
Straightforward Heterogeneous Computing with the oneAPI Coexecutor Runtime



Abstract
:1. Introduction
- Providing Intel oneAPI with co-execution capabilities, squeezing the capacity of the heterogeneous system to exploit a single kernel.
- Implementing a set of load-balancing algorithms that allow efficient use of all devices in the system, both with regular and irregular applications.
- Validating the co-execution runtime in terms of the performance, balancing efficiency, scalability, and energy efficiency for a set of benchmarks and schedulers.
2. Background
2.1. Platform Model
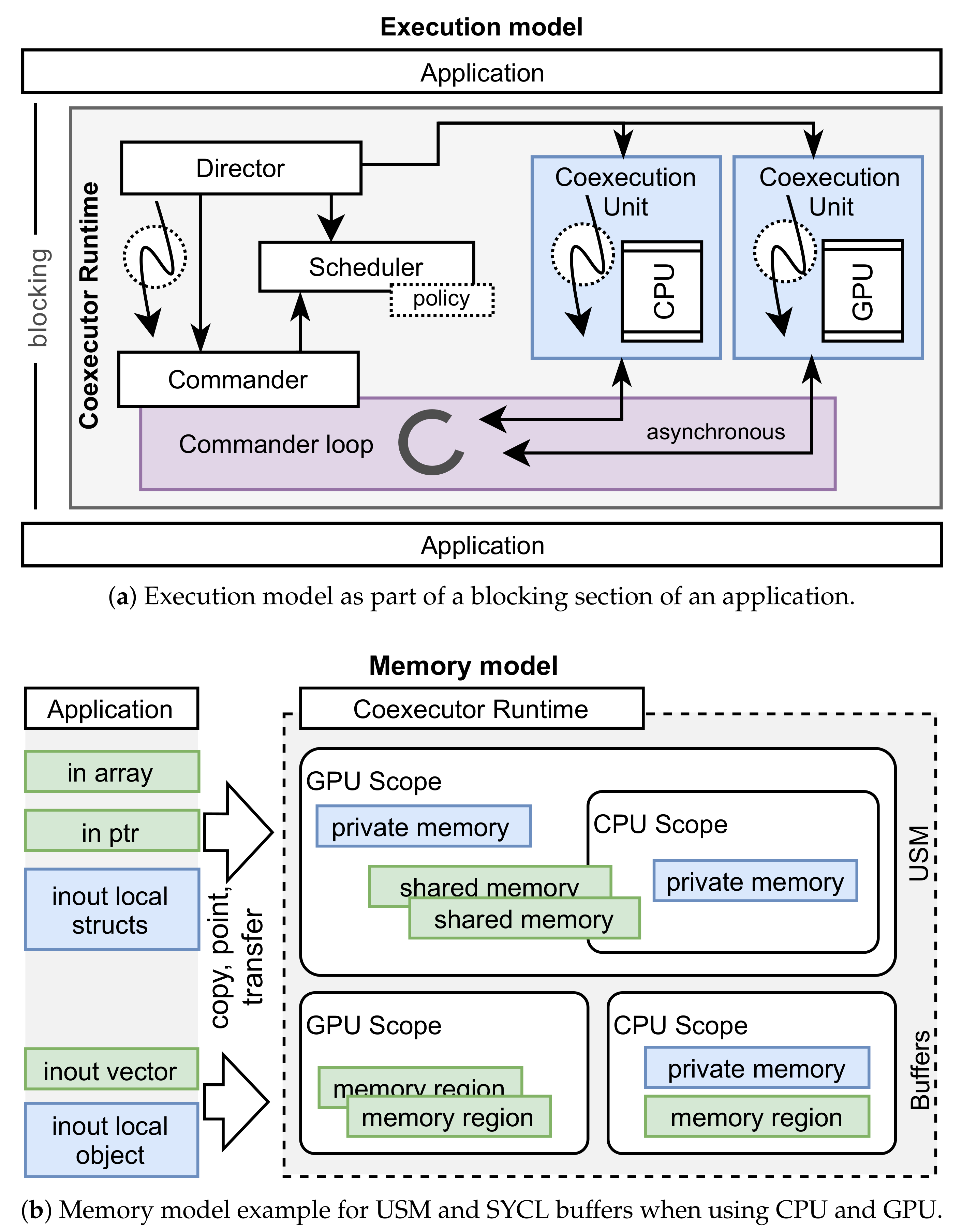
2.2. Execution Model
2.3. Memory Model
2.4. Kernel Programming Model
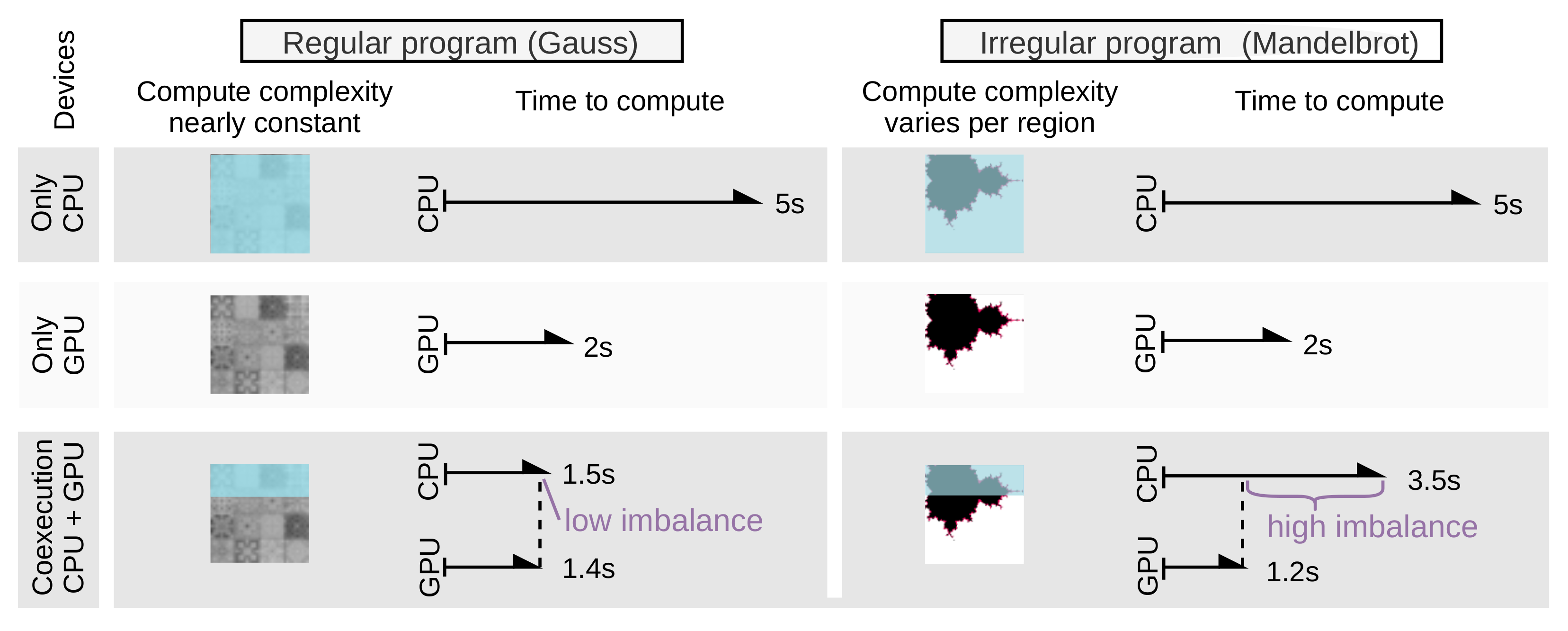
3. Motivation
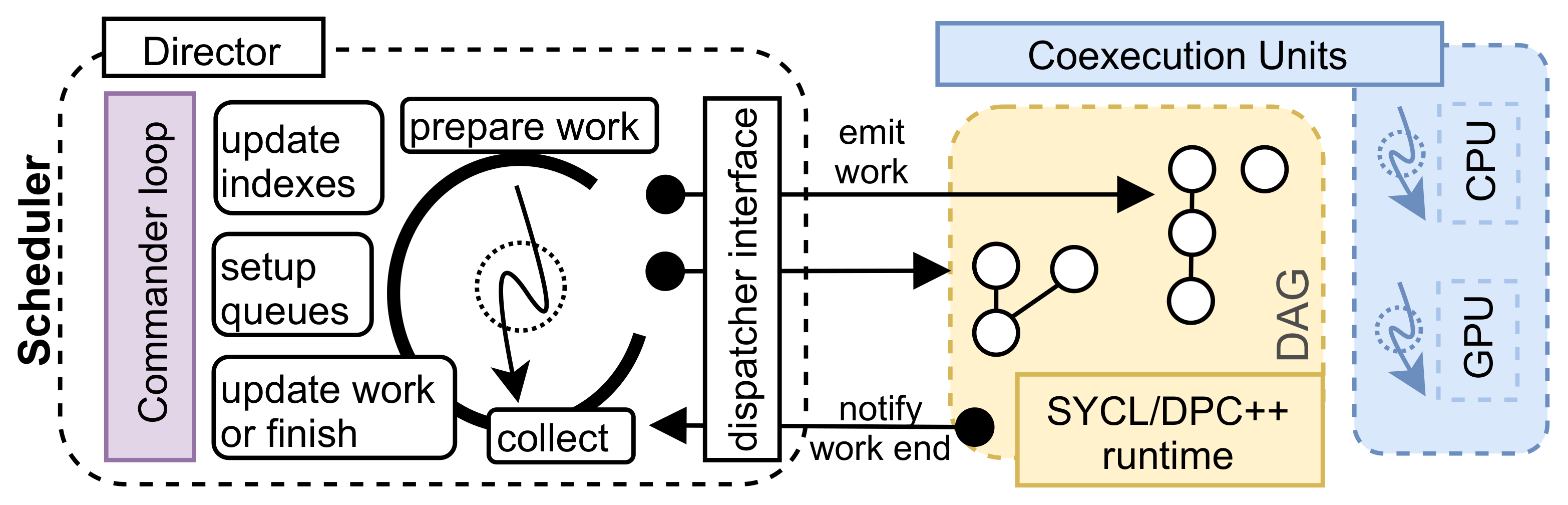
4. OneAPI Coexecutor Runtime
4.1. Static Co-Execution
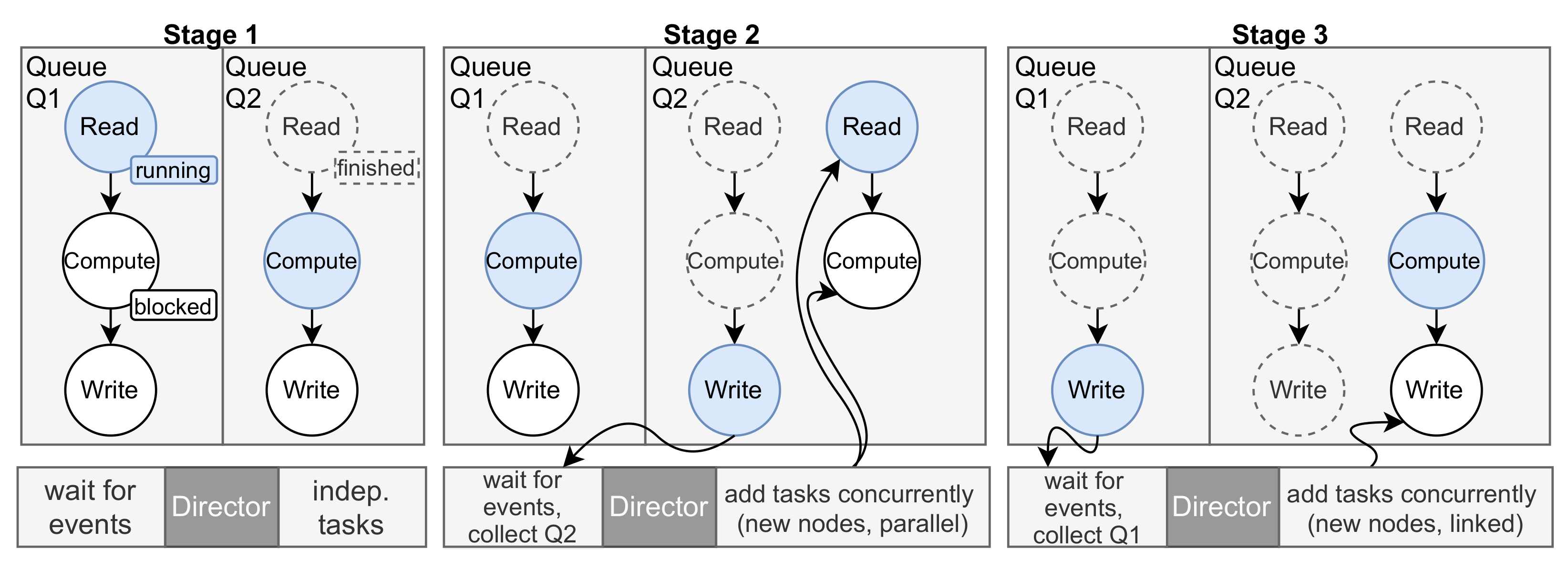
4.2. Dynamic Co-Execution
4.3. Load Balancing Algorithms
4.4. API Design
| Listing 1. Coexecutor Runtime computing SAXPY with a dynamic algorithm using simultaneously CPU and GPU |
 |
| Listing 2. SAXPY program definition using the CommanderKernel interface provided by Coexecutor Runtime to implement the kernel behavior as an independent unit. |
 |
| Listing 3. Coexecutor Runtime using the CPU and GPU simultaneously to compute the SAXPY kernel definition of the Listing 2. This example shows the exploitation of the extended computation mode to enhance the flexibility of the runtime. |
 |
5. Methodology
6. Validation
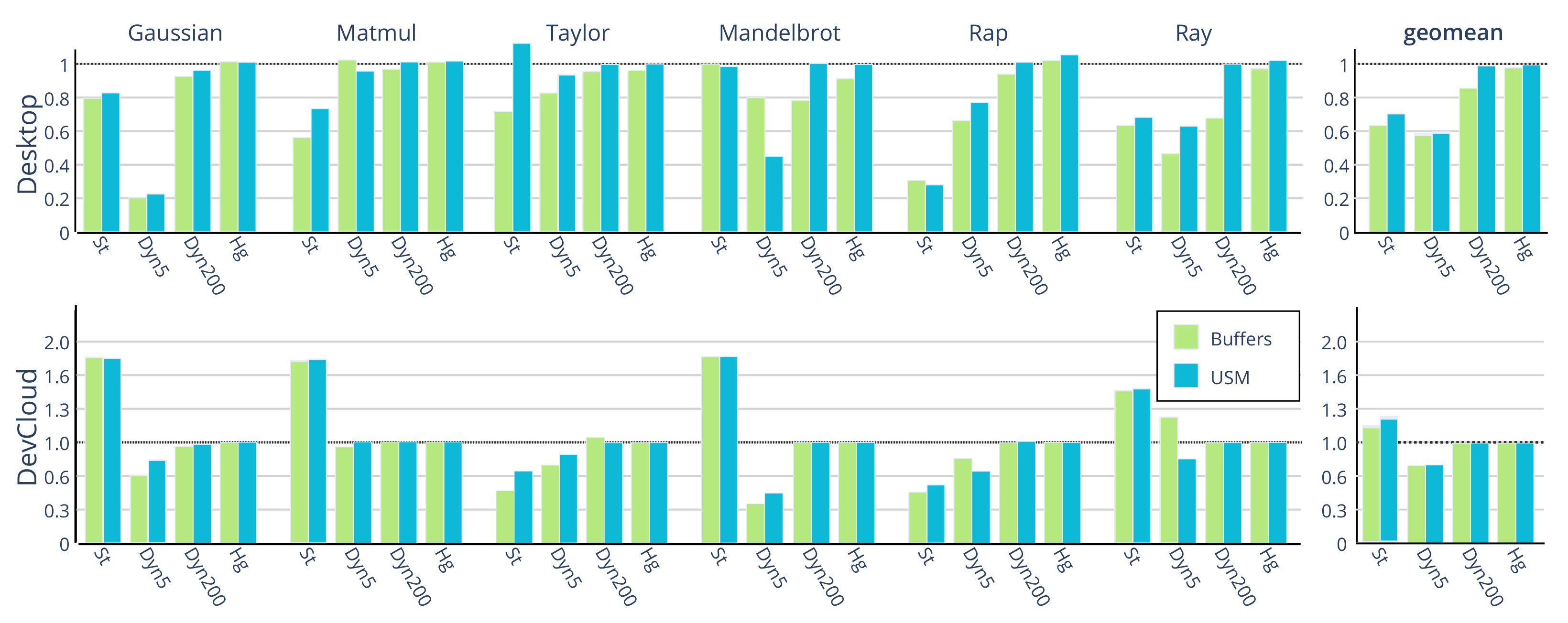
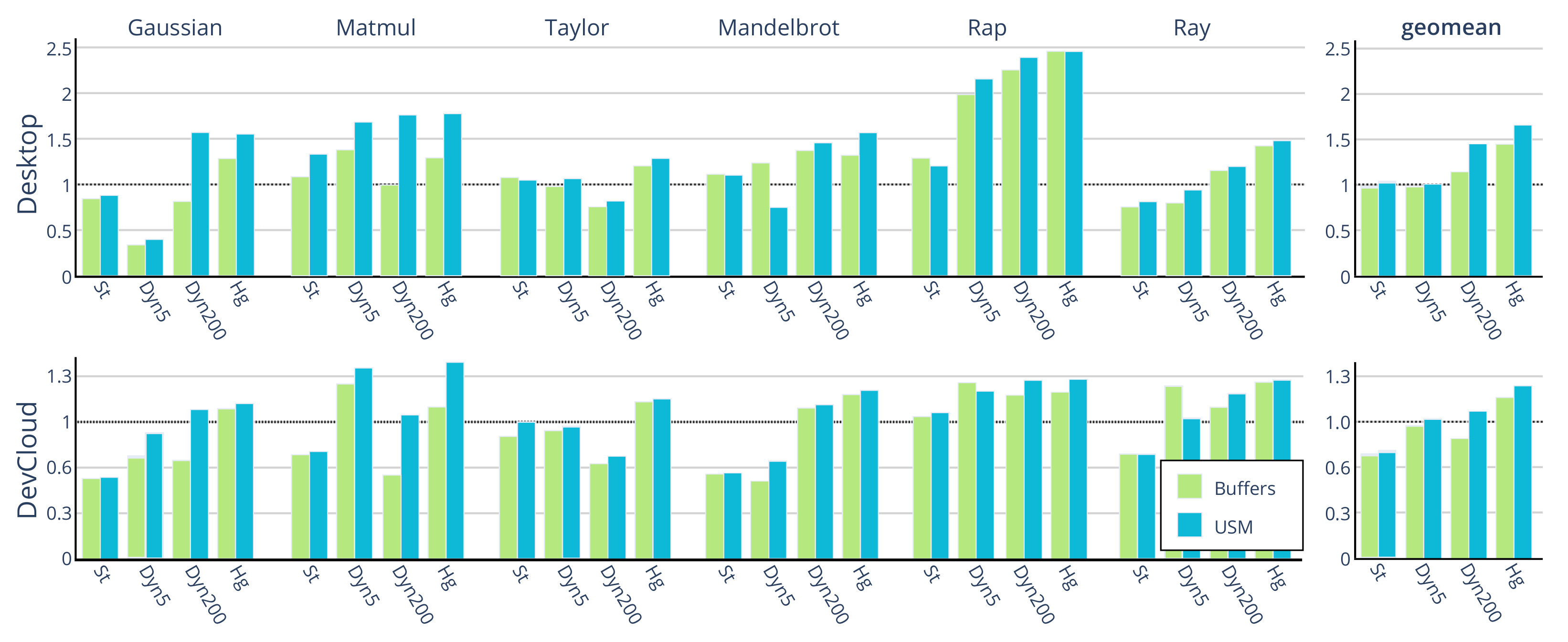
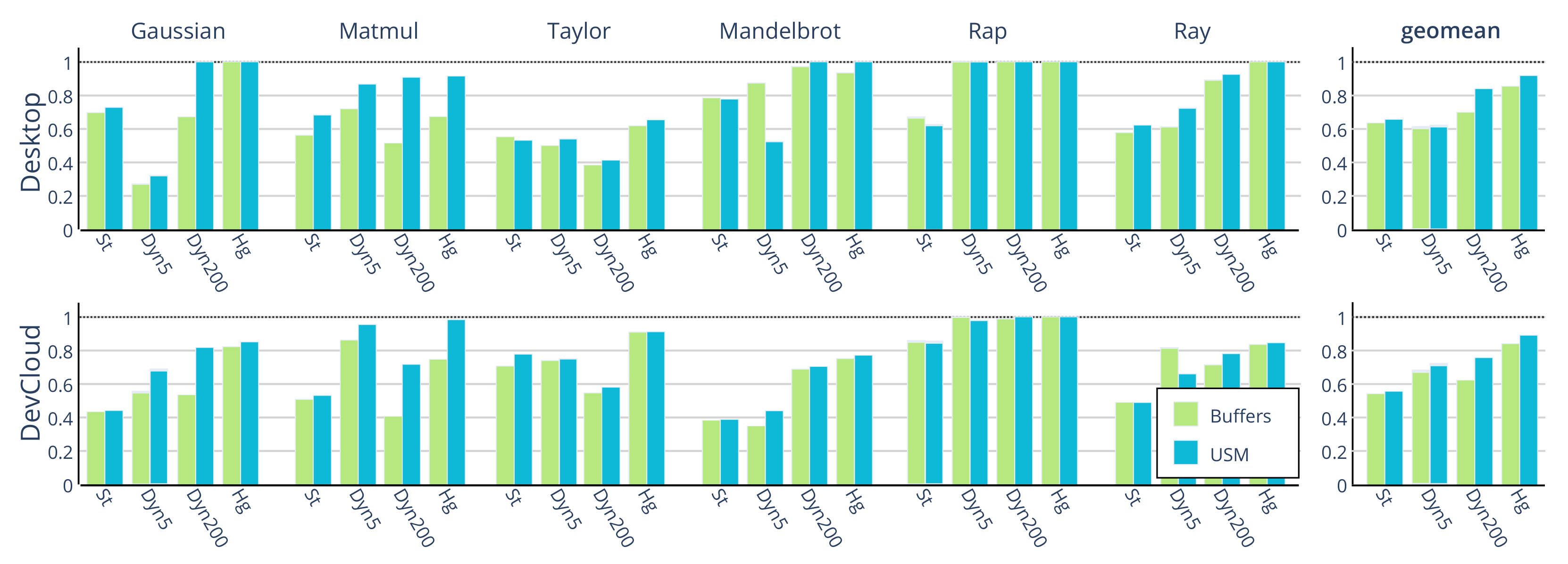
6.1. Performance
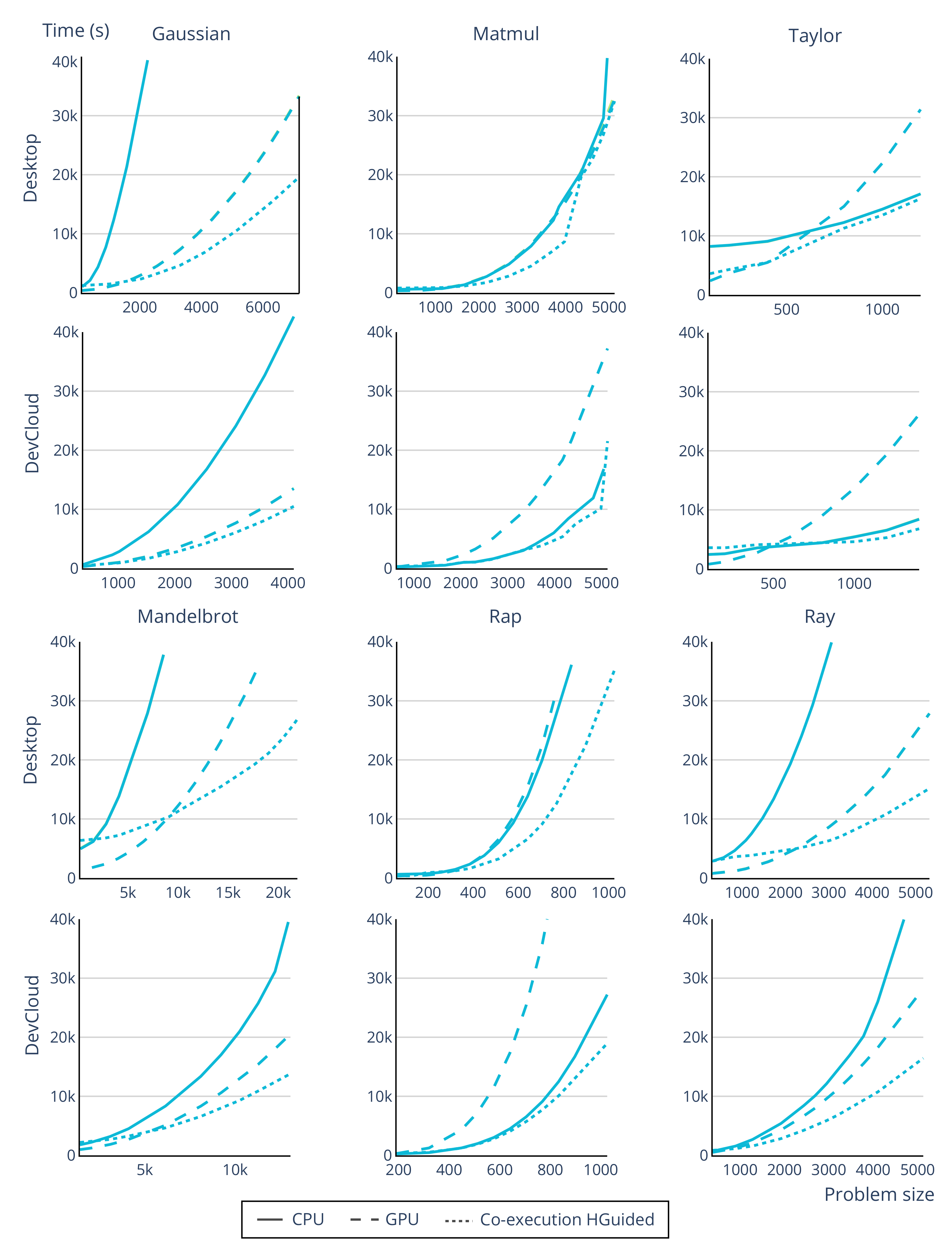
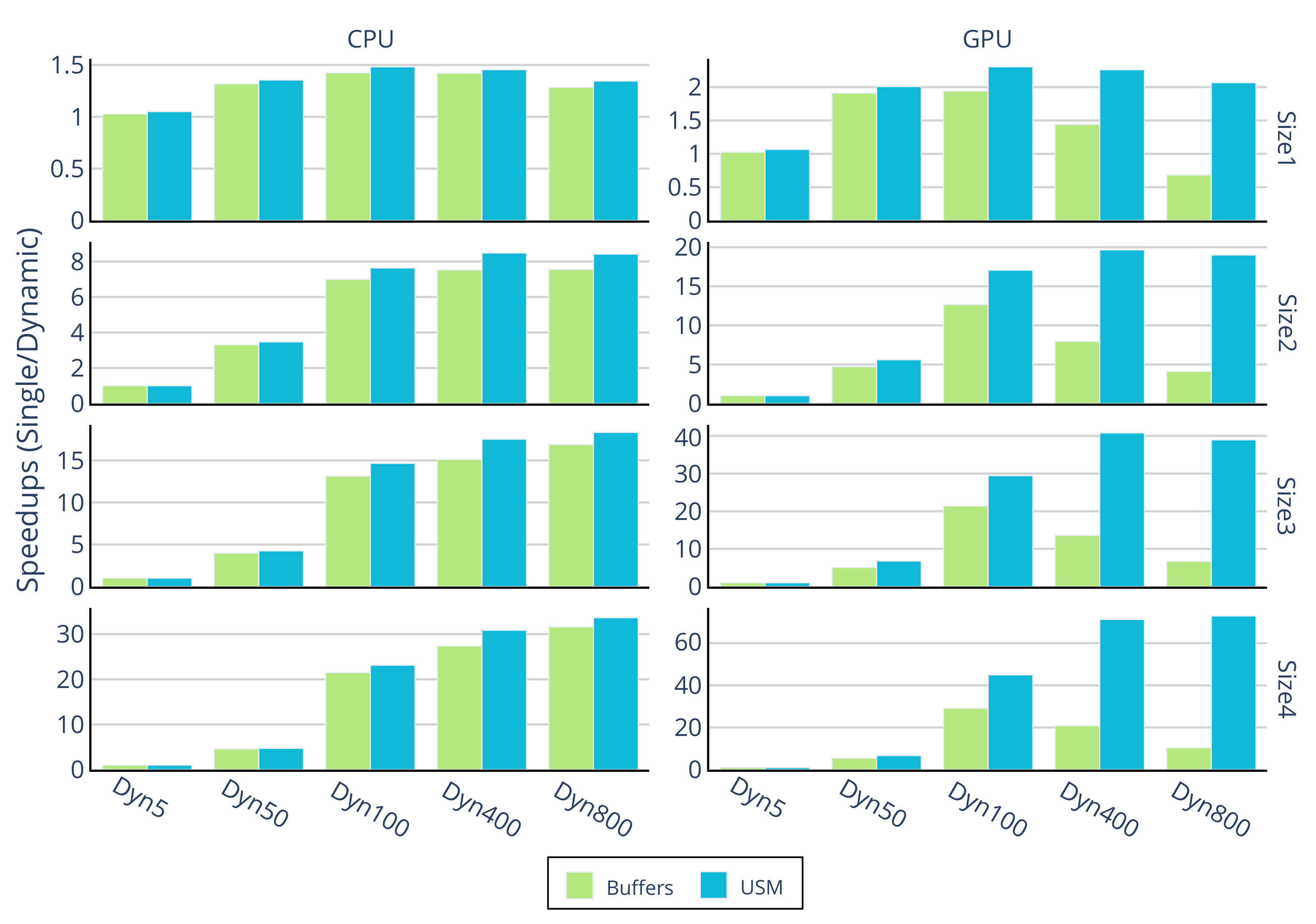
6.2. Scalability
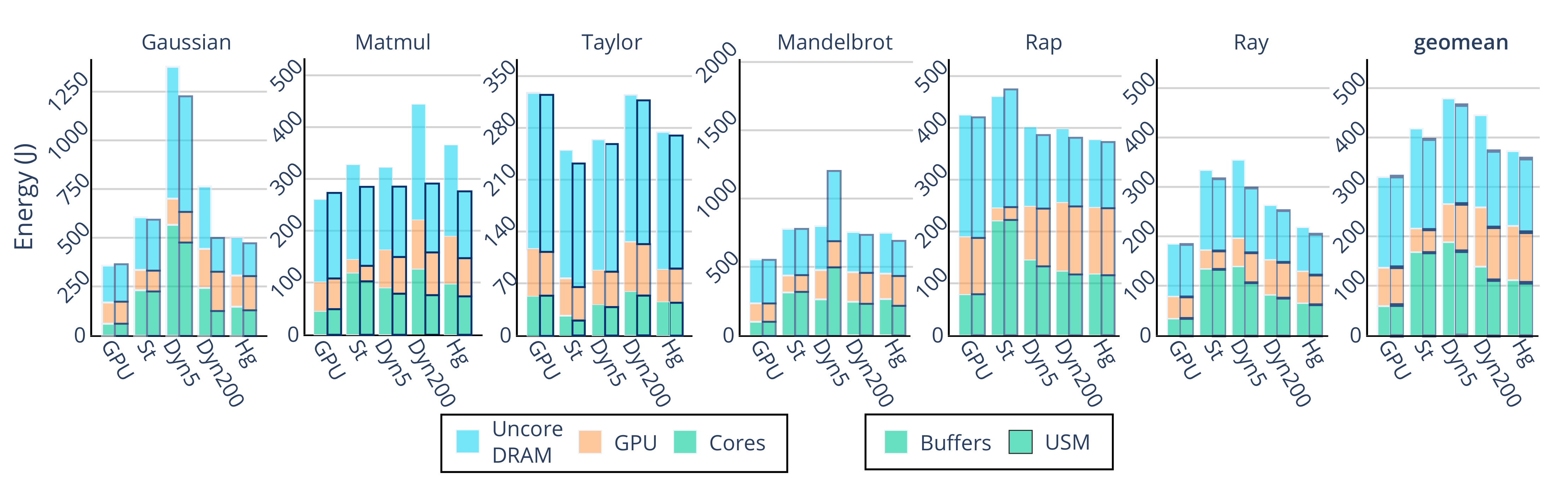
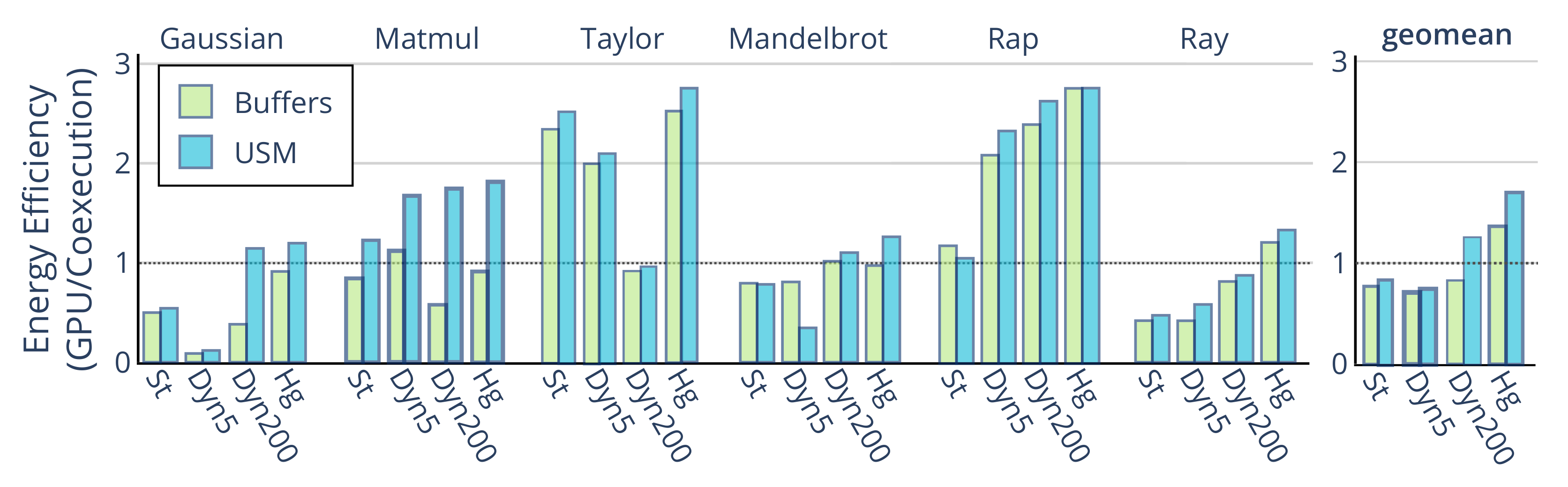
6.3. Energy
6.4. NBoby Benchmark
7. Related Work
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zahran, M. Heterogeneous Computing: Here to Stay. Commun. ACM 2017, 60, 42–45. [Google Scholar] [CrossRef]
- Lin, F.C.; Huy, N.H.; Dow, C.R. A cloud-based face video retrieval system with deep learning. J. Supercomput. 2020, 76, 8473–8493. [Google Scholar] [CrossRef]
- Robles, O.D.; Bosque, J.L.; Pastor, L.; Rodríguez, A. Performance Analysis of a CBIR System on Shared-Memory Systems and Heterogeneous Clusters. In Proceedings of the Seventh International Workshop on Computer Architecture for Machine Perception, Palermo, Italy, 4–6 July 2005; IEEE Computer Society: Piscataway, NJ, USA, 2005; pp. 309–314. [Google Scholar] [CrossRef]
- Wang, Y.; Zhou, Y.; Wang, Q.S.; Wang, Y.; Xu, Q.; Wang, C.; Peng, B.; Zhu, Z.; Takuya, K.; Wang, D. Developing medical ultrasound beamforming application on GPU and FPGA using oneAPI. In Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Portland, OR, USA, 17–21 June 2021; pp. 360–370. [Google Scholar]
- Costero, L.; Igual, F.D.; Olcoz, K.; Tirado, F. Leveraging knowledge-as-a-service (KaaS) for QoS-aware resource management in multi-user video transcoding. J. Supercomput. 2020, 76, 9388–9403. [Google Scholar] [CrossRef]
- Toharia, P.; Robles, O.D.; Suárez, R.; Bosque, J.L.; Pastor, L. Shot boundary detection using Zernike moments in multi-GPU multi-CPU architectures. J. Parallel Distrib. Comput. 2012, 72, 1127–1133. [Google Scholar] [CrossRef]
- Castillo, E.; Camarero, C.; Borrego, A.; Bosque, J.L. Financial applications on multi-CPU and multi-GPU architectures. J. Supercomput. 2015, 71, 729–739. [Google Scholar] [CrossRef]
- Wang, X.; Gan, L.; Liu, S. Research on intelligence analysis technology of financial industry data based on genetic algorithm. J. Supercomput. 2020, 76, 3391–3401. [Google Scholar] [CrossRef]
- Shin, W.; Yoo, K.H.; Baek, N. Large-Scale Data Computing Performance Comparisons on SYCL Heterogeneous Parallel Processing Layer Implementations. Appl. Sci. 2020, 10, 1656. [Google Scholar] [CrossRef] [Green Version]
- Mrozek, M.; Ashbaugh, B.; Brodman, J. Taking Memory Management to the Next Level: Unified Shared Memory in Action. In Proceedings of the International Workshop on OpenCL, Munich, Germany, 27–29 April 2020. [Google Scholar] [CrossRef]
- Pérez, B.; Bosque, J.L.; Beivide, R. Simplifying programming and load balancing of data parallel applications on heterogeneous systems. In Proceedings of the 9th Annual Workshop on General Purpose Processing using Graphics Processing Unit, Barcelona, Spain, 12 March 2016; pp. 42–51. [Google Scholar]
- Pérez, B.; Stafford, E.; Bosque, J.L.; Beivide, R. Energy efficiency of load balancing for data-parallel applications in heterogeneous systems. J. Supercomput. 2017, 73, 330–342. [Google Scholar] [CrossRef]
- Beri, T.; Bansal, S.; Kumar, S. The Unicorn Runtime: Efficient Distributed Shared Memory Programming for Hybrid CPU-GPU Clusters. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 1518–1534. [Google Scholar] [CrossRef]
- Nozal, R.; Bosque, J.L.; Beivide, R. EngineCL: Usability and Performance in Heterogeneous Computing. Future Gener. Comput. Syst. 2020, 107, 522–537. [Google Scholar] [CrossRef] [Green Version]
- Augonnet, C.; Thibault, S.; Namyst, R.; Wacrenier, P.A. StarPU: A unified platform for task scheduling on heterogeneous multicore architectures. Concurr. Comput. Pract. Exp. 2011, 23, 187–198. [Google Scholar] [CrossRef] [Green Version]
- Gautier, T.; Lima, J.; Maillard, N.; Raffin, B. XKaapi: A Runtime System for Data-Flow Task Programming on Heterogeneous Architectures. In Proceedings of the 2013 IEEE 27th International Symposium on Parallel and Distributed Processing, Cambridge, MA, USA, 20–24 May 2013; pp. 1299–1308. [Google Scholar]
- Nozal, R.; Perez, B.; Bosque, J.L.; Beivide, R. Load balancing in a heterogeneous world: CPU-Xeon Phi co-execution of data-parallel kernels. J. Supercomput. 2019, 75, 1123–1136. [Google Scholar] [CrossRef]
- Gaster, B.R.; Howes, L.W.; Kaeli, D.R.; Mistry, P.; Schaa, D. Heterogeneous Computing with OpenCL-Revised OpenCL 1.2 Edation; Morgan Kaufmann: Burlington, MA, USA, 2013. [Google Scholar]
- Farber, R. Parallel Programming with OpenACC, 1st ed.; Morgan Kaufmann Publishers: San Francisco, CA, USA, 2016. [Google Scholar]
- Vitali, E.; Gadioli, D.; Palermo, G.; Beccari, A.; Cavazzoni, C.; Silvano, C. Exploiting OpenMP and OpenACC to accelerate a geometric approach to molecular docking in heterogeneous HPC nodes. J. Supercomput. 2019, 75, 3374–3396. [Google Scholar] [CrossRef]
- Ronan, K. Modern C++, Heterogeneous Computing & OpenCL SYCL. 2015. Available online: https://www.iwocl.org/wp-content/uploads/iwocl-2015-tutorial-SYCL-part2.pdf (accessed on 15 August 2021).
- Da Silva, H.C.; Pisani, F.; Borin, E. A Comparative Study of SYCL, OpenCL, and OpenMP. In Proceedings of the 2016 International Symposium on Computer Architecture and High Performance Computing Workshops (SBAC-PADW), Los Angeles, CA, USA, 26–28 October 2016; pp. 61–66. [Google Scholar] [CrossRef]
- Szuppe, J. Boost. In Compute: A Parallel Computing Library for C++ Based on OpenCL. In Proceedings of the 4th International Workshop on OpenCL, Vienna, Austria, 19–21 April 2016. [Google Scholar] [CrossRef]
- Corporation, I. Intel® oneAPI Programming Guide; 2020. Available online: https://software.intel.com/content/www/us/en/develop/documentation/oneapi-programming-guide/top.html (accessed on 15 August 2021).
- Ashbaugh, B.; Bader, A.; Brodman, J.; Hammond, J.; Kinsner, M.; Pennycook, J.; Schulz, R.; Sewall, J. Data Parallel C++: Enhancing SYCL Through Extensions for Productivity and Performance. In Proceedings of the International Workshop on OpenCL, Munich, Germany, 27–29 April 2020. [Google Scholar] [CrossRef]
- Zhang, F.; Zhai, J.; He, B.; Zhang, S.; Chen, W. Understanding Co-Running Behaviors on Integrated CPU/GPU Architectures. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 905–918. [Google Scholar] [CrossRef]
- Shen, J.; Varbanescu, A.L.; Lu, Y.; Zou, P.; Sips, H. Workload Partitioning for Accelerating Applications on Heterogeneous Platforms. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 2766–2780. [Google Scholar] [CrossRef]
- Nozal, R.; Bosque, J.L.; Beivide, R. Towards Co-execution on Commodity Heterogeneous Systems: Optimizations for Time-Constrained Scenarios. In Proceedings of the 2019 International Conference on High Performance Computing &Simulation (HPCS), Dublin, Ireland, 15–19 July 2019; pp. 628–635. [Google Scholar]
- Nozal, R.; Bosque, J.L. Exploiting Co-execution with OneAPI: Heterogeneity from a Modern Perspective. In Euro-Par 2021: Parallel Processing; Sousa, L., Roma, N., Tomás, P., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 501–516. [Google Scholar]
- Dávila Guzmán, M.A.; Nozal, R.; Gran Tejero, R.; Villarroya-Gaudó, M.; Suárez Gracia, D.; Bosque, J.L. Cooperative CPU, GPU, and FPGA heterogeneous execution with EngineCL. J. Supercomput. 2019, 75, 1732–1746. [Google Scholar] [CrossRef]
- Bosque, J.L.; Perez, L.P. Theoretical scalability analysis for heterogeneous clusters. In Proceedings of the 4th IEEE/ACM International Symposium on Cluster Computing and the Grid (CCGrid 2004), Chicago, IL, USA, 19–22 April 2004; IEEE Computer Society: Piscataway, NJ, USA, 2004; pp. 285–292. [Google Scholar] [CrossRef]
- Jin, Z. The Rodinia Benchmark Suite in SYCL; Technical Report; Argonne National Lab. (ANL): Lemont, IL, USA, 2020. [Google Scholar]
- Christgau, S.; Steinke, T. Porting a Legacy CUDA Stencil Code to oneAPI. In Proceedings of the 2020 IEEE International Parallel and Distributed Processing Symposium Workshops, New Orleans, LA, USA, 18–22 May 2020; pp. 359–367. [Google Scholar]
- Jin, Z.; Morozov, V.; Finkel, H. A Case Study on the HACCmk Routine in SYCL on Integrated Graphics. In Proceedings of the 2020 IEEE International Parallel and Distributed Processing Symposium Workshops, New Orleans, LA, USA, 18–22 May 2020; pp. 368–374. [Google Scholar] [CrossRef]
- Aktemur, B.; Metzger, M.; Saiapova, N.; Strasuns, M. Debugging SYCL Programs on Heterogeneous Intel® Architectures. In Proceedings of the International Workshop on OpenCL, Munich, Germany, 27–29 April 2020. [Google Scholar] [CrossRef]
- Tibrewala, S.; Faria, A.D.O. Making Banking Secure via Bio Metrics Application Built Using OneAPI and DPC++ Based on SYCL/C++. In Proceedings of the International Workshop on OpenCL, Munich, Germany, 27–29 April 2020. [Google Scholar] [CrossRef]
- Constantinescu, D.A.; Navarro, A.G.; Corbera, F.; Fernández-Madrigal, J.A.; Asenjo, R. Efficiency and productivity for decision making on low-power heterogeneous CPU+GPU SoCs. J. Supercomput. 2021, 77, 44–65. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property | Gauss | Matmul | Taylor | Ray | Rap | Mandel | NBody |
|---|---|---|---|---|---|---|---|
| Local Work Size | 128 | 1.64 | 64 | 128 | 128 | 256 | 64 |
| Read:Write buffers | 2:1 | 2:1 | 3:2 | 1:1 | 2:1 | 0:1 | 2:2 |
| Kernel args | 6 | 5 | 7 | 11 | 4 | 8 | 7 |
| Use local memory | no | yes | yes | yes | no | no | no |
| Work-items (N ) | 262 | 237 | 10 | 94 | 5 | 703 | 4 |
| Mem. usage (MiB) | 195 | 264 | 46 | 35 | 6 | 1072 | 26 |
| Use custom types | no | no | no | yes | no | no | no |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nozal, R.; Bosque, J.L. Straightforward Heterogeneous Computing with the oneAPI Coexecutor Runtime. Electronics 2021, 10, 2386. https://doi.org/10.3390/electronics10192386
Nozal R, Bosque JL. Straightforward Heterogeneous Computing with the oneAPI Coexecutor Runtime. Electronics. 2021; 10(19):2386. https://doi.org/10.3390/electronics10192386
Chicago/Turabian StyleNozal, Raúl, and Jose Luis Bosque. 2021. "Straightforward Heterogeneous Computing with the oneAPI Coexecutor Runtime" Electronics 10, no. 19: 2386. https://doi.org/10.3390/electronics10192386
APA StyleNozal, R., & Bosque, J. L. (2021). Straightforward Heterogeneous Computing with the oneAPI Coexecutor Runtime. Electronics, 10(19), 2386. https://doi.org/10.3390/electronics10192386