
Word-Based Systolic Processor for Field Multiplication and Squaring Suitable for Cryptographic Processors in Resource-Constrained IoT Systems



Abstract
:1. Introduction
1.1. Paper Motivation and Related Work
1.2. Paper Contribution
1.3. Paper Organization
2. Combined Polynomial Multiplication-Squaring Algorithm in
- Variable is updated by shifting left and by reducing using the irreducible polynomial G;
- Variable is updated by multiplying by coefficient and by adding the obtained result to ;
- Variable is updated by multiplying by coefficient and by adding the obtained result to .
| Algorithm 1 Algorithm for multiplication and squaring over GF() [13]. |
|
Input: , , and Mult. Output: Square Output: Initialization: Algorithm: 1: for do 2: 3: 4: 5: end for |
| Algorithm 2 Bit-level algorithm for multiplication and squaring over GF(). |
|
Input: , , and Mult. Output: Square Output: Initialization: Algorithm: 1: for do 2: for do 3: 4: 5: 6: end for 7: end for |
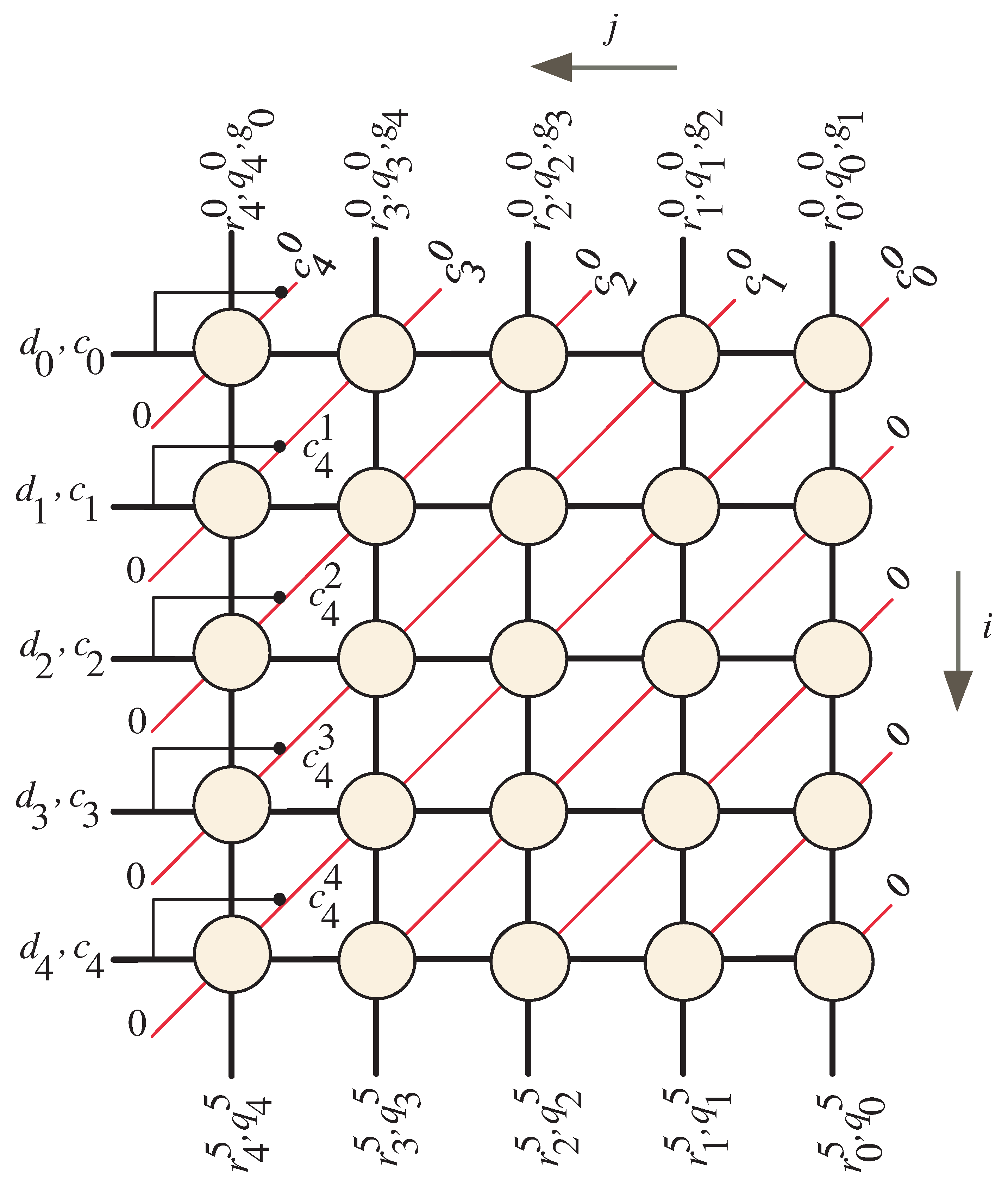
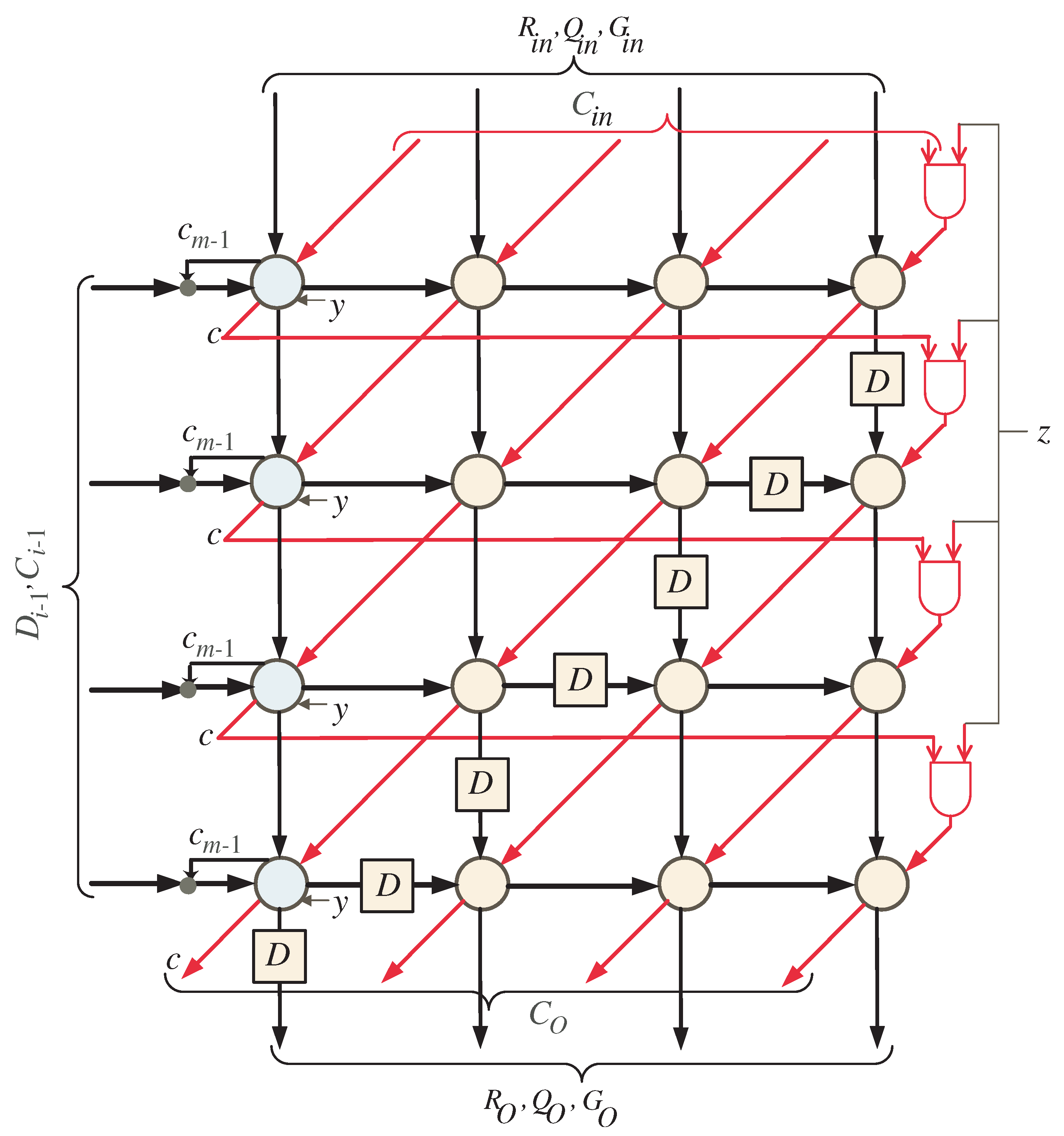
3. Algorithm Dependency Graph
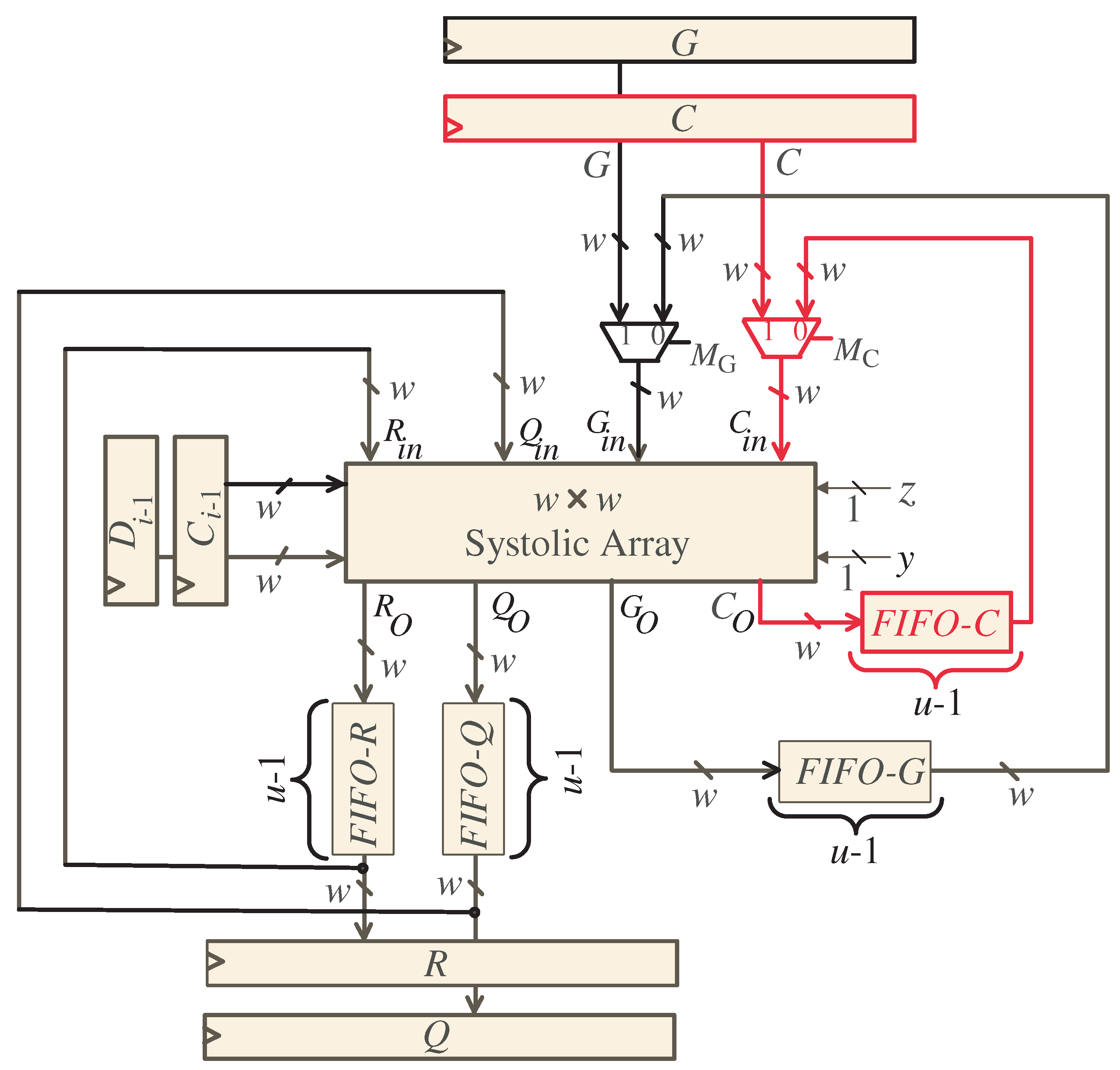
4. Combined Two-Dimensional SISO Multiplier-Squarer
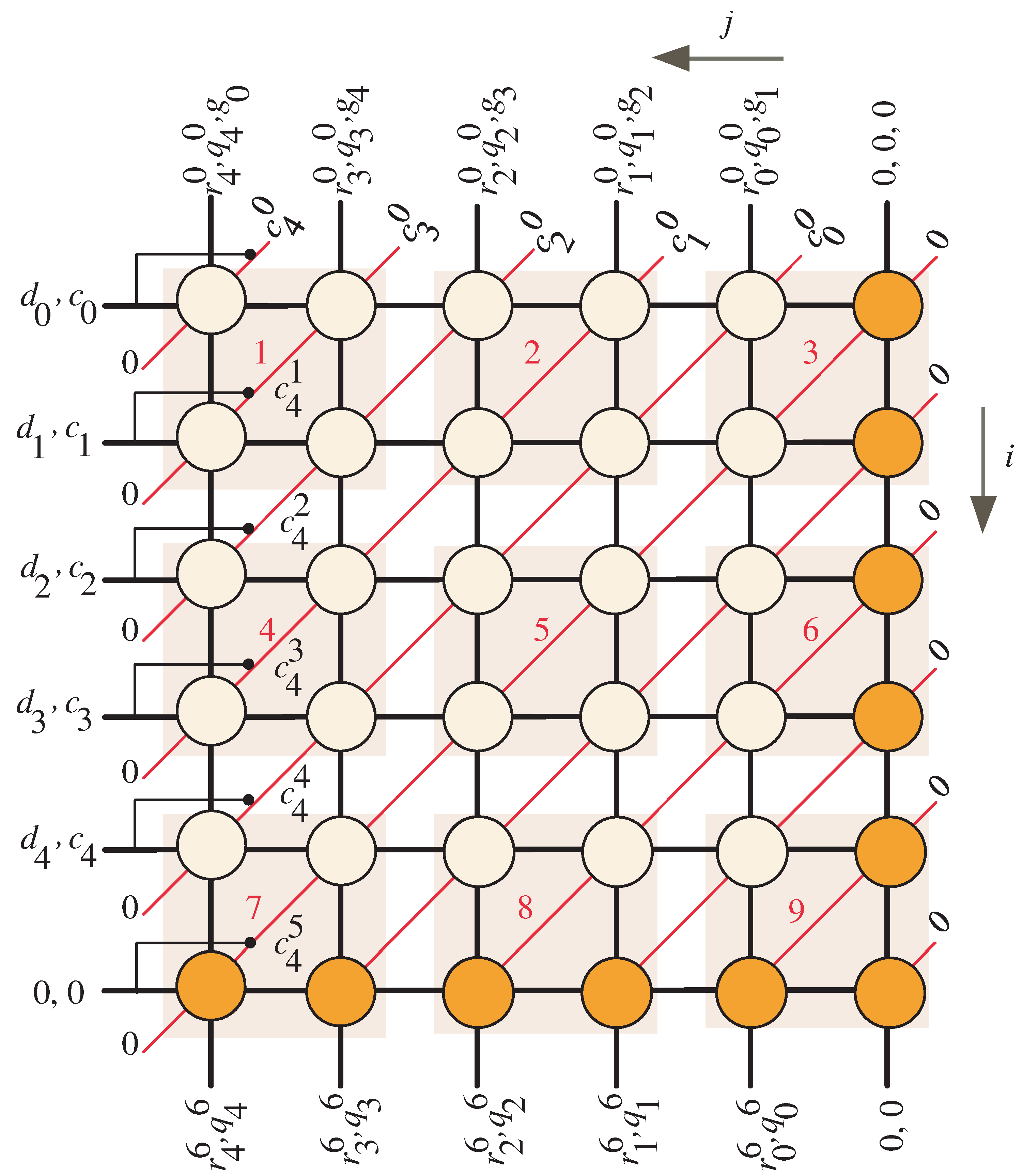
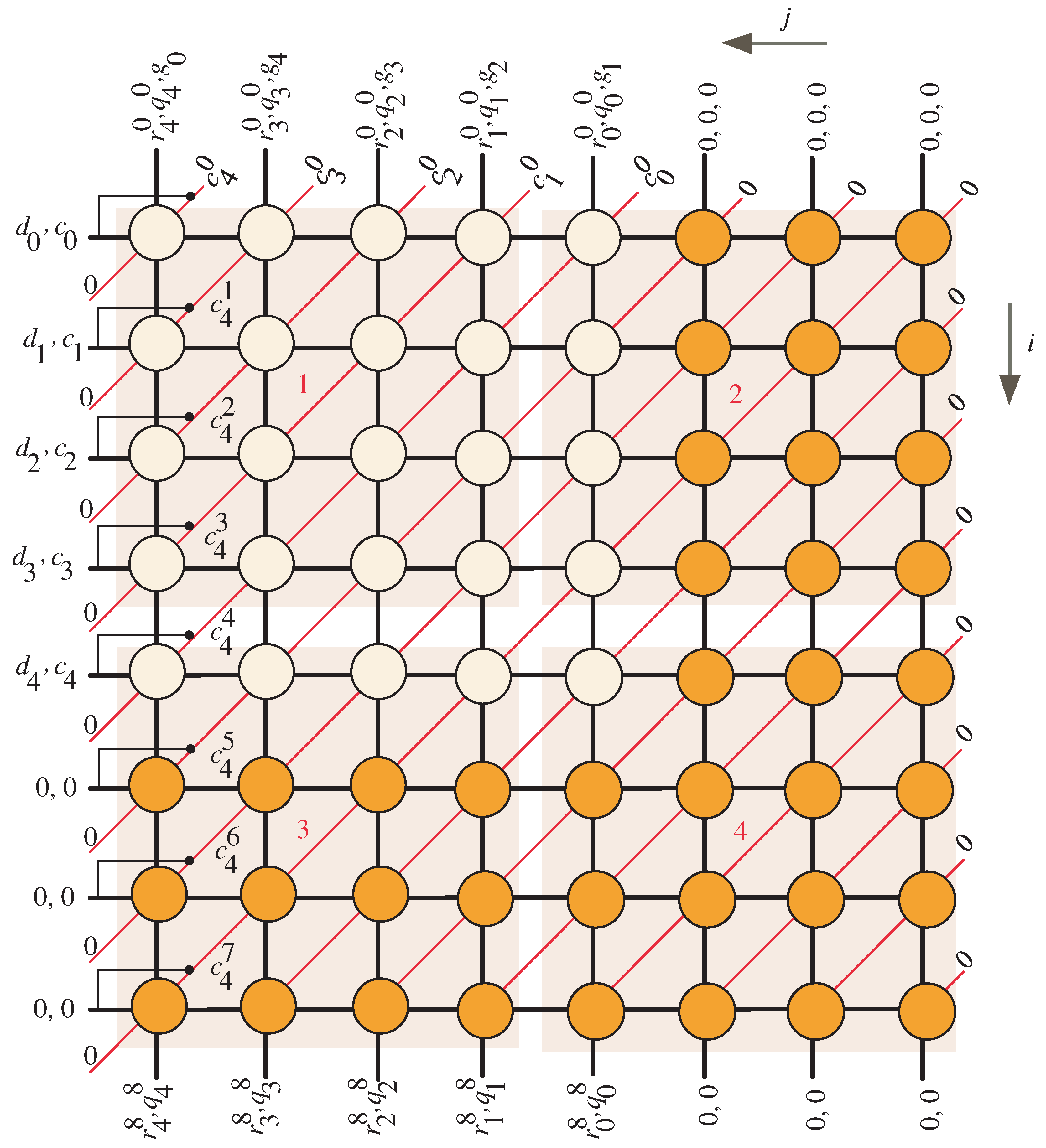
4.1. Two-Dimensional SISO Task Scheduling
Two-Dimentional SISO Task Projection
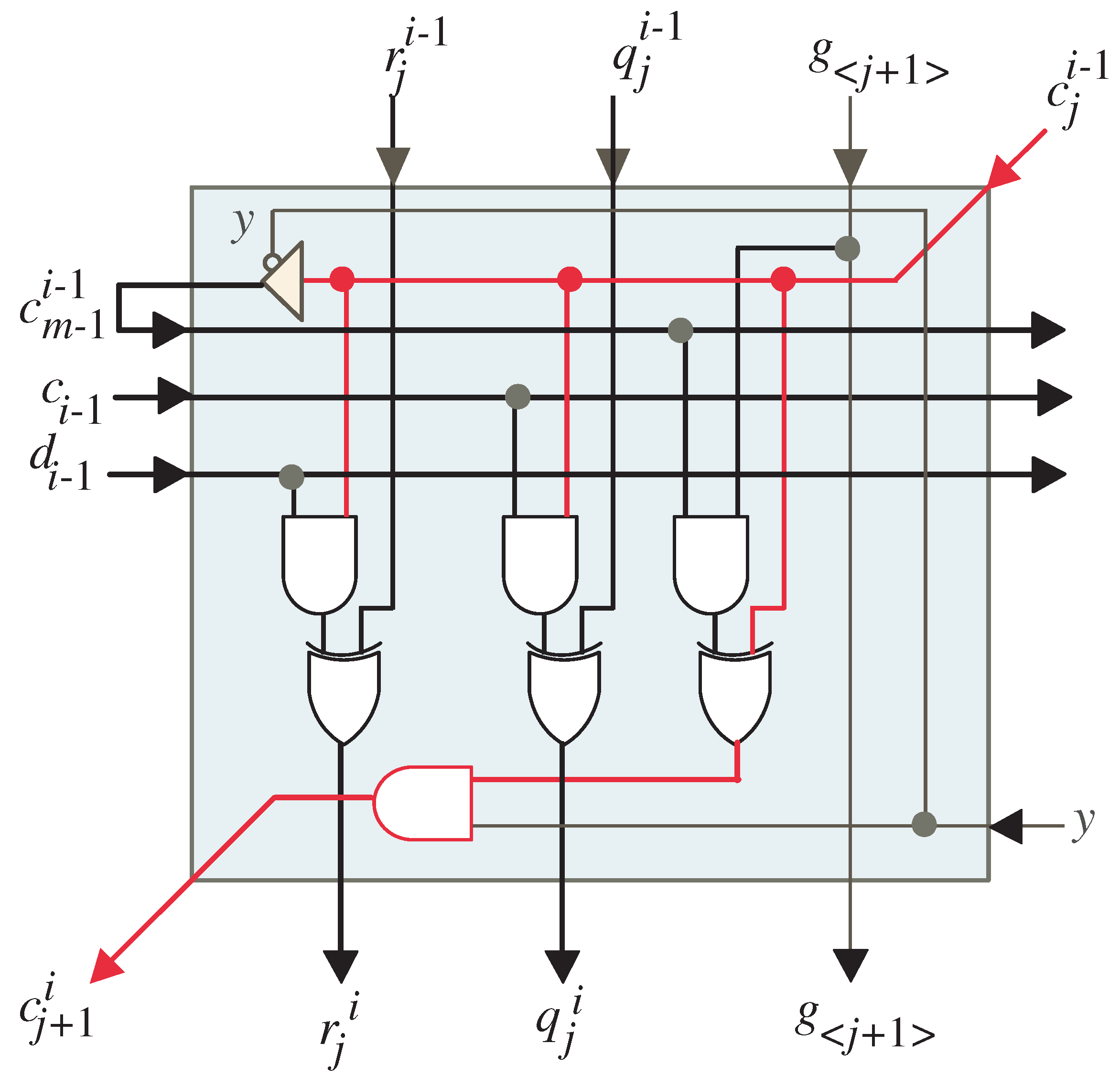
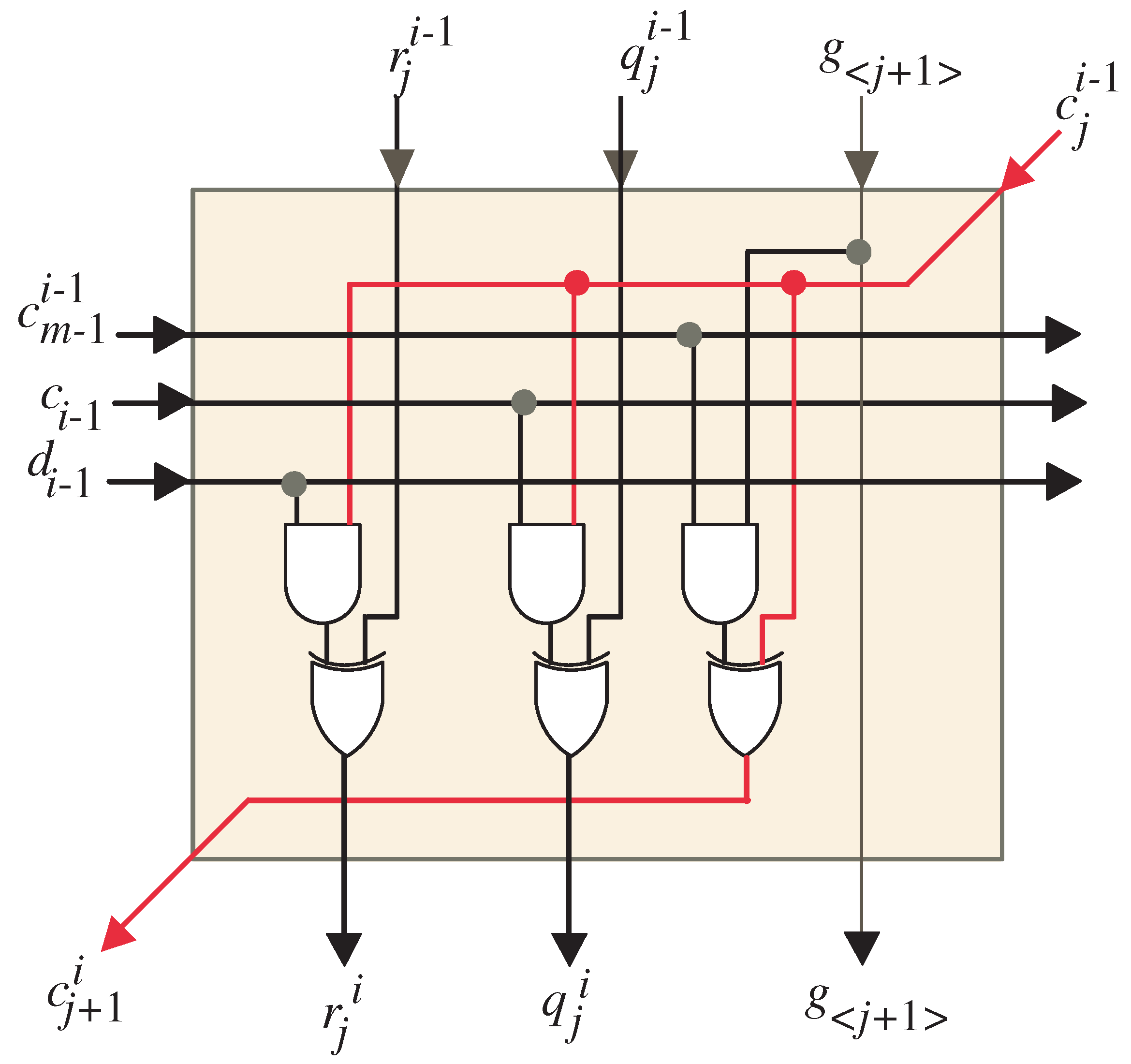
- At time , MUXes and shown in Figure 5, are set to pass the w MSBs of operands C and G, respectively, to the systolic array block. Moreover, FIFO buffers of R and Q are reset at the same time to pass zero inputs to the systolic array block since the initial values of R and Q are zeros as indicated in Algorithm 1. Notice that, the control signals y and z are set to 0 and 1, respectively, through this time step. The control signal enables the tristate buffer shown in Figure 7 for all the light blue PEs of the systolic array, Figure 6, to pass the computed w bits of and . The computed word of along with the w LSBs of and , , are passed horizontally to the remaining PEs nodes of the systolic array. Moreover, the control signal forces the bits of and through the AND gate shown in Figure 7 to have zero values as shown at the left edge of the DG, Figure 3.
- At time instances , MUXs and are still set to pass the remaining words of inputs C and G, one word at each time step, to the systolic array. These operand words are used with the horizontally passed words of , , and , , to compute the intermediate words of R, Q, and C in a word serial fashion. The resulting words of R, Q, and C are pipelined through the FIFOs of R, Q, and C shown in Figure 5, respectively. These FIFOs have a width size of w bits and a depth size of , where . Notice that the depth of R and Q FIFOs ensures keeping the initial values of R and Q equal to zero through these time instances.
- At time instances , MUXs and passes the computed C words stored in FIFO-C and the G words stored in FIFO-G to the systolic array, one word at each time step. These words, along with the computed R and Q words that are stored in FIFO-R and FIFO-Q and the broadcasted words of , , and , , , are used to update the intermediate partial results of R, Q, and C in a word serial fashion, one word at each time step.
- At time instances , the tri-sate buffer shown in Figure 7 is enabled () in all the light blue PEs of the systolic array, Figure 6, to pass horizontally through the computed w bits of , , along with the w bits of inputs and , , to the remaining PEs nodes of the systolic array. Notice that the and registers, shown in Figure 5, feeds the systolic array with the input words of and through these time instances. Furthermore, through these time instances, the control signal () forces the bits of and through the AND gate shown in Figure 7 to have zero values as shown at the left edge of the DG of Figure 3. At the remaining time instances, this control signal is equal to one.
- Through time instances , the resulting output words of R and Q will be loaded in a word serial fashion, one word at each time step, in registers R and Q shown in Figure 5, respectively.
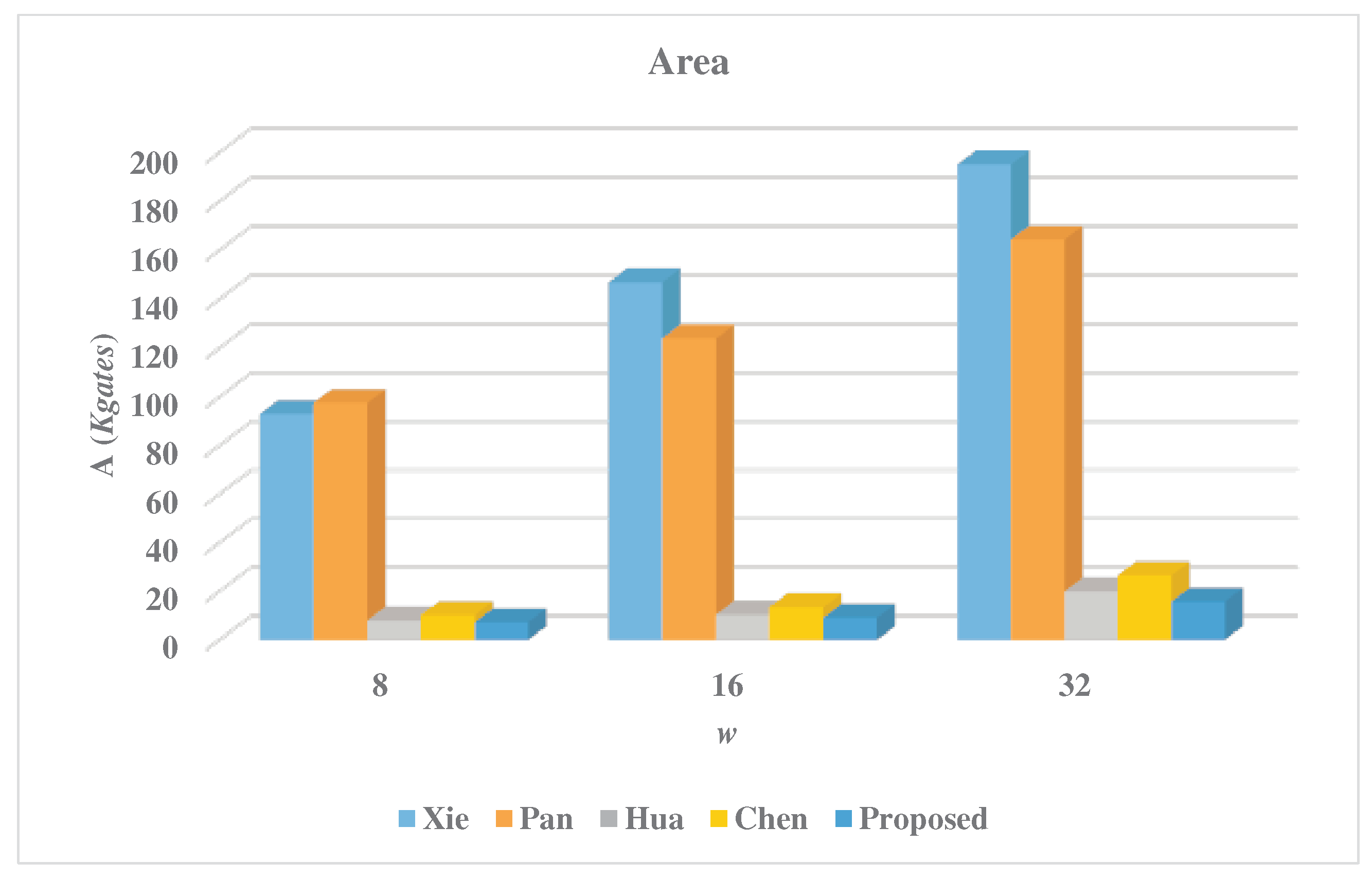
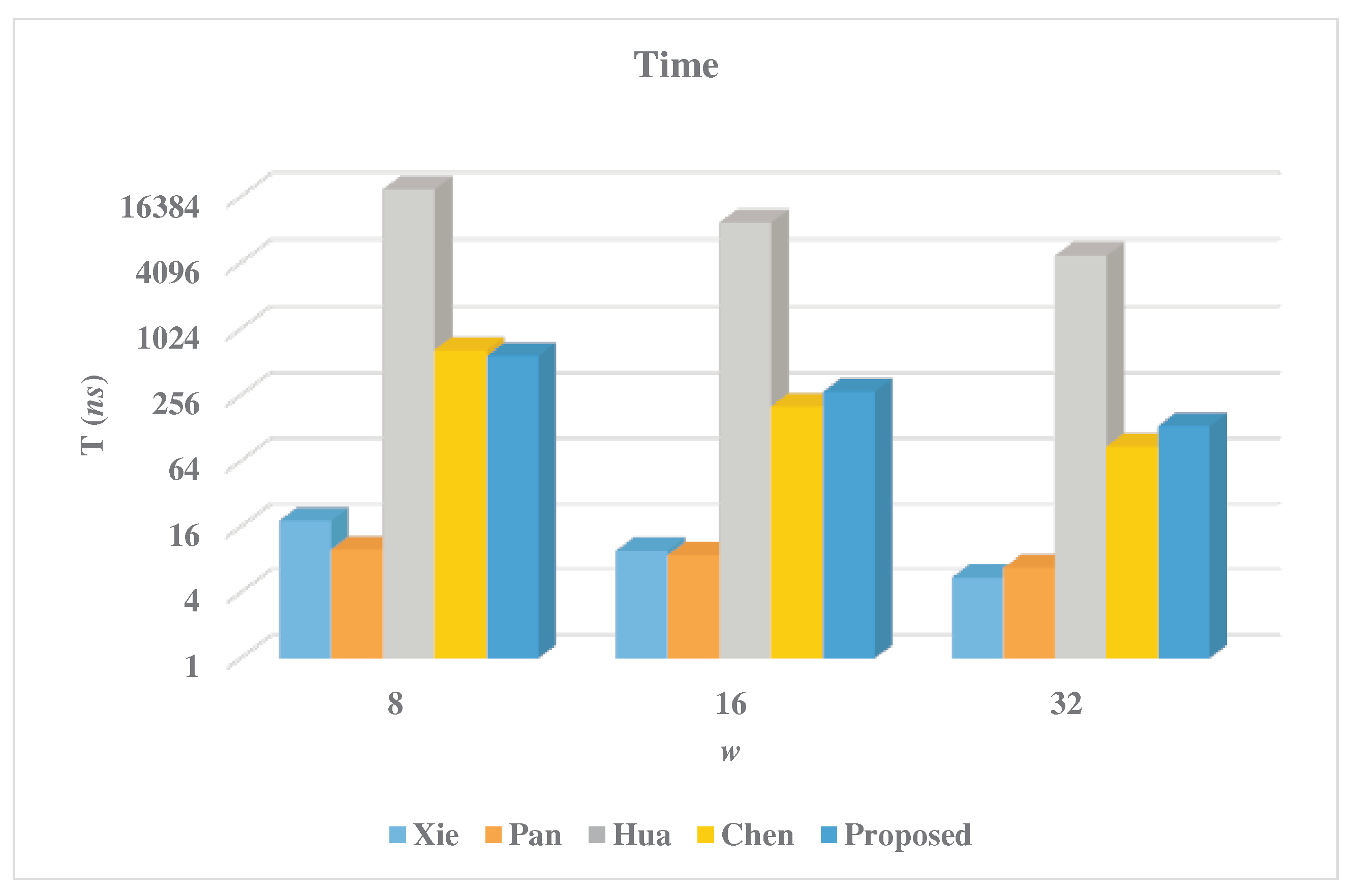
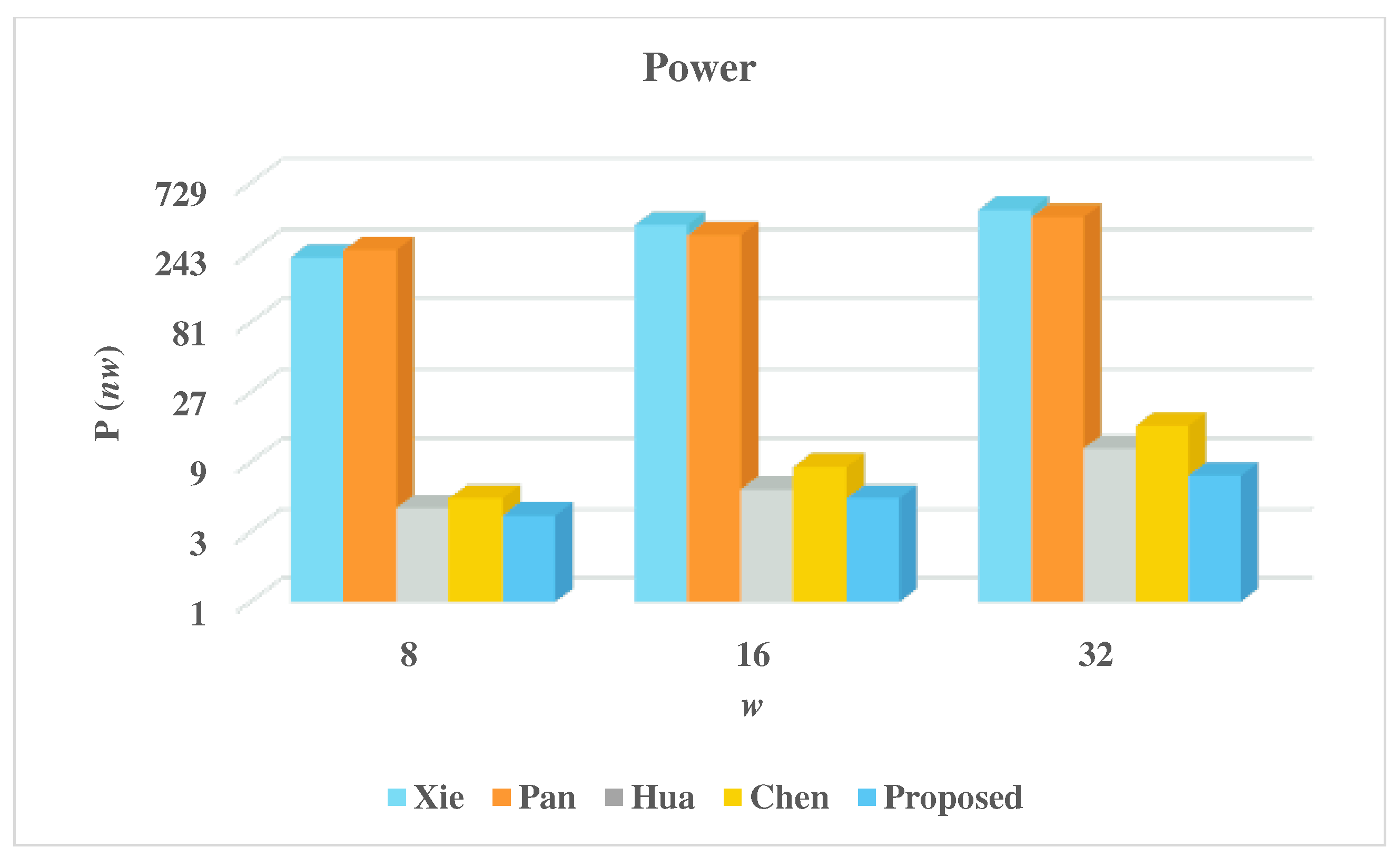
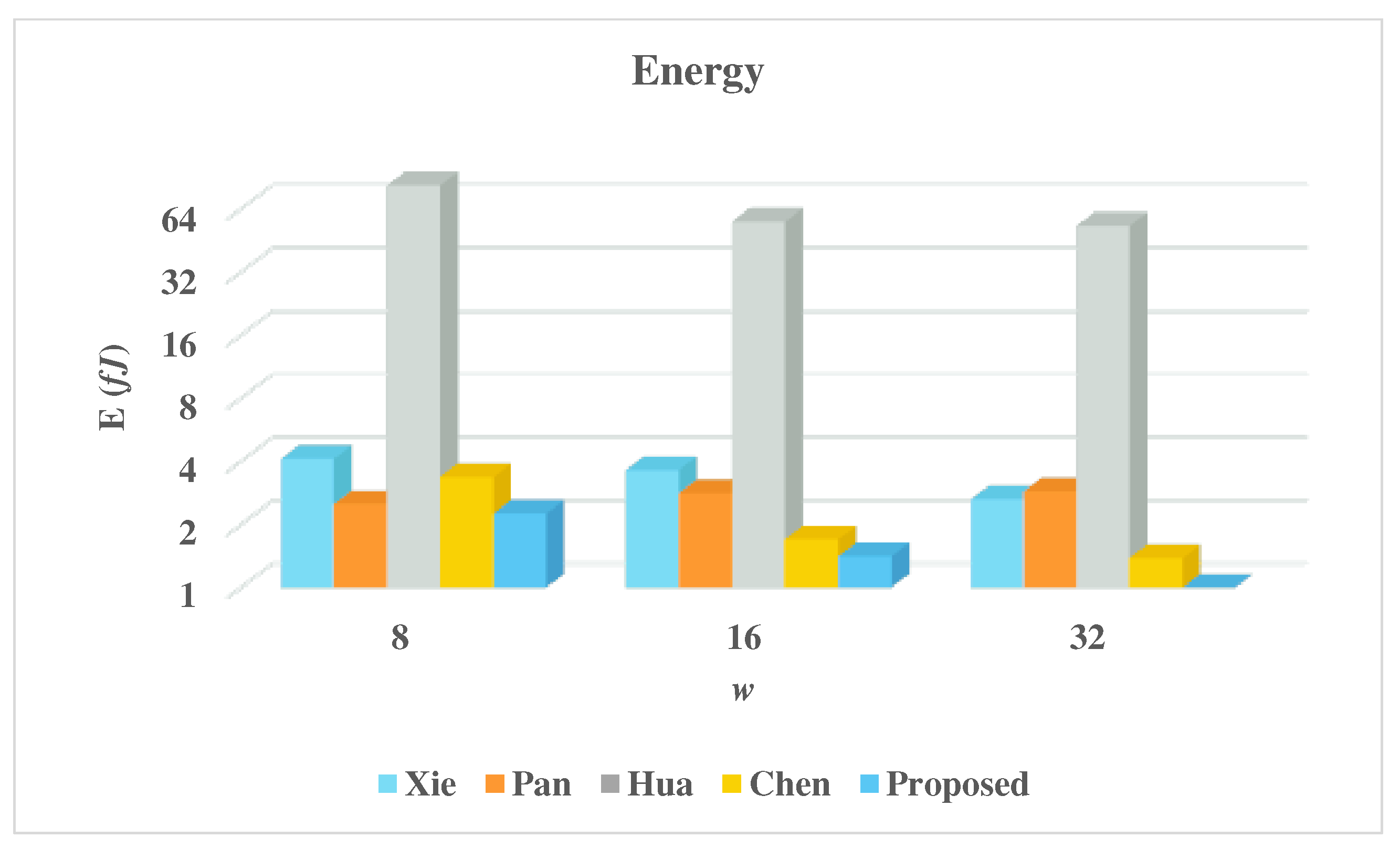
5. Experimental Results and Discussion
- Latency: is the total number of clock cycles needed to complete a single operation;
- Area (A): is the estimated design area in terms of the equivalent area of 2-input NAND gate;
- CPD: is the synthesized critical path delay;
- Time (T): is the total computation time required to complete a single operation;
- Power (P): is the consumed power obtained at 1 KHZ;
- Energy (E): is the consumed energy which obtained by multiplying power (P) by the total computation time (T).
6. Summary and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| IoT | Internet of Things; |
| RFID | Radio Frequency Identification; |
| ASIC | Application Specific Integrated Circuit; |
| RSA | Rivest, Shamir, and Adleman; |
| DSA | Digital Signature Algorithm; |
| ECC | Elliptic Curve Cryptography; |
| SISO | Serial-In/Serial-Out; |
| SIPO | Serial-In/Parallel-Out; |
| PISO | Parallel-In/Serial-Out; |
| RIA | Regular Iterative Algorithm; |
| CPD | Critical Path Delay. |
References
- Chen, D.; Zhang, N.; Qin, Z.; Mao, X.; Qin, Z.; Shen, X.; Li, X.Y. S2M: A lightweight acoustic fingerprints-based wireless device authentication protocol. IEEE Internet Things J. 2016, 4, 88–100. [Google Scholar] [CrossRef]
- Sowjanya, K.; Dasgupta, M.; Ray, S. An elliptic curve cryptography based enhanced anonymous authentication protocol for wearable health monitoring systems. Int. J. Inf. Secur. 2020, 19, 129–146. [Google Scholar] [CrossRef]
- Granjal, J.; Monteiro, E.; Silva, J.S. Security for the internet of things: A survey of existing protocols and open research issues. IEEE Commun. Surv. Tutor. 2015, 17, 1294–1312. [Google Scholar] [CrossRef]
- Safkhani, M.; Vasilakos, A. A new secure authentication protocol for telecare medicine information system and smart campus. IEEE Access 2019, 7, 23514–23526. [Google Scholar] [CrossRef]
- Aghili, S.F.; Mala, H.; Kaliyar, P.; Conti, M. Seclap: Secure and lightweight RFID authentication protocol for medical IoT. Future Gener. Comput. Syst. 2019, 101, 621–634. [Google Scholar] [CrossRef]
- Anajemba, J.H.; Iwendi, C.; Mittal, M.; Yue, T. Improved advance encryption standard with a privacy database structure for IoT nodes. In Proceedings of the 2020 IEEE 9th International Conference on Communication Systems and Network Technologies (CSNT), Gwalior, India, 10–12 April 2020; pp. 201–206. [Google Scholar]
- Anajemba, J.H.; Yue, T.; Iwendi, C.; Alenezi, M.; Mittal, M. Optimal cooperative offloading scheme for energy efficient multi-access edge computation. IEEE Access 2020, 8, 53931–53941. [Google Scholar] [CrossRef]
- Atzori, L.; Iera, A.; Morabito, G. The internet of things: A survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Rivest, R.L.; Shamir, A.; Adleman, L. A method for obtaining digital signatures and public-key cryptosystems. Mag. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef]
- Lidl, R.; Niederreiter, H. Introduction to Finite Fields and Their Applications; Cambridge University Press: Cambridge, UK, 1994. [Google Scholar]
- Chiou, C.W.; Lee, C.Y.; Deng, A.W.; Lin, J.M. Concurrent error detection in Montgomery multiplication over GF(2m). IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2006, E89-A, 566–574. [Google Scholar] [CrossRef]
- Kim, K.W.; Jeon, J.C. Polynomial Basis Multiplier Using Cellular Systolic Architecture. IETE J. Res. 2014, 60, 194–199. [Google Scholar] [CrossRef]
- Choi, S.; Lee, K. Efficient ssystolic modular multiplier/squarer for fast exponentiation over GF(2m). IEICE Electron. Express 2015, 12, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.W.; Kim, S.H. Efficient bit-parallel systolic architecture for multiplication and squaring over GF(2m). IEICE Electron. Express 2018, 15, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Kim, C.H.; Hong, C.P.; Kwon, S. A digit-serial multiplier for finite Field GF(2m). IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2005, 13, 476–483. [Google Scholar]
- Talapatra, S.; Rahaman, H.; Mathew, J. Low complexity digit serial systolic montgomery multipliers for special class of GF(2m). IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2010, 18, 847–852. [Google Scholar] [CrossRef]
- Guo, J.H.; Wang, C.L. Hardware-efficient Systolic Architecture for Inversion and Division in GF(2m). IEE Proc. Comput. Digit. Tech. 1998, 145, 272–278. [Google Scholar] [CrossRef]
- Pan, J.S.; Lee, C.Y.; Meher, P.K. Low-Latency Digit-Serial and Digit-Parallel Systolic Multipliers for Large Binary Extension Fields. IEEE Trans. Circ. Syst.-I 2013, 60, 3195–3204. [Google Scholar] [CrossRef]
- Lee, C.Y.; Fan, C.C.; Yuan, S.M. New Digit-Serial Three-Operand Multiplier over Binary Extension Fields for High-Performance Applications. In Proceedings of the 2017 2nd IEEE International Conference on Computational Intelligence and Applications, Beijing, China, 8–11 September 2017; pp. 498–502. [Google Scholar]
- Hariri, A.; Reyhani-Masoleh, A. Digit-serial structures for the shifted polynomial basis multiplication over binary extension fields. In Proc. LNCS Intl Workshop Arithmetic of Finite Fields (WAIFI); Springer: Berlin/Heidelberg, Germany, 2008; pp. 103–116. [Google Scholar]
- Kumar, S.; Wollinger, T.; Paar, C. Optimum digit serial multipliers for curve-based cryptography. IEEE Trans. Comput. 2006, 55, 1306–1311. [Google Scholar] [CrossRef]
- Lee, C.Y. Super digit-serial systolic multiplier over GF(2m). In Proceedings of the 6th International Conference Genetic Evolutionary Computing, Kitakyushu, Japan, 25–28 August 2012; pp. 509–513. [Google Scholar]
- Xie, J.; Meher, P.K.; Mao, Z. Low-latency high-throughput systolic multipliers over GF(2m) for NIST recommended pentanomials. IEEE Trans. Circuits Syst. 2015, 62, 881–890. [Google Scholar] [CrossRef]
- Namin, A.H.; Wu, H.; Ahmadi, M. A word-level finite field multiplier using normal basis. IEEE Trans. Comput. 2011, 60, 890–895. [Google Scholar] [CrossRef]
- Lee, C.Y.; Chiou, C.W.; Lin, J.M.; Chang, C.C. Scalable and systolic Montgomery multiplier over generated by trinomials. IET Circuits Devices Syst. 2007, 1, 477–484. [Google Scholar] [CrossRef]
- Chen, L.H.; Chang, P.L.; Lee, C.Y.; Yang, Y.K. Scalable and systolic dual basis multiplier Over GF(2m). Int. J. Innov. Comput. Inf. Control 2011, 7, 1193–1208. [Google Scholar]
- Orlando, G.; Paar, C. A super-serial galois fields multiplier for FPGAs and its application to public-key algorithms. In Proceedings of the IEEE Symposium Field-Programmable Custom Computing, Napa Valley, CA, USA, 23 April 1999; pp. 232–239. [Google Scholar]
- Bayat-Sarmadi, S.; Kermani, M.M.; Azarderakhsh, R.; Lee, C.Y. Dual Basis Super-Serial Mult. for Secure Applications and Lightweight Cryptographic Arch. IEEE Trans. Circ. Syst.-II 2014, 61, 125–129. [Google Scholar]
- Gebali, F.; Ibrahim, A. Efficient Scalable Serial Multiplier Over GF(2m) Based on Trinomial. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2015, 23, 2322–2326. [Google Scholar] [CrossRef]
- Ibrahim, A.; Gebali, F.; El-Simary, H.; Nassar, A. High-performance, low-power architecture for scalable radix 2 Montgomery modular multiplication algorithm. IEEE Can. J. Electr. Comput. Eng. 2009, 34, 152–157. [Google Scholar] [CrossRef]
- Ibrahim, A.; Gebali, F. Scalable and Unified Digit-Serial Processor Array Architecture for Multiplication and Inversion over GF(2m). IEEE Trans. Circuits Syst. I Regul. Pap. 2017, 22, 2894–2906. [Google Scholar] [CrossRef]
- Kim, K.W.; Lee, J.D. Efficient unified semi-systolic arrays for multiplication and squaring over GF(2m). IEICE Electron. Express 2017, 14, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Gebali, F. Algorithms and Parallel Computers; John Wiley: New York, NY, USA, 2011. [Google Scholar]
- Ibrahim, A.; Elsimary, H.; Gebali, F. New systolic array architecture for finite field division. IEICE Electronics Express 2018, 15, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, A.; Elsimary, H.; Aljumah, A.; Gebali, F. Reconfigurable hardware accelerator for profile hidden Markov models. Arabian J. Sci. Eng. 2016, 41, 3267–3277. [Google Scholar] [CrossRef]
- Ibrahim, A. Scalable digit-serial processor array architecture for finite field division. Microelectron. J. 2019, 85, 83–91. [Google Scholar] [CrossRef]
- Ibrahim, A.; Alsomani, T.; Gebali, F. Unified Systolic Array Architecture for Field Multiplication and Inversion Over GF(2m). Comput. Electr. Eng. J.-Elsevier 2017, 61, 104–115. [Google Scholar] [CrossRef]
- Ibrahim, A.; Alsomani, T.; Gebali, F. New Systolic Array Architecture for Finite Field Inversion. IEEE Can. J. Electr. Comput. Eng. 2017, 40, 23–30. [Google Scholar]
- Gebali, F.; Ibrahim, A. Low space-complexity and low power semi-systolic multiplier architectures over GF(2m) based on irreducible trinomial. Microprocess. Microsyst. 2016, 40, 45–52. [Google Scholar] [CrossRef]
- Hua, Y.Y.; Lin, J.M.; Chiou, C.W.; Lee, C.Y.; Liu, Y.H. Low space-complexity digit-serial dual basis systolic multiplier over Galois field GF (2m) using Hankel matrix and Karatsuba algorithm. IET Inf. Secur. 2013, 7, 75–86. [Google Scholar]
- Chen, C.C.; Lee, C.Y.; Lu, E.H. Scalable and Systolic Montgomery Multipliers Over GF(2m). IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2008, E91-A, 1763–1771. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Design | Tri-State | AND | XOR | MUXs | Flip-Flops | Latency | CPD |
|---|---|---|---|---|---|---|---|
| Xie [23] | 0 | 0 | |||||
| Pan [18] | 0 | 0 | |||||
| Hua [40] | 0 | 0 | |||||
| Chen [41] | 0 | ||||||
| Proposed | w |
| Multiplier | w | Latency | Area (A) | CPD | Time (T) | Power (P) | Energy (E) |
|---|---|---|---|---|---|---|---|
| (Kgates) | (ps) | (ns) | (nW) | (fJ) | |||
| Xie [23] | 8 | 324 | 92.98 | 56.4 | 18.27 | 225.56 | 4.12 |
| 16 | 172 | 146.96 | 56.4 | 9.70 | 375.5 | 3.64 | |
| 32 | 98 | 195.13 | 56.4 | 5.53 | 477.4 | 2.64 | |
| Pan [18] | 8 | 48 | 97.46 | 206.3 | 9.90 | 252.91 | 2.50 |
| 16 | 36 | 123.93 | 244.4 | 8.80 | 320.07 | 2.82 | |
| 32 | 24 | 164.34 | 282.5 | 6.78 | 425.09 | 2.88 | |
| Hua [40] | 8 | 259,584 | 7.99 | 73.4 | 19053.47 | 4.35 | 82.88 |
| 16 | 129,792 | 10.40 | 73.4 | 9526.73 | 5.85 | 55.73 | |
| 32 | 64896 | 19.91 | 73.4 | 4763.37 | 11.15 | 53.11 | |
| Chen [41] | 8 | 11946 | 10.16 | 55.2 | 659.42 | 5.11 | 3.37 |
| 16 | 3678 | 13.51 | 55.2 | 203.03 | 8.38 | 1.70 | |
| 32 | 1572 | 26.58 | 55.2 | 86.77 | 15.95 | 1.38 | |
| Proposed | 8 | 2705 | 7.26 | 215.7 | 583.47 | 3.88 | 2.26 |
| 16 | 677 | 9.19 | 407.7 | 276.01 | 5.12 | 1.41 | |
| 32 | 170 | 15.78 | 791.7 | 134.59 | 7.28 | 0.98 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ibrahim, A.; Gebali, F. Word-Based Systolic Processor for Field Multiplication and Squaring Suitable for Cryptographic Processors in Resource-Constrained IoT Systems. Electronics 2021, 10, 1777. https://doi.org/10.3390/electronics10151777
Ibrahim A, Gebali F. Word-Based Systolic Processor for Field Multiplication and Squaring Suitable for Cryptographic Processors in Resource-Constrained IoT Systems. Electronics. 2021; 10(15):1777. https://doi.org/10.3390/electronics10151777
Chicago/Turabian StyleIbrahim, Atef, and Fayez Gebali. 2021. "Word-Based Systolic Processor for Field Multiplication and Squaring Suitable for Cryptographic Processors in Resource-Constrained IoT Systems" Electronics 10, no. 15: 1777. https://doi.org/10.3390/electronics10151777
APA StyleIbrahim, A., & Gebali, F. (2021). Word-Based Systolic Processor for Field Multiplication and Squaring Suitable for Cryptographic Processors in Resource-Constrained IoT Systems. Electronics, 10(15), 1777. https://doi.org/10.3390/electronics10151777