Achieving Balanced Load Distribution with Reinforcement Learning-Based Switch Migration in Distributed SDN Controllers





Abstract
:1. Introduction
- We enhance the switch migration decision-making scheme by considering various types of resource utilization of controllers and a switch to migrate as an input state of the RL model to cope with changed correlation among resource types;
- We efficiently consider all possible cases of migration with relatively small action sizes (i.e., the number of controllers) by modeling the switches as RL agents in the proposed scheme;
- We conduct the performance evaluation of our proposed scheme and other competing schemes on stochastic and various environment settings. We evaluate SAR-LB in two network conditions (i.e., with/without bursty network traffic) and five cases with different numbers of switches and controllers. The results show that our scheme performs better when the number of switches is much larger than the number of controllers, and this confirms that our SAR-LB is well suited to the common data center where the controller manages more than dozens of switches [19,20,21,22].
2. Background
2.1. Switch Migration in Load Balancing of Distributed SDN Controllers
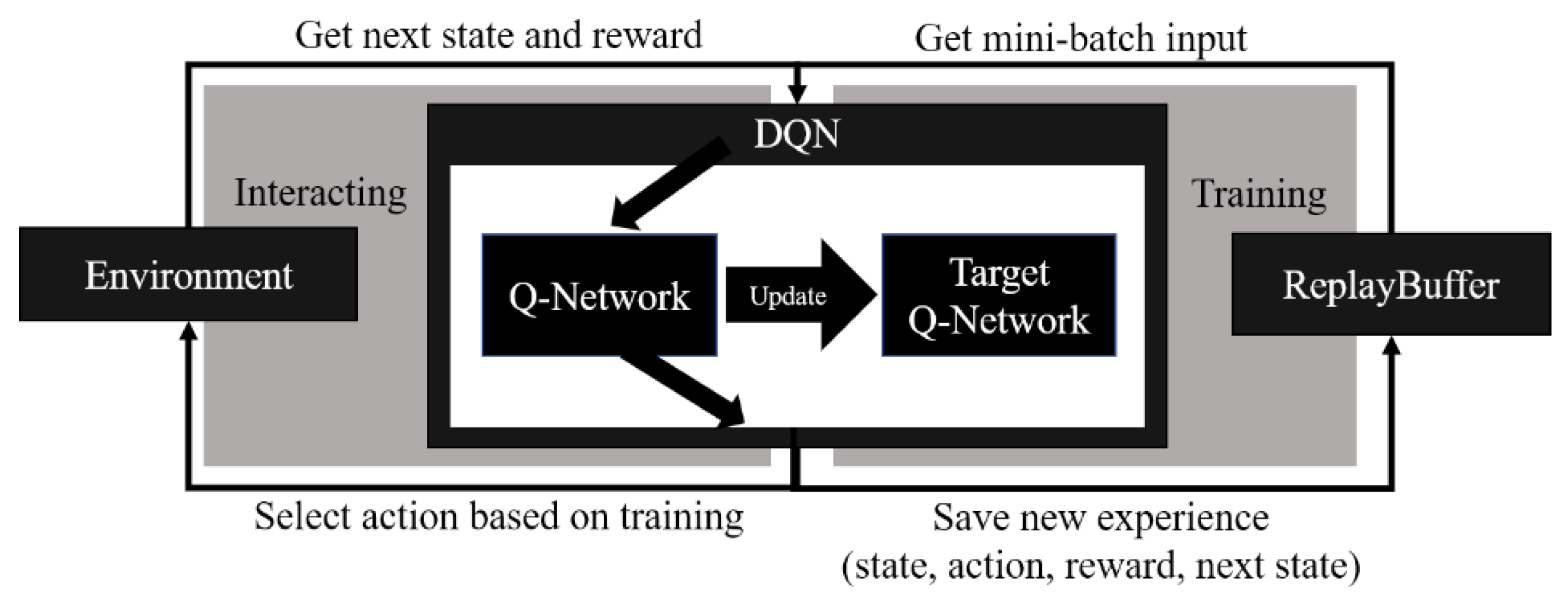
2.2. Reinforcement Learning
| Algorithm 1 DQN |
| Input: ReplayBuffer: data store for saving experience (i.e., state, reward, next state, action, done) Q: the neural network which is directly trained for the approximate value of actions in each state, target Q: the neural network which is trained through the Q neural network for stable training, EPISODE_NUM: total number of episodes, STEP_NUM: total step numbers in each episode 1. 2. for i in range (EPISODE_NUM): 3. for j in range (STEP_NUM): 4. Select by -decay policy 5. Send to the environment and get and by 6. if (j == STEP_NUM-1): 7. = True 8. else: 9. = False 10. Store experience (,,,,) in ReplayBuffer 11. if learning start < : 12. Sample random experiences (, , , , ) as 13. if () 14. 15. else; 16. 17. Optimize a Q network by loss . 18. if target Q model update frequency % == 0: 19. Apply weight parameter of Q to target Q 20. |
3. Related Works
3.1. Switch Migration Schemes for Load Balancing in SDN Environment
3.2. Reinforcement Learning-Based Load Balancing in SDN Environment
4. Design of SAR-LB
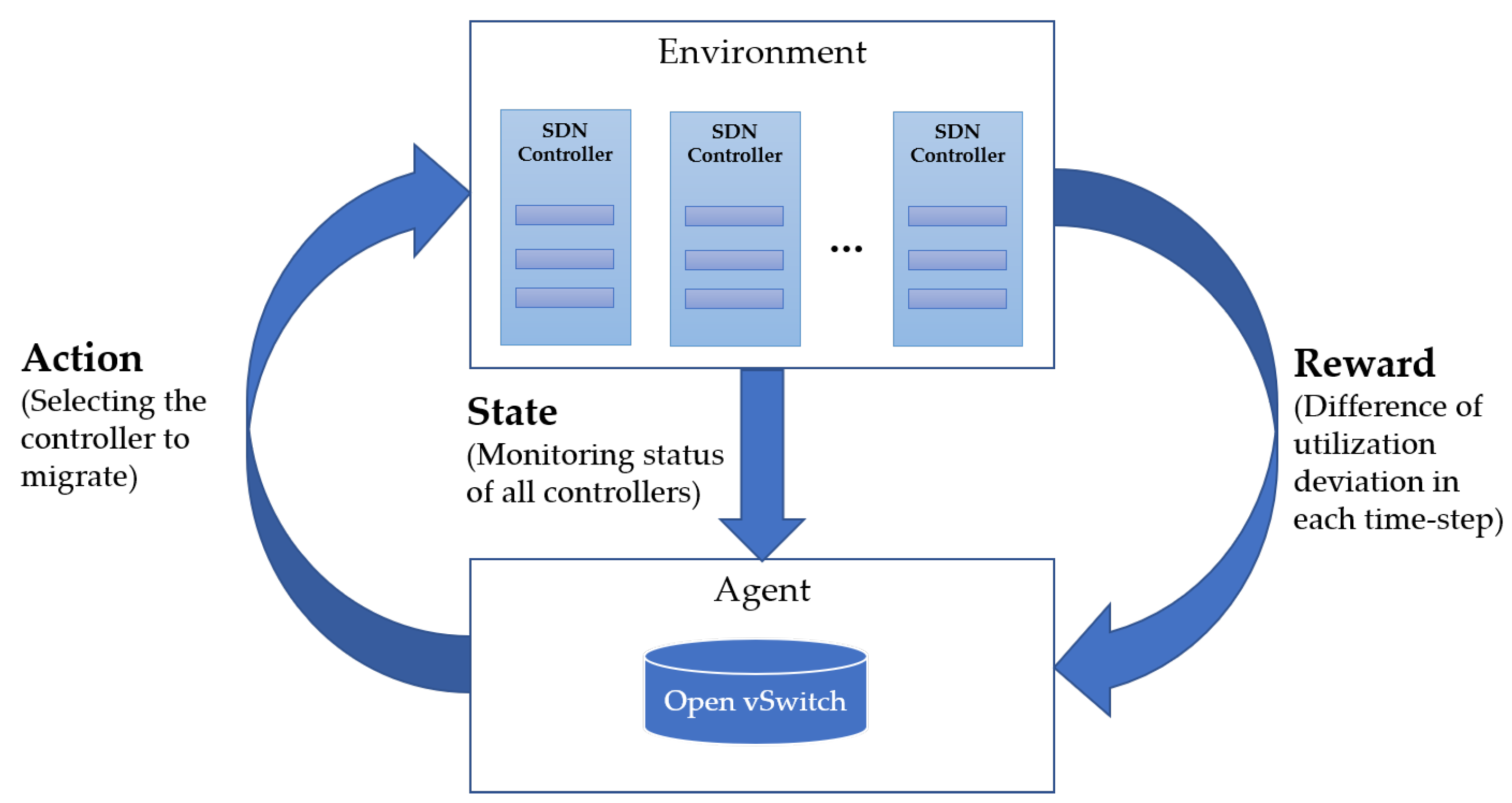
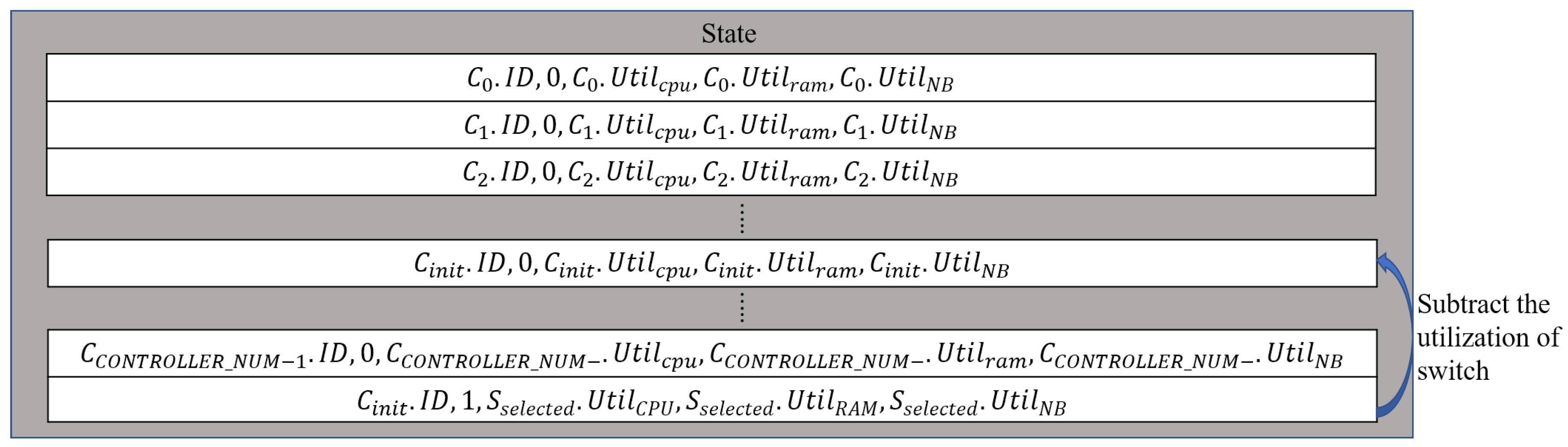
4.1. The Definition of RL Communication Channel for Switch Migration
4.2. Training and Working Phases of SAR-LB
| Algorithm 2 Training phase of SAR-LB |
| Input: ReplayBuffer: the memory space for saving previous experiences EPISODE_NUM: the number of episodes, STEP_NUM: the number of steps, CONTROLLER_NUM: the number of controllers in the SDN environment, SWITCH_NUM: the number of switches in the SDN environment, Output: switch migration decision 1. for i in range (EPISODE_NUM): 2. Initialize SDN environment and get initial state with CONTROLLER_NUM and SWITCH_NUM 3. Select migration target switch, randomly in the overutilized controller 4. Append information of migration target switch on initial state as shown in equation (1) 5. for j in range (STEP_NUM): 6. Select destination controller (i.e., action), by DQN agent with epsilon greedy policy 7. Migrate target switch, based on selected controller, 8. Get next state, and reward, from SDN environment 9. Save experience (, , ) on ReplayBuffer 10. Select next target switch for migration, randomly in the overutilized controller 11. Append information for on next_state as shown in Equation (1) 12. Next state, assigns to current state, 13. Sampling experience from ReplayBuffer 14. Train DQN agent by sampled experience//which is equal to line 11–19 in algorithm 1 15. end for 16. end for |
| Algorithm 3 Working phase of SAR-LB |
| Input: Ci: Controller i, ,, : CPU utilization, RAM utilization, and network bandwidth utilization of Ci : total resource utilization rate, : switch j from Ci, CONTROLLER_NUM: the number of controllers in SDN environment, Output: Load balanced controllers 1. Set list for of all controllers 2. for i in range (CONTROLLER_NUM): 3. Append each utilization of controller in in 4. end for 5. Find in which has maximum resource utilization 6. Set list for rewards of switches in , 7. for in : 8. Get reward, by selected action, of the agent for switch, based on current input state 9. Append reward in 10. end for 11. Find action (i.e., destination controller), actionmaxwhich has maximum reward, 12. Migrate target switch which have maximum reward action to target controller, actionmax |
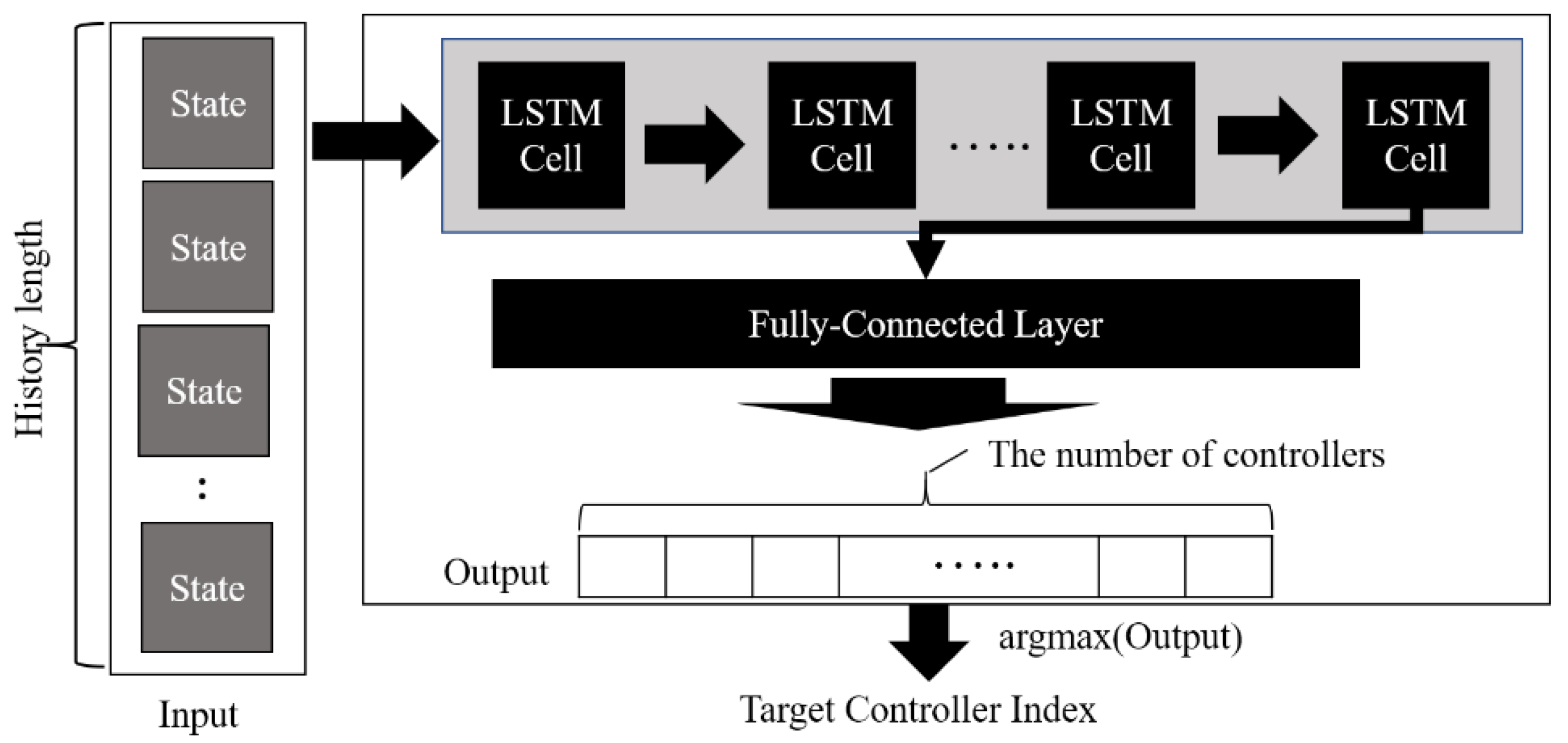
4.3. DNN Model for DQN Agent
5. Evaluation and Results
5.1. Experimental Environment
5.2. Competing Schemes to Evaluate with SAR-LB
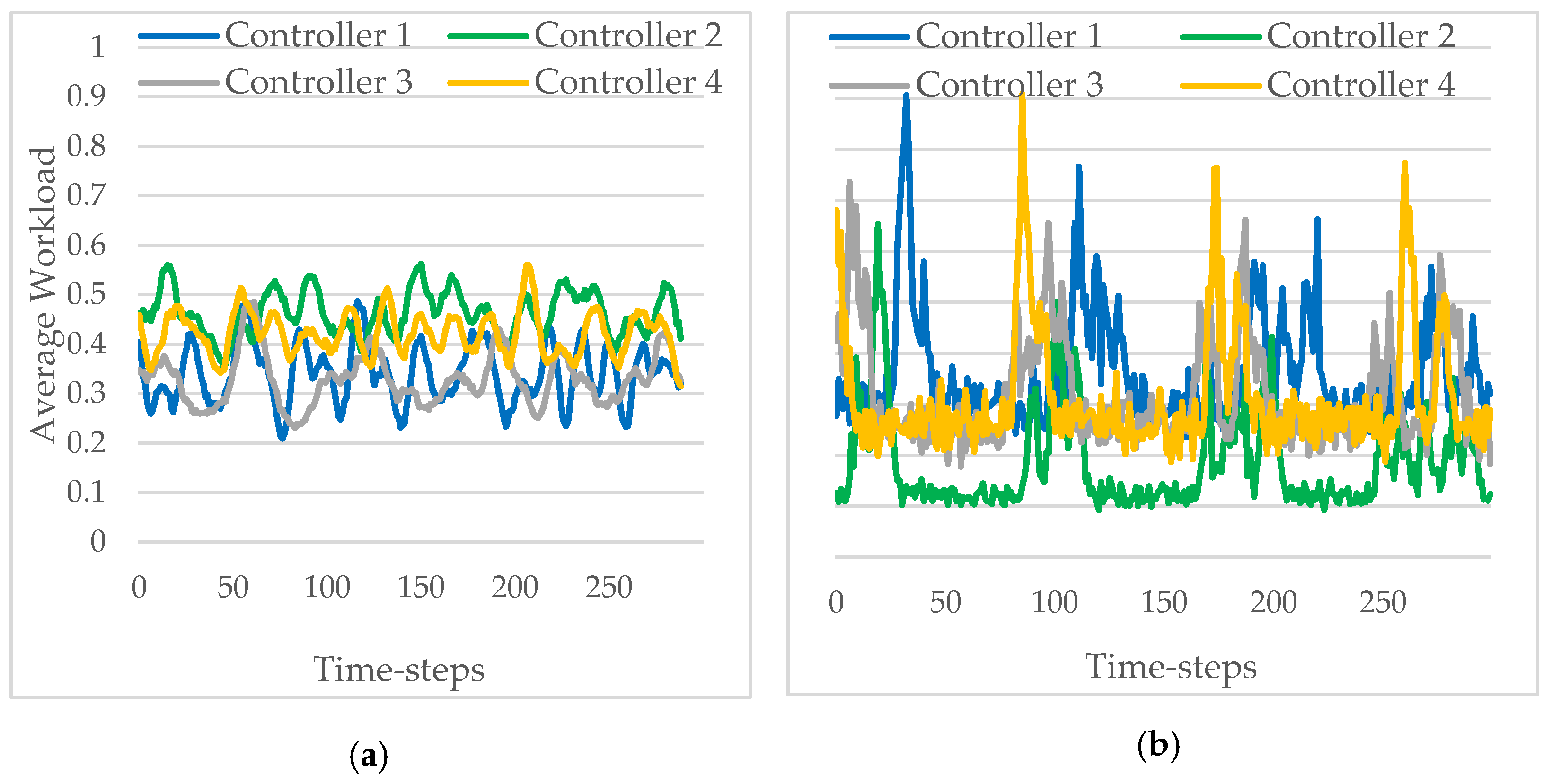
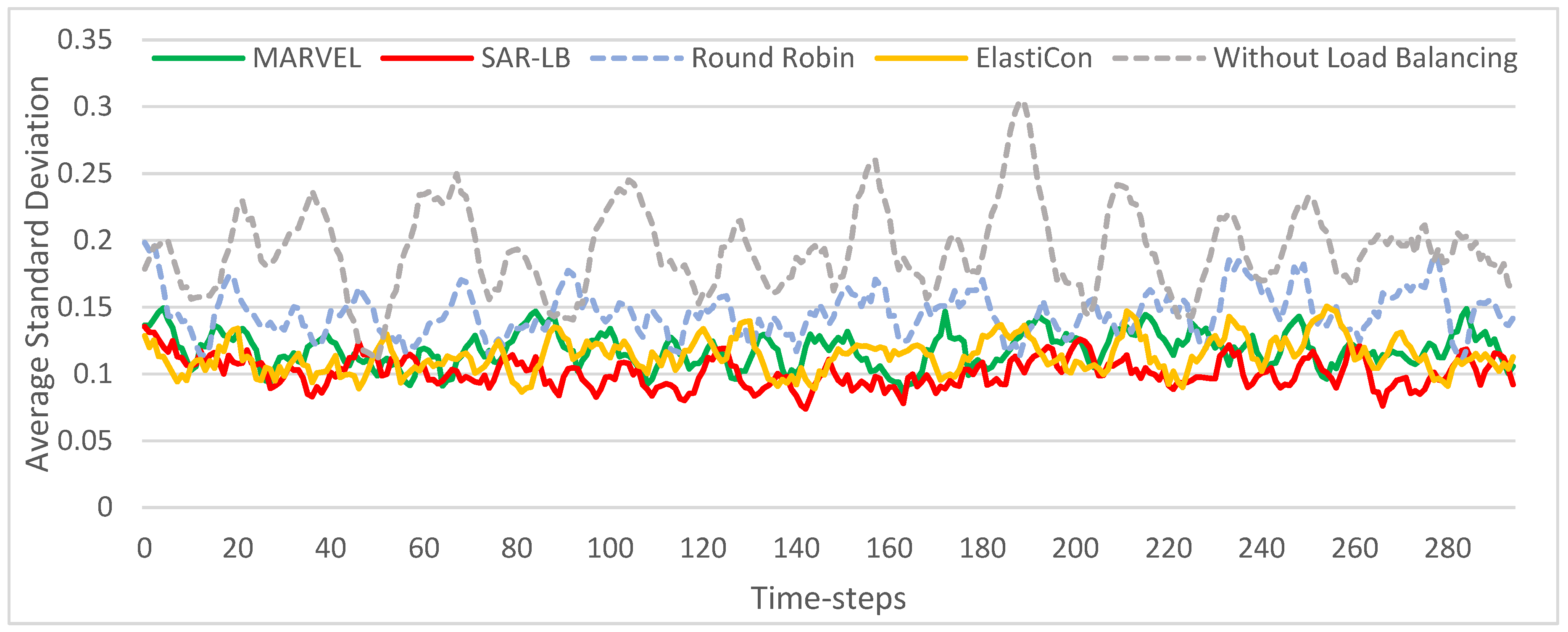
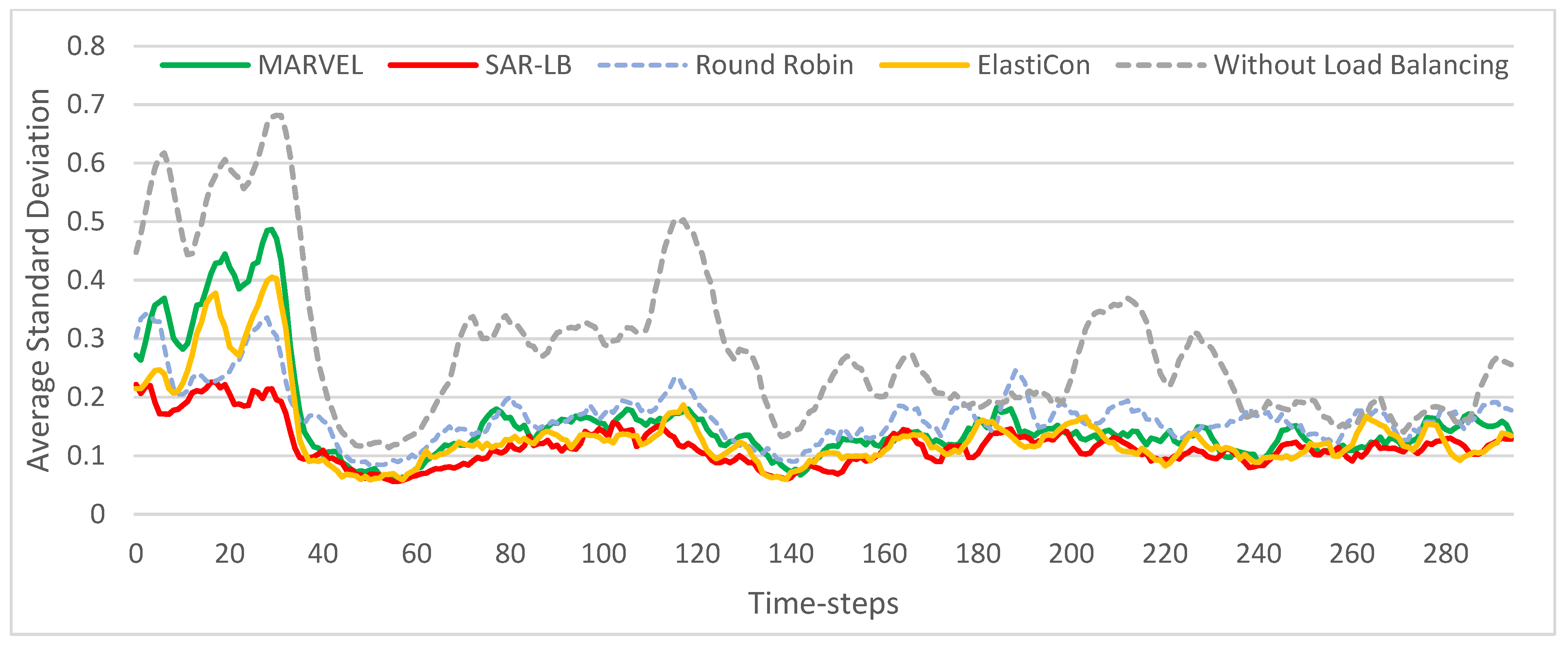
5.3. Evaluation Results and Analysis
5.3.1. Comparison of Load Balancing Rate
5.3.2. Comparison of Decision Time per Time-Step
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.; Peterson, L.; Rexford, J.; Shenker, S.; Turner, J. OpenFlow: Enabling innovation in campus networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- Shin, M.K.; Nam, K.H.; Kim, H.J. Software-defined networking (SDN): A reference architecture and open APIs. In Proceedings of the IEEE 2012 International Conference on ICT Convergence (ICTC), Jeju Island, Korea, 15–17 October 2012; pp. 360–361. [Google Scholar]
- Open Flow Protocol 1.3. Available online: https://opennetworking.org/wp-content/uploads/2014/10/openflow-spec-v1.3.0.pdf (accessed on 30 November 2020).
- Pashkov, V.; Shalimov, A.; Smeliansky, R. Controller failover for SDN enterprise networks. In Proceedings of the IEEE 2014 International Science and Technology Conference (Modern Networking Technologies)(MoNeTeC), Moscow, Russia, 28–29 October 2014; pp. 1–6. [Google Scholar]
- Hu, T.; Guo, Z.; Yi, P.; Baker, T.; Lan, J. Multi-Controller Based Software-Defined Networking: A Suvey. IEEE Access 2018, 6, 15980–15996. [Google Scholar] [CrossRef]
- Ye, X.; Cheng, G.; Luo, X. Maximizing SDN control resource utilization via switch migration. Comput. Netw. 2017, 126, 69–80. [Google Scholar] [CrossRef]
- Al-Tam, F.; Correia, N. On Load Balancing via Switch Migration in Software-Defined Networking. IEEE Access 2019, 7, 95998–96010. [Google Scholar] [CrossRef]
- Cui, J.; Lu, Q.; Zhong, H.; Tian, M.; Liu, L. A Load-Balancing Mechanism for Distributed SDN Control Plane Using Response Time. IEEE Trans. Netw. Serv. Manag. 2018, 15, 1197–1206. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Chen, H.; Hu, H.; Lan, J. Dynamic switch migration towards a scalable SDN control plane. Int. J. Commun. Syst. 2016, 29, 1482–1499. [Google Scholar] [CrossRef]
- Sahoo, K.S.; Puthal, D.; Tiwary, M.; Usman, M.; Sahoo, B.; Wen, Z.; Sahoo, B.P.S.; Ranjan, R. ESMLB: Efficient Switch Migration-Based Load Balancing for Multicontroller SDN in IoT. IEEE Internet Things J. 2020, 7, 5852–5860. [Google Scholar] [CrossRef]
- Cello, M.; Xu, Y.; Walid, A.; Wilfong, G.; Chao H., J.; Marchese, M. BalCon: A Distributed Elastic SDN Control via Efficient Switch Migration. In Proceedings of the 2017 IEEE International Conference on Cloud Engineering (IC2E), Vancouver, BC, Canada, 4–7 April 2017; pp. 40–50. [Google Scholar] [CrossRef]
- Guowei, W.; Jinlei, W.; Obaidat, M.; Yao, L.; Hsiao, K.F. Dynamic switch migration with noncooperative game towards control plane scalability in SDN. Int. J. Commun. Syst. 2019, 32, e3927. [Google Scholar]
- Sun, P.; Guo, Z.; Wang, G.; Lan, J.; Hu, Y. MARVEL: Enabling controller load balancing in software-defined networks with multi-agent reinforcement learning. Comput. Netw. 2020, 177, 107230. [Google Scholar] [CrossRef]
- Li, Z.; Zhou, Z.; Gao, J.; Qin, Y. SDN Controller Load Balancing Based on Reinforcement Learning. In Proceedings of the 2018 IEEE 9th International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 November 2018. [Google Scholar] [CrossRef]
- Zhu, M.; Hua, Q.; Zhao, J. Dynamic switch migration with Q-learning towards scalable SDN control plane. In Proceedings of the 2017 9th International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 11–13 October 2017. [Google Scholar] [CrossRef]
- Zhu, X.; Chang, C.; Xi, Q.; Zuo, Z. Attribute-Guard: Attribute-Based Flow Access Control Framework in Software-Defined Networking. Secur. Commun. Netw. 2020, 2020, 6302739. [Google Scholar] [CrossRef]
- Imran, M.; Durad, M.H.; Khan, F.A.; Derhab, A. Reducing the effects of DoS attacks in software defined networks using parallel flow installation. Human Cent. Comput. Inf. Sci. 2019, 9, 16. [Google Scholar] [CrossRef]
- Wang, C.A.; Hu, B.; Chen, S.; Li, D.; Liu, B. A switch migration-based decision-making scheme for balancing load in SDN. IEEE Access 2017, 5, 4537–4544. [Google Scholar] [CrossRef]
- Wang, T.; Liu, F.; Xu, H. An efficient online algorithm for dynamic SDN controller assignment in data center networks. IEEE/ACM Trans. Netw. 2017, 25, 2788–2801. [Google Scholar] [CrossRef]
- Wang, T.; Liu, F.; Guo, J.; Xu, H. Dynamic SDN controller assignment in data center networks: Stable matching with transfers. In Proceedings of the IEEE INFOCOM 2016—The 35th Annual IEEE International Conference on Computer Communications, San Francisco, CA, USA, 10–14 April 2016; pp. 1–9. [Google Scholar]
- Bogdanski, B. Optimized Routing for Fat-Tree Topologies. Ph.D. Thesis, Department of Informatics Faculty of Mathematics and Natural Sciences University of Oslo, Oslo, Norway, January 2014. [Google Scholar]
- Liu, W.; Wang, Y.; Zhang, J.; Liao, H.; Liang, Z.; Liu, X. AAMcon: An adaptively distributed SDN controller in data center networks. Front. Comput. Sci. 2020, 14, 146–161. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Rafique, D.; Velasco, L. Machine learning for network automation: Overview, architecture, and applications [Invited Tutorial]. IEEE/OSA J. Opt. Commun. Netw. 2018, 10, D126–D143. [Google Scholar] [CrossRef] [Green Version]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Mu, T.; Al-Fuqaha, A.; Shuaib, K.; Sallabi, F.M.; Qadir, J. SDN Flow Entry Management Using Reinforcement Learning. ACM Trans. Auton. Adapt. Syst. 2018, 13, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Zhou, S.; Wei, Y.; Leng, S. Deep Reinforcement Learning for Controller Placement in Software Defined Network. In Proceedings of the IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020. [Google Scholar]
- Tosounidis, V.; Pavlidis, G.; Sakellaiou, I. Deep Q-Learning for Load Balancing Traffic in SDN Networks. In Proceedings of the SETN: Hellenic Conference on Artificial Intelligence, Athens, Greece, 2–4 September 2020. [Google Scholar]
- Pfaff, B.; Pettit, J.; Koponen, T.; Jackson, E.; Zhou, A.; Rajahalme, J.; Amidon, K. The design and implementation of open vswitch. In Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI’ 15), Oakland, CA, USA, 13 January 2015; pp. 117–130. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Xu, Z.; Tang, J.; Meng, J.; Zhang, W.; Wang, Y.; Liu, C.H.; Yang, D. Experience-driven networking: A deep reinforcement learning based approach. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 15–19 April 2018; pp. 1871–1879. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Desmaison, A. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Dixit, A.; Hao, F.; Mukherjee, S.; Lakshman, T.V.; Kompella, R.R. ElastiCon; an elastic distributed SDN controller. In Proceedings of the ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS), Marina del Rey, CA, USA, 20–21 October 2014. [Google Scholar]
- Gropp, W.; Gropp, W.D.; Lusk, E.; Skjellum, A.; Lusk, A.D.F.E.E. Using MPI: Portable Parallel Programming with the Message-Passing Interface; MIT press: Cambridge, MA, USA, 1999; Volume 1. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | MARVEL | Li et al. [14] | Min et al. [15] | SAR-LB (Ours) |
|---|---|---|---|---|
| Utilized multi-agent model | Yes | No | No | No |
| State definition | Coarse-grained resource utilization | Index of initial controller | Index of initial controller | Fine-grained resource utilization |
| Utilized DNN | Yes | No (tabular Q learning) | No (tabular Q learning) | Yes |
| Processor | Memory | Graphics Card |
|---|---|---|
| Intel Xeon Skylake (Gold 6230)/ 2.10 GHz (20-cores) processor | 384 GB | V100 GPU |
| Hyper Parameters | Values |
|---|---|
| Minibatch size | 64 |
| Replay buffer size | 1,000,000 frames |
| Learning start (i.e., time-steps to start learning) | 3000 time-steps |
| Learning frequency (i.e., time-steps intervals to train RL agent) | 4 time-steps |
| History length | 32 frames |
| Target Q model update frequency | 10,000 time-steps |
| Learning rate | 0.0001 |
| Optimizer | RMSProp [33] |
| The number of episodes | 10,000 |
| The number of time-steps per episode | 300 |
| Schemes | 4 CTRLs, 20 Switches | 4 CTRLs, 40 Switches | 4 CTRLs, 80 Switches | 8 CTRLs, 40 Switches | 16 CTRLs, 80 Switches |
|---|---|---|---|---|---|
| W/O Load Balancing | 0.0811 (100%) | 0.1210 (100%) | 0.1918 (100%) | 0.0970 (100%) | 0.0960 (100%) |
| ElastiCon | 0.0669 (121%) | 0.0857 (141%) | 0.1136 (169%) | 0.0687 (141%) | 0.0729 (132%) |
| Round Robin | 0.0991 (82%) | 0.1175 (103%) | 0.1455 (132%) | 0.0948 (102%) | 0.0942 (102%) |
| SAR-LB | 0.0645 (126%) | 0.0781 (155%) | 0.1014 (189%) | 0.0670 (145%) | 0.0906 (106%) |
| MARVEL | 0.0724 (112%) | 0.0900 (134%) | 0.1183 (162%) | 0.0732 (132%) | 0.0740 (130%) |
| Schemes | 4 CTRLs, 20 Switches | 4 CTRLs, 40 Switches | 4 CTRLs, 80 Switches | 8 CTRLs, 40 Switches | 16 CTRLs, 80 Switches |
|---|---|---|---|---|---|
| W/O Load Balancing | 0.1162(100%) | 0.1809(100%) | 0.2818(100%) | 0.1126(100%) | 0.1209(100%) |
| ElastiCon | 0.0717(162%) | 0.0917(197%) | 0.1364(207%) | 0.0751(150%) | 0.0850(142%) |
| Round Robin | 0.1028(113%) | 0.1313(138%) | 0.1682(168%) | 0.1014(111%) | 0.1103(110%) |
| SAR-LB | 0.0712(163%) | 0.0852(212%) | 0.1170(241%) | 0.0740(152%) | 0.1157(104%) |
| MARVEL | 0.0781(149%) | 0.1027(176%) | 0.1588(177%) | 0.0796(141%) | 0.0873(138%) |
| Schemes | 4 CTRLs, 20 Switches | 4 CTRLs, 40 Switches | 4 CTRLs, 80 Switches | 8 CTRLs, 40 Switches | 16 CTRLs, 80 Switches |
|---|---|---|---|---|---|
| W/O load balancing | 0.00212 (34%) | 0.00447 (52%) | 0.00889 (65%) | 0.00439 (35%) | 0.00882 (36%) |
| ElastiCon | 0.00277 (44%) | 0.00535 (62%) | 0.01054 (76%) | 0.00562 (45%) | 0.01234 (50%) |
| Round Robin | 0.00214 (34%) | 0.00422 (49%) | 0.00839 (61%) | 0.00433 (35%) | 0.00857 (35%) |
| SAR-LB | 0.00517 (82%) | 0.00817 (94%) | 0.01426 (104%) | 0.00773 (62%) | 0.01312 (53%) |
| MARVEL | 0.00630 (100%) | 0.00865 (100%) | 0.01377 (100%) | 0.01238 (100%) | 0.02478 (100%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeo, S.; Naing, Y.; Kim, T.; Oh, S. Achieving Balanced Load Distribution with Reinforcement Learning-Based Switch Migration in Distributed SDN Controllers. Electronics 2021, 10, 162. https://doi.org/10.3390/electronics10020162
Yeo S, Naing Y, Kim T, Oh S. Achieving Balanced Load Distribution with Reinforcement Learning-Based Switch Migration in Distributed SDN Controllers. Electronics. 2021; 10(2):162. https://doi.org/10.3390/electronics10020162
Chicago/Turabian StyleYeo, Sangho, Ye Naing, Taeha Kim, and Sangyoon Oh. 2021. "Achieving Balanced Load Distribution with Reinforcement Learning-Based Switch Migration in Distributed SDN Controllers" Electronics 10, no. 2: 162. https://doi.org/10.3390/electronics10020162
APA StyleYeo, S., Naing, Y., Kim, T., & Oh, S. (2021). Achieving Balanced Load Distribution with Reinforcement Learning-Based Switch Migration in Distributed SDN Controllers. Electronics, 10(2), 162. https://doi.org/10.3390/electronics10020162