
Physical Layer Latency Management Mechanisms: A Study for Millimeter-Wave Wi-Fi




Abstract
:1. Introduction
1.1. The Millimeter-Wave Spectrum for Time-Critical Applications
1.2. Related Work on Latency Reduction
1.3. Physical Layer Latency Probing
- PHY latency analysis: The dependency of time delays on PHY protocol data unit (PPDU) payload length, PPDU aggregation, the selected MCS, the employed demapping algorithm, and the number of LDPC decoding iterations is established
- Latency management mechanisms: Data transmission over an additive white Gaussian noise (AWGN) channel is carried out to study the trade-offs between the incurred latency and the resulting BER. The lowest achievable latency is determined in relation to PHY tuning parameters and using 10 as the BER constraint. Moreover, Pareto optimality in achieving minimal BER is addressed in light of different latency thresholds.
- Simulation framework: An open-source IEEE 802.11ad PHY latency and BER simulation framework has been designed during the course of the study. It closely complies with the WiGig standard, offers flexibility for future studies, and is shared in open access.
2. Latency Definition and the Ideal Case Study
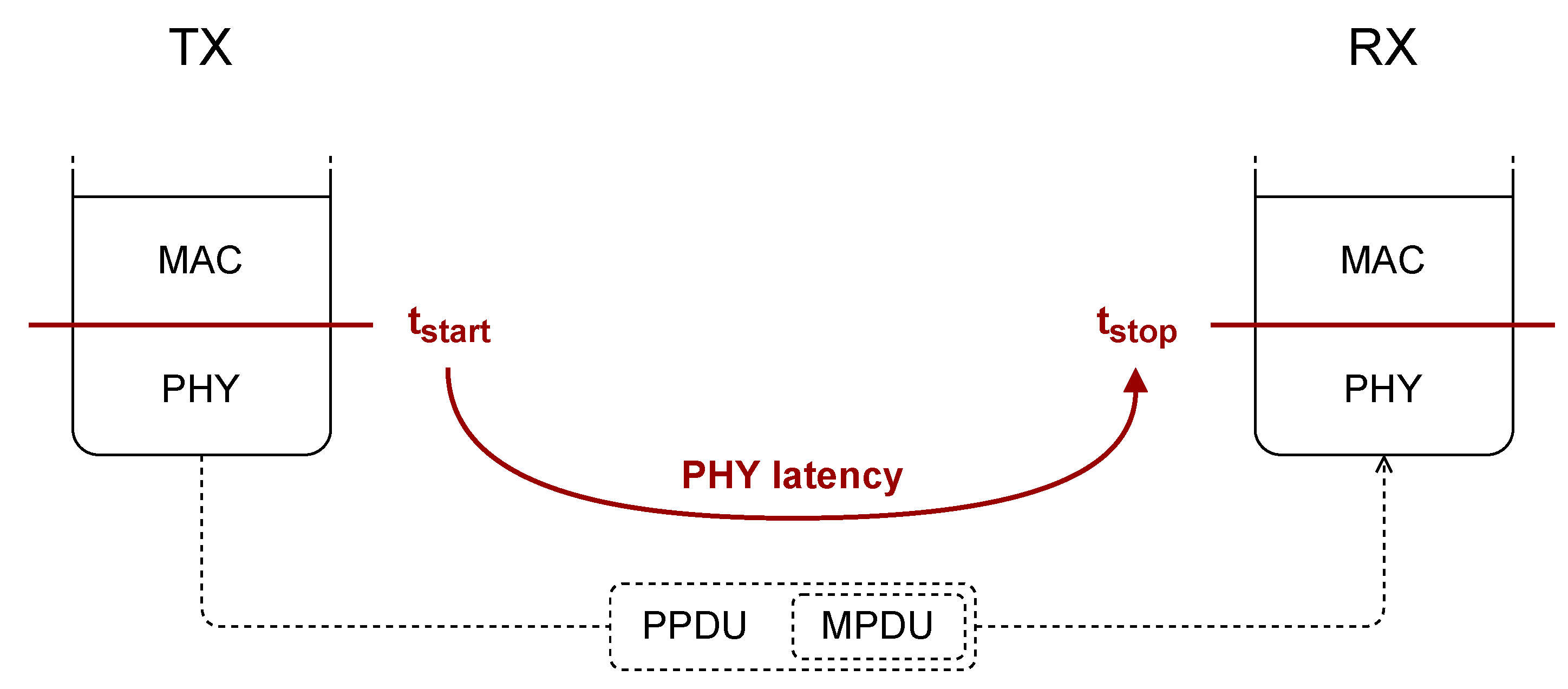
2.1. Physical Layer Latency
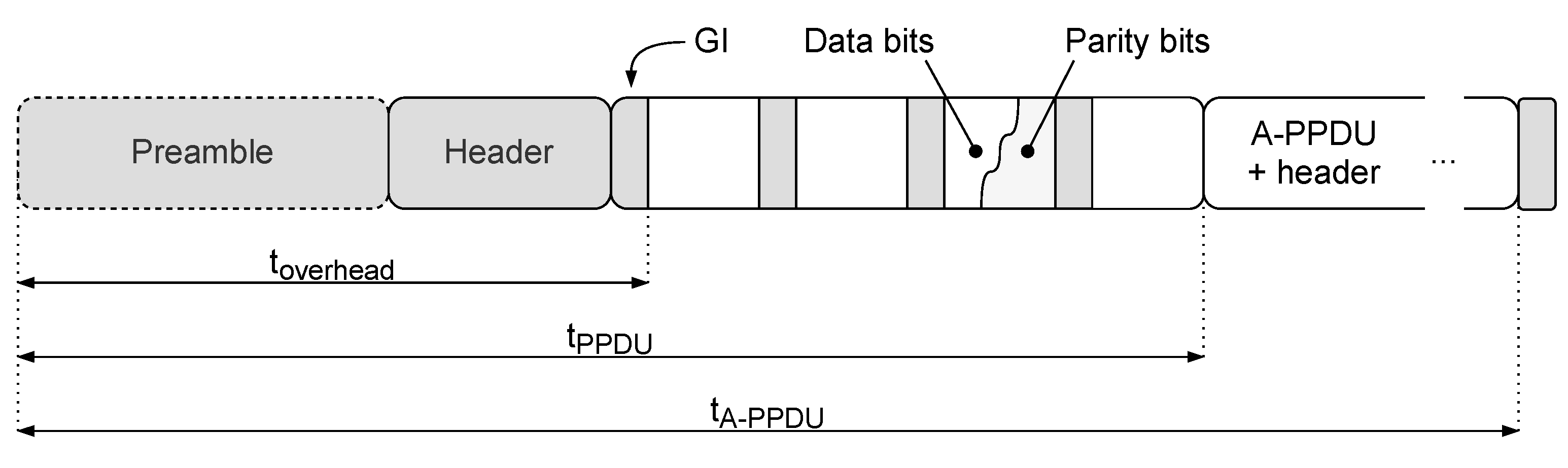
2.2. Analytical Derivation of Latency in the Ideal Scenario
3. Latency-Inducing Receiver Digital Baseband
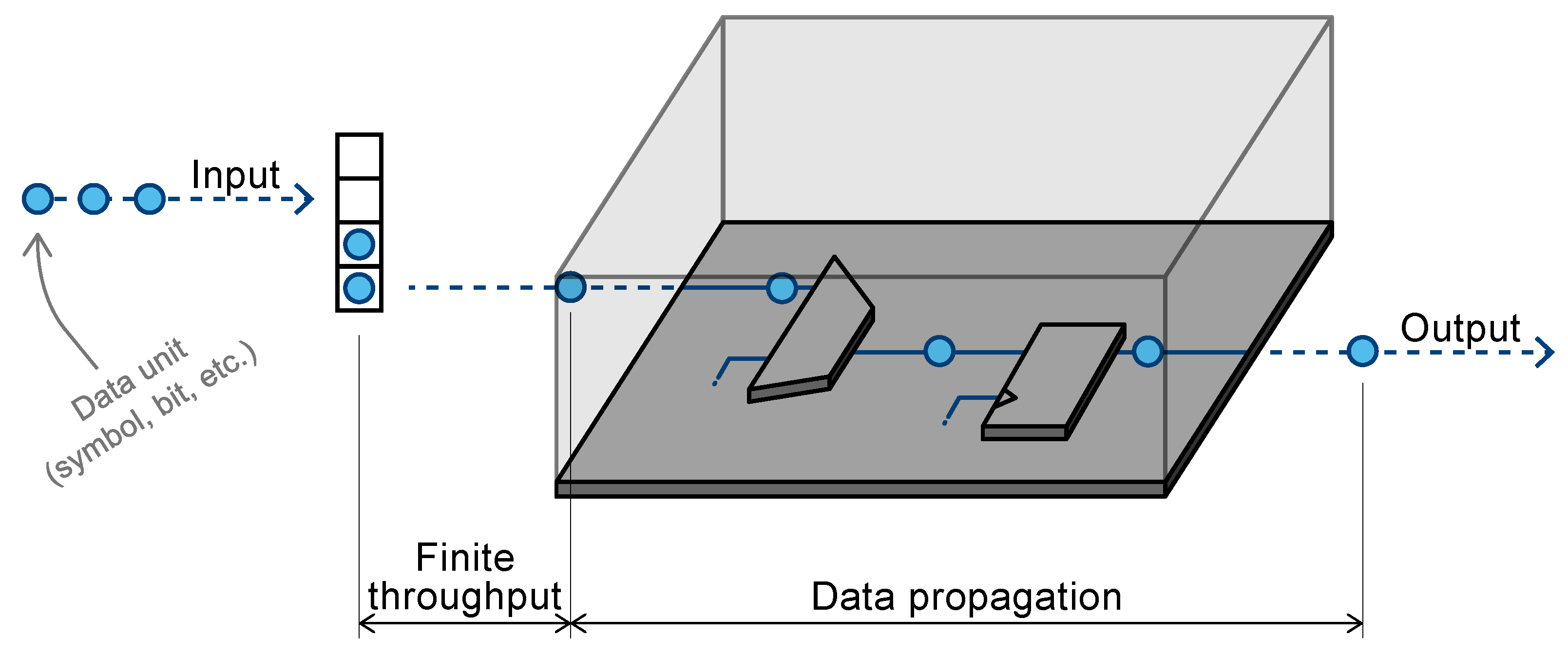
3.1. Two Distinct Time Delays
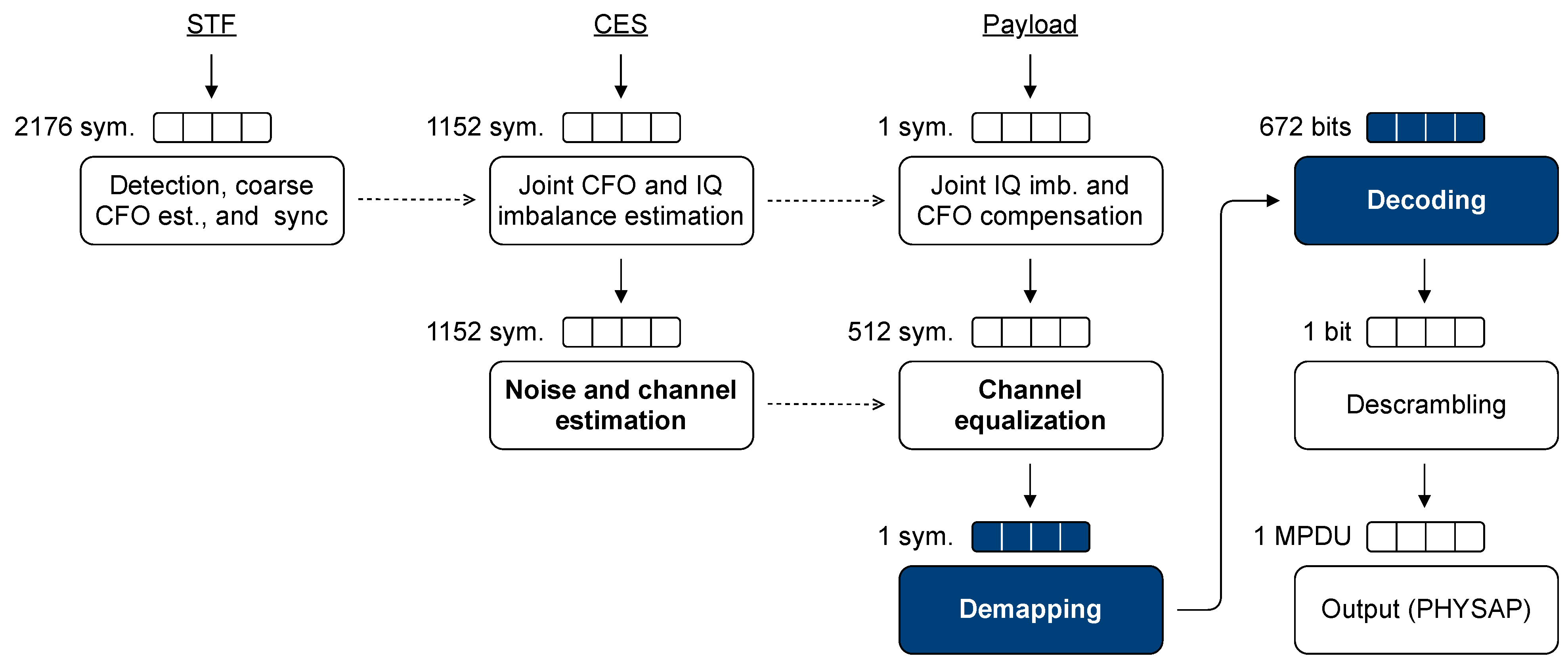
3.2. Performance Figure Derivation
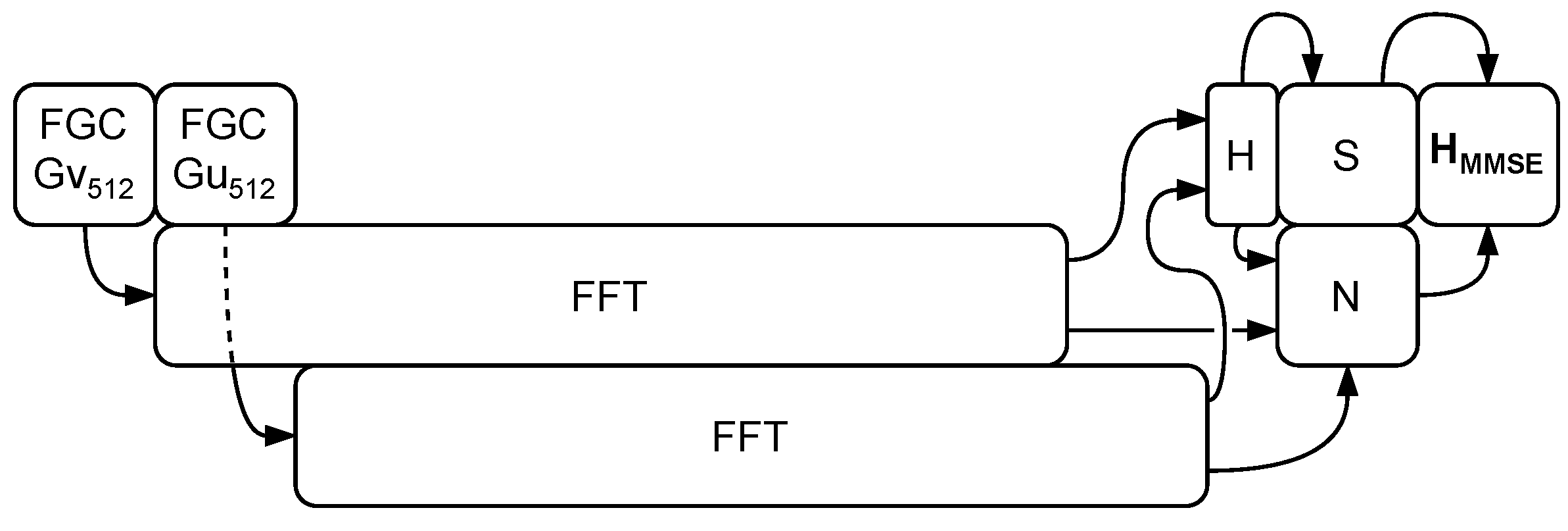
3.2.1. Noise and Channel Estimator
- Using the fast Golay correlation (FGC) algorithm [34] to calculate the cross-correlation between the received signal and the two known complementary Golay sequences and . The process is repeated twice—once for each Golay sequence—and ultimately yields the channel input response (CIR).
- Converting the FGC results to the frequency domain via a fast Fourier transform (FFT) block, weighing them with , and adding them together, forming the channel frequency response (CFR).
- Calculating the signal-to-noise ratio (SNR) using the CFR and the frequency-domain correlation results.
- Finally, obtaining the MMSE matrix using the CFR and SNR.
3.2.2. Channel Equalizer
3.2.3. Symbol Demapper
3.2.4. LDPC Decoder
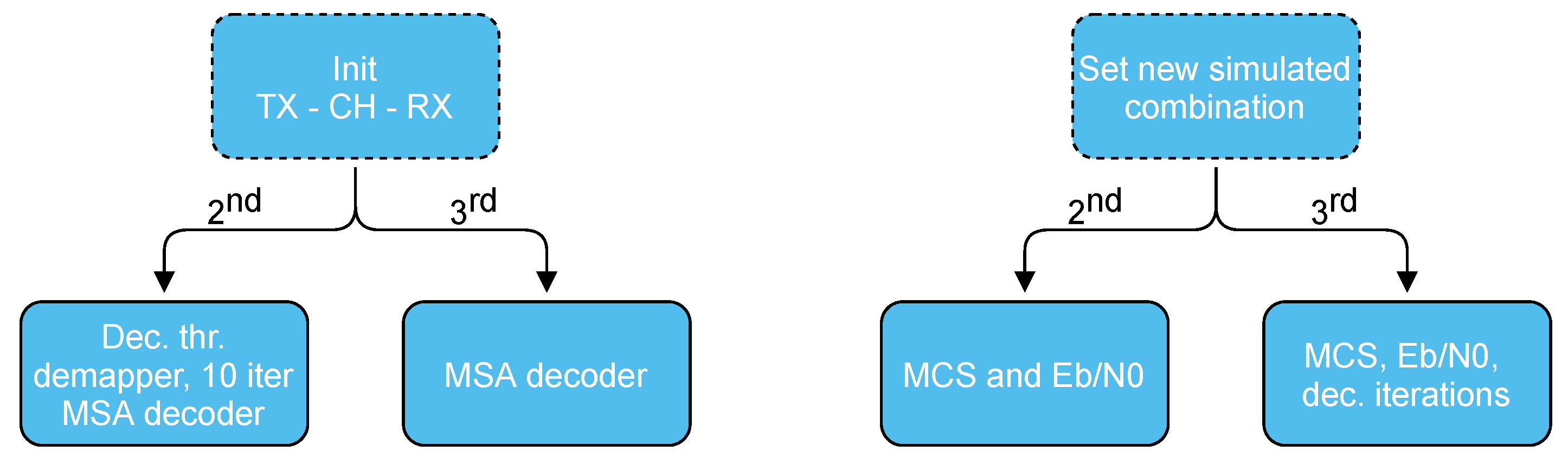
4. Simulation Environment
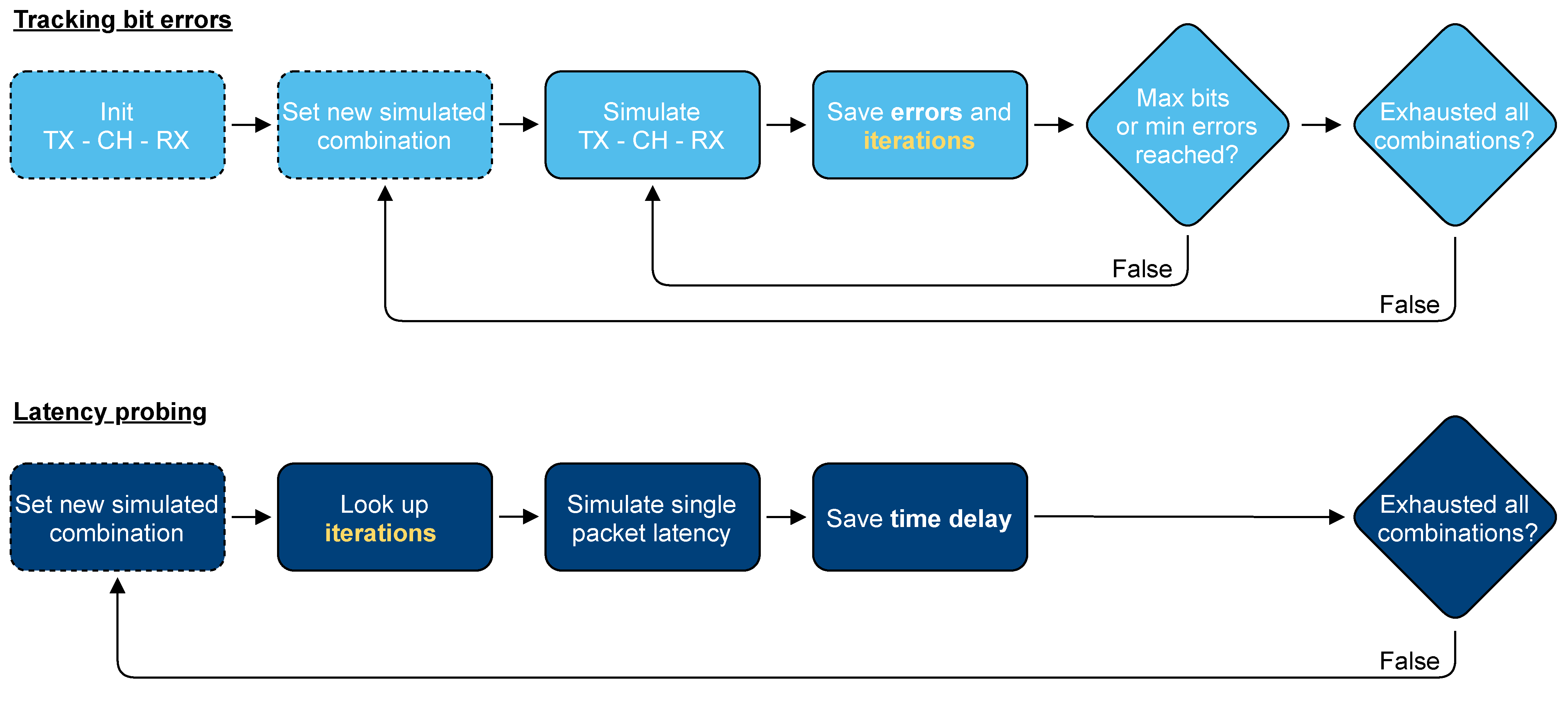
4.1. Tracking Bit Errors
4.2. Latency Probing
5. Results
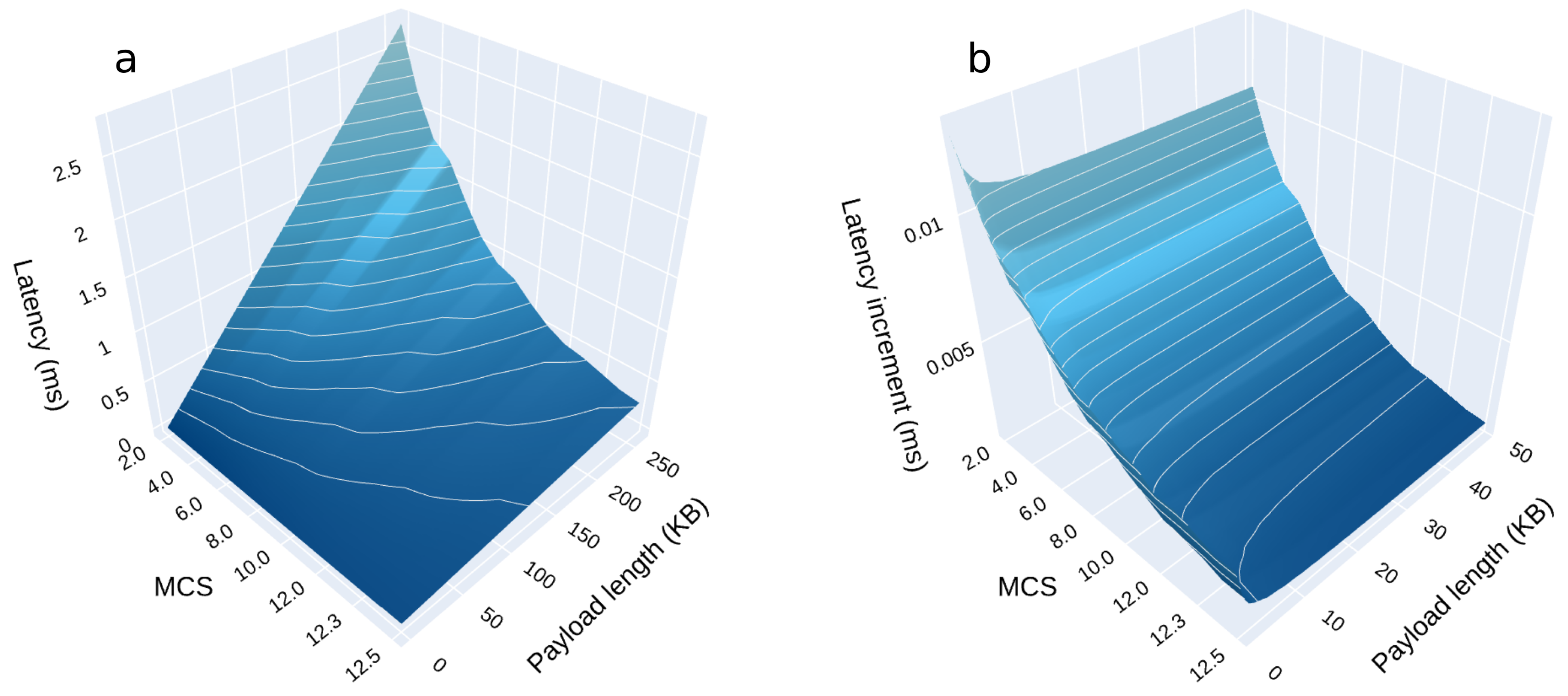
5.1. Steering the Physical Layer in an Ideal Scenario
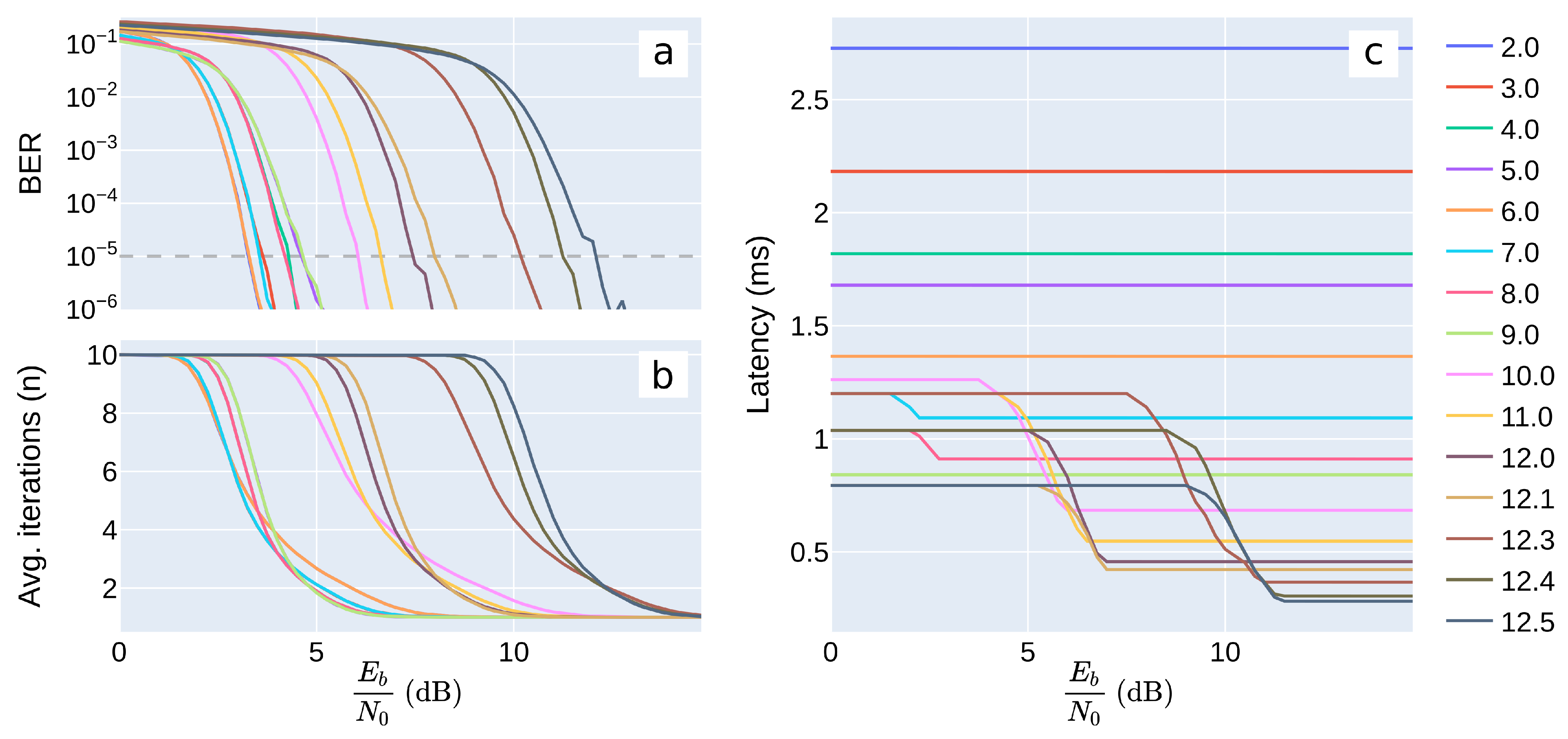
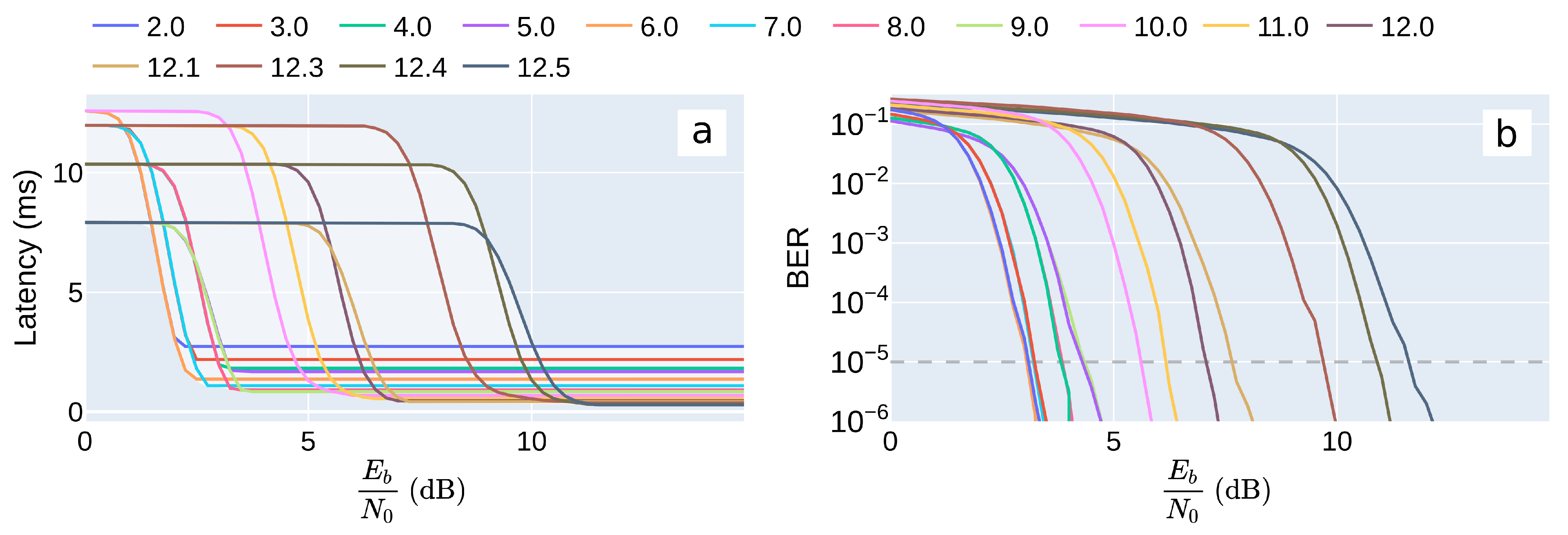
5.2. Including Physical Layer Latency and Channel Noise
5.3. Tuning the RX DBB Components
6. Discussion
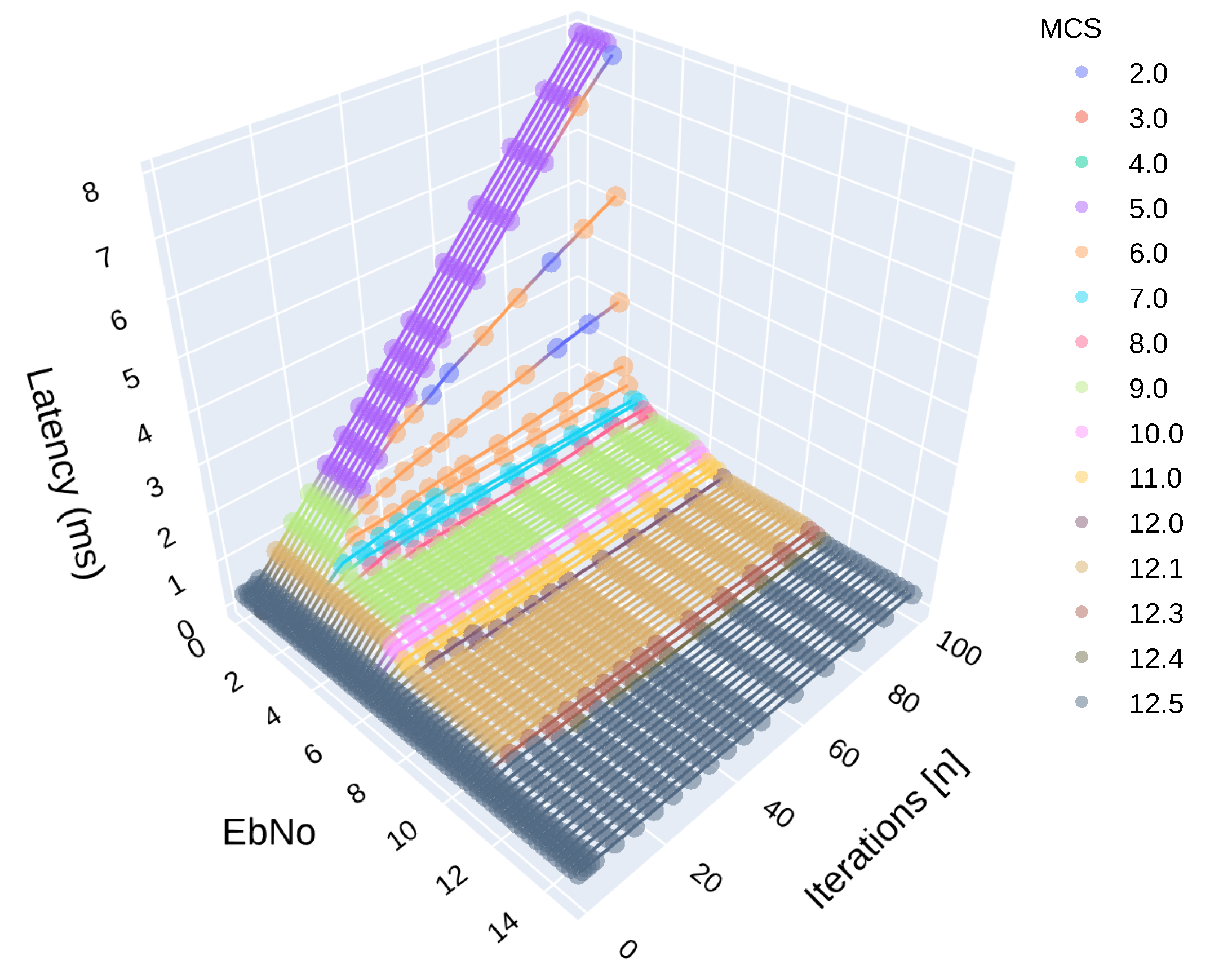
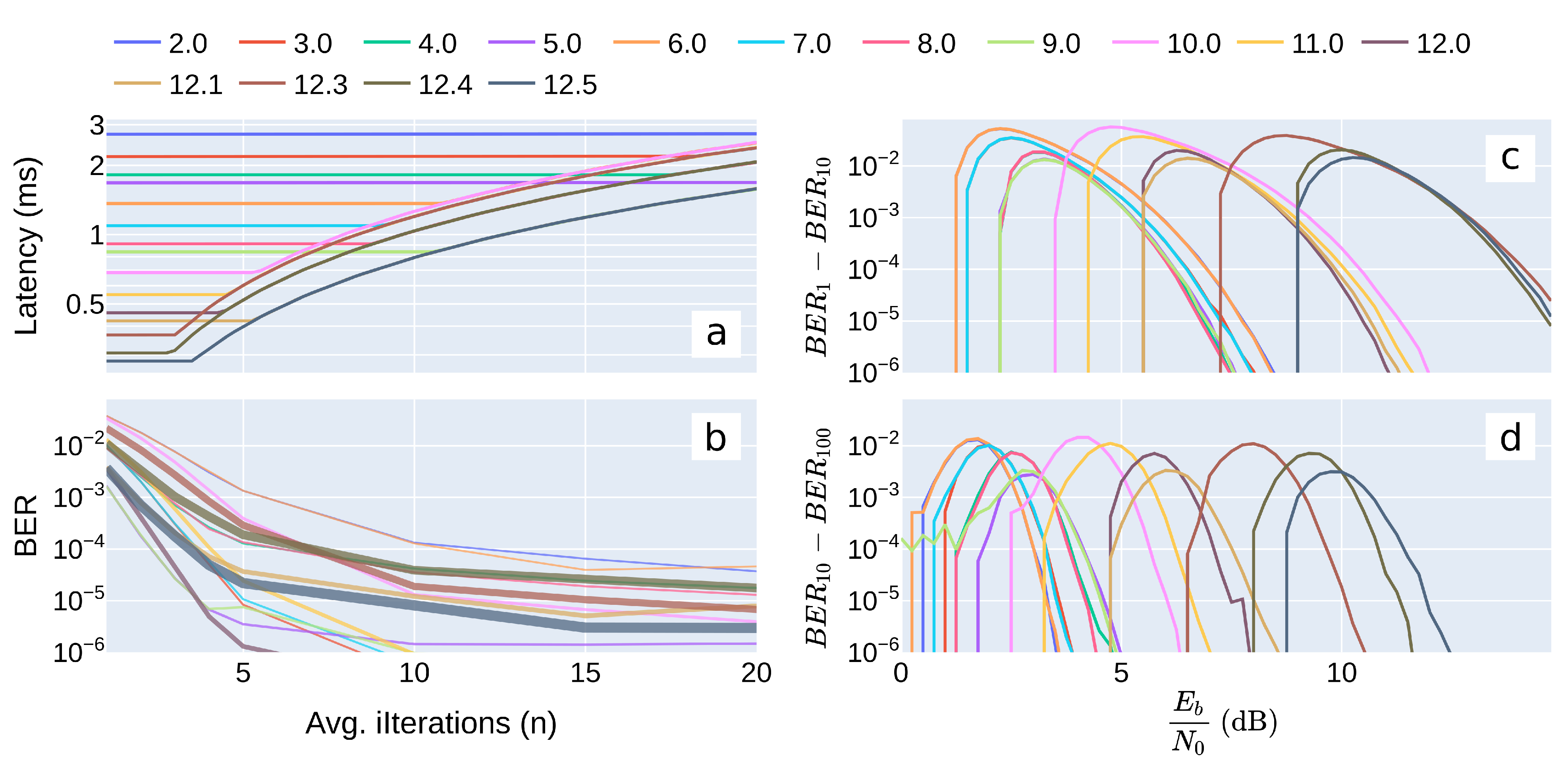
6.1. Allowing More Iterations for Using up Additional Time
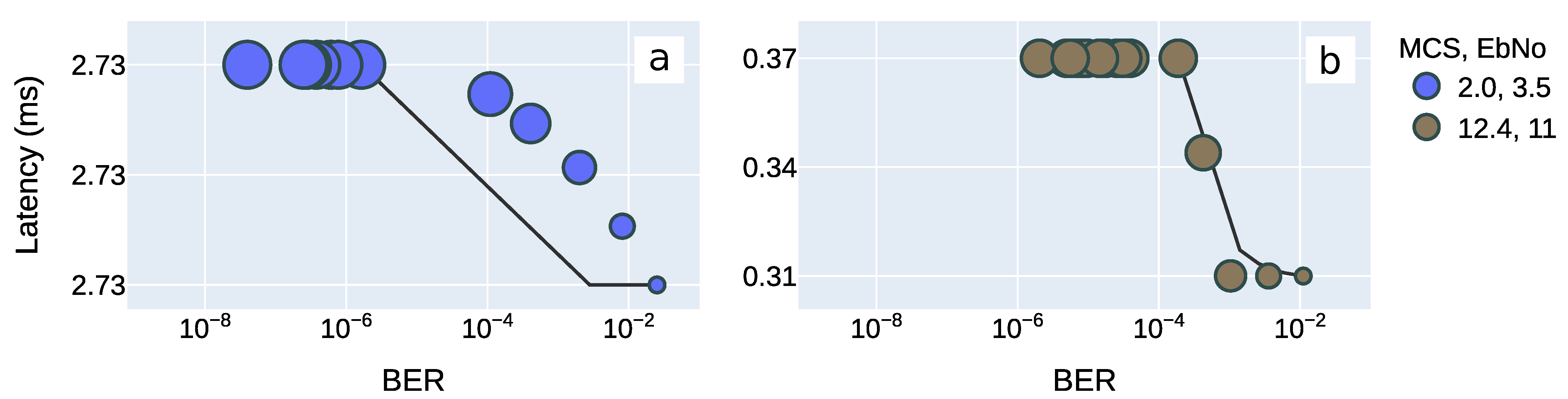
6.2. Latency Versus Bit Error Rate
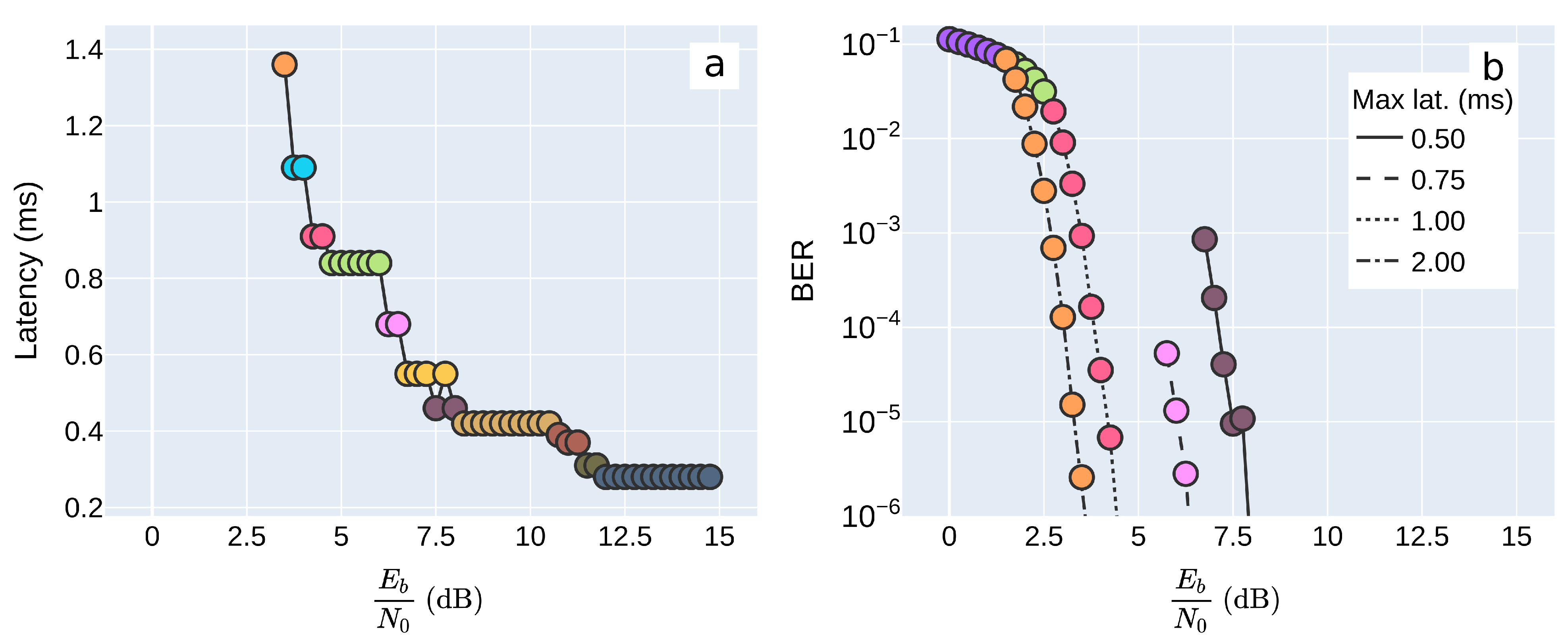
6.3. Pareto Optimality
6.4. Summary of Simulation Results
7. Conclusions
Author Contributions
Funding

Data Availability Statement
Conflicts of Interest
References
- Cisco and Its Affiliates. Cisco Annual Internet Report (2018–2023). 2020. Available online: https://www.cisco.com/c/en/us/solutions/collateral/executive-perspectives/annual-internet-report/white-paper-c11-741490.html (accessed on 14 May 2021).
- IEEE Computer Society. Directional multi-gigabit (DMG) PHY specification. In 802.11-2016—IEEE Standard for Information Technology—Telecommunications and Information Exchange between Systems Local and Metropolitan area Networks—Specific Requirements—Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications; IEEE: New York, NY, USA, 2016; pp. 2436–2496. ISBN 9781504436458. [Google Scholar] [CrossRef]
- IEEE Communications Society. Very high throughput (VHT) PHY specification. In IEEE Standard for Information Technology—Telecommunications and Information Exchange between Systems Local and Metropolitan Area Networks—Specific Requirements—Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications; IEEE: New York, NY, USA, 2016; pp. 2497–2624. ISBN 9781504436458. [Google Scholar] [CrossRef]
- Yao, R.; Heath, T.; Davies, A.; Forsyth, T.; Mitchell, N.; Hoberman, P. Oculus VR Best Practices Guide; Technical Report 36.777; Oculus VR Inc.: Irvine, CA, USA, 2014; Version 0.008. [Google Scholar]
- Adame, T.; Carrascosa, M.; Bellalta, B. Time-Sensitive Networking in IEEE 802.11be: On the Way to Low-latency WiFi 7. arXiv 2019, arXiv:1912.06086. [Google Scholar]
- 3GPP. Study on Communication for Automation in Vertical Domains; Technical Report (TR) 22.804; 3rd Generation Partnership Project (3GPP): Sophia Antipolis, France, 2020; Version 16.3.0. [Google Scholar]
- Siddiqi, M.A.; Yu, H.; Joung, J. 5G Ultra-Reliable Low-Latency Communication Implementation Challenges and Operational Issues with IoT Devices. Electronics 2019, 8, 981. [Google Scholar] [CrossRef] [Green Version]
- Kanavos, A.; Fragkos, D.; Kaloxylos, A. V2X Communication over Cellular Networks: Capabilities and Challenges. Telecom 2021, 2, 1. [Google Scholar] [CrossRef]
- Kim, C.; Tomas Gareau, N.M. 5G for Drone-Based Vertical Applications—D1.1 Use Case Specifications and Requirements; Technical Report; 5G!Drones: Oulu, Finland, 2019; Version 1.0. [Google Scholar]
- 5GACIA. 5G for Connected Industries and Automation; Technical Report; 5G Alliance for Connected Industries and Automation (5GACIA): Frankfurt, Germany, 2019. [Google Scholar]
- Elbamby, M.S.; Perfecto, C.; Bennis, M.; Doppler, K. Toward Low-Latency and Ultra-Reliable Virtual Reality. IEEE Netw. 2018, 32, 78–84. [Google Scholar] [CrossRef] [Green Version]
- Singh, H.; Oh, J.; Kweon, C.; Qin, X.; Shao, H.R.; Ngo, C. A 60 GHz wireless network for enabling uncompressed video communication. IEEE Commun. Mag. 2008, 46, 71–78. [Google Scholar] [CrossRef]
- Furst, J.; Argerich, M.F.; Cheng, B.; Papageorgiou, A. Elastic Services for Edge Computing; Poster Session; IEEE: Rome, Italy, 2018; p. 5. [Google Scholar]
- Bailey, R.E.; Parrish, R.V.; Arthur III, J.J.; Norman, R.M. Latency Requirements for Head-Worn Display S/EVS Applications; SPIE, Enhanced and Synthetic Vision: Orlando, FL, USA, 2004; Volume 5424, pp. 98–109. [Google Scholar] [CrossRef] [Green Version]
- Jerald, J.; Whitton, M. Relating Scene-Motion Thresholds to Latency Thresholds for Head-Mounted Displays. In Proceedings of the IEEE Virtual Reality Conference, Lafayette, LA, USA, 14–18 March 2009; pp. 211–218. [Google Scholar] [CrossRef] [Green Version]
- Geršak, G.; Lu, H.; Guna, J. Effect of VR technology matureness on VR sickness. Multimed. Tools Appl. 2020, 79, 14491–14507. [Google Scholar] [CrossRef]
- Potter, M.C.; Wyble, B.; Hagmann, C.E.; McCourt, E.S. Detecting meaning in RSVP at 13 ms per picture. Atten. Percept. Psychophys. 2014, 76, 270–279. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shukla, G.; Beg, M.T.; Lall, B. Evaluation of Latency in IEEE 802.11ad. In Innovations in Electronics and Communication Engineering; Series Title: Lecture Notes in Networks and Systems; Saini, H.S., Singh, R.K., Tariq Beg, M., Sahambi, J.S., Eds.; Springer: Singapore, 2020; Volume 107, pp. 139–145. [Google Scholar] [CrossRef]
- Wei, T.; Zhang, X. Pose Information Assisted 60 GHz Networks: Towards Seamless Coverage and Mobility Support. In Proceedings of the 23rd Annual International Conference on Mobile Computing and Networking, Snowbird, UT, USA, 16–20 October 2017; pp. 42–55. [Google Scholar] [CrossRef]
- Kim, S.; Yun, J.H. Motion-Aware Interplay between WiGig and WiFi for Wireless Virtual Reality. Sensors 2020, 20, 6782. [Google Scholar] [CrossRef]
- Liu, L.; Zhong, R.; Zhang, W.; Liu, Y.; Zhang, J.; Zhang, L.; Gruteser, M. Cutting the Cord: Designing a High-quality Untethered VR System with Low Latency Remote Rendering. In Proceedings of the 16th Annual International Conference on Mobile Systems, Applications, and Services, Munich, Germany, 10–15 June 2018; pp. 68–80. [Google Scholar] [CrossRef]
- Ravichandran, A.; Jain, I.K.; Hegazy, R.; Wei, T.; Bharadia, D. Facilitating Low Latency and Reliable VR over Heterogeneous Wireless Networks. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking, New Delhi, India, 29 October–2 November 2018; pp. 723–725. [Google Scholar] [CrossRef]
- Sur, S.; Pefkianakis, I.; Zhang, X.; Kim, K.H. WiFi-Assisted 60 GHz Wireless Networks. In Proceedings of the 23rd Annual International Conference on Mobile Computing and Networking, Snowbird, UT, USA, 16–20 October 2017; pp. 28–41. [Google Scholar] [CrossRef]
- Lu, C.; Wu, B.; Wang, L.; Wei, Z.; Tang, Y. A Novel QoS-Aware ARQ Scheme for Multi-User Transmissions in IEEE802.11ax WLANs. Electronics 2020, 9, 2065. [Google Scholar] [CrossRef]
- Lu, C.; Wu, B.; Ye, T. A Novel QoS-Aware A-MPDU Aggregation Scheduler for Unsaturated IEEE802.11n/ac WLANs. Electronics 2020, 9, 1203. [Google Scholar] [CrossRef]
- Shah, V.; Cooklev, T. Throughput and latency performance of IEEE 802.11e with 802.11a, 802.11b, and 802.11g physical layers. J. Inst. Eng. India Ser. B 2004, 93, 247–253. [Google Scholar] [CrossRef]
- Jiang, X.; Shokri-Ghadikolaei, H.; Fodor, G.; Modiano, E.; Pang, Z.; Zorzi, M.; Fischione, C. Low-Latency Networking: Where Latency Lurks and How to Tame It. Proc. IEEE 2019, 107, 280–306. [Google Scholar] [CrossRef]
- Fehrenbach, T.; Datta, R.; Göktepe, B.; Wirth, T.; Hellge, C. URLLC Services in 5G Low Latency Enhancements for LTE. In Proceedings of the 2018 IEEE 88th Vehicular Technology Conference (VTC-Fall), Chicago, IL, USA, 27–30 August 2018; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Ji, H.; Park, S.; Yeo, J.; Kim, Y.; Lee, J.; Shim, B. Ultra-Reliable and Low-Latency Communications in 5G Downlink: Physical Layer Aspects. IEEE Wirel. Commun. 2018, 25, 124–130. [Google Scholar] [CrossRef] [Green Version]
- Sachs, J.; Wikstrom, G.; Dudda, T.; Baldemair, R.; Kittichokechai, K. 5G Radio Network Design for Ultra-Reliable Low-Latency Communication. IEEE Netw. 2018, 32, 24–31. [Google Scholar] [CrossRef]
- Jung, Y.M.; Chung, C.H.; Jung, Y.H.; Kim, J.S. 7.7 Gbps Encoder Design for IEEE 802.11ac QC-LDPC Codes. In Proceedings of the 2012 International SoC Design Conference (ISOCC), Jeju, South Korea, 4–7 November 2012. [Google Scholar]
- Genc, Z.; Thillo, W.V.; Bourdoux, A.; Onur, E. 60 GHz PHY Performance Evaluation with 3D Ray Tracing under Human Shadowing. IEEE Wirel. Commun. Lett. 2012, 1, 117–120. [Google Scholar] [CrossRef]
- Chen, J.; Lin, H.; Tang, Y.C. Efficient high-throughput architectures for high-speed parallel scramblers. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Paris, France, 30 May–2 June 2010; pp. 441–444. [Google Scholar] [CrossRef]
- Budišin, S. Efficient pulse compressor for golay complementary sequences. Electron. Lett. 1991, 27, 219. [Google Scholar] [CrossRef]
- Ahmed, T.; Garrido, M.; Gustafsson, O. A 512-point 8-parallel pipelined feedforward FFT for WPAN. In Proceedings of the 2011 Conference Record of the Forty Fifth Asilomar Conference on Signals, Systems and Computers (ASILOMAR), Pacific Grove, CA, USA, 6–9 November 2011; pp. 981–984. [Google Scholar] [CrossRef] [Green Version]
- Jafri, A.R.; Baghdadi, A.; Waqas, M.; Najam-Ul-Islam, M. High-Throughput and Area-Efficient Rotated and Cyclic Q Delayed Constellations Demapper for Future Wireless Standards. IEEE Access 2017, 5, 3077–3084. [Google Scholar] [CrossRef]
- Jafri, A.; Baghdadi, A.; Jezequel, M. ASIP-Based Universal Demapper for Multiwireless Standards. IEEE Embed. Syst. Lett. 2009, 1, 9–13. [Google Scholar] [CrossRef]
- Ali, I.; Wasenmüller, U.; Wehn, N. A high throughput architecture for a low complexity soft-output demapping algorithm. Adv. Radio Sci. 2015, 13, 73–80. [Google Scholar] [CrossRef] [Green Version]
- Kuon, I.; Rose, J. Measuring the Gap Between FPGAs and ASICs. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2007, 26, 203–215. [Google Scholar] [CrossRef] [Green Version]
- Borkar, S. Design challenges of technology scaling. IEEE Micro 1999, 19, 23–29. [Google Scholar] [CrossRef]
- Stillmaker, A.; Baas, B. Scaling equations for the accurate prediction of CMOS device performance from 180 nm to 7 nm. Integration 2017, 58, 74–81. [Google Scholar] [CrossRef]
- Salbiyono, A.; Adiono, T. LDPC decoder performance under different number of iterations in mobile WiMax. In Proceedings of the 2010 International Symposium on Intelligent Signal Processing and Communication Systems, Chengdu, China, 6–8 December 2010; pp. 1–4. [Google Scholar] [CrossRef]
- Koike-Akino, T.; Millar, D.S.; Kojima, K.; Parsons, K.; Miyata, Y.; Sugihara, K.; Matsumoto, W. Iteration-Aware LDPC Code Design for Low-Power Optical Communications. J. Light. Technol. 2016, 34, 573–581. [Google Scholar] [CrossRef]
- Li, M.; Naessens, F.; Li, M.; Debacker, P.; Desset, C.; Raghavan, P.; Dejonghe, A.; Van der Perre, L. A processor based multi-standard low-power LDPC engine for multi-Gbps wireless communication. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; pp. 1254–1257. [Google Scholar] [CrossRef]
- Marinšek, A.; Van der Perre, L. Keeping up with the Bits: Tracking Physical Layer Latency in Millimeter-Wave Wi-Fi Networks. arXiv 2021, arXiv:cs.NI/2105.13147. [Google Scholar]
- Franceschini, M.; Ferrari, G.; Raheli, R. Decoding algorithms for LDPC codes. In LDPC Coded Modulations; Signals and Communication Technology; Springer: Berlin/Heidelberg, Germany, 2009; pp. 42–53. [Google Scholar] [CrossRef]
- Borlenghi, F.; Witte, E.M.; Ascheid, G.; Meyr, H.; Burg, A. A 772Mbit/s 8.81bit/nJ 90nm CMOS soft-input soft-output sphere decoder. In Proceedings of the IEEE Asian Solid-State Circuits Conference, Jeju, Korea, 14–16 November 2011; pp. 297–300. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Industry | Application | Max. Latency (ms) | Latency Type | Ref. |
|---|---|---|---|---|
| XR | VR entertainment | 20 | RTT and E2E | [4,5] |
| Professional AR/MR usage | 10 | RTT and E2E | [6,7] | |
| V2X, UVs | Platooning | 25 | RTT | [6,8,9] |
| and | Remote control | 10 | E2E | [6,7,8,9] |
| drones | Cooperative driving/flight | 10 | RTT | [6,7,8,9] |
| i4.0 | Remote control and monitoring | 50 | E2E | [10] |
| Cooperative robots | 1 | RTT | [10] |
| BPSK | QPSK | 16QAM | 64QAM | |
|---|---|---|---|---|
| 2 | 6 | 10 | / | |
| 3 | 7 | 11 | 12.3 | |
| 4 | 8 | 12 | 12.4 | |
| 5 | 9 | 12.1 | 12.5 |
| Name | Throughput () | Demapping Algorithm | Ref. |
|---|---|---|---|
| Exact | 800 | [36] | |
| Approximative | 3030 | [37] | |
| Decision threshold | 6640 | [38] |
| A-PPDU | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 12.1 | 12.3 | 12.4 | 12.5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2.73 | 2.18 | 1.82 | 1.68 | 1.36 | 1.09 | 0.91 | 0.84 | 0.68 | 0.55 | 0.46 | 0.42 | 0.37 | 0.31 | 0.28 |
| 1 | 5.45 | 4.36 | 3.63 | 3.36 | 2.73 | 2.18 | 1.82 | 1.68 | 1.37 | 1.09 | 0.91 | 0.84 | 0.73 | 0.61 | 0.56 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marinšek, A.; Delabie, D.; De Strycker, L.; Van der Perre, L. Physical Layer Latency Management Mechanisms: A Study for Millimeter-Wave Wi-Fi. Electronics 2021, 10, 1599. https://doi.org/10.3390/electronics10131599
Marinšek A, Delabie D, De Strycker L, Van der Perre L. Physical Layer Latency Management Mechanisms: A Study for Millimeter-Wave Wi-Fi. Electronics. 2021; 10(13):1599. https://doi.org/10.3390/electronics10131599
Chicago/Turabian StyleMarinšek, Alexander, Daan Delabie, Lieven De Strycker, and Liesbet Van der Perre. 2021. "Physical Layer Latency Management Mechanisms: A Study for Millimeter-Wave Wi-Fi" Electronics 10, no. 13: 1599. https://doi.org/10.3390/electronics10131599
APA StyleMarinšek, A., Delabie, D., De Strycker, L., & Van der Perre, L. (2021). Physical Layer Latency Management Mechanisms: A Study for Millimeter-Wave Wi-Fi. Electronics, 10(13), 1599. https://doi.org/10.3390/electronics10131599