An Efficient Indexing Scheme for Network Traffic Collection and Retrieval System


Abstract
:1. Introduction
2. Related Works
- Hash: Hash index uses a certain hash algorithm to convert the key value into a hash value. According to the hash value, the location for an entry to be inserted or queried can be found immediately. Therefore, it has a very fast speed. Linked lists are the most commonly used method to resolve hash conflicts. Inevitably, as the number of entries increases, hash collisions will become more frequent. This will result in a significant reduction in retrieval efficiency. Moreover, a hash index cannot support range queries and union queries. In Reference [7], S. Kornexl and V. Paxson et al. proposed a typical hash-based indexing scheme Time Machine for the archiving and retrieval of the network traffic stream. It could greatly reduce the recorded volume based on the heavy-tailed characteristics of network traffic. Due to the characteristics of hash, Time Machine was faced with the problem that the retrieval efficiency will be significantly reduced with the increase of network traffic.
- B+ Tree: B+ tree has been widely used in relational database management systems, such as MySQL and SQL Server. Compared with the hash index, the B+ tree index has good support for range queries. However, the B+ tree is not suitable for indexing columns with many duplicate values. For network traffic retrieval, some commonly used indexed attributes, such as the destination port, typically contain a large number of duplicate values. In References [10,11], the B+ tree was used to build indexes for network traffic. According to the evaluation results in Reference [10], the performance of indexing for network traffic using B+ trees is up to 40 K records per second. Hence, the indexing efficiency of the B+ tree cannot meet the requirements of the current 10G or even higher network links.
- Bitmap: Indexing for packets with bitmaps is a popular way to solve the problem of network traffic retrieval. Many indexing schemes based on bitmaps, such as pcapIndex [12], FastBit [13] and NET-FLi [14], have been studied. Bitmap index maps a key value to a bit vector which contains 0 or 1. Table 1 illustrates a bitmap example. Bitmap index supports efficient queries and can easily handle complex queries. However, the disadvantage of the bitmap index is that it takes up much storage space when handling a large number of records. To address this challenge, many bitmap compression algorithms have been proposed. In Reference [16], Wu et al. proposed the WAH algorithm. For further compression on the basis of WAH, many variants of WAH have been proposed, including Position List WAH (PLWAH) [17], Compressed ‘n’ Composable Integer Set (CONCISE) [18], Compressed Adaptive Index (COMPAX) [14], SECOMPAX [19], Byte Aligned Hybrid (BAH) [20] and Compressing Dirty Snippet (CODIS) [21]. Some of them are already applied in network traffic archival and retrieval. In Reference [22], Chen et al. presented a survey of different traffic archival and retrieval systems and various bitmap index compression algorithms.
3. Overview of Wavelet Matrix
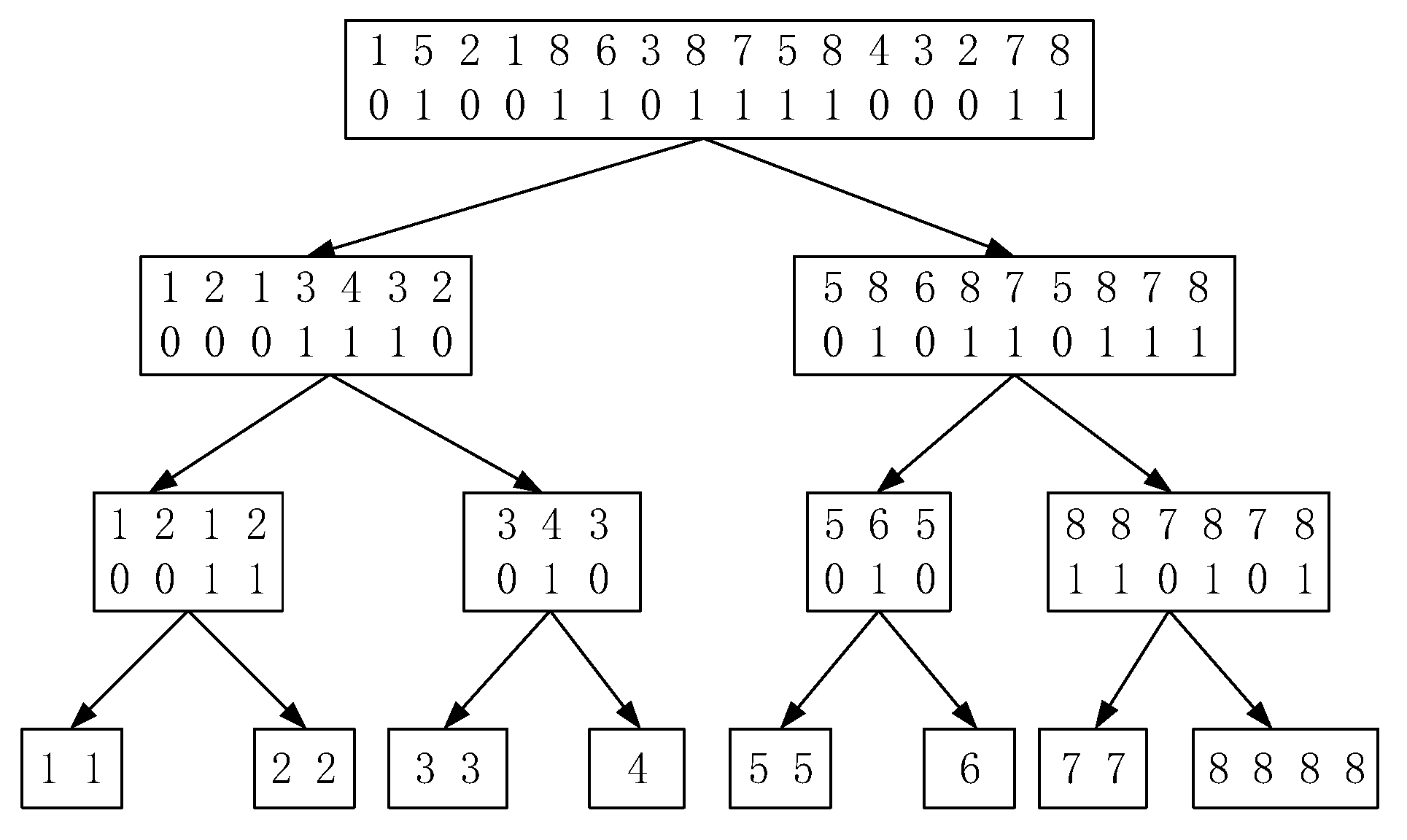
3.1. Wavelet Tree
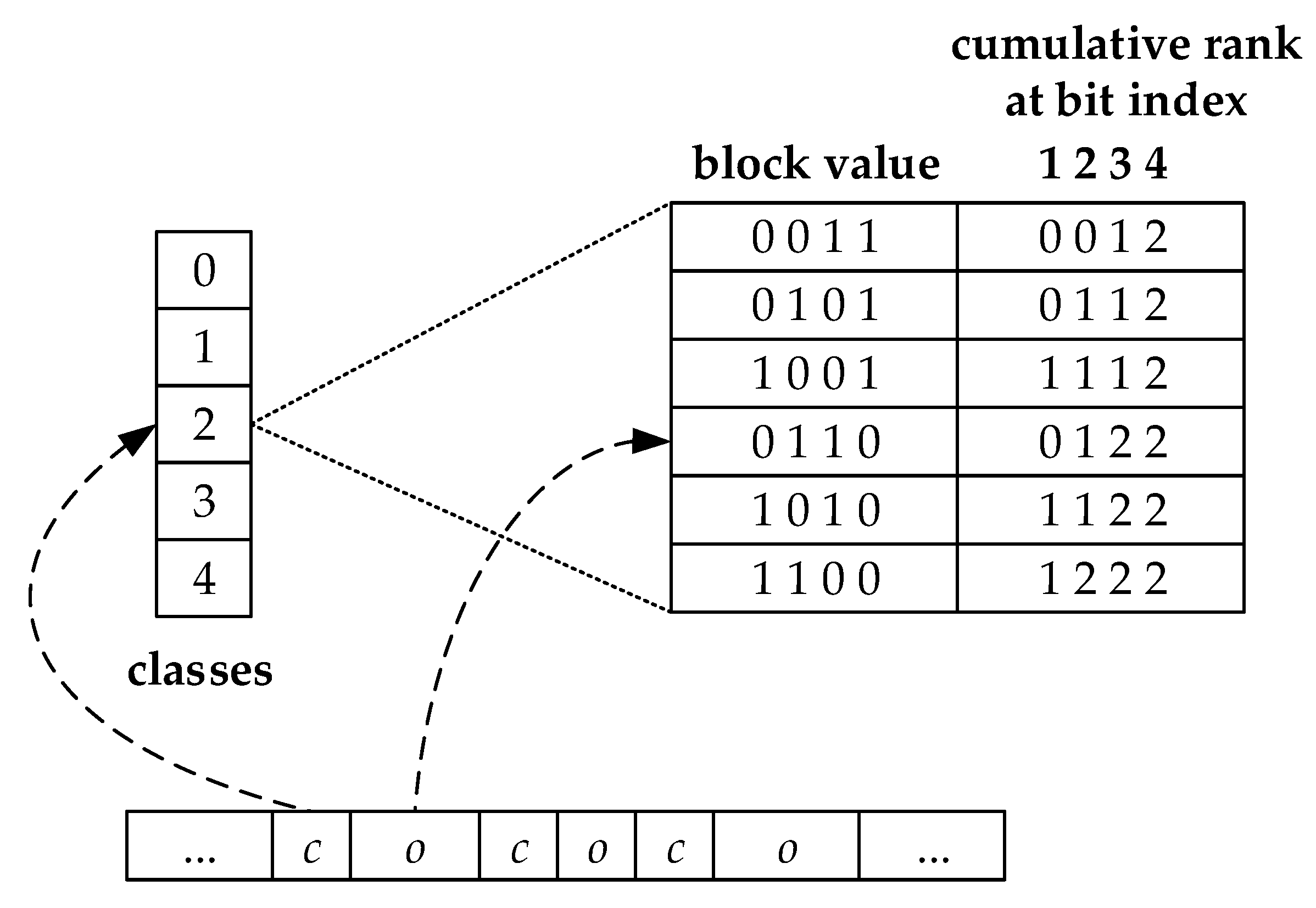
3.2. Wavelet Matrix
| Algorithm 1 Wavelet matrix algorithms: on the wavelet matrix of sequence , returns ; returns ; and returns . | ||
if reach a leaf node then return end if if then else end if return | if reach a leaf node then return end if if then else end if return | while do if then else end if end while return |
4. Implementation
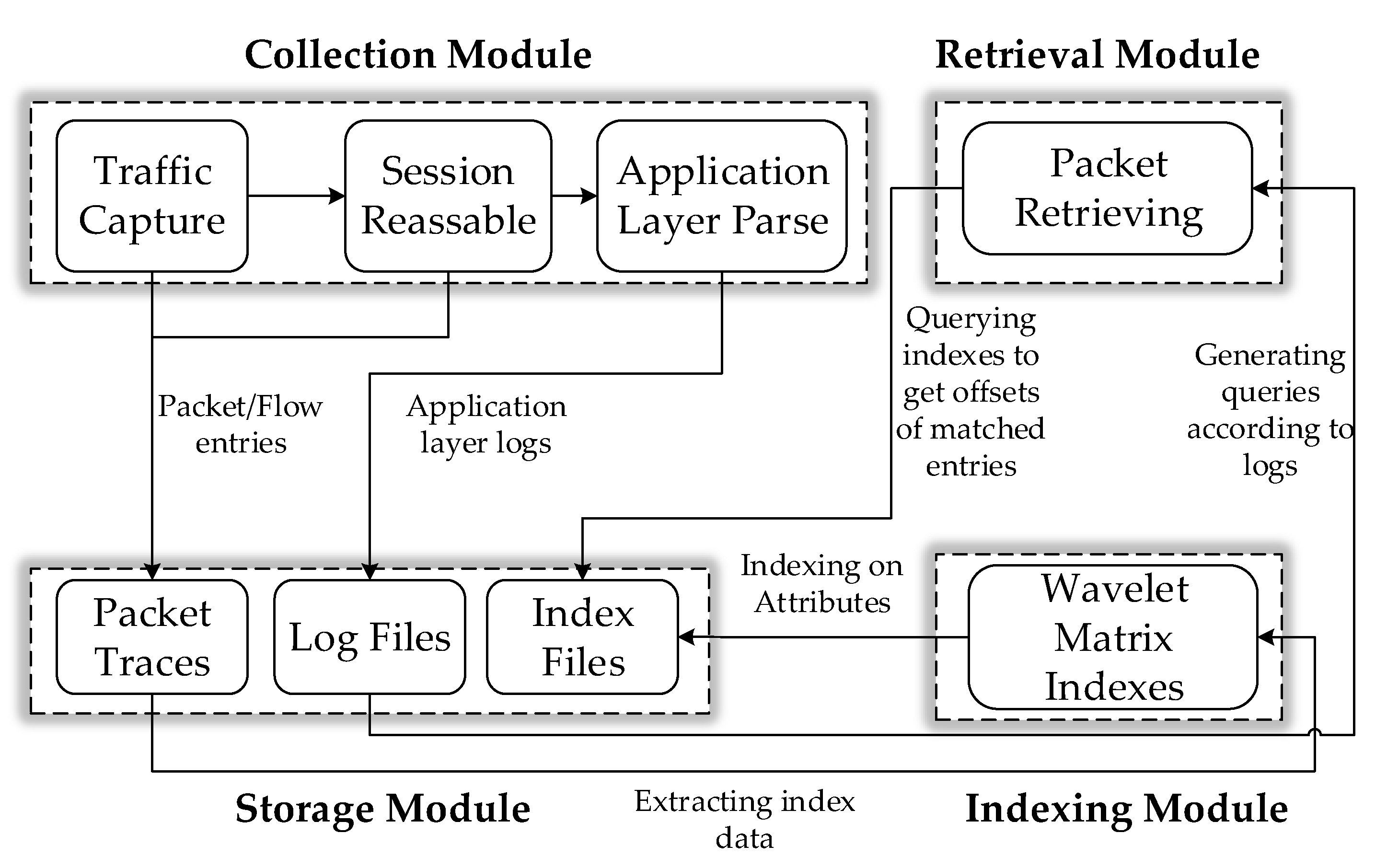
4.1. System Architecture
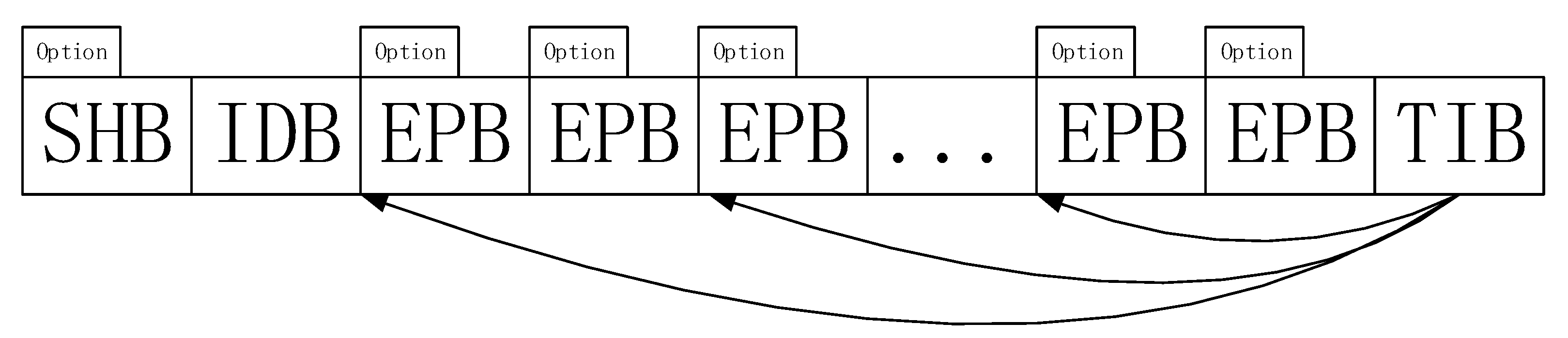
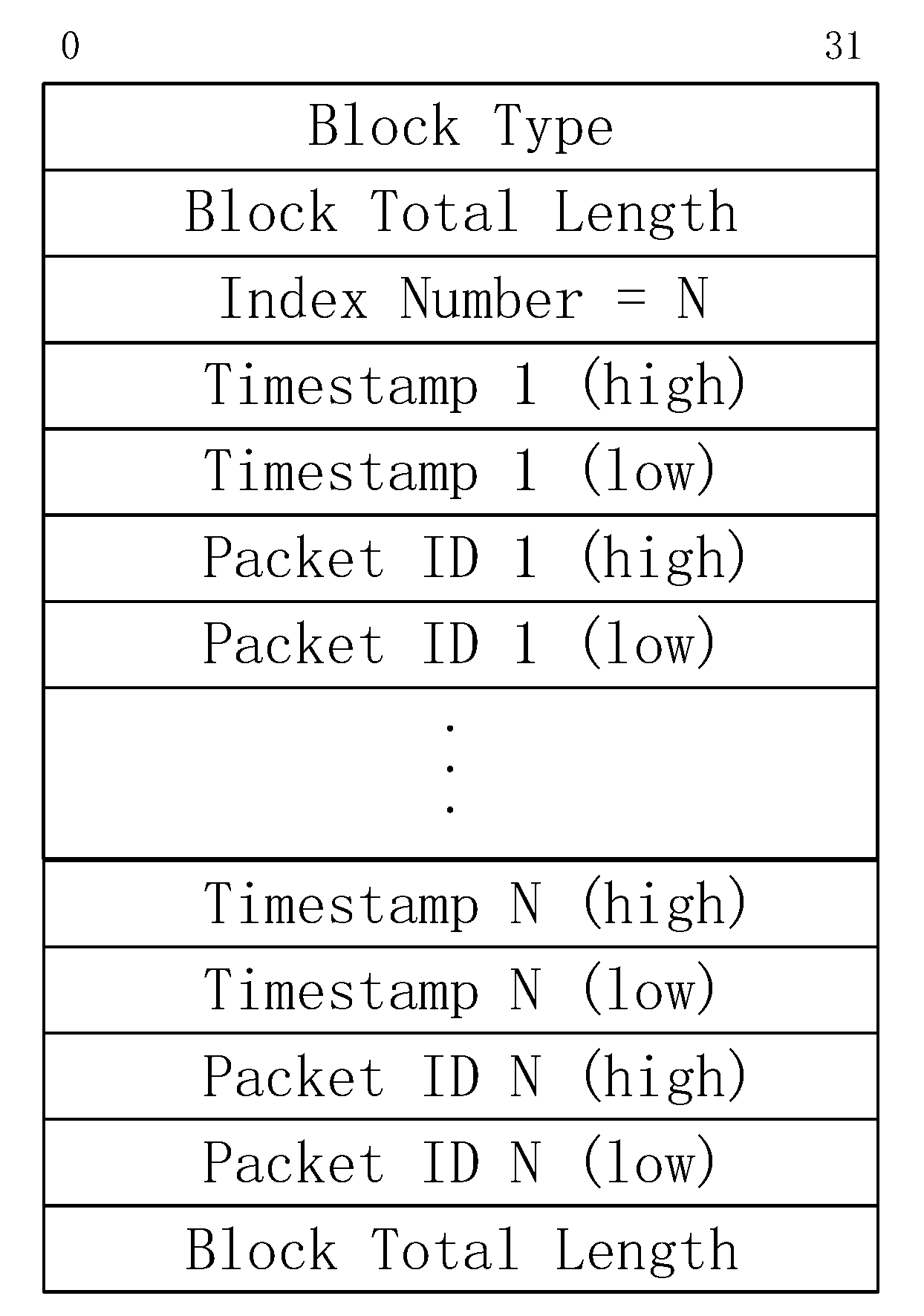
4.2. Packet Storage Format
4.3. Indexing Scheme
4.3.1. Indexing
4.3.2. Index Query
4.4. Performance Optimization
5. Performance Evaluation
5.1. Time Consumption for Indexing
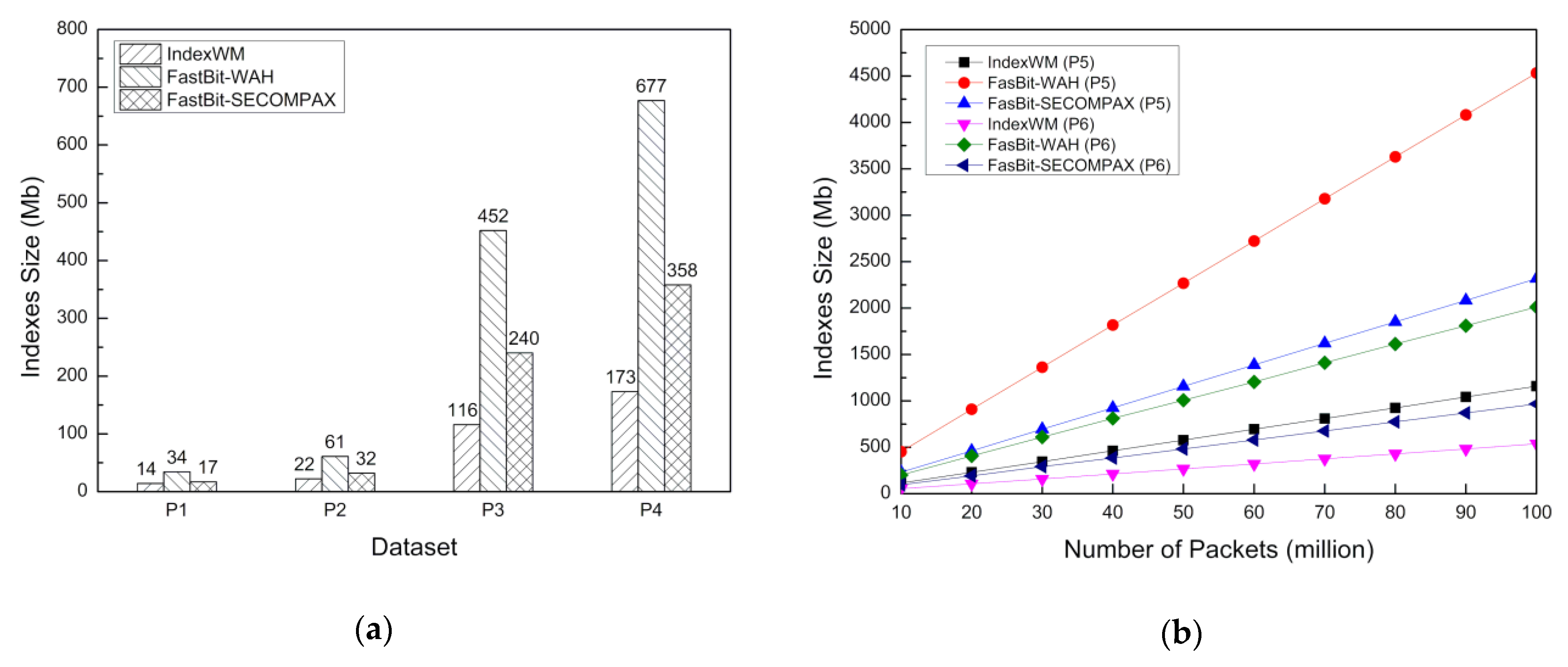
5.2. Storage Consumption for Indexing
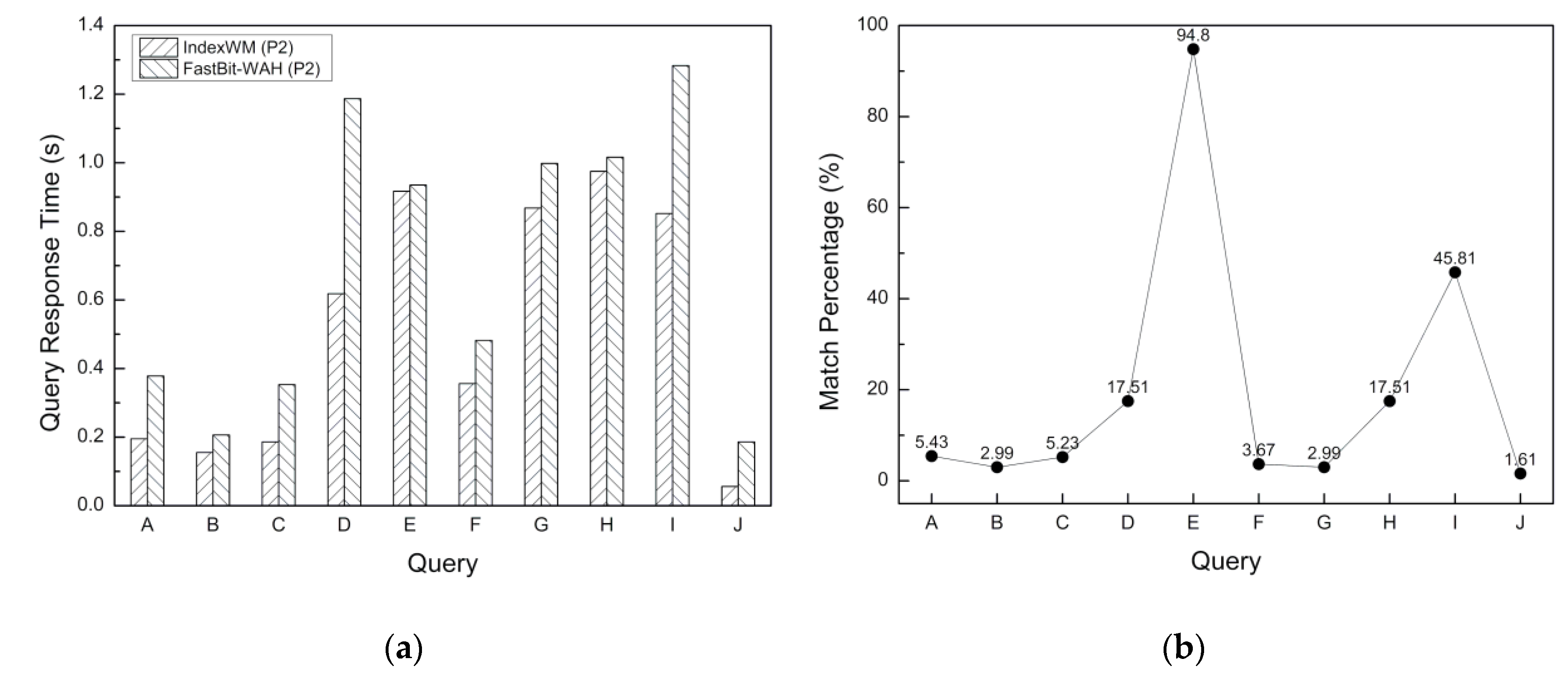
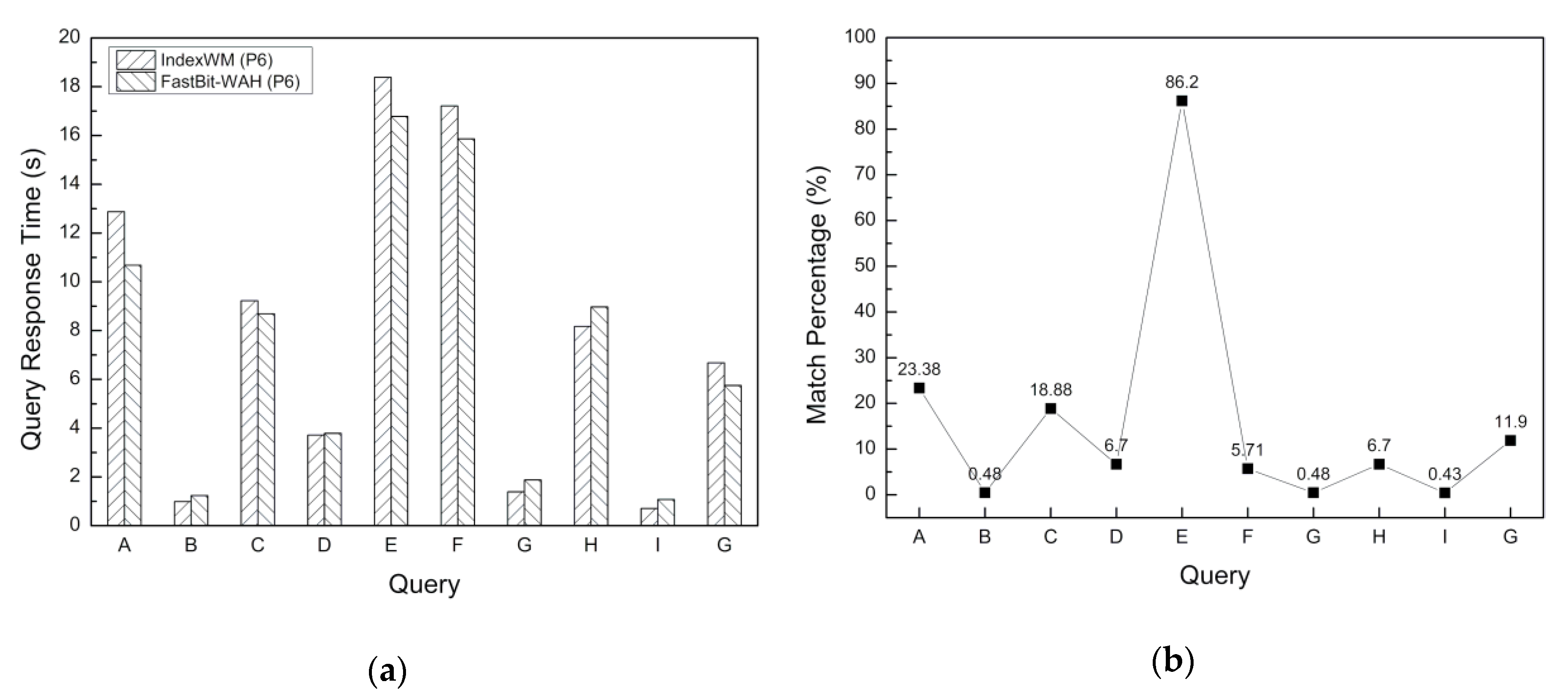
5.3. Query Response Time
5.4. Performance Evaluation Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Joshi, R.C.; Pilli, E.S. Network Forensic Acquisition. In Fundamentals of Network Forensics: A Research Perspective; Springer London: London, UK, 2016; pp. 97–106. [Google Scholar]
- Tcpdump/Libpcap Public Repository. Available online: https://www.tcpdump.org (accessed on 3 November 2020).
- PCAP Next Generation Dump File Format. Available online: https://github.com/pcapng/pcapng (accessed on 3 November 2020).
- Goyal, P.; Goyal, A. Comparative study of two most popular packet sniffing tools-Tcpdump and Wireshark. In Proceedings of the 2017 9th International Conference on Computational Intelligence and Communication Networks (CICN), Girne, Cyprus, 16–17 September 2017; pp. 77–81. [Google Scholar]
- Chandrasekaran, S.; Cooper, O.; Deshpande, A.; Franklin, M.J.; Hellerstein, J.M.; Hong, W.; Krishnamurthy, S.; Madden, S.R.; Reiss, F.; Shah, M.A. TelegraphCQ: Continuous dataflow processing. In Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data, San Diego, CA, USA, 10–12 June 2003; p. 668. [Google Scholar]
- Desnoyers, P.J.; Shenoy, P. Hyperion: High volume stream archival for retrospective querying. In Proceedings of the 2007 USENIX Annual Technical Conference, Santa Clara, CA, USA, 17–22 June 2007; pp. 1–14. [Google Scholar]
- Kornexl, S.; Paxson, V.; Dreger, H.; Feldmann, A.; Sommer, R. Building a Time Machine for Efficient Recording and Retrieval of High-Volume Network Traffic. In Proceedings of the 5th ACM SIGCOMM Conference on Internet measurement, Berkeley, CA, USA, 19–21 October 2005; pp. 267–272. [Google Scholar]
- Chen, Z.; Ruan, L.; Cao, J.; Yu, Y.; Jiang, X. TIFAflow: Enhancing traffic archiving system with flow granularity for forensic analysis in network security. Tsinghua Sci. Technol. 2013, 18, 406–417. [Google Scholar] [CrossRef] [Green Version]
- Xie, G.; Su, J.; Wang, X.; He, T.; Zhang, G.; Uhlig, S.; Salamatian, K. Index–Trie: Efficient archival and retrieval of network traffic. Comput. Netw. 2017, 124, 140–156. [Google Scholar] [CrossRef]
- Geambasu, R.; Bragin, T.; Jung, J.; Balazinska, M. On-demand view materialization and indexing for network forensic analysis. In Proceedings of the 3rd USENIX International Workshop on Networking Meets Databases, Cambridge, MA, USA, 10 April 2007; pp. 1–7. [Google Scholar]
- Pcap-Index. Available online: https://github.com/taterhead/PCAP-Index (accessed on 3 November 2020).
- Fusco, F.; Dimitropoulos, X.; Vlachos, M.; Deri, L. pcapIndex: An index for network packet traces with legacy compatibility. ACM Sigcomm Comput. Commun. Rev. 2012, 42, 47–53. [Google Scholar] [CrossRef]
- Wu, K.; Ahern, S.; Bethel, E.W.; Chen, J.; Childs, H.; Cormier-Michel, E.; Geddes, C.; Gu, J.; Hamann, B.; Koegler, W.; et al. FastBit: Interactively Searching Massive Data. J. Phys. Conf. Ser. 2009, 180, 012053. [Google Scholar] [CrossRef]
- Fusco, F.; Stoecklin, M.P.; Vlachos, M. NET-FLi: On-the-fly compression, archiving and indexing of streaming network traffic. Proc. VLDB Endow. 2010, 3, 1382–1393. [Google Scholar] [CrossRef]
- Xu, X.Y.; Li, M.S. Bitmap Index Design and Implementation. J. Netw. New Media 2006, 27, 188–191. [Google Scholar]
- Wu, K.; Otoo, E.J.; Shoshani, A. Optimizing bitmap indices with efficient compression. ACM Trans. Database Syst. 2006, 31, 1–38. [Google Scholar] [CrossRef]
- Deliège, F.; Pedersen, T.B. Position list word aligned hybrid: Optimizing space and performance for compressed bitmaps. In Proceedings of the 13th International Conference on Extending Database Technology, Lausanne, Switzerland, 22–26 March 2010; pp. 228–239. [Google Scholar]
- Colantonio, A.; Pietro, R.D. Concise: Compressed ‘n’ Composable Integer Set. Inf. Process. Lett. 2010, 110, 644–650. [Google Scholar] [CrossRef] [Green Version]
- Wen, Y.; Chen, Z.; Ma, G.; Cao, J.; Zheng, W.; Peng, G.; Li, S.; Huang, W. SECOMPAX: A bitmap index compression algorithm. In Proceedings of the 23rd International Conference on Computer Communication and Networks (ICCCN), Shanghai, China, 4–7 August 2014; pp. 1–7. [Google Scholar]
- Li, C.; Chen, Z.; Zheng, W.; Wu, Y.; Cao, J. BAH: A Bitmap Index Compression Algorithm for Fast Data Retrieval. In Proceedings of the 2016 IEEE 41st Conference on Local Computer Networks (LCN), Dubai, UAE, 7–10 November 2016; pp. 697–705. [Google Scholar]
- Zheng, W.; Liu, Y.; Chen, Z.; Cao, J. CODIS: A New Compression Scheme for Bitmap Indexes. In Proceedings of the 2017 ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS), Beijing, China, 18–19 May 2017; pp. 103–104. [Google Scholar]
- Chen, Z.; Wen, Y.; Cao, J.; Zheng, W.; Chang, J.; Yinjun, W.; Ma, G.; Hakmaoui, M.; Peng, G. A survey of bitmap index compression algorithms for Big Data. Tsinghua Sci. Technol. 2015, 20, 100–115. [Google Scholar] [CrossRef]
- Deri, L.; Lorenzetti, V.; Mortimer, S. Collection and exploration of large data monitoring sets using bitmap databases. In Proceedings of the Second International Conference on Traffic Monitoring and Analysis, Zurich, Switzerland, 7 April 2010; pp. 73–86. [Google Scholar]
- Li, J.; Ding, S.; Xu, M.; Han, F.; Guan, X.; Chen, Z. TIFA: Enabling Real-Time Querying and Storage of Massive Stream Data. In Proceedings of the Second International Conference on Networking and Distributed Computing, Beijing, China, 21–24 September 2011; pp. 61–64. [Google Scholar]
- Fusco, F.; Vlachos, M.; Stoecklin, M.P. Real-time creation of bitmap indexes on streaming network data. VLDB J. 2012, 21, 287–307. [Google Scholar] [CrossRef]
- Claude, F.; Navarro, G.; Ordóñez, A. The wavelet matrix: An efficient wavelet tree for large alphabets. Inf. Syst. 2014, 47, 15–32. [Google Scholar] [CrossRef] [Green Version]
- Grossi, R.; Gupta, A.; Vitter, J. High-order entropy-compressed text indexes. In Proceedings of the 14th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), Baltimore, MD, USA, 12–14 January 2003; pp. 841–850. [Google Scholar]
- Navarro, G. Wavelet trees for all. J. Discret. Algorithms 2014, 25, 2–20. [Google Scholar] [CrossRef]
- González, R.; Grabowski, S.; Mäkinen, V.; Navarro, G. Practical Implementation of Rank and Select Queries. In Proceedings of the 4th Workshop on Efficient and Experimental Algorithms (WEA), Santorini Island, Greece, 10–13 May 2005; pp. 27–38. [Google Scholar]
- Raman, R.; Raman, V.; Rao, S.S. Succinct indexable dictionaries with applications to encoding k-ary trees and multisets. In Proceedings of the Thirteenth Annual ACM-SIAM Symposium on Discrete Algorithms, San Francisco, CA, USA, 6–8 January 2002; pp. 233–242. [Google Scholar]
- Rizzo, L. Netmap: A novel framework for fast packet I/O. In Proceedings of the 2012 USENIX Conference on Annual Technical Conference, Boston, MA, USA, 13–15 June 2012; p. 9. [Google Scholar]
- PF_RING. Available online: http://www.ntop.org/products/packet-capture/pf_ring/ (accessed on 3 November 2020).
- Data Plane Development Kit. Available online: http://www.dpdk.org (accessed on 3 November 2020).
- Han, S.; Jang, K.; Park, K.; Moon, S. PacketShader: A GPU-accelerated software router. In Proceedings of the ACM SIGCOMM 2010 Conference, New Delhi, India, 30 August –3 September 2010; pp. 195–206. [Google Scholar]
- Quick Benchmark. Available online: https://catchchallenger.first-world.info/wiki/Quick_Benchmark:_Gzip_vs_Bzip2_vs_LZMA_vs_XZ_vs_LZ4_vs_LZO (accessed on 3 November 2020).
- 201904090815.Pcap. Available online: http://mawi.wide.ad.jp/mawi/ditl/ditl2019-G/201904090815.html (accessed on 3 November 2020).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RowID | Value | Bitmap Index | |||
|---|---|---|---|---|---|
| =1 | =2 | =3 | =4 | ||
| 1 | 4 | 0 | 0 | 0 | 1 |
| 2 | 2 | 0 | 1 | 0 | 0 |
| 3 | 3 | 0 | 0 | 1 | 0 |
| 4 | 1 | 1 | 0 | 0 | 0 |
| 5 | 3 | 0 | 0 | 1 | 0 |
| Dataset | File Size (GB) | Number of Packets | Average Packet Size (Bytes) |
|---|---|---|---|
| P1 | 1.1 | 1,676,198 | 661.30 |
| P2 | 2.2 | 3,036,636 | 773.43 |
| P3 | 3.1 | 9,971,170 | 325.98 |
| P4 | 10.0 | 14,952,785 | 712.0 |
| P5 | 27 | 108,448,597 | 260.0 |
| P6 | 8.4 | 112,414,148 | 1350.3 |
| Types | Description | Examples |
|---|---|---|
| Single | Exact match on a single attribute | |
| Multiple | Exact match on multiple attributes | |
| Wildcard | Wildcard match on a single attribute |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, C.; Wang, J.; Li, Y. An Efficient Indexing Scheme for Network Traffic Collection and Retrieval System. Electronics 2021, 10, 191. https://doi.org/10.3390/electronics10020191
Jiang C, Wang J, Li Y. An Efficient Indexing Scheme for Network Traffic Collection and Retrieval System. Electronics. 2021; 10(2):191. https://doi.org/10.3390/electronics10020191
Chicago/Turabian StyleJiang, Chao, Jinlin Wang, and Yang Li. 2021. "An Efficient Indexing Scheme for Network Traffic Collection and Retrieval System" Electronics 10, no. 2: 191. https://doi.org/10.3390/electronics10020191
APA StyleJiang, C., Wang, J., & Li, Y. (2021). An Efficient Indexing Scheme for Network Traffic Collection and Retrieval System. Electronics, 10(2), 191. https://doi.org/10.3390/electronics10020191