1. Introduction
Humans recognize more sharpened images as being clearer and perceive images embedding finely resolved signals as being higher resolution images, even at the same resolution. So, as image contents are increasingly produced toward higher quality and are presented at higher resolution displays, state-of-the-art detail image enhancements need to make images clearer and finely resolved.
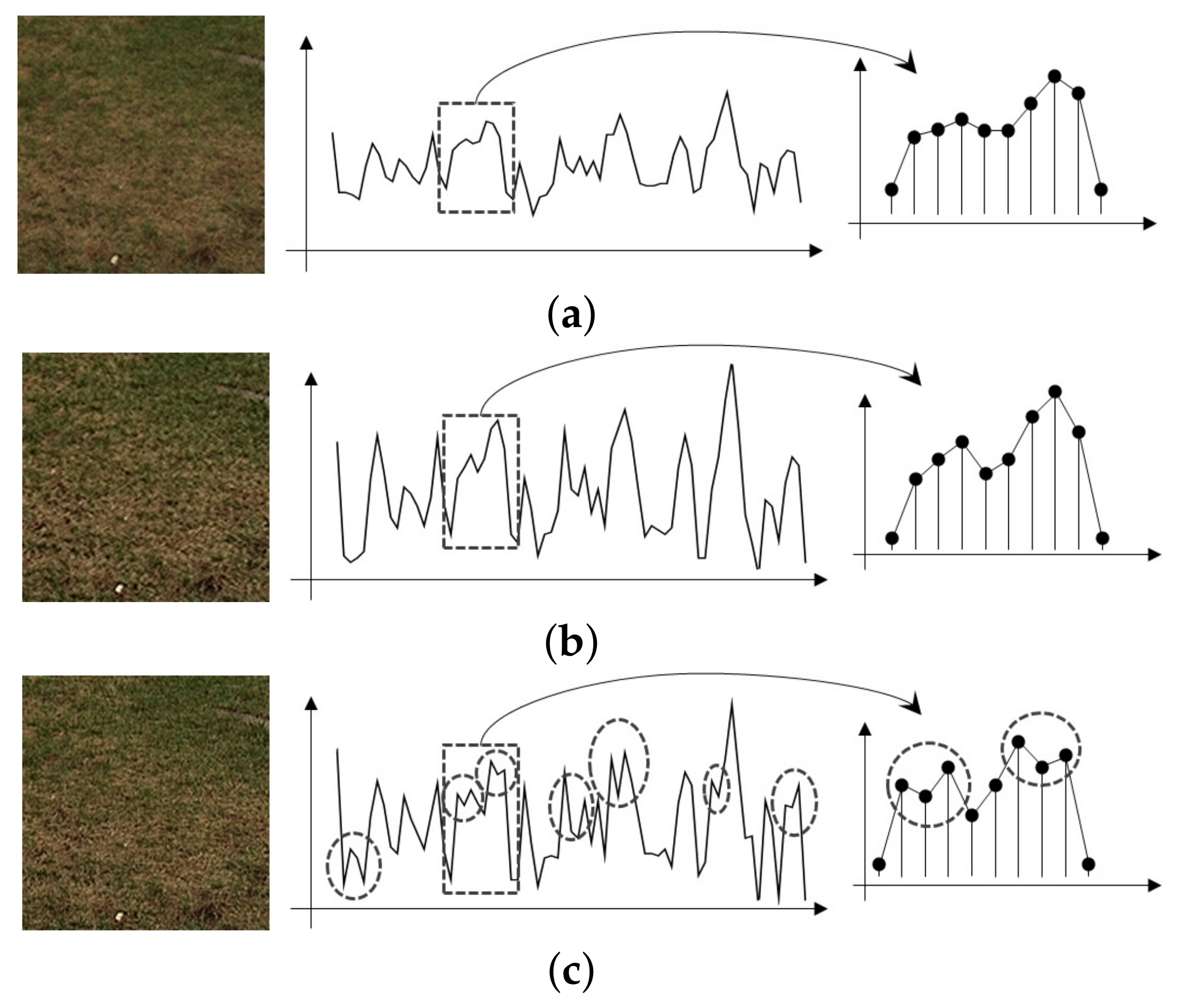
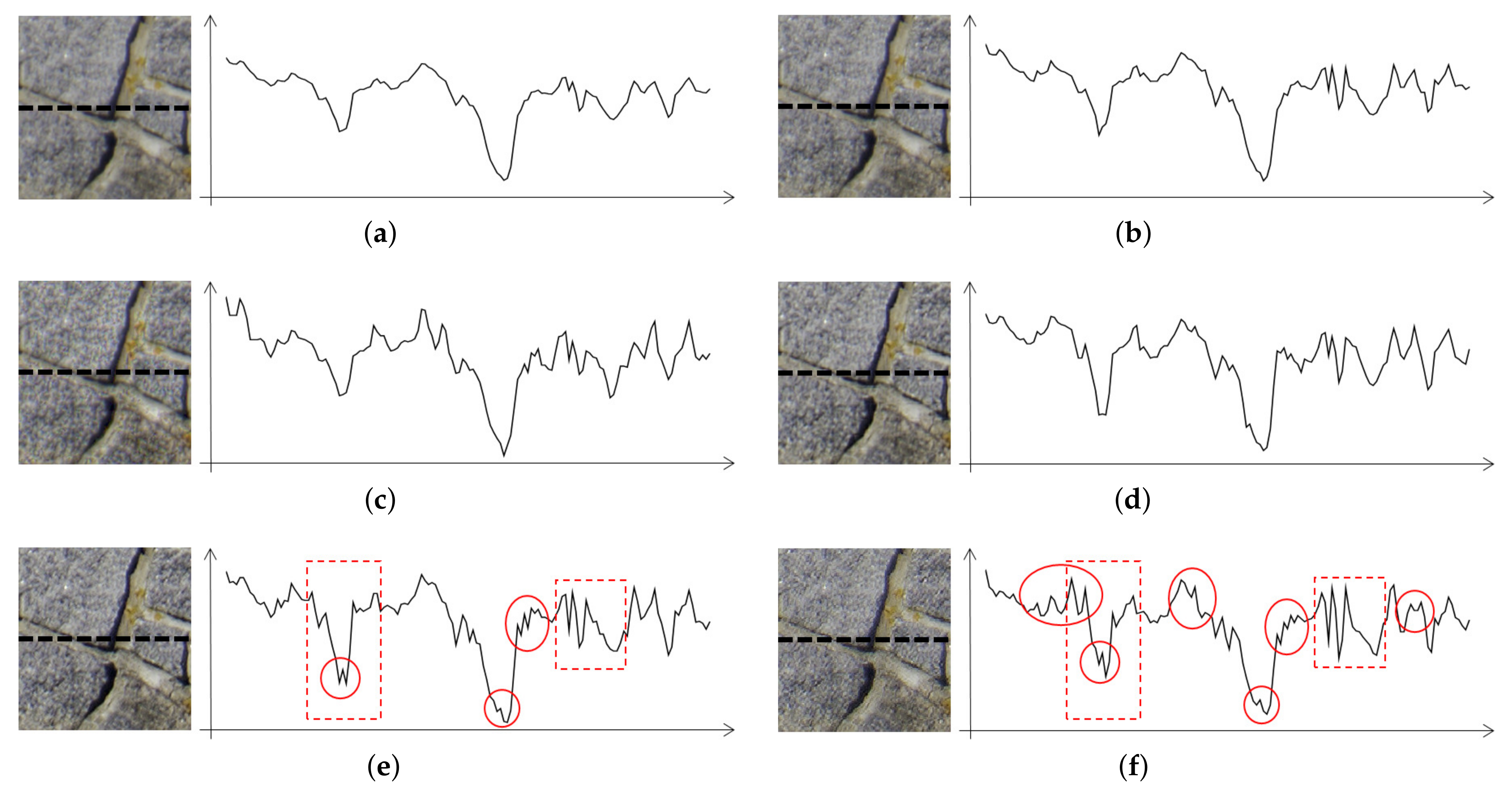
Figure 1 shows a comparison of the original image with one that is clearer and another that is clearer and more finely resolved. To get a better understanding, one-dimensional horizontal signals of the images are plotted. The image in
Figure 1b is clearer than the original image because magnified local variations sharpen the image. In the image in
Figure 1c, the local variations are magnified, and, simultaneously, the granular variations indicated by circles are embedded while preserving the contour of the local variant signals. The granular signals are the most resolved signals for an image display to represent. Owing to the granular variations, humans tend to perceive the image shown in
Figure 1c as being the highest resolution.
Since existing detail enhancement methods increase local contrast only without observing the different effects of local variants and granular signals, they enhance only the sharpness of the images. Therefore, it is necessary to develop a detail image enhancement capable of magnifying local variations and simultaneously emphasizing granular signals in harmony with local variant signals.
The detail enhancement methods can be roughly categorized into spatial domain, frequency domain, and learning-based methods. Spatial domain methods focus primarily on elevating local variant signals. In the spatial domain, Majumder et al. [
1] intensified the local contrasts based on Weber’s law. Kou et al. equalized the overall gradient by increasing the image signal gradients at small local variant regions [
2]. Deng et al. applied a multi-resolution filter to decompose image signals into base and detail image signals and then emphasized the detail image signals [
3]. Nercessian et al. measured the energy ratio among different resolution signals in the wavelet transform domain and then increased the energy ratio of high-resolution signals [
4]. Since the granular signals are tiny compared to local variant signals, these methods are technically unable to extract the granular signals and thus rarely enhance them. Therefore, although the spatial domain methods usually enhance the local contrast for the images to become clearer, they rarely enhance images to be finely resolved.
Using the capability of dissolving the image signals into frequency components, the frequency domain methods have focused on how to increase the frequency energy of detail signals. The multi-band energy scaling method (MESM) developed by Tang et al. recursively scales up the frequency energy ratio in the discrete cosine transform (DCT) domain as the frequency band increases [
5]. This method sharpens local variant signals in line with human visual perception, but rarely makes images seemed more resolved. The alpha rooting method exponentially boosts the frequency energy inversely to the original frequency energy [
6] and results in the granular signals well, but often produces noisy signals. Celik conducted the DCT over the entire image to utilize an extremely fine frequency resolution [
7]. This method weights higher frequency components as being greater in proportion to the global variation. Since the method processes detail signals globally, it may produce insufficiently enhanced textures or excessively boosted noises. Moreover, it is not easy in actual systems to take the DCT over the entire image. Therefore, the existing frequency domain methods either rarely reveal granular signals or may produce noisy signals when they reveal granular signals.
More recently, learning-based image-enhancement methods have been developed and are effective for improving global contrast or tuning color tones, such as de-hazing, low-light and underwater areas [
8,
9]. Yan et al. applied a convolution neural network (CNN) that was learned from images enhanced by algorithms or human experts [
10]. Gharbi et al. designed a bilateral CNN separately learning global and local variant signals to achieve real-time processing, even on mobile devices [
11]. Chen et al. proposed a GAN-based image enhancement network that overcomes the ill-convergence that often occurs in GAN [
12]. Since the GAN-based methods are unsupervised approaches, the method inherently bears the possibility of producing unnatural image signals. Because learning-based methods could easily lose detailed signal information in deep-hidden layers, the methods may generate insufficient detail signals or erroneous detail signals. Therefore, learning-based methods mainly improve the global contrast and color brightness; however, it has limitations in generating or inferring detail image signals. Moreover, learning-based methods commonly require heavy computation, compared to model-based methods.
We develop a frequency domain method that enhances an image to be perceived as being both clearer and of a higher resolution, distinguished from existing methods that enhance images to be clearer, only. The proposed method further decomposes the detail image signals into local variant and granular signals. To increase the sharpness of local variant signals, we devise a recursive frequency energy scaling-up method from the perceived contrast model that indicates the visual sensitivity of detail signals in the frequency domain. We enhance the frequency components by the alpha-rooting while scaling up the frequency energy to embed the granular signals harmonically on the local variant signals. We also design the energy scalar to emphasize the detail image signals at texture images and suppress the increasing noisy patterns in plain images. Additionally, to reduce the ringing artifact, we devise a method for tuning the enhancement direction to be parallel with the signal direction in the DCT domain.
The remainder of this paper is organized as follows.
Section 2 discusses the perceived contrast measure in the DCT domain.
Section 3 proposes the perceptual contrast increment method that recursively modifies DCT coefficients and presents a method to avoid artifacts and noise boosting.
Section 4 evaluates the proposed method’s performance, compared to existing enhancement methods, and analyzes the artifacts caused by enhancement methods.
Section 5 reaches conclusions.
2. DCT Domain Human Perceptual Contrast
Many psychological and physiological studies have reported that human visual neurons accept visual signals in frequency components; thus, human visual perception is primarily affected by the frequency energy distributions of images [
13,
14]. The image signal components in the frequency domain are also efficiently separated and robustly processed. Therefore, we adopt the DCT as the enhancement platform.
Let
be an image pixel value at position
of the
DCT block. The DCT coefficient
is obtained as follows:
where
When the ratio between the viewing distance and display height is
and the vertical pixel number of the displayed image is Pix, the spatial frequency,
, in actual viewing conditions is converted into the DCT frequency as follows:
where
Several studies have found that the human physiological visual sensitivity varies in the spatial frequency, is highest at 3 ∼ 5 cycles/degree, and is higher in the vertical and horizontal directions than in the diagonal direction because of the oblique effect. The studies also have modeled the visual sensitivity in the DCT domain, referred to as the contrast sensitivity function (CSF) [
15,
16]. The CSF in the DCT domain is as follows:
where the direction angle is
.
In addition to the CSF, the human visual sensitivity at specific frequency is also affected by the frequency energy distribution of an underlying image. Haun and Peli conducted experiments measuring human visual sensitivities to stimuli with different frequencies and directions, deriving a human visual sensitivity model, called perceptual contrasts (PC) [
13,
14]. The perceptual contrasts (PC) are as follows:
where
is the background energy at
. The background energy with respect to
is the energy accumulation of the frequency components lower than
[
5,
14]. That is,
The PC indicates that human visual sensitivity is higher for the frequency components with a larger CSF value, lower background energy and larger frequency energy [
13,
14]. While the existing contrast measurements quantify image signal variations in the spatial domain, the PC measures how much a human actually perceives each frequency component and thus, provides the contrast measure more matched with human visual perception.
3. Development of Human Perception Oriented Detail Image Enhancement
We develop a detail image signal enhancement method that recursively increases the perceptual contrast (PC) and simultaneously intensifies the granular signals. In addition, to avoid the ringing artifact, we devise a method that adjusts the enhancement direction to be parallel to the image signal direction.
3.1. Perceptual Contrast (PC) Based Energy Scaling Method
Human visual perception generally prefers images with higher visual sensitivity [
17]. In order to increase human perceived visual sensitivities at frequency components, we propose a method that recursively scales up the PC as the frequency proceeds from low to high band.
The original and enhanced DCT coefficients are denoted as
and
, respectively. Subsequently, the perceptual contrast at
of the original and enhanced images are denoted as
and
, respectively. Introducing the PC-enhancing scalar,
,
is related to
in the following way:
By inserting (
4) to (
6), the following equation is obtained:
where
is the energy scaling factor and the following holds:
To enhance the granular signals, the alpha rooting method is exploited, which emphasizes the energy of high-frequency components. The frequency component enhanced by the alpha rooting method is as follows:
where
is the enhancement factor. As
is closer to 0, the higher-frequency components are emphasized to generate more granular signals.
Then,
embedding the alpha routine enhancement becomes the following:
is recursively updated from (
7) and (10) as the frequency increases.
The role of is to control the enhancement in adaptation with the characteristics of the image signals. Since has high values at middle-frequency components corresponding to local variant image signals, correspondingly has large values at these frequency bands so that it primarily enhances the local variant signals to produce sharpened images. Because the alpha rooting enhanced frequency component is embedded into , the granular signals become more visible, while the noise signals probably occurring from the enhanced high-frequency signals are prevented. Thus, in texture images typically having a large energy at middle- and high-frequency components, enhances the detail signals while revealing the granular signals. In plain images that do not contain many detail image signals, the frequency energies of detail image signals are much smaller that those of , and dominates over the background energy. Therefore, becomes approximately 1 at all frequency bands and rarely produces noise signals that may occur if the plain image signals are enhanced.
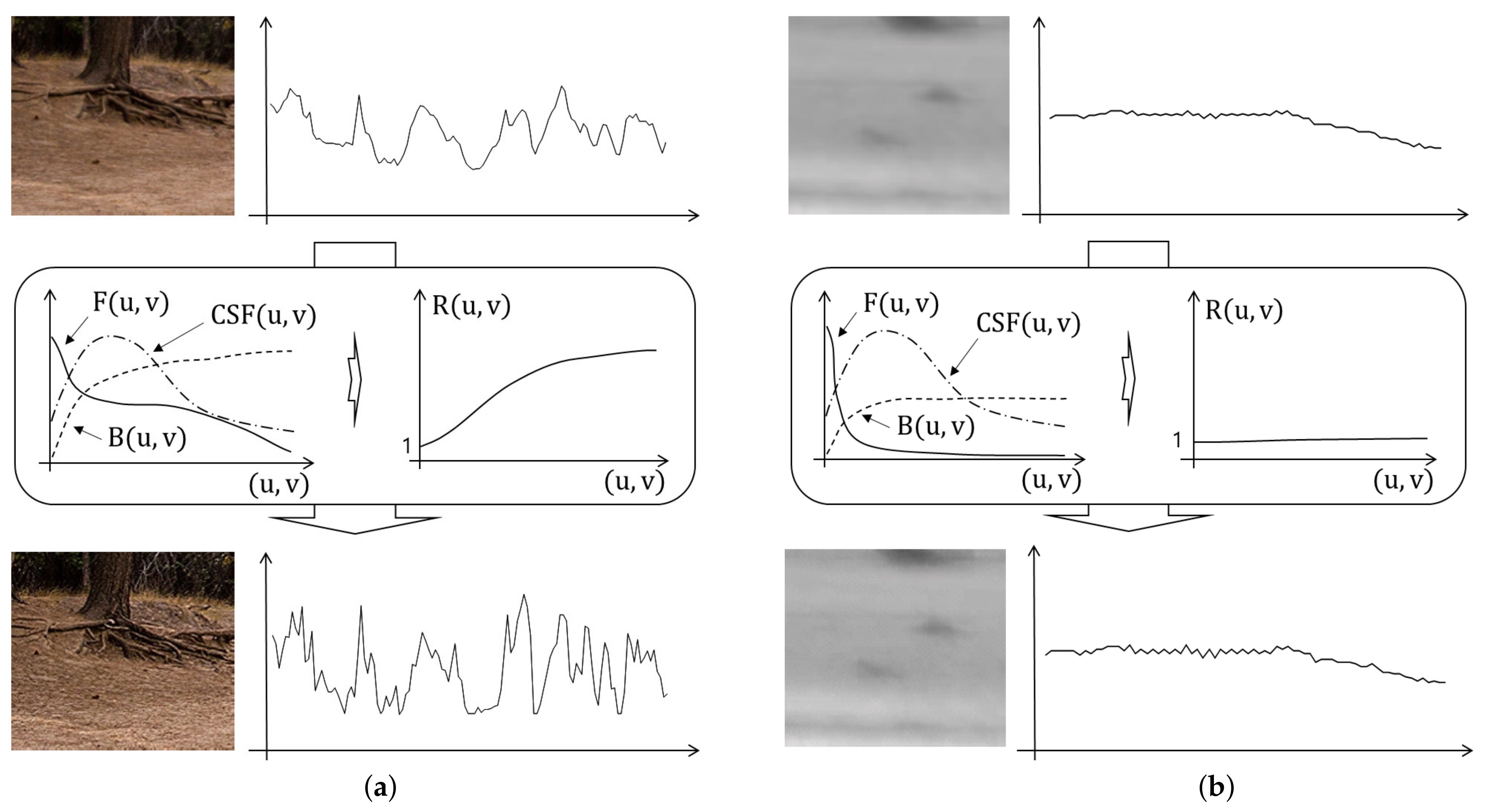
Figure 2 compares
for the texture and plain images and shows their detail enhanced images. The texture image is shown in
Figure 2a, where the proposed method not only increases local variations but also embeds granular signals in local variant signals. The plane image is shown in
Figure 2b, where the proposed method rarely enhances the image signals and does not produce noisy image signals.
3.2. Signal Direction Adaptive Enhancement
We develop the DCT domain method to remove the ringing artifact. When directional images, such as edges, are not processed in parallel with their directions, overshooting occurs, which appears as ringing patterns. The ringing artifact is apparent as the enhancement direction becomes more perpendicular to the image direction. To prevent ringing artifacts, the enhancement direction must be parallel to the signal direction.
Figure 3 shows the DCT energy distribution of edge and texture images. As shown in
Figure 3a, when an image signal is directed more vertically, the energy of the DCT coefficients is further condensed in the first row. Conversely, more horizontally directed signals have greater energy from the DCT coefficients in the first column as shown in
Figure 3b. In the diagonal signals, the DCT coefficients are symmetric such as in
Figure 3c. Therefore, the magnitudes of the first column and row DCT coefficients are equivalent to the gradients in the vertical and horizontal directions [
18,
19]. Let
and
be the vertical and horizontal gradients, respectively. Then, the following hold:
where
As an image signal slants closer to the vertical direction, is larger than . When an image signal is directed diagonally, .
To adjust the energy scaling direction, the DCT coefficients are decomposed into horizontal and vertical directions. The recursive PC scaling factors for the horizontal and vertical directions are obtained as follows:
Then, the enhanced DCT coefficients for each direction become the following:
To steer the PC scaling direction in parallel with the image signal direction, we weight each gradient to vertical and horizontal enhanced DCT coefficients. So, we propose the direction adaptive enhanced DCT coefficients as the following:
where
.
The energies of the DC and low-frequency bands control the overall brightness of the DCT block. A change in the energy in the DC and low-frequency bands induces a brightness discontinuity among adjacent blocks, called the block artifact. The existing methods that avoid block artifacts do not scale the energies at DC and the first three frequency bands [
20]. Following the existing methods, we do not scale the energy at the first three bands by setting
as follows:
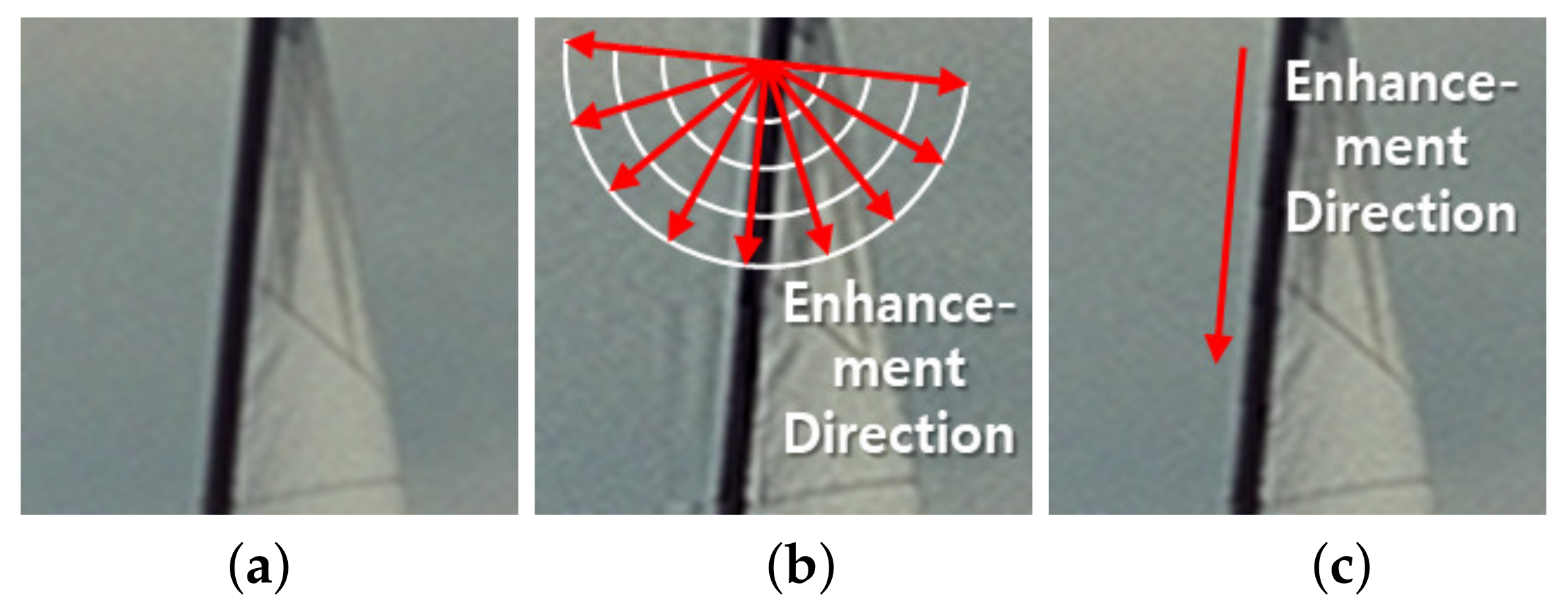
Figure 4 shows the edge images enhanced by the proposed method without the signal direction adaptive method and the proposed method with the signal direction adaptive method. Not using the signal direction adaptive method creates ringing artifacts at the sail edges; however, the direction-adaptive method tunes the DCT-coefficient scaling direction in parallel with the sail edge direction to avoid visible ringing artifacts.
Figure 5 shows the edge images enhanced by MESM, CWM and the proposed method. The proposed method and CWM do not create the ringing artifact, whereas MESM does, as it enhances image signals in all directions. The CWM linearly scales up the frequency components as the frequency increases. Hence, it does not significantly change low- and middle-frequency components corresponding to edge signals and avoids visible ringing artifacts. As discussed in this section, the proposed method scales up the frequency components in parallel with the edge direction, and so does not make the ringing artifact.
3.3. Outline of the Proposed Method
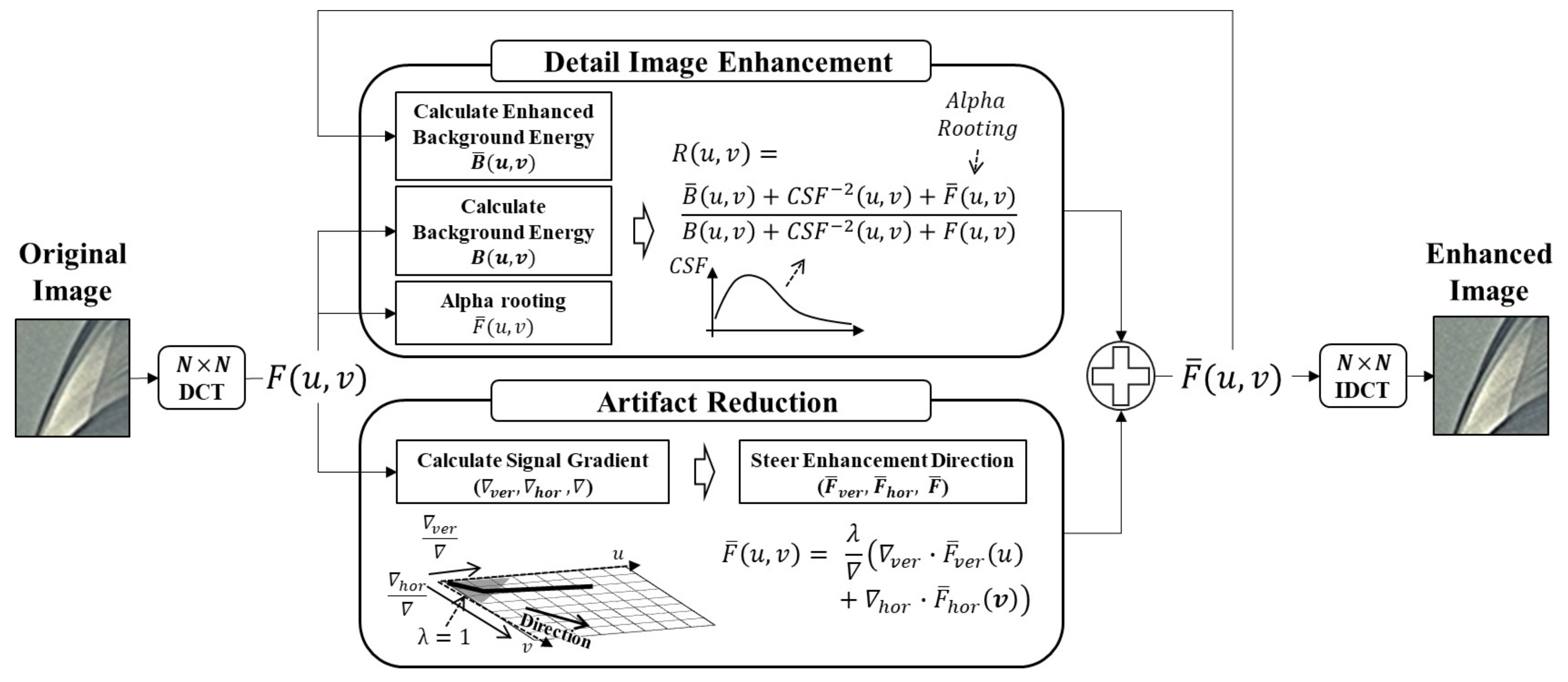
Figure 6 shows an overview of the proposed detail image enhancement method. The method consists of detail signal enhancement and artifact reduction.
In part of the detail image signal enhancement, the frequency energies are recursively scaled up in match with the human-perceived contrast. The proposed method designs the energy scalar from the perceived contrast embedding the alpha-rooting enhanced frequency components. enhances the detail image signals in texture images suppressing the enhancement of noisy signals in plain images. Additionally, since the alpha rooting enhanced frequency component is embedded into the perceived contrast, the granular signals become more suitable for human visual perception.
In part of the artifact reduction, the proposed method measures the vertical and horizontal gradients in the DCT domain. To reduce ringing artifacts, the proposed method adjusts the frequency energy scaling direction parallel to the image signal direction by weighting each gradient to the enhanced DCT coefficients in the horizontal and vertical directions.
We analyze the computing complexity of the proposed method. Our method is the time method, where N is the block size. So, the large block size requires less computing time. If the block size is 16, the computing time of the proposed method is 118 msec per 1 mega pixel on a processor of intel I5-2500 3.3 GHz and 8 GB RAM. Thus, our proposed method would be processed in real time at full HD image.
5. Conclusions
We exploited the human perceptual contrast that measures the sensitivity of human visual perception to frequency components. Based on the perceptual contrast measure, we developed a frequency energy scaling-up method that not only emphasizes the local variant signals, but also strengthens the granular signals embedded in the local variant signals. Additionally, we developed a method to control the enhancement strength in adaptation to the characteristics of the underlying image signals. To reduce the ringing artifact, we devised a method that adjusts the enhancement direction to be parallel to the signal direction in the DCT domain. Therefore, the developed method enhances images to be perceived as clear and finely resolved, while avoiding any visible artifacts.
For improvements and further application of the proposed method, future work could proceed as follows. To increase enhancement performance, it is required to tune lambda adaptively to the underlying image signals. It would also be beneficial to extend the proposed method to color channels. For applications, in super-resolution, low-light, de-haze, and under-water areas, the parts—especially
—of the proposed method could be positively exploited to efficiently enhance the detail images. Additionally, the proposed method could be applied to next generation displays for virtual and augmented reality [
29,
30].













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}