 10(13), 1589. https://doi.org/10.3390/electronics10131589